1. Introduction
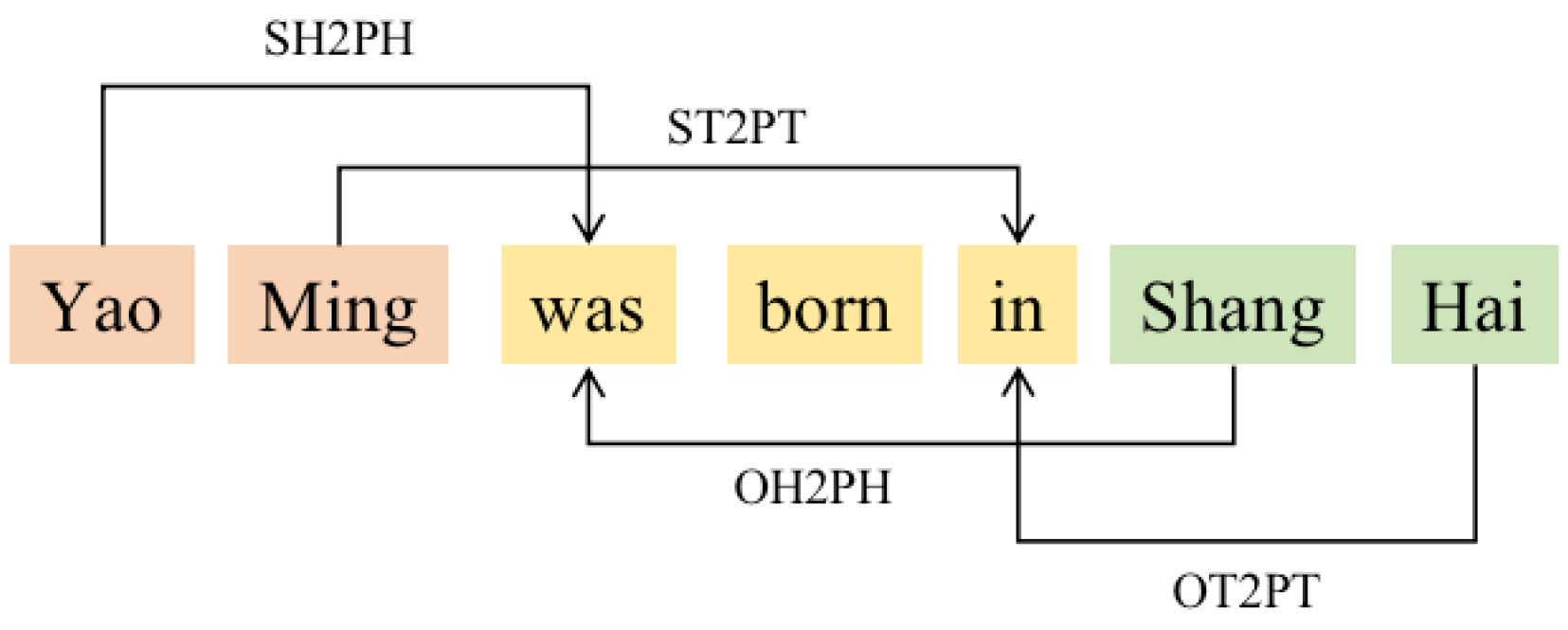
With the rapid development of the web, the Internet is currently flooded with texts of all kinds, including news, chat conversations, professional books, etc. It will be of great value if we can discover valuable knowledge from this large web data. Knowledge extraction enables us to extract valuable knowledge from large text corpora quickly and accurately. Knowledge extraction includes two subtasks, named entity recognition and relation extraction. Named entity recognition and relation extraction are two core tasks that output structured representation in the form of relational tuples (Entity1, RelationWords, Entity2). For example, in the sentence “Yao Ming and Yi Jianlian were born in Shang Hai and Guang Dong respectively”, we can extract the knowledge tuple: {”Subject”: “Yao Ming”, “Predicate”: “born in”, “Object”: “Shang Hai”}, {“Subject”: “Yi Jianlian”, “Predicate”: “born in”, “Object”: “Guang Dong”}. These tuples can be used to construct a knowledge graph, which is further used in Q and A or recommendation systems.
Although many knowledge extraction systems have achieved reasonable performance, especially in English data. However, traditional knowledge extraction systems have two main drawbacks. Firstly, some systems are carried out through a knowledge extraction pipeline; thus, the named entities are extracted first, and then the relationships are determined through relationship classification. This pipeline leads to error accumulation and affects the final end-to-end performance. On the other hand, some systems are only suitable for closed domain knowledge extraction; thus, the entity types and relationships are fixed. Therefore, such systems can not meet the requirements of open-domain knowledge extraction, where relations are massive and undefined in advance.
For Chinese knowledge extraction systems, the development is slower than in English ones for two reasons. Firstly, there is a lack of Chinese annotated corpus. Especially when we use a neural network model, a large-scale training corpus is needed. In addition, the Chinese language is more sophisticated and flexible than English in morphology, syntax and grammar, which makes open-domain knowledge extraction more difficult [
1]. There are more entity nesting and relation nesting issues in Chinese sentences. Knowledge extraction from Chinese biomedical text is more challenging because the sentence structure is complicated, and most of the sentences contain multiple relationships. According to [
2], from a statistic analysis of 3000 sentences from Chinese biomedical text, about 66% of the sentences are multiple relation-bearing sentences.
Traditional Chinese knowledge extraction systems are based on the results of Dependency Parsing (DP) [
3] and then combine rules to extract relation tuples. With the development of deep learning, especially the successful application of pre-training language models such as BERT [
4,
5] in the field of natural language understanding, more and more researchers have begun to adopt deep neural network models in knowledge extraction tasks. For fixed-domain relation extraction, the deep neural network model has made good achievements.
In this paper, we studied how to extract open knowledge from unstructured Chinese text. Given a Chinese text fragment, our task is to extract entities and their relationships. Entity types and relationship types are not predefined. The formal problem definition is given in
Section 3.
Generally speaking, we faced two challenges. The first one is the nested entities and nested relationship issues, and we used a handshaking tagging scheme to alleviate this issue. Handshake tagging is very flexible, where it treats the predicate entity like the subject and object entity and solves the scenario of an unfixed relationship in the open domain. The second one is the imbalance issue since the naive multi-label classification method uses Sigmoid as the activation function and then turns it into d two-classification problems, using the sum of binary cross-entropy (BCE) as the loss. Moreover, in our model, the entity mentions were arranged and combined, and each position may have multi labels, which leads most positions of the matrix are label 0, and only a few labels are label 1, which causes an imbalance issue. During training, traditional BCE loss tends to identify all labels as 0 in the first few rounds, resulting in almost no relationship can be extracted in the early stage of training. Therefore, we adopted a new loss function that conducts a pairwise comparison of target category score and non-target category score to automatically balance the weights, and experiment results indicate that the new loss function can not only greatly improve the convergence speed in the early stage, but also increased the experimental results slightly.
We proposed an end-to-end Chinese knowledge extraction model leveraging BERT and a handshaking tagging scheme [
6]. The proposed model can alleviate the nested entities and nested relations issues in complex Chinese sentences; additionally, with the help of the pre-training model, the migration ability of the model can be improved.
The major contributions of this paper are: (i) Our proposed method is able to handle named entity recognition, fixed domain and Open-domain Relation Extraction simultaneously. (ii) We adopted a new loss function defined in Formula (5). The new loss function does not turn multi-label classification into multiple binary classification problems; instead, it conducts a pairwise comparison of target category score and non-target category score to automatically balance the weight, which can alleviate imbalance issues in multiple binary classifications. The new loss function brings speed and performance improvements. (iii) Experiments on open domain data (COER [
1] and SpanSAOKE derived from SAOKE [
7]) show that our method has a significant improvement over strong baselines. In the COER dataset, F1 increased from 66.36 to 79.63, and in the SpanSAOKE dataset, F1 increased from 46.0 to 54.91. Our method can obtain close performance compared with the SOTA method in the CMeEE [
8] and CMeIE [
9] datasets.
2. Related Work
In the beginning, knowledge extraction mainly focused on fixed-domain relation extraction. With the accumulation of web data, more and more researchers are beginning to extract knowledge from open domains. Therefore, open relation extraction has become the mainstream of research. Another trend is from supervised learning to unsupervised or distant supervised learning approaches. Recently, with the development of deep learning, more and more neural network methods such as pre-training language models are used in knowledge extraction systems.
The existing knowledge extraction methods can be divided into two main categories:
In the following sections, each category is reviewed in detail.
2.1. Fixed-Domain Relation Extraction (FRE)
Fixed-domain relation extraction, also known as traditional relation extraction, requires defining entity types and relationships between entities in advance. Once the types of entities and relations are determined, no new entities and relations are extracted. Traditional knowledge extraction systems use predefined extraction rules or annotated data to learn extractors, mainly based on feature engineering and statistical supervised machine learning methods [
10,
11,
12,
13,
14,
15,
16,
17]. These methods need a lot of annotated data. Other work is based on unsupervised methods [
18,
19] by clustering representative relationship words and using these relationship words as triggers to extract relationships. Generally, FRE adopts two kinds of methods: the pipelined method and the joint model.
Pipelined method: The pipelined method transforms the task into two subtasks, named entity recognition (NER) [
20] and relation classification (RC) [
21]. Mintz et al. [
22] proposed an alternative paradigm called Distant Supervision to train a text classifier with a large unlabeled corpus. Zhong et al. [
23] used two independent encoders to learn different contextual representations of entities and relations, respectively, and fuse entity category information at the input layer of the relational model.
Joint model: pipelined models are often considered inferior to joint models because breaking the relation extraction task into subtasks can lead to error propagation, so the relation extraction work based on the joint model is also gradually expanded. Zheng et al. [
24] proposed a novel tagging scheme that can convert the joint extraction task into a sequence labeling problem. Wang et al. [
6] used a handshaking tagging scheme that aligns the boundary tokens of entity pairs under each relation type.
However, it is difficult to cover all relational facts in a predefined way. Once the domain data are replaced, the task not only needs to rename the entity relation but also needs to manually define new extraction rules or re-label new training data. As such, these systems rely heavily on human intervention.
2.2. Open Domain Relation Extraction (ORE)
In order to reduce the manual effort required by FRE, Banko et al. [
25] introduced a new extraction paradigm, open-domain relation extraction [
26]. In this way, it is helpful to independently extract the relations in the open domains, and it has good transferability.
Systems based on self-supervised learning include TextRunner [
27] and WOE [
28]. TextRunner proposes a deep-level grammar parser to automatically extract triples from a web corpus. It first learns a Bayesian classifier, then generates all candidate triples for the input sentence; after that, it retains the results with high confidence through the classifier, and finally, it filters out unqualified results by counting the frequency of triples in the text. PGCORE [
29] proposed Pointer-Generator Networks to extract open-domain relations end-to-end, which outperforms rule-based methods, but it only considers the case where there is a single triple in the sentence. SpanOIE [
30] first finds the predicates in the sentence, then takes the predicate and the sentence as an input and outputs the argument pairs that belong to this predicate. However, most neural OpenIE systems, including PGCORE and SpanOIE, cannot extract appositive relations. A complex sentence may contain multiple groups of entities and relations, and none of the above models or systems can solve this issue perfectly. CasRel [
31] first extracted the subject and then the corresponding object for each relation type separately, which can solve various overlapping problems. However, it has low computational efficiency due to the variable number of subjects during prediction, and the batch size can only be set to 1. PRGC [
32] used sequence labeling combined with token pair global correspondence matrix, which has higher robustness. However, it relies on pre-steps such as potential relation judgment, so the pre-steps need to prioritize recall. PRGC claimed to solve the sparse problem in handshake extraction; however, its optimization is limited to fixed relationship fields. PRGC needs to identify which relationships are contained in the given text first and then add the relationship type as a feature to the subsequent relationship extraction, which limits its application to open relationship extraction. Similarly, PURE also needs to conduct relationship classification. By optimizing decoding labels, OneRel [
33] reduces redundant information and generates more deep interactions. The one-stage decoding method used is more direct and efficient, which can reduce error propagation. However, OneRel still cannot change the common problem of the global information matrix-relational redundancy and too many negative samples.
3. Problem Definition
Open-domain relation extraction is one of the main tasks for building a knowledge graph. It aims to extract triples from unstructured text. Different from FRE, all the values in the triples extracted by ORE come from the text. Therefore, ORE can be seen as a combination of the named entity recognition task and entity pairing task.
Let X denote an input sentence, denotes a set of subjects extracted from X, the predicate set P and the object set O follow the same definition. Therefore, there are different combinations of triples, where and are the number of the subject set, predicate set and object set, respectively.
For each combined triple
, the ORE task is to determine whether t is a correct pairing result, and the objective function of the model is given Formula (1):
where
is the parameters of the whole model, G(t) indicates whether triple t is correctly classified. Therefore, the task of the model is not only to ensure that the relational elements identified by the model are correct but also to ensure that they are correctly paired.
5. Experiments
5.1. Dataset
We conducted our experiments using four datasets, two general domain datasets, “COER” [
1] and “SpanSAOKE” [
35], and two medical domain datasets, “CMeEE” and “CMeIE”. COER (Chinese open entity and relation) includes NER and ORE tasks, and SAOKE (Symbol Aided Open Knowledge Expression) has FRE and ORE tasks. Medical domain datasets are CMeEE (Chinese Medical Entity Extraction dataset) [
8] and CMeIE (Chinese Medical Information Extraction dataset) [
9]. The proposed method is suitable for NER, FRE and ORE tasks, so the four public datasets are used for experiments.
COER is a scalable entity and relation corpus that currently contains approximately 1 million relation triples, where relations are open and arbitrary. It aims to promote the research of Chinese information extraction. Since the data set is too large, we randomly selected 20,000 pieces of data and divided them according to 8:1:1 for k-fold cross-validation.
SpanSAOKE comes from the original dataset SAOKE [
7], a large-scale sentence-level dataset for Chinese open information extraction. SpanSAOKE filtered out unknown, description and concept facts due to these having missing subject, predicate and object or introducing special predicates such as “ISA ” and “DESC”.
Besides COER and SpanSAOKE datasets, in order to verify the performance of our model in the medical domain, we also conducted comparative experiments on two medical data sets, CMeEE and CMeIE.
CMeEE is a dataset of medical documents that was developed to identify and extract clinically relevant entities and classify them into nine predefined categories. In CMeEE, an entity can be a word, phrase or sentence, and there are entity nesting cases.
CMeIE is a fixed-domain relation extraction dataset containing a pediatric training corpus and hundreds of common diseases. The datasets are derived from medical textbooks, clinical practice, chief complaints, current illness history, differential diagnosis, etc., in electronic medical record data.
5.2. Evaluation
Following previous work, we used Exact Match and Partial Match precision(P), recall(R) and F1-measure(F1) as evaluation metrics in our experiments. In particular, we used Exact Match in dataset COER and Partial Match in dataset SpanSAOKE. Since there are some nested cases in the dataset SpanSAOKE, the predicate may be rewritten during the manual labeling process. However, the extracted predicate by our mode is the original fragment in the sentence. Therefore, Partial Match was used in the dataset SpanSAOKE evaluation.
For Exact Match, the starting and ending positions of each element of the extracted triplet must be exactly the same. For Partial Match, the criterion for judging whether two triples
and
match is to satisfy: (1)
or (2)
, where
is the gestalt pattern-matching function [
36],
concatenates triple components as a whole string and the threshold
= 0.85.
5.3. Hyperparameters
Table 2 shows the major hyperparameters in our model, and we use a unified setting for all of the ablation experiments.
5.4. Experiment Results
We compared our proposed approach TPORE with several competitive baselines for Chinese open relation extraction.
UnCORE [
18] exploits using word distance and entity distance constraints to generate candidate relation triples from the raw corpus and then adopts global ranking and domain ranking methods to discover relation words from the candidate relation triples.
ZORE [
37] is a syntactic-based system, which identifies relation candidates from automatically parsed dependency trees, and then extracts relations with their semantic patterns iteratively through a novel double propagation algorithm.
PGCORE [
29] casts relation extraction as a text summary task and proposes an end-to-end abstract Chinese Open RE model based on the Pointer-Generator Network.
SpanOIE [
30], instead of the previously adopted sequence labeling formulization for n-ary OpenIE, first finds predicate spans and then takes a sentence and predicate span as input and outputs argument spans for this predicate.
MGD-CNN [
35] constructs a multi-grained dependency (MGD) graph with dependency edges between words and soft-segment edges between words and characters and updates node representations using a deep graph neural network to fully exploit the topology structure of the MGD graph and capture multi-hop dependencies.
Table 3 shows the experiment results of ZORE, UnCORE and PGCORE, and we used the results in their original papers. As shown in
Table 3 and
Table 4, experiment results in COER are much higher than SpanSAOKE; even an exact match is used in the COER dataset. By analyzing the data, we found that cases in SpanSAOKE are much more sophisticated than COER. First, the average sentence length of the COER is 21, while the average sentence length of SpanSAOKE is 46. Previous work can capture context information, even using the LSTM model, and obtain a higher precision in the COER dataset. We also statistically analyzed the case that one sentence contains multiple triples; in COER, 25% percentage of sentences contain multiple triples, while in SpanSAOKE, the percentage is 53.9%. Since our model is good at dealing with the situation of multiple triples in one sentence, compared with previous methods, our method can greatly improve recall and F1 with comparable precision.
Table 4 shows the experiment results of ZORE, charLSTM, Span OIE, MGD-GNN, and for charLSTM, Span OIE and MGD-GNN, we used the results in their original papers.
Table 4 shows the experiment results in the SpanSAOKE dataset; our model obtained the best performance in P, R and F1. The model learned the paradigm of each element in ORE, as a large number of relations that are not present in training data are extracted correctly in test data. Our model can solve various nesting problems, while other works cannot handle the situation where there are multiple entities and relations in a single sentence very well. This is also the main reason why the performance of our model is significantly higher than in previous works. For example, the sentence “Cooling water, the full name should be called antifreeze coolant, which means coolant with antifreeze function” contains two sets of relations, <cooling water, full name, antifreeze coolant> and <antifreeze, means, coolant with antifreeze function>. Among them, “antifreeze coolant” is both the object of the former relation triple and the subject of the latter relation triple. Our model decoding method can handle this situation, which is difficult for other models.
Traditional unsupervised Chinese open relationship extraction methods (ZORE and UnCORE) are generally based on dependency parser and semantic paradigm (DSNF), which are used to extract the relationship between verbs and nouns. These methods heavily rely on the performance of word segmentation, entity recognition, dependency parser and pattern quantity and quality. Some deep learning models, such as PGCORE, use the pointer mechanism and simplification of the open relationship extraction task because it can only extract a group of open relational triples from a single sentence. Our proposed approach can enumerate all triples; therefore, the proposed model can extract as many triples as possible and improve recall. MGD-GNN uses a graph neural network to extract the relationships between entities, but the performance is affected by the long dependency path. The proposed method can extract relationships in a long dependency path between each entity pair.
5.5. Ablation Experiments
We also conducted ablation experiments, as shown in
Table 5. BCELoss means the model uses the BCE loss function and keeps the other parameter unchanged. From
Table 5, we can see that our proposed loss function in Formula (5) can improve the final performance. Moreover, we conducted an experiment to verify the advantage of the new loss function in terms of convergence speed.
Figure 4 illustrates the results, the horizontal axis is the number of iterations, and the vertical axis represents F1 scores. From
Figure 4, we can see that the new loss function could more effectively speed the convergence rate than BCE Loss. In summary, our proposed loss function not only improves the F1 score but also speeds up convergence.
3HS means the model uses three-times-handshaking decoding instead of twice-handshaking decoding and keeps the other parameter unchanged. Strangely, compared with 2HS, three-times-handshaking does not bring better experimental results. Through careful analysis of test data, we found there are few sophisticated cases like the case shown in
Figure 3. Although these sophisticated cases can be solved by introducing three-times-handshaking, the decoding of other simple triples becomes more stringent by shaking hands once more. From the results of the experiment, the low recall is the main factor that ultimately affects the performance of F1. Although one more handshake can solve the problem in
Figure 3, it improves the precision but hurts the recall and decrease F1.
5.6. Experiment Results on NER Task and FRE Task
In order to evaluate the effectiveness of the model on the NER and FRE task, we selected the NER dataset CMeEE [
8] and the FRE dataset CMeEE [
9] from the public benchmark CBLUE [
38]. For each task, we selected the SOTA methods to compare with our model. From
Table 6 and
Table 7, we can see our model has a performance that is not inferior to SOTA. Our model obtained higher precision than BERT-CRF [
39] model and obtained better recall than BERT-CRF, BERT-MRC [
40] and BERT-SPAN [
41] models. On F1, our model outperforms BERT-CRF and BERT-MRC. For the FRE task, our model obtained higher precision than the PURE [
23] model and obtained better recall than the TPLinker model [
6]. On F1, our model outperformed PURE.
Based on the above experiment results and analysis, we can conclude that our model can reach the SOTA level in NER, FRE and ORE tasks, especially in ORE tasks, and achieve a new SOTA.







{kind=link}
{kind=link}
{kind=link}
{kind=link}