
Research on Long Text Classification Model Based on Multi-Feature Weighted Fusion


Abstract
:1. Introduction
2. Materials and Methods
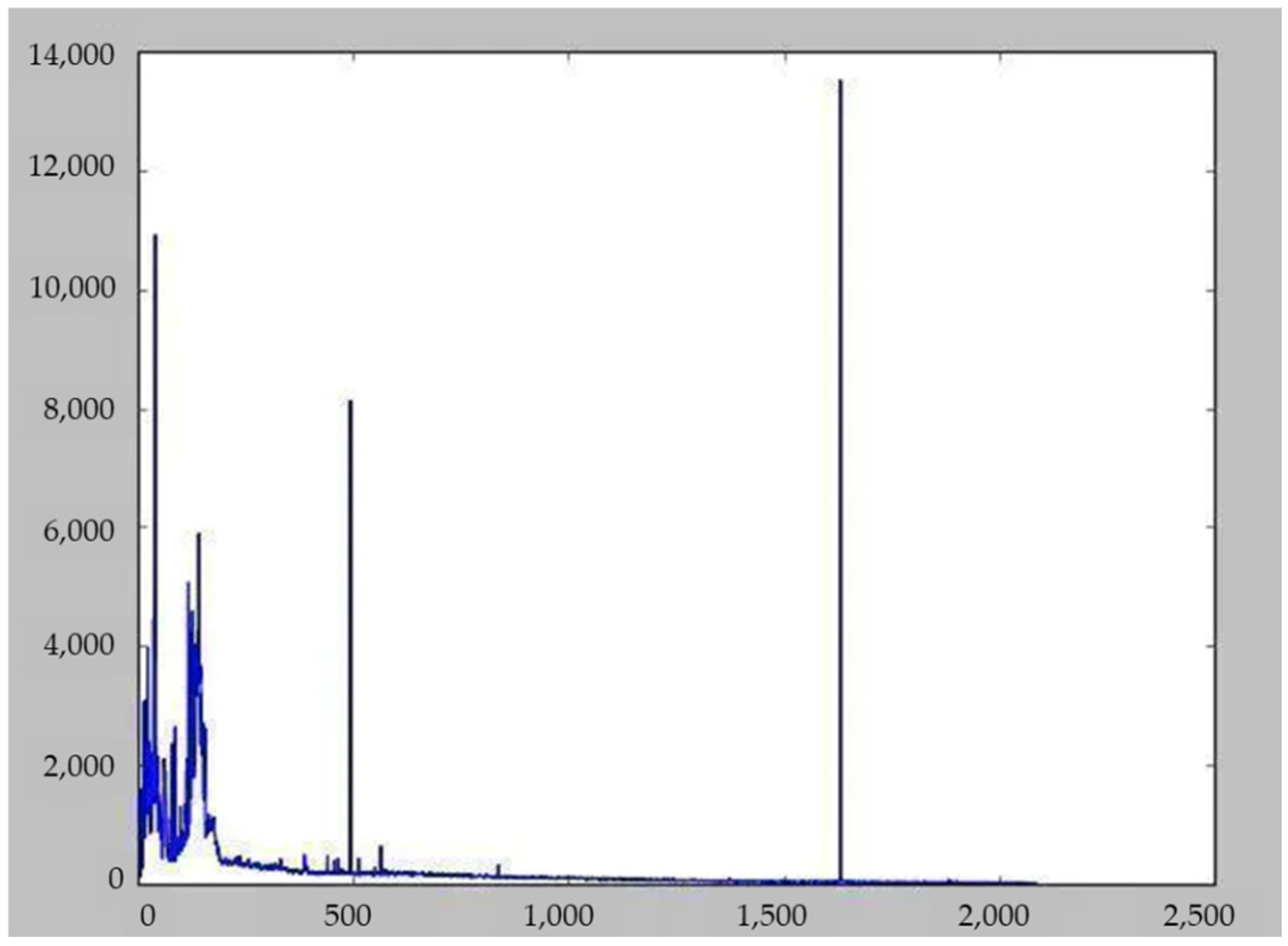
2.1. DataSet
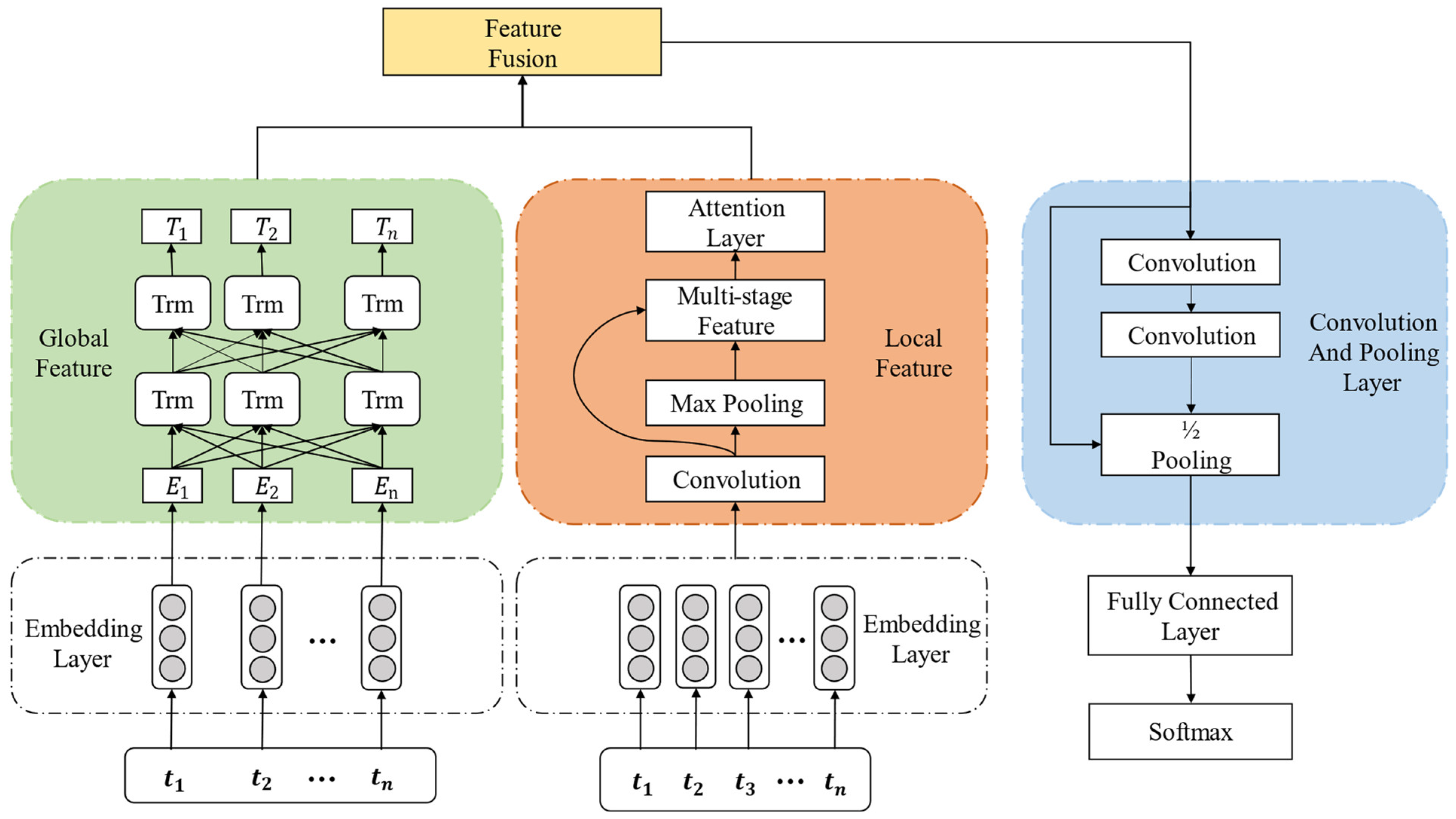
2.2. Methods
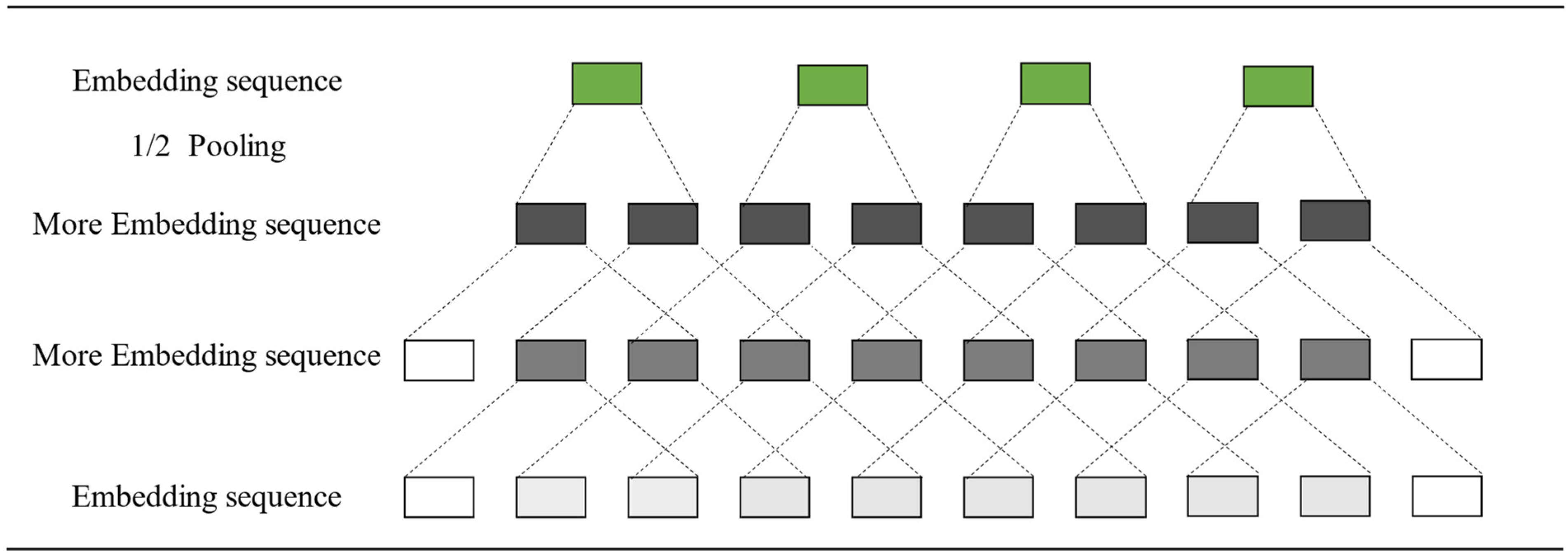
2.2.1. Word Embedding Layer
2.2.2. Feature Fusion Layer
2.2.3. Convolution Pooling Layer
3. Results
3.1. Experimental Environment and Design
3.2. Scoring Criteria
- Accuracy
- 2.
- Precision
- 3.
- Recall
- 4.
- F1 value
- 5.
- Macro Average
3.3. Experimental Results
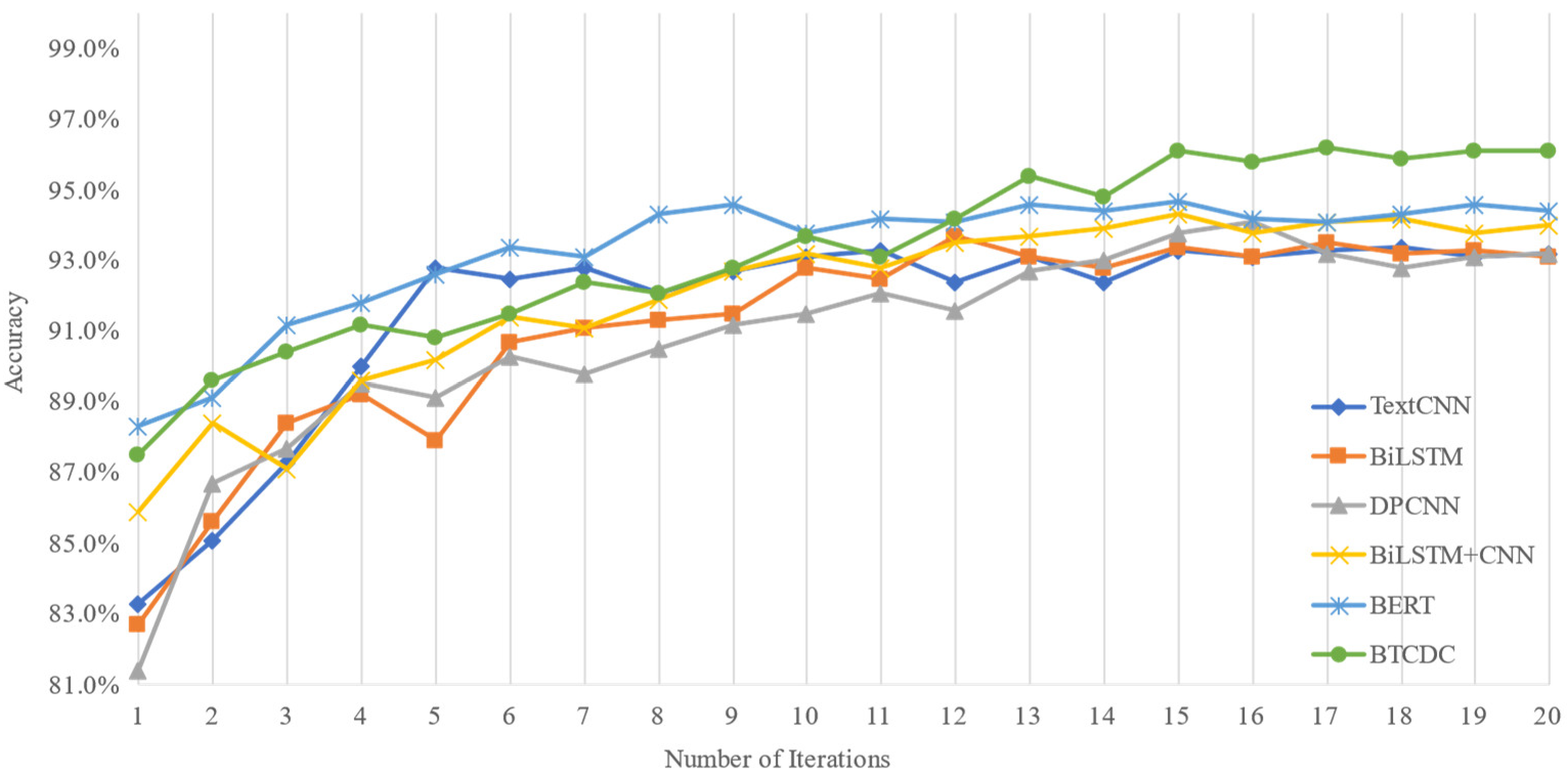
3.3.1. Experimental Results on the THUCNews Dataset
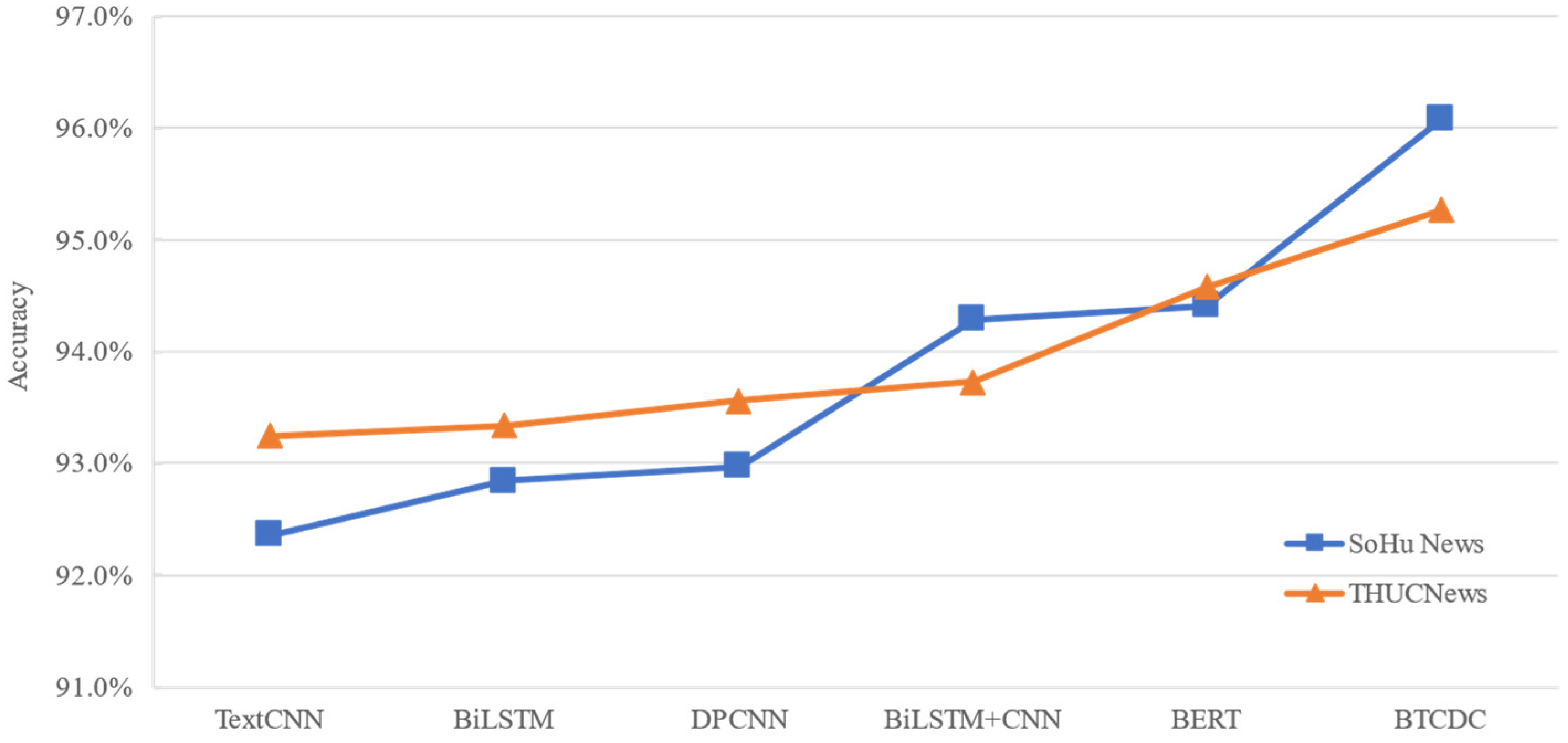
3.3.2. Experimental Results on Sohu News Dataset
3.3.3. Ablation Experiments Result
4. Discussion
4.1. Discussion of Experimental Results on the THUCNews Dataset
4.2. Discussion of Experimental Results on the Sohu News Dataset
4.3. Discussion of the Results of Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Salehan, M.; Kim, D.J. Predicting the performance of online consumer reviews: A sentiment mining approach to big data analytics. Decis. Support Syst. 2016, 81, 30–40. [Google Scholar] [CrossRef]
- Khatua, A.; Khatua, A.; Cambria, E. A tale of two epidemics: Contextual Word2Vec for classifying twitter streams during outbreaks. Inf. Processing Manag. 2019, 56, 247–257. [Google Scholar] [CrossRef]
- Koleck, T.A.; Dreisbach, C.; Bourne, P.E.; Bakken, S. Natural language processing of symptoms documented in free-text narratives of electronic health records: A systematic review. J. Am. Med. Inform. Assoc. 2019, 26, 364–379. [Google Scholar] [CrossRef]
- Xu, D.; Tian, Z.; Lai, R.; Kong, X.; Tan, Z.; Shi, W. Deep learning based emotion analysis of microblog texts. Inf. Fusion 2020, 64, 1–11. [Google Scholar] [CrossRef]
- Luo, Y.; Xu, X. Comparative study of deep learning models for analyzing online restaurant reviews in the era of the COVID-19 pandemic. Int. J. Hosp. Manag. 2021, 94, 102849. [Google Scholar] [CrossRef] [PubMed]
- Luhn, H.P. The Automatic Creation of Literature Abstracts. IBM J. Res. Dev. 1958, 2, 159–165. [Google Scholar] [CrossRef] [Green Version]
- McCallum, A.; Nigam, K. A comparison of event models for Naive Bayes text classification. In AAAI-98 Workshop on Learning for Text Categorization; AAAI Press: Menlo Park, CA, USA, 1998; pp. 41–48. [Google Scholar]
- Zhai, Y.; Song, W.; Liu, X.; Liu, L.; Zhao, X. A chi-square statistics based feature selection method in text classification. In Proceedings of the 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 November 2018; pp. 160–163. [Google Scholar]
- Liu, C.-z.; Sheng, Y.-x.; Wei, Z.-q.; Yang, Y.-Q. Research of text classification based on improved TF-IDF algorithm. In Proceedings of the 2018 IEEE International Conference of Intelligent Robotic and Control Engineering (IRCE), Lanzhou, China, 24–27 August 2018; pp. 218–222. [Google Scholar]
- Han, K.-X.; Chien, W.; Chiu, C.-C.; Cheng, Y.-T. Application of Support Vector Machine (SVM) in the Sentiment Analysis of Twitter DataSet. Appl. Sci. 2020, 10, 1125. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Sutskever, I.; Martens, J.; Hinton, G.E. Generating text with recurrent neural networks. In Proceedings of the 2011 International Conference on Machine Learning (ICML), Bellevue, WA, USA, 28 June–1 July 2011. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Elnagar, A.; Al-Debsi, R.; Einea, O. Arabic text classification using deep learning models. Inf. Processing Manag. 2020, 57, 102121. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Johnson, R.; Zhang, T. Deep pyramid convolutional neural networks for text categorization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Canada, 30 July–4 August 2017; Volume 1: Long Papers, pp. 562–570. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Pota, M.; Esposito, M.; De Pietro, G.; Fujita, H. Best Practices of Convolutional Neural Networks for Question Classification. Appl. Sci. 2020, 10, 4710. [Google Scholar] [CrossRef]
- Shu, Z.; Zheng, D.; Hu, X.; Ming, Y. Bidirectional Long Short-Term Memory Networks for Relation Classification. In Proceedings of the 29th Pacific Asia Conference on Language, Information and Computation, Shanghai, China, 30 October–1 November 2015. [Google Scholar]
- Xu, C.; Huang, W.; Wang, H.; Wang, G.; Liu, T.-Y. Modeling local dependence in natural language with multi-channel recurrent neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 5525–5532. [Google Scholar]
- Du, J.; Vong, C.-M.; Chen, C.P. Novel efficient RNN and LSTM-like architectures: Recurrent and gated broad learning systems and their applications for text classification. IEEE Trans. Cybern. 2020, 51, 1586–1597. [Google Scholar] [CrossRef]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 2: Short Papers, pp. 207–212. [Google Scholar]
- Zheng, W.; Liu, X.; Yin, L. Sentence Representation Method Based on Multi-Layer Semantic Network. Appl. Sci. 2021, 11, 1316. [Google Scholar] [CrossRef]
- Zheng, W.; Yin, L. Characterization inference based on joint-optimization of multi-layer semantics and deep fusion matching network. PeerJ Comput. Sci. 2022, 8, e908. [Google Scholar] [CrossRef] [PubMed]
- Zheng, W.; Zhou, Y.; Liu, S.; Tian, J.; Yang, B.; Yin, L. A deep fusion matching network semantic reasoning model. Appl. Sci. 2022, 12, 3416. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Martinčić-Ipšić, S.; Miličić, T.; Todorovski, L. The Influence of Feature Representation of Text on the Performance of Document Classification. Appl. Sci. 2019, 9, 743. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Hongbin, D. Text sentiment analysis based on feature fusion of convolution neural network and bidirectional long short-term memory network. J. Comput. Appl. 2018, 38, 3075. [Google Scholar]
- Zhang, J.; Liu, F.A.; Xu, W.; Yu, H. Feature Fusion Text Classification Model Combining CNN and BiGRU with Multi-Attention Mechanism. Future Internet 2019, 11, 237. [Google Scholar] [CrossRef] [Green Version]
- Luo, X.; Wang, X. Research on multi-feature fusion text classification model based on self-attention mechanism. J. Physics: Conf. Ser. 2020, 1693, 012071. [Google Scholar] [CrossRef]
- Xie, J.; Hou, Y.; Wang, Y.; Wang, Q.; Li, B.; Lv, S.; Vorotnitsky, Y.I. Chinese text classification based on attention mechanism and feature-enhanced fusion neural network. Computing 2020, 102, 683–700. [Google Scholar] [CrossRef]
- Jang, B.; Kim, M.; Harerimana, G.; Kang, S.; Kim, J.W. Bi-LSTM Model to Increase Accuracy in Text Classification: Combining Word2vec CNN and Attention Mechanism. Appl. Sci. 2020, 10, 5841. [Google Scholar] [CrossRef]
- Abdi, A.; Shamsuddin, S.M.; Hasan, S.; Piran, J. Deep learning-based sentiment classification of evaluative text based on Multi-feature fusion. Inf. Processing Manag. 2019, 56, 1245–1259. [Google Scholar] [CrossRef]
- Sun, M.; Li, J.; Guo, Z.; Yu, Z.; Zheng, Y.; Si, X.; Liu, Z. Thuctc: An Efficient Chinese Text Classifier. GitHub Repos. 2016. Available online: https://github.com/thunlp/THUCTC (accessed on 15 January 2022).
- Wang, C.; Zhang, M.; Ma, S.; Ru, L. Automatic online news issue construction in web environment. In Proceedings of the 17th International Conference on World Wide Web, Beijing, China, 21–25 April 2008; pp. 457–466. [Google Scholar]
- Mao, X.; Chang, S.; Shi, J.; Li, F.; Shi, R. Sentiment-Aware Word Embedding for Emotion Classification. Appl. Sci. 2019, 9, 1334. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Jiang, M.; Liang, Y.; Feng, X.; Fan, X.; Pei, Z.; Xue, Y.; Guan, R. Text classification based on deep belief network and softmax regression. Neural Comput. Appl. 2018, 29, 61–70. [Google Scholar] [CrossRef]
- Rezaeinia, S.M.; Rahmani, R.; Ghodsi, A.; Veisi, H. Sentiment analysis based on improved pre-trained word embeddings. Expert Syst. Appl. 2019, 117, 139–147. [Google Scholar] [CrossRef]
- Liu, G.; Guo, J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep learning-based text classification: A comprehensive review. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Format |
|---|
| <doc> <url>Page URL</url> <docno>Page ID</docno> <contenttitle>Page title</contenttitle> <content>Page content</content> </doc> |
| Model | Accuracy (%) | Macro-F (%) |
|---|---|---|
| TextCNN | 93.25 | 93.17 |
| BiLSTM | 93.34 | 93.36 |
| BERT | 94.58 | 94.59 |
| DPCNN | 93.56 | 93.57 |
| BiLSTM+CNN | 93.73 | 93.71 |
| BTCDC | 95.27 | 95.26 |
| Classification Result | Classification Result |
|---|---|
| Text: 意甲第36轮,国米主场4-2逆转恩波利,劳塔罗又进了2个球,其中本队第二个球扳平比分,随后第64分钟,他将比分改写为3-2,为国米拿下比赛立下汗马功劳。现在的劳塔罗状态太好了, 最近11场比赛打入了11球, 在意甲联赛中, 他打入了19球, 这是新高, 虽然排在意甲第三, 但是他罚点球少, 只有3个, 因莫比莱 (27球) 和弗拉霍维奇 (23球) 点球都多, 前面进了7个, 后面进了5个。所以运动战进球, 劳塔罗进步很大。劳塔罗的爆发对于阿根廷世界杯绝对利好, 有这样一个生猛的, 梅西世界杯之旅稳当了吧? 梅西又多了个帮手是毋庸置疑的。劳塔罗, 迪玛利亚、梅西绝对是顶配了。此外还应该有尤文的迪巴拉、佛罗伦萨前锋尼古拉斯冈萨雷斯、国际米兰的华金科雷亚、马竞的安赫尔科雷亚、塞维利亚边锋奥坎波斯、当然还有大巴黎的伊卡尔迪, 听着都是那么让人羡慕。所以本届世界杯之旅, 阿根廷的锋线绝对可以和任何一支球队比进球, 当然能拿下冠军还要看防守,不过能不能比对方多进一球, 那真要看梅西带领的锋线如何表现了? Label:体育 | Text: In the 36th round of Serie A, Inter reversed Empoli 4-2 at home, Lautaro scored two more goals, including his team’s second goal, to equalize the score, and then in the 64th minute, he made the score 3-2, which made a great contribution for Inter to take the game. Now Lautaro is in great form, scoring 11 goals in the last 11 games. In Serie A, he scored 19 goals, which is a new high, and although he ranks third in Serie A, he has fewer penalty kicks, only 3, and both Immobile (27 goals) and Vlahovec (23 goals) have more penalty kicks, scoring 7 in front and 5 behind. So sporting war goals, Lautaro progressed a lot. Lautaro’s outbreak for Argentina World Cup is definitely good, there is such a fierce, Messi World Cup trip is stable, right? There is no doubt that Messi has an additional helper. Lautaro, Di Maria, Messi is definitely the top match. There should also be Juve’s Dybala, Fiorentina striker Nicolas Gonzalez, Inter Milan’s Joaquin Correa, Atletico Madrid’s Angel Correa, Sevilla winger Ocampos, and of course, Big Paris’ Icardi, which is so enviable to hear. So this World Cup trip, Argentina’s front line can absolutely and any team than goals, of course, to take the championship depends on the defense, but can more than the other side to score a goal, it really depends on how the front line led by Lionel Messi performance? Label: Sports |
| Model | Accuracy (%) | Macro-F (%) |
|---|---|---|
| TextCNN | 92.36 | 92.32 |
| BiLSTM | 92.84 | 92.91 |
| DPCNN | 92.97 | 92.94 |
| BiLSTM+CNN | 94.29 | 94.33 |
| BERT | 94.41 | 94.42 |
| BTCDC | 96.08 | 96.09 |
| Model | THUCNews | SouHuNews |
|---|---|---|
| BTCDC | 95.27 | 96.58 |
| BTCDC-ATT | 94.12 | 93.14 |
| BTCDC-MC | 94.36 | 93.51 |
| BTCDC-B | 93.85 | 92.74 |
| BTCDC-EP | 94.68 | 93.89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, X.; Zhou, T.; He, L.; Li, Y. Research on Long Text Classification Model Based on Multi-Feature Weighted Fusion. Appl. Sci. 2022, 12, 6556. https://doi.org/10.3390/app12136556
Yue X, Zhou T, He L, Li Y. Research on Long Text Classification Model Based on Multi-Feature Weighted Fusion. Applied Sciences. 2022; 12(13):6556. https://doi.org/10.3390/app12136556
Chicago/Turabian StyleYue, Xi, Tao Zhou, Lei He, and Yuxia Li. 2022. "Research on Long Text Classification Model Based on Multi-Feature Weighted Fusion" Applied Sciences 12, no. 13: 6556. https://doi.org/10.3390/app12136556
APA StyleYue, X., Zhou, T., He, L., & Li, Y. (2022). Research on Long Text Classification Model Based on Multi-Feature Weighted Fusion. Applied Sciences, 12(13), 6556. https://doi.org/10.3390/app12136556