
Recurrent Neural Network-Based Multimodal Deep Learning for Estimating Missing Values in Healthcare


Abstract
:1. Introduction
- It is possible to determine the direction of data integration in an environment where the types of wearable devices are diversifying and contribute to enabling continuous service to users.
- This is a method for dealing with the data duplication that occurs in a heterogeneous healthcare environment.
- Previous studies on the imputation of missing values were conducted on one device or one data set in healthcare.
- The proposed method is more suitable for healthcare environments by the imputation of missing values in a structure where different devices complement each other.
- The proposed method can flexibly integrate the data collected in the perfume healthcare environment.
2. Related Work
2.1. Research Trends of Soft Computing
2.2. Data Characteristics in Heterogeneous Healthcare Platfrom
3. Recurrent Neural Network-Based Multimodal Deep Learning for Estimating Missing Values in Healthcare
3.1. Selection of a Representative Value for Data Duplication Processing
| Algorithm 1. Selection of representative values |
| Input dk,c // unique value of the variable c collected on device k Vc // eigenvalues of the variable c dkmatrix[c] // variable c data matrix of device k Vcmatrix // data matrix of variable c Output (i) Uamatrix// data matrix of user a Step 1. Device scan of variables for k = 1 to num_decvice do for c = 1 to num_variable do if Vc == dk,c then Vcmatrix <- dkmatrix[c] // Store the variable c matrix of the device k in the data matrix of the variable c Step 2. Selection of a data matrix for variable c for c = 1 to num_variable do find representative value from Vcmatrix[t] save data matrix return |
3.2. Recurrent Neural Network Learning by Variables Using GRU Cells
3.3. Estimation of Missing Value Using Multimodal Deep Learning
4. Results and Performance Evaluation
4.1. Performance of Time Series Prediction
4.2. Performance by Estimation of Missing Values
4.3. Performance by Sparse Coding
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zadeh, L.A. Fuzzy logic, neural networks, and soft computing. In Fuzzy Sets, Fuzzy Logic, and Fuzzy Systems: Selected Papers by Lotfi A Zadeh; Word Scientific: Singapore, 1996; pp. 775–782. [Google Scholar]
- Mitra, S.; Pal, S.K.; Mitra, P. Data mining in soft computing framework: A survey. IEEE Trans. Neural Netw. 2002, 13, 3–14. [Google Scholar] [CrossRef] [Green Version]
- Yoo, H.; Chung, K. PHR based diabetes index service model using life behavior analysis. Wirel. Pers. Commun. 2017, 93, 161–174. [Google Scholar] [CrossRef]
- Kim, J.C. Collaborative Layer Based Hybrid Multi-Modal Deep Learning for Improving Prediction Accuracy. Ph.D. Thesis, Department of Computer Science, Kyonggi University, Suwon-si, Korea, 2020. [Google Scholar]
- Das, T.K.; Mohapatro, A. A System for Diagnosing Hepatitis Based on Hybrid Soft Computing Techniques. Indian J. Public Health Res. Dev. 2018, 9, 235–239. [Google Scholar] [CrossRef]
- Bernal, E.A.; Yang, X.; Li, Q.; Kumar, J.; Madhvanath, S.; Ramesh, P.; Bala, R. Deep Temporal Multimodal Fusion for Medical Procedure Monitoring Using Wearable Sensors. IEEE Trans. Multimed. 2018, 20, 107–118. [Google Scholar] [CrossRef]
- Radu, V.; Tong, C.; Bhattacharya, S.; Lane, N.D.; Mascolo, C.; Marina, M.K.; Kawsar, F. Multimodal deep learning for activity and context recognition. In ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies; Association for Computing Machinery: New York, NY, USA, 2018; Volume 1, p. 157. [Google Scholar]
- Kim, J.H.; Ahn, S.H.; Soh, J.Y.; Chung, K.Y. U-health platform for health management service based on home health gateway. In IT Convergence and Security 2012; Springer: Dordrecht, The Netherlands, 2013; pp. 351–356. [Google Scholar]
- Greco, S.; Kadziński, M.; SŁowiński, R. Selection of a representative value function in robust multiple criteria sorting. Comput. Oper. Res. 2011, 38, 1620–1637. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Zhong, Y.; Zhu, Z.; Ong, Y.S. Soft computing in remote sensing image processing. Soft Comput. 2016, 20, 4629–4630. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Tao, C.; Wang, P. A review of soft computing based on deep learning. In Proceedings of the International Conference on Industrial Informatics-Computing Technology, Intelligent Technology, Industrial Information Integration (ICIICII), Wuhan, China, 3–4 December 2016; pp. 136–144. [Google Scholar]
- Erturk, E.; Sezer, E.A. A comparison of some soft computing methods for software fault prediction. Expert Syst. Appl. 2015, 42, 1872–1879. [Google Scholar] [CrossRef]
- Moretti, F.; Pizzuti, S.; Panzieri, S.; Annunziato, M. Urban traffic flow forecasting through statistical and neural network bagging ensemble hybrid modeling. Neurocomputing 2015, 167, 3–7. [Google Scholar] [CrossRef]
- Yoo, H.; Park, R.C.; Chung, K. IoT-Based Health Big-Data Process Technologies: A Survey. KSII Trans. Internet Inf. Syst. 2021, 15, 974–992. [Google Scholar]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef]
- Kang, J.S.; Baek, J.W.; Chung, K. PrefixSpan Based Pattern Mining using Time Sliding Weight from Streaming Data. IEEE Access 2020, 8, 124833–124844. [Google Scholar] [CrossRef]
- Xi, R.; Li, M.; Hou, M.; Fu, M.; Qu, H.; Liu, D.; Haruna, C.R. Deep Dilation on Multimodality Time Series for Human Activity Recognition. IEEE Access 2018, 6, 53381–53396. [Google Scholar] [CrossRef]
- Feldman, R.; Sanger, J. The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Schmidt, P.; Reiss, A.; Duerichen, R.; Marberger, C.; Van Laerhoven, K. Introducing WESAD, a Multimodal Dataset for Wearable Stress and Affect Detection. In Proceedings of the International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 400–408. [Google Scholar]
- Banos, O.; Villalonga, C.; Garcia, R.; Saez, A.; Damas, M.; Holgado-Terriza, J.A.; Rojas, I. Design, implementation and validation of a novel open framework for agile development of mobile health applications. Biomed. Eng. Online 2015, 14, S6. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Rodriguez, J.C.; Beheshti, M. Diabetes data analysis and prediction model discovery using rapidminer. In Proceedings of the International Conference on Future Generation Communication and Networking, Sanya, China, 13–15 December 2008; pp. 96–99. [Google Scholar]
- Fanaee-T, H.; Gama, J. Event labeling combining ensemble detectors and background knowledge. Prog. Artif. Intell. 2014, 2, 113–127. [Google Scholar] [CrossRef] [Green Version]
- Karami, A.; Gangopadhyay, A.; Zhou, B.; Kharrazi, H. Fuzzy approach topic discovery in health and medical corpora. Int. J. Fuzzy Syst. 2018, 20, 1334–1345. [Google Scholar] [CrossRef]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černocký, J.; Khudanpur, S. Recurrent neural network based language model. Int. Speech Commun. Assoc. 2018, 2, 1045–1048. [Google Scholar]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. arXiv 2014, arXiv:1402.1128. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Hassanalieragh, M.; Page, A.; Soyata, T.; Sharma, G.; Aktas, M.; Mateos, G.; Andreescu, S. Health monitoring and management using Internet-of-Things (IoT) sensing with cloud-based processing: Opportunities and challenges. In Proceedings of the 2015 IEEE International Conference on Services Computing, New York City, NY, USA, 27 June–2 July 2015; pp. 285–292. [Google Scholar]
- Batista, G.E.; Monard, M.C. An analysis of four missing data treatment methods for supervised learning. Appl. Artif. Intell. 2003, 17, 519–533. [Google Scholar] [CrossRef]
- Lika, B.; Kolomvatsos, K.; Hadjiefthymiades, S. Facing the cold start problem in recommender systems. Expert Syst. Appl. 2014, 41, 2065–2073. [Google Scholar] [CrossRef]
- Zhu, X.; Zhang, S.; Jin, Z.; Zhang, Z.; Xu, Z. Missing value estimation for mixed-attribute data sets. IEEE Trans. Knowl. Data Eng. 2011, 23, 110–121. [Google Scholar] [CrossRef]
- Teoh, E.J.; Tan, K.C.; Xiang, C. Estimating the number of hidden neurons in a feedforward network using the singular value decomposition. IEEE Trans. Neural Netw. 2006, 17, 1623–1629. [Google Scholar] [CrossRef]
- Lane, N.D.; Bhattacharya, S.; Georgiev, P.; Forlivesi, C.; Jiao, L.; Qendro, L.; Kawsar, F. Deepx: A software accelerator for low-power deep learning inference on mobile devices. In Proceedings of the 15th International Conference on Information Processing in Sensor Networks, Vienna, Austria, 11–14 April 2016; p. 23. [Google Scholar]
- Baek, J.W.; Chung, K. Context Deep Neural Network Model for Predicting Depression Risk Using Multiple Regression. IEEE Access 2020, 8, 18171–18181. [Google Scholar] [CrossRef]
- Shin, D.H.; Park Roy, C.; Chung, K. Decision Boundary-Based Anomaly Detection Model Using Improved AnoGAN from ECG Data. IEEE Access 2020, 8, 108664–108674. [Google Scholar] [CrossRef]
- Shin, D.H.; Chung, K.; Park Roy, C. Prediction of Traffic Congestion Based on LSTM through Correction of Missing Temporal and Spatial Data. IEEE Access 2020, 8, 150784–150796. [Google Scholar] [CrossRef]
- Kim, J.C.; Chung, K. Discovery of Knowledge of Associative Relations using Opinion Mining Based on a Health Platform. Pers. Ubiquitous Comput. 2020, 24, 583–593. [Google Scholar] [CrossRef]
- Choi, S.Y.; Chung, K. Knowledge Process of Health Big Data using MapReduce-based Associative Mining. Pers. Ubiquitous Comput. 2020, 24, 571–581. [Google Scholar] [CrossRef]
- Kim, J.C.; Chung, K. Neural-Network based Adaptive Context Prediction Model for Ambient Intelligence. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 1451–1458. [Google Scholar] [CrossRef]
- Chung, K.; Jung, H. Knowledge-based Dynamic Cluster Model for Healthcare Management using a Convolutional Neural Network. Inf. Technol. Manag. 2020, 21, 41–50. [Google Scholar] [CrossRef]
- Yoo, H.; Chung, K. Deep Learning-based Evolutionary Recommendation Model for Heterogeneous Big Data Integration. KSII Trans. Internet Inf. Syst. 2020, 14, 3730–3744. [Google Scholar]
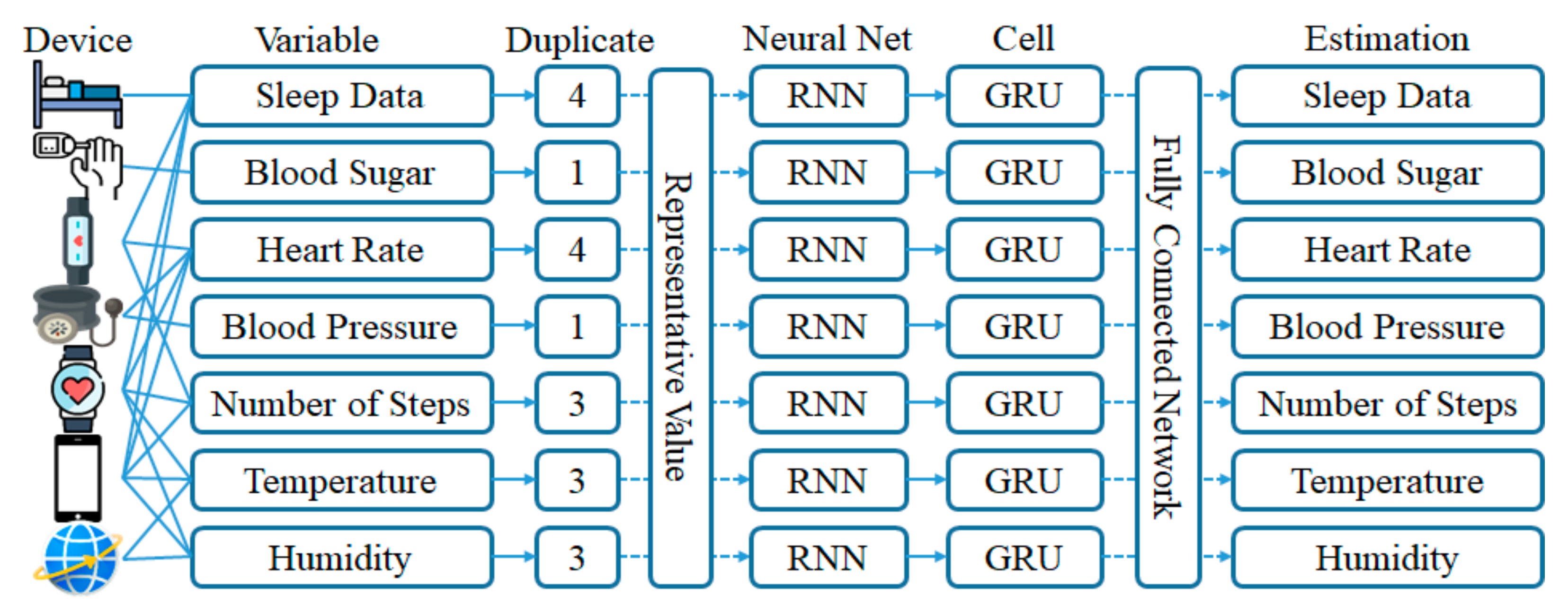


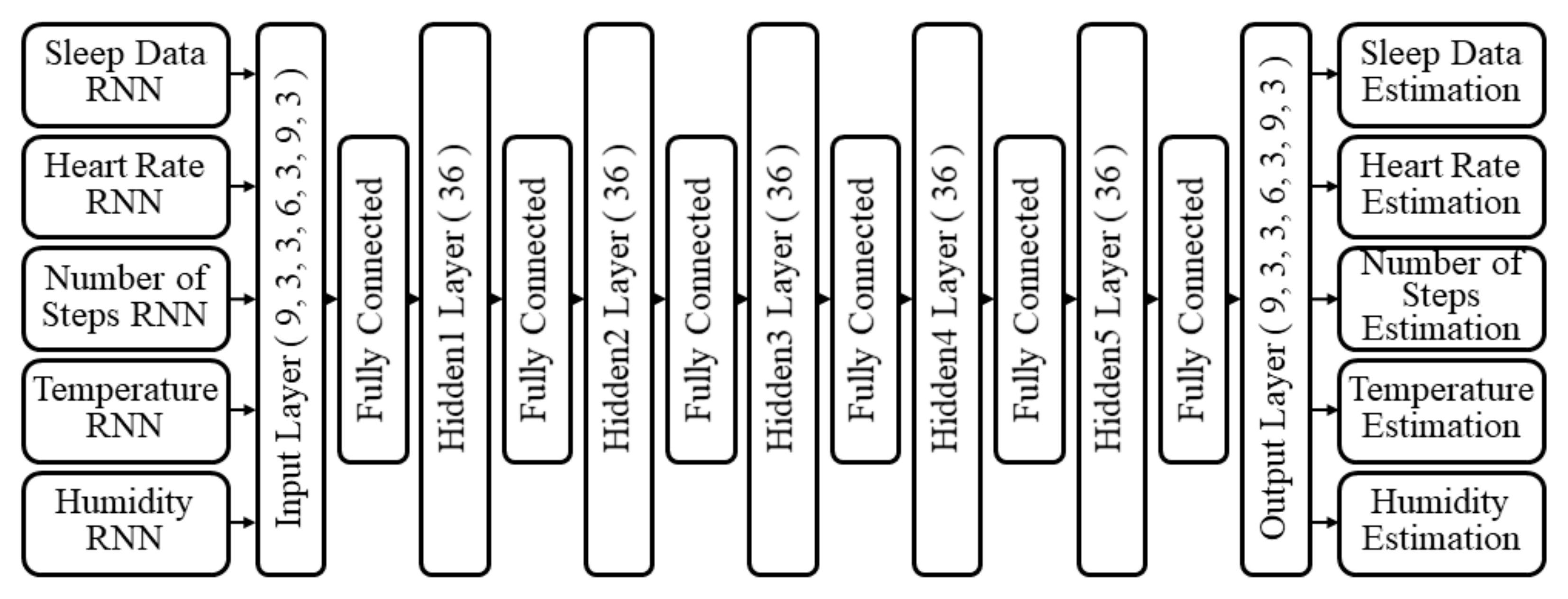

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Consist of Device | |||||
|---|---|---|---|---|---|
| Group | A | B | C | D | E |
| Smart Phone | O | O | O | O | O |
| Mobile App. | O | O | O | O | O |
| Health Band | O | O | O | - | O |
| Sleep Mat | - | O | - | O | O |
| Smart Watch | - | - | O | O | O |
| Blood Pressure Monitor | O | - | - | - | - |
| Glucose Meter | O | - | - | - | - |
| People | 11 | 5 | 5 | 4 | 1 |
| Group | Member | Number of Data Duplication | ||||
|---|---|---|---|---|---|---|
| Sleep | HR | Steps | Temp. | Hum. | ||
| A | 11 | 0 | 3 | 3 | 2 | 2 |
| B | 5 | 3 | 2 | 3 | 2 | 2 |
| C | 5 | 0 | 3 | 4 | 3 | 3 |
| D | 4 | 3 | 2 | 3 | 3 | 3 |
| E | 1 | 4 | 3 | 3 | 3 | 3 |
| Representative Value | t001 | t002 | t003 | t004 | t005 | t006 | t007 | … |
|---|---|---|---|---|---|---|---|---|
| smartphone | 4011 | 7893 | 10,048 | 3212 | 8772 | 3541 | 4065 | … |
| travel range | 3678 | 6980 | 9887 | 3098 | 8322 | 3289 | 3808 | … |
| smartband | 4237 | 8012 | 10,832 | 3348 | 8845 | 3743 | 4261 | … |
| median | 4011 | 7893 | 10,048 | 3212 | 8772 | 3541 | 4065 | … |
| mean | 3975 | 7628 | 10,255 | 3219 | 8646 | 3524 | 4044 | … |
| RMSE of Sleep Data | |||
|---|---|---|---|
| Attribute | to + 0, 1, 2 | ls + 0, 1, 2 | ds + 0, 1, 2 |
| Mean | 1.298 | 14.240 | 8.122 |
| Median | 1.310 | 14.397 | 8.147 |
| 1Quartile | 2.619 | 17.155 | 9.299 |
| 2Quartile | 2.376 | 16.487 | 8.802 |
| 3Quartile | 2.554 | 17.178 | 9.169 |
| RMSE of Number of Steps | |||
|---|---|---|---|
| Attribute | ns + 0 | ns + 1 | ns + 2 |
| Mean | 80.478 | 96.474 | 107.023 |
| Median | 82.897 | 99.501 | 111.051 |
| 1Quartile | 160.489 | 190.984 | 212.258 |
| 2Quartile | 120.714 | 150.418 | 170.143 |
| 3Quartile | 160.529 | 191.019 | 211.879 |
| RMSE of Number of Steps Estimation | ||||||
|---|---|---|---|---|---|---|
| Data | Estimation Methods | |||||
| Variable | Attribute | Mean | CF | RM | KNN | RMD |
| Sleep Data | to + 0, 1, 2 | 18.299 | 1.615 | 1.896 | 1.624 | 1.298 |
| ls + 0, 1, 2 | 154.122 | 17.717 | 20.807 | 17.821 | 14.240 | |
| ds + 0, 1, 2 | 70.048 | 10.106 | 11.868 | 10.165 | 8.122 | |
| Blood Sugar mg/dL | bs + 0, 1, 2 | 147.820 | 29.813 | 32.294 | 28.302 | 27.029 |
| Heart Rate | hr + 0, 1, 2 | 88.260 | 8.631 | 10.137 | 8.683 | 6.938 |
| Blood Pressure mmHg | sb + 0, 1, 2 | 118.915 | 9.840 | 10.468 | 12.088 | 8.829 |
| db + 0, 1, 2 | 83.175 | 7.507 | 7.876 | 7.406 | 6.933 | |
| Number of Steps | ns + 0, 1, 2 | 8864.1 | 1383.2 | 1624.4 | 1391.4 | 1111.7 |
| Temperature (°C) | tm + 0, 1, 2 | 15.262 | 1.491 | 1.867 | 1.504 | 1.068 |
| lt + 0, 1, 2 | 7.215 | 0.341 | 0.423 | 0.340 | 0.262 | |
| ht + 0, 1, 2 | 18.661 | 2.475 | 2.815 | 2.525 | 1.955 | |
| Humidity (%) | hu + 0, 1, 2 | 78.140 | 10.837 | 12.727 | 10.901 | 8.711 |
| Average | 805.33 | 123.63 | 144.80 | 124.39 | 99.76 | |
| Avg. | 0.897 | 0.811 | 0.941 | 1.194 | ||
| Measure | Model | ||||
|---|---|---|---|---|---|
| MDM | S_MDM | D_MDM | SD_MDM | ||
| Accuracy | 75.37% | 71.46% | 69.51% | 66.47% | |
| Parameter | 15,157 | 11,578 | 10,578 | 7578 | |
| Turnaround Time (sec) | Max. | 1.356 | 1.156 | 1.014 | 0.814 |
| Min. | 1.077 | 0.866 | 0.781 | 0.611 | |
| Avg. | 1.194 | 0.918 | 0.844 | 0.784 | |
| Data Size | 2.7 MB | 2.2 MB | 1.9 MB | 1.3 MB | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-C.; Chung, K. Recurrent Neural Network-Based Multimodal Deep Learning for Estimating Missing Values in Healthcare. Appl. Sci. 2022, 12, 7477. https://doi.org/10.3390/app12157477
Kim J-C, Chung K. Recurrent Neural Network-Based Multimodal Deep Learning for Estimating Missing Values in Healthcare. Applied Sciences. 2022; 12(15):7477. https://doi.org/10.3390/app12157477
Chicago/Turabian StyleKim, Joo-Chang, and Kyungyong Chung. 2022. "Recurrent Neural Network-Based Multimodal Deep Learning for Estimating Missing Values in Healthcare" Applied Sciences 12, no. 15: 7477. https://doi.org/10.3390/app12157477