

Computational Linguistics with Deep-Learning-Based Intent Detection for Natural Language Understanding

 , , and
, , and
Abstract
:1. Introduction
2. Related Works
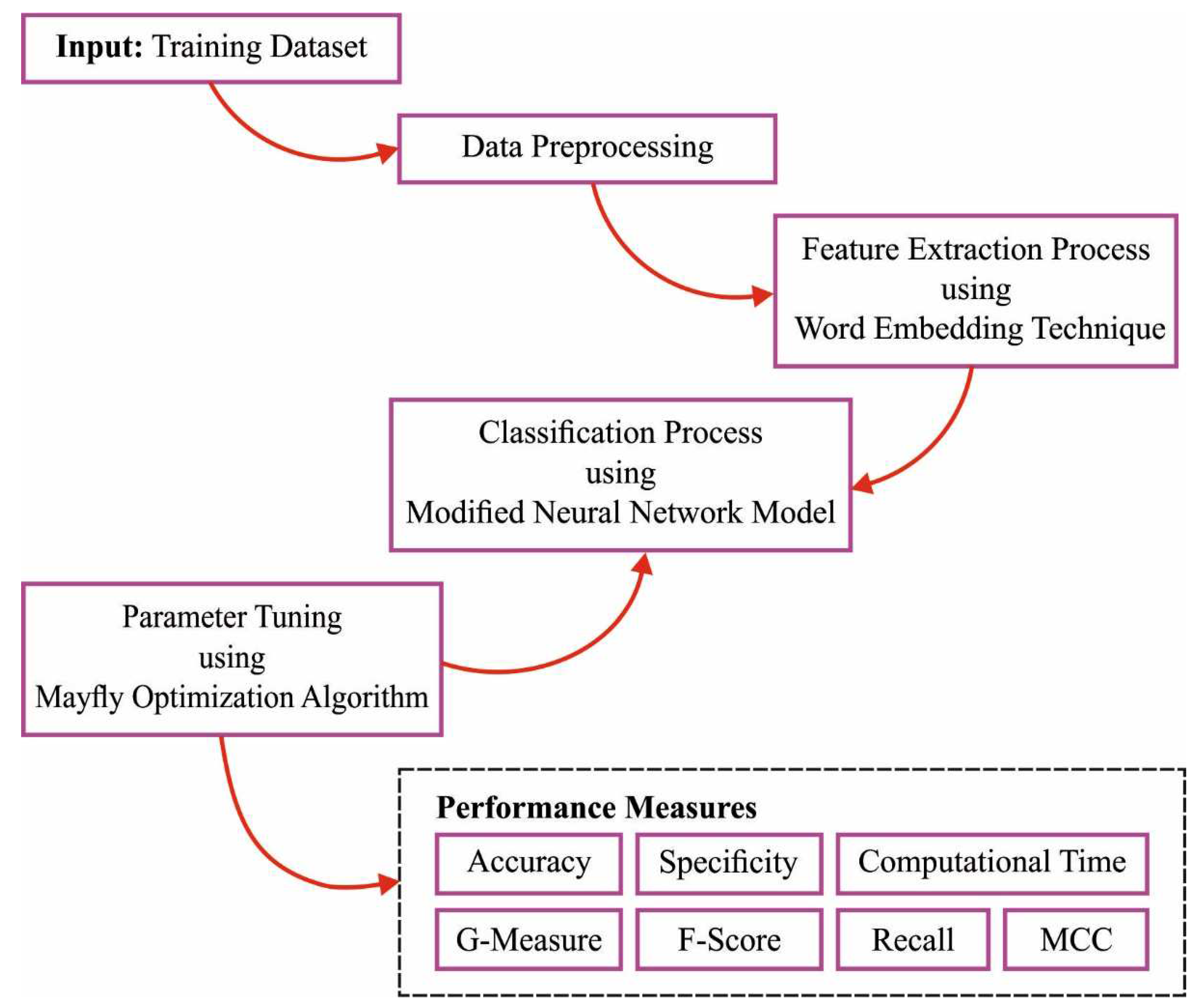
3. The Proposed Model
3.1. Word Embedding
3.1.1. Enrichment Using Synonyms
3.1.2. Enrichment Using Antonyms
3.1.3. Enriching with Related Words
3.1.4. Enriching with Hypernyms and Hyponyms
3.1.5. Regularization
3.2. Intent Detection Using the DLMNN Model
3.3. Parameter Tuning Using the MFO Algorithm
4. Experimental Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Firdaus, M.; Golchha, H.; Ekbal, A.; Bhattacharyya, P. A deep multi-task model for dialogue act classification, intent detection and slot filling. Cogn. Comput. 2021, 13, 626–645. [Google Scholar] [CrossRef]
- Fernández-Martínez, F.; Griol, D.; Callejas, Z.; Luna-Jiménez, C. An approach to intent detection and classification based on attentive recurrent neural networks. In Proceedings of the IberSPEECH, Valladolid, Spain, 24–25 March 2021; pp. 46–50. [Google Scholar]
- Song, S.; Chen, X.; Wang, C.; Yu, X.; Wang, J.; He, X. A Two-Stage User Intent Detection Model on Complicated Utterances with Multi-task Learning. In Proceedings of the WebConf 2022, Lyon, France, 25–29 April 2022. [Google Scholar]
- Al-Wesabi, F.N. Proposing high-smart approach for content authentication and tampering detection of arabic text transmitted via internet. IEICE Trans. Inf. Syst. 2020, E103, 2104–2112. [Google Scholar] [CrossRef]
- Weld, H.; Huang, X.; Long, S.; Poon, J.; Han, S.C. A survey of joint intent detection and slot-filling models in natural language understanding. arXiv 2021, arXiv:2101.08091. [Google Scholar] [CrossRef]
- Al-Wesabi, F.N. A hybrid intelligent approach for content authentication and tampering detection of arabic text transmitted via internet. Comput. Mater. Contin. 2021, 66, 195–211. [Google Scholar] [CrossRef]
- Liu, J.; Li, Y.; Lin, M. Review of intent detection methods in the human-machine dialogue system. J. Phys. Conf. Ser. 2019, 1267, 012059. [Google Scholar] [CrossRef]
- Al-Wesabi, F.N. Entropy-based watermarking approach for sensitive tamper detection of arabic text. Comput. Mater. Contin. 2021, 67, 3635–3648. [Google Scholar] [CrossRef]
- Hou, Y.; Lai, Y.; Wu, Y.; Che, W.; Liu, T. Few-shot learning for multi-label intent detection. Proc. AAAI Conf. Artif. Intell. 2021, 35, 13036–13044. [Google Scholar]
- Liu, H.; Zhao, S.; Zhang, X.; Zhang, F.; Sun, J.; Yu, H.; Zhang, X. A Simple Meta-learning Paradigm for Zero-shot Intent Classification with Mixture Attention Mechanism. arXiv 2022, arXiv:2206.02179. [Google Scholar]
- Siddique, A.B.; Jamour, F.; Xu, L.; Hristidis, V. Generalized zero-shot intent detection via commonsense knowledge. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; pp. 1925–1929. [Google Scholar]
- Zhang, J.G.; Hashimoto, K.; Wan, Y.; Liu, Y.; Xiong, C.; Yu, P.S. Are pretrained transformers robust in intent classification? a missing ingredient in evaluation of out-of-scope intent detection. arXiv 2021, arXiv:2106.04564. [Google Scholar]
- Zhang, H.; Xu, H.; Lin, T.E. Deep Open Intent Classification with Adaptive Decision Boundary. In Proceedings of the AAAI, Virtual, 2–9 February 2021; pp. 14374–14382. [Google Scholar]
- Yan, G.; Fan, L.; Li, Q.; Liu, H.; Zhang, X.; Wu, X.M.; Lam, A.Y. Unknown intent detection using Gaussian mixture model with an application to zero-shot intent classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, online, 5–10 July 2020; pp. 1050–1060. [Google Scholar]
- Gangadharaiah, R.; Narayanaswamy, B. Joint multiple intent detection and slot labeling for goal-oriented dialog. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 564–569. [Google Scholar]
- Dopierre, T.; Gravier, C.; Logerais, W. ProtAugment: Intent detection meta-learning through unsupervised diverse paraphrasing. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), online, 1–6 August 2021; pp. 2454–2466. [Google Scholar]
- Nigam, A.; Sahare, P.; Pandya, K. Intent detection and slots prompt in a closed-domain chatbot. In Proceedings of the 2019 IEEE 13th International Conference on Semantic Computing (ICSC), Newport Beach, CA, USA, 30 January–1 February 2019; pp. 340–343. [Google Scholar]
- Zhou, Y.; Liu, P.; Qiu, X. Knn-contrastive learning for out-of-domain intent classification. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 5129–5141. [Google Scholar]
- Büyük, O.; Erden, M.; Arslan, L.M. Leveraging the information in in-domain datasets for transformer-based intent detection. In Proceedings of the 2021 Innovations in Intelligent Systems and Applications Conference (ASYU), Elazig, Turkey, 6–8 October 2021; pp. 1–4. [Google Scholar]
- Shen, Y.; Hsu, Y.C.; Ray, A.; Jin, H. Enhancing the generalization for Intent Classification and Out-of-Domain Detection in SLU. arXiv 2021, arXiv:2106.14464. [Google Scholar]
- Qin, L.; Xu, X.; Che, W.; Liu, T. AGIF: An adaptive graph-interactive framework for joint multiple intent detection and slot filling. arXiv 2020, arXiv:2004.10087. [Google Scholar]
- Sreelakshmi, K.; Rafeeque, P.C.; Sreetha, S.; Gayathri, E.S. Deep bi-directional lstm network for query intent detection. Procedia Comput. Sci. 2018, 143, 939–946. [Google Scholar] [CrossRef]
- Muthu, B.; Cb, S.; Kumar, P.M.; Kadry, S.N.; Hsu, C.H.; Sanjuan, O.; Crespo, R.G. A framework for extractive text summarization based on deep learning modified neural network classifier. Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20, 1–20. [Google Scholar] [CrossRef]
- Mo, S.; Ye, Q.; Jiang, K.; Mo, X.; Shen, G. An improved MPPT method for photovoltaic systems based on mayfly optimization algorithm. Energy Rep. 2022, 8, 141–150. [Google Scholar] [CrossRef]
- Coucke, A.; Saade, A.; Ball, A.; Bluche, T.; Caulier, A.; Leroy, D.; Doumouro, C.; Gisselbrecht, T.; Caltagirone, F.; Lavril, T.; et al. Snips voice platform: An embedded spoken language understanding system for private-by-design voice interfaces. arXiv 2018, arXiv:1805.10190. [Google Scholar]
- Agarwal, V.; Shivnikar, S.D.; Ghosh, S.; Arora, H.; Saini, Y. Lidsnet: A lightweight on-device intent detection model using deep siamese network. In Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), Pasadena, CA, USA, 13–16 December 2022; pp. 1112–1117. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Class | No. of Samples |
|---|---|---|
| 1 | CreativeWork | 500 |
| 2 | PlayMusic | 500 |
| 3 | RateBook | 500 |
| 4 | ScreeningEvent | 500 |
| 5 | GetWeather | 500 |
| 6 | AddToPlaylist | 500 |
| 7 | BookRestaurant | 500 |
| Total No. of Samples | 3500 | |
| Labels | Accuracy | Recall | Specificity | F-Score | MCC | G-Measure |
|---|---|---|---|---|---|---|
| Training Set (80%) | ||||||
| 1 | 99.04 | 97.48 | 99.29 | 96.63 | 96.07 | 96.63 |
| 2 | 99.14 | 94.78 | 99.87 | 96.95 | 96.48 | 96.97 |
| 3 | 99.11 | 99.75 | 99.00 | 96.91 | 96.44 | 96.95 |
| 4 | 99.39 | 96.95 | 99.79 | 97.82 | 97.47 | 97.82 |
| 5 | 99.64 | 98.53 | 99.83 | 98.77 | 98.56 | 98.77 |
| 6 | 99.14 | 96.77 | 99.54 | 97.01 | 96.51 | 97.01 |
| 7 | 99.54 | 98.27 | 99.75 | 98.39 | 98.12 | 98.39 |
| Average | 99.29 | 97.50 | 99.58 | 97.50 | 97.09 | 97.51 |
| Testing Set (20%) | ||||||
| 1 | 98.86 | 98.06 | 98.99 | 96.19 | 95.54 | 96.21 |
| 2 | 99.71 | 100.00 | 99.67 | 98.99 | 98.83 | 98.99 |
| 3 | 99.57 | 99.07 | 99.66 | 98.60 | 98.35 | 98.61 |
| 4 | 99.86 | 99.07 | 100.00 | 99.53 | 99.45 | 99.53 |
| 5 | 99.71 | 97.83 | 100.00 | 98.90 | 98.74 | 98.91 |
| 6 | 99.43 | 96.94 | 99.83 | 97.94 | 97.61 | 97.94 |
| 7 | 99.43 | 96.84 | 99.83 | 97.87 | 97.55 | 97.88 |
| Average | 99.51 | 98.26 | 99.71 | 98.29 | 98.01 | 98.30 |
| Labels | Accuracy | Recall | Specificity | F-Score | MCC | G-Measure |
|---|---|---|---|---|---|---|
| Training Set (70%) | ||||||
| 1 | 98.57 | 95.82 | 99.04 | 95.16 | 94.32 | 95.16 |
| 2 | 98.94 | 95.84 | 99.47 | 96.38 | 95.76 | 96.38 |
| 3 | 98.37 | 94.72 | 98.96 | 94.17 | 93.22 | 94.17 |
| 4 | 99.22 | 96.80 | 99.62 | 97.23 | 96.78 | 97.23 |
| 5 | 99.10 | 97.10 | 99.43 | 96.82 | 96.30 | 96.82 |
| 6 | 99.02 | 96.20 | 99.48 | 96.48 | 95.91 | 96.48 |
| 7 | 99.10 | 96.65 | 99.52 | 96.92 | 96.39 | 96.92 |
| Average | 98.90 | 96.16 | 99.36 | 96.16 | 95.53 | 96.17 |
| Testing Set (30%) | ||||||
| 1 | 99.24 | 98.58 | 99.34 | 97.20 | 96.77 | 97.21 |
| 2 | 99.05 | 95.68 | 99.56 | 96.38 | 95.83 | 96.38 |
| 3 | 99.05 | 98.11 | 99.21 | 96.89 | 96.34 | 96.90 |
| 4 | 99.24 | 95.51 | 99.89 | 97.39 | 96.97 | 97.40 |
| 5 | 99.24 | 97.42 | 99.55 | 97.42 | 96.97 | 97.42 |
| 6 | 99.33 | 97.47 | 99.66 | 97.78 | 97.39 | 97.78 |
| 7 | 99.33 | 97.89 | 99.56 | 97.54 | 97.16 | 97.54 |
| Average | 99.21 | 97.24 | 99.54 | 97.23 | 96.78 | 97.23 |
| Methods | Accuracy (%) | F1-Score (%) |
|---|---|---|
| CL-DLBIDC | 99.51 | 98.29 |
| Stack-PBERT | 99.25 | 97.98 |
| LIDSNet | 97.79 | 95.61 |
| Stack-Propagation | 98.29 | 96.23 |
| Capsule-NLU | 97.43 | 96.40 |
| SFID-BLSTM | 97.36 | 97.21 |
| Attention-SG-BiLSTM | 96.87 | 96.99 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alshahrani, H.J.; Tarmissi, K.; Alshahrani, H.; Ahmed Elfaki, M.; Yafoz, A.; Alsini, R.; Alghushairy, O.; Ahmed Hamza, M. Computational Linguistics with Deep-Learning-Based Intent Detection for Natural Language Understanding. Appl. Sci. 2022, 12, 8633. https://doi.org/10.3390/app12178633
Alshahrani HJ, Tarmissi K, Alshahrani H, Ahmed Elfaki M, Yafoz A, Alsini R, Alghushairy O, Ahmed Hamza M. Computational Linguistics with Deep-Learning-Based Intent Detection for Natural Language Understanding. Applied Sciences. 2022; 12(17):8633. https://doi.org/10.3390/app12178633
Chicago/Turabian StyleAlshahrani, Hala J., Khaled Tarmissi, Hussain Alshahrani, Mohamed Ahmed Elfaki, Ayman Yafoz, Raed Alsini, Omar Alghushairy, and Manar Ahmed Hamza. 2022. "Computational Linguistics with Deep-Learning-Based Intent Detection for Natural Language Understanding" Applied Sciences 12, no. 17: 8633. https://doi.org/10.3390/app12178633
APA StyleAlshahrani, H. J., Tarmissi, K., Alshahrani, H., Ahmed Elfaki, M., Yafoz, A., Alsini, R., Alghushairy, O., & Ahmed Hamza, M. (2022). Computational Linguistics with Deep-Learning-Based Intent Detection for Natural Language Understanding. Applied Sciences, 12(17), 8633. https://doi.org/10.3390/app12178633