Abstract
In recent years data science has been applied in a variety of real-life applications such as human-computer interaction applications, computer gaming, mobile services, and emotion evaluation. Among the wide range of applications, speech emotion recognition (SER) is also an emerging and challenging research topic. For SER, recent studies used handcrafted features that provide the best results but failed to provide accuracy while applied in complex scenarios. Later, deep learning techniques were used for SER that automatically detect features from speech signals. Deep learning-based SER techniques overcome the issues of accuracy, yet there are still significant gaps in the reported methods. Studies using lightweight CNN failed to learn optimal features from composite acoustic signals. This study proposed a novel SER model to overcome the limitations mentioned earlier in this study. We focused on Arabic vocal emotions in particular because they received relatively little attention in research. The proposed model performs data augmentation before feature extraction. The 273 derived features were fed as input to the transformer model for emotion recognition. This model is applied to four datasets named BAVED, EMO-DB, SAVEE, and EMOVO. The experimental findings demonstrated the robust performance of the proposed model compared to existing techniques. The proposed SER model achieved 95.2%, 93.4%, 85.1%, and 91.7% accuracy on BAVED, EMO-DB, SAVEE, and EMOVO datasets respectively. The highest accuracy was obtained using BAVED dataset, indicating that the proposed model is well suited to Arabic vocal emotions.
1. Introduction
Humans are able to produce a wide range of sounds in conversations, pertaining to a variety of multilingual words through their mouths [1,2]. The understanding of these words among humans, while communicating with each other is obvious, but when it comes to the human—machine emulation, it requires considerable speech signal processing. Humanoid speech signals reveal exploitable information about the language, overarching message content, intonation, trait, accent, gender, and other distinct properties of the speaker. To make machines capable to infer emotional information from speakers’ utterances by processing and classifying the speech signals is referred to as Speech Emotion Recognition (SER) [3].
Researchers have recently paid a lot of attention to the creation of an efficient human-technology communication interface, which falls under the category of human-computer interaction (HCI). In a broader perspective, emotion recognition from speech signals has been used in a variety of applications, including speech synthesis, robotics, automobile industry, multimedia technologies, healthcare, education, forensics, customer service, and entertainment [4]. The taxonomy of text-to-speech aids in the development of screen readers for the blind [5]. Nowadays, robotic technologies are increasingly evolving sensor data that comes from internal and external environmental factors, impacting decision-making through emotion recognition. Experimental paradigms that identify emotions from publicly available datasets must be carefully evaluated since they may fail when used in a real-world context [6]. In the automobile industry advanced image/video and voice-based signal processing methods are employed to identify drowsiness and lassitude in drivers [7,8,9].
The abstraction of hidden features of an individual or a system extracted from heterogeneous multimedia content for recommendation systems has received the attention of SER researchers [10]. Intensity detection of virus attacks through patients’ voice signals has opened a new challenge area in medical science since the current COVID-19 spread [11]. Speech recognition techniques have recently been incorporated into online learning platforms for emotional analysis. Positive emotions consequently influence students’ inspiration, dedication, and self-learning abilities. On the other hand, negative emotions leave an adverse impact on students’ performance [12]. A recent study has discovered several significant facts in human brain images, demonstrating how they do cognitive-based speech synthesis, which has given rise to new research trends in automatic speech recognition (ASR) and forensic systems [11,12,13]. In order to provide high-quality customer care services, SER techniques are being applied to estimate the emotions of telemarketing agents and customers from their conversations.
The desirable emotion detection can be achieved directly from speech signals. A classic SER system includes signal pre-processing, feature extraction, feature selection, and classifier to emotional information like happy, sad, fear, surprise, anger, etc. Each phase of the SER process is detailed as follows.
Speech Signal Processing: Speech signals data collected from speakers’ utterances are generally uneven and cumbersome, which requires apt pre-processing and post-processing for extraction of appropriate acoustic features [13]. Pre-emphasis, speech segmentation or block framing, window weighing function, voice activity detection (VAD), normalization, noise reduction, and feature selection are examples of commonly used speech processing techniques.
Feature Extraction: The success ratio of SER classifiers mainly depends on the extraction of discriminative and relevant feature sets. There is currently no set of traits for SER that is accepted globally, according to experimental studies. Therefore, whether to use global or local features for better classification outcomes relies on the research methodology. In addition, inappropriate features can be overhead for the classifier. The continuous and variable length speech signals enclose rich information about the emotions. Global features signify overall statistical facts like minimum or maximum values, mean, median, and standard deviation. These are also known as long-term or suprasegmental features. Local features, on the other hand (also known as short-term or segmental features) [14] describe the chronologically changing aspects in which a stationary state is estimated [15].
In recent research work, handcrafted feature extraction remained immensely under consideration, however, it required sufficient domain knowledge for the experts. The four main categories listed below [16,17] can be used to analyze speech features in SER systems [18,19].
- Prosodic Features: Innovation of prosodic or para-linguistic features has carried out the most distinguishing properties of emotional information for SER systems. Prosodic features like intonation and rhythm are extracted from large units of human utterances, thus categorized in long-term features. Widely employed characteristics on which typical prosodic features are based are pitch, energy, length, and frequency.
- Spectral Features: Humanoid vocal tract is a kind of filter that controls the shape of sound produced during speech utterance. Vocal tract properties are better explained when presented in the frequency domain. The process of transformation of time domain signals into equivalent frequency domain signals through Fourier transform contributes to spectral features extraction. The segmented acoustic data of variable length (usually 20 to 30 ms) obtained from window weighting function is used as input in spectral filters. Various types of spectral parameters in speech have been explored using manifold dimensional reduction methods, such as Linear Predictive Coding (LPC), Linear Prediction Cepstral Coefficients (LPCC), Log Frequency Power Coefficient (LFPC), Gamma tone Frequency Cepstral Coefficients (GFCC) and Mel-Frequency Cepstral Coefficients (MFCC).Among all the above-mentioned filter-banks, MFCC is the most implemented in SER because of its robustness and noisy background resistance. After segmentation of utterances, MFCC features are obtained that describe the short-term power spectrum in acoustic signals. Frequencies of the acoustic tone of vocal tract are known as Formants, which define phonetic features of vowels.
- Voice Quality Features: Voice Quality features define the physical characteristics of the glottal source. And there exists a strong correlation between the quality of voice and the emotional data of the speech. The set of features associated with voice quality includes jitter (i.e., per cycle frequency variation parameter), shimmer (defined as amplitude variation parameter for soundwave), fundamental frequency and harmonics to noise ratio (HNR) [20].
- TEO Based Features: Teager Energy Operator (TEO) was presented by Teager [21] for the detection of stress rate in speech signals. In a stressful state, due to muscular tension in the glottal of a speaker, changes may occur in airflow while producing sound. The non-linear TEO was mathematically formulated by Kaiser as shown in Equation (1). Where, represents the TEO and depicts the acoustic signal under consideration.
SER Classification: Emotion classification in the SER system is accomplished by a variety of classifiers trained based on the master feature vector. The traditional Machine Learning (ML) classifiers [4], specifically used in SER systems include K-Nearest Neighbours (k-NN), Support Vector Machine (SVM), Hidden Markov Model, Gaussian Mixture Model (GMM) and Artificial Neural Network (ANN). Additionally, instead of using an individual classifiers, different classifiers have also been used in combination to improve the efficacy of emotion detection process [22].
There are few limitations of classic ML based techniques when applied for speech emotion detection [23]. First, there is no definite ML based algorithm, capable of extracting discriminative and accurate features for multilingual speech databases. Moreover, the frequency and time domain acoustic features are unable to train a model for multilingual SER. Second, manually extracted features through knowledgeable domain experts are specifically domain dependent that cannot be reused in other identical domains. Third, efficient modelling of machine learning classifiers necessitates a massive number of labelled handcrafted features to attain maximum performance for speech emotion detection. Construction of database for the languages, for instance Arabic, collecting large amount of labelled data may require a soundproof eco-friendly environment. Fourth, because of the generic nature of ML based SER classifiers, the classification performance may drastically decrease for variant linguistic content, speakers, and acoustic settings.
In contrast to the longstanding ML techniques, Deep Learning (DL) methods reduced the manual efforts for the extraction of discriminative features from acoustic signals. Deep Learning comprises of manifold layered architecture of artificial neural networks that learns the features in hierarchical manner. The most practicing speech emotion detection classifiers based on DL are Deep Neural Networks (DNN), restricted Boltzmann machine (RBM), Convolutional Neural Networks (CNN), Long-Short Term Memory Networks (LSTM) and Recurrent Neural Networks (RNN). Additionally, some enhanced DL methods such as Deep Autoencoder (AE), Multitask Learning, Attention Mechanism, Transfer Learning and Adversarial Training have also been employed for SER. Most importantly, multiple DL classification methods can be collectively employed in different layers for model construction, which is robust and improve overall performance and flexibility. Thus, in this study, a novel transformer based method was proposed to improve the recognition rate of emotion detection and reduce the model training time under limited computation resources. The performance of proposed transformer is compared with baseline deep learning methods in terms of accuracy. In addition, this also investigate the optimize set of features and data augmentation methods to reduce the overfitting problem due to inadequate data.
The rest of this paper is structured as follows. Section 2 presents the literature review on SER techniques. Section 3 describes the datasets employed to perform experiments, features extraction, transformer model adopted for SER and evaluation measures. Section 4 presents the experimental results and the significance of the observed findings. The conclusion and future research directions are provided in Section 5.
2. Literature Review
Numerous works has been done for emotion detection from the speech signals using both machine and deep learning techniques. However, to a great extent, performance and efficacy of the proposed model depends on dataset used for model training. This section is divided into two sections; first analyses few pre-constructed speech datasets for SER along with their shortcomings and second reviews some latest research contributions for the development of effective SER classification models using DL techniques.
An Urdu database for speech emotion recognition have been introduced for the training of ML models. The data collection comprises of recorded audios for seven emotions with 734 Urdu and 701 Sindhi utterances [24]. Moreover, the authors employed baseline classification using OpenSmile feature extraction toolkit in terms of UAR. The results show that the regression models applied on ComParE performs better classification, achieving 56.03% accuracy for Urdu and Sindhi SER. The collection of Urdu-Sindhi Corpus encompasses only 10 scripted sentences for every type of emotion. The major limitation of such recordings is that, for instance, a specific scripted sentence utterance may represent more than one emotion. Moreover, in such cases speaker is not representing real world situation. In another acted Urdu SER database, ref. [25] collected utterances of 25 words from 50 speakers (25 male and 25 female) based on three emotions. Nonetheless, the employment of such small-scale Urdu databases using DL models would be inappropriate and may not be useful for the development of real time SER applications. Ref. [26] formulated first custom URDU dataset for Urdu language. In URDU dataset 400 audio records were collected from different Urdu television talk shows representing 4 basic emotions. Though, the collected data contained unscripted spontaneous conversations of anchors with their guests, representation of actual emotions in TV talk shows is quite unusual because the most dominant emotion in such conversations is neutral or aggressive. Since the training of deep learning models require huge amount of data, the small URDU dataset may lead to over fitting or under fitting problems.
In a study, ref. [27] used an endways multi-learning trick (MLT) based on 1D enhanced CNN model for automatic extraction of local and global emotional features from acoustic signals. For the enhancement of recognition rate, the proposed solution extracted the discriminative features using dynamic fusion framework. The proposed multi-learning model evaluated both short as well as long-term relative dependencies over two benchmark SER databases, IEMOCAP and EMO-DB, with 73% and 90% accuracy rates, respectively. However, the method relatively takes more time to train and test the real time speech signals as compared to other models. Exploring two datasets, RECOLA (to employ regression) and IEMOCAP (for classification task), ref. [28] detected the emotions in speech using a novel end-to-end DNN algorithm. The authors found that SER performance in simulation results was optimum when proposed method applied with RMS aggregation and context stacking. The proposed DiCCOSER-CS model improved the arousal CCC by 9.5% and the valence CCC by 12.7% in regression task as compared with CNN-LSTM.
Recurrent Neural Networks models have also been implemented with slight variations for feature learning in SER systems. A similar study [29] illustrates deep RNN, learning frame-level categorization as well as temporal collection into long time intervals. Also, the authors presented weighted time-pooling scheme to classify emotionally prominent fragments from the speech signals using simple attention mechanism. The model achieved 5.7% weighted and 3.1% unweighted classification accuracy using IEMOCAP dataset, when compared with conventional SVM-SER model. Although, the model introduced novel technique for emotion recognition, the experiments were conducted using only one database.
For the imbalanced SER [30] introduced Attention-Integrated Convolutional RNN. The experimental results on Emo-DB and IEMOCAP demonstrate better performance for imbalanced speech emotions. In another related work, a self-attention mechanism [31] is added to the Bidirectional Long Short-Term Memory (BLSTM) based classification. The proposed solution not only accomplished correlation of speech signals in the statements but also improved the diverse information using directional self-attention (DSA). The algorithm performed well on IEMOCAP (comprising complete, script, and spontaneous) and EMO databases.
There are few works on the domain of Arabic spoken speech emotion recognition. Therefore, this study focused on the recognition of Arabic speech emotion. In 2018, according to [32], the first study on emotion recognition in spoken Arabic data is proposed. The speech corpus is collected from Arabic TV shows. Videos were labeled into three categories happy, angry or surprised. The study used 35 classification methods. The best classification performance is provided by the Sequential Minimal Optimization (SMO) classifier, which achieves 95.5%.
Another study on Arabic speech emotion was introduced in [33]. This study provides a dataset called “Semi-natural Egyptian Arabic speech emotion (EYASE)”. This study was focused on Egyptian sentences. This study adopts SVM and KNN classifiers. The highest accuracy achieved was 95% using SVM. The highest accuracy was obtained in Male emotion recognition. Happiness was the most difficult to detect, while anger was the easiest.
A study by [34] that built dataset based on real-world Arabic speech dialogs for detecting anger in Arabic conversation. The result revealed that acoustic sound features such as fundamental frequency, energy, and formants are more suitable for detecting anger. The experimental findings demonstrated that support vector machine classifiers can identify anger in real time at detection rate of more than 77%.
3. Proposed Methodology
This section discusses the detailed research methodology adopted for emotion recognition from audio files. In the proposed research methodology, the augmentation methods (white noise, time stretch) were utilized on each file to enhance the training data. Secondly, a variety of features including MFCCs, spectrograms, chroma, and tonnetz, and spectral contrast are extracted from each file and fed as input to train the transformer model for SER. Finally, the proposed method is evaluated using four datasets based on robustness, accuracy, and time. The proposed transformer model has been implemented using Keras library that helps to perform simulations easily. Moreover, for SER, Librosa library is used to perform experiments and used to evaluate the sound signals. This library packages helps to implement the data augmentation and feature extraction methods. All the experiments are performed on a laptop with 2.5 GHz Dual-Core Intel® Core i5 processer, 12 GB memory and 512 GB SSD hard drive. The detail description of each subsection is presented below.
3.1. Datasets
As the initial process of the proposed methodology, four publicly available datasets are collected. In this work, Basic Arabic Vocal-Emotions Dataset (BAVED) is selected to evaluate the proposed method. This dataset is the collection of Arabic audio/wav including seven words ([“like”] أعجبني, [“dislike”] لم يعجبني, [“this”] هذا, [“film”] الفيلم, [“fabulous”] رائع, [“good”] معقول, [“bad”] سيئ) to assess the emotions starting from 0 to 6 respectively. Furthermore, each these words was divided in three higher classes presenting the human emotions and these classes are 0, 1 and 2. The first corresponding level 0 defines low emotions that present tired or exhausted, level 1 defines neutral emotions and level 2 number correspondence represents higher level of emotion either it is positive or negative like happiness or sadness enjoying or feeling angry. The complete set of recordings in BAVED dataset have 1935 instances recorded from 61 individuals selected 45 men and 16 women voices in different occasions.
We also used the following datasets to evaluate the proposed model: EMO-DB, SAVEE, and EMOVO. EMO-DB [35] is employed as one of the datasets for our experiments as it is widely used by the researchers in the field of SER. This is a German dataset that comprises 535 audio files of distinct duration belonging to 5 male and 5 female’s speakers. These files are further classified into seven classes: disgusting, angry, boredom, happy, fear, neutral, and sad. As voice quality depends on the sample rate, encoded method, bit rate, and file format, all the files are consisting of wav format, mono-channel, 16 kHz sample rate, and 16-bits per sample.
Surrey Audio-Visual Expressed Emotion (SAVEE) is another famous multimodal dataset which contains seven types of emotions recorded from 4 male actors. The total utterances in this dataset are 480 created in British English. Ten evaluators examine the audio, video, and combined audio-visual conditions to assess the quality of recordings. Labels of used emotion utterances in our study are neutral, happiness, sadness, anger, surprise, fear, and disgust. The standard TIMIT corpus script was used to record statements.
EMOVO dataset contains seven emotional states that are disgust, fear, anger, joy, surprise, sadness, and neutral. EMOVO is the first dataset that contains Italian language utterances. This dataset has recordings of 6 actors speaking the content of 14 sentences. All 588 utterances in this dataset are further annotated and divided into two groups, including 24 annotators in each group. The Fondazione Ugo Bordoni laboratories were used to record all utterances.
3.2. Data Augmentation
Data augmentation is a technique that is commonly used to prevent overfitting while applying machine learning based techniques for classification of speech emotions. Some common techniques like addition of Gaussian noise, stretching time or shifting the pitch are used for data augmentation applied while training the data. Besides the overfitting, data augmentation is also used for different purposes like generalization of accuracy, robust performance, and perfect data distribution while having less variance in data. To enhance the performance of proposed transformer model, this study used above mentioned data augmentation techniques. Gaussian noise technique was used to increase the training data considering the amplitude of noise value denoted as “σ”. It is important to select the value of σ because higher or low value can affect the performance of model. If it is low, it decreases the performance while a higher value of σ increase the difficulty in model optimization. The pitch shift technique was used to generate new speech signals whose pitch wavelength was shifted by a series up to n steps. Pitch shifting does not affect the duration of signal. Time stretching approach was used in last that altered the tempo and pitch of the signal. These three data augmentation techniques increase the training data to improve the performance of proposed model and keep away from overfitting. The results of the three augmentation methods applied in our proposed model is shown in Figure 1.

Figure 1.
Audio features extraction after data augmentation in the form of spectrogram (a) MFCC (b) Chromagram (c) Spectral Contrast (d) Mel spectrogram (e) Tonnetz.
3.3. Feature Extraction
In the sake of speech emotion classification feature extraction can help to diminish computational errors, computational time, and model complexity. However, it is necessary to extract such acoustic feature who provide valid information about the emotion. For the proposed model, Mel-spectrogram, Chromagram, MFCCs, delta MFCCs, delta-delta MFCCs and Tonnetz representation and Spectral Contrast features were extracted from BAVED, EMO-DB, SAVEE and EMOVO datasets. The following list provide some details about extracted features.
- Mel-spectrogram features: to extract these features audio signals broken down into frames and for each frame Fast Fourier transform is applied. The frequency spectrum is separated by the frequency of equal space to get the Mel-scale of signal frame.
- Chromagram features: 12 distinct pitch classes used to extract Chromagram features using STFT and binning method. These features help to differentiate harmony and pitch classes.
- MFFCs, delta MFCCs, delta–delta MFCCs based features: MFCCs features represent short-term power spectrum while Mel-frequency Cepstrum have equally spaced frequency band and provide insights for better classification by measuring the capacity of human ear to bear the audio signal. There are 40 sets of MFCCs, delta MFCCs, delta-delta MFCCs in the three Mel-cepstrum extracted features. All audio signals were divided into equal length frames to extract MFCC features. These frames revised to remove silence portion for both the start and end of the frame by applying windowing operations. Furthermore, the time domain signal converted to the frequency domain using Fast Fourier Transform (FFT). A mean scale filter bank applied to compute values of FFT computed frequencies. Equation of Mean scale filter bank isAfter the computation of frequency values power logs are further computed for each Mel-frequency. At the end Discrete Cosine Transform (DCT) used to transform all log-Mel-spectrums into time domain and the extracted amplitudes known as MFCCs.Mel(f) = 2595 × log10 (1 + f/700)
- Tonnetz based features: the relation in between fall and rise of speech signal of harmonic network is described by pitch space of six-dimensions. To distinguish Q1 environmental sounds the tonal features of audio frames play an important role.
- Spectral contrast-based features: the root mean square difference between spectral proof and the peak of signal frames computed to attain Spectral features.
The total number of features extracted for this study is 273 which includes 128 + 12 + 40 + 40 + 40 + 6 + 7 features of Mel-spectrogram, chromagram, MFFC, delta-MFCC, delta-delta MFCC, tonnetz, and spectral respectively. These extracted features are further used for the training of the proposed model.
3.4. Evaluation Metrics
Different evaluation metrics like Accuracy, precision, recall, and F1-score were applied to evaluate each ESC model. For each prediction, a confusion matrix was used to detect True-positive (TP), False-positive (FP), True-negative (TN), and False-negative (FN).
Accuracy: this metric is used to calculate the frequency of sound classes that can be accurately determined from the entire speech signal. The following equation is used to calculate the accuracy of results:
Recall: to check the number of positive instances that are accurately detected by the proposed model is checked by recall using the following equation.
Precision: to check the correctly detected actual utterances precision method is used using the following equation.
The evaluation matrices used to evaluate the proposed transformer model are widely used to measure the performance of models used for detection, classification, and prediction systems.
3.5. Transformer Model
Initially, the transformer model was erected to use for machine-level translation. However later it becomes popular in Natural Language Processing (NLP) and replaces recurrent neural networks (RNN) with its efficient performance [36,37]. The transformer model uses a different internal attention mechanism also known as the self-attention mechanism eliminate the recurrence of any type of processing. It uses a linear transformation to generate significant features for a given statement or utterance.
Exploring its structure, it consists of a block having sub-blocks of encoders and decoders. Both sub-blocks perform different activities like encoder transforming audio signals into an order of transitional illustrations. These illustrations are further passed to the decoder block to produce the desired output. Encoder encodes feature vectors into X = (x1, …, xT) and decoder decodes encoded feature illustrations into W = wm = (w1, …, wM). Because of the autoregressive nature of the transformer model, each stage takes input that is the output of the previous stage and each block has multiple self-attention layers that are connected with each other. Both encoder and decoder blocks worked individually.
The traditional speech recognition models used attention mechanisms that include simple blocks of encoder and decoder. First, the sound signals given to the encoder encode into alternative signals that are further decoded by the decoder that predicts the input features and converts the labels into the sequence provided by the encoder. To predict the output and recognition of speech the attention mechanism is used and highlights the significant parts of speech. As compared to all these traditional models the transformer model has multiple encoders and decoders and each block has an internal self-attention mechanism, and these attention layers are interconnected.
According to the studies, an encoder of a transformer model contains six layers of coders placed in a sequence of top to bottom. All coders have the same structures, and several coders are not fixed and can vary in different models for the encoder block. The structure of coders is similar to a block, but weights can be different. Usually, the encoder of the transformer model takes extracted features as input that were extracted by frequency coefficients or convolutional neural networks. Each encoder in a sequence performs a similar task and transforms extracted features into an alternative signal using self-attention and feed-forward transformed vectors to the next encoder using a simple Artificial neural network. The transformed vectors are transmitted to the decoder block by the last encoder.
The decoder block has the same numbers of decoders as in the encoder block arranged in a sequence. Each decoder in the block has a similar two-layered structure to encoders where the first layer takes input and transforms features into vectors and the second layer feeds these encoded vectors to the subsidiary encoder. However, the difference in the decoder layer is that there is an additional attention layer that helps the decoder to focus on a significant part of given frames of encoded feature vectors. Here the self-attention layer considers the prior data to decode the feature vectors and predict the incoming sentences. Then the second layer outputs the posterior probabilities of decoded words or characters and the same procedure is applied for each word of the statement.
The self-attention mechanism makes the transformer model successful in speech recognition however this mechanism can be further extended to improve the performance of the model. It can be expanded to a multi-head self-attention mechanism. It can be extended in a way that it split the input sequence into different chunks and these chunks can be augmented in multiple dimensions and projections. The other way to extend the mechanism is that each chunk of input features passed through an individual and unbiased attention mechanism. The third way to extend the mechanism is that before projecting the output encoding each chunk is concatenated while encoding. The third way of extending the self-attention mechanism can be described as follows
where ei = Attention (QWQi, KWKi, V WVi)
Multi-Head Attention or MHA (Q, K, V) = [e1, · · ·, eH] Wo
However, in the above equation of MHA H describes the total number of heads, the input sequence of dimensions is din while dk= din/H, and the encoding generated by head i is ei, Wo ∈ Rdin×din, W×WQi ∈ Rdin×dk, WKi ∈ Rdin×dk and WVi ∈ Rdin×dv.
Transformer models provide higher dimensional representations because of the multi-head self-attention mechanism from multiple subspaces. The structure of the proposed transformer model is presented in Table 1.

Table 1.
Structure of proposed model.
4. Experiments
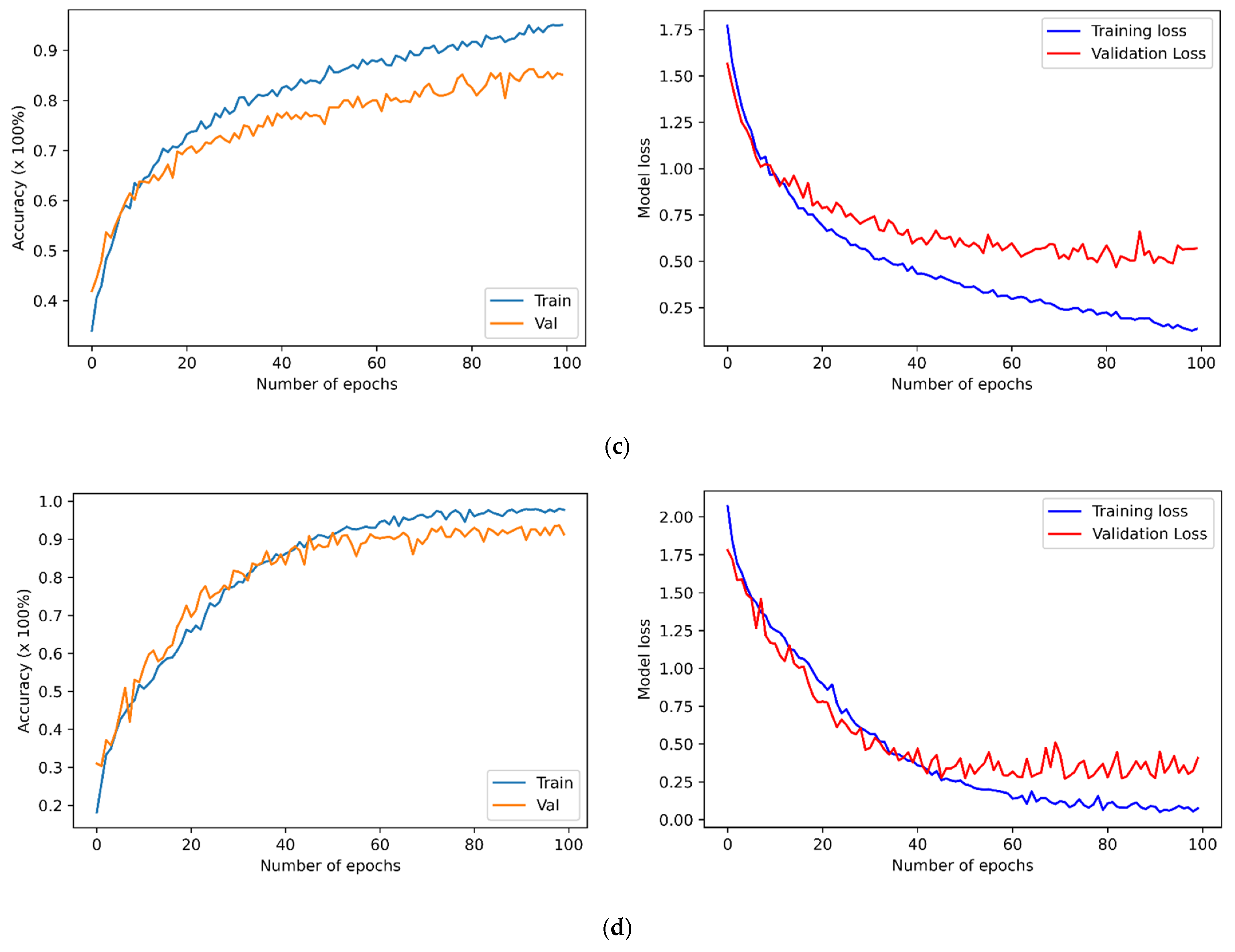
The four previously described datasets were used to run speaker-independent experiments to evaluate the proposed SER. It applied a percentage-split technique where it split the data into two sets, the first set including 80% of the data used to train the SER models, and the remaining 20% data were used to perform testing. Prior studies concluded that it is better to train the model using 70–80% of the dataset, and the remaining 30–20% should be used for testing purposes. This dataset splitting technique can help achieve improved results, and SER models prevent overestimating and overlapping results. Figure 2 presents the performance of the proposed transformer model applied to the datasets as mentioned above, using a feature set of 273 to train the model. The table provides information about the accuracy of the proposed model applied to selected datasets.
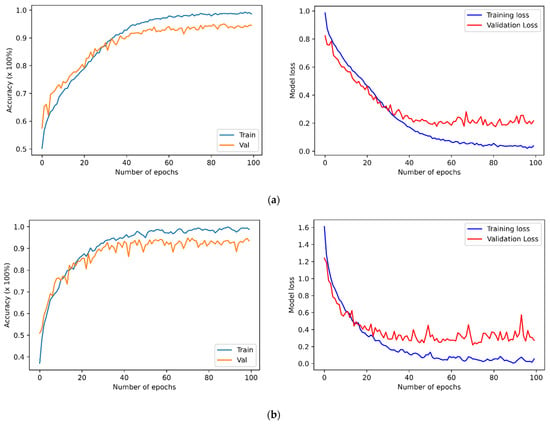
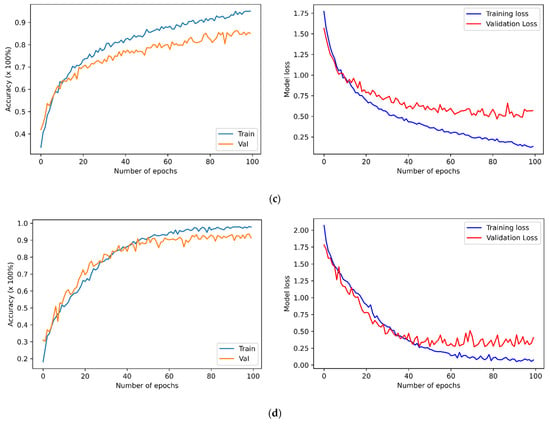
Figure 2.
The training and validation accuracies along with losses of SER models for the (a) BAVED, (b) EMO-DB, (c) SAVEE, and (d) EMOVO.
4.1. Models Prediction Performance
The proposed model uses four datasets in this study. Table 2, Table 3, Table 4 and Table 5 present the evaluation and classification results of BAVED, EMO-DB, SAVEE, and EMOVO datasets respectively. The metrics used for evaluation are precision, recall, F1-measure, and accuracy for each emotion type. Tabulated results describe the efficiency of the proposed model compared with baseline techniques for SER [38,39,40,41,42].
Table 2.
Performance of the proposed model for the BAVED dataset.
Table 3.
Performance of the proposed model for the EMO-DB dataset.
Table 4.
Performance of the proposed model for the SAVEE dataset.
Table 5.
Performance of the proposed model for the EMOVO dataset.
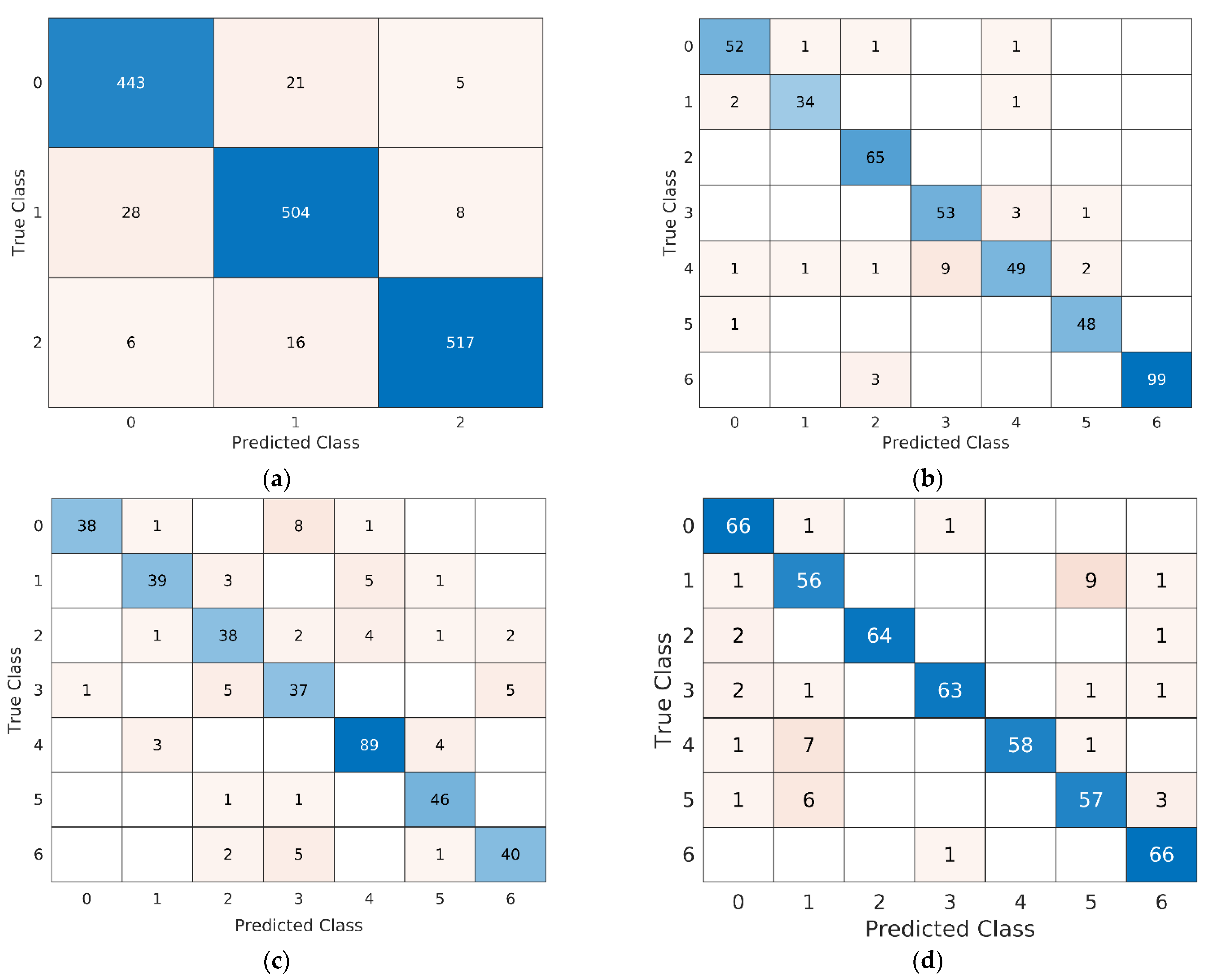
The highest predicted accuracy is shown in the confusion matrix (Figure 3a) of the BAVED dataset. It achieved 96% for anger/sad/happy emotion, 94% for tired/exhausted emotion, and 93% for neutral. The overall predicted accuracy of the proposed model also outperformed the existing SER models applied on BAVED [43]. The proposed model achieved 93% accuracy for EMO-DB and outperforms the baseline EMO-DB models. The proposed model predicts better accuracy because of discriminative features for all types of emotions. Figure 3b describes the accuracy and confusion of inter-emotions for the SER model. The diagonal values show the predicted values in the confusion matrix, while the values shown in equivalent rows represent the inter-emotion confusion.
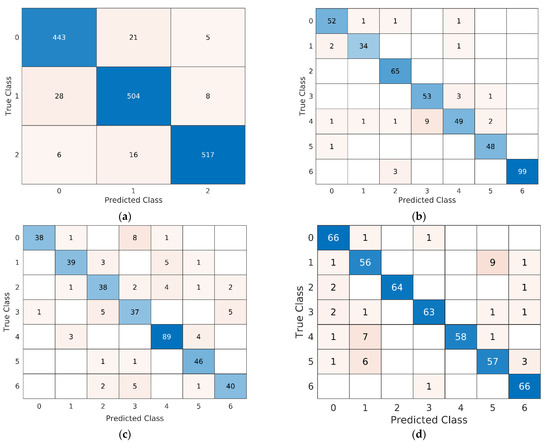
Figure 3.
Confusion matrixes of the BAVED, EMO-DB, SAVEE, and EMOVO. (a) The BAVED; (b) the EMO-DB; (c) the SAVEE; (d) the EMOVO. The y-axes illustrate the true/actual labels, and the x-axis illustrates the predicted labels.
Figure 3c shows the SAVEE dataset confusion matrix that represents accuracies for all emotions. It presents 96% accuracy for sad emotion, 93% for neutral, 83% for surprise, 81% for disgust, and 79% for anger emotion. However, the fear emotion achieved the lowest accuracy. The possible reason behind this misclassification might be because the frequency of signals of this emotion is very similar to other emotions and hence is challenging for the proposed model to recognize emotion accurately. In the end, Figure 3d shows the confusion matrix of the EMOVO dataset. The average accuracy of the EMOVO SER model in emotion prediction is 91%. However, the individual emotions also achieved higher accuracy as surprise amotion achieved 99% accuracy, 97% for anger emotions, and 96% for fear emotion. For the F1 score of BAVED, neutral emotion achieved the lowest score of 93%, while anger/sad/happy emotion achieved a 96% F1 score, and tired/exhausted emotion achieved 94%. The proposed SER model was low in memory size and computational time, which made the transformer model possible to improve the prediction performance. Another factor that makes the proposed SER model robust is the usage of discriminative emotion features and plain transformer model design.
4.2. Comparison with Baseline Techniques
Four publicly available datasets BAVED, EMO-DB, SAVEE and, EMOVO are used to train the proposed transformer model for an effective SER system. The results demonstrated the effectiveness of the proposed transformer model in predicting emotions from audio signals. To achieve higher accuracy for SER models the proposed model was trained with highly effective features. To avoid overfitting the raw data was augmented with a data augmentation technique and then fed to the transformer model for training. Many techniques are applied for SER based on deep learning and machine learning algorithms taking high-level features to train them are not enough competent to predict higher accuracy, reduce computational time and lower model size [44]. As a way to address these problems a comparatively lighter transformer model was proposed that takes 273 acoustic features as input and can learn higher concentrations of input representations. The proposed model depicts higher accuracy for all datasets used to train the model. When the problem of accuracy was resolved then computational time was reduced by a lighter transformer model. To prove that the proposed transformer model provides robust results in solving the accuracy, computational cost, and model size problems the results were compared with the standard techniques used for speech emotion detection.
The performance of the proposed model was compared to the baseline techniques using the same datasets for training and testing the model to evaluate its significance and strength. Table 6 comprehensively summarizes the comparative analysis of baseline techniques and the proposed model. The results in the table evidence the robustness and significance of the proposed SER model compared to baseline methods. However, the proposed model loses its performance a bit for some instances of individual emotions. For example, the proposed model obtained 98% accuracy for neutral emotion, but in [38] it is 100% in the EMO-DB SER model. On the other hand, the proposed model achieved the highest overall prediction accuracy compared to baseline methods with prediction accuracy. The proposed model is suitable for real-life applications because of its lightweight structure, low computational cost, and ability to predict accuracy for individual instances. To conclude, it can be stated that the proposed SER model is more reliable, generic, and accurate.
Table 6.
Comparison of the proposed model and the baseline models using BAVED, EMO-DB, SAVEE and, the EMOVO datasets.
5. Conclusions
Significant feature extraction and accurate classification are the main reasons that make SER more challenging. This study presented a novel transformer model based on the fusion of 273 acoustic features. This study presented a novel transformer model based on the fusion of seven acoustic features. To address the issue of computational cost, the proposed model employed a smaller number of layers. This study concentrated on Arabic vocal emotions since they got less attention in the research community. We used the transformer model on the “Basic Arabic Vocal Emotions” Dataset named BAVED, which resulted in a 95% accuracy. We further tested the transformer model on three more datasets: EMO-DB, SAVEE, and EMOVO, achieving accuracy of 93.4%, 85.1%, and 91.7%, respectively. The cross comparison of results with baseline SER techniques showed the robustness and significance of proposed transformer model. However, the accuracy levels were improved by enhancement of the proposed model. The results also show that the proposed transformer model is particularly well suited to Arabic vocal emotions recognition. The context or aspect of the emotion will be extracted in future work. Furthermore, implementing recurrent neural networks while using optimal speech features with the proposed transformer can increase the performance of the SER system since it can offer high-level features more accurately. A comparative analysis of SER models based on deep learning techniques applied to other databases is also planned for future work. Moreover, the accuracy of gender-based speech emotion recognition will be compared, and the emotion that is most easily recognized should be identified.
Author Contributions
Conceptualization, E.H.A., B.B.A.-o. and M.A.N.; methodology, E.H.A. and R.J.; software, R.J.; validation, B.B.A.-o., M.A.N., E.H.A. and M.M.M.; formal analysis, E.H.A., R.J. and A.M.E.; investigation, R.J.; resources, E.H.A., A.M.E. and A.M.E.; data curation, R.J.; writing—original draft preparation, R.J. and A.M.E.; writing—review and editing, E.H.A. and A.M.E.; visualization, A.M.E.; supervision, E.H.A.; project administration, E.H.A. and B.B.A.-o.; funding acquisition, E.H.A. and B.B.A.-o. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R263), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors would like to acknowledge Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R263), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mahlberg, M. Lexical cohesion: Corpus linguistic theory and its application in English language teaching. Int. J. Corpus Linguist. 2006, 11, 363–383. [Google Scholar] [CrossRef]
- Stenström, A.B.; Aijmer, K. Discourse patterns in Spoken and Written Corpora; Pragmatics and Beyond New Series; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2004; pp. 1–14. [Google Scholar]
- Huijuan, Z.; Ning, Y.; Ruchuan, W. Coarse-to-Fine Speech Emotion Recognition Based on Multi-Task Learning. J. Signal Process. Syst. 2020, 93, 299–308. [Google Scholar] [CrossRef]
- Koduru, A.; Valiveti, H.B.; Budati, A.K. Feature extraction algorithms to improve the speech emotion recognition rate. Int. J. Speech Technol. 2020, 23, 45–55. [Google Scholar] [CrossRef]
- Taylor, P. Text-to-Speech Synthesis; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Cavallo, F.; Semeraro, F.; Fiorini, L.; Magyar, G.; Sinčák, P.; Dario, P. Emotion Modelling for Social Robotics Applications: A Review. J. Bionic Eng. 2018, 15, 185–203. [Google Scholar] [CrossRef]
- De Naurois, C.J.; Bourdin, C.; Stratulat, A.; Diaz, E.; Vercher, J.-L. Detection and prediction of driver drowsiness using artificial neural network models. Accid. Anal. Prev. 2019, 126, 95–104. [Google Scholar] [CrossRef] [PubMed]
- Katsis, C.D.; Rigas, G.; Goletsis, Y.; Fotiadis, D.I. Emotion Recognition in Car Industry. In Emotion Recognition: A Pattern Analysis Approach; Konar, A., Chakraborty, A., Eds.; Wiley Online Library: Hoboken, NJ, USA, 2015; pp. 515–544. [Google Scholar] [CrossRef]
- Jahangir, R.; Teh, Y.W.; Mujtaba, G.; Alroobaea, R.; Shaikh, Z.H.; Ali, I. Convolutional neural network-based cross-corpus speech emotion recognition with data augmentation and features fusion. Mach. Vis. Appl. 2022, 33, 1–16. [Google Scholar] [CrossRef]
- Jiang, J.; Wang, H.H. Application intelligent search and recommendation system based on speech recognition technology. Int. J. Speech Technol. 2021, 24, 23–30. [Google Scholar] [CrossRef]
- Brown, C.; Chauhan, J.; Grammenos, A.; Han, J.; Hasthanasombat, A.; Spathis, D.; Xia, T.; Cicuta, P.; Mascolo, C. Exploring automatic diagnosis of covid-19 from crowdsourced respiratory sound data. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020. [Google Scholar]
- El Hammoumi, O.; Benmarrakchi, F.; Ouherrou, N.; El Kafi, J.; El Hore, A. Emotion Recognition in E-learning Systems. In Proceedings of the 2018 6th International Conference on Multimedia Computing and Systems (ICMCS), Rabat, Morocco, 10–12 May 2018. [Google Scholar]
- Alim, S.A.; Rashid, N.K.A. Some Commonly Used Speech Feature Extraction Algorithms; IntechOpen: London, UK, 2018. [Google Scholar] [CrossRef]
- Borrelli, C.; Bestagini, P.; Antonacci, F.; Sarti, A.; Tubaro, S. Synthetic speech detection through short-term and long-term prediction traces. EURASIP J. Inf. Secur. 2021, 2021, 1–14. [Google Scholar] [CrossRef]
- Chougule, S.V. Analyzing Vocal Tract Parameters of Speech. In Advances in Signal and Data Processing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 369–376. [Google Scholar] [CrossRef]
- Glittas, A.X.; Gopalakrishnan, L. A low latency modular-level deeply integrated MFCC feature extraction architecture for speech recognition. Integration 2020, 76, 69–75. [Google Scholar] [CrossRef]
- Jahangir, R.; Teh, Y.W.; Nweke, H.F.; Mujtaba, G.; Al-Garadi, M.A.; Ali, I. Speaker identification through artificial intelligence techniques: A comprehensive review and research challenges. Expert Syst. Appl. 2021, 171, 114591. [Google Scholar] [CrossRef]
- Akçay, M.B.; Oğuz, K. Speech emotion recognition: Emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers. Speech Commun. 2019, 116, 56–76. [Google Scholar] [CrossRef]
- Wani, T.M.; Gunawan, T.S.; Qadri, S.A.A.; Kartiwi, M.; Ambikairajah, E. A Comprehensive Review of Speech Emotion Recognition Systems. IEEE Access 2021, 9, 47795–47814. [Google Scholar] [CrossRef]
- Teixeira, J.P.; Oliveira, C.; Lopes, C.J.P.T. Vocal acoustic analysis–jitter, shimmer and hnr parameters. Procedia Technol. 2013, 9, 1112–1122. [Google Scholar] [CrossRef]
- Teager, H.; Teager, S. Evidence for nonlinear sound production mechanisms in the vocal tract. In Speech Production and Speech Modelling; Springer: Berlin/Heidelberg, Germany, 1990; pp. 241–261. [Google Scholar]
- Bharti, D.; Kukana, P. A Hybrid Machine Learning Model for Emotion Recognition From Speech Signals. In Proceedings of the 2020 International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 10–12 September 2020. [Google Scholar]
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A Survey of Deep Learning and Its Applications: A New Paradigm to Machine Learning. Arch. Comput. Methods Eng. 2019, 27, 1071–1092. [Google Scholar] [CrossRef]
- Syed, Z.S.; Ali, S.; Shehram, M.; Shah, M.S. Introducing the Urdu-Sindhi Speech Emotion Corpus: A Novel Dataset of Speech Recordings for Emotion Recognition for Two Low-Resource Languages. Int. J. Adv. Comput. Sci. Appl. 2020, 11. [Google Scholar] [CrossRef]
- Peerzade, G.; Deshmukh, R.R.; Waghmare, S.D.; Jans, P.V. Design and Development of Emotion Recognition System for Urdu Language. Int. J. Sci. Res. Comput. Sci. Appl. Manag. Stud. 2018, 7. [Google Scholar]
- Latif, S.; Qayyum, A.; Usman, M.; Qadir, J. Cross lingual speech emotion recognition: Urdu vs. western languages. In Proceedings of the 2018 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 17–19 December 2018. [Google Scholar]
- Kwon, S. MLT-DNet: Speech emotion recognition using 1D dilated CNN based on multi-learning trick approach. Expert Syst. Appl. 2021, 167, 114177. [Google Scholar]
- Tang, D.; Kuppens, P.; Geurts, L.; van Waterschoot, T. End-to-end speech emotion recognition using a novel context-stacking dilated convolution neural network. EURASIP J. Audio Speech Music Process. 2021, 2021, 1–16. [Google Scholar] [CrossRef]
- Mirsamadi, S.; Barsoum, E.; Zhang, C. Automatic speech emotion recognition using recurrent neural networks with local attention. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2227–2231. [Google Scholar]
- Ai, X.; Sheng, V.S.; Fang, W.; Ling, C.X.; Li, C. Ensemble Learning With Attention-Integrated Convolutional Recurrent Neural Network for Imbalanced Speech Emotion Recognition. IEEE Access 2020, 8, 199909–199919. [Google Scholar] [CrossRef]
- Li, D.; Liu, J.; Yang, Z.; Sun, L.; Wang, Z. Speech emotion recognition using recurrent neural networks with directional self-attention. Expert Syst. Appl. 2021, 173, 114683. [Google Scholar] [CrossRef]
- Klaylat, S.; Osman, Z.; Hamandi, L.; Zantout, R. Emotion recognition in Arabic speech. Analog. Integr. Circuits Signal Processing 2018, 96, 337–351. [Google Scholar] [CrossRef]
- Abdel-Hamid, L. Egyptian Arabic speech emotion recognition using prosodic, spectral and wavelet features. Speech Commun. 2020, 122, 19–30. [Google Scholar] [CrossRef]
- Khalil, A.; Al-Khatib, W.; El-Alfy, E.S.; Cheded, L. Anger detection in arabic speech dialogs. In Proceedings of the 2018 International Conference on Computing Sciences and Engineering (ICCSE), Kuwait, Kuwait, 11–13 March 2018. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Liu, M.; Ren, S.; Ma, S.; Jiao, J.; Chen, Y.; Wang, Z.; Song, W. Gated transformer networks for multivariate time series classification. arXiv 2021, arXiv:2103.14438. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. Adv. Neural Inf. Processing Syst. 2015, 28. [Google Scholar]
- Issa, D.; Demirci, M.F.; Yazici, A. Speech emotion recognition with deep convolutional neural networks. Biomed. Signal Process. Control 2020, 59, 101894. [Google Scholar] [CrossRef]
- Farooq, M.; Hussain, F.; Baloch, N.K.; Raja, F.R.; Yu, H.; Bin Zikria, Y. Impact of Feature Selection Algorithm on Speech Emotion Recognition Using Deep Convolutional Neural Network. Sensors 2020, 20, 6008. [Google Scholar] [CrossRef]
- Chen, L.; Su, W.; Feng, Y.; Wu, M.; She, J.; Hirota, K. Two-layer fuzzy multiple random forest for speech emotion recognition in human-robot interaction. Inf. Sci. 2019, 509, 150–163. [Google Scholar] [CrossRef]
- Ancilin, J.; Milton, A. Improved speech emotion recognition with Mel frequency magnitude coefficient. Appl. Acoust. 2021, 179, 108046. [Google Scholar] [CrossRef]
- Sajjad, M. and S. Kwon, Clustering-based speech emotion recognition by incorporating learned features and deep BiLSTM. IEEE Access 2020, 8, 79861–79875. [Google Scholar]
- Mohamed, O.; Aly, S.A. Arabic Speech Emotion Recognition Employing Wav2vec2. 0 and HuBERT Based on BAVED Dataset. arXiv 2021, arXiv:2110.04425. [Google Scholar]
- Mustaqeem; Kwon, S. Att-Net: Enhanced emotion recognition system using lightweight self-attention module. Appl. Soft Comput. 2021, 102, 107101. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).