1. Introduction
In recent years, deep neural networks have made significant achievements in many computer vision tasks such as image classification [
1,
2,
3,
4], object detection [
5,
6,
7], and semantic segmentation [
8,
9]. However, deep layers and millions of neurons also lead to inadequate training of CNN. Dropout [
10] is proposed as a regularization method widely used to fight against overfitting, which stochastically sets the activations of hidden units to zero during training. For deep CNN, dropout works well in fully connected layers, but its effect is still not apparent in convolutional layers, where features are correlated spatially. When the features are strongly correlated between adjacent neurons, the information of discarded neurons cannot be completely obscured.
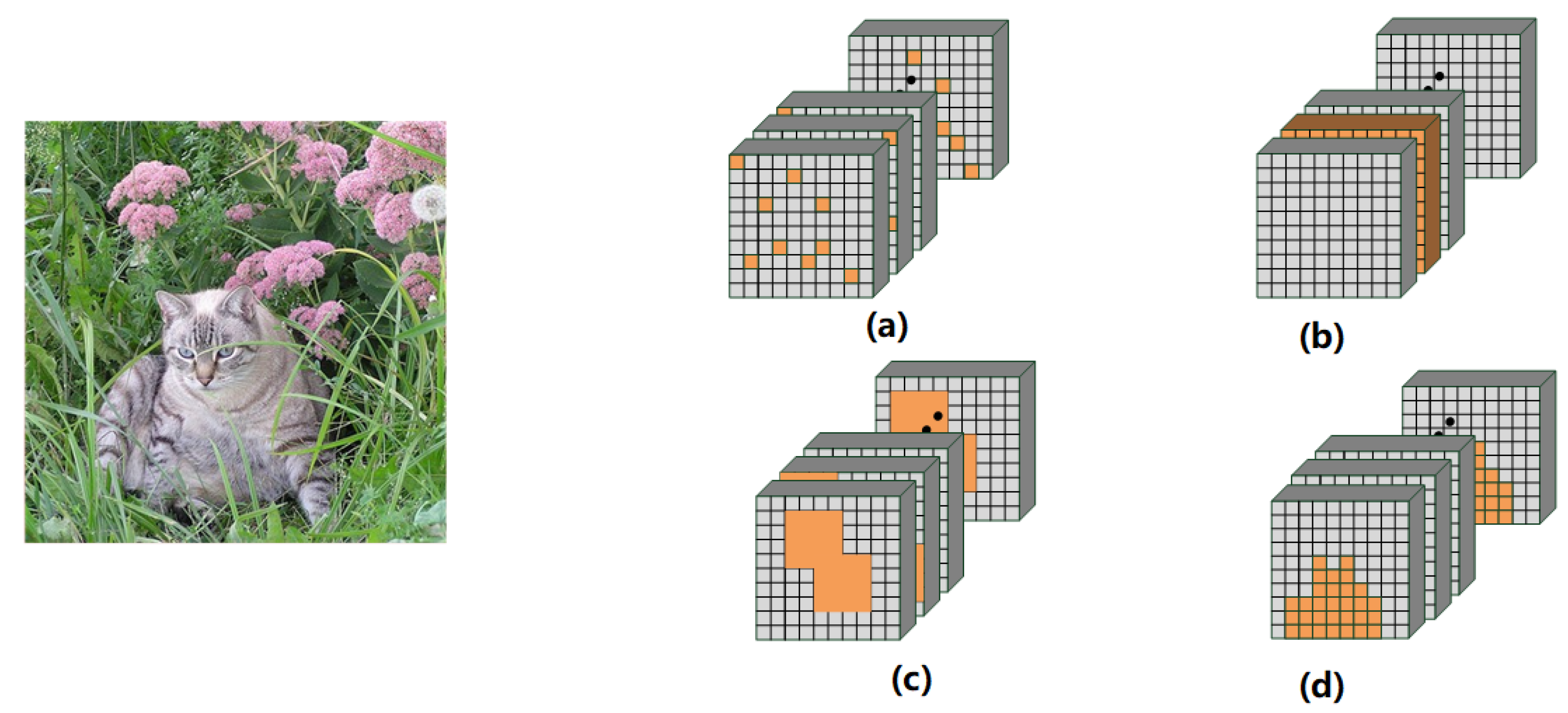
Many researchers have observed this defect and tried to make dropout better regularize CNN. As shown in
Figure 1, SpatialDropout [
11] randomly discards entire channels from whole feature maps. DropBlock [
12] randomly discards units in a contiguous region of a channel instead of substantive units. Guided dropout [
13], AttentionDrop [
14], and CamDrop [
15] search the influential units in the network through different methods and drop them to enhance the generalization performance of the network. Furthermore, Auto Dropout [
16] is proposed to learn the dropping patterns of SpatialDropout and DropBlock via reinforcement learning. Although it achieves state-of-the-art results, it requires a huge computational cost and is more like an extension of the mentioned approaches.
From another perspective, the foreground of the image is the main focus of classification, which means accurately finding the foreground is important for image classification. The results of observation experiments show the spatial information of images remains unchanged during training, and channels in the network are associated with the classification target. This indicates that we can enhance the foreground and thus improve the recognition of objects. It can also avoid noise interference from backgrounds. All of them enlightened us on using dropout to enhance the network’s ability to recognize the objects by keeping the foreground-related units and dropping other units during training, which is contrary to the existing methods that drop influential ones. There are two challenges: how to identify the foreground-related units, and how to prevent overfitting when enhancing influential ones.
In this paper, we propose FocusedDropout as a non-random dropout method to regularize CNNs. Inspired by Network Dissection [
17], a visualization method proposed by Hence, Bau et al., we first select the channel with the highest average activation value and discard the units with an activation value below a threshold on this channel. Then, we can distinguish useful units from redundant units with the support of spatial invariance of CNN by discarding all units that have the same positions as previously discarded ones on the rest of the channels. Increasing weight decay [
18] while using FocusedDropout can avoid overfitting and increase accuracy. As a result, the network focuses more on the units that have the highest probability associated with the target, which is particularly effective for regularization. Extensive experimental results show that even a slight cost, 10% of batches employing FocusedDropout, can produce a nice performance boost over the baselines on CIFAR10 [
19], CIFAR100 [
19], Tiny ImageNet (
http://tiny-imagenet.herokuapp.com/), and has a good versatility for different CNN models including ResNet [
4], DenseNet [
20], VGGNet [
21] and Wide ResNet [
22].
This work provides these primary contributions: 1. This paper proposes a non-random dropout method to regularize CNNs, called FocusedDropout. Unlike previous works, which discarded influential units, it enhances features related to the classification by discarding others, thus effectively improving the classification performance. 2. We also propose an assisted training strategy to avoid overfitting, magnifying the weight decay while the FocusedDropout is used, and only randomly select 10% of the batches to use the proposed method. 3. Extensive experiments are conducted to verify the performance. The results show the FocusedDropout is lightweight, achieving the best score in many tasks.
2. Related Work
Regularization methods have always been effective ways to improve the performance of neural networks, which involve two common regularization techniques: data augmentation and dropout [
10]. Unlike data augmentation, such as [
23,
24,
25], which expands the data space, dropout injects noise into feature space by randomly zeroing the activation function to avoid overfitting. Inspired by dropout, DropConnect [
26] drops the weights of the networks instead of activations to regularize large neural network models. Shakeout [
27] randomly chooses to enhance or inverse the contributions of each unit to the next layer. Concrete Dropout [
28] utilizes concrete distributions to generate the dropout masks. Alpha-dropout [
29] is designed for Scaled Exponential Linear Unit activation function. Variational dropout [
30] is proposed as a generalization of Gaussian dropout, but with a more flexibly parameterized posterior. These strategies work well on the fully connected network, but their performance on CNN is unsatisfactory. The reason is that the correlation between the units on each channel in CNN is so strong that information can still flow through the networks despite dropout. Obviously, this reduces the improvement [
11].
Previous studies demonstrated that the correlation always relies on location information, which pushes forward the study about dropping the network weights by leveraging structures. SpatialDropout [
11] is proposed by randomly discarding the entire channels rather than individual activations. Channel-Drop [
31] overcomes the drawbacks of local winner-takes-all methods used in deep convolutional networks. Inspired by Cutout [
32], DropBlock [
12] randomly drops some contiguous regions of the feature map. With the continuous improvement of the network models, lots of regularization methods, such as Stochastic Depth [
33], Shake-Shake [
34], and ShakeDrop [
35], have emerged for specific CNNs such as ResNet [
4] and ResNext [
36]. Although the above methods enhance the networks’ ability by randomly discarding neurons or changing weight, the network also easily suffers from the overfitting problem because the networks can still learn too many features about the objects during the training.
Therefore, some approaches focus on discarding specific units are proposed. Max-drop [
37] drops the activations which have high values across the feature map or the channels. Targeted dropout [
38] combines the concept of network cropping with dropout, which selects the least important weights in each round of training and discards the candidate weights to enhance network robustness. Guided Dropout [
13] defines the strength of each node and strengthens the training of weak nodes by discarding strong nodes during training. Weighted Channel Dropout [
39] aims to solve the overfitting in small data set training, which calculates the average activation value of each channel and retains the high-valued channels with higher possibility. AttentionDrop [
14] drops features adaptively based on attention information. CamDrop [
15] electively abandons some specific spatial regions in predominating visual patterns by considering the intensity of class activation mapping. Discarding influential units makes the network less prone to the overfitting problem. However, it cannot improve the classification performance of the network.
Recently, some algorithms have also been proposed, and had good results. R-Drop [
40] offers a simple consistency training strategy to regularize dropout. It forces the output distributions of different sub-models generated by dropout to be consistent with each other. Contextual Dropout [
41] proposes a simple and scalable sample-dependent dropout, which learns the dropout probabilities with a variational objective and is compatible with both Bernoulli and Gaussian dropout. Juan Shu et al. [
42] develop a Heteroscedastic Gaussian Dropout algorithm, where the dropout probability is determined by another model with mirrored GNN architecture. On the other hand, with the development of reinforcement learning, it has been applied to many domains, including dropout. A controller in Auto Dropout [
16] is introduced to learn the dropping patterns of SpatialDropout and DropBlock, and generate them at every channel and layer, which will be followed in the training procedure of the target network. Significantly, although those methods achieve improvement with varying degrees, our method is able to match or outperform their scores. Additionally, the computational cost increment is lower than others.
3. Motivation
Existing non-random dropout methods judge units’ influence in different ways and discard the units with greater influence, aiming to make the network more robust from the perspective of preventing overfitting. However, influential units contain information conducive to classification, and strengthening the learning of this part of units may make networks focus more on target information. The network could learn more features about the target point to the classification, thus improving the performance benefits of more precise learning. However, this may also lead to overfitting performance because the network will learn many specific characteristics rather than the general ones that indicate the semantics of said domain. Therefore, there are two challenges: one is how to identify the target-related units, and the other is how to prevent overfitting when enhancing influential ones.
We select the target-related units based on Network Dissection [
17], a visualization method for the interpretability of latent representations of CNN. In this study, after putting an image containing pixel-wise annotations for the semantic concepts into a trained network, the activation map of the target neuron is scaled up to the resolution of the ground truth segmentation mask. If the measurement result of alignment between the upsampled activation map and the ground truth segmentation mask is larger than a threshold, the neuron would be viewed as a visual detector for a specific semantic concept. The results show the visual detectors always correspond to the ground truth of the target. From this work, we can conclude that the image’s spatial information remains unchanged during training, and there are channels related to the classification target in the trained network. Next, we need to find the target-related channels.
We conduct an exploratory experiment to find the target-related units. We first put the CIFAR10 dataset’s validation set containing 10,000 images into the vanilla ResNet-56 model pretrained with CIFAR10, and record the channel with the highest activation value in the last layer for every successfully classified image. Note that there are 9392 successfully classified images in 10 categories, and the number of the channel in the last layer is 256. The result can be seen in
Figure 2. We find that the channels with the highest activation value are different for different categories. For the same category of successfully classified images, there are only one or two fixed channels with the highest activation values. This shows that the channel with the highest activation value is crucial to the success of the classification task. Thus, we speculate that the channel with the highest average activation value has the highest probability of containing foreground information, and the units with the high activation value on this channel have the highest probability of representing foreground features. Therefore, we can take this channel as a reference, and combine spatial invariance to select other useful units on the remaining channels.
As mentioned, retaining only the units with larger weights may exacerbate overfitting intuitively. Thus, we want to find a balance between strengthening the network’s attention to the target and preventing the network from overfitting. To achieve this balance, we propose two countermeasures. First, we only randomly select 10% of the batches to use FocusedDropout during every training epoch. Additionally, we will magnify weight decay when using FocusedDropout. We find these two measures can avoid overfitting effectively and improve the robustness of the network.
4. Our Approach
FocusedDropout is a highly targeted approach that makes the networks focus on the foreground rather than the background or noise. The main idea of FocusedDropout is to keep the units in the preferred locations related to the classification target and drop the units in other locations. According to the spatial invariance of CNN, the locations of images’ features are fixed during training so that different channels’ units with the same spatial positions represent the same image features. Inspired by this phenomenon, FocusedDropout uses a binary mask to cover the target-independent units with the same positions on each channel, as demonstrated in
Figure 3. The algorithm of FocusedDropout is illustrated in Algorithm 1. Next, we will present the details of FocusedDropout.
| Algorithm 1 FocusedDropout |
| Require: whole channels of the previous layer , mode |
|
1: if mode = Inference, then |
|
2: Return = C |
|
3: end if |
|
4: Calculate the average activation value for each as , Get the with the max |
|
5: Get the unit having the highest activation value as |
|
6: Make the all-zero mask m having the same size with |
|
7: for in m do |
|
8: if then |
|
9: |
|
10: end if |
|
11: end for |
|
12: Return |
4.1. Selecting the Reference Channel
Each channel output by convolutional layers can be regarded as a set of features extracted from the image. Our goal is to find the channel with the highest possibility of obtaining the features relevant to the target. We observe that the channel with the largest average activation value has the greatest effect on the result, and we consider that it contains the most important features. Therefore, FocusedDropout uses Global Average Pooling to acquire the average activation value of each channel. To facilitate the presentation, we introduce the following concepts.
denotes the whole channels from the previous layer;
denotes the single channel, i.e., the entire feature map; and
denotes the activation value of a unit on
. So, the average activation value of
is computed as
where
w and
h are the shared width and height of all channels. After getting all the weights, we choose the max one,
, as the reference channel, and
k is computed as
4.2. Finding the Focused Area
After obtaining the reference channel, we need to get the location information of the target-related features from it. The units with high activation values have more influence on the task, so first, we find the highest activation value
on the reference channel as the criterion for setting the threshold, where
is set as
We take a random ratio
between 0.3 and 0.6 and set the threshold as
We set a random ratio rather than a certain one, because different images have different numbers of features. Units with an activation value higher than the threshold are considered target-related. The assembling of these units’ positions is considered as the area related to the target, i.e., the focused area A.
4.3. Generating the Binary Mask
Although the focused area is obtained from the reference channel, units in the same area on the other channels are still related to the target due to the spatial invariance of CNN. In other words, different channels from the previous layer extract various features from the image, but the same position of these channels represents the same location of the image. Thus, we need to retain each channel’s units in the preferred area. To simplify the calculation, we use a binary mask multiplying all channels to achieve this step. The binary mask
m satisfies
where
represents the value of the binary mask, and
A represents the focused area. Only the units contained in the focused area can be reserved when the binary mask is multiplied by all channels.
4.4. Magnifying Weight Decay (MWD)
During training, we randomly choose 10% of batches using FocusedDropout rather than every batch. Only retaining the high-weight units may aggravate the overfitting, so we increase weight decay when using FocusedDropout, which can limit the network’s over attention to the classification target and inhibit the overfitting. This is a new training trick for dropout, because dropout is often used in all batches of every epoch and weigh decay is fixed during training. We call the rate of batches applying FocusedDropout . The computing resource and time consumption can be decreased obviously, and the model’s performance can still be enhanced with this trick. In the testing phase, we retain all units as conventional dropout.
4.5. Summing Up
In summary, we first find the focused areas by searching the reference channel with the highest activation value. They will be considered units, with the higher activation value associated with the mentioned reference channel. Then, we drop backgrounds by generating a binary mask and multiplying it with all channels. In this way, the network will focus on the objects, thus improving the performance. However, it may also lead to the network falling into the overfitting trap. Therefore, the weight decay will be magnified while the FocusedDropout is used, and only 10% of the batches are selected to use the proposed method.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}