3.1. Lightweight Detection Model Edge-YOLO
As shown in
Figure 2, the proposed lightweight detection model is called Edge-YOLO which is based on the combination of YOLOv5, ShuffleNetv2, and coord attention [
2]. It is designed for the edge embedded device to detect objects from airport apron surveillance.
The proposed Edge-YOLO is built by simplifying the structure of YOLOv5 and the new network architecture reduces the amount of parameters by more than 90%. YOLOv5 [
3] is an end-to-end method for object detection based on nonregional candidates, and it is the current state-of-the-art method in the field of one-stage object detection. Its network structure is mainly divided into two parts: backbone (feature extraction network) and head (detection head). There are four versions of YOLOv5, namely YOLOv5s, YOLOv5m, YOLOv5l, YOLOv5x. The model size and accuracy of the four versions increase in turn, and the channel and layer control factors are used to select the appropriate size model according to the application scenario. In order to obtain a model that is easier to apply to resource-limited embedded devices, we choose YOLOv5s with the best real-time performance as the benchmark for optimization. Its network structure is mainly divided into two parts: backbone (feature extraction network) and head (detection head). In order to improve its detection speed, we chose to simplify the structure of both parts.
For backbone, we choose to use a light-weight image classification network for feature extraction. After comparing some light-weight image classification networks, we choose to use shuffleNetv2 [
10] with the least amount of parameters and the best real-time performance for feature extraction. ShuffleNetv2 [
10] is an image classification network designed for mobile devices and replaces the original backbone. This structure greatly reduces the computation of convolution operations by using group point wise convolutions. Moreover, a mechanism for information exchange between groups called ChannelShuffle, is used to achieve information fusion between groups. Compared with the original YOLOv5s feature extraction network, ShuffleNetv2 has better speed performance on edge devices.
Table 1 shows the parameters and calculation complexity comparison of YOLOv5s-backbone and ShuffleNetV2 [
10].
For the detection head part, the number of channels is cropped, since the number of categories to be detected in the airport apron scene is much less than that in the general scene. There are no more than 20 categories in the airport apron scene, while the detected categories are 80 in the COCO dataset. Only a quarter of channels is kept in order to get the highest cost-effectiveness in accuracy loss and compression ratio.
Table 2 shows the parameters and calculation complexity comparison of YOLOv5s-head and Edge-YOLO-head.
The reduction of the computational complexity of the feature extraction network may cause the weakening of the feature extraction capability. The coord attention [
27] module is used to the extracted features, in order to make full use of the extracted features. This module is able to make the model pay attention to the parts that have a more significant impact on the final result. As shown in
Figure 2, the coord attention [
27] module decomposes channel attention into two 1D feature encoding processes. Since these two processes aggregate features along different directions, the long-range dependencies can be captured along one spatial direction, while precise location information can be preserved along the other. Then, the generated feature maps are separately encoded to form a pair of orientation-aware and position-sensitive feature maps, which is able to enhance the representation of objects of interest according to the complementary feature maps.
3.2. Edge Video Detection Acceleration Based on Motion Inference
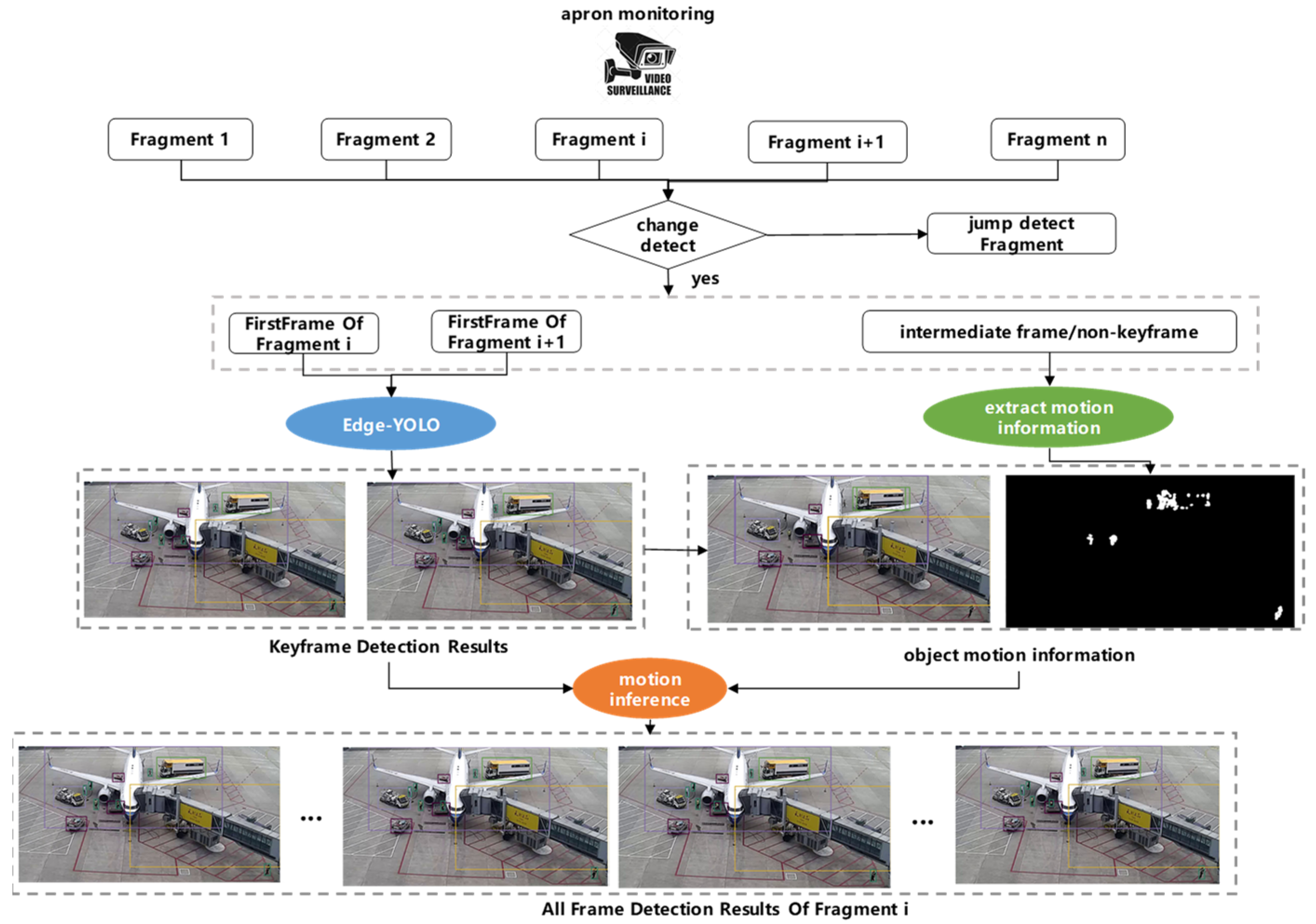
Based on the characteristics of airport apron operations, there are two proposed acceleration strategies shown in
Figure 3 in order to further accelerate edge detection and reduce the power consumption of edge devices.
The first strategy is to avoid detection of some idle periods. There is a statistic of work time and free time of a certain apron shown in
Figure 4. The operation of the apron is not continuous. There is a long idle period between the two jobs that totals more than half of the total time. Obviously, it is not necessary to detect idle periods when no jobs are taking place. Therefore, it is important to distinguish whether the current airport apron is in operation and skip the detection of idle periods to save computing power and power consumption.
The video is divided into small segments with a duration of T (in order to avoid too long detection delay, T should take a small value. T takes 1 s, 2 s, 3 s, 4 s, 5 s in the experiments). According to whether object position changed in the segment, the judger decides whether the detection can be skipped (As shown in
Figure 5). The Algorithm 1 is used to determine whether the position of an object has changed in a segment.
| Algorithm 1: Determine whether exist object position changes in the video segment |
| Input: frame list F = {f0, f1, …, fk}; minimum object area Tarea; minimum pixel change of object movement Tpixel; |
| Output: the flag of whether the video clip has changed |
| convert frame f0 to gray frame f0gray; |
| fgmask = (f0gray < 0); |
| forfiinF: |
| convert frame fi to gray frame figray; |
| fgmask = fgmask∪(figray − f0gray > Tpixel) |
| contours = find potential object contours in fgmask; |
| for c in contours: |
| if area(c) > Tarea: |
| return true; |
| return false; |
In Algorithm 1, the parameter Tarea represents the pixel value of the minimum object to be detected, which can be determined according to the specific detection task. The parameter Tpixel represents the minimum pixel change of the object movement. We recommend a value of 10 to 20.
The second strategy is to employ motion inference to avoid frame-by-frame detection. The objects in the airport apron usually take regular slowly movements, due to the civil aviation relevant rules. Thus, there should be same object in most of near frames of the video. This means that not all frames need to be detected. Even a few frame detections might be able to get all objects. These frames are defined as key frames. Thus, the video could be divided into small segments with duration. The results for non-key frames are inferred from the detection of key frames, according to the motion information. The results of non-key frames are inferred from the detection of key frames, according to the motion information. There are two methods to extract the motion information of objects: matching based on IOU, and matching based on the improved T frame dynamic and static separation method.
The effect diagram of the way based on
IOU matching is shown in
Figure 6. For the detection results of two key frames, if the
IOU of the two objects is greater than 0.2 and less than 0.9, we regard them as the same object. The
IOU calculation formula of two objects
A and
B is given by Equation (1).
However, the
IOU-based matching method sometimes misses the relatively small objects on the airport apron such as staffs (as shown in
Figure 7). In this case, the motion trajectory of the object may be incomplete. Thus, we proposed the T frame dynamic and static separation method based on the three-frame difference method to handle this problem as a supplement.
The three-frame difference method is one of the well-known methods to perform moving objects detection. The difference of frame
i and frame
i − 1, and the difference of frame
i + 1 and frame
i is used to obtain the motion mask layers
D1 and
D2, respectively. The final motion mask layer
D of frame
i is calculated as
D1 AND
D2. The formula is expressed as Equations (2)–(4).
In the above expression, D(x,y) denotes the value of the position of the motion mask layer (x,y), i.e., the pixel change interpolation of this point. T denotes the minimum pixel change threshold where motion has occurred, and Fi(x,y) denotes the pixel value at frame i in (x,y) position.
The three-frame difference method does not perform well for objects with similar internal pixels, and the effect is very dependent on the parameter
Tpixel, which represents the minimum pixel change of the object movement. Thus, we proposed T frames dynamic and static separation method to make up for its deficiencies. The static layers as the dynamic background of these T frames are obtained according to Algorithm 2. In Algorithm 2, we recommend
Tpixel to be in the range of 10 to 20, and the motion layer can be obtained by
f0 subtracting the dynamic background, which is expressed as Equation (5).
| Algorithm 2: Get dynamic background mask. |
| Input: frame list F = {f0, f1, …, fk}; minimum pixel change of object movement Tpixel; |
| Output: dynamic background mask; |
| convert frame f0 to gray frame f0gray;bgmask = (f0gray > 0); |
| for fiin F: |
| convert frame fi to gray frame figray; |
| bgmask = bgmask∩(figray − f0gray < Tpixel) |
| return bgmask |
The final motion information is inferred from the motion layer and the
IOU matching mechanism. As shown in
Figure 8, if the value of the motion mask is greater than a certain threshold, the objects involved to this motion are seen as the same. Thus, the detection results of the key frame can be passed to the non-key frames.
3.3. Cloud-Based Detection Results Verification Mechanism
Although the edge detection we proposed greatly improves the real-time detection, it inevitably brings the decrease of detection accuracy at the same time. However, through experimental analysis, we found that the decrease of detection accuracy is not for the whole video, but is more obvious in some busy segments. Based on this observation, we consider using a small amount of cloud computing power to detect these fragments, improving the overall detection accuracy with little impact on detection speed.
Figure 9 shows the cloud calibration mechanism to improve the reliability of detection results.
For each group edge detection results [
EDRi,
EDRi+T] (
EDR: Edge Detection Result), the cloud detection model
DC (Cloud Detector) re-detects its intermediate frame
Fcenter (
Fi+T/2).
CDRcenter (
CDR: Cloud Detection Result) denotes the result of re-detection. Since
Fcenter is inferred from
EDRi,
EDRi+T, and motion layer,
Fcenter could show the correctness of the edge detection model and the motion layer. Thus, if Fcenter is consistent with CDRcenter, the set of detection results could be inferred as correct. Otherwise, it means the result of DE (Edge Detector) or DC is incorrect. Then we let
DC re-detect the first frame
Fi and last frame
Fi+T of the group to obtain
CDRi,
CDRi+T and let the motion inference strategy proposed in 3.2 re-generate detection result [
DRi,
DRi+T] (
DR: Detection Result) using
CDRi,
CDRi+T, and motion layer. The set of detection results is inferred as correct if the generated intermediate frame detection results
DRcenter is consistent with
CDRcenter. Otherwise, the extraction of the motion layer is inferred as incorrect, since the motion of the objects in the segment is not linear. In this case, let
DC detects this group of video frames one by one, and use the obtained result [
CDRi,
CDRi+T] as the final detection result of this video segment.
Figure 10 shows the number of frames detected in the cloud for a segment of a T frame in different situations.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}