
Efficiently Detecting Non-Stationary Opponents: A Bayesian Policy Reuse Approach under Partial Observability

Abstract
:1. Introduction
2. Preliminaries
2.1. Reinforcement Learning
2.2. Bayesian Policy Reuse
2.3. Variational Autoencoders
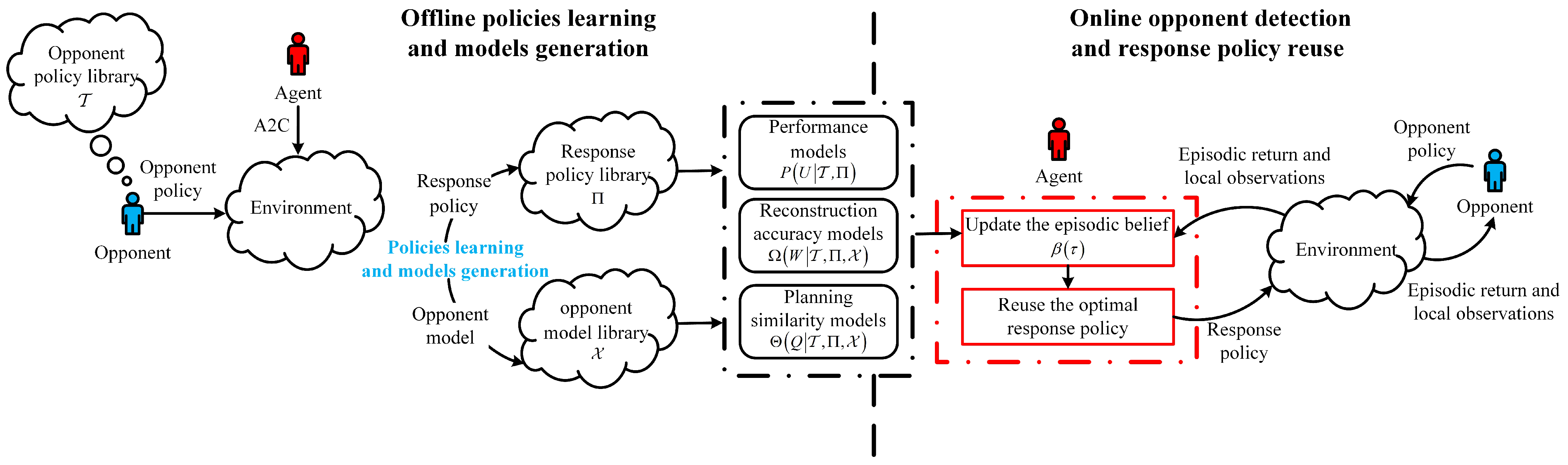
3. Bayes-Lab
3.1. Offline Policy Learning and Model Generation
| Algorithm 1 Offline models’ generation |
|
3.2. Online Opponent Detection and Policy Reuse
| Algorithm 2 Online opponent detection and policy reuse |
|
4. Experiments and Results
4.1. Experimental Setup
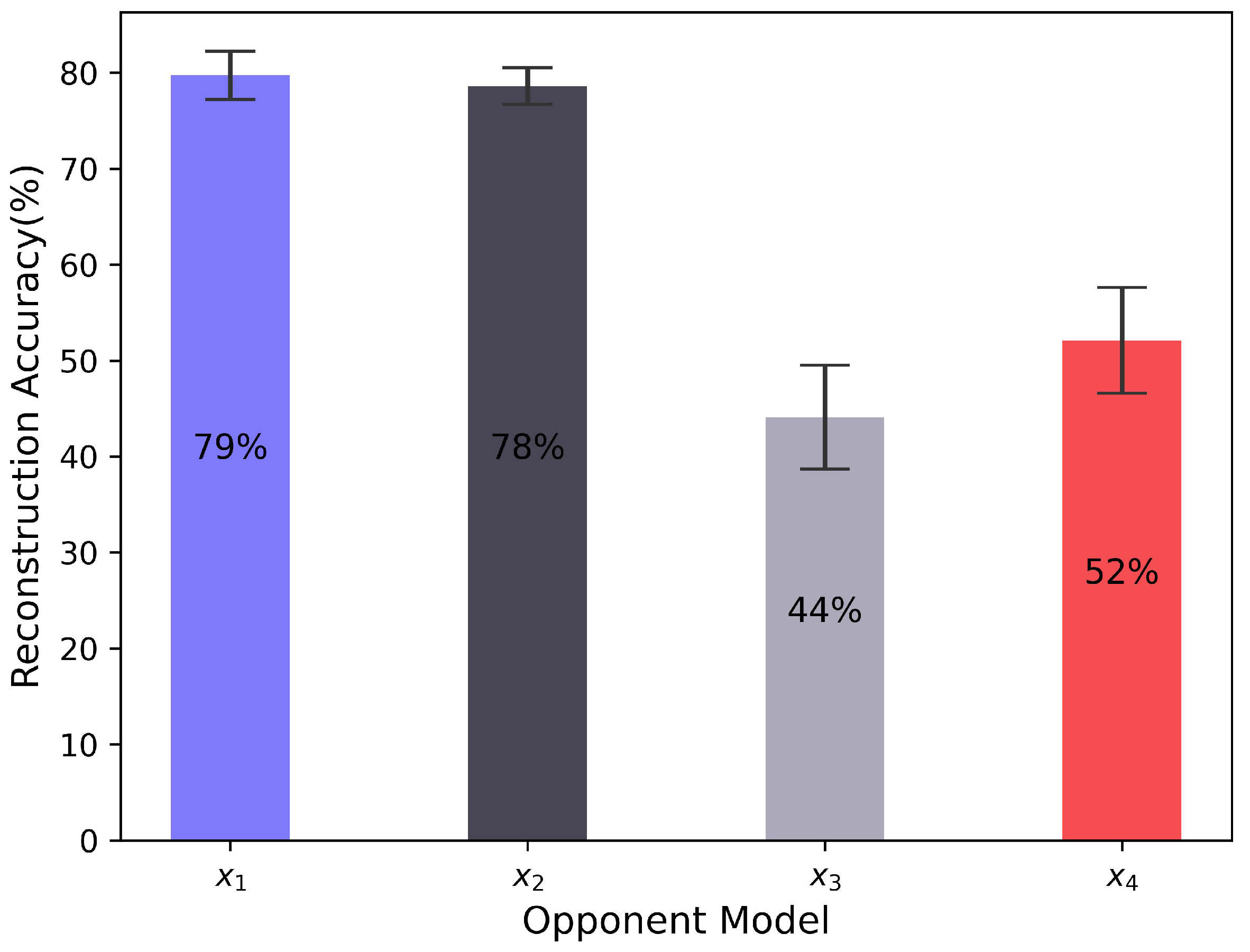
4.2. Results in the Offline Stage
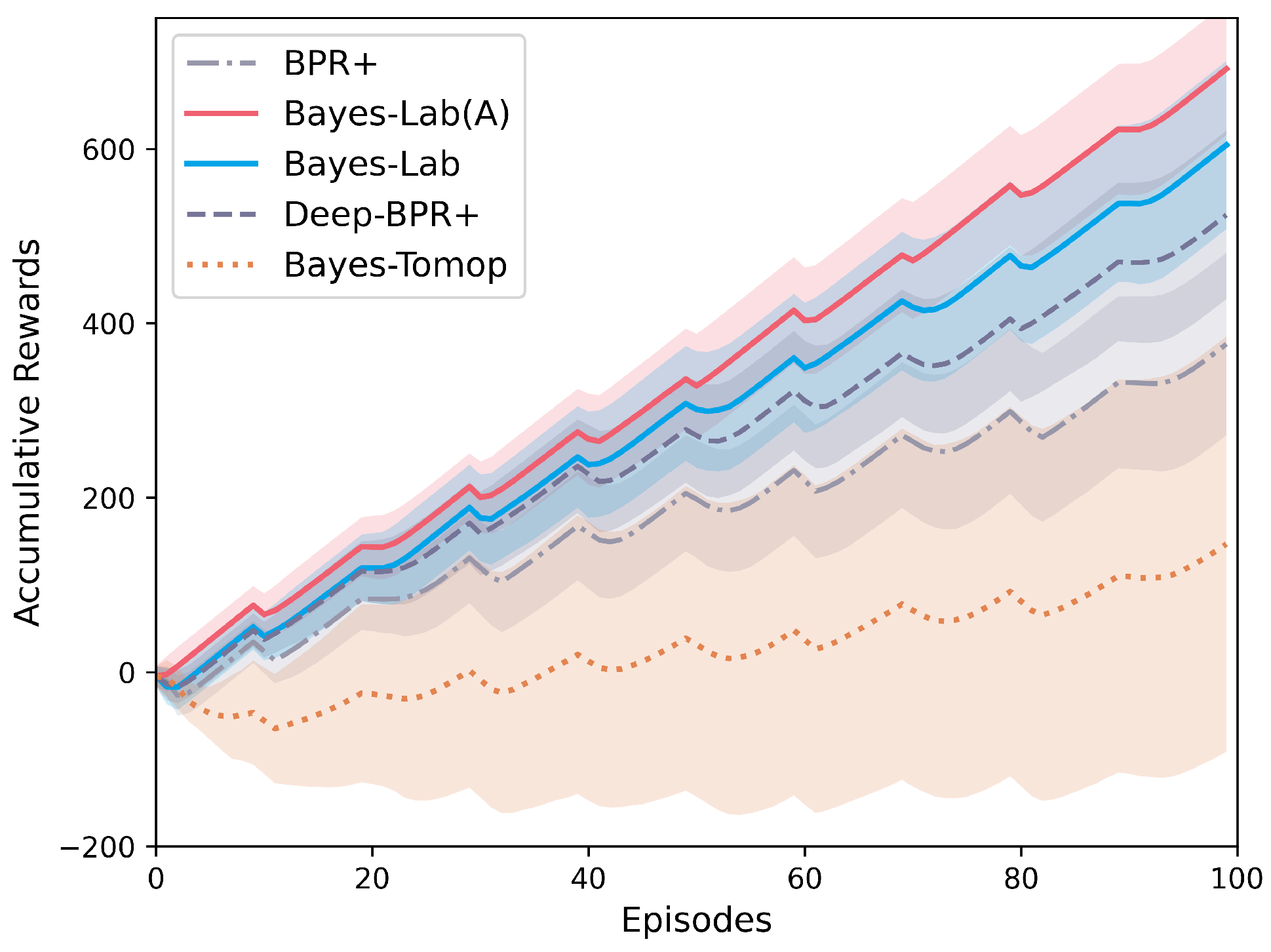
4.3. Results in Online Stage
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Kwon, H.; Lee, S. Ensemble transfer attack targeting text classification systems. Comput. Secur. 2022, 117, 102695. [Google Scholar] [CrossRef]
- Kwon, H.; Lee, S. Textual Adversarial Training of Machine Learning Model for Resistance to Adversarial Examples. Secur. Commun. Netw. 2022, 2022, 4511510. [Google Scholar] [CrossRef]
- Kwon, H.; Kim, Y. BlindNet backdoor: Attack on deep neural network using blind watermark. Multimed. Tools Appl. 2022, 81, 6217–6234. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3389–3396. [Google Scholar]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 31–36. [Google Scholar]
- Zhang, F.; Leitner, J.; Milford, M.; Upcroft, B.; Corke, P. Towards vision-based deep reinforcement learning for robotic motion control. arXiv 2015, arXiv:1511.03791. [Google Scholar]
- Barzegar, A.; Lee, D.J. Deep Reinforcement Learning-Based Adaptive Controller for Trajectory Tracking and Altitude Control of an Aerial Robot. Appl. Sci. 2022, 12, 4764. [Google Scholar] [CrossRef]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. Deep reinforcement learning framework for autonomous driving. Electron. Imaging 2017, 2017, 70–76. [Google Scholar] [CrossRef] [Green Version]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Chang, C.C.; Tsai, J.; Lin, J.H.; Ooi, Y.M. Autonomous Driving Control Using the DDPG and RDPG Algorithms. Appl. Sci. 2021, 11, 10659. [Google Scholar] [CrossRef]
- Zhao, W.; Meng, Z.; Wang, K.; Zhang, J.; Lu, S. Hierarchical Active Tracking Control for UAVs via Deep Reinforcement Learning. Appl. Sci. 2021, 11, 10595. [Google Scholar] [CrossRef]
- Wooldridge, M. An Introduction to Multiagent Systems; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep reinforcement learning for multiagent systems: A review of challenges, solutions, and applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [Green Version]
- Conitzer, V.; Sandholm, T. AWESOME: A general multiagent learning algorithm that converges in self-play and learns a best response against stationary opponents. Mach. Learn. 2007, 67, 23–43. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Liu, Q.; Huang, J.; Fu, K. Efficiently tracking multi-strategic opponents: A context-aware Bayesian policy reuse approach. Appl. Soft Comput. 2022, 121, 108715. [Google Scholar] [CrossRef]
- Chen, H.; Liu, Q.; Fu, K.; Huang, J.; Wang, C.; Gong, J. Accurate policy detection and efficient knowledge reuse against multi-strategic opponents. Knowl.-Based Syst. 2022, 242, 108404. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Hernandez-Leal, P.; Kaisers, M. Towards a fast detection of opponents in repeated stochastic games. In International Conference on Autonomous Agents and Multiagent Systems; Springer: Berlin/Heidelberg, Germany, 2017; pp. 239–257. [Google Scholar]
- Hernandez-Leal, P.; Kaisers, M.; Baarslag, T.; de Cote, E.M. A survey of learning in multiagent environments: Dealing with non-stationarity. arXiv 2017, arXiv:1707.09183. [Google Scholar]
- Rabinowitz, N.; Perbet, F.; Song, F.; Zhang, C.; Eslami, S.A.; Botvinick, M. Machine theory of mind. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4218–4227. [Google Scholar]
- Papoudakis, G.; Christianos, F.; Rahman, A.; Albrecht, S.V. Dealing with non-stationarity in multi-agent deep reinforcement learning. arXiv 2019, arXiv:1906.04737. [Google Scholar]
- He, H.; Boyd-Graber, J.; Kwok, K.; Daumé, H., III. Opponent modeling in deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1804–1813. [Google Scholar]
- Albrecht, S.V.; Stone, P. Autonomous agents modelling other agents: A comprehensive survey and open problems. Artif. Intell. 2018, 258, 66–95. [Google Scholar] [CrossRef] [Green Version]
- Grover, A.; Al-Shedivat, M.; Gupta, J.; Burda, Y.; Edwards, H. Learning policy representations in multiagent systems. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1802–1811. [Google Scholar]
- Tacchetti, A.; Song, H.F.; Mediano, P.A.; Zambaldi, V.; Rabinowitz, N.C.; Graepel, T.; Botvinick, M.; Battaglia, P.W. Relational forward models for multi-agent learning. arXiv 2018, arXiv:1809.11044. [Google Scholar]
- Hernandez-Leal, P.; Kartal, B.; Taylor, M.E. A survey and critique of multiagent deep reinforcement learning. Auton. Agents Multi-Agent Syst. 2019, 33, 750–797. [Google Scholar] [CrossRef] [Green Version]
- Raileanu, R.; Denton, E.; Szlam, A.; Fergus, R. Modeling others using oneself in multi-agent reinforcement learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4257–4266. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Hong, Z.W.; Su, S.Y.; Shann, T.Y.; Chang, Y.H.; Lee, C.Y. A deep policy inference q-network for multi-agent systems. arXiv 2017, arXiv:1712.07893. [Google Scholar]
- Papoudakis, G.; Christianos, F.; Albrecht, S. Agent Modelling under Partial Observability for Deep Reinforcement Learning. Adv. Neural Inf. Process. Syst. 2021, 34, 19210–19222. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Rosman, B.; Hawasly, M.; Ramamoorthy, S. Bayesian policy reuse. Mach. Learn. 2016, 104, 99–127. [Google Scholar] [CrossRef] [Green Version]
- Hernandez-Leal, P.; Taylor, M.E.; Rosman, B.; Sucar, L.E.; De Cote, E.M. Identifying and tracking switching, non-stationary opponents: A Bayesian approach. In Proceedings of the Workshops at the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–13 February 2016. [Google Scholar]
- Harsanyi, J.C. Games with incomplete information played by “Bayesian” players, I–III Part I. The basic model. Manag. Sci. 1967, 14, 159–182. [Google Scholar] [CrossRef]
- Crandall, J.W. Just add Pepper: Extending learning algorithms for repeated matrix games to repeated markov games. In Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems, Valencia, Spain, 4–8 June 2012; Volume 1, pp. 399–406. [Google Scholar]
- Zheng, Y.; Meng, Z.; Hao, J.; Zhang, Z.; Yang, T.; Fan, C. A deep bayesian policy reuse approach against non-stationary agents. Adv. Neural Inf. Process. Syst. 2018, 31, 962–972. [Google Scholar]
- Yang, T.; Meng, Z.; Hao, J.; Zhang, C.; Zheng, Y.; Zheng, Z. Towards efficient detection and optimal response against sophisticated opponents. arXiv 2018, arXiv:1809.04240. [Google Scholar]
- Papoudakis, G.; Christianos, F.; Albrecht, S.V. Local Information Opponent Modelling Using Variational Autoencoders. arXiv 2020, arXiv:2006.09447. [Google Scholar]
- Bellman, R. A Markovian decision process. J. Math. Mech. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Zacharaki, A.; Kostavelis, I.; Dokas, I. Decision Making with STPA through Markov Decision Process, a Theoretic Framework for Safe Human-Robot Collaboration. Appl. Sci. 2021, 11, 5212. [Google Scholar] [CrossRef]
- Doersch, C. Tutorial on variational autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Yan, X.; Yang, J.; Sohn, K.; Lee, H. Attribute2image: Conditional image generation from visual attributes. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2016; pp. 776–791. [Google Scholar]
- Ha, D.; Schmidhuber, J. Recurrent world models facilitate policy evolution. In Proceedings of the Advances in Neural Information Processing Systems 31, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Igl, M.; Zintgraf, L.; Le, T.A.; Wood, F.; Whiteson, S. Deep variational reinforcement learning for POMDPs. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2117–2126. [Google Scholar]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. Beta-vae: Learning basic visual concepts with a constrained variational framework. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Gretton, A.; Borgwardt, K.; Rasch, M.; Schölkopf, B.; Smola, A. A kernel method for the two-sample-problem. arXiv 2006, arXiv:0805.2368. [Google Scholar]
- Zhao, S.; Song, J.; Ermon, S. Infovae: Information maximizing variational autoencoders. arXiv 2017, arXiv:1706.02262. [Google Scholar]
- Stone, P.; Veloso, M. Multiagent systems: A survey from a machine learning perspective. Auton. Robot. 2000, 8, 345–383. [Google Scholar] [CrossRef]
- Böhmer, W.; Kurin, V.; Whiteson, S. Deep coordination graphs. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 980–991. [Google Scholar]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Abbeel, O.P.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. arXiv 2017, arXiv:1706.0227530. [Google Scholar]
- Son, K.; Kim, D.; Kang, W.J.; Hostallero, D.E.; Yi, Y. Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 5887–5896. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Switch Cycle 4 | Switch Cycle 8 | Switch Cycle 10 | Switch Cycle 12 |
|---|---|---|---|---|
| BPR+ | −103.9 ± 73.6 | 190.9 ± 112.3 | 376.1 ± 104.5 | 563.4 ± 106.0 |
| Deep-BPR+ | −33.4 ± 89.4 | 326.5 ± 88.8 | 524.2 ± 96.8 | 728.8 ± 93.1 |
| Bayes-Tomop | −171.6 ± 108.1 | −16.1 ± 216.9 | 146.8 ± 237.9 | 302.7 ± 262.6 |
| Bayes-Lab | 23.9 ± 81.0 | 422.3 ± 82.5 | 604.3 ± 96.4 | 793.1 ± 90.5 |
| Bayes-Lab (A) | 131.8 ± 58.2 | 494.1 ± 74.8 | 691.6 ± 75.9 | 875.7 ± 74.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Fu, K.; Chen, H.; Liu, Q.; Huang, J.; Zhang, Z. Efficiently Detecting Non-Stationary Opponents: A Bayesian Policy Reuse Approach under Partial Observability. Appl. Sci. 2022, 12, 6953. https://doi.org/10.3390/app12146953
Wang Y, Fu K, Chen H, Liu Q, Huang J, Zhang Z. Efficiently Detecting Non-Stationary Opponents: A Bayesian Policy Reuse Approach under Partial Observability. Applied Sciences. 2022; 12(14):6953. https://doi.org/10.3390/app12146953
Chicago/Turabian StyleWang, Yu, Ke Fu, Hao Chen, Quan Liu, Jian Huang, and Zhongjie Zhang. 2022. "Efficiently Detecting Non-Stationary Opponents: A Bayesian Policy Reuse Approach under Partial Observability" Applied Sciences 12, no. 14: 6953. https://doi.org/10.3390/app12146953