2.1. On the Challenges and Responses of System Configuration Code Generation
In recent years, the field of software development has been undergoing a dramatic evolution. With the advent of middle-end platforms packaging the underlying logic and data capabilities, concise source codes, manifest logic layering, and definite module disassembly have become mainstream. When developing, deploying, operating, and maintaining software systems, the specialized code that is closely coupled with each software development target gradually begins to expand, and the connotation of the code itself is constantly changing and iterating. In addition to the essential source code during the development process, driven by the Infrastructure as Code (Iac), Configuration as Code (CaC) and cloud-native concepts, increasing system configuration code exists in the system implementation explicitly and plays a crucial role. System configuration code disassembles various integrated configuration information of the system, focusing on the compilation and integration targets.
In this paper, we examine a typical instance of system configuration code: Maven dependency code. Dependency code allows developers to leverage well-founded programming utilities without re-implementing software functionalities from scratch [
2]. It plays a vital role in improving the quality of software projects. The first step in enabling effective reuse is to provide the projects with the proper libraries, followed by considering how to implement the libraries at the functional level. Current studies about dependency code pay close attention to accompanying dependency recommendations [
4], dependency migration [
2], global dependency graphs [
10], and detection of bloated dependencies [
11].
Dependency code is a semi-structured XML-like text, which contains information about the project and configuration details used by Maven to build the project [
12] and identified by dependency coordinates (groupId, artifactId, version). The dependency code can be represented as a multiway tree, where each child node in the tree is an XML tag. There are two distinct language features and relatively specific usage patterns of dependency code that require significant attention.
First of all, the dependency code is more concise than the essential source code, presenting remarkable weak-constraint features. The essential source code takes AST as an intermediate structure for code representation, while the XML structure-based dependency code is more straightforward with fewer node types. Generally speaking, all nodes in AST can be divided into terminal and non-terminal nodes. These two work together to express syntax and semantics; the non-terminal nodes represent the most syntactic information. However, the structural scheme of non-terminal nodes in the dependency code is prefabricated and cannot represent critical semantics as well. In contrast, terminal nodes contribute more semantic concerns: the dependency coordinates.
Next, the dependency code also has an order-independent feature. Rather than arranging libraries based on importance, priority, and functional subdivision, programmers construct dependency code by randomly inserting specific libraries under the Dependencies tag. Therefore, the functionalities expressed by a particular dependency library have no connection with its tandem position at the same tier; the out-of-order dependency libraries in the same tier would not affect their actual semantics.
Lastly, the usage pattern is especially significant for dependency code [
13]. In contrast to the varied API (Application Programming Interfaces) usage patterns derived from object-oriented languages, developers are faced with a more straightforward and rudimentary dependency code. Despite the large number and rapid evolution of open-source libraries, developers spend considerable effort selecting libraries and continuously iterating. For usage pattern learning, models encounter challenges when mining [
5,
14] and learning inherent features of combinational dependency libraries under different scenarios, such as achieving specific cross-cutting functionalities, constructing specific frameworks, etc. Due to the concise nature of dependency code, it is difficult to learn usage patterns directly from native code itself. Therefore, incorporating domain knowledge into dependency libraries is a worthwhile approach.
Based on the above analysis of the challenges for generating configuration code, enhancement elements of the model were identified, among which the most accessible are the language features and domain knowledge. Our previous research [
8] proposed a core technical enablers landscape, which provides practical guidelines about building source code generation tasks from a holistic perspective. Detailed descriptions of the technical enablers for structural modeling of the source code are given in the landscape. To be specific, the landscape summarizes token-based constraints for code with weak structural modeling requirements. Of this type of constraints, a particular focus should be placed on the type of constraints that simplify code generation to targeted slot prediction based on demonstrative functional types of different domain characteristics. Our previous research results, along with the analysis of these challenges, indicate that we can implement the dependency code generation task in this paper in the following foreseeable route. Firstly, we select the token-based constraints [
8] to capture weaker syntactic features, namely concentrating on the dependency coordinates. Secondly, we endeavor to ignore the sequential order while constructing dependency generation models; to be specific, we (1) reduce the importance of the order in sequential-based models by formulating strategies [
6]; or (2) select order-independent models directly. Finally, we suggest integrating domain knowledge into the modeling process during dependency library representations.
2.2. Enhancement Path for Generating Dependency Code
We have previously studied [
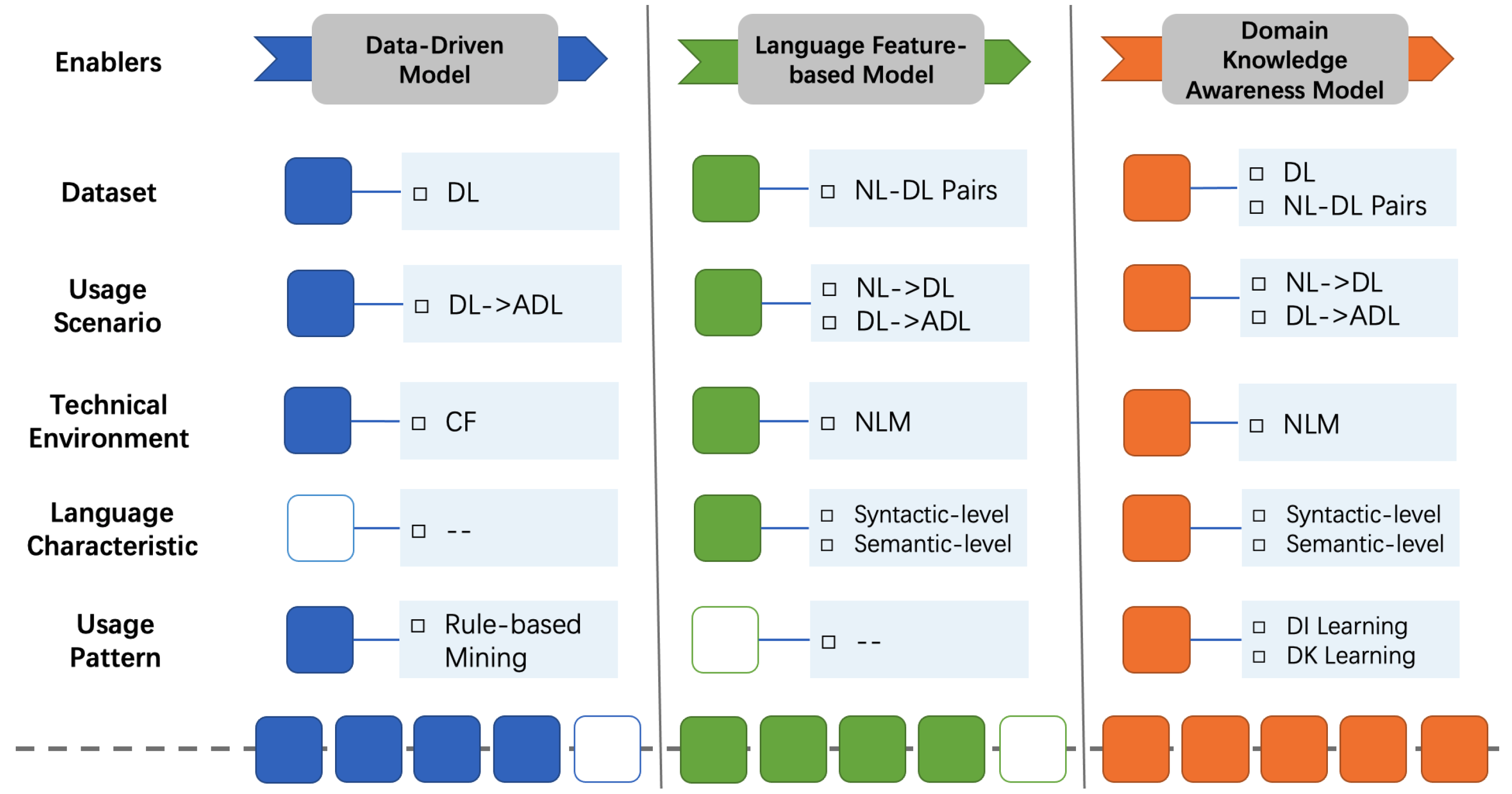
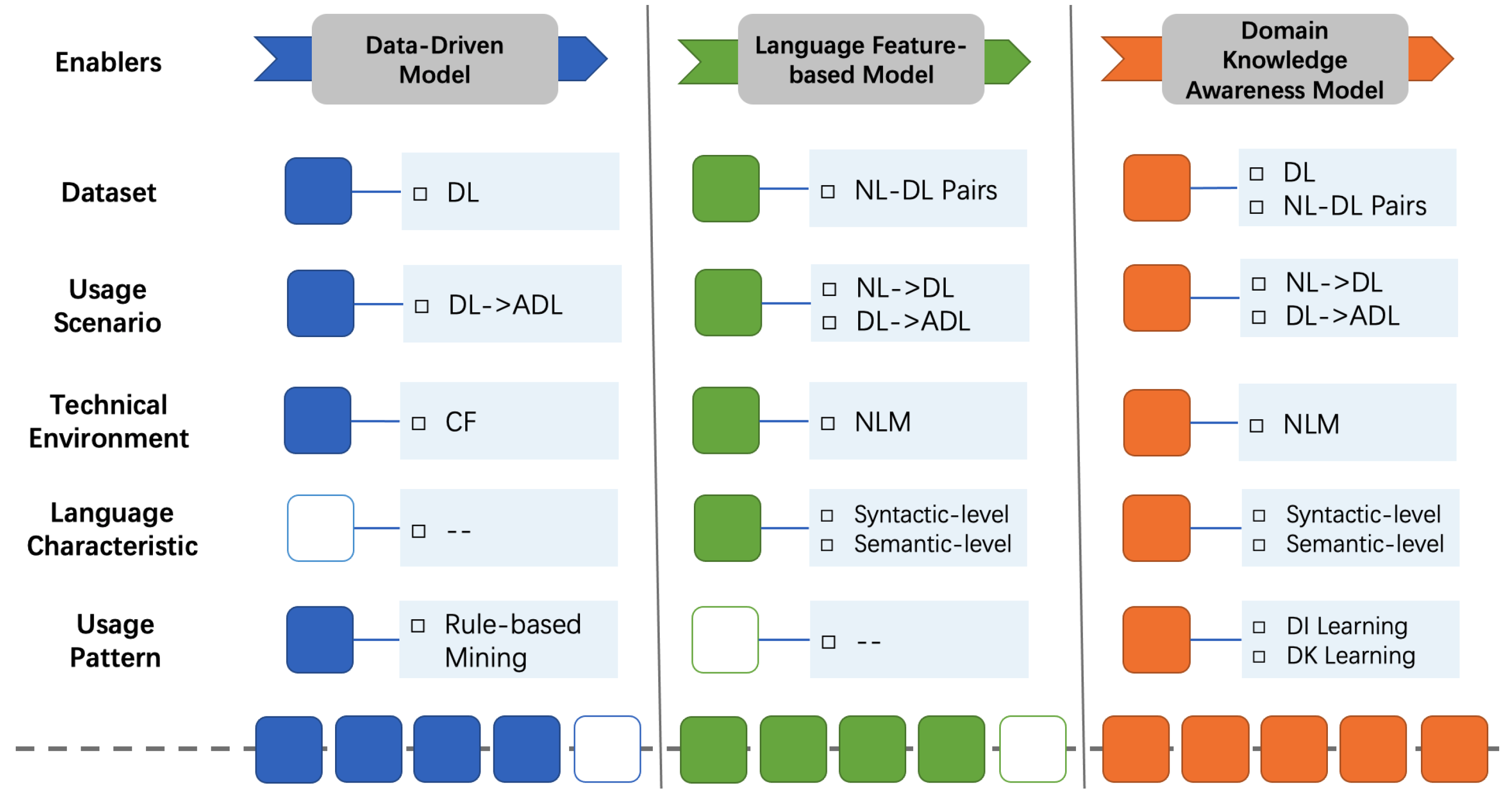
8] the critical handlers of code generation solutions, summarizing various algorithms, architectures, tools, and strategies derived from machine translation and code analytics, which we consider to be the technical enablers. Drawing inspiration from these achievements, we attempt to enhance the intelligent generation model for dependency code. To be specific, we condense and combine the enablers of generating dependency code at different levels. These enablers include a dataset for determining the upper bound of the model, a usage scenario of a more user-friendly and innovative, technical environment for driving the model architecture, language characteristics of relative explicitness, and a usage pattern to be explored intensively. On this basis, we introduce an enhancement path shown in
Figure 1, which comprehensively considers the research actuality, the inherent characteristics of dependency code, and the crucial handlers of the existing code generation framework and technology stack [
8]. Foreseeable models for automatically generating dependency code fall into three different levels, namely data-driven models, language feature-based models and domain knowledge awareness models, paying close attention to five enablers that impact the model design. Therein, the content and quality of the dataset affect the scope of dependency code generation scenarios and the applicability of model algorithms. The popularity of open-source repositories, and the continuous development of technical environments, especially neural language models, have brought more feasibility to broadening the generation scenarios and introducing language characteristics and usage patterns. Overall, along the enhancement path, more powerful models take into account language features specific to dependency code, rather than textual information or essential source code. These three types of essence models reflect different model design priorities at various times and guide more practical directions for the ongoing enhancement of subsequent models.
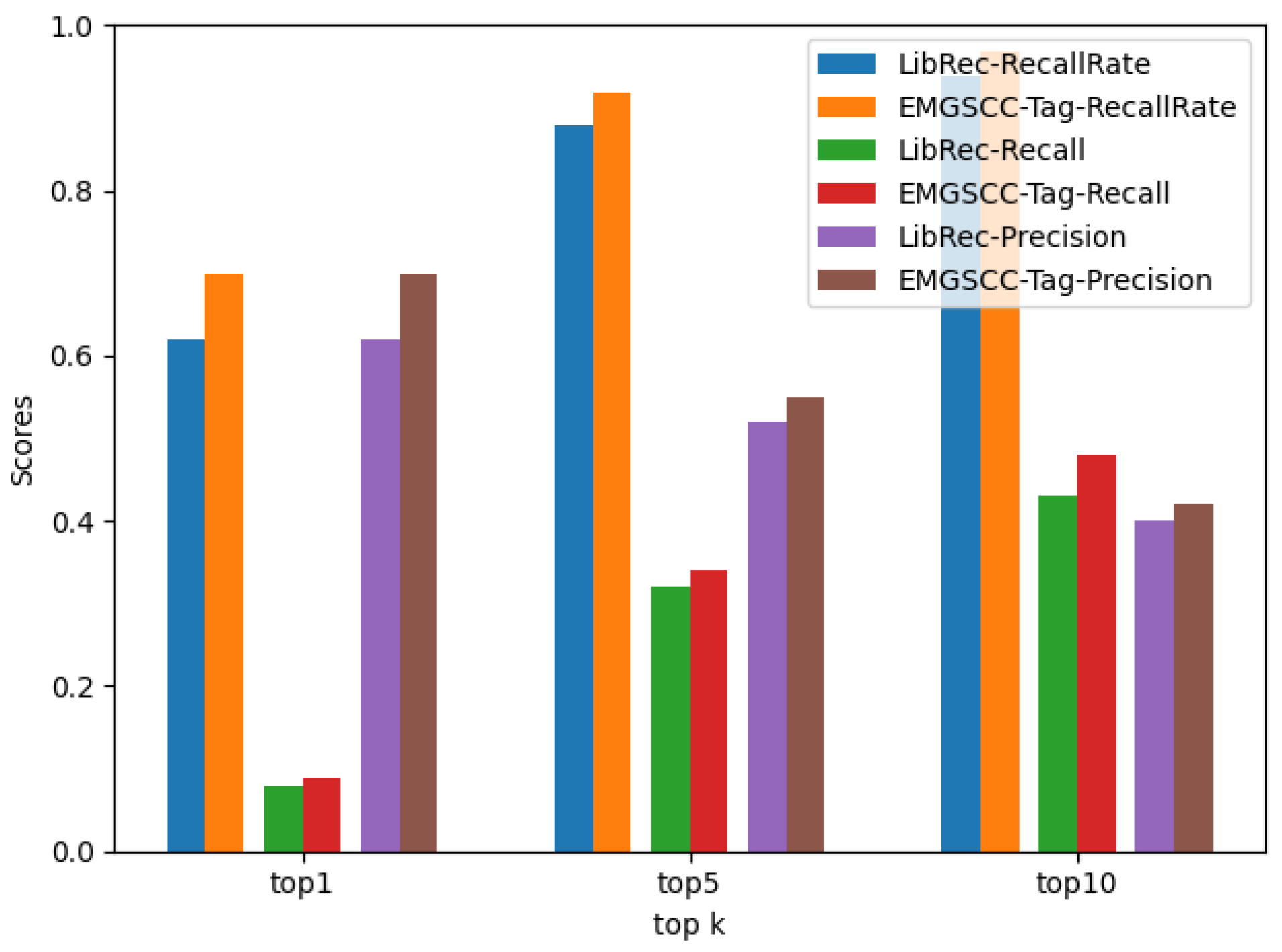
Data-Driven Model. A classic recommendation model can easily identify the intuitive values and inherent relationships of the current dataset. Considering the technical environment at the time, researchers proposed data-driven models to discover or summarize potential relations according to their first impression. By omitting the additional domain knowledge, data-driven models pay scant attention to what kind of information the data contains, instead focusing on the latent state of the whole dataset, which is mostly derived from statistical-based algorithms. LibRec [
4] is a typical example, which proposes a hybrid approach that combines association rule mining and collaborative filtering to recommend relevant libraries for developers.
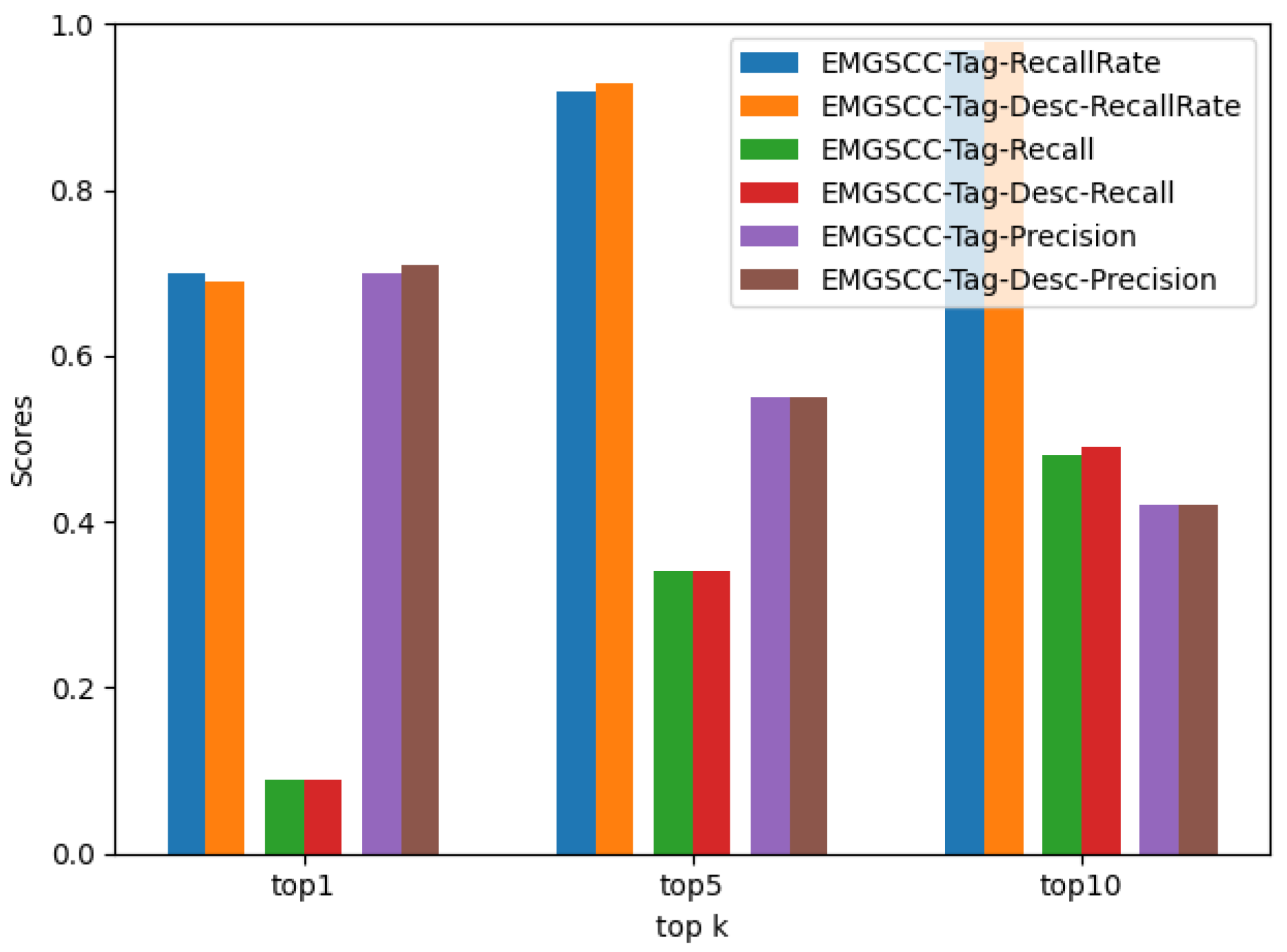
Language Feature-based Model. The target language of this paper is the system configuration code, and the generation model is discussed with the dependency code as a typical example. However, the data-driven models are too straightforward to take into account the characteristics of the dependency code that are obviously different from the underlying data item. In this context, a dependency code is a particular source code, and the primary approach is launching intelligent exploration using the neural language model. With the release of brand-new datasets [
6] and the continuous iteration of modeling algorithms [
15,
16], in addition to recommending accompanying dependency libraries, it has become more practical and feasible to carry out intelligent exploration such as natural language-based dependency library generation. In terms of source code modeling, the integration of syntactic and semantic level information has proven to be effective in capturing and learning more features [
17,
18]. In contrast to essential source code, a dependency code exhibits its peculiarities, which are also suitable for a system configuration code. Starting with the syntax of a dependency code, its most highlighted features include its conciseness, prefabrication, and unordered lists. Incorporating these features into the model design requires treating the skeleton as fixed, while filling the slots of the skeleton empirically. Therefore, the generation of a dependency code is converted into the purposeful generation of dependency libraries. The unordered list prompts the generation model to ignore the sequential order of dependency libraries. Practical approaches include reducing the importance of the order in a sequential-based model or directly selecting an order-independent model. The semantics of dependency codes is very intuitive, importing given third-party libraries to access encapsulated methods and tools. Yet few studies have investigated the deep-level semantics of dependency codes, such as the combination of function and framework-oriented multi-dependency libraries. These deep-level semantics can facilitate the rapid implementation of a function module and will be enhanced by learned usage patterns.
Domain Knowledge Awareness Model. After exploring the main routes of dependency code generation, the last enhancement level we will focus on is how to exploit the dependency code usage pattern effectively. Since the dependency code usage pattern (DC usage pattern) is not defined, we refer to the definition of an API usage pattern [
19] and define the DC usage pattern as follows: a DC usage pattern is a set of dependency libraries required to assist in implementing a functionality; one dependency library may play multiple roles in the system. The large and continuously updated dependency libraries create a barrier for developers to import them effectively. Using DC usage patterns would help developers overcome these challenges, and domain information and knowledge are crucial to mining and learning these patterns. The domain information is readily available, as the Maven central repository stores such information for all dependency libraries, such as domain tags and descriptions. In contrast, the domain knowledge of a dependency code is challenging, as it is not obtained by local features derived from single training simples but by aggregating and overlapping the bounded context information from various scenarios. DC usage patterns are capable of providing transferable knowledge to the generation model, which would greatly improve model performance.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}