
Path-Following and Obstacle Avoidance Control of Nonholonomic Wheeled Mobile Robot Based on Deep Reinforcement Learning


Abstract
:1. Introduction
- The path-following control method is designed and implemented by considering the deep reinforcement learning algorithm DDPG, which reveals excellent performance regarding the efficiency and accuracy of the following control.
- A new path-following and obstacle avoidance control strategy for NWMRs is proposed based on the RL algorithm, specifically in the design of a new mechanism for the state and reward for both in the environment, which simplifies the dimensionality of the environment state, ensuring that the mobile robot can achieve the optimal solution between path selection and obstacle avoidance actions. Moreover, the minimum representative value approach for avoiding collisions is proposed to solve for multiple obstacles, along with path-following control.
2. Problem Formulations
2.1. Kinematics Model for NWMRs
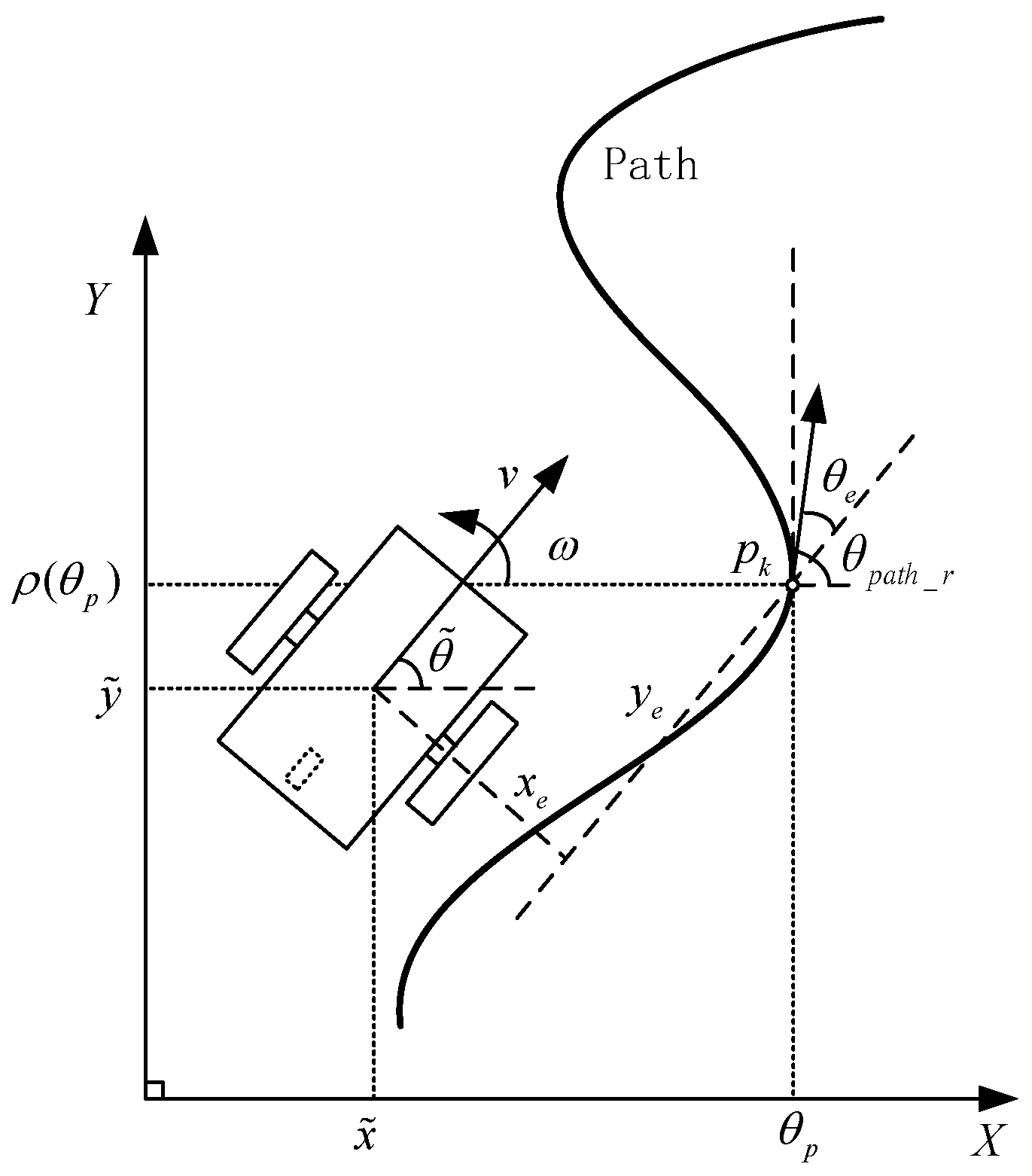
2.2. Path-Following
3. Path-Following and Obstacle Avoidance Control Strategy Incorporating Reinforcement Learning
3.1. Reinforcement Learning Control Method
3.2. Path-Following and Obstacle Avoidance Controller Based on DDPG
| Algorithm 1 Path-Following and Obstacle Avoidance Control Strategy for NWMRs |
| Require: robot random initial pose , path p, training , time step , learning rate for actor network and for critic network, parameter for stability of training, discount factor , experience replay buffer size N, the number k of obstacles, obstacle avoidance position , parameters , , , , and parameters related to obstacle avoidance , , , , ; |
| Intialize: critic network and actor network randomly, target network and ; |
| 1: for each do |
| 2: Obtain an observation of random initial pose to NWMR in environment, then output position error through path parameters, and finally obtain initial state ; |
| 3: for all do |
| 4: Initialize a random noise for the deterministic strategy; |
| 5: Randomly select an action as a control input based on the current environment strategy and exploration noise ; |
| 6: Execute u, then obtain reward and new state ; |
| 7: Put into experience replay buffer D; |
| 8: if number of > Memory then |
| 9: Extract randomly a batch of transitions from D; |
| 10: Update actor network and critic network, (9) (11); |
| 11: Update target network for stable training as: |
| 12: |
| 13: |
| 14: end if |
| 15: end for |
| 16: end for |
4. Results and Discussions
4.1. Training Setting
4.2. Comparison of Path-Following between the Proposed Method and MPC
4.3. The Performance of Path-Following with Collision Avoidance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| NWMR | Nonholonomic Wheeled Mobile Robot |
| RL | Reinforcement Learning |
| DDPG | Deep Deterministic Policy Gradient |
| DPG | Deterministic Policy Gradient |
| DQN | Deep Q-Network |
| SCDRL | Smoothly Convergent Deep Reinforcement Learning |
| MPC | Model Predictive Control |
| GVF | Guiding Vector Field |
| SMC | Sliding Mode Control |
| PID | Proportional Integral Derivative |
| MDP | Markov Decision Process |
References
- Faulwasser, T.; Kern, B.; Findeisen, R. Model predictive path-following for constrained nonlinear systems. In Proceedings of the 48h IEEE Conference on Decision and Control (CDC) Held Jointly with 2009 28th Chinese Control Conference, Shanghai, China, 15–18 December 2009; pp. 8642–8647. [Google Scholar]
- Sun, Z.; Xie, H.; Zheng, J.; Man, Z.; He, D. Path-following control of Mecanum-wheels omnidirectional mobile robots using nonsingular terminal sliding mode. Mech. Syst. Signal Process. 2021, 147, 107128. [Google Scholar] [CrossRef]
- Chen, J.; Wu, C.; Yu, G.; Narang, D.; Wang, Y. Path Following of Wheeled Mobile Robots Using Online-Optimization-Based Guidance Vector Field. IEEE/ASME Trans. Mechatron. 2021, 26, 1737–1744. [Google Scholar] [CrossRef]
- Wang, H.; Tian, Y.; Xu, H. Neural adaptive command filtered control for cooperative path following of multiple underactuated autonomous underwater vehicles along one path. IEEE Trans. Syst. Man Cybern. Syst. 2021, 52, 2966–2978. [Google Scholar] [CrossRef]
- Liang, X.; Qu, X.; Hou, Y.; Li, Y.; Zhang, R. Finite-time unknown observer based coordinated path-following control of unmanned underwater vehicles. J. Frankl. Inst. 2021, 358, 2703–2721. [Google Scholar] [CrossRef]
- Rubí, B.; Morcego, B.; Pérez, R. Deep reinforcement learning for quadrotor path following with adaptive velocity. Auton. Robot. 2021, 45, 119–134. [Google Scholar] [CrossRef]
- Eskandarpour, A.; Sharf, I. A constrained error-based MPC for path following of quadrotor with stability analysis. Nonlinear Dyn. 2020, 99, 899–918. [Google Scholar] [CrossRef]
- Kapitanyuk, Y.A.; Proskurnikov, A.V.; Cao, M. A guiding vector-field algorithm for path-following control of nonholonomic mobile robots. IEEE Trans. Control. Syst. Technol. 2017, 26, 1372–1385. [Google Scholar] [CrossRef] [Green Version]
- Napolitano, O.; Fontanelli, D.; Pallottino, L.; Salaris, P. Information-Aware Lyapunov-Based MPC in a Feedback-Feedforward Control Strategy for Autonomous Robots. IEEE Robot. Autom. Lett. 2022, 7, 4765–4772. [Google Scholar] [CrossRef]
- Subari, M.A.; Hudha, K.; Kadir, Z.A.; Dardin, S.M.F.S.M.; Amer, N.H. Path following control of tracked vehicle using modified sup controller optimized with particle swarm optimization (PSO). Int. J. Dyn. Control. 2022, 1–10. [Google Scholar] [CrossRef]
- Rukmana, M.A.F.; Widyotriatmo, A.; Siregar, P.I. Anti-Jackknife Autonomous Truck Trailer for Path Following Control Using Genetic Algorithm. In Proceedings of the 2021 International Conference on Instrumentation, Control, and Automation (ICA), Bandung, Indonesia, 25–27 August 2021; pp. 186–191. [Google Scholar]
- Nguyen, A.T.; Sentouh, C.; Zhang, H.; Popieul, J.C. Fuzzy static output feedback control for path following of autonomous vehicles with transient performance improvements. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3069–3079. [Google Scholar] [CrossRef]
- Martinsen, A.B.; Lekkas, A.M. Curved path following with deep reinforcement learning: Results from three vessel models. In Proceedings of the OCEANS 2018 MTS/IEEE Charleston, Charleston, SC, USA, 22–25 October 2018; pp. 1–8. [Google Scholar]
- Szepesvári, C. Algorithms for reinforcement learning. Synth. Lect. Artif. Intell. Mach. Learn. 2010, 4, 1–103. [Google Scholar]
- Duan, K.; Fong, S.; Chen, C.P. Reinforcement learning based model-free optimized trajectory tracking strategy design for an AUV. Neurocomputing 2022, 469, 289–297. [Google Scholar] [CrossRef]
- Cao, S.; Sun, L.; Jiang, J.; Zuo, Z. Reinforcement Learning-Based Fixed-Time Trajectory Tracking Control for Uncertain Robotic Manipulators with Input Saturation. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]
- Okafor, E.; Udekwe, D.; Ibrahim, Y.; Bashir Mu’azu, M.; Okafor, E.G. Heuristic and deep reinforcement learning-based PID control of trajectory tracking in a ball-and-plate system. J. Inf. Telecommun. 2021, 5, 179–196. [Google Scholar] [CrossRef]
- Wang, S.; Yin, X.; Li, P.; Zhang, M.; Wang, X. Trajectory tracking control for mobile robots using reinforcement learning and PID. Iran. J. Sci. Technol. Trans. Electr. Eng. 2020, 44, 1059–1068. [Google Scholar] [CrossRef]
- Woo, J.; Yu, C.; Kim, N. Deep reinforcement learning-based controller for path following of an unmanned surface vehicle. Ocean. Eng. 2019, 183, 155–166. [Google Scholar] [CrossRef]
- Nie, C.; Zheng, Z.; Zhu, M. Three-dimensional path-following control of a robotic airship with reinforcement learning. Int. J. Aerosp. Eng. 2019, 2019, 7854173. [Google Scholar] [CrossRef]
- Liu, M.; Zhao, F.; Yin, J.; Niu, J.; Liu, Y. Reinforcement-Tracking: An Effective Trajectory Tracking and Navigation Method for Autonomous Urban Driving. IEEE Trans. Intell. Transp. Syst. 2021. [Google Scholar] [CrossRef]
- Zhao, Y.; Qi, X.; Ma, Y.; Li, Z.; Malekian, R.; Sotelo, M.A. Path following optimization for an underactuated USV using smoothly-convergent deep reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2020, 22, 6208–6220. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, J.; He, H.; Sun, C. Deterministic policy gradient with integral compensator for robust quadrotor control. IEEE Trans. Syst. Man Cybern. Syst. 2019, 50, 3713–3725. [Google Scholar] [CrossRef]
- Zhu, W.; Guo, X.; Fang, Y.; Zhang, X. A path-integral-based reinforcement learning algorithm for path following of an autoassembly mobile robot. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 4487–4499. [Google Scholar] [CrossRef]
- Chen, L.; Chen, Y.; Yao, X.; Shan, Y.; Chen, L. An adaptive path tracking controller based on reinforcement learning with urban driving application. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2411–2416. [Google Scholar]
- Lapierre, L.; Zapata, R.; Lepinay, P. Combined path-following and obstacle avoidance control of a wheeled robot. Int. J. Robot. Res. 2007, 26, 361–375. [Google Scholar] [CrossRef]
- Meyer, E.; Robinson, H.; Rasheed, A.; San, O. Taming an autonomous surface vehicle for path following and collision avoidance using deep reinforcement learning. IEEE Access 2020, 8, 41466–41481. [Google Scholar] [CrossRef]
- Rubí, B.; Morcego, B.; Pérez, R. Quadrotor Path Following and Reactive Obstacle Avoidance with Deep Reinforcement Learning. J. Intell. Robot. Syst. 2021, 103, 1–17. [Google Scholar] [CrossRef]
- Kanayama, Y.; Kimura, Y.; Miyazaki, F.; Noguchi, T. A stable tracking control method for an autonomous mobile robot. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Cincinnati, OH, USA, 13–18 May 1990; pp. 384–389. [Google Scholar]
- Faulwasser, T.; Findeisen, R. Nonlinear model predictive control for constrained output path following. IEEE Trans. Autom. Control. 2015, 61, 1026–1039. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International Conference on Machine Learning, PMLR, Bejing, China, 22–24 June 2014; pp. 387–395. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Zhang, J.J.; Fang, Z.L.; Zhang, Z.Q.; Gao, R.Z.; Zhang, S.B. Trajectory Tracking Control of Nonholonomic Wheeled Mobile Robots Using Model Predictive Control Subjected to Lyapunov-based Input Constraints. Int. J. Control. Autom. Syst. 2022, 20, 1640–1651. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Actor/Target Actor | Critic/Target Critic | Activation Function |
|---|---|---|---|
| Input layer | 5 | 5 | ReLU |
| 1st hidden layer | 400 | 400 | ReLU |
| 2nd hidden layer | 300 | 300 | ReLU |
| 3rd hidden layer | 300 | 300 | ReLU |
| Output layer | 2 | 1 | Tanh |
| Stage | MSE for Longitudinal Errors | MSE for Cross Errors |
|---|---|---|
| Stage 1 (proposed) | 16.5702 | 2.111 |
| Stage 2 (proposed) | 0.6008 | 0.3512 |
| Stage 3 (proposed) | 0.0005 | 0.0705 |
| Stage 4 (proposed) | 0.0069 | 0.0031 |
| MPC | 1.5378 | 0.1930 |
| Stage | MSE for Longitudinal Errors | MSE for Cross Errors |
|---|---|---|
| Stage 1 | 34.0757 | 37.7735 |
| Stage 2 | 54.4655 | 16.6814 |
| Stage 3 | 0.0647 | 2.1392 |
| Stage 4 | 0.0127 | 1.5788 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, X.; Zhang, S.; Cheng, S.; Xia, Q.; Zhang, J. Path-Following and Obstacle Avoidance Control of Nonholonomic Wheeled Mobile Robot Based on Deep Reinforcement Learning. Appl. Sci. 2022, 12, 6874. https://doi.org/10.3390/app12146874
Cheng X, Zhang S, Cheng S, Xia Q, Zhang J. Path-Following and Obstacle Avoidance Control of Nonholonomic Wheeled Mobile Robot Based on Deep Reinforcement Learning. Applied Sciences. 2022; 12(14):6874. https://doi.org/10.3390/app12146874
Chicago/Turabian StyleCheng, Xiuquan, Shaobo Zhang, Sizhu Cheng, Qinxiang Xia, and Junhao Zhang. 2022. "Path-Following and Obstacle Avoidance Control of Nonholonomic Wheeled Mobile Robot Based on Deep Reinforcement Learning" Applied Sciences 12, no. 14: 6874. https://doi.org/10.3390/app12146874
APA StyleCheng, X., Zhang, S., Cheng, S., Xia, Q., & Zhang, J. (2022). Path-Following and Obstacle Avoidance Control of Nonholonomic Wheeled Mobile Robot Based on Deep Reinforcement Learning. Applied Sciences, 12(14), 6874. https://doi.org/10.3390/app12146874