

Spoken Language Identification System Using Convolutional Recurrent Neural Network


Abstract
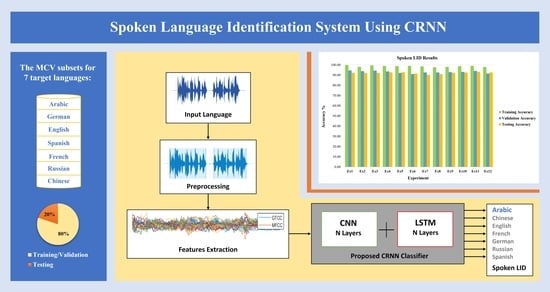
:
1. Introduction
2. Literature Review
3. Selected Speech Corpus
4. Proposed Spoken Language Identification System
4.1. Motivation
4.2. Preprocessing
4.3. Selected Features
4.3.1. MFCC
4.3.2. GTCC
4.4. Proposed CRNN Architecture
4.5. Layers Description
- (1)
- The Sequence Input Layer for 2-D image sequence input contains the vector of three elements. Depending on the used parameters, this article includes 26 dimensions: 13 for GTCC and 13 for MFCC; there are 50 feature vectors per sequence (Because the features that were extracted from segments have different feature vectors depending on speech file length, we need the framing to buffer the feature vectors into fixed sequences of size 50 frames with 47 overlaps); hence the input size is [26 50 1], where 26, 50, and 1 correspond to the height, width, and the number of channels of the image, respectively.
- (2)
- To use Convolutional Layers to extract features (that is, to apply convolutional operations to each speech frame independently), we use a Sequence Folding Layer followed by convolutional layers.
- (3)
- The Batch Normalization Layer follows the Convolution Layer, where Batch Normalization is responsible for the convergence of learned representations. Then the ELU Layer.
- (4)
- Average Pooling 2 d = 1 × 1 with stride [10 10] and padding [0 0 0 0]. A 2-D average pooling layer performs downsampling by dividing the input into rectangular pooling regions and computing the average values of each region.
- (5)
- We use a Sequence Unfolding Layer and a Flatten Layer to restore the sequence structure and reshape the output to vector sequences.
- (6)
- We include the LSTM Layers to classify the resulting vector sequences.
- (7)
- The Dropout Layer, with a dropout possibility of 40%, always follows every LSTM layer.
- (8)
- The Fully Connected Layer contains seven neurons.
- (9)
- The Softmax Layer applies a softmax function to the input.
- (10)
- The Classification Output Layer acts as an output layer for the proposed system.
5. Experiments
5.1. Performance Evaluation
5.1.1. Accuracy (A)
5.1.2. Precision (P)
5.1.3. Recall (R)
5.1.4. F-Measure (F1)
5.2. Experimental Setup
6. Results and Discussion
6.1. Feature Comparison Results
6.2. Spoken Language Identification Results
6.3. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lounnas, K.; Satori, H.; Hamidi, M.; Teffahi, H.; Abbas, M.; Lichouri, M. CLIASR: A Combined Automatic Speech Recognition and Language Identification System. In Proceedings of the 2020 1st International Conference on Innovative Research in Applied Science, Engineering and Technology (IRASET), Meknes, Morocco, 16–19 April 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Bartz, C.; Herold, T.; Yang, H.; Meinel, C. Language Identification Using Deep Convolutional Recurrent Neural Networks. arXiv 2017. [Google Scholar] [CrossRef]
- Fromkin, V.; Rodman, R.; Hyams, N.M. An Introduction to Language, 10th ed.; Wadsworth/Cengage Learning: Boston, MA, USA, 2014. [Google Scholar]
- The World’s Major Languages; Routledge Handbooks Online: London, UK, 2008. [CrossRef]
- Crystal, D. The Cambridge Encyclopedia of Language, 3rd ed.; Cambridge University Press: Cambridge, NY, USA, 2010. [Google Scholar]
- Shaalan, K.; Siddiqui, S.; Alkhatib, M.; Monem, A.A. Challenges in Arabic Natural Language Processing. In Systems Computational Linguistics, Speech and Image Processing for Arabic Language; World Scientific: Singapore, 2018; pp. 59–83. [Google Scholar] [CrossRef]
- Alotaibi, Y.A.; Muhammad, G. Study on pharyngeal and uvular consonants in foreign accented Arabic for ASR. Comput. Speech Lang. 2010, 24, 219–231. [Google Scholar] [CrossRef]
- Spoken Language Recognition: From Fundamentals to Practice. IEEE J. Mag. IEEE Xplore 2013, 101, 1136–1159. Available online: https://ieeexplore.ieee.org/document/6451097 (accessed on 26 February 2022).
- Waibel, A.; Geutner, P.; Tomokiyo, L.; Schultz, T.; Woszczyna, M. Multilinguality in speech and spoken language systems. Proc. IEEE 2000, 88, 1297–1313. [Google Scholar] [CrossRef]
- Schultz, T.; Waibel, A. Language-independent and language-adaptive acoustic modeling for speech recognition. Speech Commun. 2001, 35, 31–51. [Google Scholar] [CrossRef]
- Kim, H.; Park, J.-S. Automatic Language Identification Using Speech Rhythm Features for Multi-Lingual Speech Recognition. Appl. Sci. 2020, 10, 2225. [Google Scholar] [CrossRef]
- Liu, D.; Xu, J.; Zhang, P.; Yan, Y. A unified system for multilingual speech recognition and language identification. Speech Commun. 2020, 127, 17–28. [Google Scholar] [CrossRef]
- Chelba, C.; Hazen, T.; Saraclar, M. Retrieval and browsing of spoken content. IEEE Signal Process. Mag. 2008, 25, 39–49. [Google Scholar] [CrossRef]
- Walker, K.; Strassel, S. The RATS radio traffic collection system. In Odyssey Speaker and Language Recognition Workshop; ISCA: Cape Town, South Africa, 2012. [Google Scholar]
- Shen, P.; Lu, X.; Li, S.; Kawai, H. Knowledge Distillation-Based Representation Learning for Short-Utterance Spoken Language Identification. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2674–2683. [Google Scholar] [CrossRef]
- Srinivas, N.S.S.; Sugan, N.; Kar, N.; Kumar, L.S.; Nath, M.K.; Kanhe, A. Recognition of Spoken Languages from Acoustic Speech Signals Using Fourier Parameters. Circuits Syst. Signal Process. 2019, 38, 5018–5067. [Google Scholar] [CrossRef]
- He, K.; Xu, W.; Yan, Y. Multi-Level Cross-Lingual Transfer Learning With Language Shared and Specific Knowledge for Spoken Language Understanding. IEEE Access 2020, 8, 29407–29416. [Google Scholar] [CrossRef]
- Padi, B.; Mohan, A.; Ganapathy, S. Towards Relevance and Sequence Modeling in Language Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1223–1232. [Google Scholar] [CrossRef]
- Nofal, M.; Abdel-Reheem, E.; El Henawy, H. Arabic/English automatic spoken language identification. In Proceedings of the 1999 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing (PACRIM 1999). Conference Proceedings (Cat. No.99CH36368), Victoria, BC, Canada, 22–24 August 1999; pp. 400–403. [Google Scholar] [CrossRef]
- Zazo, R.; Lozano-Diez, A.; Gonzalez-Dominguez, J.; Toledano, D.T.; Gonzalez-Rodriguez, J. Language Identification in Short Utterances Using Long Short-Term Memory (LSTM) Recurrent Neural Networks. PLoS ONE 2016, 11, e0146917. [Google Scholar] [CrossRef]
- Draghici, A.; Abeßer, J.; Lukashevich, H. A study on spoken language identification using deep neural networks. In Proceedings of the 15th International Conference on Audio Mostly, New York, NY, USA, 15–17 September 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 253–256. Available online: https://doi.org/10.1145/3411109.3411123 (accessed on 17 June 2022).
- Guha, S.; Das, A.; Singh, P.K.; Ahmadian, A.; Senu, N.; Sarkar, R. Hybrid Feature Selection Method Based on Harmony Search and Naked Mole-Rat Algorithms for Spoken Language Identification From Audio Signals. IEEE Access 2020, 8, 182868–182887. [Google Scholar] [CrossRef]
- Sangwan, P.; Deshwal, D.; Dahiya, N. Performance of a language identification system using hybrid features and ANN learning algorithms. Appl. Acoust. 2021, 175, 107815. [Google Scholar] [CrossRef]
- Garain, A.; Singh, P.K.; Sarkar, R. FuzzyGCP: A deep learning architecture for automatic spoken language identification from speech signals. Expert Syst. Appl. 2021, 168, 114416. [Google Scholar] [CrossRef]
- Shen, P.; Lu, X.; Kawai, H. Transducer-based language embedding for spoken language identification. arXiv 2022, arXiv:2204.03888. [Google Scholar]
- Das, A.; Guha, S.; Singh, P.K.; Ahmadian, A.; Senu, N.; Sarkar, R. A Hybrid Meta-Heuristic Feature Selection Method for Identification of Indian Spoken Languages From Audio Signals. IEEE Access 2020, 8, 181432–181449. [Google Scholar] [CrossRef]
- Ma, Z.; Yu, H. Language Identification with Deep Bottleneck Features. arXiv 2020, arXiv:1809.08909. Available online: http://arxiv.org/abs/1809.08909 (accessed on 23 February 2022).
- Alshutayri, A.; Albarhamtoshy, H. Arabic Spoken Language Identification System (ASLIS): A Proposed System to Identifying Modern Standard Arabic (MSA) and Egyptian Dialect. In Proceedings of the Informatics Engineering and Information Science Conference, Kuala Lumpur, Malaysia, 12–14 November 2011; Springer: Berlin/Heidelberg, Germany; pp. 375–385. [Google Scholar] [CrossRef]
- Mohammed, E.M.; Sayed, M.S.; Moselhy, A.M.; Abdelnaiem, A.A. LPC and MFCC Performance Evaluation with Artificial Neural Network for Spoken Language Identification. Int. J. Signal Process. Image Process. Pattern Recognit. 2013, 6, 55. [Google Scholar]
- Pimentel, I. The Top 10 Languages in Higher Demand for Business. Available online: https://blog.acolad.com/the-top-10-languages-in-higher-demand-for-business (accessed on 21 August 2022).
- “10 Foreign Languages in Demand across the Globe”. Education World, 19 November 2018. Available online: https://www.educationworld.in/foreign-languages-in-demand-across-the-globe/ (accessed on 21 August 2022).
- Sisodia, D.S.; Nikhil, S.; Kiran, G.S.; Sathvik, P. Ensemble Learners for Identification of Spoken Languages using Mel Frequency Cepstral Coefficients. In Proceedings of the 2nd International Conference on Data, Engineering and Applications (IDEA), Bhopal, India, 28–29 February 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Singh, G.; Sharma, S.; Kumar, V.; Kaur, M.; Baz, M.; Masud, M. Spoken Language Identification Using Deep Learning. Comput. Intell. Neurosci. 2021. [Google Scholar] [CrossRef]
- Alashban, A.A.; Alotaibi, Y.A. Speaker Gender Classification in Mono-Language and Cross-Language Using BLSTM Network. In Proceedings of the 2021 44th International Conference on Telecommunications and Signal Processing (TSP), Brno, Czech Republic, 26–28 July 2021; pp. 66–71. [Google Scholar] [CrossRef]
- Mozilla Common Voice. Available online: https://commonvoice.mozilla.org/ (accessed on 27 February 2022).
- Ardila, R.; Branson, M.; Davis, K.; Henretty, M.; Kohler, M.; Meyer, J.; Morais, R.; Saunders, L.; Tyers, F.M.; Weber, G. Common Voice: A Massively-Multilingual Speech Corpus. arXiv 2020, arXiv:1912.06670. Available online: http://arxiv.org/abs/1912.06670 (accessed on 27 December 2021).
- Automatic Speech Recognition: A Deep Learning Approach—PDF Drive. Available online: http://www.pdfdrive.com/automatic-speech-recognition-a-deep-learning-approach-e177783075.html (accessed on 30 March 2022).
- Alashban, A.A.; Alotaibi, Y.A. Language Effect on Speaker Gender Classification Using Deep Learning. In Proceedings of the 2022 2nd International Conference on Artificial Intelligence and Signal Processing (AISP), Vijayawada, India, 12–14 February 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Detect Boundaries of Speech in Audio Signal—MATLAB detectSpeech—MathWorks Switzerland. Available online: https://ch.mathworks.com/help/audio/ref/detectspeech.html (accessed on 17 August 2022).
- Journal, I. Extracting Mfcc and Gtcc Features for Emotion Recognition from Audio Speech Signals. Available online: https://www.academia.edu/8088548/EXTRACTING_MFCC_AND_GTCC_FEATURES_FOR_EMOTION_RECOGNITION_FROM_AUDIO_SPEECH_SIGNALS (accessed on 31 March 2022).
- Kotsakis, R.; Matsiola, M.; Kalliris, G.; Dimoulas, C. Investigation of Spoken-Language Detection and Classification in Broadcasted Audio Content. Information 2020, 11, 211. [Google Scholar] [CrossRef]
- Dua, S.; Kumar, S.S.; Albagory, Y.; Ramalingam, R.; Dumka, A.; Singh, R.; Rashid, M.; Gehlot, A.; Alshamrani, S.S.; AlGhamdi, A.S. Developing a Speech Recognition System for Recognizing Tonal Speech Signals Using a Convolutional Neural Network. Appl. Sci. 2022, 12, 6223. [Google Scholar] [CrossRef]
- Nisar, S.; Shahzad, I.; Khan, M.A.; Tariq, M. Pashto spoken digits recognition using spectral and prosodic based feature extraction. In Proceedings of the 2017 Ninth International Conference on Advanced Computational Intelligence (ICACI), Doha, Qatar, 4–6 February 2017; pp. 74–78. [Google Scholar] [CrossRef]
- Liu, G.K. Evaluating Gammatone Frequency Cepstral Coefficients with Neural Networks for Emotion Recognition from Speech. arXiv 2018, arXiv:1806.09010. [Google Scholar]
- Liu, J.-M.; You, M.; Li, G.-Z.; Wang, Z.; Xu, X.; Qiu, Z.; Xie, W.; An, C.; Chen, S. Cough signal recognition with Gammatone Cepstral Coefficients. In Proceedings of the 2013 IEEE China Summit and International Conference on Signal and Information Processing, Beijing, China, 6–10 July 2013; pp. 160–164. [Google Scholar] [CrossRef]
- Alcaraz, J.C.; Moghaddamnia, S.; Peissig, J. Efficiency of deep neural networks for joint angle modeling in digital gait assessment. EURASIP J. Adv. Signal Process 2021, 2021, 10. [Google Scholar] [CrossRef]
- Sequence Folding Layer—MATLAB—MathWorks Switzerland. Available online: https://ch.mathworks.com/help/deeplearning/ref/nnet.cnn.layer.sequencefoldinglayer.html#mw_e600a552-2ab0-48a8-b1d9-ae672b821805 (accessed on 18 August 2022).
- Sequence Unfolding Layer—MATLAB—MathWorks Switzerland. Available online: https://ch.mathworks.com/help/deeplearning/ref/nnet.cnn.layer.sequenceunfoldinglayer.html?searchHighlight=unfolding%20layer&s_tid=srchtitle_unfolding%20layer_1 (accessed on 18 August 2022).
- Flatten Layer—MATLAB—MathWorks Switzerland. Available online: https://ch.mathworks.com/help/deeplearning/ref/nnet.cnn.layer.flattenlayer.html?searchHighlight=flatten%20layer&s_tid=srchtitle_flatten%20layer_1 (accessed on 18 August 2022).
- Time Series Forecasting Using Hybrid CNN—RNN. Available online: https://ch.mathworks.com/matlabcentral/fileexchange/91360-time-series-forecasting-using-hybrid-cnn-rnn (accessed on 30 March 2022).
- Qamhan, M.A.; Altaheri, H.; Meftah, A.H.; Muhammad, G.; Alotaibi, Y.A. Digital Audio Forensics: Microphone and Environment Classification Using Deep Learning. IEEE Access 2021, 9, 62719–62733. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Saeed, W.; Omlin, C. Explainable AI (XAI): A Systematic Meta-Survey of Current Challenges and Future Opportunities. arXiv 2021. [Google Scholar] [CrossRef]
- Božinović, N.; Perić, B. The role of typology and formal similarity in third language acquisition (German and Spanish). Stran-Jez. 2021, 50, 9–30. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | Features | Classifiers | Corpus | Classes | Languages | Results (%) |
|---|---|---|---|---|---|---|---|
| Zazo et al. [20] | 2016 | MFCC-SDC | LSTM-RNN | NIST LRE | 8 | Dari, English, French, Chinese, Pashto, Russian, Spanish, and Urdu | Accuracy = 70.90 |
| Bartz et al. [2] | 2017 | Spectrogram | CRNN | European Parliament Statements and News Channels on YouTube | 6 | English, French, German, Chinese, Russian, and Spanish | Accuracy = 91.00 |
| Ma and Yu. [27] | 2018 | DNN-BN | LSTM | AP17-OLR | 10 | Tibetan, Japanese, Kazakh, Korean, Indonesian, Mandarin, Cantonese, Vietnamese, Uyghur, and Russian | ER = 50.00 |
| Kumar. [16] | 2019 | FP-MFCC | ANN | IITKGP-MLILSC and AP18-OLR | 10 | Russian, Vietnamese, Indonesian, Cantonese, Japanese, Kazakh, Korean, Tibetan, Uyghur, and Mandarin | Accuracy = 70.80 |
| Kim and Park [11] | 2020 | Rhythm | R-Vector with I-Vector | SiTEC | 2 | English and Korean | ER = 4.73 |
| Mozilla | 3 | Chinese, English, and Spanish | ER = 47.38 | ||||
| Guha et al. [22] | 2020 | Mel spectrogram-RASTA-PLP | RF | CSS10 | 10 | French, Chinese, German, Dutch, Spanish, Greek, Finnish, Japanese, Russian, and Hungarian | Accuracy = 99.89 |
| VoxForge | 6 | English, French, German, Italian, Russian, and Spanish | Accuracy = 98.22 | ||||
| IIT-Madras | 10 | Assamese, English, Bangla, Gujarati, Tamil, Hindi, Telugu, Kannada, Marathi, and Malayalam | Accuracy = 99.75 | ||||
| Draghici et al. [21] | 2020 | Mel spectrogram | CRNN | EU Repo | 6 | English, French, German, Greek, Italian, and Spanish | Accuracy = 83.00 |
| Sisodia et al. [32] | 2020 | MFCC-DFCC | Extra Trees | VoxForge | 5 | Dutch, English, French, German, and Portuguese | Accuracy = 85.71 |
| Garain et al. [24] | 2021 | MFCC-Spectral Bandwidth- Spectral Contrast- Spectral Roll-Off- Spectral Flatness- Spectral Centroid- Polynomial-Tonnetz | FuzzyGCP | MaSS | 8 | Basque, English, Finnish, French, Hungarian, Romanian, Russian, and Spanish | Accuracy = 98.00 |
| VoxForge | 5 | French, German, Italian, Portuguese, and Spanish | Accuracy = 67.00 | ||||
| Sangwan et al. [23] | 2021 | MFCC-RASTA-PLP | FFBPNN | New Corpus | 4 | English, Hindi, Malayalam, and Tamil | Accuracy = 95.30 |
| Singh et al. [33] | 2021 | Log-Mel spectrograms | CNN | Mozilla | 4 | Estonian, Tamil, Turkish, and Mandarin | Accuracy = 80.21 |
| Shen et al. [25] | 2022 | Acoustic-Linguistic | RNN-T | MLS | 8 | Dutch, English, French, German, Polish, Portuguese, Italian, and Spanish | ER = 5.44 |
| Parameter | Value |
|---|---|
| Sampling Rate | 48 kHz |
| Date | 19 January 2022 |
| Validated Hours | 14,122 |
| Recorded Hours | 18,243 |
| Languages | 87 |
| Language | Number of Speech Files | Training/Validation 80%, Testing 20% | ||
|---|---|---|---|---|
| Training (90%) from 80% | Validation (10%) from 80% | Testing (20%) | ||
| Arabic | 2000 | 1440 | Arabic | 2000 |
| German | 2000 | 1440 | German | 2000 |
| English | 2000 | 1440 | English | 2000 |
| Spanish | 2000 | 1440 | Spanish | 2000 |
| French | 2000 | 1440 | French | 2000 |
| Russian | 2000 | 1440 | Russian | 2000 |
| Chinese | 2000 | 1440 | Chinese | 2000 |
| Total | 14,000 | 10,080 | Total | 14,000 |
| # Experiment | # Convolution Layers | Parameters | # Hidden Units in LSTM Layer | Training Accuracy (%) | Validation Accuracy (%) | Testing Accuracy (%) | Time Taken |
|---|---|---|---|---|---|---|---|
| 1 | 5 | Filter Size = 5 | 128 | 99.74 | 94.46 | 92.21 | 162 min 40 s |
| # Filters = 12 | |||||||
| 2 | 5 | Filter Size = 10 | 128 | 97.99 | 93.12 | 92.00 | 251 min 37 s |
| # Filters = 32 | |||||||
| 3 | 3 | Filter Size1 = 10 | 128 | 99.42 | 93.83 | 92.14 | 170 min 4 s |
| # Filters1 = 32 | |||||||
| Filter Size2 = 5 | |||||||
| # Filters2 = 12 | |||||||
| Filter Size3 = 15 | |||||||
| # Filters3 = 64 | |||||||
| 4 | 5 | Filter Size1 = 4 | 128 | 98.94 | 94.29 | 92.57 | 236 min 41 s |
| # Filters1 = 32 | |||||||
| Filter Size2 = 6 | |||||||
| # Filters2 = 12 | |||||||
| Filter Size3 = 8 | |||||||
| # Filters3 = 64 | |||||||
| Filter Size4 = 10 | |||||||
| # Filters4 = 32 | |||||||
| Filter Size5 = 12 | |||||||
| # Filters5 = 12 | |||||||
| 5 | 5 | Filter Size = 10 | 64 | 98.69 | 93.57 | 92.71 | 253 min 12 s |
| # Filters = 32 | |||||||
| 6 | 5 | Filter Size1 = 5 | 128 | 98.90 | 92.05 | 91.42 | 196 min 39 s |
| # Filters1 = 4 | |||||||
| Filter Size2 = 6 | |||||||
| # Filters2 = 8 | |||||||
| Filter Size3 = 7 | |||||||
| # Filters3 = 16 | |||||||
| Filter Size4 = 8 | |||||||
| # Filters4 = 32 | |||||||
| Filter Size5 = 7 | |||||||
| # Filters5 = 64 | |||||||
| 7 | 3 | Filter Size1 = 12 | 128 | 98.44 | 90.98 | 90.18 | 142 min 14 s |
| # Filters1 = 16 | |||||||
| Filter Size2 = 8 | |||||||
| # Filters2 = 24 | |||||||
| Filter Size3 = 5 | |||||||
| # Filters3 = 32 | |||||||
| 8 | 5 | Filter Size = 5 | 64 | 97.54 | 92.5 | 90.89 | 195 min 33 s |
| # Filters = 32 | |||||||
| 9 | 3 | Filter Size1 = 10 | 128 | 97.92 | 92.86 | 92.14 | 355 min 34 s |
| # Filters1 = 32 | |||||||
| Filter Size2 = 10 | |||||||
| # Filters2 = 64 | |||||||
| Filter Size3 = 10 | |||||||
| # Filters3 = 128 | |||||||
| 10 | 5 | Filter Size = 10 | 32 | 98.57 | 93.03 | 92.32 | 862 min 51 s |
| # Filters = 32 | |||||||
| 11 | 5 | Filter Size1 = 10 | 128 | 98.96 | 94.01 | 93.00 | 221 min 29 s |
| # Filters1 = 32 | |||||||
| Filter Size2 = 5 | |||||||
| # Filters2 = 12 | |||||||
| Filter Size3 = 15 | |||||||
| # Filters3 = 64 | |||||||
| Filter Size4 = 5 | |||||||
| # Filters4 = 12 | |||||||
| Filter Size5 = 10 | |||||||
| # Filters5 = 32 | |||||||
| 12 | 5 | Filter Size = 5 | 128 | 97.78 | 91.42 | 92.57 | 195 min 2 s |
| # Filters = 32 |
| Features: | GTCC | MFCC | GTCC-MFCC | |||
|---|---|---|---|---|---|---|
| Per Files (%) | Testing Accuracy (%) | Time Taken | Testing Accuracy (%) | Time Taken | Testing Accuracy (%) | Time Taken |
| Experiment 1 | ||||||
| Run # 1 | 89.07 | 142 min 49 s | 89.21 | 137 min 48 s | 92.21 | 162 min 40 s |
| Run # 2 | 90.00 | 145 min 31 s | 89.93 | 139 min 2 s | 91.79 | 161 min 36 s |
| Run # 3 | 88.68 | 145 min 43 s | 90.11 | 139 min 52 s | 91.25 | 163 min 11 s |
| Run # 4 | 89.21 | 145 min 54 s | 90.82 | 140 min 52 s | 91.86 | 164 min 57 s |
| Run # 5 | 88.64 | 147 min 3 s | 90.57 | 141 min 15 s | 91.68 | 153 min 46 s |
| Average | 89.12 | 145 min 36 s | 90.13 | 138 min 34 s | 91.76 | 160 min 38 s |
| Testing Accuracy | Per Sequences (%) | Per Files (%) | ||
|---|---|---|---|---|
| GTCC and MFCC | Experiment 1 | Experiment 11 | Experiment 1 | Experiment 11 |
| Run # 1 | 83.73 | 83.77 | 92.21 | 93.00 |
| Run # 2 | 82.31 | 83.61 | 91.79 | 92.61 |
| Run # 3 | 82.18 | 83.93 | 91.25 | 92.86 |
| Run # 4 | 82.28 | 84.08 | 91.86 | 93.11 |
| Run # 5 | 82.44 | 83.58 | 91.68 | 92.46 |
| Average | 82.59 | 83.79 | 91.76 | 92.81 |
| Standard Deviation | 0.64 | 0.21 | 0.35 | 0.27 |
| The Best Accuracy | 83.73 | 84.08 | 92.21 | 93.11 |
| The Worst Accuracy | 82.18 | 83.58 | 91.25 | 92.46 |
| Predicted | ||||||||
|---|---|---|---|---|---|---|---|---|
| Arabic | Chinese | English | French | German | Russian | Spanish | ||
| Actual | Arabic | 377 | 5 | 3 | 4 | 8 | 2 | 1 |
| Chinese | 4.6 | 345 | 14 | 9.8 | 15.6 | 5 | 6 | |
| English | 4 | 4.2 | 366.8 | 2 | 16 | 1 | 6 | |
| French | 2 | 3 | 1 | 364.8 | 21.2 | 3 | 5 | |
| German | 2 | 1 | 2.2 | 3 | 385.8 | 2 | 4 | |
| Russaian | 3 | 1 | 1.6 | 3 | 4 | 385.4 | 2 | |
| Spanish | 1 | 6 | 8.6 | 7.8 | 26 | 6.2 | 344.4 | |
| P(%) | 95.78 | 94.47 | 92.35 | 92.49 | 80.95 | 95.25 | 93.49 | |
| R(%) | 94.25 | 86.25 | 91.70 | 91.20 | 96.45 | 96.35 | 86.10 | |
| F1(%) | 95.01 | 90.17 | 92.02 | 91.84 | 88.02 | 95.80 | 89.64 | |
| Accuracy(%) | 91.76 | |||||||
| Predicted | ||||||||
|---|---|---|---|---|---|---|---|---|
| Arabic | Chinese | English | French | German | Russian | Spanish | ||
| Actual | Arabic | 378.2 | 4 | 3.6 | 4 | 7 | 1 | 2.2 |
| Chinese | 4.4 | 353.4 | 10.6 | 8.8 | 14.4 | 4.4 | 4 | |
| English | 3.8 | 3.2 | 369 | 2 | 16 | 1 | 5 | |
| French | 3 | 1.6 | 2 | 367.8 | 21.8 | 1.2 | 2.6 | |
| German | 1.8 | 0 | 1 | 2 | 390.2 | 1 | 4 | |
| Russian | 3.4 | 1 | 0 | 4.2 | 3 | 385.4 | 3 | |
| Spanish | 0 | 1.8 | 7 | 8.2 | 24.2 | 4.2 | 354.6 | |
| P(%) | 95.84 | 96.82 | 93.85 | 92.64 | 81.87 | 96.79 | 94.46 | |
| R(%) | 94.55 | 88.35 | 92.25 | 91.95 | 97.55 | 96.35 | 88.65 | |
| F1(%) | 95.19 | 92.39 | 93.04 | 92.29 | 89.02 | 96.57 | 91.46 | |
| Accuracy(%) | 92.81 | |||||||
| Study and Ref. | Features | Classifiers | Corpus | Classes | Languages | Results (%) |
|---|---|---|---|---|---|---|
| Bartz et al. [2] | Spectrogram | CRNN | European Parliament Statements and News Channels on YouTube | 6 | English, French, German, Chinese, Russian, and Spanish | Accuracy = 91.00 |
| Kim and Park. [11] | Rhythm | R-vector with SVM | SiTEC | 2 | English and Korean | ER = 2.26 |
| Mozilla | 3 | Chinese, English, and Spanish | ER = 53.27 | |||
| Zazo et al. [20] | MFCC-SDC | LSTM-RNN | NIST LRE | 8 | Dari, English, French, Chinese, Pashto, Russian, Spanish, and Urdu | Accuracy = 70.90 |
| Ma and Yu [27] | DNN-BN | LSTM | AP17-OLR | 10 | Tibetan, Japanese, Kazakh, Korean, Indonesian, Mandarin, Cantonese, Vietnamese, Uyghur, and Russian | ER = 50.00 |
| Draghici et al. [21] | Mel-spectrograms | CRNN | EU Repo | 6 | English, French, German, Greek, Italian, and Spanish | Accuracy = 83.00 |
| Singh et al. [33] | Log-Mel spectrograms | CNN | Mozilla | 4 | Estonian, Tamil, Turkish, and Mandarin | Accuracy = 80.21 |
| Proposed System | GTCC-MFCC | CRNN | Mozilla | 7 | Arabic,German,English,Spanish,French,Russian,andChinese | Accuracy = 92.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alashban, A.A.; Qamhan, M.A.; Meftah, A.H.; Alotaibi, Y.A. Spoken Language Identification System Using Convolutional Recurrent Neural Network. Appl. Sci. 2022, 12, 9181. https://doi.org/10.3390/app12189181
Alashban AA, Qamhan MA, Meftah AH, Alotaibi YA. Spoken Language Identification System Using Convolutional Recurrent Neural Network. Applied Sciences. 2022; 12(18):9181. https://doi.org/10.3390/app12189181
Chicago/Turabian StyleAlashban, Adal A., Mustafa A. Qamhan, Ali H. Meftah, and Yousef A. Alotaibi. 2022. "Spoken Language Identification System Using Convolutional Recurrent Neural Network" Applied Sciences 12, no. 18: 9181. https://doi.org/10.3390/app12189181
APA StyleAlashban, A. A., Qamhan, M. A., Meftah, A. H., & Alotaibi, Y. A. (2022). Spoken Language Identification System Using Convolutional Recurrent Neural Network. Applied Sciences, 12(18), 9181. https://doi.org/10.3390/app12189181