
Enhancements to Neural Language Model for Generating System Configuration Code: A Study with Maven Dependency


Abstract
:1. Introduction
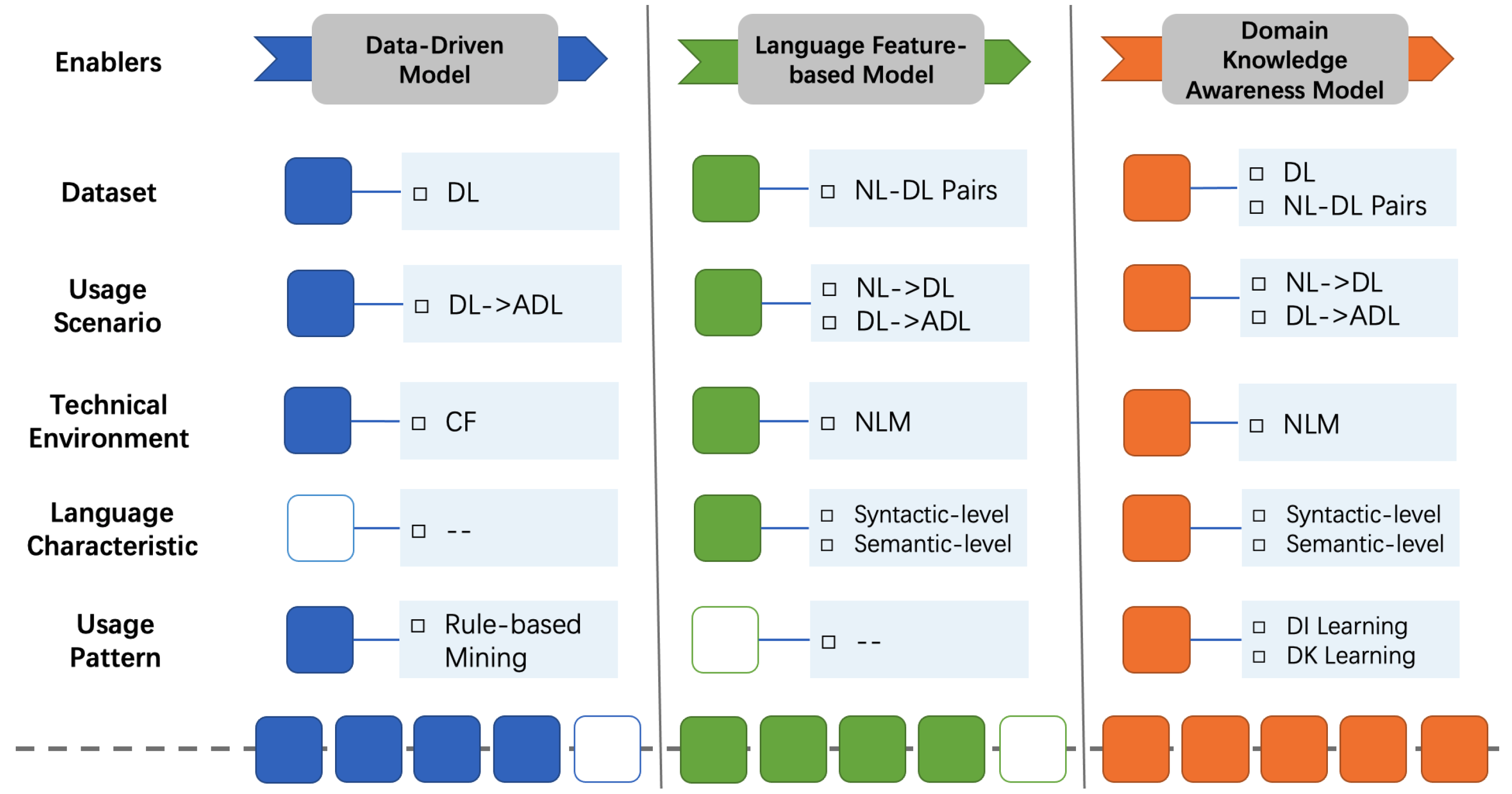
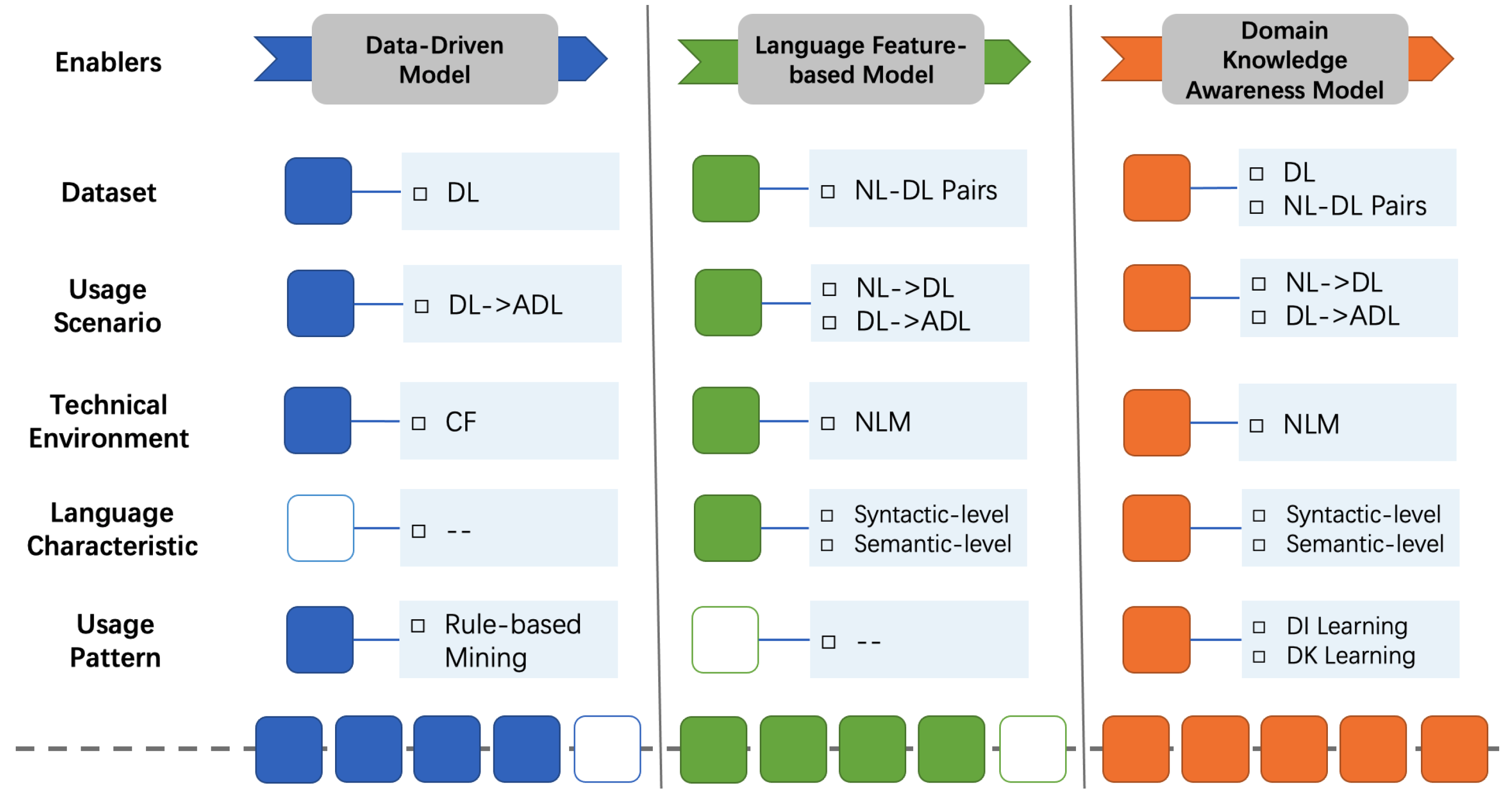
- We present an enhancement path to clarify the ongoing dependency code generation at different levels, introducing five enablers that drive the model design, including data sources, usage scenarios, technical environments, language characteristics, and usage patterns.
- We propose EMGSCC (Enhanced Model for Generating System Configuration Code), a concrete generation model that mirrors the language feature introduction and domain knowledge integration simultaneously. EMGSCC learns from the dependency code from different open-source Maven projects, then customizes a neural language model with special consideration for the order-independent features and domain information to generate practical accompanying items.
- We evaluate EMGSCC on the DDDI dataset to generate accompanying dependency libraries. By comparing with the baseline model and ablation experiments, EMGSCC demonstrates its effectiveness through improvements varying from 1% to 8% on all metrics.
2. Research Contexts
2.1. On the Challenges and Responses of System Configuration Code Generation
2.2. Enhancement Path for Generating Dependency Code
3. Enabling the Enhancements of Language Features and Domain Knowledge
3.1. EMGSCC: Enhanced Model for Generating System Configuration Code
3.2. Integrating Domain Information
3.3. Dealing with an Unordered Dependency Library Set
3.3.1. Processing Input Dependency Library Set
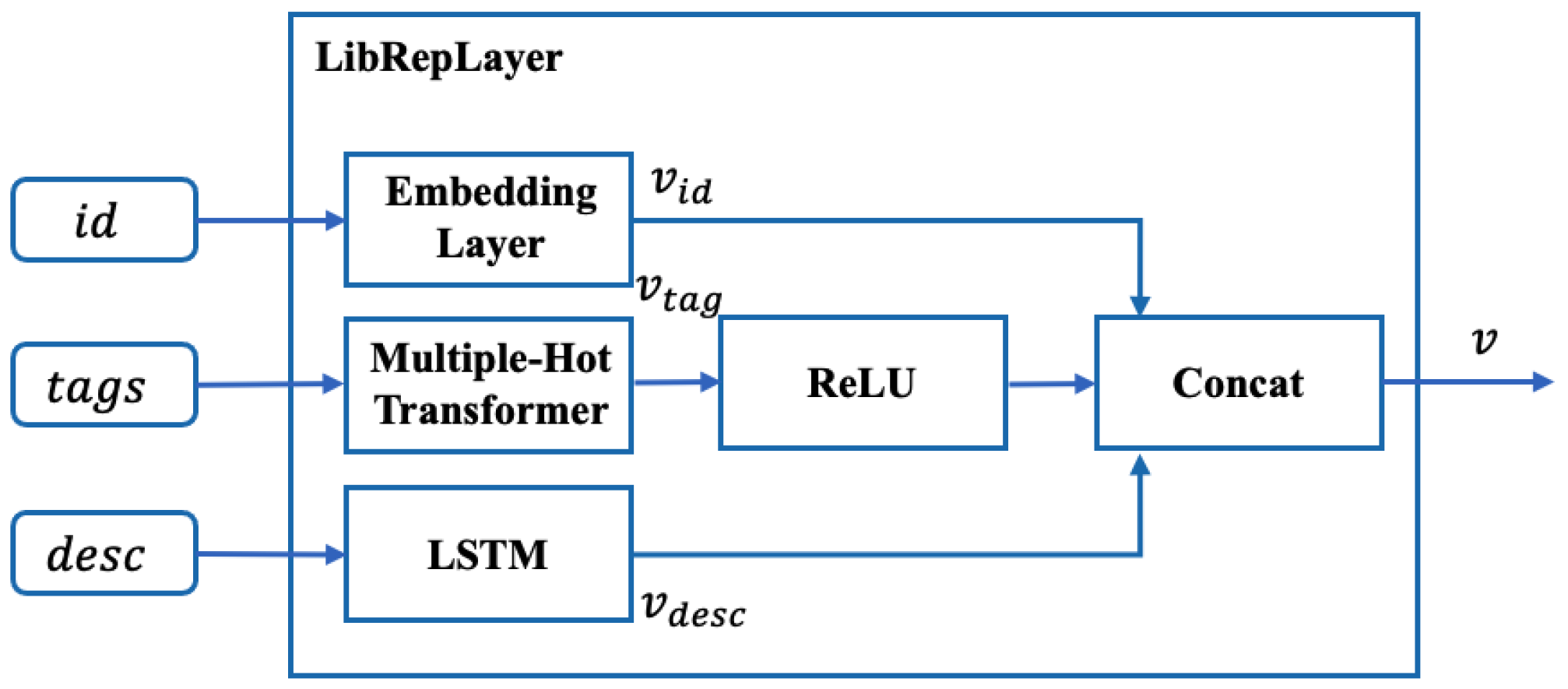
- For each imported dependency library of the project, a fixed-dimensional dependency representation vector is obtained through the LibRepLayer with the identifier, tags, and description as the input.
- We employ an LSTM to merely calculate the recurrent states:
- After obtaining the input representation vectors , …, , each of them is considered as a memory vector; the attention weight of each dependency library can be computed by:where , , and are weight parameters of linear layers.
- With attention weights, we can obtain the context vector . By concatenating the context vectors and hidden state recurrently, the last hidden state is the target representation that is permutation-invariant to the inputs.
3.3.2. Processing Output Dependency Library Set
4. Experiments and Results
4.1. Dataset and Baselines Description
- Filtering: Similar to the previous model LibRec [4], we filtered out Maven projects with less than ten total dependency libraries, resulting in 8282 Maven projects that used a total of 4785 different libraries.
- Splitting Inputs and Outputs: For each Maven project, half of the dependency libraries were randomly selected to be the employed items of the current project, and the remaining half were the accompanying items.
- Description preprocessing: In virtue of the Stanford Core NLP tool (Stanford Core NLP: https://stanfordnlp.github.io/CoreNLP/, accessed on 8 June 2022), we finally obtained a ready-to-use vocabulary through lowercasing, filtering, lemmatization, word segmentation, etc.
- Tokenization: We tokenized the participants in EMGSCC. As for dependency libraries, each library was treated as a token; as for domain tags and functional descriptions, each unique tag and each description word were treated as a token separately. With incrementally generated dictionaries, we represented the tokens with numerical ids.
4.2. Metrics
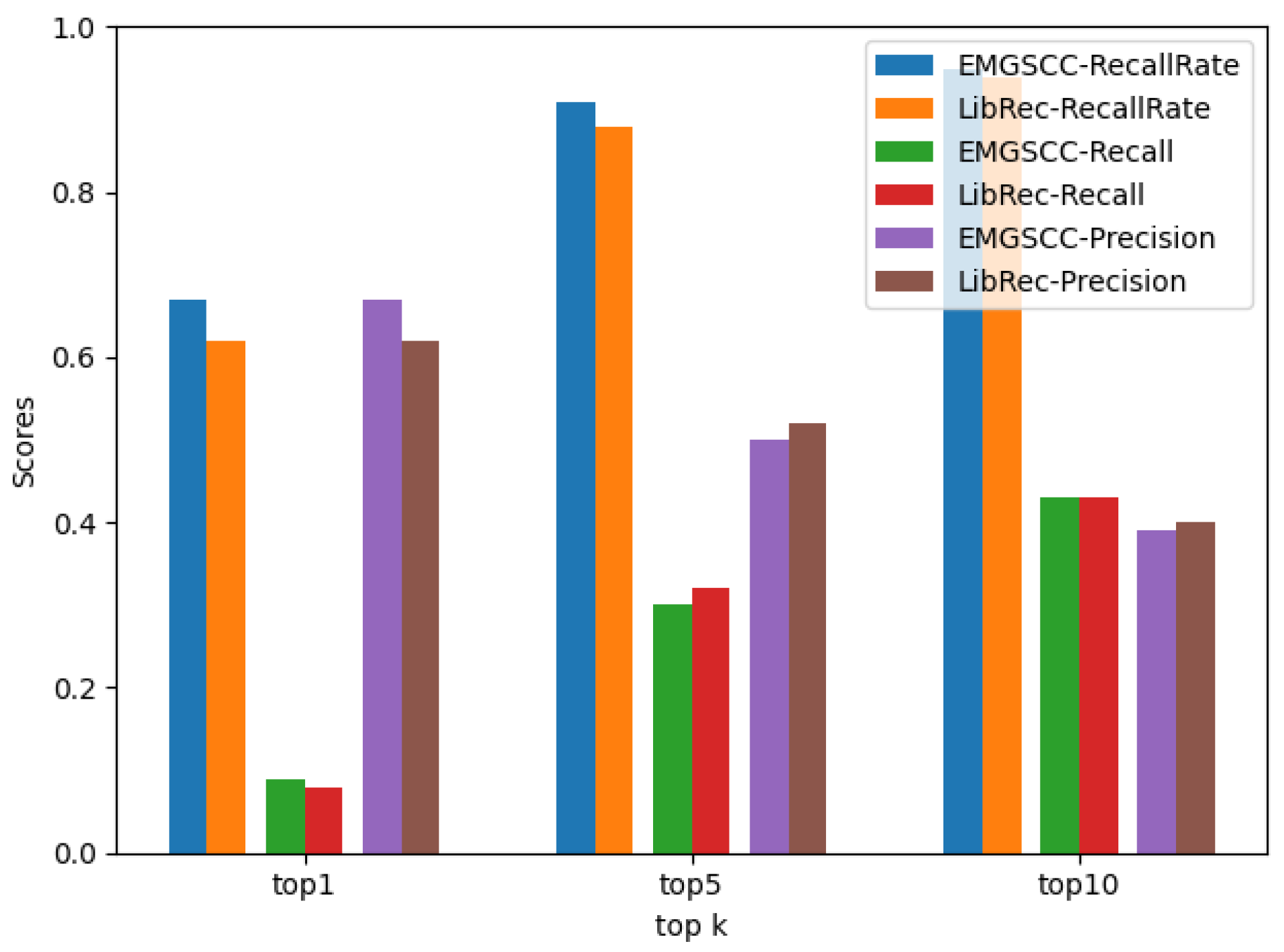
4.3. ADL Prediction Accuracy
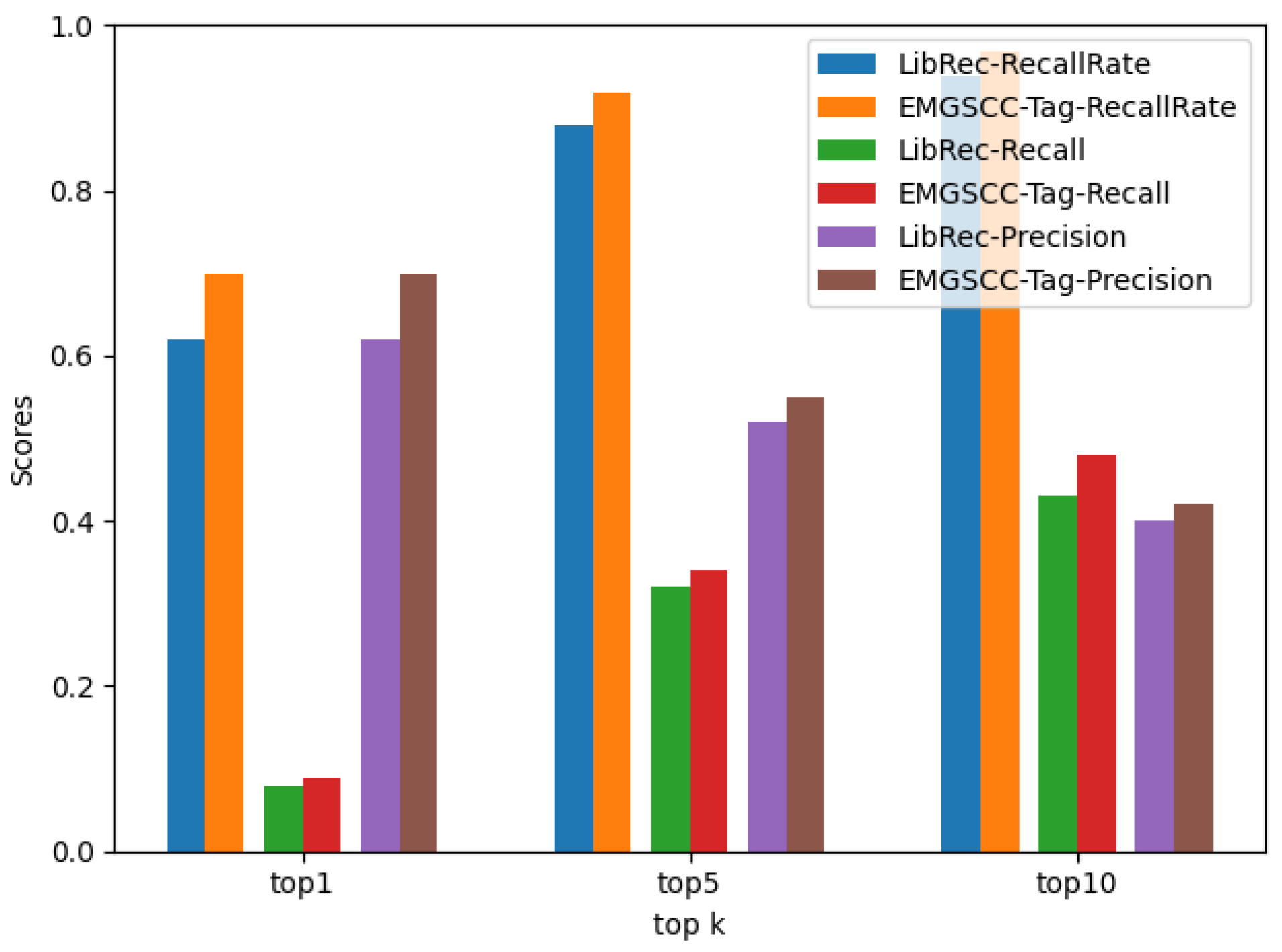
- RQ1: Compared with the baseline model LibRec [4], how accurate is EMGSCC in predicting the accompanying dependency library?
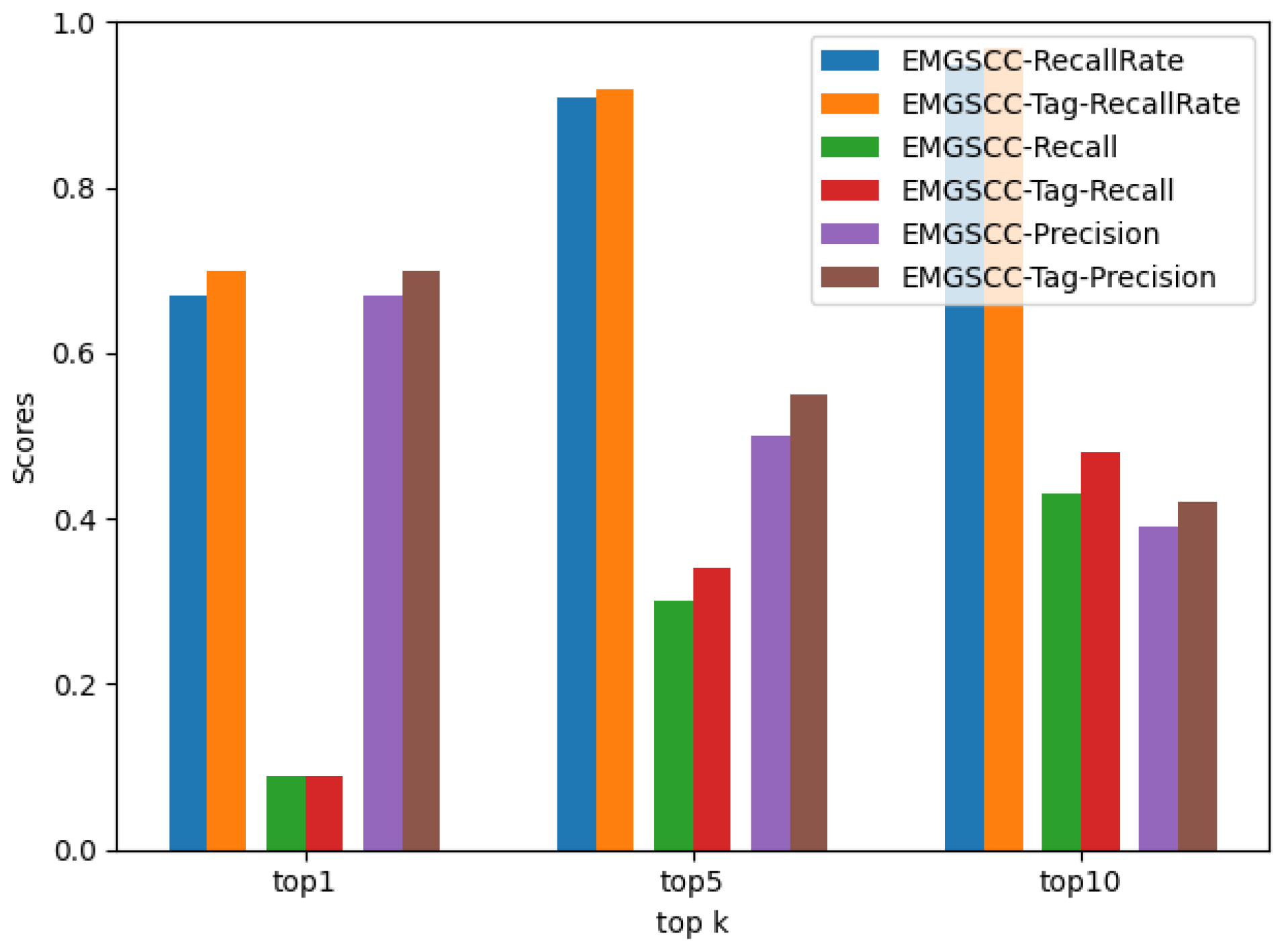
4.4. Contribution of Domain Tags and Functional Description
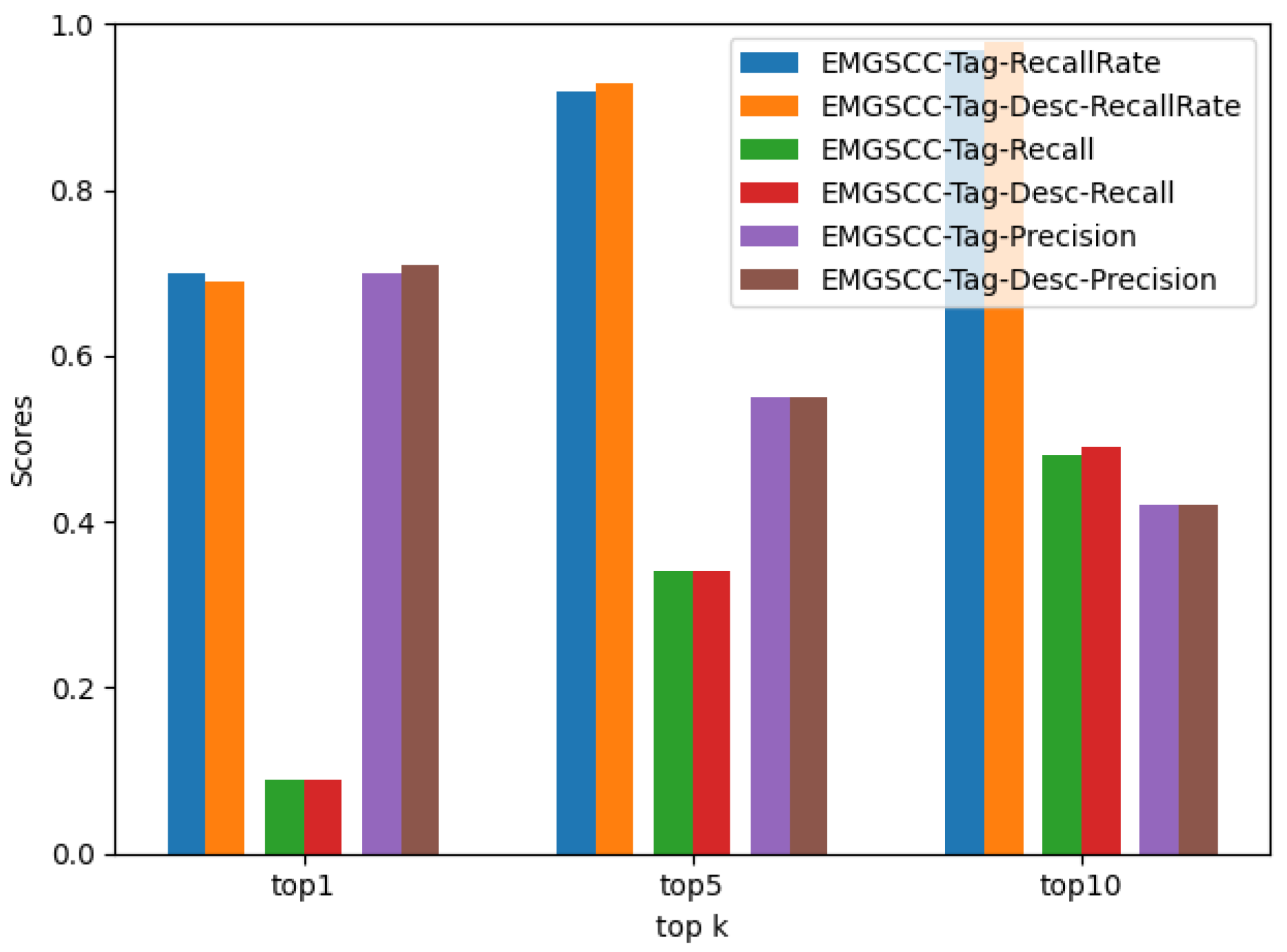
- RQ2: Compared with the baseline model LibRec and the basic EMGSCC, how do domain tags contribute to predicting the accompanying dependency library?
- RQ3: Compared with the EMGSCC with domain tags, how does the functional description contribute to predicting the accompanying dependency library?
5. Discussion
5.1. Why Does EMGSCC Work Well?
5.2. Threats to Validity
6. Related Work
6.1. Dependency Recommendation and Generation
6.2. Neural Language Model
6.3. The Importance of Contexts
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| OTS components | Off-The-Shelf components |
| DSL | Domain-Specific Language |
| SCC | System Configuration Code |
| NLSCG | Natural Language-based Source Code Generation |
| EMGSCC | Enhanced Model for Generating System Configuration Code |
| DDDI | Dependency Dataset with Domain Information |
| API | Application Programming Interfaces |
| DC usage pattern | Dependency Code usage pattern |
| DL | Dependency Libraries |
| NL | Natural Language |
| ADL | Accompanying Dependency Libraries |
| CF | Collaborative Filtering |
| NLM | Neural Language Model |
| DI | Domain Information |
| DK | Domain Knowledge |
References
- Bass, L.; Weber, I.; Zhu, L. DevOps: A Software Architect’s Perspective; Addison-Wesley Professional: Boston, MA, USA, 2015. [Google Scholar]
- Nguyen, P.T.; Di Rocco, J.; Rubei, R.; Di Sipio, C.; Di Ruscio, D. DeepLib: Machine translation techniques to recommend upgrades for third-party libraries. Expert Syst. Appl. 2022, 202, 117267. [Google Scholar] [CrossRef]
- Allamanis, M.; Barr, E.T.; Devanbu, P.; Sutton, C. A survey of machine learning for big code and naturalness. ACM Comput. Surv. (CSUR) 2018, 51, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Thung, F.; Lo, D.; Lawall, J. Automated library recommendation. In Proceedings of the 2013 20th Working Conference on Reverse Engineering (WCRE), Koblenz, Germany, 14–17 October 2013; pp. 182–191. [Google Scholar]
- Ouni, A.; Kula, R.G.; Kessentini, M.; Ishio, T.; German, D.M.; Inoue, K. Search-based software library recommendation using multi-objective optimization. Inf. Softw. Technol. 2017, 83, 55–75. [Google Scholar] [CrossRef]
- Sun, Z.; Liu, Y.; Cheng, Z.; Yang, C.; Che, P. Req2Lib: A Semantic Neural Model for Software Library Recommendation. In Proceedings of the 2020 IEEE 27th International Conference on Software Analysis, Evolution and Reengineering (SANER), London, ON, Canada, 18–21 February 2020; pp. 542–546. [Google Scholar]
- Nguyen, P.T.; Di Rocco, J.; Rubei, R.; Di Sipio, C.; Di Ruscio, D. Recommending Third-Party Library Updates with LSTM Neural Networks 2021. Available online: http://ceur-ws.org/Vol-2947/paper7.pdf (accessed on 2 June 2022).
- Yang, C.; Liu, Y.; Yin, C. Recent Advances in Intelligent Source Code Generation: A Survey on Natural Language Based Studies. Entropy 2021, 23, 1174. [Google Scholar] [CrossRef] [PubMed]
- Houidi, Z.B.; Rossi, D. Neural language models for network configuration: Opportunities and reality check. arXiv 2022, arXiv:2205.01398. [Google Scholar]
- Benelallam, A.; Harrand, N.; Soto-Valero, C.; Baudry, B.; Barais, O. The maven dependency graph: A temporal graph-based representation of maven central. In Proceedings of the 2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR), Montreal, QC, Canada, 25–31 May 2019; pp. 344–348. [Google Scholar]
- Soto-Valero, C.; Harrand, N.; Monperrus, M.; Baudry, B. A comprehensive study of bloated dependencies in the maven ecosystem. Empir. Softw. Eng. 2021, 26, 45. [Google Scholar] [CrossRef]
- Apache Maven Pom Introduction. Available online: https://maven.apache.org/guides/introduction/introduction-to-the-pom.html (accessed on 5 July 2022).
- Blech, E.; Grishchenko, A.; Kniazkov, I.; Liang, G.; Serebrennikov, O.; Tatarnikov, A.; Volkhontseva, P.; Yakimets, K. Patternika: A Pattern-Mining-Based Tool For Automatic Library Migration. In Proceedings of the 2021 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), Wuhan, China, 25–28 October 2021; pp. 333–338. [Google Scholar]
- Thung, F.; Wang, S.; Lo, D.; Lawall, J. Automatic recommendation of API methods from feature requests. In Proceedings of the 2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE), Silicon Valley, CA, USA, 11–15 November 2013; pp. 290–300. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008.
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling laws for neural language models. arXiv 2020, arXiv:2001.08361. [Google Scholar]
- Yin, P.; Neubig, G. A syntactic neural model for general-purpose code generation. arXiv 2017, arXiv:1704.01696. [Google Scholar]
- Rabinovich, M.; Stern, M.; Klein, D. Abstract syntax networks for code generation and semantic parsing. arXiv 2017, arXiv:1704.07535. [Google Scholar]
- Zhong, H.; Xie, T.; Zhang, L.; Pei, J.; Mei, H. MAPO: Mining and recommending API usage patterns. In European Conference on Object-Oriented Programming; Springer: Berlin/Heidelberg, Germany, 2009; pp. 318–343. [Google Scholar]
- Vinyals, O.; Bengio, S.; Kudlur, M. Order Matters: Sequence to sequence for sets. In Proceedings of the 4th International Conference on Learning Representations (ICLR 2016), San Juan, Puerto Rico, 2–4 May 2016; Conference Track Proceedings. Bengio, Y., LeCun, Y., Eds.; OpenReview.net: Amherst, MA, USA, 2016. [Google Scholar]
- Zhang, M.L.; Zhou, Z.H. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2013, 26, 1819–1837. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Sorower, M.S. A Literature Survey on Algorithms for Multi-Label Learning; Oregon State University: Corvallis, OR, USA, 2010; Volume 18, pp. 1–25. [Google Scholar]
- Godbole, S.; Sarawagi, S. Discriminative methods for multi-labeled classification. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2004; pp. 22–30. [Google Scholar]
- Katsuragawa, D.; Ihara, A.; Kula, R.G.; Matsumoto, K. Maintaining Third-Party Libraries through Domain-Specific Category Recommendations. In Proceedings of the 2018 IEEE/ACM 1st International Workshop on Software Health (SoHeal), Gothenburg, Sweden, 27 May–3 June 2018. [Google Scholar]
- He, H.; He, R.; Gu, H.; Zhou, M. A large-scale empirical study on Java library migrations: Prevalence, trends, and rationales. In Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Athens, Greece, 20 August 2021; pp. 478–490. [Google Scholar]
- Rubei, R.; Di Ruscio, D.; Di Sipio, C.; Di Rocco, J.; Nguyen, P.T. Providing Upgrade Plans for Third-party Libraries: A Recommender System using Migration Graphs. arXiv 2022, arXiv:2201.08201. [Google Scholar] [CrossRef]
- He, H.; Xu, Y.; Ma, Y.; Xu, Y.; Liang, G.; Zhou, M. A multi-metric ranking approach for library migration recommendations. In Proceedings of the 2021 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), Honolulu, HI, USA, 9–12 March 2021; pp. 72–83. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P. A neural probabilistic language model. In Advances in Neural Information Processing Systems 13; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Interspeech 2010, Makuhari, Japan, 26–30 September 2010; Volume 2, pp. 1045–1048. [Google Scholar]
- Sundermeyer, M.; Schlüter, R.; Ney, H. LSTM neural networks for language modeling. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Balog, M.; Gaunt, A.L.; Brockschmidt, M.; Nowozin, S.; Tarlow, D. Deepcoder: Learning to write programs. arXiv 2016, arXiv:1611.01989. [Google Scholar]
- Ling, W.; Grefenstette, E.; Hermann, K.M.; Kočiskỳ, T.; Senior, A.; Wang, F.; Blunsom, P. Latent predictor networks for code generation. arXiv 2016, arXiv:1603.06744. [Google Scholar]
- Chen, Q.; Zhou, M. A neural framework for retrieval and summarization of source code. In Proceedings of the 2018 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE), Montpellier, France, 3–7 September 2018; pp. 826–831. [Google Scholar]
- Lee, D.; Yoon, J.; Song, J.; Lee, S.; Yoon, S. One-shot learning for text-to-sql generation. arXiv 2019, arXiv:1905.11499. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Krishnamurthy, J.; Dasigi, P.; Gardner, M. Neural semantic parsing with type constraints for semi-structured tables. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 1516–1526. [Google Scholar]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. arXiv 2015, arXiv:1503.00075. [Google Scholar]
- Stylianou, N.; Vlahavas, I. ET: Entity-transformers. coreference augmented neural language model for richer mention representations via entity-transformer blocks. arXiv 2020, arXiv:2011.05431. [Google Scholar]
- Nguyen, A.T.; Nguyen, T.D.; Phan, H.D.; Nguyen, T.N. A deep neural network language model with contexts for source code. In Proceedings of the 2018 IEEE 25th International Conference on Software Analysis, Evolution and Reengineering (SANER), Campobasso, Italy, 20–23 March 2018; pp. 323–334. [Google Scholar]
- Sun, Z. Research on Code Search Using Semantic Vector Matching. Master’s Thesis, Tongji University, Shanghai, China, 2021. [Google Scholar]
- Liu, F.; Li, G.; Fu, Z.; Lu, S.; Hao, Y.; Jin, Z. Learning to Recommend Method Names with Global Context. arXiv 2022, arXiv:2201.10705. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total | Number |
|---|---|
| Total Maven projects | 8282 |
| Total dependency libraries | 4785 |
| Total domain tags | 450 |
| Maven projects in the training set | 6626 |
| Maven projects in the test set | 1656 |
| Top k | |||
|---|---|---|---|
| top 1 | 0.67 | 0.09 | 0.67 |
| top 5 | 0.91 | 0.30 | 0.50 |
| top 10 | 0.95 | 0.43 | 0.39 |
| Top k | |||
|---|---|---|---|
| top 1 | 0.62 | 0.08 | 0.62 |
| top 5 | 0.88 | 0.32 | 0.52 |
| top 10 | 0.94 | 0.43 | 0.40 |
| Top k | |||
|---|---|---|---|
| top 1 | 0.70 | 0.09 | 0.70 |
| top 5 | 0.92 | 0.34 | 0.55 |
| top 10 | 0.97 | 0.48 | 0.42 |
| Top k | |||
|---|---|---|---|
| top 1 | 0.69 | 0.09 | 0.71 |
| top 5 | 0.93 | 0.34 | 0.55 |
| top 10 | 0.98 | 0.49 | 0.42 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, C.; Liu, Y. Enhancements to Neural Language Model for Generating System Configuration Code: A Study with Maven Dependency. Appl. Sci. 2022, 12, 8347. https://doi.org/10.3390/app12168347
Yang C, Liu Y. Enhancements to Neural Language Model for Generating System Configuration Code: A Study with Maven Dependency. Applied Sciences. 2022; 12(16):8347. https://doi.org/10.3390/app12168347
Chicago/Turabian StyleYang, Chen, and Yan Liu. 2022. "Enhancements to Neural Language Model for Generating System Configuration Code: A Study with Maven Dependency" Applied Sciences 12, no. 16: 8347. https://doi.org/10.3390/app12168347
APA StyleYang, C., & Liu, Y. (2022). Enhancements to Neural Language Model for Generating System Configuration Code: A Study with Maven Dependency. Applied Sciences, 12(16), 8347. https://doi.org/10.3390/app12168347