
Explainability of Predictive Process Monitoring Results: Can You See My Data Issues?


Abstract
:1. Introduction
1.1. Problem Statement
1.2. Contributions
- A study of the effects that the underlying choices made in the context of a PPM task have on the predicted outcomes of a running process instance. In particular, we investigate changes in preprocessed data as a result of applying different transformation and preprocessing configurations.
- A study of how the explanations generated by two different global XAI methods (i.e., two model-specific methods, in addition to permutation feature importance and SHAP) can reflect inconsistencies and sensitivities in the executed predictive models. We investigate how changes in data that result from the application of different preprocessing configurations can expose the sensitivities of a predictive model and how this exposure can be reflected through explanations. Global methods used in the context of this research generate explanations for the outcomes of two predictive models. The latter are executed over process instances from three real-life event logs preprocessed with two different preprocessing configurations.
- An open-access framework of various XAI methods built upon different PPM workflow settings.
2. Background
2.1. Predictive Process Monitoring
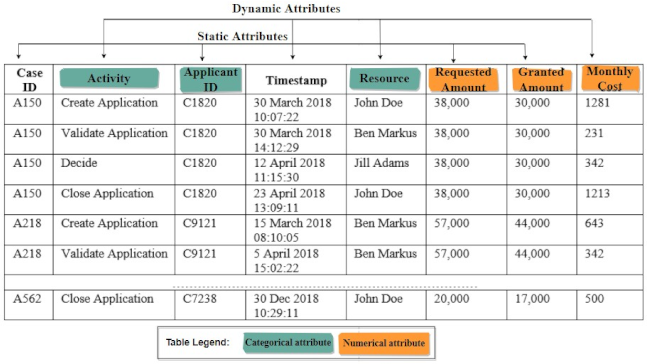
- Case ID: represents a unique identifier of the case in the whole event log.
- Event class: represents a step carried out in fulfilling the process instance. This step is the activity name. Receive application, check documents, assess risks, and notify customer are all examples of events carried out in a loan application process instance.
2.1.1. PPM Workflow
- 1.
- PPM offline stage. The input in this stage is an event log. Usually, the latter meets process mining requirements, i.e., it is organised in the form of cases. Each case has a number of mandatory and optional attributes. Preprocessing steps are performed on the event log to transform its cases into a format compatible with the constraints and requirements of the prediction generation process.
- (a)
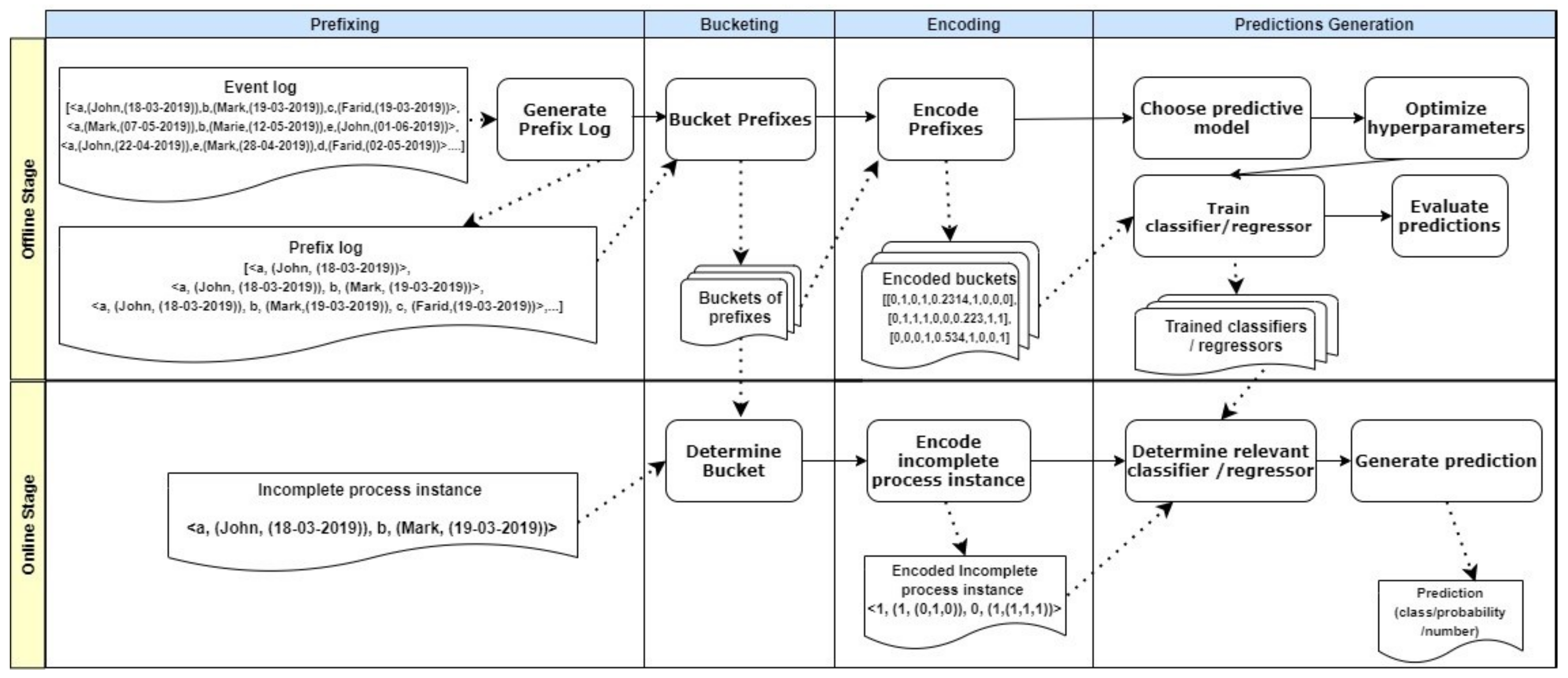
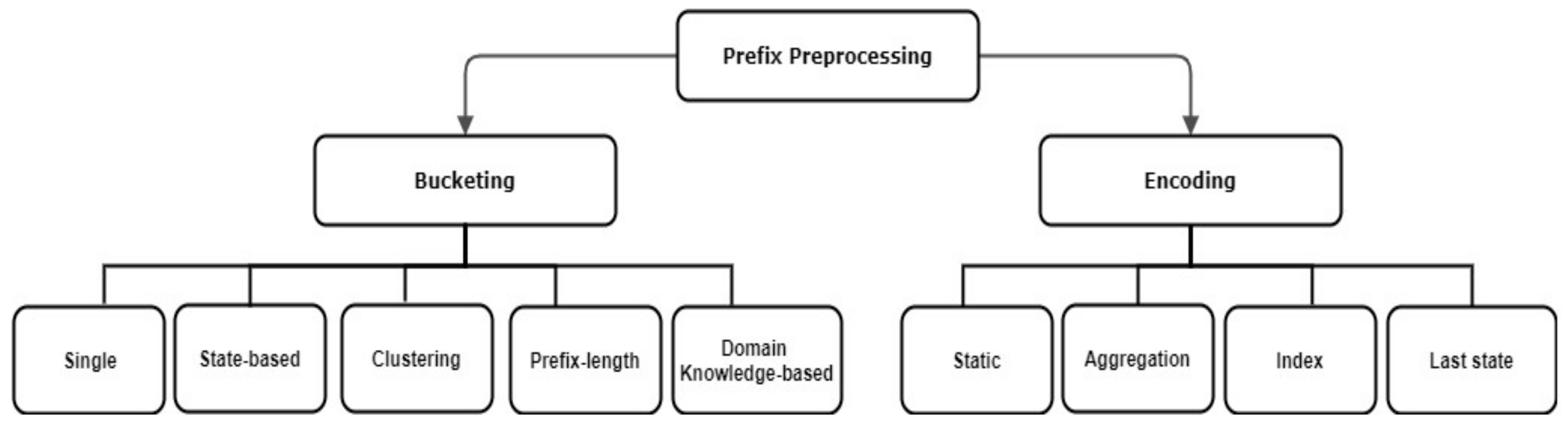
- Prefix log construction. As stated by [2], the input of most PPM approaches relying on ML is a prefix log constructed from the input event log. Note that a predictive model is expected to predict information related to an incomplete process instance (i.e., a partial case). Consequently, the predictive model has to be trained on partial cases of historical process instances captured in the event log. Note that the prefixes generated from an event log may increase to the extent of slowing down the overall prediction process [2]. Therefore, prefixes can be generated by truncating a process instance up to a predefined number of events. As proposed by [13], truncating a process instance can be carried out up to the first k events of its case, or up to k events with a gap step (g) separating each two events, where k and g are user-defined. The latter prefixing approach is called gap-based prefixing.Prefix case, prefix log. Consider a case , where n ∈ N is the number of events and m ∈ M is the number of event attributes. A prefix is generated from , where , g is the gap or step size between an event and the following one in , , and . A prefix log is the set of all prefixes generated from all cases (or a defined set of cases) in the event log during preprocessing. A prefix log may include events with or without their associated data attributes.After obtaining a prefix log from the given event log, the prefixes need to be further preprocessed in order to serve as appropriate inputs for the predictive model. Prefix preprocessing steps include bucketing and encoding. Available preprocessing configurations are limited in the literature, as reported by [2,12]. Figure 2 shows an overview of these techniques, which are introduced briefly through our illustration of the bucketing and encoding preprocessing steps.
- (b)
- Bucketing. During prefix bucketing, the prefixes are grouped according to certain criteria (e.g., the number of events or the state reached during process execution). Prefixes in the same bucket are treated as a unit in the encoding and training steps of the offline stage. Moreover, in the online stage, these prefixes form a unit when examining an incomplete process instance in order to find its respective bucket, i.e., similar group of instances. Bucketing can be based on the commonly reached state of the grouped prefixes, on applying clustering techniques to group prefixes, on using domain knowledge or prefix length to bucket several prefixes, or simply on grouping all prefixes into one bucket, which is called the single bucketing technique.In single bucketing, all prefixes generated from the cases of an event log are treated as a single bucket, whereas in prefix length-based bucketing, prefixes of the same length are bucketed together. Finally, for each bucket, a separate predictive model is created. Therefore, the choice of bucketing technique affects the number of prefixes belonging to the same bucket as well as the number of predictive models to be built.
- (c)
- Encoding. While bucketing techniques deal with how to group prefixes together, encoding techniques are concerned with how to format a single prefix in order to align it with the prediction process requirements. During prefix encoding, a prefix is transformed into a feature vector that serves as an input of the predictive model, either for training purposes or for making predictions. A predictive model can only receive numerical values. Therefore, all categorical attributes of a training event log or a training process instance need to first be transformed into a numerical form. The same applies to process instances with prefixes that serve as input for a predictive model. In the context of PPM-related encoding, a slight change to the regular ML encoding step is needed.As reviewed in [2,12], there are four techniques used to encode prefixes. Static encoding is used to encode static attributes of a prefix event log, where numerical static features are used as-is and one-hot encoding is applied to categorical static attributes. In contrast, aggregation, index-based and last state encoding are examples of techniques used to encode dynamic attributes of prefix event logs. In last-state encoding, the last m states of a process instance are converted into a numerical form. This encoding technique is thus considered to be a lossy technique, as it leaves out important information about events that are executed before the selected last m states.Aggregation encoding aggregates values of numerical dynamic attributes by using selected aggregation functions such as the sum, mean, or standard deviation of the values of the attribute for a single process instance. Furthermore, for categorical attributes all of the occurrences of the values of an attribute associated with a single process instance are either aggregated according to frequency-based or boolean-based counting (i.e., the attribute has a value or it does not). In index-based encoding, a process instance is represented by a single row, in which each value of each categorical attribute is the header of a column. Numerical values can thus be propagated as-is when using this encoding technique.To illustrate both techniques, we refer back to Table 1 and take the process instance with Case ID = A150. Table 2 and Table 3 provide two forms of this process instance, encoded using either aggregation or index-based encoding techniques, respectively. Note that we do not consider the Timestamp column in these examples, as this column is usually used to derive latent columns, e.g., hour, year, or day. However, the same encoding rules are applied to the latent columns according to the data type of these columns. Different encoding techniques yield different sizes of encoded prefixes with different types of included information. In turn, this diversity has been proven to affect both the accuracy of the predictions and the efficiency of the prediction process expressed in terms of execution times and needed resources [2].Note that the difference between the two examples is represented by the differences in how dynamic attributes are encoded. All encoding techniques applied to dynamic attributes are accompanied by static encoding used for encoding static attributes.
- (d)
- Predictive model construction and operation. Depending on the PPM task, the respective predictive model is chosen. In this context, the prediction task type is not the only factor guiding the process of selecting the predictive model. Other relevant factors include the scalability of the predictive model when facing larger event logs, its simplicity, and the interpretability of the results. According to [2], Decision Trees (DT) are most often selected in current PPM research thanks to their simplicity. XGBoost represents another type of high-performing predictive model used in the context of PPM tasks [2].The assignment of parameter values follows the model selection step. The values of model parameters are learned by the model during the training phase, whereas the values of hyperparameters are set prior to training the model. In the next step, the predictive model is trained based on encoded prefixes that represent completed process instances. Note that for each bucket, a dedicated predictive model needs to be trained, i.e., the number of predictive models depends on the chosen bucketing technique. After generating predictions for the training event log, the performance of a predictive model needs to be evaluated. Generally, the choice of the evaluation technique depends on the prediction task, e.g., classification tasks have different evaluation metrics than regression tasks.
- 2.
- PPM online stage. This stage starts with an incomplete process instance, i.e., a running process instance. Buckets formed in the offline stage are recalled to determine the suitable bucket for the running process instance. Finding the relevant bucket is based on the similarity between the running process instance and the prefixes in a bucket according to the criteria defined by the bucketing method.For example, in the case of state bucketing, a running process instance is assigned to a bucket in which all process instances have the same state as the running process instance. Afterwards, the running process instance is encoded according to the encoding method chosen for the PPM task. The encoded form of the running process instance then qualifies as an input to the most relevant predictive model from those created in the offline stage. Finally, this stage is completed by the predictive model, which generates a prediction for the running process instance according to the pre-specified goal of the PPM task.
2.2. eXplainable Artificial Intelligence
3. Research Problems
4. Experiments
4.1. Experimental Setup
4.1.1. Dimension 1: Data
- Sepsis: This event log refers to the healthcare domain and reports cases of sepsis as a life threatening condition.
- Traffic Fines: This event log is a governmental one extracted from an Italian information system for managing road traffic fines.
- BPIC2017: This event log records instances of loan application processes in a Dutch financial institution.
- whether a patient returned to the emergency room within 28 days of discharge in Sepsis1, and
- whether a patient was admitted to intensive care in Sepsis2.
- Correlations analysis. Correlation coefficient constitutes a measurement used to describe the degree to which two variables are linearly related [23]. It takes values between −1 and 1, with higher values indicating a stronger relationship. The sign represents the direction of the relation. Correlation coefficient is computed to allow the normalised values of features to be investigated. For original event logs, we computed the correlations between categorical attributes before encoding them with Cramer’s V coefficient [24]. The latter measures the correlation between two nominal variables and is based on Pearson’s chi-square.
- Mutual Information (MutInfo). Correlations between features indicate the degree to which those features are dependent. However, correlations are not decisive with respect to the independence of features [23]. This means that if two variables are independent, their correlation coefficient equals zero. However, note that a correlation coefficient of zero does not indicate the independence of two variables [23]. We measured the MutInfo of features with respect to the label. MutInfo is the reduction of uncertainty in a variable after observing the dependent one [23]. This analysis is capable of capturing any kind of dependency, unlike the F-test, which captures only linear dependency [25]. Results take values between 0 and 1, with 0 meaning that the predicted label is independent of the feature and 1 meaning that both are totally dependent.
- Profiling an event log. For each event log, we generated a statistical profile called the pandas profile [26] both before and after preprocessing. Each pandas profile reports on statistical characteristics of each feature within the event log. Such characteristics include, for example, descriptive statistics of the feature, quantile statistics, missing values, most frequent values, and histograms.
4.1.2. Dimension 2: Preprocessing
- Considering that certain encoding techniques turn subcategories of categorical attributes into separate features, we wanted to study how the relationship between the resulting new features is reflected though an explanation.
- We needed to study the ability of explanations in order to reflect differences in the reasoning process of a predictive model when all information is available in one input bucket. We aimed to compare the former situation against others when several predictive models are trained based on different groups of traces that differ in their lengths, and hence in the amount of information provided to a single predictive model.
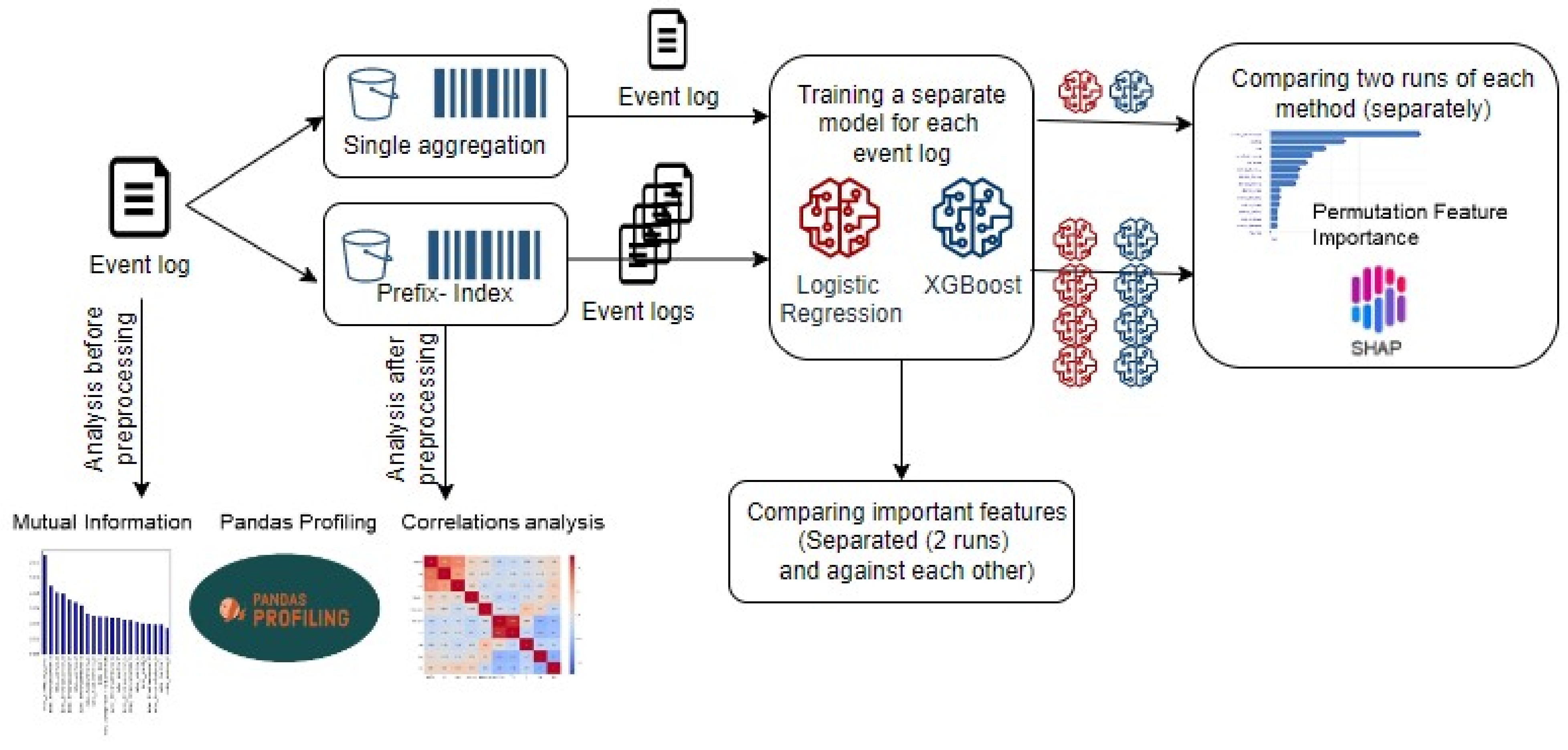
- Our goal was to ensure the coherence of each scenario when a PPM pipeline is supported with explanations on top of it. By coherence, we mean that a scenario employs the best-performing techniques so as not to result in explanations which might be affected by limitations of the underlying choices. For example, we excluded the last-state encoding technique from our experiments, as its working mechanism ends with a scenario in which the predictive model is provided with limited information that is often insufficient for making accurate predictions [2].We chose single-aggregation and prefix-index because they have the least information-lossy techniques (i.e., index encoding) or the most comprehensive techniques to enable the input of various sizes of prefixes to the same predictive model (i.e., single bucketing). Finally, the results reported in [2,12] show that these configurations enable the building of predictive models with good performance. We applied single-aggregation to the five labelled event logs. After applying prefix-index (with a gap of five events) to the same event logs, we obtained thirteen event logs. At this point, we executed our experiments on eighteen event logs in total.
4.1.3. Dimension 3: ML Model
- Both models provide mechanisms to highlight the most important features used in generating their predictions. In LR, the weights of the features may serve this purpose, whereas in XGBoost, a built-in capability can be used to retrieve feature sets and rank them by their importance to the model. Criteria used to rank features include gain, weight, and cover, according to the XGBoost API documentation [27]. Two complementary importance criteria are available through the scikit-learn implementation of XGBoost. These criteria are total_gain and total_cover.
- XGBoost is the best performing model according to the findings reported in [2], and is one of the best performing according to [12]. In order to build on the results and findings of these benchmarks with respect to different prediction tasks in predictive process monitoring, especially outcome predictions, we decided to adopt XGBoost.
4.1.4. Dimension 4: XAI
- 1.
- Conduct data analysis of the event log features using three different techniques, namely, pandas profiling, correlation analysis, and mutual information analysis.
- 2.
- Preprocess the event log using single-aggregation and prefix-index configurations, which in turn produce several versions of the same event log.
- 3.
- For each event log resulting from the previous step,
- Conduct data analysis using the same techniques as in step (1);
- Train and build a separate predictive model using Logistic Regression and XGBoost;
- Query each model for the important features it depends on (intrinsic explainability);
- Compare the most important features of each model over two runs (stability check);
- Compare the most important features of the two models with each other;
- Explain the predictions of the two models based on two XAI methods, i.e., Permutation Importance and SHAP (global explainability). We generated explanations twice and checked the similarity of the results in both runs (stability check).
5. Results
5.1. Data- and Preprocessing-Related Observations
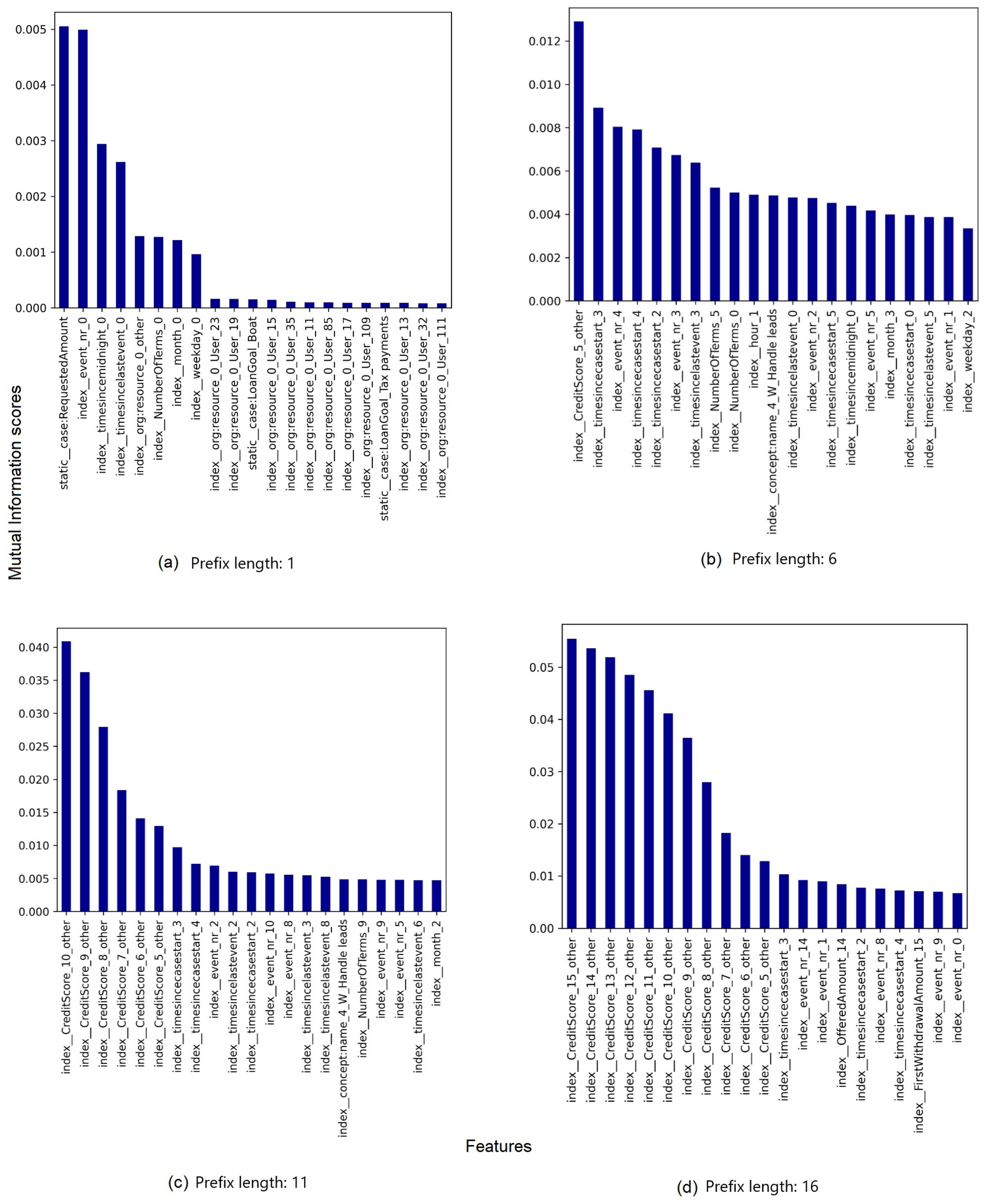
- The effect of the bucketing technique. Aggregation encoding is combined with single bucketing, which buckets all prefixes in the same group. Having many prefixes of the same process instance is more likely to reduce the effect of feature value imbalances. Such imbalances can happen due to the presence of prefixes generated from process instances with longer trace lengths. Moreover, index encoding is combined with prefix bucketing, which reduces the number of process instances fed into each encoding technique. As a result, combining index encoding with prefix-based bucketing has the potential to magnify imbalances in feature values.
- The difference in ’zero’ indication in both encoding techniques. In aggregation encoding, a zero means that the feature did not have any value in the encoded event. In turn, in index encoding, a zero indicates whether the feature has a value in the process instance. Note that after aggregation encoding, a process instance might be represented along many rows, whereas after index encoding, it is represented by exactly one row. As a result, a high number of zeros does not guarantee the absence of a feature value after preprocessing certain events using aggregation encoding. A high number of zeros after index encoding, however, denotes the absence of a value. In summary, a feature might be considered for a predictive model even though it has a large percentage of zeros.
5.2. XAI-Related Observations
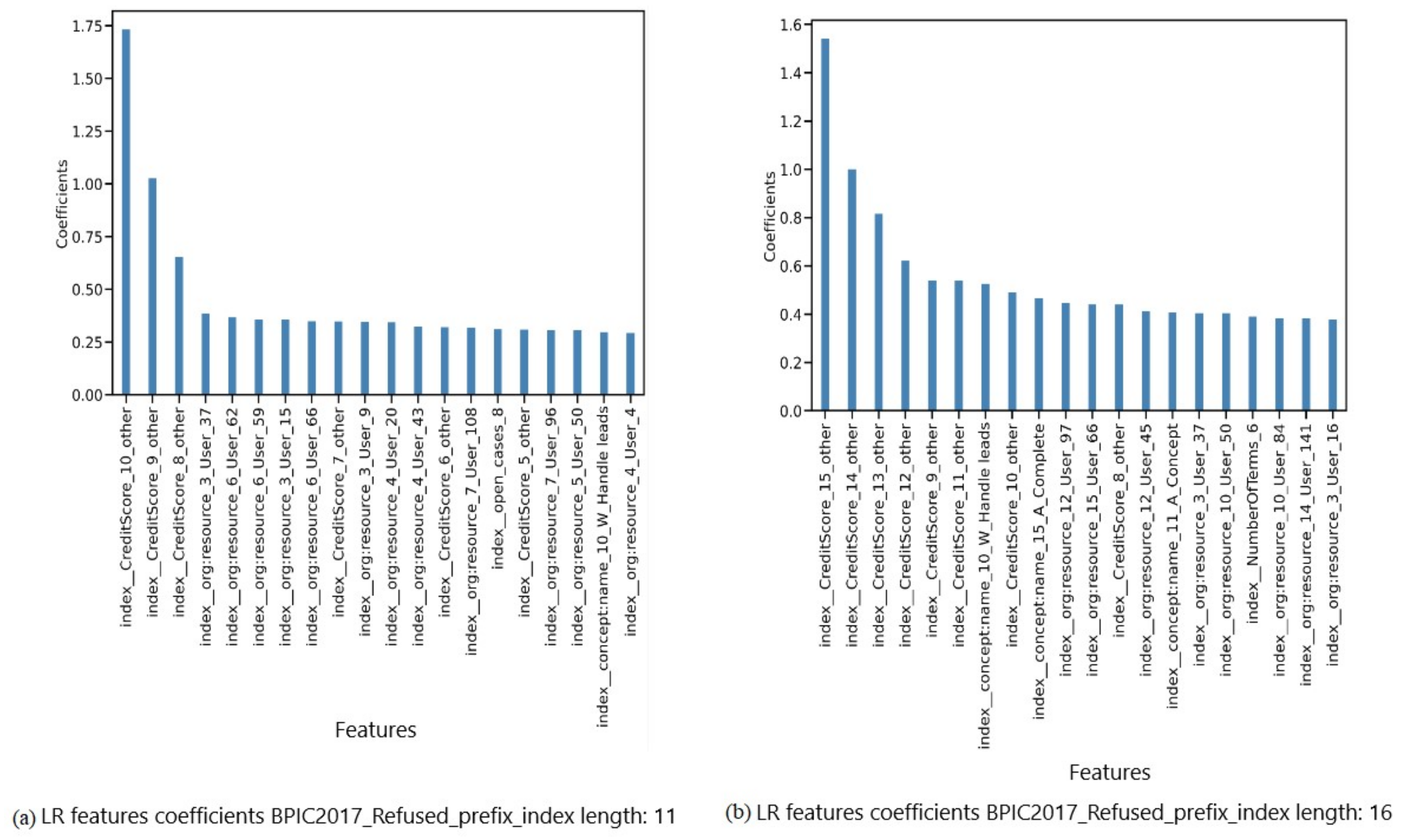
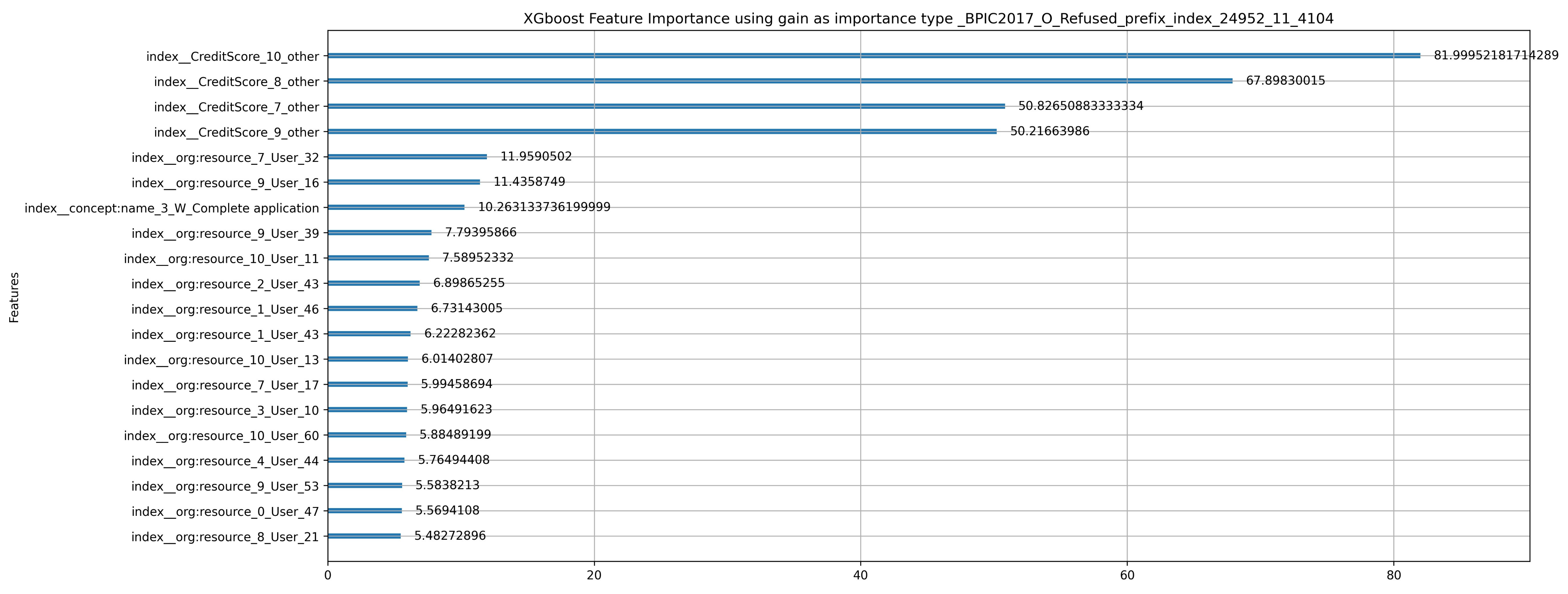
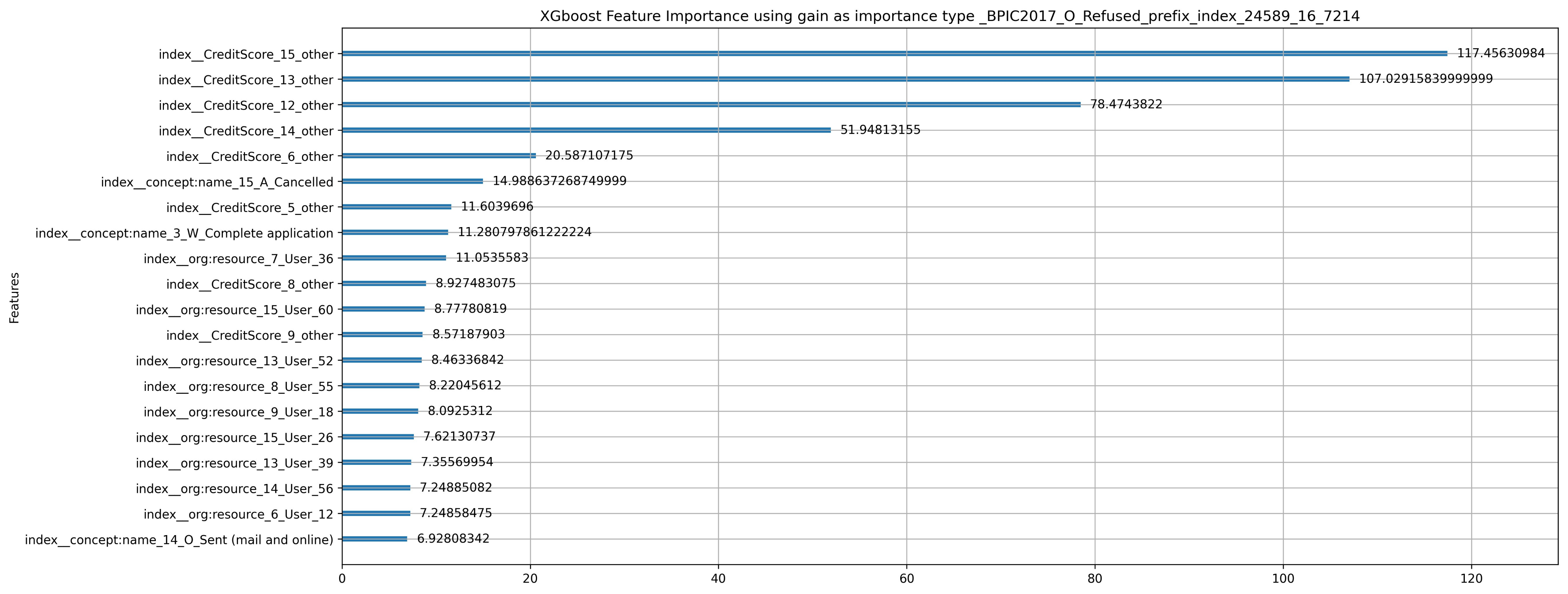
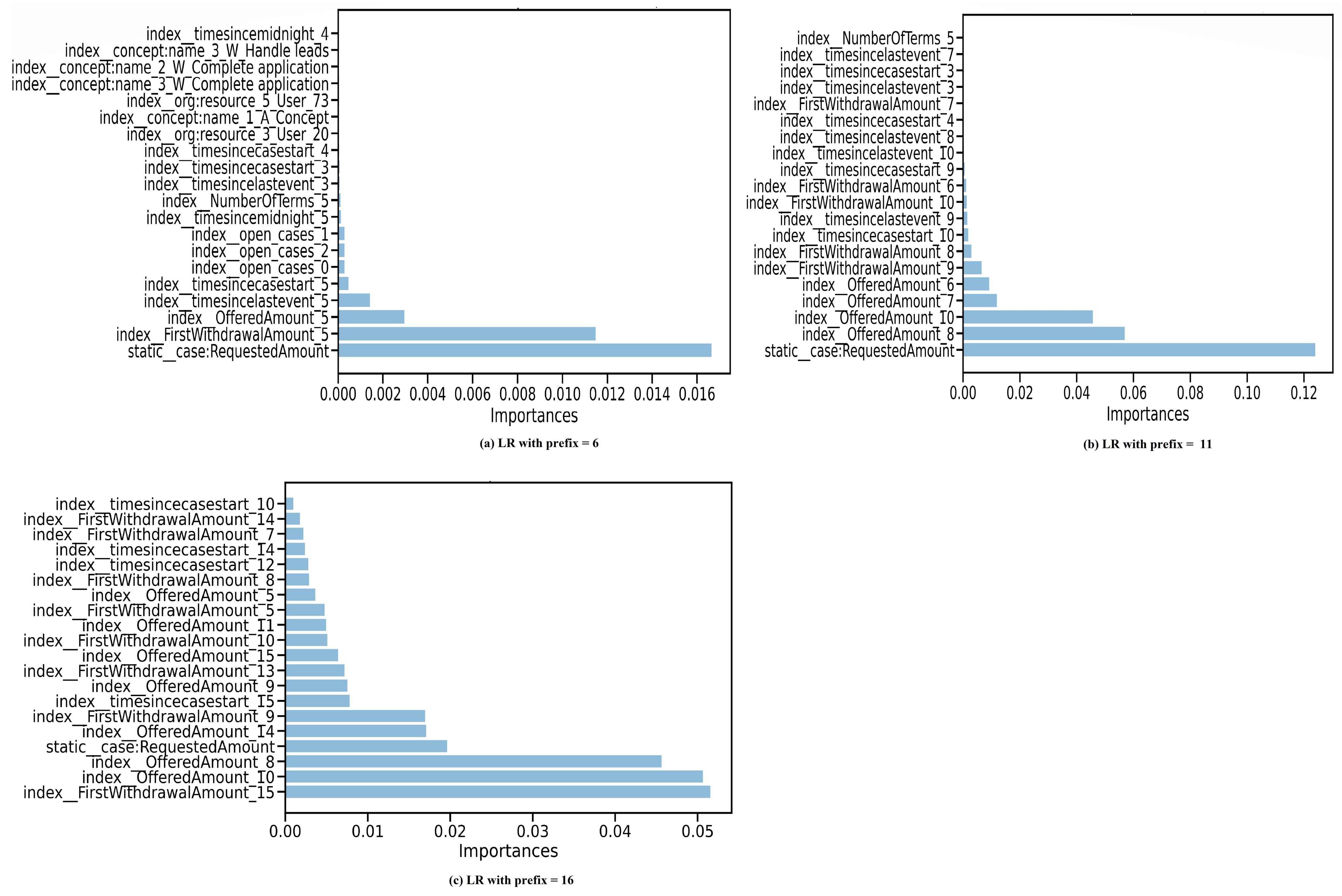
5.2.1. Observations of Model-Specific Explanations
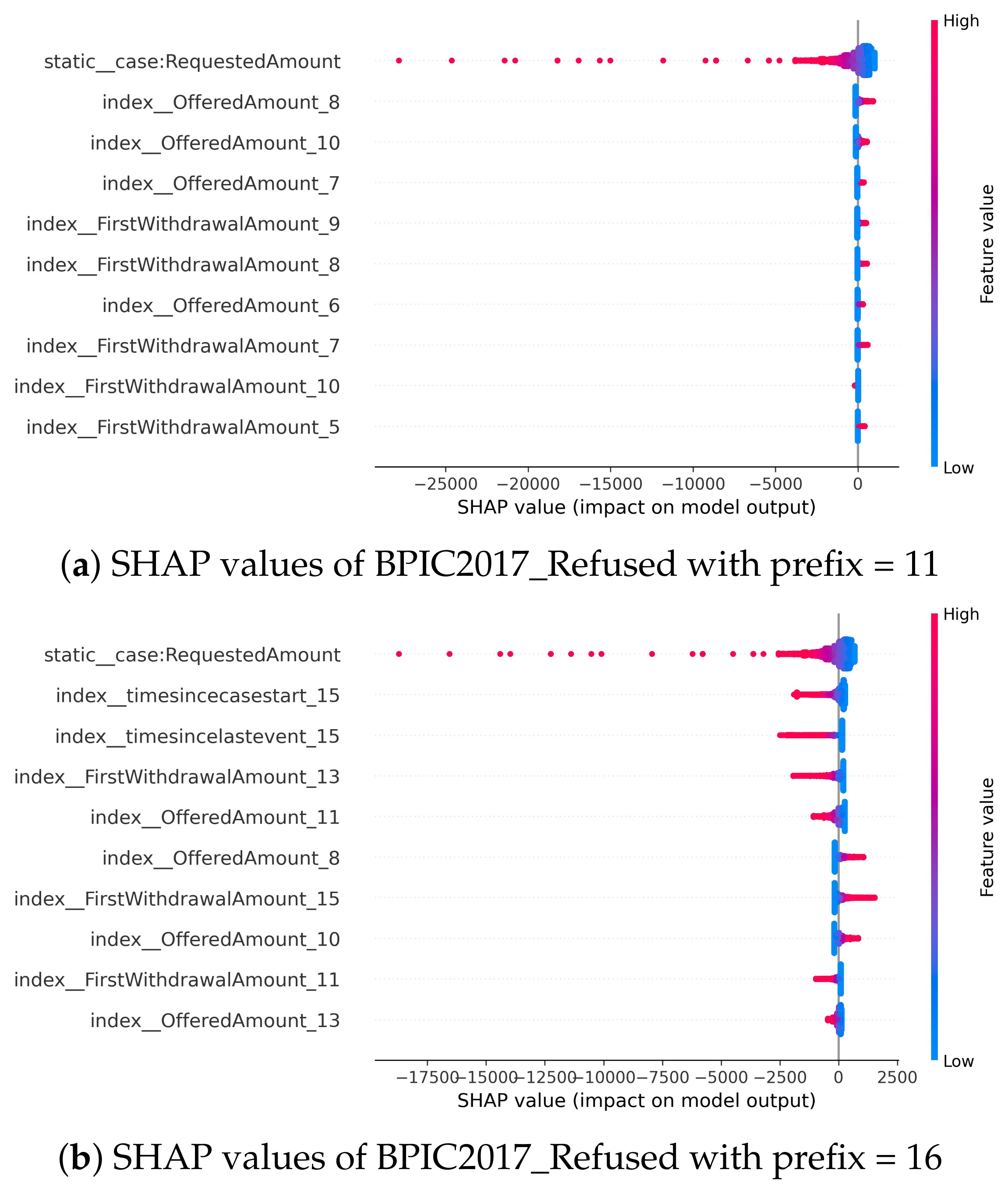
5.2.2. Observations of Global XAI Methods Results
6. Discussion
- Encoding techniques used in the preprocessing phase of PPM have a major impact on both the ability of the predictive model to be decisive as to what the important features are and the selection of certain XAI methods to explain the model’s predictions. Both studied encoding techniques load the event log with a large number of derived features. However, the situation is worse in index-based encoding, as the number of resulting features increases proportionally with the number of dynamic attributes, especially the number of categorical levels of a dynamic categorical attribute. In aggregation-based encoding, the number of resulting features increases in proportion with the number of dynamic attributes.Increased collinearity in the underlying data constitutes another problem, resulting from encoding techniques in varying degrees. The effect of collinearity is observed in index-based preprocessed event logs, and is not totally absent in aggregation-based event logs. This collinearity is reflected in explanations of predictions with respect to process instances from prefix-indexed event logs as the length of a prefix increases.
- The selected bucketing technique has an effect on global XAI methods, especially when accuracy depends on the sufficiency of the process instances to be analysed. PFI is affected by the number of process instances as the average of errors in prediction is calculated over the number of event log process instances.
- Our experiments show the sensitivity of LR to collinearity in several situations. This conclusion can be made, for example, when comparing features ranked highly based on SHAP and PFI to high-importance features based on LR coefficients. In contrast, there is a degree of similarity when comparing the former important feature sets to XGBoost important features sets, especially for explanations of predictions from prefix-index preprocessed event logs. However, when querying the XGBoost model for the set of important features twice, the resulting sets do not match. Such a mismatch indicates inconsistency as a result of the collinearity between features. Note that both predictive models are affected by collinearity. However, in LR the effect is magnified, and prevails in all comparisons in which LR coefficients take part. In most cases, it is observed that dimensionality and collinearity prevent both LR and XGBoost from relying on features that have a dependency relationship with the label.
7. Related Work
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ALE | Accumulated Local Effects |
| BPM | Business Process Management |
| GAM | General Additive Models |
| MutInfo | Mutual Information |
| ML | Machine Learning |
| PDP | Partial Dependence Plot |
| PFI | Permutation Feature Importance |
| PPM | Predictive Process Monitoring |
| RQ | Research Question |
| SHAP | SHapley Additive exPlanations |
| XAI | eXplainable Artificial Intelligence |
| XGBoost | eXtreme Gradient BOOsting |
References
- van der Aalst, W. Process Mining: Data Science in Action; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Teinemaa, I.; Dumas, M.; La Rosa, M.; Maggi, F.M. Outcome-Oriented Predictive Process Monitoring. ACM Trans. Knowl. Discov. Data 2019, 13, 1–57. [Google Scholar] [CrossRef]
- Dumas, M.; La Rosa, M.; Mendling, J.; Reijers, H.A. Fundamentals of Business Process Management; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable. 2020. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 29 June 2022).
- Lundberg, S.; Lee, S. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 4768–4777. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 145–3153. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why Should I Trust You? In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Krishnapuram, B., Shah, M., Smola, A., Aggarwal, C., Shen, D., Rastogi, R., Eds.; ACM: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Apley, D.W.; Zhu, J. Visualizing the effects of predictor variables in black box supervised learning models. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2020, 82, 1059–1086. [Google Scholar] [CrossRef]
- Binder, A.; Montavon, G.; Lapuschkin, S.; Müller, K.R.; Samek, W. Layer-Wise Relevance Propagation for Neural Networks with Local Renormalization Layers. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2016, Barcelona, Spain, 6–9 September 2016; Villa, A.E., Masulli, P., Pons Rivero, A.J., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9887, pp. 63–71. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Model-Agnostic Interpretability of Machine Learning. arXiv, 2016; arXiv:1606.05386. [Google Scholar]
- Verenich, I.; Dumas, M.; La Rosa, M.; Maggi, F.M.; Teinemaa, I. Survey and Cross-benchmark Comparison of Remaining Time Prediction Methods in Business Process Monitoring. ACM Trans. Intell. Syst. Technol. 2019, 10, 34. [Google Scholar] [CrossRef]
- Di Francescomarino, C.; Dumas, M.; Maggi, F.M.; Teinemaa, I. Clustering-Based Predictive Process Monitoring. IEEE Trans. Serv. Comput. 2019, 12, 896–909. [Google Scholar] [CrossRef]
- Zhou, J.; Gandomi, A.H.; Chen, F.; Holzinger, A. Evaluating the Quality of Machine Learning Explanations: A Survey on Methods and Metrics. Electronics 2021, 10, 593. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kortz, M.; Budish, R.; Bavitz, C.; Gershman, S.; O’Brien, D.; Scott, K.; Schieber, S.; Waldo, J.; Weinberger, D.; et al. Accountability of AI Under the Law: The Role of Explanation. arXiv, 2017; arXiv:1711.01134. [Google Scholar] [CrossRef]
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Mohseni, S.; Zarei, N.; Ragan, E.D. A Multidisciplinary Survey and Framework for Design and Evaluation of Explainable AI Systems. ACM Trans. Interact. Intell. Syst. 2021, 11, 1–45. [Google Scholar] [CrossRef]
- Belle, V.; Papantonis, I. Principles and Practice of Explainable Machine Learning. Front. Big Data 2021. [Google Scholar] [CrossRef] [PubMed]
- Lipton, Z.C. The Mythos of Model Interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Teinemaa, I. Outcome-Oriented Predictive Process Monitoring Benchmark-github. 2019. Available online: https://github.com/irhete/predictive-monitoring-benchmark (accessed on 19 February 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- 4TU Centre for Research Data. Process Mining Datasets. 2021. Available online: https://data.4tu.nl/Eindhoven_University_of_Technology (accessed on 19 February 2022).
- Murphy, K.P. Machine Learning: A Probabilistic Perspective (Adaptive Computation and Machine Learning); MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Cremér, H. Mathematical Methods of Statistics, 19 Printing and 1st pbk. Printing ed.; Princeton Landmarks in Mathematics and Physics; Princeton University: Princeton, NJ, USA, 1999. [Google Scholar]
- Scikit-Learn Developers. Comparison between F-Test and Mutual Information. 2019. Available online: https://scikit-learn.org/stable/auto_examples/feature_selection/plot_f_test_vs_mi.html (accessed on 19 February 2022).
- Brugman, S. Pandas Profiling. 2021. Available online: https://github.com/pandas-profiling/pandas-profiling (accessed on 19 February 2022).
- XGBoost Developers. XGBoost: Release 1.0.2. 2020. Available online: https://xgboost.readthedocs.io/en/release_1.0.0/python/index.html (accessed on 29 June 2022).
- Elkhawaga, G.; Abuelkheir, M.; Reichert, M. XAI in the Context of Predictive Process Monitoring: An Empirical Analysis Framework. Algorithms 2022, 15, 199. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Di Francescomarino, C.; Ghidini, C.; Maggi, F.M.; Milani, F. Predictive Process Monitoring Methods: Which One Suits Me Best? In Proceedings of the Business Process Management; Weske, M., Montali, M., Weber, I., vom Brocke, J., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 462–479. [Google Scholar]
- Márquez-Chamorro, A.E.; Resinas, M.; Ruiz-Cortés, A. Predictive Monitoring of Business Processes: A Survey. IEEE Trans. Serv. Comput. 2018, 11, 962–977. [Google Scholar] [CrossRef]
- Brunk, J.; Stierle, M.; Papke, L.; Revoredo, K.; Matzner, M.; Becker, J. Cause vs. effect in context-sensitive prediction of business process instances. Inf. Syst. 2021, 95, 101635. [Google Scholar] [CrossRef]
- Verenich, I.; Dumas, M.; La Rosa, M.; Nguyen, H. Predicting process performance: A white-box approach based on process models. J. Softw. Evol. Process 2019, 31, e2170. [Google Scholar] [CrossRef]
- Pasquadibisceglie, V.; Castellano, G.; Appice, A.; Malerba, D. FOX: A neuro-Fuzzy model for process Outcome prediction and eXplanation. In Proceedings of the 2021 3rd International Conference on Process Mining (ICPM), Eindhoven, The Netherlands, 31 October–4 November 2021; pp. 112–119. [Google Scholar] [CrossRef]
- Weinzierl, S.; Zilker, S.; Brunk, J.; Revoredo, K.; Matzner, M.; Becker, J. XNAP: Making LSTM-Based Next Activity Predictions Explainable by Using LRP. In Proceedings of the Business Process Management Workshops; Del Río Ortega, A., Leopold, H., Santoro, F.M., Eds.; Lecture Notes in Business Information Processing. Springer International Publishing: Cham, Switzerland, 2020; Volume 397, pp. 129–141. [Google Scholar] [CrossRef]
- Galanti, R.; Coma-Puig, B.; de Leoni, M.; Carmona, J.; Navarin, N. Explainable Predictive Process Monitoring. In Proceedings of the 2020 2nd International Conference on Process Mining (ICPM), Padua, Italy, 5–8 October 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Rizzi, W.; Di Francescomarino, C.; Maggi, F.M. Explainability in Predictive Process Monitoring: When Understanding Helps Improving. In Business Process Management Forum; Fahland, D., Ghidini, C., Becker, J., Dumas, M., Eds.; Lecture Notes in Business Information Processing; Springer International Publishing: Cham, Switzerland, 2020; Volume 392, pp. 141–158. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 |
| Case_Id | Applicant Id | Act_Create_app | Act_valid_app | Act_decide_app | Act_close_app | Res_John | Res_Benn | Res_Jill | Sum_monthly_cost | Requested_amount | Granted_amount |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A150 | C1820 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1281 | 38,000 | 30,000 |
| A150 | C1820 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1512 | 38,000 | 30,000 |
| A150 | C1820 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1854 | 38,000 | 30,000 |
| A150 | C1820 | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 3067 | 38,000 | 30,000 |
| Case_Id | Applicant Id | Act_1 | Act_2 | Act_3 | Act_4 | Res_1 | Res_2 | Res_3 | Monthly_cost_1 | Monthly_cost_2 | Monthly_cost_3 | Monthly_cost_4 | Requested_amount | Granted_amount |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A150 | C1820 | Create_app | valid_app | decide_app | close_app | John | Benn | Jill | 1281 | 231 | 342 | 1213 | 38,000 | 30,000 |
| Event log | #Traces | Short. Trace len. | Avg. Trace len. | Long. Trace len. | Max prfx len. | #Case Variants | %pos Class | #Event Class | # Static Col | # Dynamic Cols | #Cat Cols | #num Cols | #Cat Levels Static Cols | #Cat Levels Dynamic Cols |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sepsis1 | 776 | 5 | 14 | 185 | 20 | 703 | 0.0026 | 14 | 24 | 13 | 28 | 14 | 76 | 38 |
| Sepsis2 | 776 | 4 | 13 | 60 | 13 | 650 | 0.14 | 14 | 24 | 13 | 28 | 14 | 76 | 39 |
| Traffic_fines | 129615 | 2 | 4 | 20 | 10 | 185 | 0.455 | 10 | 4 | 14 | 13 | 11 | 54 | 173 |
| BPIC2017_Accepted | 31413 | 10 | 35 | 180 | 20 | 2087 | 0.41 | 26 | 3 | 20 | 12 | 13 | 6 | 682 |
| BPIC2017_Refused | 31413 | 10 | 35 | 180 | 20 | 2087 | 0.12 | 26 | 3 | 20 | 12 | 13 | 6 | 682 |
| Event Log | Training Bucket Size | Testing Bucket Size | # Features |
|---|---|---|---|
| Sepsis1 | 8974 | 2297 | 175 |
| Sepsis2 | 7222 | 1848 | 174 |
| Traffic_Fines | 362,094 | 88,530 | 254 |
| BPIC2017_Accepted | 494,892 | 124,815 | 722 |
| BPIC2017_Refused | 494,892 | 124,815 | 722 |
| Event Log | Prefix Length | Training Bucket Size | Testing Bucket Size | # Features |
|---|---|---|---|---|
| Sepsis1 | 1 | 620 | 156 | 99 |
| 6 | 618 | 156 | 243 | |
| 11 | 531 | 140 | 425 | |
| 16 | 226 | 158 | 543 | |
| Sepsis2 | 1 | 620 | 156 | 99 |
| 6 | 614 | 154 | 240 | |
| 11 | 468 | 124 | 408 | |
| Traffic_Fines | 1 | 103,652 | 25,923 | 201 |
| 6 | 8736 | 1965 | 901 | |
| BPIC2017_Refused | 1 | 25,130 | 6283 | 120 |
| 6 | 25,118 | 6283 | 1143 | |
| 11 | 24,952 | 6283 | 4104 | |
| 16 | 24,589 | 6261 | 7214 |
| Event Log | Preprocessing | XGboost | Logistic Regression |
|---|---|---|---|
| Sepsis1 | single_agg | 0.33427 | 0.57124 |
| prefix_index (avg. AUC of len 1–16, gap = 5) | 0.4292 | 0.52599 | |
| Sepsis2 | single_agg | 0.91374 | 0.88567 |
| prefix_index (avg. AUC of len 1–11, gap = 5) | 0.81379 | 0.46253 | |
| Traffic_fines | single_agg | 0.73918 | 0.7949 |
| prefix_index (avg. AUC of len 1 & 6, gap = 5) | 0.6515 | 0.67804 | |
| BPIC2017_Accepted | single_agg | 0.86429 | 0.8244 |
| BPIC2017_Refused | single_agg | 0.68328 | 0.70706 |
| prefix_index (avg. AUC of len 1–16, gap = 5) | 0.7556 | 0.7677 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elkhawaga, G.; Abu-Elkheir, M.; Reichert, M. Explainability of Predictive Process Monitoring Results: Can You See My Data Issues? Appl. Sci. 2022, 12, 8192. https://doi.org/10.3390/app12168192
Elkhawaga G, Abu-Elkheir M, Reichert M. Explainability of Predictive Process Monitoring Results: Can You See My Data Issues? Applied Sciences. 2022; 12(16):8192. https://doi.org/10.3390/app12168192
Chicago/Turabian StyleElkhawaga, Ghada, Mervat Abu-Elkheir, and Manfred Reichert. 2022. "Explainability of Predictive Process Monitoring Results: Can You See My Data Issues?" Applied Sciences 12, no. 16: 8192. https://doi.org/10.3390/app12168192