
Chinese Named Entity Recognition of Geological News Based on BERT Model



Abstract
:1. Introduction
- (1)
- GNNER was based on the BERT model, integrating a variety of different models and extracting various types of entities from the constructed geological news corpus.
- (2)
- This research used crawler technology to obtain geological news texts from the China Geological Survey Bureau, preprocessed the data, including long text segmentation, data cleaning, and removal of uncommon punctuation marks, and used the “BIO” named entity labeling method to label the texts to create a dataset of a certain scale in the field of geological news.
- (3)
- The BERT-BiLSTM-CRF model was used to conduct a comparative experiment with the other five models on the geological news dataset, analyze the quality of the six models, and discuss the effects of geological news entity type, number of labels, and model hyperparameters on model evaluation.
2. Materials and Methods
2.1. Word2vec
2.2. BiLSTM-CRF
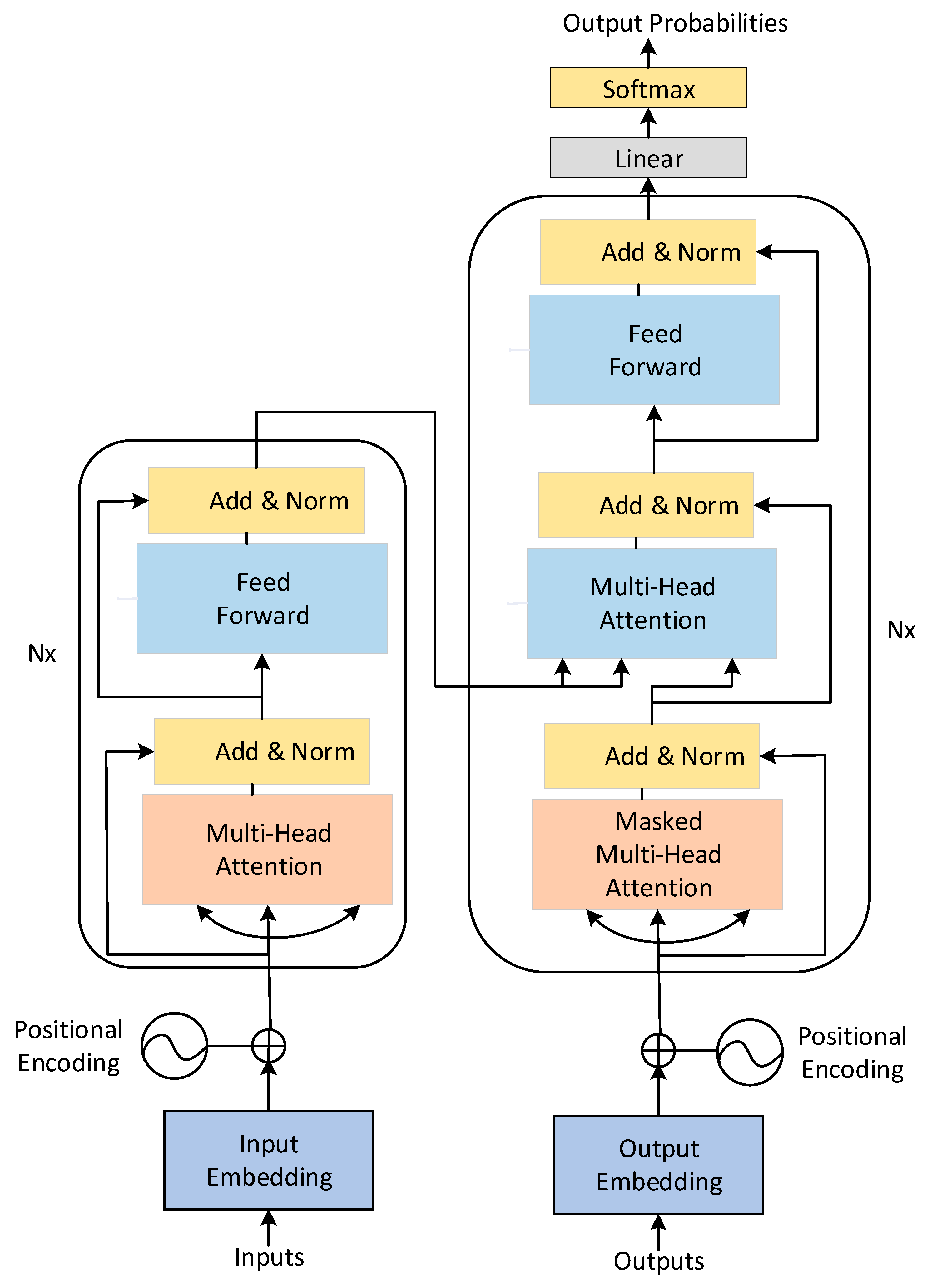
2.3. BERT
- (1)
- Input of Transformer
- (2)
- Self-attention mechanism
- (3)
- Multi-head mechanism
- (4)
- Summation and normalization
2.4. Model Design
2.5. Data Processing and Experimental Setup
2.5.1. Data Source and Pre-Processing
2.5.2. Text Corpus Annotation
2.5.3. Experimental Environment and Parameters
3. Results
3.1. Experimental Evaluation Indicators
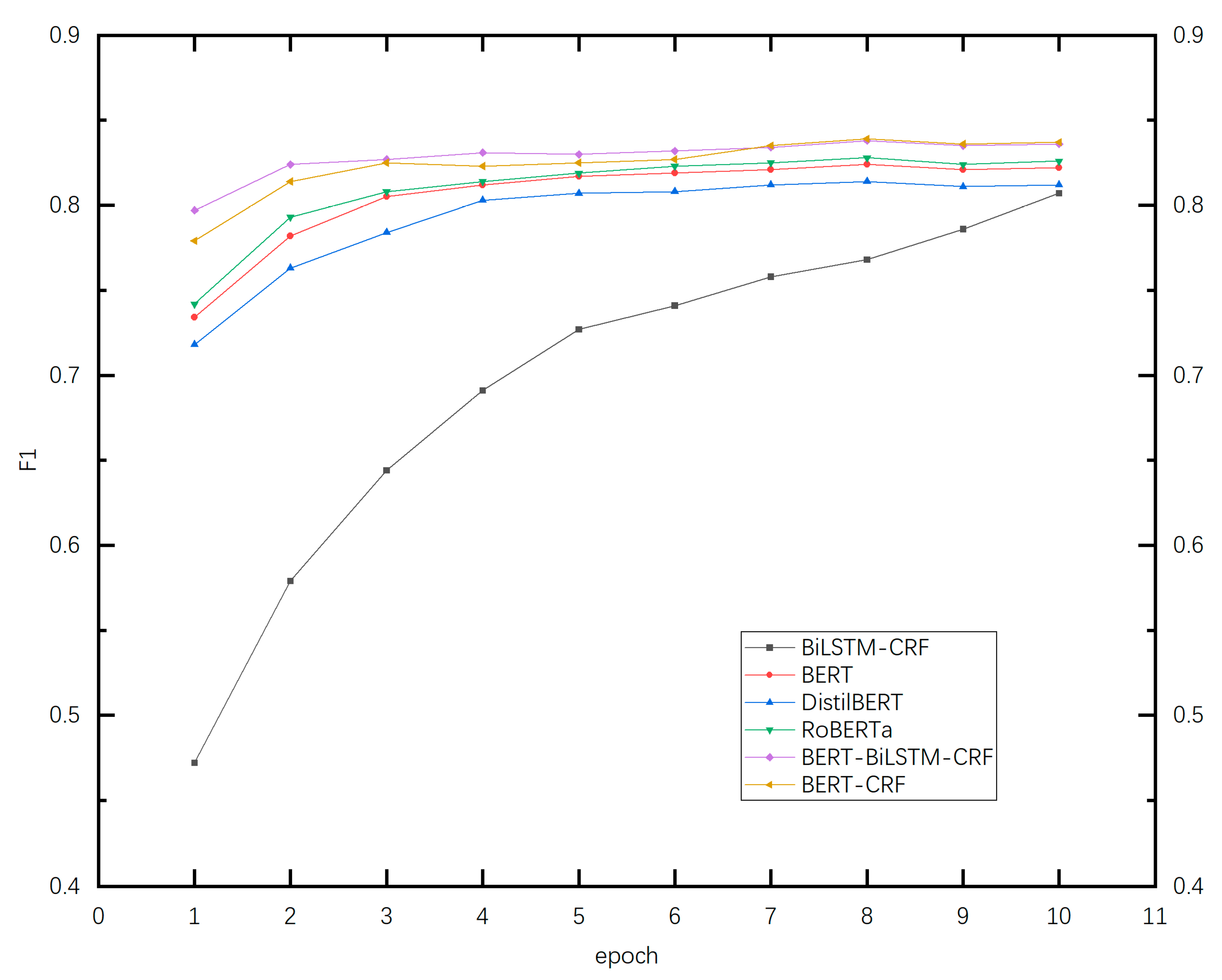
3.2. Comparison of Different Models
- (1)
- The six models adopted in the experiment have achieved good results in the geological news text NER task.
- (2)
- In the geological news text NER task, the F1 scores of the BERT, DistilBERT, RoBERTa, BERT-CRF, and BERT-BiLSTM-CRF models are 0.824, 0.814, 0.828, 0.839, and 0.838, respectively. Compared to BiLSTM-CRF, the F1 scores increase by 5.6%, 4.6%, 6%, 7.1%, and 7%. This shows that as the BERT pre-training model can understand the contextual information of the text well and solve the polysemy problem, it has a good effect on the named entity recognition task.
- (3)
- The improved DistilBERT and RoBERTa models based on BERT achieve F1 scores of 0.814 and 0.828, respectively. Compared to the BERT model, the entity recognition effect of the DistilBERT model is slightly worse, while the RoBERTa model is better.
- (4)
- In the geological news text NER task, the P, R, and F1 scores of the BERT-CRF model improve by 1.9%, 1.2%, and 1.5%, respectively, compared to the BERT model because of a mutual constraint relationship between the tags (e.g., the tag of an entity can only start with “B” but not “I”). It can be seen after adding the CRF layer that CRF can deal with the mutual constraint relationship between the tags and effectively solve the problem of inconsistent sequence tags.
- (5)
- The P, R, and F1 scores of BERT-CRF are 0.838, 0.841, and 0.839, respectively, which are the best among all models. Compared to the BERT-BiLSTM-CRF model, which introduced the BiLSTM layer, the two achieved comparable results in the NER task of geological news texts. The reason for this is that the BERT model itself is effective in feature extraction, and the BiLSTM layer is introduced based on the BERT-CRF model. Overfitting occurs after this layer is trained, resulting in a decreased effect.
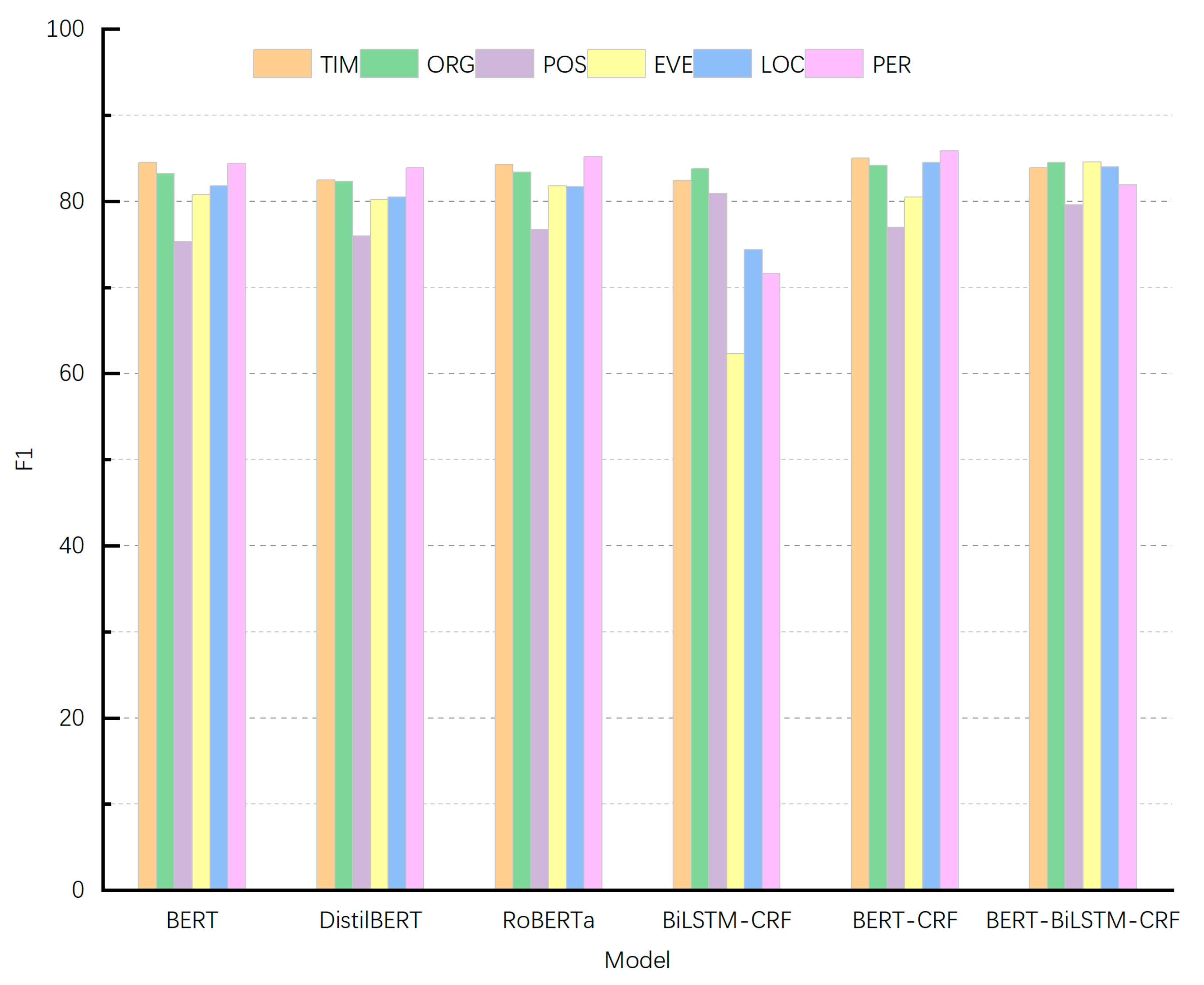
3.3. Effect of Entity Type and Quantity
3.4. Influence of Model Hyperparameters
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goralski, M.A.; Tan, T.K. Artificial intelligence and sustainable development. Int. J. Manag. Educ. 2020, 18, 100330. [Google Scholar] [CrossRef]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. arXiv 2017, arXiv:1708.05148. [Google Scholar] [CrossRef]
- Shaalan, K.; Raza, H. Arabic named entity recognition from diverse text types. In Proceedings of the International Conference on Natural Language Processing, Gothenburg, Sweden, 25–27 August 2008; pp. 440–451. [Google Scholar]
- Alfred, R.; Leong, L.C.; On, C.K.; Anthony, P. Malay named entity recognition based on rule-based approach. Int. J. Mach. Learn. Comput. 2014, 3, 300–306. [Google Scholar] [CrossRef] [Green Version]
- Shaalan, K.; Raza, H. NERA: Named entity recognition for Arabic. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 1652–1663. [Google Scholar] [CrossRef]
- Todorovic, B.T.; Rancic, S.R.; Markovic, I.M.; Mulalic, E.H.; Ilic, V.M. Named entity recognition and classification using context Hidden Markov Model. In Proceedings of the 2008 9th Symposium on Neural Network Applications in Electrical Engineering, Belgrade, Serbia, 25–27 September 2008; pp. 43–46. [Google Scholar]
- Eddy, S.R. What is a hidden Markov model? Nat. Biotechnol. 2004, 22, 1315–1316. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Och, F.J.; Ney, H. Discriminative training and maximum entropy models for statistical machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 295–302. [Google Scholar]
- Ratnaparkhi, A. Maximum Entropy Models for Natural Language Processing. In Encyclopedia of Machine Learning and Data Mining; Springer: New York, NY, USA, 2017; pp. 800–805. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the 18th International Conference on Machine Learning, San Francisco, CA, USA, 28 June–1 July 2001. [Google Scholar]
- Zhang, X.Y.; Ye, P.; Wang, S.; Du, M. Geological entity recognition method based on deep belief network. Chin. J. Petrol. 2018, 34, 343–351. [Google Scholar]
- Liu, P.; Ye, S.; Shu, Y.; Lu, X.L.; Liu, M.M. Research on coal mine safety knowledge graph construction and intelligent query method. Chin. J. Inf. 2020, 34, 49–59. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K.J.a.p.a. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Viterbi, A.J. A personal history of the Viterbi algorithm. IEEE Signal Processing Mag. 2006, 23, 120–142. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30, Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, J.; Zhang, Y.; Li, L.; Li, X. YEDDA: A lightweight collaborative text span annotation tool. arXiv 2017, arXiv:1711.03759. [Google Scholar]
- Chen, Z.L.; Yuan, F.; Li, X.H.; Zhang, M.M. Joint extraction of named entities and relations from Chinese rock description text based on BERT-BiLSTM-CRF Model. Geol. Rev. 2022, 68, 742–750. Available online: https://kns.cnki.net/kcms/detail/detail.aspx?doi=10.16509/j.georeview.2022.01.115 (accessed on 23 July 2022).
- Xie, T.; Yang, J.A.; Liu, H. Chinese entity recognition based on BERT-BiLSTM-CRF model. Comput. Syst. Appl. 2020, 29, 48–55. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tags | Type | Number |
|---|---|---|
| TIM | Time | 3492 |
| ORG | Organization | 5630 |
| POS | Job title | 1050 |
| EVE | Event | 2032 |
| LOC | Geographic location | 7702 |
| PER | Name | 1417 |
| Category | Configuration |
|---|---|
| Hardware | GPU: 4*NVIDIA Tesla K80 |
| OS: CentOS 8.3 | |
| Video memory: 11 GB GDDR6 | |
| Software | CUDA: 11.4 |
| Python: 3.6 | |
| Tensorflow: 1.14.0 | |
| Pytorch: 1.4.0 | |
| Numpy: 1.19.2 |
| Hyper-Parameter | Parameter Values |
|---|---|
| Epochs | 8 |
| max_len | 128 |
| batch_size | 16 |
| learning_rate | 3 × 10−5 |
| drop_rate | 0.5 |
| Model | Eval | TIM | ORG | POS | EVE | LOC | PER | Avg |
|---|---|---|---|---|---|---|---|---|
| BERT | P | 0.863 | 0.820 | 0.691 | 0.820 | 0.802 | 0.887 | 0.819 |
| R | 0.827 | 0.844 | 0.827 | 0.796 | 0.835 | 0.806 | 0.829 | |
| F | 0.845 | 0.832 | 0.753 | 0.808 | 0.818 | 0.844 | 0.824 | |
| DistilBERT | P | 0.847 | 0.796 | 0.721 | 0.793 | 0.787 | 0.864 | 0.808 |
| R | 0.804 | 0.852 | 0.803 | 0.812 | 0.824 | 0.816 | 0.821 | |
| F | 0.825 | 0.823 | 0.760 | 0.802 | 0.805 | 0.839 | 0.814 | |
| RoBERTa | P | 0.865 | 0.828 | 0.725 | 0.815 | 0.808 | 0.876 | 0.823 |
| R | 0.823 | 0.841 | 0.814 | 0.821 | 0.827 | 0.829 | 0.834 | |
| F | 0.843 | 0.834 | 0.767 | 0.818 | 0.817 | 0.852 | 0.828 | |
| BiLSTM-CRF | P | 0.893 | 0.876 | 0.864 | 0.563 | 0.812 | 0.854 | 0.814 |
| R | 0.765 | 0.803 | 0.760 | 0.697 | 0.687 | 0.616 | 0.728 | |
| F | 0.824 | 0.838 | 0.809 | 0.623 | 0.744 | 0.716 | 0.768 | |
| BERT-CRF | P | 0.841 | 0.837 | 0.733 | 0.803 | 0.849 | 0.878 | 0.838 |
| R | 0.860 | 0.847 | 0.811 | 0.808 | 0.841 | 0.840 | 0.841 | |
| F | 0.850 | 0.842 | 0.770 | 0.805 | 0.845 | 0.859 | 0.839 | |
| BERT-BiLSTM-CRF | P | 0.844 | 0.844 | 0.739 | 0.853 | 0.843 | 0.827 | 0.839 |
| R | 0.835 | 0.846 | 0.863 | 0.838 | 0.838 | 0.811 | 0.838 | |
| F | 0.839 | 0.845 | 0.796 | 0.846 | 0.840 | 0.819 | 0.838 |
| Model | Learning_Rate | P | R | F |
|---|---|---|---|---|
| BiLSTM-CRF | 1 × 10−5 | 0.795 | 0.725 | 0.758 |
| 2 × 10−5 | 0.804 | 0.732 | 0.766 | |
| 3 × 10−5 | 0.814 | 0.728 | 0.768 | |
| 4 × 10−5 | 0.817 | 0.721 | 0.766 | |
| 5 × 10−5 | 0.806 | 0.725 | 0.763 | |
| BERT | 1 × 10−5 | 0.805 | 0.823 | 0.814 |
| 2 × 10−5 | 0.814 | 0.827 | 0.821 | |
| 3 × 10−5 | 0.819 | 0.829 | 0.824 | |
| 4 × 10−5 | 0.823 | 0.819 | 0.821 | |
| 5 × 10−5 | 0.817 | 0.822 | 0.819 | |
| DistilBERT | 1 × 10−5 | 0.798 | 0.812 | 0.805 |
| 2 × 10−5 | 0.803 | 0.814 | 0.808 | |
| 3 × 10−5 | 0.808 | 0.821 | 0.814 | |
| 4 × 10−5 | 0.812 | 0.811 | 0.811 | |
| 5 × 10−5 | 0.805 | 0.818 | 0.811 | |
| RoBERTa | 1 × 10−5 | 0.809 | 0.816 | 0.812 |
| 2 × 10−5 | 0.817 | 0.822 | 0.819 | |
| 3 × 10−5 | 0.823 | 0.834 | 0.828 | |
| 4 × 10−5 | 0.826 | 0.828 | 0.827 | |
| 5 × 10−5 | 0.821 | 0.827 | 0.824 | |
| BERT-BiLSTM-CRF | 1 × 10−5 | 0.821 | 0.823 | 0.822 |
| 2 × 10−5 | 0.832 | 0.833 | 0.832 | |
| 3 × 10−5 | 0.839 | 0.838 | 0.838 | |
| 4 × 10−5 | 0.834 | 0.838 | 0.836 | |
| 5 × 10−5 | 0.834 | 0.825 | 0.829 | |
| BERT-CRF | 1 × 10−5 | 0.823 | 0.819 | 0.821 |
| 2 × 10−5 | 0.829 | 0.832 | 0.831 | |
| 3 × 10−5 | 0.838 | 0.841 | 0.839 | |
| 4 × 10−5 | 0.836 | 0.838 | 0.837 | |
| 5 × 10−5 | 0.832 | 0.824 | 0.828 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, C.; Wang, Y.; Yu, Y.; Hao, Y.; Liu, Y.; Zhao, X. Chinese Named Entity Recognition of Geological News Based on BERT Model. Appl. Sci. 2022, 12, 7708. https://doi.org/10.3390/app12157708
Huang C, Wang Y, Yu Y, Hao Y, Liu Y, Zhao X. Chinese Named Entity Recognition of Geological News Based on BERT Model. Applied Sciences. 2022; 12(15):7708. https://doi.org/10.3390/app12157708
Chicago/Turabian StyleHuang, Chao, Yuzhu Wang, Yuqing Yu, Yujia Hao, Yuebin Liu, and Xiujian Zhao. 2022. "Chinese Named Entity Recognition of Geological News Based on BERT Model" Applied Sciences 12, no. 15: 7708. https://doi.org/10.3390/app12157708
APA StyleHuang, C., Wang, Y., Yu, Y., Hao, Y., Liu, Y., & Zhao, X. (2022). Chinese Named Entity Recognition of Geological News Based on BERT Model. Applied Sciences, 12(15), 7708. https://doi.org/10.3390/app12157708