
Conditional Generative Adversarial Networks for Domain Transfer: A Survey



Abstract
:1. Introduction
- This paper first summarizes the research on the CGAN in the domain transfer.
- This paper summarizes the CGAN from different aspects, such as the loss function, the model variants, application fields and so on, so that readers can easily understand the situation of current research.
- This paper discusses the remaining problems and challenges of CGAN and provides the possible future directions for the development of CGAN.
2. The Development Methods of CGAN
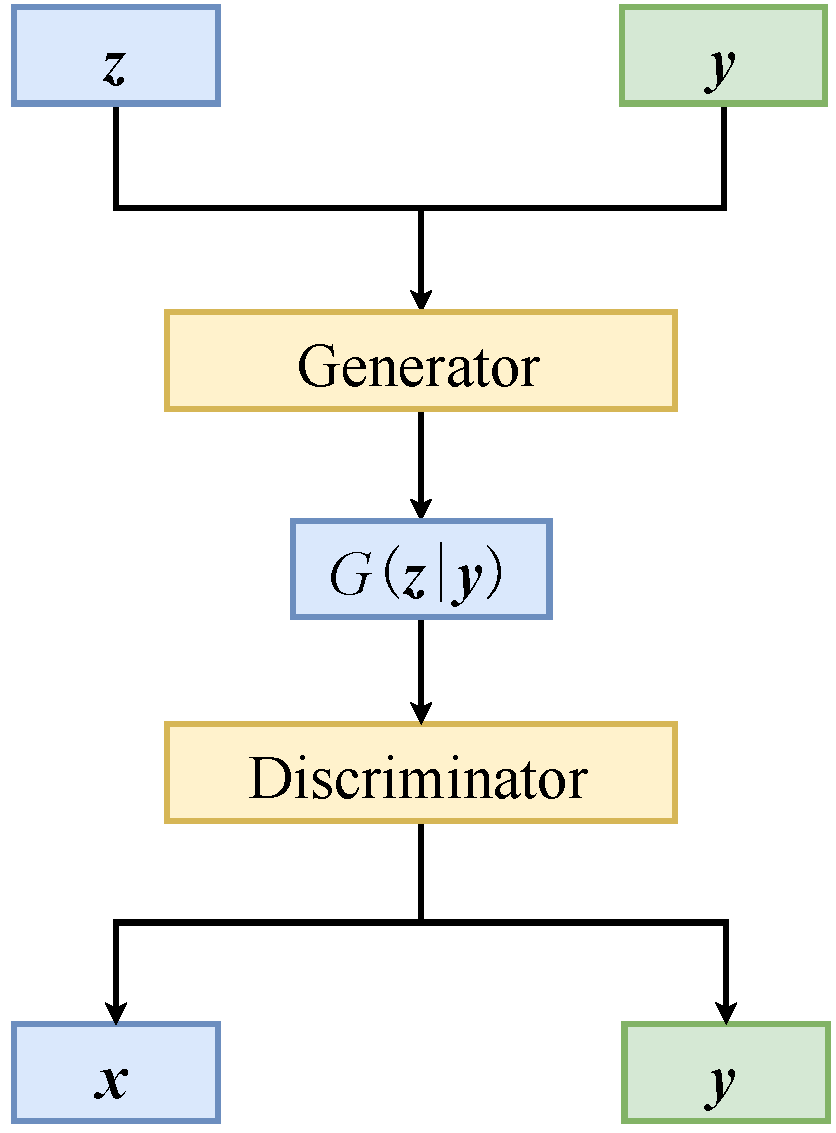
2.1. The Principle of CGAN
2.2. The Improvement of CGAN
2.2.1. The Loss Function of CGAN
- Content loss: This loss is primarily used to measure the gap between the generated image and the user’s expectations. For example, when training CGANs whose task is to transfer gray-level images to color images, the general strategy is to first render a set of color images grayscale and then use the paired gray level image and color image as training data. During the training process, when the generative network inputs gray level images and outputs color images, users usually expect the output results to be as close as possible to the corresponding color image in the training set. Therefore, the loss is expressed as the difference between the values of each pixel in the generated images and the training data, which is generally characterized by mean square error (MSE),Here , and , respectively, represent the number of channels, height and width of the image, represents the -th channel, -th row and -th column of a sample. However, it is worth noting that excessive increases in this loss will lead to image blurring.
- Perception loss: Although content loss can monitor the content of the generated image, it gives more consideration to the underlying semantics of the image due to its pixel-by-pixel differential mechanism. In order to monitor the high-level semantic consistency between the generated image and the actual image, perception loss is often used. In essence, it is still the MSE of two tensors, except that the two tensors are no longer about the image itself, and instead, the feature map is derived from the images with a certain model. For example, ESRGAN [14] takes the generated image and the actual image as the input of the VGG19 network [24], respectively, and then calculates the MSE of hidden variables of each layer in the middle of the VGG19 network. Generally, the expression of the loss is:Here, similarly, , and , respectively, represent the number of channels, height and width of the image, represents the -th channel, -th row and -th column of a sample, and can be any model.
- Hidden variable loss: Both content loss and perception loss are evaluated by the final images generated by the generated network. However, when the network is deep, the idea of end-to-end learning can swiftly cause the problem of gradient disappearance or gradient explosion. For this reason, we would consider monitoring hidden variables in the network. Since hidden variables do not have a dataset as the “standard answer”, it is necessary to design the network architecture in a reasonable way to construct two hidden variables with the same semantics. For example, in the task of improving image resolution, if the generative network is designed to resemble an auto-encoder network, two hidden variables on the symmetry of the bottleneck can be considered to represent the same semantic information, and the difference between them can be designed as the loss of hidden variables. The expression of the loss iswhere and are the distributions of two hidden variables, and is f-divergence. The specific type of f-divergence can be selected according to different tasks.
- Category loss: In some scenarios, the user does not require the generated image to be similar to an expected image, as long as it has the correct category. For example, after training with MNIST, the user requires the network to generate the specified number but does not require the handwriting characteristics of the number. For these requirements, many CGAN models put the generated images into a pre-trained classifier. Therefore, the expression of this kind of loss is similar to the common classification problem, and cross-entropy loss is commonly used. The expression of the loss iswhere represents the classifier and represents the category to which the image belongs.
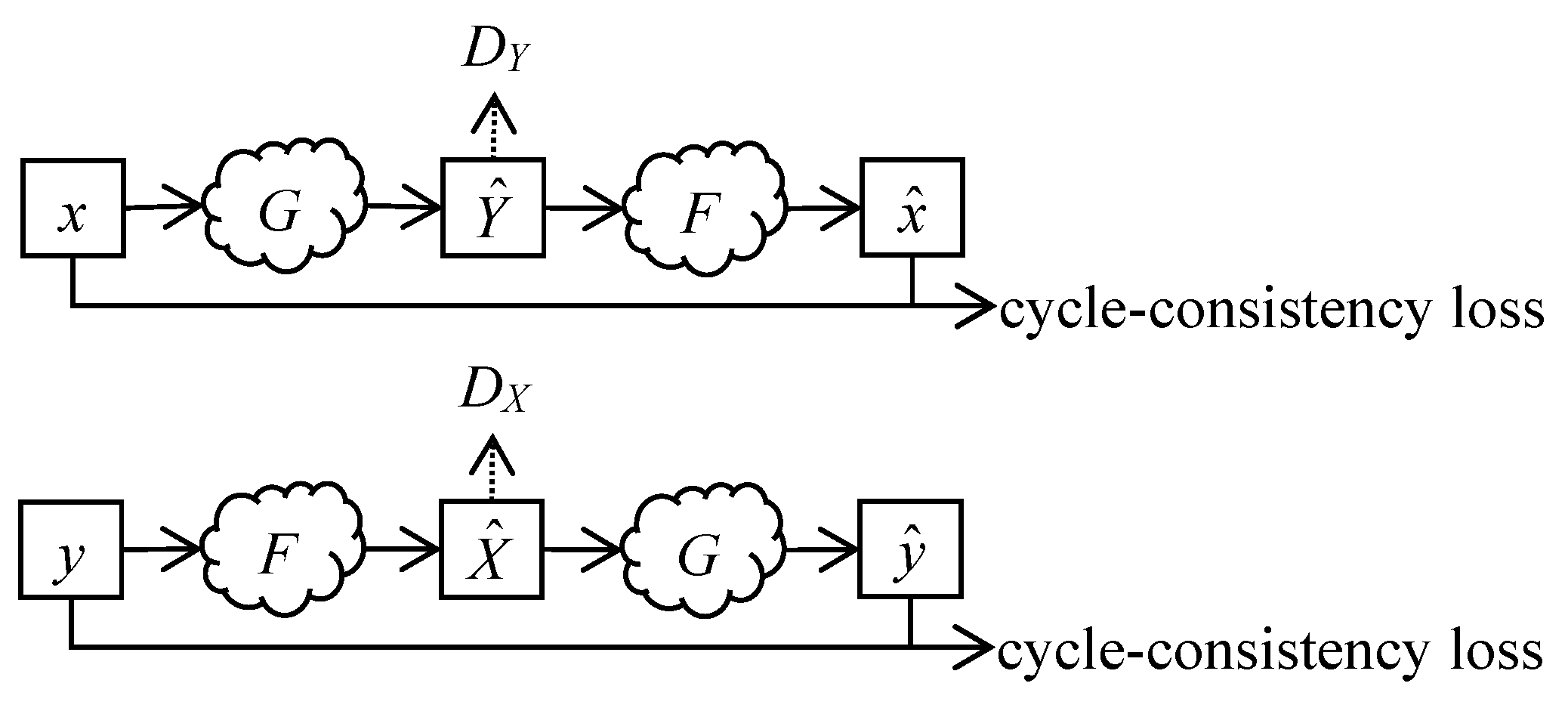
2.2.2. Cycle Consistency
CycleGAN
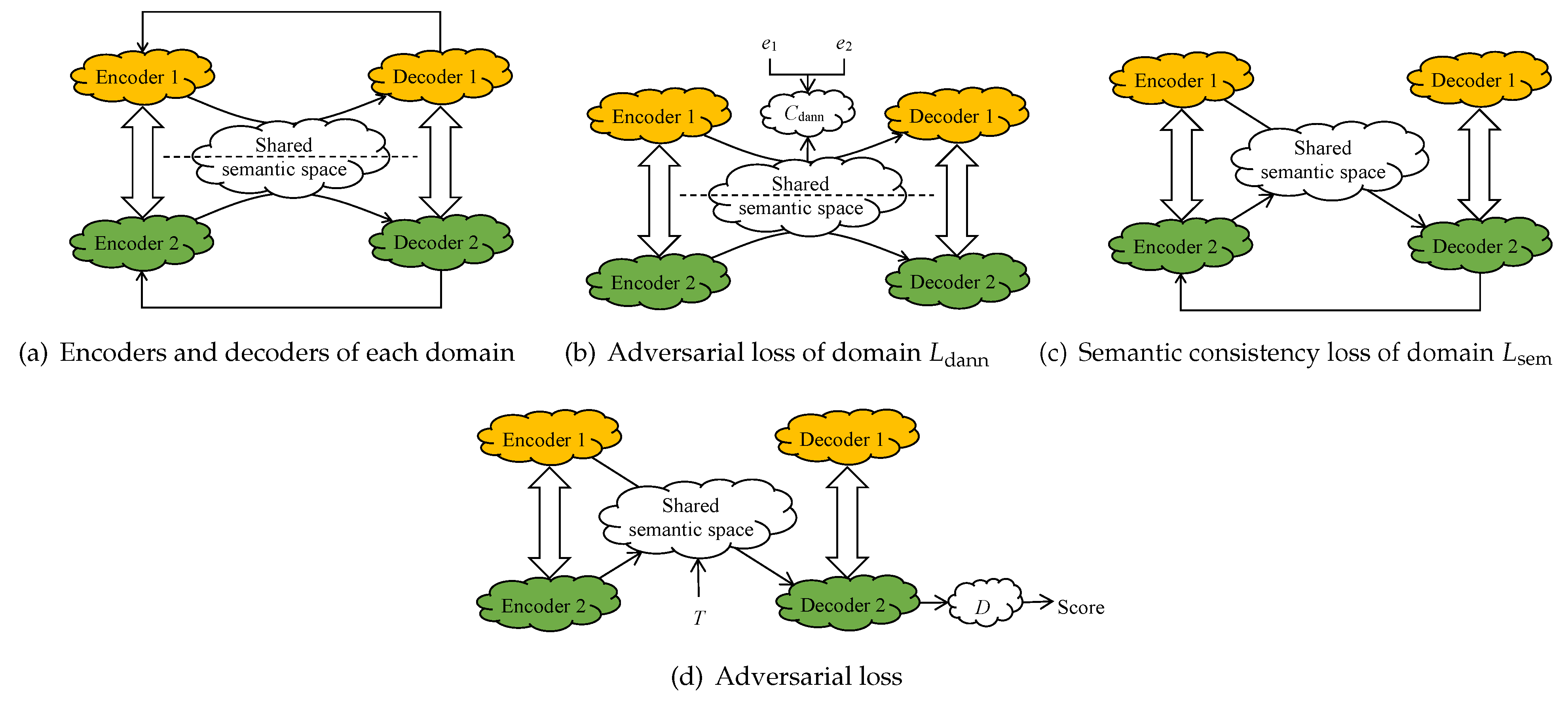
StarGAN
DTN
XGAN
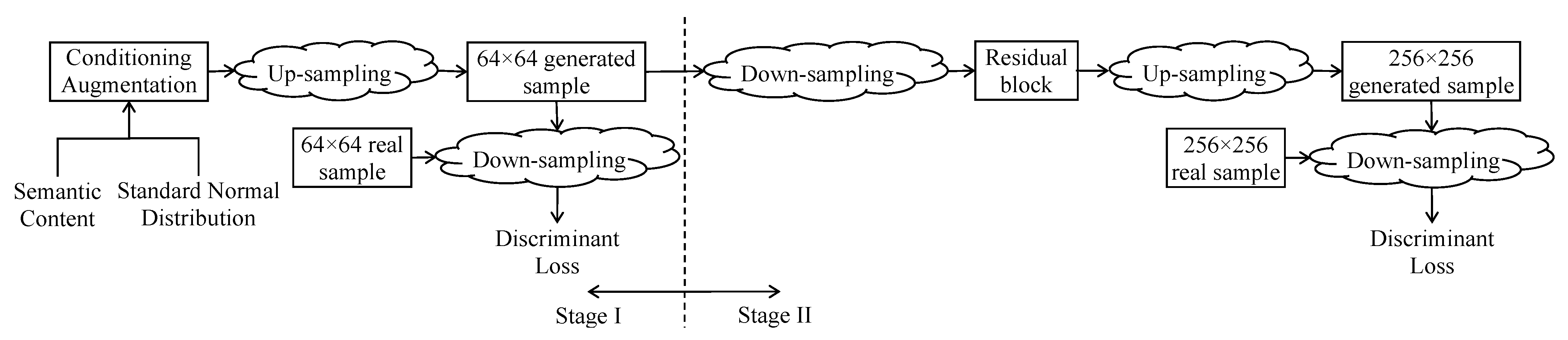
2.2.3. Progressive Enhancement Mechanism
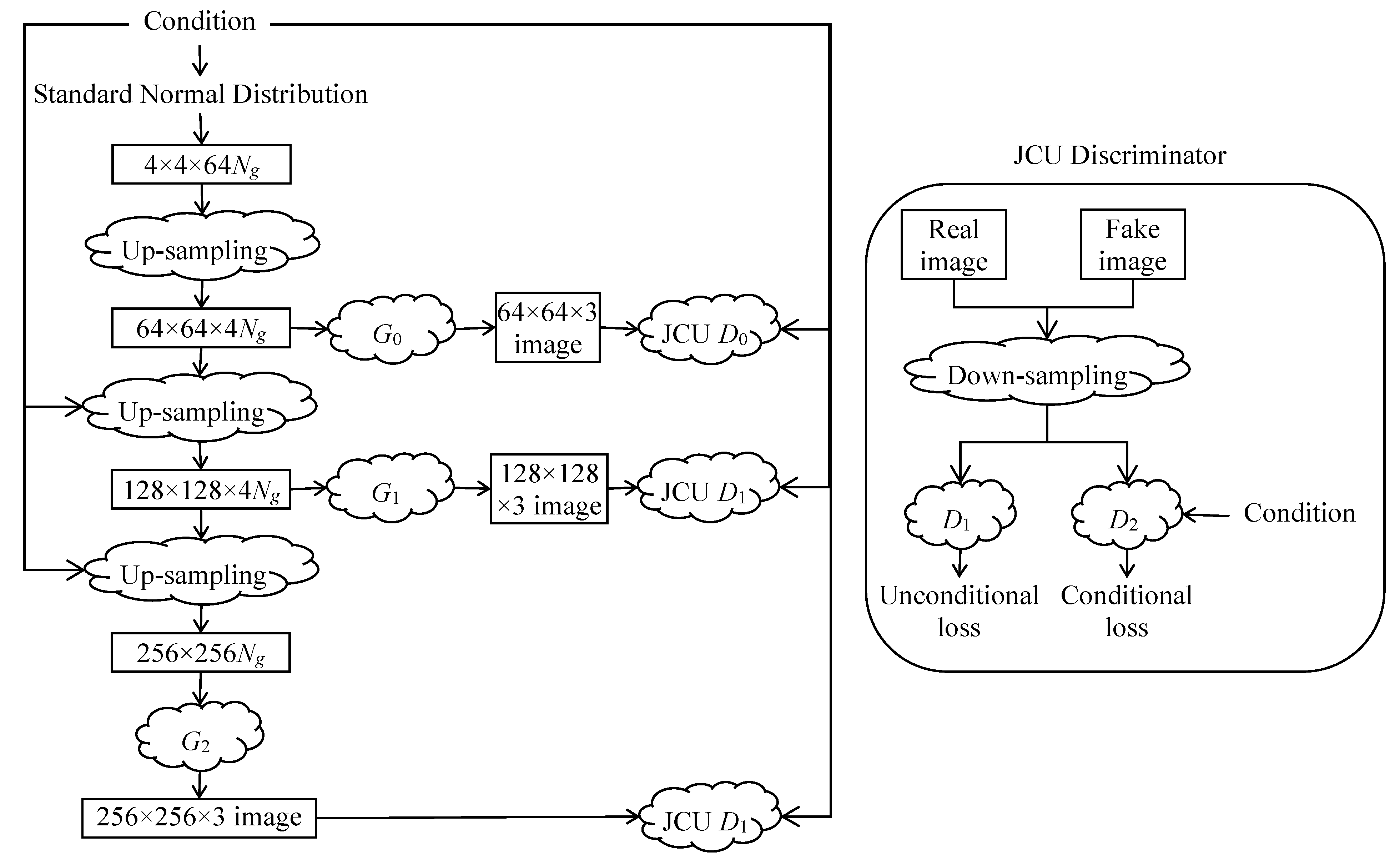
StackGAN
StackGAN++
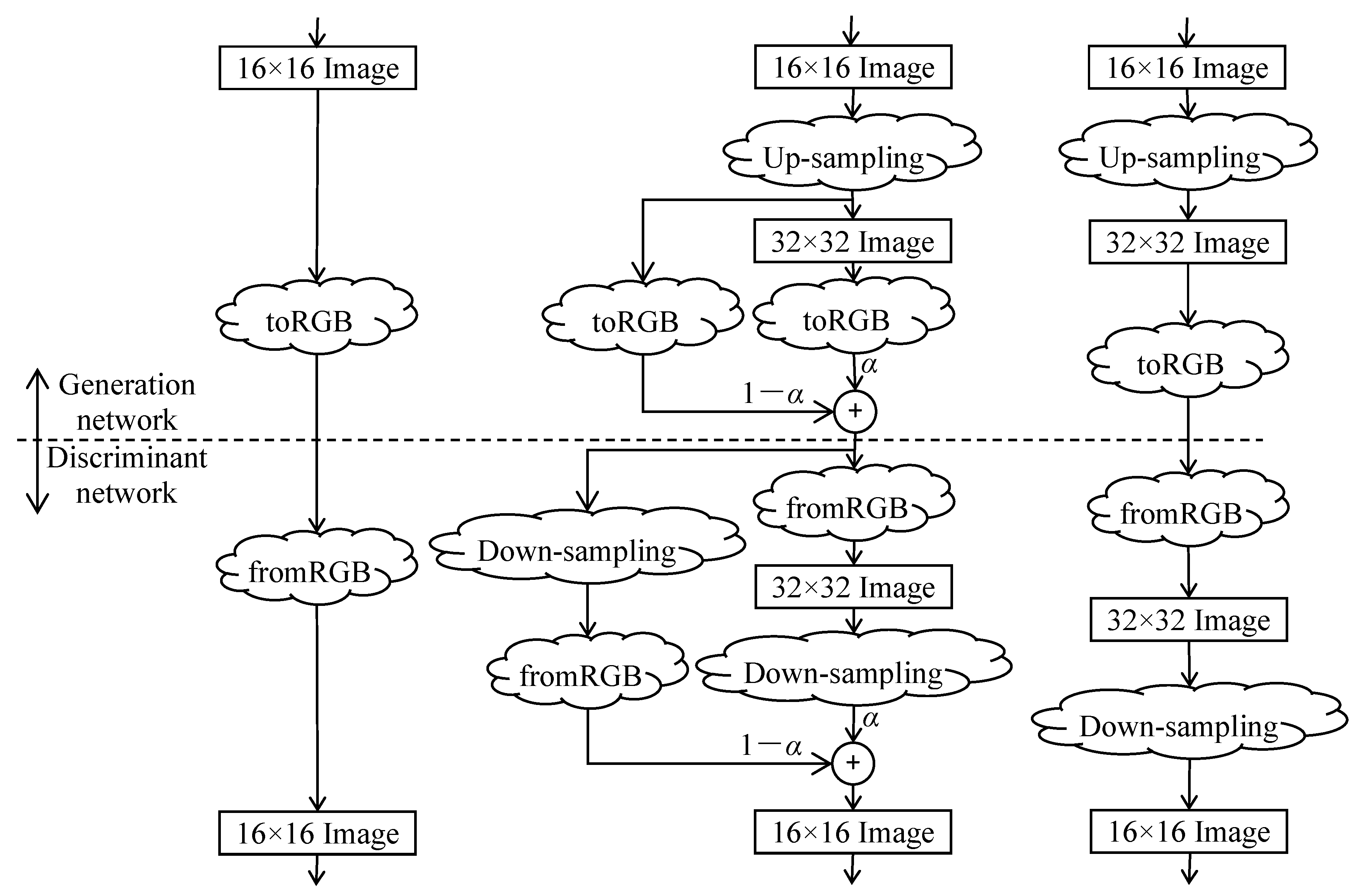
PGGAN
3. The Evaluation Method of CGAN
3.1. Automatic Evaluation
3.2. Manual Evaluation
4. The Applications of CGAN
4.1. Super Resolution (SR)
4.2. Image Style Transfer
4.3. Feature Synthesis
4.4. Image Inpainting
4.5. Pose Transfer
4.6. Image Generation from Text Descriptions
4.7. Other Fields
5. The Remaining Problems and Challenges
- Conditions are ignored. Many CGAN models easily ignore the conditions and generate data that fail to meet the conditions in some practical applications. Currently, there are maybe two causes for this problem. First, the characteristics of samples under different conditions in the training set are not significantly different; that is, the model cannot accurately classify samples according to conditions. Second, the network architecture is not reasonable. For example, the conditions representing high-level semantics of data only act on the first half of the network, resulting in only affecting low-level semantics of data.
- Proper coding of conditions. In order to make the CGAN model easily trainable, conditions need to be coded. However, how to have the reasonable encoding of conditions is a problem that needs further study in the field of CGAN because the commonly used Convolution Neural Network (CNN) may not contain the details that essentially correspond to the characteristics of the generated image.
- The high calculation cost. In CGAN, in addition to learning the distribution of generated images as unconditional GAN, the relationship between input conditions and generated images should also be learned, which further aggravates the burden of the model. Therefore, from this perspective, it is necessary to reduce the complexity of the model. One possible approach to this problem is model compression. However, the current research on how to implement model compression for CGAN is still very preliminary. For example, reference [104] only reduces the capacity of the model by screening the convolution kernel, which plays a rather limited role actually.
- The strong coupling with data. The training effectiveness of CGAN often depends heavily on the given data. For example, in the image style conversion task, let us consider a scenario where the image time needs to be converted from noon to evening. If the training data are only natural scenery photos, it is still difficult for CGAN to convert city photos after the training, which restricts the application of CGAN. This problem is difficult to solve by moderating the model alone. Therefore, a variety of standard data sets is the viable solution to this problem. At present, in terms of scientific research, some websites such as Kaggle have provided many types of data sets, but they are far from satisfying the research needs.
- The strong coupling with the task. Compared with the unconditional GAN, CGAN can be used to complete more tasks. However, the network used to solve one task is difficult to apply directly to another task. Despite that quite a few researchers summarized some design principles, such as the tricks summarized in Section 2.2, most of them only guided the overall framework of the network rather than a specific architecture inside the generative network and the discriminative network, which might have a great difference in different tasks.
- Neural Architecture Search (NAS) It should be noted that in recent years, Neural Architecture Search (NAS) technology has made a lot of achievements in the field of image classification [125,126], which is expected to help with the automatic design of network architecture. However, the complexity of CGAN means that there is still a long way to go, and even NAS technology can be employed.
6. Conclusions and Prospects
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Laloy, E.; Linde, N.; Jacques, D. Approaching geoscientific inverse problems with vector-to-image domain transfer networks. Adv. Water Resour. 2021, 152, 103917. [Google Scholar] [CrossRef]
- Li, L.; Li, J.; Lv, C.; Yuan, Y.; Zhao, B. Maize residue segmentation using Siamese domain transfer network. Comput. Electron. Agric. 2021, 187, 106261. [Google Scholar] [CrossRef]
- Liu, H.; Guo, F.; Xia, D. Domain adaptation with structural knowledge transfer learning for person re-identification. Multimed. Tools Appl. 2021, 80, 29321–29337. [Google Scholar] [CrossRef]
- Liu, J.; Li, Q.; Zhang, P.; Zhang, G.; Liu, M. Unpaired domain transfer for data augment in face recognition. IEEE Access 2020, 8, 39349–39360. [Google Scholar] [CrossRef]
- Al-Shannaq, A.; Elrefaei, L. Age estimation using specific domain transfer learning. Jordanian J. Comput. Inf. Technol. (JJCIT) 2020, 6, 122–139. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Suh, Y.; Han, B.; Kim, W.; Lee, K.M. Stochastic class-based hard example mining for deep metric learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7251–7259. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14454–14463. [Google Scholar]
- Mao, J.; Wang, H.; Spencer, B.F., Jr. Toward data anomaly detection for automated structural health monitoring: Exploiting generative adversarial nets and autoencoders. Struct. Health Monit. 2021, 20, 1609–1626. [Google Scholar] [CrossRef]
- Xia, Y.; Zhang, L.; Ravikumar, N.; Attar, R.; Piechnik, S.K.; Neubauer, S.; Petersen, S.E.; Frangi, A.F. Recovering from missing data in population imaging–Cardiac MR image imputation via conditional generative adversarial nets. Med. Image Anal. 2021, 67, 101812. [Google Scholar] [CrossRef]
- Wen, P.; Zhang, S.; Du, S.; Qu, B.; Song, X. A Full Mean-Square Analysis of CNSAF Algorithm For Noncircular Inputs. J. Frankl. Inst. 2021, 358, 7883–7899. [Google Scholar] [CrossRef]
- Wang, Z.; She, Q.; Ward, T.E. Generative adversarial networks in computer vision: A survey and taxonomy. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 63–79. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE international Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Zhao, L.; Liang, J.; Bai, H.; Wang, A.; Zhao, Y. Simultaneously Color-Depth Super-Resolution with Conditional Generative Adversarial Network. arXiv 2017, arXiv:1708.09105. [Google Scholar]
- Vaishali, I.; Rishabh, S.; Pragati, P. Image to Image Translation: Generating maps from satellite images. arXiv 2021, arXiv:2105.09253. [Google Scholar]
- He, Z.; Zuo, W.; Kan, M.; Shan, S.; Chen, X. AttGAN: Facial Attribute Editing by Only Changing What You Want. IEEE Trans. Image Process. 2019, 28, 5464–5478. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Alzubi, O.A.; Alzubi, J.A.; Alweshah, M.; Qiqieh, I.; Al-Shami, S.; Ramachandran, M. An optimal pruning algorithm of classifier ensembles: Dynamic programming approach. Neural Comput. Appl. 2020, 32, 16091–16107. [Google Scholar] [CrossRef]
- Perraudin, N.; Marcon, S.; Lucchi, A.; Kacprzak, T. Emulation of cosmological mass maps with conditional generative adversarial networks. arXiv 2020, arXiv:2004.08139. [Google Scholar] [CrossRef]
- Kamran, S.A.; Hossain, K.F.; Tavakkoli, A.; Zuckerbrod, S.L. Fundus2Angio: A Novel Conditional GAN Architecture for Generating Fluorescein Angiography Images from Retinal Fundus Photography. arXiv 2020, arXiv:2005.05267. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1857–1865. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Denton, E.; Chintala, S.; Szlam, A.; Fergus, R. Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks. arXiv 2015, arXiv:1506.05751. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. arXiv 2016, arXiv:1609.04802. [Google Scholar]
- Sonderby, C.K.; Caballero, J.; Theis, L.; Shi, W.; Huszar, F. Amortised MAP Inference for Image Super-resolution. In Proceedings of the International Conference on Learning Representation, Toulon, France, 24–26 April 2017. [Google Scholar]
- Yoo, D.; Kim, N.; Park, S.; Paek, A.S.; Kweon, I.S. Pixel-level domain transfer. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 517–532. [Google Scholar]
- Li, C.; Wand, M. Precomputed real-time texture synthesis with markovian generative adversarial networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 702–716. [Google Scholar]
- Zhu, J.Y.; Krähenbühl, P.; Shechtman, E.; Efros, A.A. Generative visual manipulation on the natural image manifold. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 597–613. [Google Scholar]
- Perarnau, G.; De Weijer, J.V.; Raducanu, B.; Alvarez, J.M. Invertible Conditional GANs for image editing. arXiv 2016, arXiv:1611.06355. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Sangkloy, P.; Lu, J.; Fang, C.; Yu, F.; Hays, J. Scribbler: Controlling Deep Image Synthesis with Sketch and Color. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6836–6845. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Huang, X.; Liu, M.Y.; Belongie, S.; Kautz, J. Multimodal Unsupervised Image-to-Image Translation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 172–189. [Google Scholar]
- Choi, Y.; Uh, Y.; Yoo, J.; Ha, J.W. Stargan v2: Diverse image synthesis for multiple domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8188–8197. [Google Scholar]
- Ding, H.; Sricharan, K.; Chellappa, R. ExprGAN: Facial Expression Editing with Controllable Expression Intensity. In Proceedings of the Association for the Advance of Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–3 February 2018; pp. 6781–6788. [Google Scholar]
- Liu, M.; Ding, Y.; Xia, M.; Liu, X.; Ding, E.; Zuo, W.; Wen, S. Stgan: A unified selective transfer network for arbitrary image attribute editing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3673–3682. [Google Scholar]
- Dey, S.; Das, S.; Ghosh, S.; Mitra, S.; Chakrabarty, S.; Das, N. SynCGAN: Using learnable class specific priors to generate synthetic data for improving classifier performance on cytological images. arXiv 2020, arXiv:2003.05712. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1947–1962. [Google Scholar] [CrossRef] [Green Version]
- Qiao, T.; Zhang, J.; Xu, D.; Tao, D. Mirrorgan: Learning text-to-image generation by redescription. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1505–1514. [Google Scholar]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. Dm-gan: Dynamic memory generative adversarial networks for text-to-image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5802–5810. [Google Scholar]
- Taigman, Y.; Polyak, A.; Wolf, L. Unsupervised cross-domain image generation. arXiv 2016, arXiv:1611.02200. [Google Scholar]
- Royer, A.; Bousmalis, K.; Gouws, S.; Bertsch, F.; Mosseri, I.; Cole, F.; Murphy, K. Xgan: Unsupervised image-to-image translation for many-to-many mappings. In Domain Adaptation for Visual Understanding; Springer: Berlin/Heidelberg, Germany, 2020; pp. 33–49. [Google Scholar]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Liu, S.; Dong, C.; Zhang, X.; Yuan, Y. Multiple cycle-in-cycle generative adversarial networks for unsupervised image super-resolution. IEEE Trans. Image Process. 2019, 29, 1101–1112. [Google Scholar] [CrossRef]
- Ma, Y.; Zhong, G.; Liu, W.; Wang, Y.; Jiang, P.; Zhang, R. ML-CGAN: Conditional Generative Adversarial Network with a Meta-learner Structure for High-Quality Image Generation with Few Training Data. Cogn. Comput. 2021, 13, 418–430. [Google Scholar] [CrossRef]
- Liu, R.; Ge, Y.; Choi, C.L.; Wang, X.; Li, H. Divco: Diverse conditional image synthesis via contrastive generative adversarial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16377–16386. [Google Scholar]
- Han, L.; Min, M.R.; Stathopoulos, A.; Tian, Y.; Gao, R.; Kadav, A.; Metaxas, D.N. Dual Projection Generative Adversarial Networks for Conditional Image Generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QB, Canada, 11 October 2021; pp. 14438–14447. [Google Scholar]
- Ueda, Y.; Fujii, K.; Saito, Y.; Takamichi, S.; Baba, Y.; Saruwatari, H. HumanACGAN: Conditional generative adversarial network with human-based auxiliary classifier and its evaluation in phoneme perception. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 6–12 June 2021; pp. 6468–6472. [Google Scholar]
- Wang, Z. Learning Fast Converging, Effective Conditional Generative Adversarial Networks with a Mirrored Auxiliary Classifier. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Montreal, QB, Canada, 11 October 2021; pp. 2566–2575. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6626–6637. [Google Scholar]
- Stap, D.; Bleeker, M.; Ibrahimi, S.; ter Hoeve, M. Conditional Image Generation and Manipulation for User-Specified Content. arXiv 2020, arXiv:2005.04909. [Google Scholar]
- Souza, D.M.; Wehrmann, J.; Ruiz, D.D. Efficient Neural Architecture for Text-to-Image Synthesis. arXiv 2020, arXiv:2004.11437. [Google Scholar]
- Yin, G.; Liu, B.; Sheng, L.; Yu, N.; Wang, X.; Shao, J. Semantics disentangling for text-to-image generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2327–2336. [Google Scholar]
- Bhattarai, B.; Kim, T. Inducing Optimal Attribute Representations for Conditional GANs. arXiv 2020, arXiv:2003.06472. [Google Scholar]
- Liu, M.; Huang, X.; Mallya, A.; Karras, T.; Aila, T.; Lehtinen, J.; Kautz, J. Few-Shot Unsupervised Image-to-Image Translation. arXiv 2019, arXiv:1905.01723. [Google Scholar]
- Chen, J.; Li, Y.; Ma, K.; Zheng, Y. Generative Adversarial Networks for Video-to-Video Domain Adaptation. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020; pp. 3462–3469. [Google Scholar]
- Zhu, J.Y.; Zhang, R.; Pathak, D.; Darrell, T.; Efros, A.A.; Wang, O.; Shechtman, E. Toward multimodal image-to-image translation. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 465–476. [Google Scholar]
- Zakharov, E.; Shysheya, A.; Burkov, E.; Lempitsky, V. Few-shot adversarial learning of realistic neural talking head models. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9459–9468. [Google Scholar]
- Antoniou, A.; Storkey, A.; Edwards, H. Data augmentation generative adversarial networks. arXiv 2017, arXiv:1711.04340. [Google Scholar]
- Abdollahi, A.; Pradhan, B.; Sharma, G.; Maulud, K.N.A.; Alamri, A. Improving Road Semantic Segmentation Using Generative Adversarial Network. IEEE Access 2021, 9, 64381–64392. [Google Scholar] [CrossRef]
- Ji, Y.; Zhang, H.; Wu, Q.J. Saliency detection via conditional adversarial image-to-image network. Neurocomputing 2018, 316, 357–368. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Laffont, P.Y.; Ren, Z.; Tao, X.; Qian, C.; Hays, J. Transient attributes for high-level understanding and editing of outdoor scenes. ACM Trans. Graph. (TOG) 2014, 33, 1–11. [Google Scholar] [CrossRef]
- Zhang, Z.; Song, Y.; Qi, H. Age progression/regression by conditional adversarial autoencoder. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5810–5818. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2337–2346. [Google Scholar]
- Eitz, M.; Hays, J.; Alexa, M. How do humans sketch objects? ACM Trans. Graph. (TOG) 2012, 31, 1–10. [Google Scholar] [CrossRef]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Yeh, R.A.; Chen, C.; Lim, T.Y.; Hasegawajohnson, M.; Do, M.N. Semantic Image Inpainting with Perceptual and Contextual Losses. arXiv 2016, arXiv:1607.07539. [Google Scholar]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 41–48. [Google Scholar]
- Kocmi, T.; Bojar, O. Curriculum Learning and Minibatch Bucketing in Neural Machine Translation. In Proceedings of the International Conference Recent Advances in Natural Language Processing (RANLP 2017), Varna, Bulgaria, 2–8 September 2017; pp. 379–386. [Google Scholar]
- Platanios, E.A.; Stretcu, O.; Neubig, G.; Poczos, B.; Mitchell, T. Competence-based Curriculum Learning for Neural Machine Translation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 1162–1172. [Google Scholar]
- Sarafianos, N.; Giannakopoulos, T.; Nikou, C.; Kakadiaris, I.A. Curriculum learning for multi-task classification of visual attributes. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2608–2615. [Google Scholar]
- Zhang, H.; Hu, Z.; Luo, C.; Zuo, W.; Wang, M. Semantic image inpainting with progressive generative networks. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 1939–1947. [Google Scholar]
- Mahapatra, D.; Bozorgtabar, B. Retinal Vasculature Segmentation Using Local Saliency Maps and Generative Adversarial Networks for Image Super Resolution. arXiv 2017, arXiv:1710.04783. [Google Scholar]
- Sanchez, I.; Vilaplana, V. Brain MRI super-resolution using 3D generative adversarial networks. arXiv 2018, arXiv:1812.11440. [Google Scholar]
- Rangnekar, A.; Mokashi, N.; Ientilucci, E.J.; Kanan, C.; Hoffman, M.J. Aerial Spectral Super-Resolution using Conditional Adversarial Networks. arXiv 2017, arXiv:1712.08690. [Google Scholar]
- Chen, Y.; Shi, F.; Christodoulou, A.G.; Xie, Y.; Zhou, Z.; Li, D. Efficient and accurate MRI super-resolution using a generative adversarial network and 3D multi-level densely connected network. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 91–99. [Google Scholar]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 700–708. [Google Scholar]
- Kumarapu, L.; Shiv, R.D.; Baddam, K.; Satya, R.V.K. Efficient High-Resolution Image-to-Image Translation using Multi-Scale Gradient U-Net. arXiv 2021, arXiv:2105.13067. [Google Scholar]
- Wang, Y.; Bittner, K.; Zorzi, S. Machine-learned 3D Building Vectorization from Satellite Imagery. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW 2021), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Le, T.; Poplin, R.; Bertsch, F.; Toor, A.S.; Oh, M.L. SyntheticFur dataset for neural rendering. arXiv 2021, arXiv:2105.06409. [Google Scholar]
- Kim, H.J.; Lee, D. Image denoising with conditional generative adversarial networks (CGAN) in low dose chest images. Nucl. Instrum. Methods Phys. Res. Sect. A 2020, 954, 161914. [Google Scholar] [CrossRef]
- Lee, H.Y.; Tseng, H.Y.; Huang, J.B.; Singh, M.; Yang, M.H. Diverse image-to-image translation via disentangled representations. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 35–51. [Google Scholar]
- Kaneko, T.; Hiramatsu, K.; Kashino, K. Generative attribute controller with conditional filtered generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6089–6098. [Google Scholar]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Wang, W.; Webb, R. Learning from simulated and unsupervised images through adversarial training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2107–2116. [Google Scholar]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D.B. PatchMatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph. 2009, 28, 24. [Google Scholar] [CrossRef]
- Barnes, C.; Shechtman, E.; Goldman, D.B.; Finkelstein, A. The generalized patchmatch correspondence algorithm. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 29–43. [Google Scholar]
- Darabi, S.; Shechtman, E.; Barnes, C.; Goldman, D.B.; Sen, P. Image melding: Combining inconsistent images using patch-based synthesis. ACM Trans. Graph. (TOG) 2012, 31, 1–10. [Google Scholar] [CrossRef]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Iizuka, S.; Simoserra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. 2017, 36, 107. [Google Scholar] [CrossRef]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.C.; Tao, A.; Catanzaro, B. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 85–100. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Free-form image inpainting with gated convolution. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4471–4480. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A Neural Algorithm of Artistic Style. J. Vis. 2016, 16, 326. [Google Scholar] [CrossRef]
- Zhao, J.; Mathieu, M.; Lecun, Y. Energy-based Generative Adversarial Network. In Proceedings of the International Conference of Learning Representation (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Hedjazi, M.A.; Genç, Y. Learning to Inpaint by Progressively Growing the Mask Regions. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 4591–4596. [Google Scholar]
- Siarohin, A.; Sangineto, E.; Lathuiliere, S.; Sebe, N. Deformable gans for pose-based human image generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3408–3416. [Google Scholar]
- Ma, L.; Sun, Q.; Georgoulis, S.; Van Gool, L.; Schiele, B.; Fritz, M. Disentangled person image generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 99–108. [Google Scholar]
- Palazzi, A.; Bergamini, L.; Calderara, S.; Cucchiara, R. Warp and Learn: Novel Views Generation for Vehicles and Other Objects. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 14, 2216–2227. [Google Scholar] [CrossRef]
- Lv, K.; Sheng, H.; Xiong, Z.; Li, W.; Zheng, L. Pose-based view synthesis for vehicles: A perspective aware method. IEEE Trans. Image Process. 2020, 29, 5163–5174. [Google Scholar] [CrossRef]
- Sethuraman, J.; Alzubi, J.A.; Manikandan, R.; Gheisari, M.; Kumar, A. Eccentric methodology with optimization to unearth hidden facts of search engine result pages. Recent Patents Comput. Sci. 2019, 12, 110–119. [Google Scholar] [CrossRef]
- Alzubi, O.A.; Alzubi, J.A.; Tedmori, S.; Rashaideh, H.; Almomani, O. Consensus-based combining method for classifier ensembles. Int. Arab J. Inf. Technol. 2018, 15, 76–86. [Google Scholar]
- Al-Najdawi, N.; Tedmori, S.; Alzubi, O.A.; Dorgham, O.; Alzubi, J.A. A frequency based hierarchical fast search block matching algorithm for fast video communication. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 447–455. [Google Scholar] [CrossRef] [Green Version]
- Alzubi, J.A.; Jain, R.; Kathuria, A.; Khandelwal, A.; Saxena, A.; Singh, A. Paraphrase identification using collaborative adversarial networks. J. Intell. Fuzzy Syst. 2020, 39, 1021–1032. [Google Scholar] [CrossRef]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative Adversarial Text to Image Synthesis. In Proceedings of the International Conference on Machine Learning, New York City, NY, USA, 19–24 June 2016; pp. 1060–1069. [Google Scholar]
- Reed, S.E.; Akata, Z.; Mohan, S.; Tenka, S.; Schiele, B.; Lee, H. Learning what and where to draw. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 217–225. [Google Scholar]
- Zhang, Z.; Xie, Y.; Yang, L. Photographic text-to-image synthesis with a hierarchically-nested adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6199–6208. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. Attngan: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1316–1324. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Hong, S.; Yang, D.; Choi, J.; Lee, H. Inferring semantic layout for hierarchical text-to-image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7986–7994. [Google Scholar]
- Zhao, B.; Meng, L.; Yin, W.; Sigal, L. Image generation from layout. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8584–8593. [Google Scholar]
- Agrawal, S.; Venkitachalam, S.; Raghu, D.; Pai, D. Directional GAN: A Novel Conditioning Strategy for Generative Networks. arXiv 2021, arXiv:2105.05712. [Google Scholar]
- Zhu, H.; Peng, X.; Chandrasekhar, V.; Li, L.; Lim, J.H. DehazeGAN: When Image Dehazing Meets Differential Programming. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 1234–1240. [Google Scholar]
- Zhou, J.T.; Zhang, H.; Jin, D.; Peng, X. Dual adversarial transfer for sequence labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 434–446. [Google Scholar] [CrossRef]
- Xu, X.; Lu, H.; Song, J.; Yang, Y.; Shen, H.T.; Li, X. Ternary adversarial networks with self-supervision for zero-shot cross-modal retrieval. IEEE Trans. Cybern. 2019, 50, 2400–2413. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, J.; Li, X. Weakly supervised adversarial domain adaptation for semantic segmentation in urban scenes. IEEE Trans. Image Process. 2019, 28, 4376–4386. [Google Scholar] [CrossRef] [Green Version]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural architecture search: A survey. arXiv 2018, arXiv:1808.05377. [Google Scholar]
- Wistuba, M.; Rawat, A.; Pedapati, T. A survey on neural architecture search. arXiv 2019, arXiv:1905.01392. [Google Scholar]
- Wang, Y.; Chen, Y.C.; Zhang, X.; Sun, J.; Jia, J. Attentive Normalization for Conditional Image Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5094–5103. [Google Scholar]
- Odena, A.; Buckman, J.; Olsson, C.; Brown, T.B.; Olah, C.; Raffel, C.; Goodfellow, I. Is Generator Conditioning Causally Related to GAN Performance. arXiv 2018, arXiv:1802.08768. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zand, J.; Roberts, S. Mixture Density Conditional Generative Adversarial Network Models (MD-CGAN). arXiv 2020, arXiv:2004.03797. [Google Scholar]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. Seqgan: Sequence generative adversarial nets with policy gradient. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Fedus, W.; Goodfellow, I.; Dai, A.M. MaskGAN: Better Text Generation via Filling in the ______. arXiv 2018, arXiv:1801.07736. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Loss Function | Content Loss [25] | Perception Loss [14] | Hidden Variable Loss [26] | Category Loss [27] |
|---|---|---|---|---|
| Source of independent variables | The output of generative network and training data | Two latent variables in the network | The output of generation network and condition | |
| Data type of independent variables | Image tensors | Distribution | ||
| Whether to use additional networks | No | Yes | No | Yes |
| Metric | Error (usually MSE) | Divergence | Divergence (usually cross-entropy loss) | |
| Contents of supervision | Low-level semantics of generated images | High-level semantics of generated images | States of generative network | Class of generated images |
| Methods | Adversarial Loss | Content Loss | Perception Loss | Hidden Variable Loss | Category Loss |
|---|---|---|---|---|---|
| Laplacian Pyramid [28] | ✓ | ✓ | |||
| SRGAN [29] | ✓ | ✓ | |||
| Amortised MAP Inference [30] | ✓ | ||||
| ESRGAN [14] | ✓ | ✓ | ✓ | ||
| Pixel-Level Domain Transfer [31] | ✓ | ✓ | |||
| Markovian GAN [32] | ✓ | ✓ | |||
| Generative Visual Manipulation [33] | ✓ | ✓ | ✓ | ||
| ICGAN [34] | ✓ | ✓ | |||
| pix2pix [35] | ✓ | ✓ | |||
| Scribbler [36] | ✓ | ✓ | ✓ | ||
| CycleGAN [15] | ✓ | ✓ | |||
| DiscoGAN [26] | ✓ | ✓ | |||
| DualGAN [37] | ✓ | ✓ | |||
| pix2pixHD [25] | ✓ | ✓ | |||
| MUNIT [38] | ✓ | ✓ | |||
| StarGAN V2 [39] | ✓ | ✓ | ✓ | ||
| ExprGAN [40] | ✓ | ✓ | ✓ | ✓ | |
| AttGAN [19] | ✓ | ✓ | ✓ | ||
| STGAN [41] | ✓ | ✓ | ✓ | ||
| SynCGAN [42] | ✓ | ✓ | ✓ | ||
| StackGAN [16] | ✓ | ||||
| StackGAN++ [43] | ✓ | ✓ | |||
| MirrorGAN [44] | ✓ | ✓ | ✓ | ||
| DM-GAN [45] | ✓ | ✓ | ✓ |
| Type | Index | Description |
|---|---|---|
| Automatic evaluation | IS [23,45,56,58,59,60] | Mapping the evaluation task to a classifier. |
| FID [23,45,57,58,59,60] | Using the inception network to extract features from an intermediate layer. | |
| TARR [61] | Computing the recognition rate of attributes on synthetic data by a model trained on real data. | |
| PSNR [41] | Computing an expression for the ratio between the maximum possible value (power) of a signal and the power of distorting noise that affects the quality of its representation. | |
| SSIM [62] | Measuring the similarity between the two images. | |
| Dice [35,58,61,63,64,65] | Measuring the gap between the semantic segmentation result and the real result. | |
| R-Precious [45] | Retrieving the relevant text for a given image query. | |
| Manual evaluation | Sample Analysis [23,61,64] | Analyzing some typically generated images qualitatively. |
| Evaluator Tests [23,35,64,65] | Inviting some reviewers to identify the real image and the generated image. | |
| Simulative Recommendation [60] | Ranking the images from different sources under the given conditions. |
| Task Type | Task Description | Semantic Level | Typical Papers |
|---|---|---|---|
| Super resolution | Converting image from low resolution to high resolution | Low-level | [14] |
| Texture transformation | Converting photos to oil paintings | [15] | |
| Color transformation | Converting grayscale image to color image | [69] | |
| Coloring in a line drawing | [33] | ||
| Environment transformation | Time conversion of landscape photo | Middle-level | [70] |
| Season conversion of landscape photo | [15] | ||
| Attribute edition | Object style editing | [38] | |
| Object outline editing | [33] | ||
| Facial attribute editing | [71] | ||
| Image synthesis | Converting the semantic mask to a photo | [72] | |
| Converting sketch to photo | [73] | ||
| Converting normal map to satellite map | [35] | ||
| Converting thermal to photo | [74] | ||
| Image inpainting | Repairing the image with some missing pixels | High-level | [75] |
| Data augmentation | Generating more data from existing data | [66] | |
| Image creation | Generating image from text description | [58] |
| Application Fields | Task Description | Typical Papers |
|---|---|---|
| Super Resolution (SR) | Converting image from low resolution to high resolution | [17,26,28,29,30,31,32,33,34,35,36,37,72,76,77,78,79,80,81,82,83,84,85,86] |
| Image style transfer | Transforming one type of image into another style of image, such as color transformation, texture transformation, etc. | [15,18,25,27,35,38,39,62,87,88,89] |
| Feature synthesis | Combining separate features to make composite features | [19,34,38,40,41,61,71,90,91,92] |
| Image inpainting | Restoring the original appearance of the image | [20,55,75,93,94,95,96,97,98,99,100,101,102,103,104] |
| Pose transfer | Generating images of the object observed from other angles | [21,105,106,107,108,109,110,111,112] |
| Image generation from text descriptions | Generating images according to text description | [16,43,44,45,58,59,60,113,114,115,116,117,118,119,120] |
| Other fields | Such as: single image dehazing, sequence labeling, inconsistency, etc. | [121,122,123,124] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, G.; Fan, Y.; Shi, J.; Lu, Y.; Shen, J. Conditional Generative Adversarial Networks for Domain Transfer: A Survey. Appl. Sci. 2022, 12, 8350. https://doi.org/10.3390/app12168350
Zhou G, Fan Y, Shi J, Lu Y, Shen J. Conditional Generative Adversarial Networks for Domain Transfer: A Survey. Applied Sciences. 2022; 12(16):8350. https://doi.org/10.3390/app12168350
Chicago/Turabian StyleZhou, Guoqiang, Yi Fan, Jiachen Shi, Yuyuan Lu, and Jun Shen. 2022. "Conditional Generative Adversarial Networks for Domain Transfer: A Survey" Applied Sciences 12, no. 16: 8350. https://doi.org/10.3390/app12168350
APA StyleZhou, G., Fan, Y., Shi, J., Lu, Y., & Shen, J. (2022). Conditional Generative Adversarial Networks for Domain Transfer: A Survey. Applied Sciences, 12(16), 8350. https://doi.org/10.3390/app12168350