Abstract
Thanks to the widespread application of software frameworks, OTS components, DSLs, and new-generation software building and construction systems, leveraging system configuration code to assist in development is increasingly common, especially in agile software development. In software system implementation, the system configuration code is used to separate configuration items from the underlying logic, of which Maven dependency code is a typical example. To improve software productivity, developers often reuse existing dependency libraries. However, the large quantity, rapid iteration, and various application scenarios exacerbate the challenge for researchers to reuse the library efficiently and appropriately. Proper reuse of Maven dependencies requires correct importation, which is the research priority of this article; putting it into practical usage at the functional level is the next step. In order to overcome this barrier, researchers have proposed a number of recommendation and intelligent generation models based on deep learning algorithms and code learning strategies. We first introduce an enhancement path for the generation model in order to propose novel models that are more targeted than previous studies. We propose EMGSCC (Enhanced Model for Generating System Configuration Code), which generates accompanying dependency libraries based on the libraries already employed by the current system. EMGSCC uses content-based attention to cope with dependency language features and integrate additional domain information. Finally, we evaluate EMGSCC on the DDDI dataset with extra domain information, and findings show that improvement varies from 1% to 8% on all metrics compared with the baseline. We show empirical evidence of our enhancement path for generating system configuration code based on neural language models, and continuous improvement in this direction would yield promising results.
1. Introduction
The complexity of software systems and the broad application of DSL (Domain-Specific Language), particularly the popularization of agile development and DevOps [1], promote the continuous alteration of code-driven software development. These factors converge to greatly change the way software works and constantly promote the evolution of the code itself, giving it new connotations and application scenarios. This revolution affects the entire process of compiling, deploying, and operating software applications and gives rise to the system configuration code (SCC). The system configuration code can be defined as “a special type of code of configuration with a fixed pattern describing relevant integrated resource details for the current system”. When dealing with implementation tasks, the system configuration code is tightly integrated with the software development targets, especially the compiling task.
In a typical software implementation, the system configuration code is the solution to separating configuration items that are free of the underlying logic. It develops into maturity and specialization, which can be independently responsible for a specific layer in the system, such as the application context file and Maven (Maven: https://maven.apache.org/, accessed on 8 June 2022) dependency code, as well as the KerML code in the SysML V2 platform (SysML V2: https://github.com/Systems-Modeling/SysML-v2-Release, accessed on 8 June 2022). The system configuration code is essentially a special DSL with a narrow scope. It pays more attention to reflecting the critical system configuration from a central piece of information and is concise, prefabricated, and uses a lightweight syntax. As a significant example of system configuration code, Maven dependency code provides developers the opportunity not to reinvent the wheel and instead continuously utilize reusable features [2]. A dependency code describes the third-party components used in software systems. However, working with dependency code requires experience with knowing when and how to use the pre-built components. Harnessing the power of intelligent generation models would not only enable more efficient reuse of such code but also better promote the program comprehension and implementation of system configuration code. Under the influence of big code [3], dependency code has met the requirement for intelligent exploration, and may contribute to future architecture pre-design and architecture evolution research.
Previous studies [4,5,6,7] have realized the significant potential of generating code directly from the prior knowledge learned from existing open-source repositories. Automatic generation of dependency code is a promising intelligent exploration direction, with the practical purpose of predicting dovetailing sets of candidate items. Thung et al. [4] first proposed LibRec, a baseline model widely used to generate library items with similar characteristics and usages, which uses association rule mining and collaborative filtering to achieve the recommendation. Since LibRec is restricted to the datasets and technical conditions at the time, rare syntactic and semantic-level language characteristics of dependency code are taken into consideration. This leads to the narrow scope of application scenarios and lower accuracy of generation models. As opposed to the development-intensive essential code, dependency code appears concise by having a relatively fixed syntactic structure consisting of predefined slots and skeletons. The field of source code generation has received considerable attention and is thriving with various emerging models and architectures. While these existing enablers can be directly transferred into the dependency code generation model, they cannot be directly used to design the corresponding model based on dependency code features. Furthermore, exploring an enhancement path for the progressive generation model will promote dependency code generation systematically and feasibly.
Our previous research [8] carried out a systematic review of natural language-based source code generation (NLSCG), proposed the meta-model and reference framework to assist in better understanding NLSCG problems, and finally dissected the ongoing technical enablers to promote NLSCG solutions into further research enhancements or production applications. The generic pipeline proposed by recent research [9] has clarified the significance and popularity of representation learning and domain knowledge when learning from programming languages, which also confirms the enhancement direction of this paper. Based on these fundamental frameworks, this paper performs a thorough analysis of system configuration code with the Maven dependency code as the representative instance, empirically investigates intelligent dependency code generation advances according to remarkable enablers, and discovers the self-consistent enhancement path that may stimulate potential improvements for dependency code generation. We analyze the enhancement path from three levels: a data-driven model, a language feature-based model, and a domain knowledge awareness model. Following the enhancement path, we address each challenge one by one and discover the blind spot that current studies did not uncover. Since current studies generally fail to cover the language feature and domain knowledge, we implement and evaluate the generation model concentrating on these two aspects. In summary, this paper makes the following contributions:
- We present an enhancement path to clarify the ongoing dependency code generation at different levels, introducing five enablers that drive the model design, including data sources, usage scenarios, technical environments, language characteristics, and usage patterns.
- We propose EMGSCC (Enhanced Model for Generating System Configuration Code), a concrete generation model that mirrors the language feature introduction and domain knowledge integration simultaneously. EMGSCC learns from the dependency code from different open-source Maven projects, then customizes a neural language model with special consideration for the order-independent features and domain information to generate practical accompanying items.
- We evaluate EMGSCC on the DDDI dataset to generate accompanying dependency libraries. By comparing with the baseline model and ablation experiments, EMGSCC demonstrates its effectiveness through improvements varying from 1% to 8% on all metrics.
The remainder of this paper is as follows. Section 2 describes our study’s research context and presents the enhancement path. We introduce the proposed approach EMGSCC in Section 3. Section 4 introduces the DDDI dataset, evaluation metrics, and experimental results. The probable working reason and threats to validity are discussed in Section 5. Section 6 enumerates the previous studies and techniques related to our problem. Finally, this paper is concluded in Section 7.
2. Research Contexts
2.1. On the Challenges and Responses of System Configuration Code Generation
In recent years, the field of software development has been undergoing a dramatic evolution. With the advent of middle-end platforms packaging the underlying logic and data capabilities, concise source codes, manifest logic layering, and definite module disassembly have become mainstream. When developing, deploying, operating, and maintaining software systems, the specialized code that is closely coupled with each software development target gradually begins to expand, and the connotation of the code itself is constantly changing and iterating. In addition to the essential source code during the development process, driven by the Infrastructure as Code (Iac), Configuration as Code (CaC) and cloud-native concepts, increasing system configuration code exists in the system implementation explicitly and plays a crucial role. System configuration code disassembles various integrated configuration information of the system, focusing on the compilation and integration targets.
In this paper, we examine a typical instance of system configuration code: Maven dependency code. Dependency code allows developers to leverage well-founded programming utilities without re-implementing software functionalities from scratch [2]. It plays a vital role in improving the quality of software projects. The first step in enabling effective reuse is to provide the projects with the proper libraries, followed by considering how to implement the libraries at the functional level. Current studies about dependency code pay close attention to accompanying dependency recommendations [4], dependency migration [2], global dependency graphs [10], and detection of bloated dependencies [11].
Dependency code is a semi-structured XML-like text, which contains information about the project and configuration details used by Maven to build the project [12] and identified by dependency coordinates (groupId, artifactId, version). The dependency code can be represented as a multiway tree, where each child node in the tree is an XML tag. There are two distinct language features and relatively specific usage patterns of dependency code that require significant attention.
First of all, the dependency code is more concise than the essential source code, presenting remarkable weak-constraint features. The essential source code takes AST as an intermediate structure for code representation, while the XML structure-based dependency code is more straightforward with fewer node types. Generally speaking, all nodes in AST can be divided into terminal and non-terminal nodes. These two work together to express syntax and semantics; the non-terminal nodes represent the most syntactic information. However, the structural scheme of non-terminal nodes in the dependency code is prefabricated and cannot represent critical semantics as well. In contrast, terminal nodes contribute more semantic concerns: the dependency coordinates.
Next, the dependency code also has an order-independent feature. Rather than arranging libraries based on importance, priority, and functional subdivision, programmers construct dependency code by randomly inserting specific libraries under the Dependencies tag. Therefore, the functionalities expressed by a particular dependency library have no connection with its tandem position at the same tier; the out-of-order dependency libraries in the same tier would not affect their actual semantics.
Lastly, the usage pattern is especially significant for dependency code [13]. In contrast to the varied API (Application Programming Interfaces) usage patterns derived from object-oriented languages, developers are faced with a more straightforward and rudimentary dependency code. Despite the large number and rapid evolution of open-source libraries, developers spend considerable effort selecting libraries and continuously iterating. For usage pattern learning, models encounter challenges when mining [5,14] and learning inherent features of combinational dependency libraries under different scenarios, such as achieving specific cross-cutting functionalities, constructing specific frameworks, etc. Due to the concise nature of dependency code, it is difficult to learn usage patterns directly from native code itself. Therefore, incorporating domain knowledge into dependency libraries is a worthwhile approach.
Based on the above analysis of the challenges for generating configuration code, enhancement elements of the model were identified, among which the most accessible are the language features and domain knowledge. Our previous research [8] proposed a core technical enablers landscape, which provides practical guidelines about building source code generation tasks from a holistic perspective. Detailed descriptions of the technical enablers for structural modeling of the source code are given in the landscape. To be specific, the landscape summarizes token-based constraints for code with weak structural modeling requirements. Of this type of constraints, a particular focus should be placed on the type of constraints that simplify code generation to targeted slot prediction based on demonstrative functional types of different domain characteristics. Our previous research results, along with the analysis of these challenges, indicate that we can implement the dependency code generation task in this paper in the following foreseeable route. Firstly, we select the token-based constraints [8] to capture weaker syntactic features, namely concentrating on the dependency coordinates. Secondly, we endeavor to ignore the sequential order while constructing dependency generation models; to be specific, we (1) reduce the importance of the order in sequential-based models by formulating strategies [6]; or (2) select order-independent models directly. Finally, we suggest integrating domain knowledge into the modeling process during dependency library representations.
2.2. Enhancement Path for Generating Dependency Code
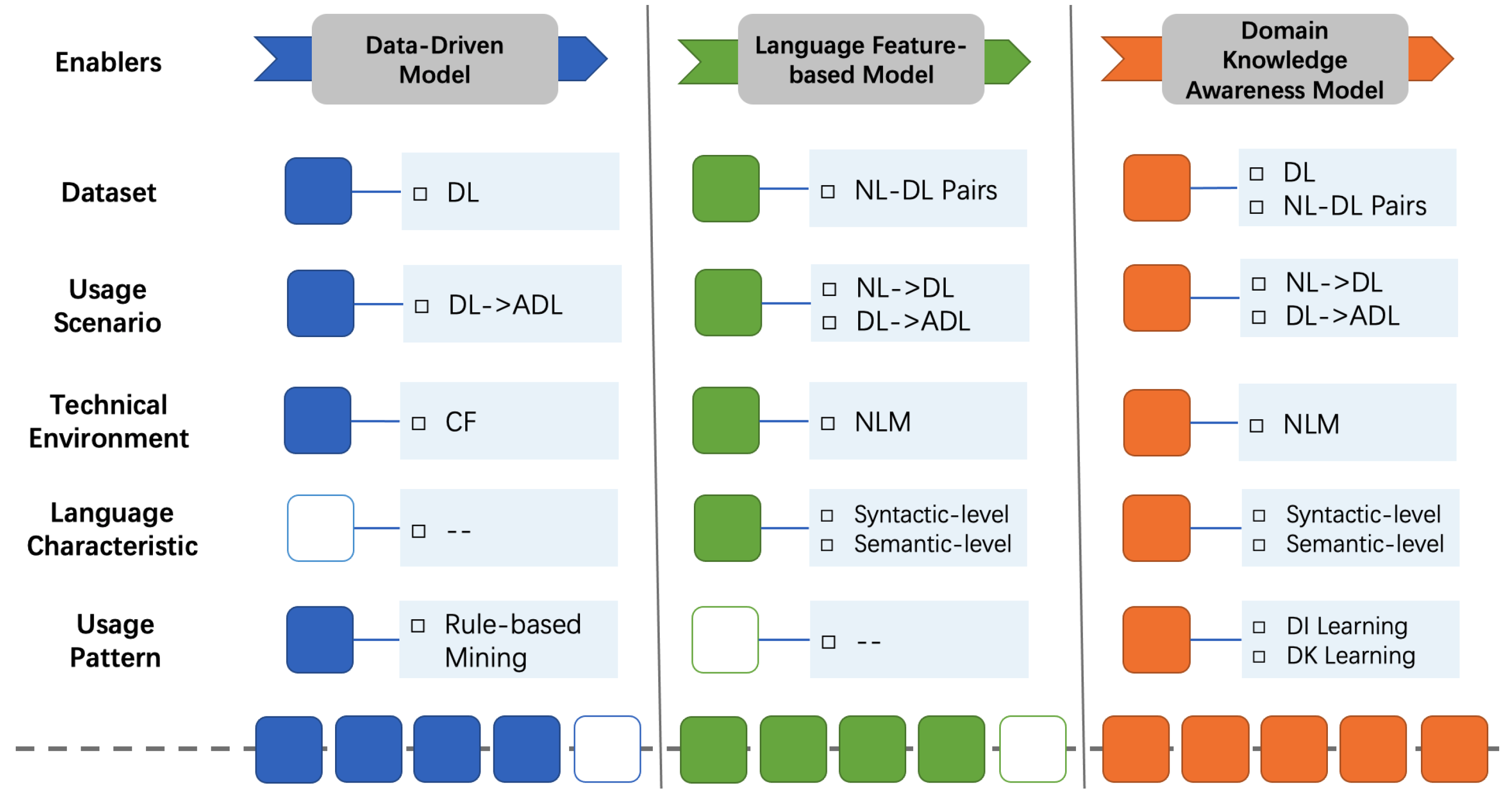
We have previously studied [8] the critical handlers of code generation solutions, summarizing various algorithms, architectures, tools, and strategies derived from machine translation and code analytics, which we consider to be the technical enablers. Drawing inspiration from these achievements, we attempt to enhance the intelligent generation model for dependency code. To be specific, we condense and combine the enablers of generating dependency code at different levels. These enablers include a dataset for determining the upper bound of the model, a usage scenario of a more user-friendly and innovative, technical environment for driving the model architecture, language characteristics of relative explicitness, and a usage pattern to be explored intensively. On this basis, we introduce an enhancement path shown in Figure 1, which comprehensively considers the research actuality, the inherent characteristics of dependency code, and the crucial handlers of the existing code generation framework and technology stack [8]. Foreseeable models for automatically generating dependency code fall into three different levels, namely data-driven models, language feature-based models and domain knowledge awareness models, paying close attention to five enablers that impact the model design. Therein, the content and quality of the dataset affect the scope of dependency code generation scenarios and the applicability of model algorithms. The popularity of open-source repositories, and the continuous development of technical environments, especially neural language models, have brought more feasibility to broadening the generation scenarios and introducing language characteristics and usage patterns. Overall, along the enhancement path, more powerful models take into account language features specific to dependency code, rather than textual information or essential source code. These three types of essence models reflect different model design priorities at various times and guide more practical directions for the ongoing enhancement of subsequent models.
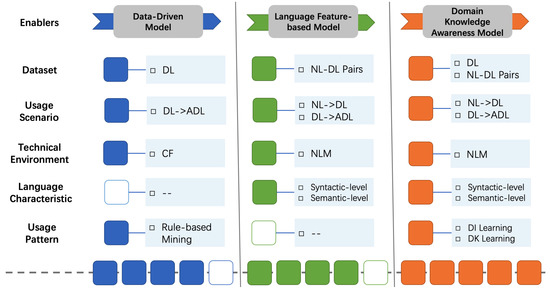
Figure 1.
Enhancement path. Abbreviations: DL—dependency libraries, NL—natural language, ADL—accompanying dependency libraries, CF—collaborative filtering, NLM—neural language model, DI—domain information, DK—domain knowledge.
Data-Driven Model. A classic recommendation model can easily identify the intuitive values and inherent relationships of the current dataset. Considering the technical environment at the time, researchers proposed data-driven models to discover or summarize potential relations according to their first impression. By omitting the additional domain knowledge, data-driven models pay scant attention to what kind of information the data contains, instead focusing on the latent state of the whole dataset, which is mostly derived from statistical-based algorithms. LibRec [4] is a typical example, which proposes a hybrid approach that combines association rule mining and collaborative filtering to recommend relevant libraries for developers.
Language Feature-based Model. The target language of this paper is the system configuration code, and the generation model is discussed with the dependency code as a typical example. However, the data-driven models are too straightforward to take into account the characteristics of the dependency code that are obviously different from the underlying data item. In this context, a dependency code is a particular source code, and the primary approach is launching intelligent exploration using the neural language model. With the release of brand-new datasets [6] and the continuous iteration of modeling algorithms [15,16], in addition to recommending accompanying dependency libraries, it has become more practical and feasible to carry out intelligent exploration such as natural language-based dependency library generation. In terms of source code modeling, the integration of syntactic and semantic level information has proven to be effective in capturing and learning more features [17,18]. In contrast to essential source code, a dependency code exhibits its peculiarities, which are also suitable for a system configuration code. Starting with the syntax of a dependency code, its most highlighted features include its conciseness, prefabrication, and unordered lists. Incorporating these features into the model design requires treating the skeleton as fixed, while filling the slots of the skeleton empirically. Therefore, the generation of a dependency code is converted into the purposeful generation of dependency libraries. The unordered list prompts the generation model to ignore the sequential order of dependency libraries. Practical approaches include reducing the importance of the order in a sequential-based model or directly selecting an order-independent model. The semantics of dependency codes is very intuitive, importing given third-party libraries to access encapsulated methods and tools. Yet few studies have investigated the deep-level semantics of dependency codes, such as the combination of function and framework-oriented multi-dependency libraries. These deep-level semantics can facilitate the rapid implementation of a function module and will be enhanced by learned usage patterns.
Domain Knowledge Awareness Model. After exploring the main routes of dependency code generation, the last enhancement level we will focus on is how to exploit the dependency code usage pattern effectively. Since the dependency code usage pattern (DC usage pattern) is not defined, we refer to the definition of an API usage pattern [19] and define the DC usage pattern as follows: a DC usage pattern is a set of dependency libraries required to assist in implementing a functionality; one dependency library may play multiple roles in the system. The large and continuously updated dependency libraries create a barrier for developers to import them effectively. Using DC usage patterns would help developers overcome these challenges, and domain information and knowledge are crucial to mining and learning these patterns. The domain information is readily available, as the Maven central repository stores such information for all dependency libraries, such as domain tags and descriptions. In contrast, the domain knowledge of a dependency code is challenging, as it is not obtained by local features derived from single training simples but by aggregating and overlapping the bounded context information from various scenarios. DC usage patterns are capable of providing transferable knowledge to the generation model, which would greatly improve model performance.
3. Enabling the Enhancements of Language Features and Domain Knowledge
3.1. EMGSCC: Enhanced Model for Generating System Configuration Code
The scenario selected in this article for generating dependency code is to generate the expected accompanying dependency libraries (ADL) based on the dependency libraries already employed in the system. According to the enhancement path we have formulated, the enhanced model proposed in this paper focuses on introducing the language characteristic of the Language Feature-based Model and capturing the usage pattern of the Domain Knowledge Awareness Model. To achieve this purpose, considering the research status quo, the deep sequence-to-sequence-based models are the top options, in conjunction with putting forward targeted improvements that rely on the motivating factors of system configuration code. Hence, we have started with the most feasible and accessible direction of improvements, namely dealing with the concise and unordered list of dependency libraries, and tentatively obtaining usage patterns from the domain information.
On this basis, we propose a set-to-set based enhanced model for generating system configuration code (EMGSCC), which employs recurrent neural networks to learn the underlying characteristics from relevant dependency corpus. EMGSCC obeys the token-based constraints [8] and concentrates on generating the critical slots of dependency code; that is, the dependency library coordinates. EMGSCC uses an augmented attention mechanism to process the unordered set of input dependency libraries and a multi-label classification layer to output the unordered set of output dependency libraries. Furthermore, EMGSCC seeks practical ways to integrate domain knowledge to learn usage patterns of dependency code. Domain tags and descriptions of dependency libraries from the Maven Central Repository are reliable sources of domain information, enabling EMGSCC to learn more about the relations between dependency libraries.
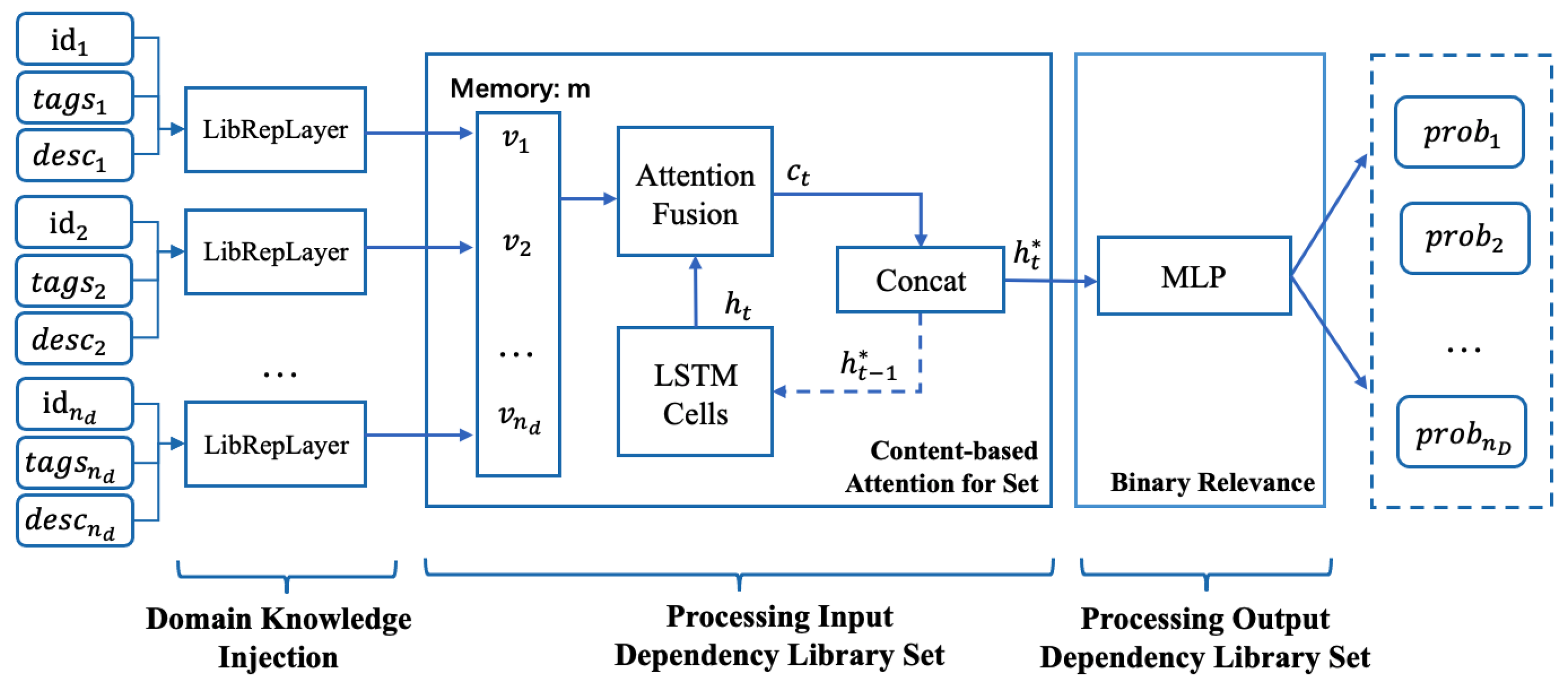
Figure 2 explains how EMGSCC works. For the selected dependency libraries in the system, we collect the domain tags and descriptions of each library and obtain representations with integrated domain information through the LibRepLayer (see Figure 3 for the detailed structure of LibRepLayer). Then, each library representation in the system naturally grounds to a time step in the LSTM. Meanwhile, we adopt an attention mechanism for the set [20], through which we obtain the weighted representation vector of all dependency libraries. These mechanisms enable sequential-based models to deal with the “order does not matter” problem. Then, EMGSCC passes through several fully connected layers using ReLU as the activation function. Finally, to cope with the output dependency library set, under the idea of binary relevance [21], we decompose the multi-label learning problem into independent binary classification problems. Therefore, EMGSCC outputs the probabilities of dependency libraries accompanied by libraries as input.
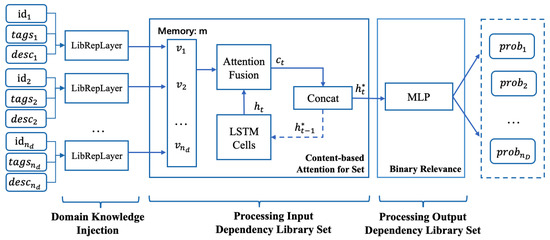
Figure 2.
EMGSCC model overview. Where * is specially used to indicate the output state of different time steps when this LSTM evolves.
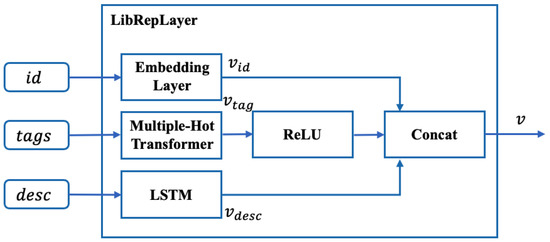
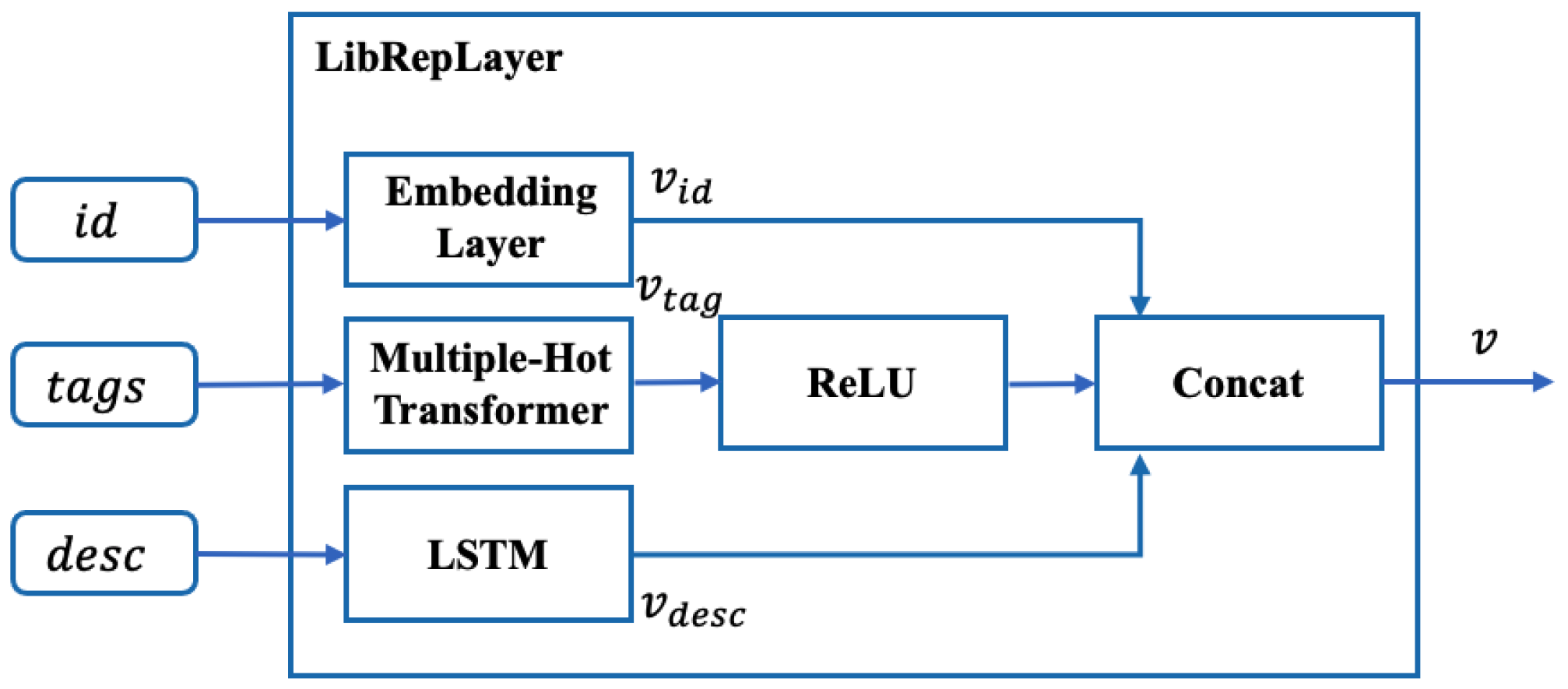
Figure 3.
The structure of LibRepLayer.
3.2. Integrating Domain Information
The essential information of a Maven dependency library includes the identification, multiple domain tags, and the description. Among them, the identification of the dependency library is the unique coordinates consisting of groupId, artifactId, and version. The groupId represents the organization to which the developers of the library belong, the artifactId represents a specific library, and version represents the specific version of the library. As an example, for the prevalent unit test dependency library JUnit, its identifications of (groupId, artifactId, version) are (junit, junit, and 4.13.1), respectively. The domain tags of a dependency library reflect the domain, functional attributes and categories to which the library belongs. For example, the tags of JUnit include ‘testing’, ‘junit’. The description of the dependency library uses short text to describe the implemented functions, features, developers, etc. For example, the description of the JUnit dependency library is ”JUnit is a unit testing framework for Java, created by Erich Gamma and Kent Beck”. To sum up, in addition to the coordinates of dependency library identification, the accessible and relatively reliable information are tags and description, which both carry a certain amount of domain information. The tags is relatively concise, while description carries more general information.
Classic models [4,6] utilized models based on association rule mining, collaborative filtering, deep learning, etc. The adopted technical approaches indicate a continuous improvement trend. However, the scope of training samples is limited to the library’s coordinates. The proposed data-driven models discover potential relations via the generation target itself. Therefore, following the enhancement path, EMGSCC designs the LibRepLayer, trying to learn the usage pattern of dependency code and obtain practical and outperforming results. EMGSCC is a domain knowledge awareness model, which integrates the library tags and description that carry a certain amount of domain information purposefully. We design the LibRepLayer module to obtain the representation that integrates various essential information of the dependency library, and the detailed structure of LibRepLayer is shown in Figure 3. The LibRepLayer consists of three main components: the Embedding Layer for the identification coordinates , the multiple-hot transformer for the domain , and the LSTM for the functional description . After obtaining the vectors of essential information , , , we concatenate three different vectors and finally feed them into the input processing layer.
The Introduction of Domain Tags of a Dependency Library. There are types of domain tags in the dataset; a dependency library may be associated with multiple domain tags. Accordingly, multiple-hot encoding is particularly suitable for converting several domain tags into dimensional multi-hot vectors. Different from one-hot encoding, multiple-hot encoding enables the binary vector to have multiple elements of 1. For the case of having several domain tags in , each tag is numbered from 1 to , and a -dimensional vector can be used to represent the multiple domain tags of a dependency library. Among them, the i-th element of the vector corresponds to the domain tag numbered i. When a dependency library is associated with the i-th domain tag, then the i-th element of is equal to 1; otherwise it is 0:
where represents the domain tags of a dependency library.
After obtaining the multiple-hot vector , we can obtain the fixed-dimensional representation integrated with domain information through a fully connected layer whose activation function is ReLU.
The Introduction of a Domain Description of the Dependency Library. The simplest way to vectorize words is to use one-hot encoding; however, the dimension of the word vector overgrows with the dictionary size, incurring high computational cost. The LibRepLayer avoids the curse of dimensionality by mapping the word identifier to a low-dimensional vector through a small neural network. The bag-of-words (BoW) model is also a common document representation method. The shortcoming of this method is that it ignores the word order and is insensitive to negative words, which results in two sentences with opposite meanings being considered “highly similar”. To cope with the word order problem, EMGSCC uses a long short-term memory recurrent neural network (LSTM) [22] to convert a dependency library’s functional description into a fixed-dimensional representation . LSTM has been proven to be effective in dealing with sequence data and addresses the long-term dependency problem by selectively memorizing valuable information and discarding useless information.
3.3. Dealing with an Unordered Dependency Library Set
3.3.1. Processing Input Dependency Library Set
After obtaining the dependency library representation that integrates certain domain information, EMGSCC focuses on dealing with the unordered set of input to obtain the representation of the project. Ordinary sequences can be encoded into vectors by recurrent neural networks. However, the principle that must be satisfied when the input is a set (which presumes order does not matter) is that swapping the two elements and in the set X should not change their encoding.
Adopting a BoW model is an intuitive choice to vectorize each library based on a dictionary of all dependency libraries. In this case, each library can be represented by a one-hot vector of the form [0, 0, 0, 1, 0, 0, 0, 0, 0, 0]. By adding the corresponding components of all library vectors, we can get the dependency library vector of the project. However, the BoW model faces apparent drawbacks. One is that the dimension of the project representation will be quite high due to the large number of all dependency libraries. The second is that one-hot vectors are incapable of reflecting inherent relationships among libraries. A more sophisticated approach is to use word embeddings to compress each dependency library into a low-dimensional dense vector and map the neighboring libraries to adjacent vectors in space. Since the number of dependency libraries of each project is indeterminate, it is necessary to add and average the dependency vectors of the project according to the corresponding positions. However, this will lead to the unavoidable loss of different criticality between the already worked libraries and the remaining ones.
In EMGSCC, we borrowed the method proposed by Vinyals et al. [20] to integrate unordered and variable-sized inputs with the attention mechanism. The main idea of this method is to concatenate the output state of the previous time steps with the attention mechanism over the memory vector composed of inputs. To satisfy the critical property that the order of elements in a set is invariant, we employ the content-based attention for set to obtain the attention weights of each dependency library. An LSTM without inputs or outputs is adopted to continuously update its state by repeatedly reading the input vector integrated by the attention. Afterward, we perform a weighted average of each dependency library vector according to the attention weights, resulting in an unordered input-friendly embedding. As shown in Figure 2, the basic processing steps are as follows:
- For each imported dependency library of the project, a fixed-dimensional dependency representation vector is obtained through the LibRepLayer with the identifier, tags, and description as the input.
- We employ an LSTM to merely calculate the recurrent states:
- After obtaining the input representation vectors , …, , each of them is considered as a memory vector; the attention weight of each dependency library can be computed by:where , , and are weight parameters of linear layers.
- With attention weights, we can obtain the context vector . By concatenating the context vectors and hidden state recurrently, the last hidden state is the target representation that is permutation-invariant to the inputs.
3.3.2. Processing Output Dependency Library Set
In order to process output dependency libraries, EMGSCC first considers the unordered set characteristic. The “order does not matter” problem is also suitable for the output result. In this case, each dependency library in the output set can be regarded as a label category . Considering the possible mutual exclusion, dependency, inclusion and other relationships between categories, the problem of finding multiple ADLs from candidates can be regarded as a multi-label classification task.
Let denote the number of dependency libraries in the dataset. EMGSCC will finally output an -dimensional vector , where represents the probability of the library numbered i. Driven by the binary relevance method [21], we decompose the multi-label classification task into independent binary classification problems. To be specific, we construct binary classifiers to output the ADLs. In order to better make the generated dependency library as close as possible to the target result set, on the basis of cross-entropy loss, the optimization goal of EMGSCC is to minimize the cross-entropy of binary classifiers:
where n is the test set size. represents whether the target set of the i-th test sample contains the library numbered j; if it contains this library, it assigns this value to 1, and otherwise, it assigns it to 0. represents the probability that the library numbered j may be imported by the test project for the i-th test sample. is the learned weights parameter.
4. Experiments and Results
4.1. Dataset and Baselines Description
The goal of EMGSCC is to generate ADLs based on input libraries. Here, to better compare and evaluate the performance of our experiments, we have collected relevant datasets from Libraries.io (Libraries.io: https://libraries.io/, accessed on 8 June 2022) and Github (Github: https://github.com/, accessed on 8 June 2022), and propose the Dependency Dataset with Domain Information (DDDI). We first explored the famous open-source dataset Libraries.io, and then filtered high-quality Maven projects with their imported dependency libraries from Github. Since EMGSCC integrated the domain tags and functional description corresponding to the dependency, we also crawled that information from the Maven Central Repository (Maven Central Repository: https://mvnrepository.com/repos/central, accessed on 8 June 2022). The final DDDI statistics are shown in Table 1. The following describes the preprocessing steps of the dataset:

Table 1.
Dataset statistics.
- Filtering: Similar to the previous model LibRec [4], we filtered out Maven projects with less than ten total dependency libraries, resulting in 8282 Maven projects that used a total of 4785 different libraries.
- Splitting Inputs and Outputs: For each Maven project, half of the dependency libraries were randomly selected to be the employed items of the current project, and the remaining half were the accompanying items.
- Description preprocessing: In virtue of the Stanford Core NLP tool (Stanford Core NLP: https://stanfordnlp.github.io/CoreNLP/, accessed on 8 June 2022), we finally obtained a ready-to-use vocabulary through lowercasing, filtering, lemmatization, word segmentation, etc.
- Tokenization: We tokenized the participants in EMGSCC. As for dependency libraries, each library was treated as a token; as for domain tags and functional descriptions, each unique tag and each description word were treated as a token separately. With incrementally generated dictionaries, we represented the tokens with numerical ids.
In order to better demonstrate the effectiveness of EMGSCC, we selected LibRec [4] as our comparison object. To the extent of our knowledge, Thung et al. [4] first proposed LibRec, which is widely used to generate accompanying dependency libraries. LibRec uses association rule mining and collaborative filtering and is a typical data-driven model. Comparisons between LibRec and EMGSCC can reflect the differences and superiorities of models at different enhancement levels.
4.2. Metrics
We evaluated how well EMGSCC generates ADLs matched with the ground-truth data. This article first used the and evaluation metrics, which are widely used in the baseline and relevant approaches [4,6,14]. calculates whether one of the k dependency libraries with the highest probability of model generation is practicable. It is calculated as follows:
and
where is the i-th model result.
merely measures whether the result list has practical dependency libraries while paying insufficient attention to the number of useful ones. Therefore, we also considered adopting more stringent metrics commonly used in recommendation systems; and [23,24] are prevalent metrics to evaluate the reasonable degree of the generated result, and they are calculated by:
4.3. ADL Prediction Accuracy
In order to verify the effectiveness of the EMGSCC method, this subsection addresses the following research question:
- RQ1: Compared with the baseline model LibRec [4], how accurate is EMGSCC in predicting the accompanying dependency library?
RQ1 was designed to verify whether EMGSCC can obtain a higher accuracy for generating ADLs. To achieve this goal, a comparative experiment was conducted between LibRec [4] and EMGSCC, which share the same test set. LibRec was chosen because it is a typical data-driven model in our proposed enhancement path; it was the state-of-the-art method at the time, and our method shares a similar usage scenario with LibRec. This version of EMGSCC uses only dependency identity coordinates as input. Additionally, LibRec can be considered as the baseline model based on association rule mining and collaborative filtering. We utilized top k as the index to compare the results of different models.
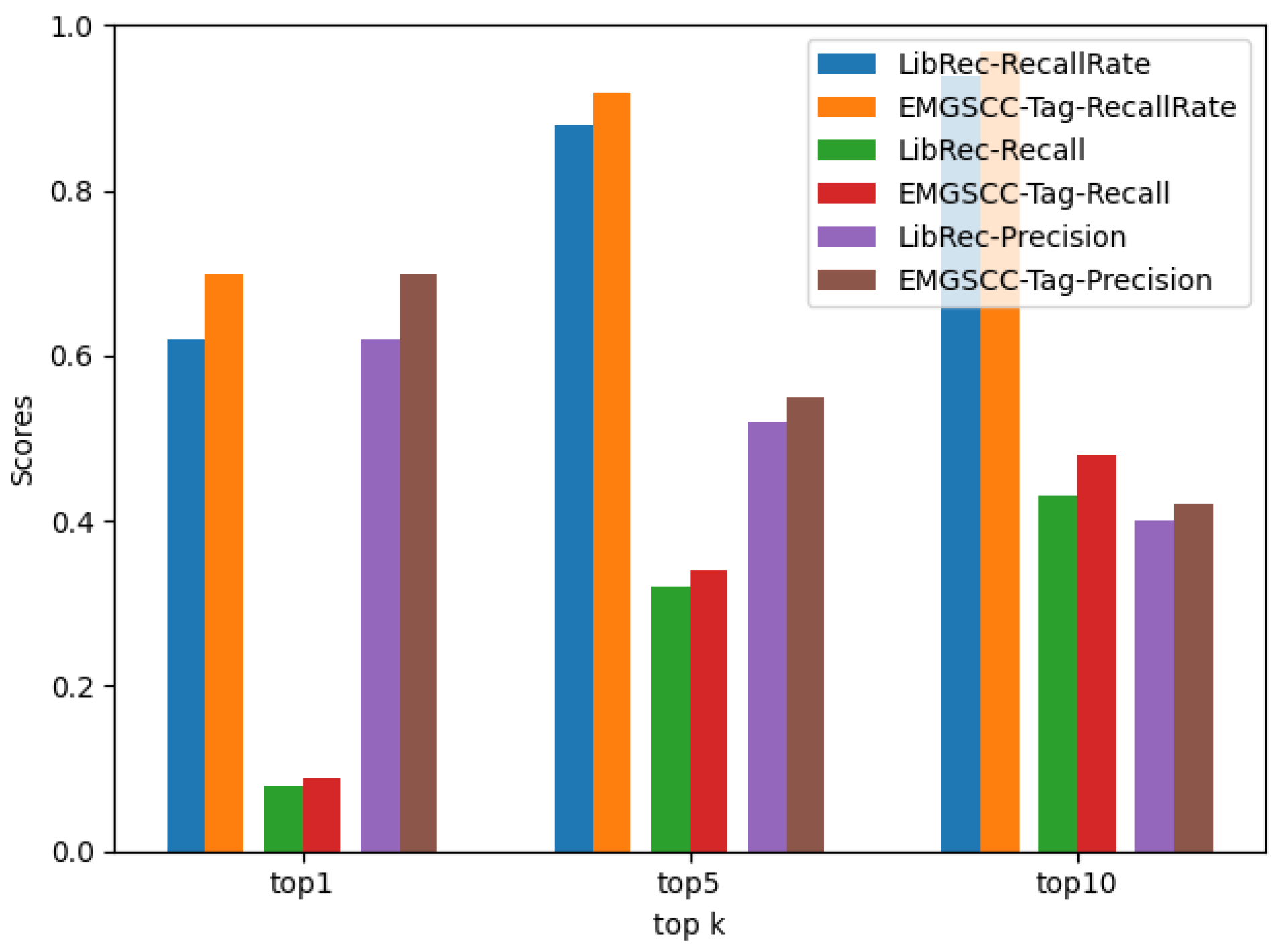
To explore RQ1, the experimental results of the comparison between EMGSCC and LibRec in the top 1, top 5, and top 10 are shown in Table 2 and Table 3 and Figure 4. EMGSCC here merely used the dependency identifier (groupId, artifactId, version) for the input (which we call “the basic EMGSCC”). Based on the above results, we have the following observations.
Table 2.
Top k accuracy of the basic EMGSCC.
Table 3.
Top k accuracy of the LibRec.
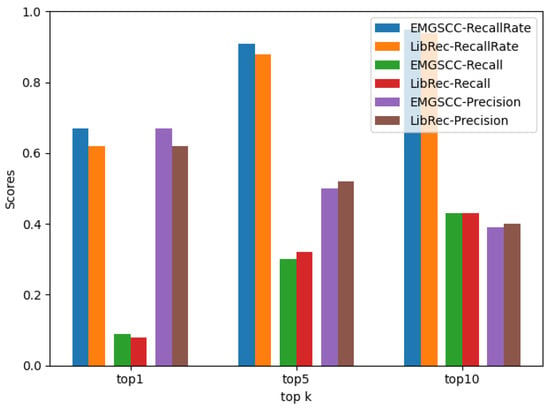
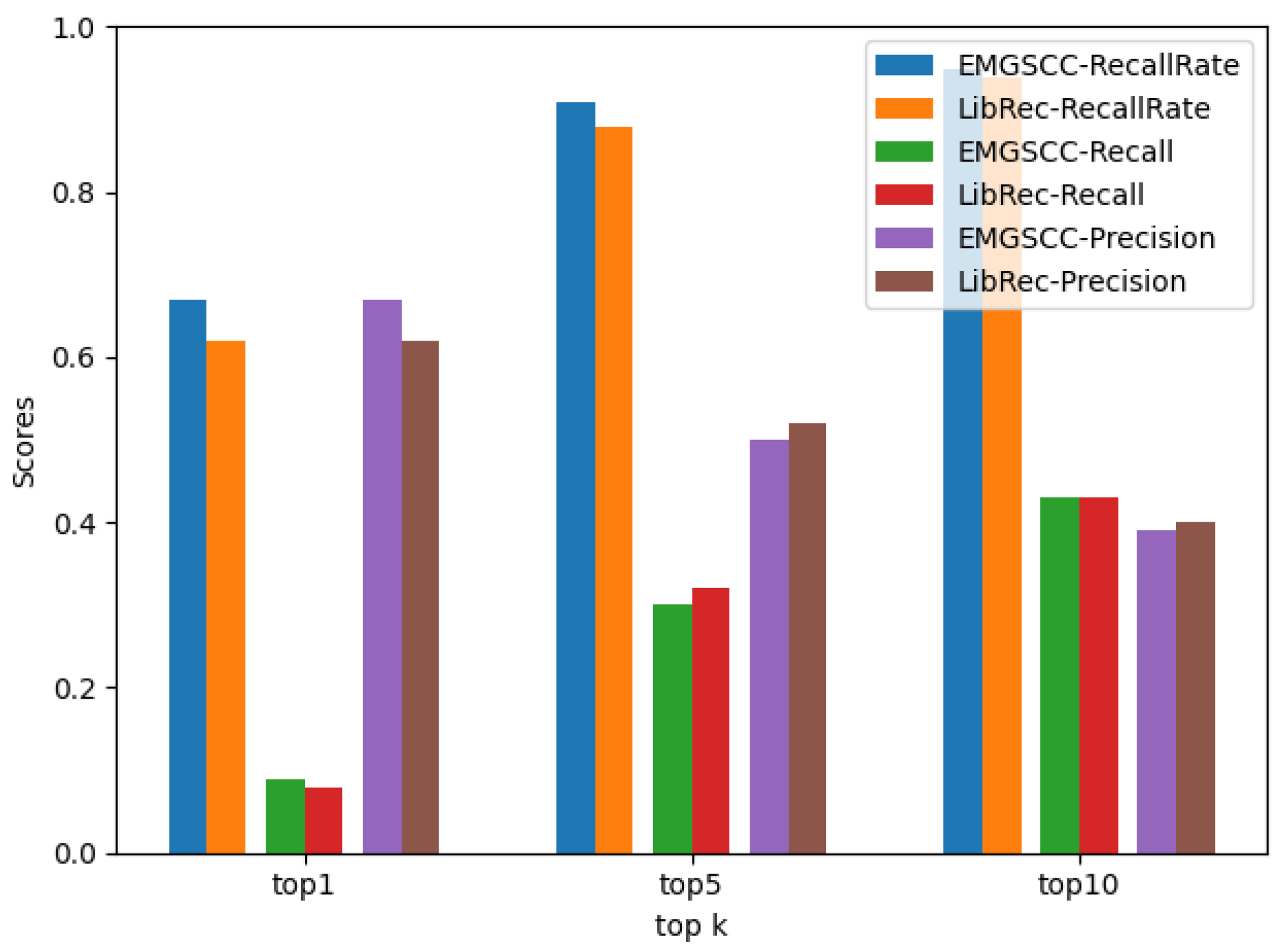
Figure 4.
The performance comparison between basic EMGSCC and LibRec.
EMGSCC performs basically better than LibRec across the three different metrics of , , and , which indicates that EMGSCC can learn more inherent relations between dependency libraries. Specifically, according to the results, for , the results of the EMGSCC are better than LibRec under different k values, 0.05, 0.03, and 0.01 higher than LibRec, respectively. Among them, when k is 10, the of LibRec and EMGSCC both achieve high scores, which are 94% and 95%, respectively, indicating that the 10 ADLs generated by EMGSCC have more than 95% possibility that there are practical libraries. LibRec recommends that 10 ADLs have a more than 90% probability of being useful. For and , when k is 1, the results of EMGSCC are 0.01 and 0.05 higher than LibRec, respectively; a slight difference exists between the two models when k is 5 and 10. Both models improve on and with the increase in k, since the practical ADLs will increase with the number of recommendations. As k increases, the of the two models will gradually decrease because the more candidate items, the more interfering libraries. Although a larger k may result in a better overall effect of the model, in recommendation systems, an overlarge value of k is not conducive to the user’s choice. Therefore, from an engineering point of view, k can generally be selected as 10.
Overall, our approach performs better than the baseline model LibRec in the current dataset. One of the reasons for this is that we have adopted a more advanced modeling approach using neural language models to replace traditional collaborative filtering algorithms. In EMGSCC, we fully account for the order-independence characteristics, which allows us to build models that better fit the language features of a dependency code and identify more inherent relationships between dependency libraries.
4.4. Contribution of Domain Tags and Functional Description
In order to evaluate the contribution of the domain tags and functional description of the EMGSCC method, this subsection focuses on the following research questions:
- RQ2: Compared with the baseline model LibRec and the basic EMGSCC, how do domain tags contribute to predicting the accompanying dependency library?
- RQ3: Compared with the EMGSCC with domain tags, how does the functional description contribute to predicting the accompanying dependency library?
The purpose of RQ2 and RQ3 is to evaluate whether introducing both domain tags and functional descriptions contribute significantly to the overall approach. In order to verify this, we carried out ablation experiments with and without these modules in EMGSCC. We selected LibRec and basic EMGSCC as the baseline model, EMGSCC-Tag as the enhanced model with domain tags, and EMGSCC-Tag-Desc as the enhanced model with domain tags and functional description. We also used the same dataset as RQ1 for our experiments and top-k as our experimental accuracy index.
In order to explore RQ2, based on the basic EMGSCC model, the experimental results of the EMGSCC-Tag model are shown in Table 4, and the comparison with the basic SS-DLE model and the LibRec model is shown in Figure 5 and Figure 6. Our experimental result shows that EMGSCC-TAG performs better than the basic EMGSCC and LibRec, indicating that the introduction of domain tags enables the generation model to obtain richer representation with domain information and predict higher-quality ADLs.
Table 4.
Top k Accuracy of EMGSCC-Tag.
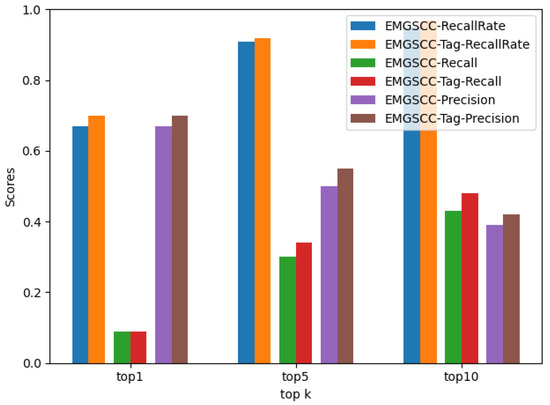
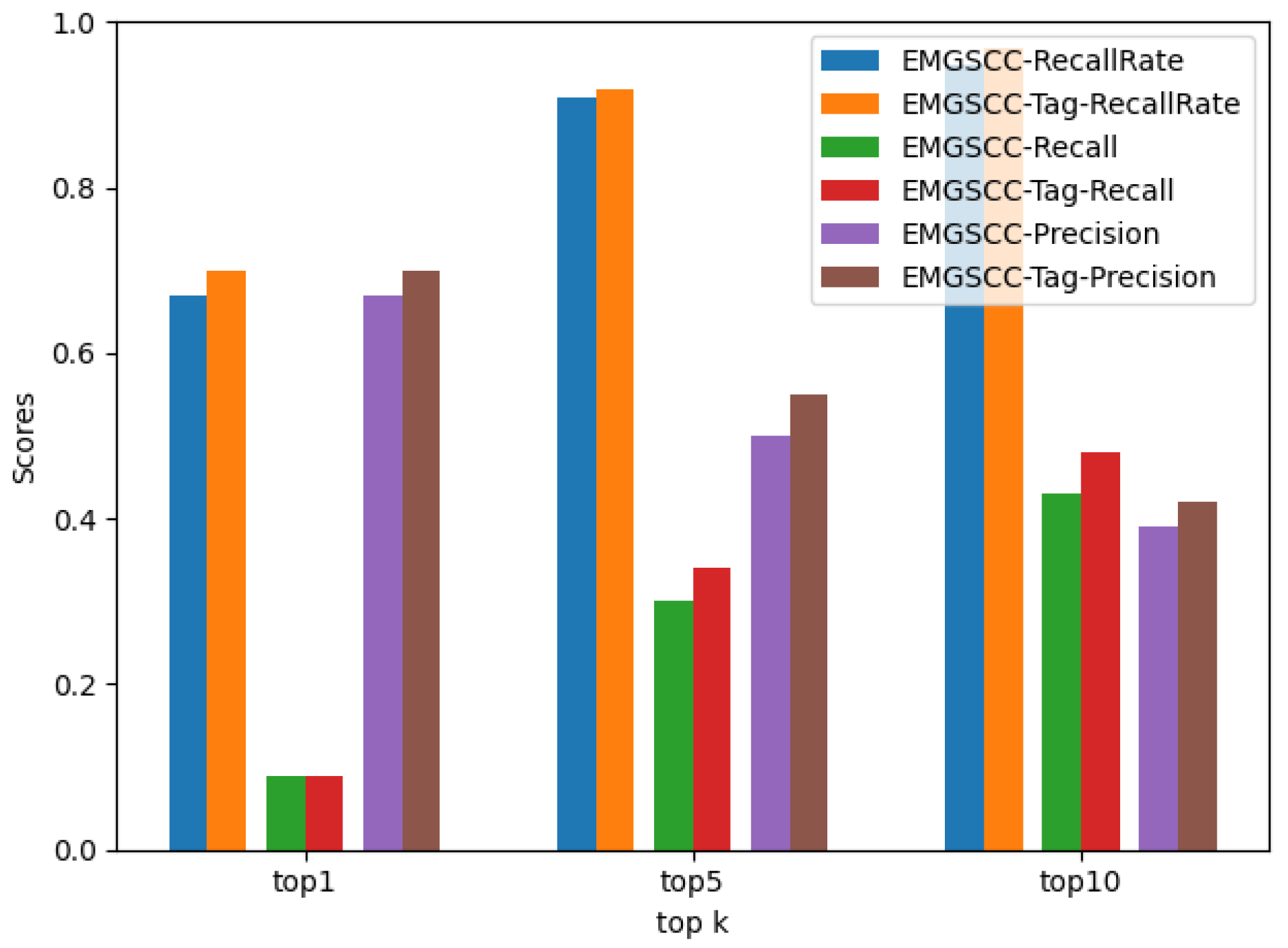
Figure 5.
The performance comparison between EMGSCC and EMGSCC-Tag.
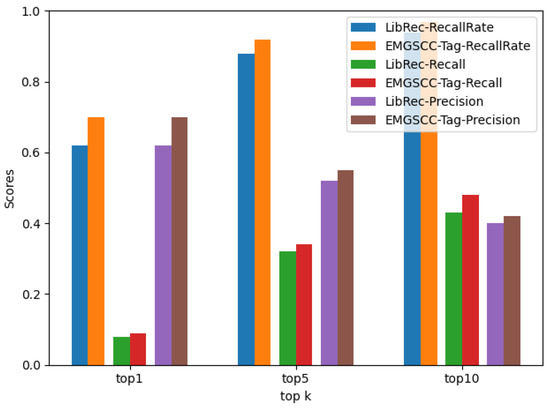
Figure 6.
The performance comparison between LibRec and EMGSCC-Tag.
Specifically, as shown in Figure 5, on the remaining the metrics except , EMGSCC-Tag performs better than EMGSCC, and the improved score is between 0.01 and 0.05. Regarding , EMGSCC-Tag and EMGSCC obtain the same score of 0.09. A comparison between EMGSCC-Tag and LibRec is shown in Figure 6. On all metrics, SS-DLE-Tag outperforms LibRec by a score of 0.01 to 0.08. These results demonstrate the importance of introducing domain information to learn potential usage patterns in generating dependency code. Therefore, EMGSCC-Tag can obtain a more accurate vector representation of a dependency library and then recommend more practical ADLs.
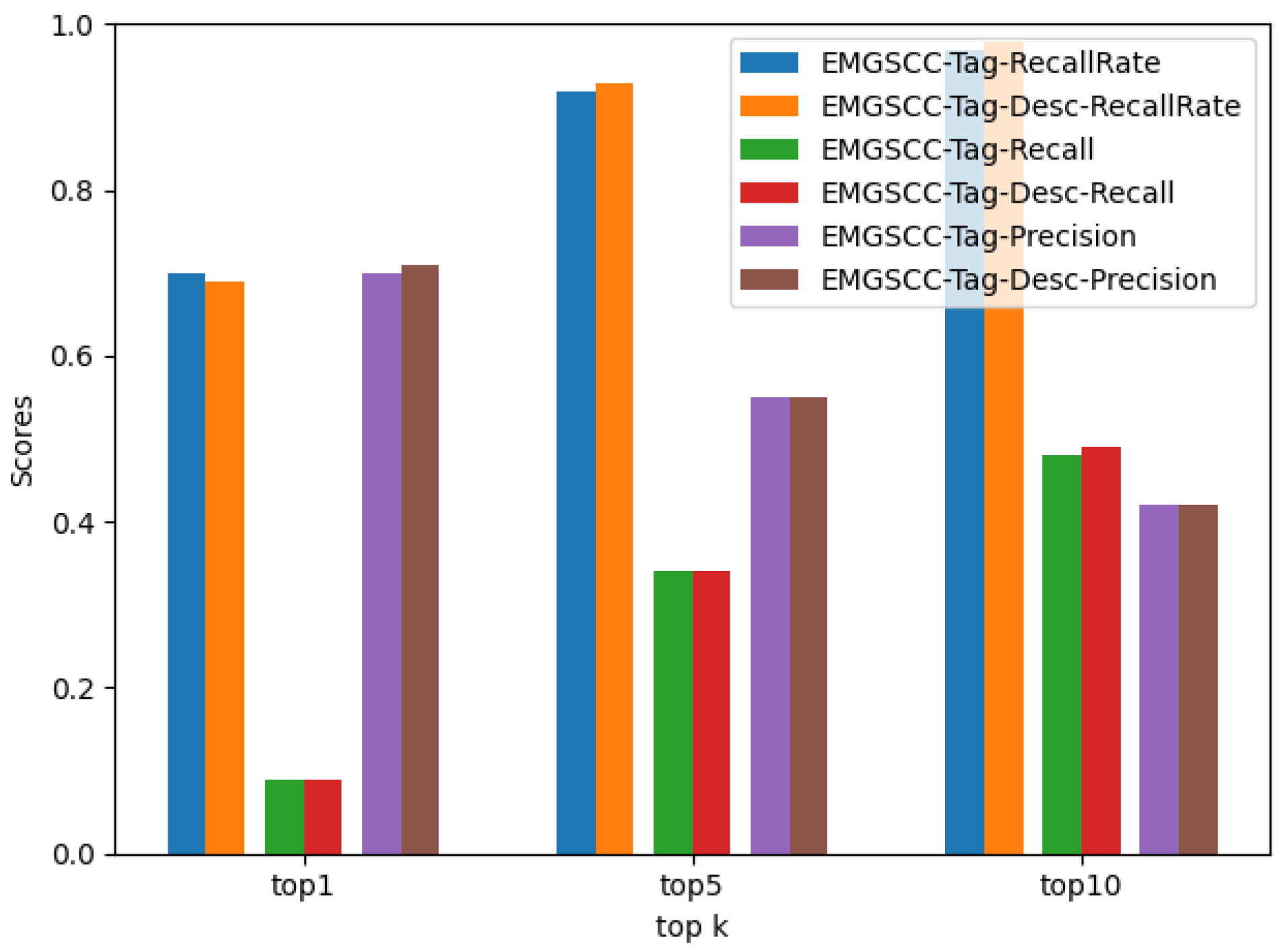
To answer RQ3, we constructed EMGSCC-Tag-Desc, which introduces the functional description of a dependency library on the basis of EMGSCC-Tag. The results are shown in Table 5 and Figure 7. Overall, we find no significant differences between the results of EMGSCC-Tag and EMGSCC-Tag-Desc. Compared with EMGSCC-Tag, EMGSCC-Tag-Desc has a slight improvement on most metrics, yet no obvious improvement can be noticed, indicating that the introduction of functional description does not have a significant impact on the performance of the generation model.
Table 5.
Top k Accuracy of EMGSCC-Tag-Desc.
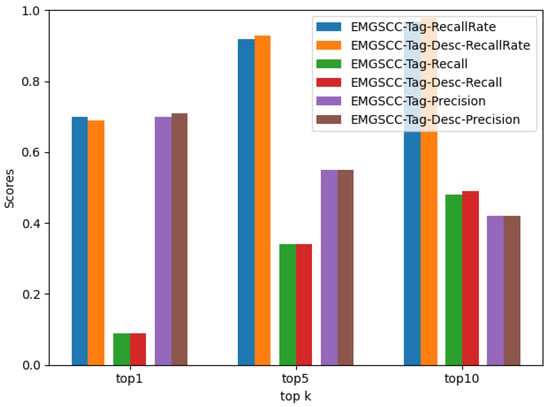
Figure 7.
The performance comparison between EMGSCC-Tag and EMGSCC-Tag-Desc.
Specifically, according to Table 4 and Table 5 and Figure 7, regarding the metrics , , , and , EMGSCC-Tag-Desc improved by 0.01 compared to EMGSCC-Tag. On the metrics , , , and , the EMGSCC-Tag-Desc obtains the same score as the EMGSCC-Tag model. In terms of , EMGSCC-Tag-Desc is 0.01 less than EMGSCC-Tag.
5. Discussion
5.1. Why Does EMGSCC Work Well?
Following the enhancement path, we construct EMGSCC using a neural language model with content-based attention and embed various domain information into the dependency library representation. EMGSCC first considers the order-independent feature of the dependency library in sequential-based models and achieves the status of being permutation-invariant to the inputs. The satisfaction of invariant representations of members in the set is paralleled by the preservation of inherent relationships between libraries. Then, EMGSCC adopts multi-label classification to solve the problem of disordered outputs. The above feature can preserve the language features of the dependency code and use the most common neural language models in the source code generation field as well. Moreover, the dependency library pattern has proven to be effective in dependency library recommendation [14]; however, how to obtain such information is still worth exploring. Our approach of introducing domain information to learn dependency code usage patterns is a novel attempt, and in general, learning from accurate domain knowledge works better than mining directly from training projects.
Compared to the association rule-based mining model LibRec, EMGSCC demonstrates its superiority in indirectly learning usage patterns by injecting domain information. This is likely due to the following reasons: (1) Compared with rule mining, deep learning models have the ability to obtain richer dependency library embeddings, which will assist in the domain highlighting of inherent relations between different libraries. (2) Relatively, domain labels are easier to obtain usage patterns than directly mining them from the training data. In addition, findings show that the integration of functional descriptions does not substantially improve the generation model. This can be attributed to the following reasons: (1) The functional description is quite a mixed bag and brings bits of domain information and blending noises as well. (2) The domain representation obtained by the simple and crude embedding method in a functional description leads to poor effectiveness, which may be improved by more specialized software engineering domain pretraining models.
Using neural language models to generate such code does not always benefit everyone compared to data-driven models. There are several limitations to the neural network architecture. On the one hand, the parameter tuning and training of neural networks are relatively difficult, which also sets obstacles for related models. In particular, the deep neural network places higher demands on the quality and quantity of the dataset; otherwise, it is more likely to experience overfitting and convergence problems. On the other hand, adopting neural network architectures tends to be more sensitive to dependencies that are particularly widespread (adopted by most projects), which may lead to the high priority of generating more general dependency libraries, squeezing the probabilities of project-specific dependency libraries that are more significant for developers. A separate approach may be required for such prevalent dependency libraries.
5.2. Threats to Validity
Internal Validity. This paper chooses LibRec as the baseline model, and we regenerate LibRec for a fair comparison between LibRec and EMGSCC since we customize the new dataset and adopt new metrics. Although we have carefully checked the regenerated code of LibRec, there is still the possibility of potential errors. Furthermore, there is a clear disparity between EMGSCC and the baseline model when it comes to technical solutions and the time span, which does not adequately accentuate the superiority of EMGSCC. More comprehensive analysis is needed.
External Validity. External validity determines how generalizable the generation results are. Although we have tried to cover the commonly used dependency libraries, this does not mean that EMGSCC can handle all the libraries that appear in the pending projects. When the input set contains more dependency libraries that do not appear in the training set, the accuracy of generation cannot be guaranteed. Therefore, we are limited to what we have learned so far in this research.
Construct Validity. Github has an abundance of credible projects uploaded by many experienced programmers, and projects with more stars are more trustworthy. To reduce construct threat, we only considered projects with more than 17 stars and 10 dependency libraries. Therefore, we have high confidence in the DDDI dataset and EMGSCC results. In addition, to cope with the selection of appropriate evaluation metrics, we have employed multiple metrics, including , , , which are also used by the baseline model LibRec. In conclusion, we see little threat to construct validity.
6. Related Work
6.1. Dependency Recommendation and Generation
We can see the substantial research dependency in library recommendation and generation. Previous studies to make recommendations on dependency libraries used already working libraries to generate the others. LibRec [14] adopts association rule mining and collaborative filtering to recommend libraries. LibFinder [5] improves the performance of LibRec by linking the usage of libraries and the semantic similarity of the identifiers of the source code. DSCRec [25] conducted an empirical study that proposes domain-specific categories and demonstrates the practicality of maintaining libraries through domain-specific categories.
In the last few years, automatic library migration has become a research hotspot. He et al. [26] conducted a descriptive mixed methods study on how and why library migrations happen in Java software projects. DeepLib [2] accepted a set of library versions and forecast the subsequent versions of related libraries using deep neural networks. EvoPlan [27] made recommendations of different upgrade plans given a pair of library versions as input using migration graphs. As we all have realized the significance of usage patterns in dependency library, Pattemika [13] proposed a pattern mining tool via static code differencing technique for automatic library migration. He et al. [28] have formulated the library migration problem as a mining and ranking problem, developed four advanced metrics for ranking, and achieved the most favorable results in the problem domain.
Research on library recommendation and generation has received less attention, and more studies focus on library migration with various deep learning algorithms. Meanwhile, these studies confirm the prioritization of library usage patterns, employing various static mining methods to extract them. We believe that introducing domain information and using the neural language model can better learn usage patterns and fit the language features of the dependency code.
6.2. Neural Language Model
Bengio et al. [29] proposed the neural language model earlier, which converts discrete representations into continuous representations and solves the curse of dimensionality and the modeling difficulties between latent relations between words. Mikolov et al. [30] and Sundermeyer et al. [31] extended neural language models to recurrent neural network architectures and adopted context-dependent target vectors and LSTM cells to build downstream tasks. In the source code analytics area, neural language models are widely used in tasks such as semantic code search [32], source code generation [33], and source code summarization [34]. The sequence-to-sequence model under the encoder-decoder architecture is a typical practice. Further, augmentations of sequential-based models include pointer networks [35], attention mechanisms [36], type constraints [37], etc. In addition, TreeLSTM [38] and Transformer [39] have also been introduced to build neural language models.
6.3. The Importance of Contexts
During the recent years, the use of contextual information for code representation learning to handle various downstream tasks has gradually gained traction. The definition and scope of the context and the integrating and modeling approaches are particularly relevant to the relevant researchers, as well as to our own work. Nguyen et al. [40] designed a local context-incorporating method for source code to learn to distinguish the lexical tokens in different syntactic and type contexts. Sun [41] performed the function-level context introduction, which integrated the critical path from contextual functions into the code representation vectors for better query accuracy. Liu et al. [42] recommended method names with a global context, considering the local context, the project-specific context, and the documentation of the method simultaneously. The idea of this paper is similar, yet we focus on external domain information of context from relatively reliable sources, bringing more opportunities to identify potential dependency usage patterns to distinguish different dependency libraries.
7. Conclusions
This study addresses the problem of how to reasonably generate the system configuration code, which shows distinctive features compared with the essential source code. To figure out this issue, we first organized an enhancement path in a self-consistent manner. Taking Maven dependency code as the typical instance, we proposed an accompanying dependency library generation approach that integrated language features and domain information. We used context-based attention to cope with the unordered input library set and the multi-label classification algorithm to deal with the output. In addition, we attempted to learn more usage patterns from domain tags and functional descriptions. According to our evaluation, our approach outperformed baselines on all selected metrics. As part of our future investigations, we plan to learn usage patterns from the more significant domain knowledge obtained by aggregating and overlapping the bounded context information derived from the Maven dependency graph [10]. We expect the inherent relations learned from the dependency graph would boost higher performance.
Author Contributions
Conceptualization, Y.L. and C.Y.; methodology, software, C.Y. and Y.L.; formal analysis, C.Y.; investigation, C.Y.; resources, C.Y.; writing—original draft preparation, C.Y.; writing—review and editing, Y.L. and C.Y.; supervision, Y.L.; project administration, Y.L.; funding acquisition, Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Science and Technology Commission of Shanghai Municipality (No. 20511102703).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://github.com/Ada12/dependency-generation-dataset, accessed on 8 June 2022.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| OTS components | Off-The-Shelf components |
| DSL | Domain-Specific Language |
| SCC | System Configuration Code |
| NLSCG | Natural Language-based Source Code Generation |
| EMGSCC | Enhanced Model for Generating System Configuration Code |
| DDDI | Dependency Dataset with Domain Information |
| API | Application Programming Interfaces |
| DC usage pattern | Dependency Code usage pattern |
| DL | Dependency Libraries |
| NL | Natural Language |
| ADL | Accompanying Dependency Libraries |
| CF | Collaborative Filtering |
| NLM | Neural Language Model |
| DI | Domain Information |
| DK | Domain Knowledge |
References
- Bass, L.; Weber, I.; Zhu, L. DevOps: A Software Architect’s Perspective; Addison-Wesley Professional: Boston, MA, USA, 2015. [Google Scholar]
- Nguyen, P.T.; Di Rocco, J.; Rubei, R.; Di Sipio, C.; Di Ruscio, D. DeepLib: Machine translation techniques to recommend upgrades for third-party libraries. Expert Syst. Appl. 2022, 202, 117267. [Google Scholar] [CrossRef]
- Allamanis, M.; Barr, E.T.; Devanbu, P.; Sutton, C. A survey of machine learning for big code and naturalness. ACM Comput. Surv. (CSUR) 2018, 51, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Thung, F.; Lo, D.; Lawall, J. Automated library recommendation. In Proceedings of the 2013 20th Working Conference on Reverse Engineering (WCRE), Koblenz, Germany, 14–17 October 2013; pp. 182–191. [Google Scholar]
- Ouni, A.; Kula, R.G.; Kessentini, M.; Ishio, T.; German, D.M.; Inoue, K. Search-based software library recommendation using multi-objective optimization. Inf. Softw. Technol. 2017, 83, 55–75. [Google Scholar] [CrossRef]
- Sun, Z.; Liu, Y.; Cheng, Z.; Yang, C.; Che, P. Req2Lib: A Semantic Neural Model for Software Library Recommendation. In Proceedings of the 2020 IEEE 27th International Conference on Software Analysis, Evolution and Reengineering (SANER), London, ON, Canada, 18–21 February 2020; pp. 542–546. [Google Scholar]
- Nguyen, P.T.; Di Rocco, J.; Rubei, R.; Di Sipio, C.; Di Ruscio, D. Recommending Third-Party Library Updates with LSTM Neural Networks 2021. Available online: http://ceur-ws.org/Vol-2947/paper7.pdf (accessed on 2 June 2022).
- Yang, C.; Liu, Y.; Yin, C. Recent Advances in Intelligent Source Code Generation: A Survey on Natural Language Based Studies. Entropy 2021, 23, 1174. [Google Scholar] [CrossRef] [PubMed]
- Houidi, Z.B.; Rossi, D. Neural language models for network configuration: Opportunities and reality check. arXiv 2022, arXiv:2205.01398. [Google Scholar]
- Benelallam, A.; Harrand, N.; Soto-Valero, C.; Baudry, B.; Barais, O. The maven dependency graph: A temporal graph-based representation of maven central. In Proceedings of the 2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR), Montreal, QC, Canada, 25–31 May 2019; pp. 344–348. [Google Scholar]
- Soto-Valero, C.; Harrand, N.; Monperrus, M.; Baudry, B. A comprehensive study of bloated dependencies in the maven ecosystem. Empir. Softw. Eng. 2021, 26, 45. [Google Scholar] [CrossRef]
- Apache Maven Pom Introduction. Available online: https://maven.apache.org/guides/introduction/introduction-to-the-pom.html (accessed on 5 July 2022).
- Blech, E.; Grishchenko, A.; Kniazkov, I.; Liang, G.; Serebrennikov, O.; Tatarnikov, A.; Volkhontseva, P.; Yakimets, K. Patternika: A Pattern-Mining-Based Tool For Automatic Library Migration. In Proceedings of the 2021 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), Wuhan, China, 25–28 October 2021; pp. 333–338. [Google Scholar]
- Thung, F.; Wang, S.; Lo, D.; Lawall, J. Automatic recommendation of API methods from feature requests. In Proceedings of the 2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE), Silicon Valley, CA, USA, 11–15 November 2013; pp. 290–300. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008.
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling laws for neural language models. arXiv 2020, arXiv:2001.08361. [Google Scholar]
- Yin, P.; Neubig, G. A syntactic neural model for general-purpose code generation. arXiv 2017, arXiv:1704.01696. [Google Scholar]
- Rabinovich, M.; Stern, M.; Klein, D. Abstract syntax networks for code generation and semantic parsing. arXiv 2017, arXiv:1704.07535. [Google Scholar]
- Zhong, H.; Xie, T.; Zhang, L.; Pei, J.; Mei, H. MAPO: Mining and recommending API usage patterns. In European Conference on Object-Oriented Programming; Springer: Berlin/Heidelberg, Germany, 2009; pp. 318–343. [Google Scholar]
- Vinyals, O.; Bengio, S.; Kudlur, M. Order Matters: Sequence to sequence for sets. In Proceedings of the 4th International Conference on Learning Representations (ICLR 2016), San Juan, Puerto Rico, 2–4 May 2016; Conference Track Proceedings. Bengio, Y., LeCun, Y., Eds.; OpenReview.net: Amherst, MA, USA, 2016. [Google Scholar]
- Zhang, M.L.; Zhou, Z.H. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2013, 26, 1819–1837. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Sorower, M.S. A Literature Survey on Algorithms for Multi-Label Learning; Oregon State University: Corvallis, OR, USA, 2010; Volume 18, pp. 1–25. [Google Scholar]
- Godbole, S.; Sarawagi, S. Discriminative methods for multi-labeled classification. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2004; pp. 22–30. [Google Scholar]
- Katsuragawa, D.; Ihara, A.; Kula, R.G.; Matsumoto, K. Maintaining Third-Party Libraries through Domain-Specific Category Recommendations. In Proceedings of the 2018 IEEE/ACM 1st International Workshop on Software Health (SoHeal), Gothenburg, Sweden, 27 May–3 June 2018. [Google Scholar]
- He, H.; He, R.; Gu, H.; Zhou, M. A large-scale empirical study on Java library migrations: Prevalence, trends, and rationales. In Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Athens, Greece, 20 August 2021; pp. 478–490. [Google Scholar]
- Rubei, R.; Di Ruscio, D.; Di Sipio, C.; Di Rocco, J.; Nguyen, P.T. Providing Upgrade Plans for Third-party Libraries: A Recommender System using Migration Graphs. arXiv 2022, arXiv:2201.08201. [Google Scholar] [CrossRef]
- He, H.; Xu, Y.; Ma, Y.; Xu, Y.; Liang, G.; Zhou, M. A multi-metric ranking approach for library migration recommendations. In Proceedings of the 2021 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), Honolulu, HI, USA, 9–12 March 2021; pp. 72–83. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P. A neural probabilistic language model. In Advances in Neural Information Processing Systems 13; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Interspeech 2010, Makuhari, Japan, 26–30 September 2010; Volume 2, pp. 1045–1048. [Google Scholar]
- Sundermeyer, M.; Schlüter, R.; Ney, H. LSTM neural networks for language modeling. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Balog, M.; Gaunt, A.L.; Brockschmidt, M.; Nowozin, S.; Tarlow, D. Deepcoder: Learning to write programs. arXiv 2016, arXiv:1611.01989. [Google Scholar]
- Ling, W.; Grefenstette, E.; Hermann, K.M.; Kočiskỳ, T.; Senior, A.; Wang, F.; Blunsom, P. Latent predictor networks for code generation. arXiv 2016, arXiv:1603.06744. [Google Scholar]
- Chen, Q.; Zhou, M. A neural framework for retrieval and summarization of source code. In Proceedings of the 2018 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE), Montpellier, France, 3–7 September 2018; pp. 826–831. [Google Scholar]
- Lee, D.; Yoon, J.; Song, J.; Lee, S.; Yoon, S. One-shot learning for text-to-sql generation. arXiv 2019, arXiv:1905.11499. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Krishnamurthy, J.; Dasigi, P.; Gardner, M. Neural semantic parsing with type constraints for semi-structured tables. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 1516–1526. [Google Scholar]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. arXiv 2015, arXiv:1503.00075. [Google Scholar]
- Stylianou, N.; Vlahavas, I. ET: Entity-transformers. coreference augmented neural language model for richer mention representations via entity-transformer blocks. arXiv 2020, arXiv:2011.05431. [Google Scholar]
- Nguyen, A.T.; Nguyen, T.D.; Phan, H.D.; Nguyen, T.N. A deep neural network language model with contexts for source code. In Proceedings of the 2018 IEEE 25th International Conference on Software Analysis, Evolution and Reengineering (SANER), Campobasso, Italy, 20–23 March 2018; pp. 323–334. [Google Scholar]
- Sun, Z. Research on Code Search Using Semantic Vector Matching. Master’s Thesis, Tongji University, Shanghai, China, 2021. [Google Scholar]
- Liu, F.; Li, G.; Fu, Z.; Lu, S.; Hao, Y.; Jin, Z. Learning to Recommend Method Names with Global Context. arXiv 2022, arXiv:2201.10705. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).