
A Generalised Neural Network Model to Estimate Sex from Cranial Metric Traits: A Robust Training and Testing Approach


Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. The Datasets
2.2. Data Preparation
2.3. The Classification Algorithm
2.4. Parameter Tuning
2.5. Training and Validation
2.6. Best Model, Variable Importance, and Testing
3. Results
3.1. Best Model Selection
3.2. Variable Importance and Model Performance
4. Discussion
4.1. The Model Performance
4.2. The Variable Importance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bass, W.M.; Folkens, P.A. Human Osteology in a Laboratory and Field Manual of the Human Skeleton; Gulf Professional Publishing: Houston, TX, USA, 1995. [Google Scholar]
- Seidemann, R.M.; Stojanowski, C.M.; Doran, G.H. The use of the supero-inferior femoral neck diameter as a sex assessor. Am. J. Phys. Anthropol. 1998, 107, 305–313. [Google Scholar] [CrossRef]
- López-Lázaro, S.; Pérez-Fernández, A.; Alemán, I.; Viciano, J. Sex estimation of the humerus: A geometric morphometric analysis in an adult sample. Leg. Med. 2020, 47, 101773. [Google Scholar] [CrossRef] [PubMed]
- Phenice, T.W. A newly developed visual method of sexing the os pubis. Am. J. Phys. Anthropol. 1969, 30, 297–302. [Google Scholar] [CrossRef] [PubMed]
- García-Campos, C.; Martinón-Torres, M.; De Pinillos, M.M.; Modesto-Mata, M.; Martín-Francés, L.; Perea-Pérez, B.; Zanolli, C.; De Castro, J.M.B. Modern humans sex estimation through dental tissue patterns of maxillary canines. Am. J. Phys. Anthropol. 2018, 167, 914–923. [Google Scholar] [CrossRef]
- Curate, F.; d’Oliveira Coelho, J.; Silva, A.M. CalcTalus: An online decision support system for the estimation of sex with the calcaneus and talus. Archaeol. Anthropol. Sci. 2021, 13, 73. [Google Scholar] [CrossRef]
- Bidmos, M.A.; Mazengenya, P. Accuracies of discriminant function equations for sex estimation using long bones of upper extremities. Int. J. Legal. Med. 2021, 135, 1095–1102. [Google Scholar] [CrossRef]
- Barrio, P.A.; Trancho, G.J.; Sánchez, J.A. Metacarpal sexual determination in a Spanish population. J. Forensic Sci. 2006, 51, 990–995. [Google Scholar] [CrossRef]
- Spradley, M.K.; Jantz, R.L. Sex estimation in forensic anthropology: Skull versus postcranial elements. J. Forensic Sci. 2011, 56, 289–296. [Google Scholar] [CrossRef]
- Byers, S.N. Introduction to Forensic Anthropology; Routledge: Boston, MA, USA, 2002. [Google Scholar]
- Acsádi, G.; Nemeskéri, J. History of Human Life Span and Mortality. Available online: https://scholar.google.es/scholar?hl=it&as_sdt=0%2C5&q=acsadi+and+nemeskeri+1970&oq=ascadi+ (accessed on 17 March 2019).
- Buikstra, J.; Ubelaker, D. Standards for Data Collection from Human Skeletal Remains: Proceedings of a Seminar at the Field Museum of Natural History Arkansas Archaeology, Fayetteville Arkansas Archaeological Survey. Available online: http://scholar.google.com/scholar?hl=en&btnG=Search&q=intitle:Standards+for+Data+Collection+from+Human+Skeletal+Remains+Proceedings+of+a+Seminar+at+the+Field+Museum+of+Natural+History#0 (accessed on 17 March 2019).
- Walker, P.L. Sexing skulls using discriminant function analysis of visually assessed traits. Am. J. Phys. Anthropol. 2008, 136, 39–50. [Google Scholar] [CrossRef]
- Walrath, D.E.; Turner, P.; Bruzek, J. Reliability test of the visual assessment of cranial traits for sex determination. Am. J. Phys. Anthropol. 2004, 125, 132–137. [Google Scholar] [CrossRef]
- Williams, B.A.; Rogers, T.L. Evaluating the accuracy and precision of cranial morphological traits for sex determination. J. Forensic Sci. 2006, 51, 729–735. [Google Scholar] [CrossRef] [PubMed]
- Klales, A.R. Sex Estimation of the Human Skeleton; Academic Press: Cambridge, MA, USA, 2020. [Google Scholar] [CrossRef]
- Franklin, D.; Freedman, L.; Milne, N. Sexual dimorphism and discriminant function sexing in indigenous South African crania. HOMO-J. Comp. Hum. Biol. 2005, 55, 213–228. [Google Scholar] [CrossRef]
- Weiss, K.M. On the systematic bias in skeletal sexing. Am. J. Phys. Anthropol. 1972, 37, 239–249. [Google Scholar] [CrossRef] [PubMed]
- Garvin, H.M.; Ruff, C.B. Sexual dimorphism in skeletal browridge and chin morphologies determined using a new quantitative method. Am. J. Phys. Anthropol. 2012, 147, 661–670. [Google Scholar] [CrossRef] [PubMed]
- Franklin, D.; Oxnard, C.E.; O’Higgins, P.; Dadour, I. Sexual dimorphism in the subadult mandible: Quantification using geometric morphometrics. J. Forensic Sci. 2007, 52, 6–10. [Google Scholar] [CrossRef]
- Boucherie, A.; Chapman, T.; García-Martínez, D.; Polet, C.; Vercauteren, M. Exploring sexual dimorphism of human occipital and temporal bones through geometric morphometrics in an identified Western-European sample. Am. J. Biol. Anthropol. 2022, 178, 54–68. [Google Scholar] [CrossRef]
- Dayal, M.R.; Spocter, M.A.; Bidmos, M.A. An assessment of sex using the skull of black South Africans by discriminant function analysis. HOMO-J. Comp. Hum. Biol. 2008, 59, 209–221. [Google Scholar] [CrossRef]
- Green, H.; Curnoe, D. Sexual dimorphism in Southeast Asian crania: A geometric morphometric approach. HOMO-J. Comp. Hum. Biol. 2009, 60, 517–534. [Google Scholar] [CrossRef]
- Milella, M.; Franklin, D.; Belcastro, M.G.; Cardini, A. Sexual differences in human cranial morphology: Is one sex more variable or one region more dimorphic? Anat. Rec. 2021, 304, 2789–2810. [Google Scholar] [CrossRef]
- Attia, M.H.; Kholief, M.A.; Zaghloul, N.M.; Kružić, I.; Anđelinović, Š.; Bašić, Ž.; Jerković, I. Efficiency of the adjusted binary classification (ABC) approach in osteometric sex estimation: A comparative study of different linear machine learning algorithms and training sample sizes. Biology 2022, 11, 917. [Google Scholar] [CrossRef]
- Nikita, E.; Nikitas, P. On the use of machine learning algorithms in forensic anthropology. Leg. Med. 2020, 47, 101771. [Google Scholar] [CrossRef] [PubMed]
- Savall, F.; Faruch-Bilfeld, M.; Dedouit, F.; Sans, N.; Rousseau, H.; Rougé, D.; Telmon, N. Metric sex determination of the human coxal bone on a virtual sample using decision trees. J. Forensic Sci. 2015, 60, 1395–1400. [Google Scholar] [CrossRef] [PubMed]
- Bewes, J.; Low, A.; Morphett, A.; Pate, F.D.; Henneberg, M. Artificial intelligence for sex determination of skeletal remains: Application of a deep learning artificial neural network to human skulls. J. Forensic Leg. Med. 2019, 62, 40–43. Available online: https://www.sciencedirect.com/science/article/pii/S1752928X18304219 (accessed on 9 April 2021). [CrossRef] [PubMed]
- Imaizumi, K.; Bermejo, E.; Taniguchi, K.; Ogawa, Y.; Nagata, T.; Kaga, K.; Hayakawa, H.; Shiotani, S. Development of a sex estimation method for skulls using machine learning on three-dimensional shapes of skulls and skull parts. Forensic Imaging 2020, 22, 200393. [Google Scholar] [CrossRef]
- Chovalopoulou, M.-E.; Valakos, E.; Manolis, S.K. Sex determination by three-dimensional geometric morphometrics of craniofacial form. Anthr. Anz. 2016, 73, 195–206. [Google Scholar] [CrossRef] [PubMed]
- Jurda, M.; Urbanová, P. Sex and ancestry assessment of Brazilian crania using semi-automatic mesh processing tools. Leg. Med. 2016, 23, 34–43. [Google Scholar] [CrossRef]
- Kelley, S.R.; Tallman, S.D. Population-Inclusive Assigned-Sex-at-Birth Estimation from Skull Computed Tomography Scans. Forensic Sci. 2022, 2, 321–348. [Google Scholar] [CrossRef]
- Milella, M.; Belcastro, M.G.; Zollikofer, C.P.; Mariotti, V. The effect of age, sex, and physical activity on entheseal morphology in a contemporary Italian skeletal collection. Am. J. Phys. Anthr. 2012, 148, 379–388. [Google Scholar] [CrossRef]
- Ortega, R.F.; Irurita, J.; Campo, E.J.E.; Mesejo, P. Analysis of the performance of machine learning and deep learning methods for sex estimation of infant individuals from the analysis of 2D images of the ilium. Int. J. Leg. Med. 2021, 135, 2659–2666. [Google Scholar] [CrossRef]
- Toneva, D.; Nikolova, S.; Agre, G.; Zlatareva, D.; Hadjidekov, V.; Lazarov, N. Machine learning approaches for sex estimation using cranial measurements. Int. J. Legal Med. 2021, 135, 951–966. [Google Scholar] [CrossRef]
- Navega, D.; Vicente, R.; Vieira, D.N.; Ross, A.H.; Cunha, E. Sex estimation from the tarsal bones in a Portuguese sample: A machine learning approach. Int. J. Leg. Med. 2015, 129, 651–659. [Google Scholar] [CrossRef] [PubMed]
- Ortiz, A.G.; Costa, C.; Silva, R.; Biazevic, M.; Michel-Crosato, E. Sex estimation: Anatomical references on panoramic radiographs using Machine Learning. Forensic Imaging 2020, 20, 200356. [Google Scholar] [CrossRef]
- Curate, F.; Umbelino, C.; Perinha, A.; Nogueira, C.; Silva, A.M.; Cunha, E. Sex determination from the femur in Portuguese populations with classical and machine-learning classifiers. J. Forensic Leg. Med. 2017, 52, 75–81. [Google Scholar] [CrossRef]
- Ying, X. An Overview of Overfitting and its Solutions. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- Jerković, I.; Bašić, Ž.; Anđelinović, Š.; Kružić, I. Adjusting posterior probabilities to meet predefined accuracy criteria: A proposal for a novel approach to osteometric sex estimation. Forensic Sci. Int. 2020, 311, 110273. [Google Scholar] [CrossRef] [PubMed]
- Howells, W.W. Who’s who in skulls. Ethnic identification of crania from measurements. Pap. Peabody Mus. Archaeol. Ethnol. 1995, 82, 108. [Google Scholar]
- Howells, W.W. Skull shapes and the map. Craniometric analyses in the dispersion of modern homo. Pap. Peabody Mus. Archaeol. Ethnol. 1989, 79, 189. [Google Scholar]
- Howells, W.W. Cranial variation in man. A study by multivariate analysis of patterns of differences among recent human populations. Pap. Peabody Mus. Archeol. Ethnol. 1973, 67, 259. [Google Scholar]
- Jantz, R.L.; Moore-Jansen, P.H. A Data Base for Forensic Anthropology; The National Institute of Justice: Washington, DC, USA, 1988.
- Holland, T.D. Sex determination of fragmentary crania by analysis of the cranial base. Am. J. Phys. Anthr. 1986, 70, 203–208. [Google Scholar] [CrossRef]
- Saini, V.; Srivastava, R.; Rai, R.K.; Shamal, S.N.; Singh, T.B.; Tripathi, S.K. Sex Estimation from the Mastoid Process Among North Indians. J. Forensic Sci. 2011, 57, 434–439. [Google Scholar] [CrossRef]
- Harrell, F.E.; Dupont, C. Hmisc. Harrell Miscellaneous; CRAN: Brisbane, Australia, 2022. [Google Scholar]
- Mosimann, J.E. Size Allometry: Size and Shape Variables with Characterizations of the Lognormal and Generalized Gamma Distributions. J. Am. Stat. Assoc. 1970, 65, 930–945. [Google Scholar] [CrossRef]
- LeDell, E.; Gill, N.; Aiello, S.; Fu, A.; Candel, A.; Click, C.; Kraljevic, T.; Nykodym, T.; Aboyoun, P.; Kurka, M.; et al. R Interface for the ‘H2O’ Scalable Machine Learning Platform; CRAN: Brisbane, Australia, 2022. [Google Scholar]
- Svozil, D.; Kvasnieka, V.; Pospichal, J. Chemometrics and intelligent laboratory systems Introduction to multi-layer feed-forward neural networks. Chemom. Intell. Lab. Syst. 1997, 39, 43–62. [Google Scholar] [CrossRef]
- Lavesson, N.; Davidsson, P. Quantifying the Impact of Learning Algorithm Parameter Tuning. In Proceedings of the National Conference on Artificial Intelligence, Boston, MA, USA, 16–20 July 2006; Volume 1. [Google Scholar]
- Venkatesh, B.; Anuradha, J. A Review of Feature Selection and Its Methods. Cybern. Inf. Technol. 2019, 19, 3–26. [Google Scholar] [CrossRef]
- Erickson, B.J.; Kitamura, F. Magician’s Corner: 9. Performance Metrics for Machine Learning Models. Radiol. Artif. Intell. 2021, 3, e200126. [Google Scholar] [CrossRef] [PubMed]
- Parsons, V.L. Stratified sampling. In Wiley StatsRef: Statistics Reference Online; Wiley: Hoboken, NJ, USA, 2014; pp. 1–11. [Google Scholar]
- Cybenko, G.; O’Leary, D.P.; Rissanen, J. The Mathematics of Information Coding, Extraction and Distribution; Springer Science & Business Media: Berlin, Germany, 1998; Volume 107. [Google Scholar]
- Caruana, R.; Lawrence, S.; Giles, C. Overfitting in neural nets: Backpropagation, conjugate gradient, and early stopping. Adv. Neural. Inf. Process. Syst. 2000, 13, 381–387. [Google Scholar]
- Gedeon, T.D. Data Mining of Inputs: Analysing Magnitude and Functional Measures. Int. J. Neural Syst. 1997, 8, 209–218. [Google Scholar] [CrossRef]
- Gao, H.; Geng, G.; Yang, W. Sex determination of 3D skull based on a novel unsupervised learning method. Comput. Math. Methods Med. 2018, 2018, 4567267. [Google Scholar] [CrossRef]
- Kubat, M.; Matwin, S. Addressing the curse of imbalanced training sets: One-sided selection. Icml 1997, 97, 179. [Google Scholar]
- McClelland, J.L.; Rumelhart, D.E.; PDP Research Group. Parallel Distributed Processing, Volume 2: Explorations in the Microstructure of Cognition: Psychological and Biological Models; MIT Press: Cambridge, MA, USA, 1987; Volumes 1 & 2. [Google Scholar]
- Ramamoorthy, B.; Pai, M.M.; Prabhu, L.V.; Muralimanju, B.; Rai, R. Assessment of craniometric traits in South Indian dry skulls for sex determination. J. Forensic Leg. Med. 2016, 37, 8–14. [Google Scholar] [CrossRef]
- Saini, V.; Srivastava, R.; Rai, R.K.; Shamal, S.N.; Singh, T.B.; Tripathi, S.K. An Osteometric Study of Northern Indian Populations for Sexual Dimorphism in Craniofacial Region. J. Forensic Sci. 2011, 56, 700–705. [Google Scholar] [CrossRef]
- Kranioti, E.F.; Apostol, M.A. Sexual dimorphism of the tibia in contemporary Greeks, Italians, and Spanish: Forensic implications. Int. J. Legal. Med. 2015, 129, 357–363. [Google Scholar] [CrossRef] [PubMed]
- Cappella, A.; Gibelli, D.; Vitale, A.; Zago, M.; Dolci, C.; Sforza, C.; Cattaneo, C. Preliminary study on sexual dimorphism of metric traits of cranium and mandible in a modern Italian skeletal population and review of population literature. Leg. Med. 2020, 44, 101695. [Google Scholar] [CrossRef] [PubMed]
- Garvin, H.M.; Sholts, S.B.; Mosca, L.A. Sexual dimorphism in human cranial trait scores: Effects of population, age, and body size. Am. J. Phys. Anthropol. 2014, 154, 259–269. [Google Scholar] [CrossRef] [PubMed]
- Ekizoglu, O.; Hocaoglu, E.; Inci, E.; Can, I.O.; Solmaz, D.; Aksoy, S.; Buran, C.F.; Sayin, I. Assessment of sex in a modern Turkish population using cranial anthropometric parameters. Leg. Med. 2016, 21, 45–52. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
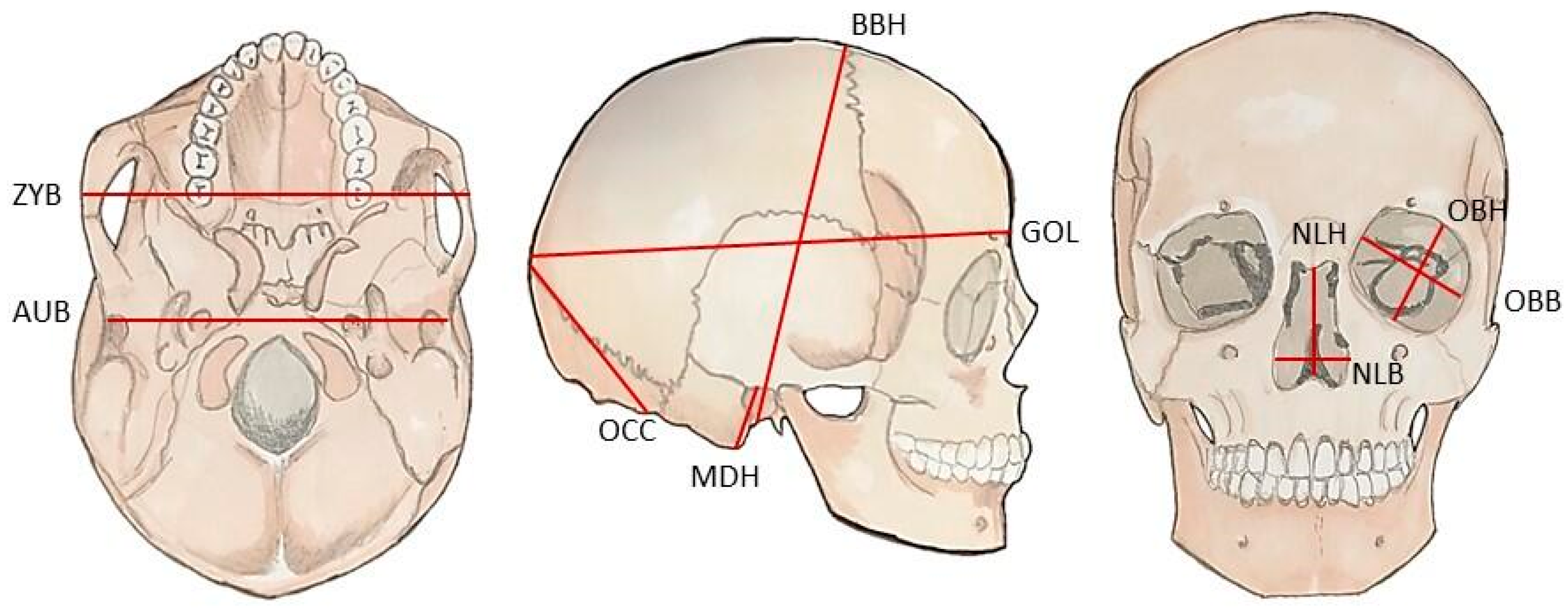
| Measurement | Abbreviation | Definition |
|---|---|---|
| Biauricular breadth | AUB | The shortest distance across the roots of the zygomatic processes |
| Basion-bregma height | BBH | The linear distance from basion to bregma |
| Glabella-occipital length | GOL | The linear distance from glabella to opisthocranion along the midsagittal plane |
| Mastoid height | MDH | The linear distance between porion and mastoidale points |
| Nasal breadth | NLB | The maximum breadth of the nasal aperture |
| Nasal height | NLH | The height from the nasion to the lowest point on the rim of the nasal aperture |
| Orbit breadth | OBB | The linear distance from dacryon to ectoconchion points |
| Orbit height | OBH | The linear distance between the superior and inferior margins of the orbits, measured perpendicularly to orbital breadth |
| Lambda-opisthion chord | OCC | The linear distance from lambda to opisthion along the mid-sagittal plane |
| Bizygomatic breadth | ZYB | The maximum breadth across the zygomatic arches, perpendicular to the mid-sagittal plane |
| Dataset | Source | Population | Sex (F:M) |
|---|---|---|---|
| Training and Validation | William W. Howell’s craniometric dataset | Ainu | 38:46 |
| Andaman | 31:33 | ||
| Arikara | 27:36 | ||
| Atayal | 17:26 | ||
| Australia (aboriginals) | 49:50 | ||
| Berg | 53:53 | ||
| Buriat | 54:45 | ||
| Bushman | 46:39 | ||
| Dogon | 51:45 | ||
| Easter Island | 37:42 | ||
| Egypt (600–200 B.C.) | 53:53 | ||
| Eskimo | 55:43 | ||
| Guam | 27:28 | ||
| Hainan | 38:43 | ||
| Mokapu | 49:45 | ||
| Moriori | 51:54 | ||
| Japan (North) | 32:52 | ||
| Japan (South) | 41:45 | ||
| Norse (medieval) | 54:52 | ||
| Peru | 55:49 | ||
| Santa Cruz | 51:47 | ||
| Tasmania (aboriginals) | 42:40 | ||
| Teita | 50:32 | ||
| Tolai | 54:49 | ||
| Zalavar (medieval) | 45:49 | ||
| Zulu | 46:50 | ||
| Test | University of Tennessee Database for Forensic Anthropology in the United States | Ancestry unknown | 303:303 |
| Parameter | Value * |
|---|---|
| Epochs | 1000 |
| Stopping metric | Log loss |
| Loss function | Cross entropy |
| Distribution | Bernoulli |
| Learning rate | 5 × 10−4 |
| Momentum start | 0.5 |
| Momentum ramp | 1 × 10−6 |
| Momentum stable | 0.99 |
| Stopping rounds | 20 |
| Stopping tolerance | 1 × 10−4 |
| Input dropout ratio | 0 |
| Number of folds | 10 |
| Fold assignment | Stratified |
| Activation function | Rectifier with dropout |
| L1 regularisation | 0 |
| L2 regularisation | 0, 1 × 10−4, 5 × 10−4, 1 × 10−3, 5 × 10−3, 1 × 10−2, and 5 × 10−2 |
| Hidden layers | 1 and 2 |
| Nodes per layer | 3, 7, 11, 15, 19, 23, and 27 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Del Bove, A.; Veneziano, A. A Generalised Neural Network Model to Estimate Sex from Cranial Metric Traits: A Robust Training and Testing Approach. Appl. Sci. 2022, 12, 9285. https://doi.org/10.3390/app12189285
Del Bove A, Veneziano A. A Generalised Neural Network Model to Estimate Sex from Cranial Metric Traits: A Robust Training and Testing Approach. Applied Sciences. 2022; 12(18):9285. https://doi.org/10.3390/app12189285
Chicago/Turabian StyleDel Bove, Antonietta, and Alessio Veneziano. 2022. "A Generalised Neural Network Model to Estimate Sex from Cranial Metric Traits: A Robust Training and Testing Approach" Applied Sciences 12, no. 18: 9285. https://doi.org/10.3390/app12189285