


Optimal Defense Strategy Selection Algorithm Based on Reinforcement Learning and Opposition-Based Learning

Abstract
1. Introduction
- A differential evolution algorithm based on reinforcement learning and opposition-based learning is proposed and successfully applied to industrial control strategy selection.
- Improve the existing enhanced differential evolution algorithm, shorten the convergence speed of the algorithm, and better avoid it falling into the local optimal solution, which is more suitable for strategy selection.
- Compared with other similar algorithms, it is proved that the differential evolution algorithm based on reinforcement learning and opposition-based learning proposed in this paper has more advantages in the field of industrial control strategy selection.
2. Method Architectures
3. ICS Security Assessment
3.1. Attack Graph
- S is the set of attribute nodes in the attack graph. Its state is 1 or 0. When , it means that the attribute S is broken by the attacker. When , it means that the attribute S has not been broken by the attacker.
- is the starting node of . It represents the node occupied by the attacker when the attack started.
- is a set of root nodes in an . It represents the final target that the attacker wants to break, and it can have multiple existences.
- is a collection of state transitions. Each transition between the two states represents an exploit that represents a network state change from to .
3.2. The Probability of Attacking Behavior
3.3. Bayesian Attack Graph
3.4. Probability Calculation
4. Constructing the Attack Benefit–Defense Cost Objective Function
4.1. Security Strategy Analysis
4.2. Cost–Benefit Analysis
4.2.1. Cost Analysis
4.2.2. Benefit Analysis
4.3. Building a Cost–Benefit Function
5. Build an Optimal Security Strategy
5.1. Differential Evolution Algorithm
- initializationRandomly select Np D-dimensional population individuals in the search space as the initial solution. The random initialization of the i-th individual is a D-dimensional vector, which is denoted as , and it can be expressed by Equation (12) [22]where and are the predetermined lower and upper bounds of the search space for the j-th design variable, respectively, and is a random number generated in [0, 1].
- MutationsIn the individual population , three individuals are selected according to the mutation strategy to create a mutation vector , and the three individuals are different from each other. There are several basic evolution strategies [27,28] in DE. The mutation strategy selected in this paper is “DE/best/1/bin”, and it can be expressed as Equation (13):where , are arbitrary and unequal random integers in the set , and is the best individual. F is the scaling factor, which is a positive control parameter for scaling the difference vector, and it is often selected as 0.8. Then, we check whether the mutation vector violates the boundary constraint, and the violated individual returns the corresponding value according to the condition. The formula can be expressed by Equation (14).where is the j-th component of ; and are the maximum upper limit and the minimum lower limit of the search space of the j-dimensional variable, respectively.
- CrossoverThe crossover operation is very similar to the crossover operation of the classical genetic algorithm, and its purpose is to diversify the individuals of the current population. However, the crossover here is different from the crossover operation of the genetic algorithm. The crossover operation here is for a certain dimension of the entire population, while the crossover in the genetic algorithm is for each individual in the population, and the experimental solution generated after the crossover operation is:
- SelectionThe experimental solution produced after cross mutation may not be better than the initial solution. Therefore, it is necessary to compare the fitness values of the two objective functions and select individuals with better fitness values as offspring, which can be expressed as:
5.2. Reinforcement Learning and Q-Learning
5.3. Opposition-Based Learning
5.4. Mixed Strategy Differential Evolution Algorithm (RODE)
Parameter Setting in Q-Learning
5.5. Setting of Parameter CR
5.6. Framework of RODE
| Algorithm 1 The pseudo of RODE |
|
6. Experiment and Discussion
6.1. Experimental Scene
6.2. Generating a Bayesian Attack Graph
6.3. Attack Benefits and Protection Costs
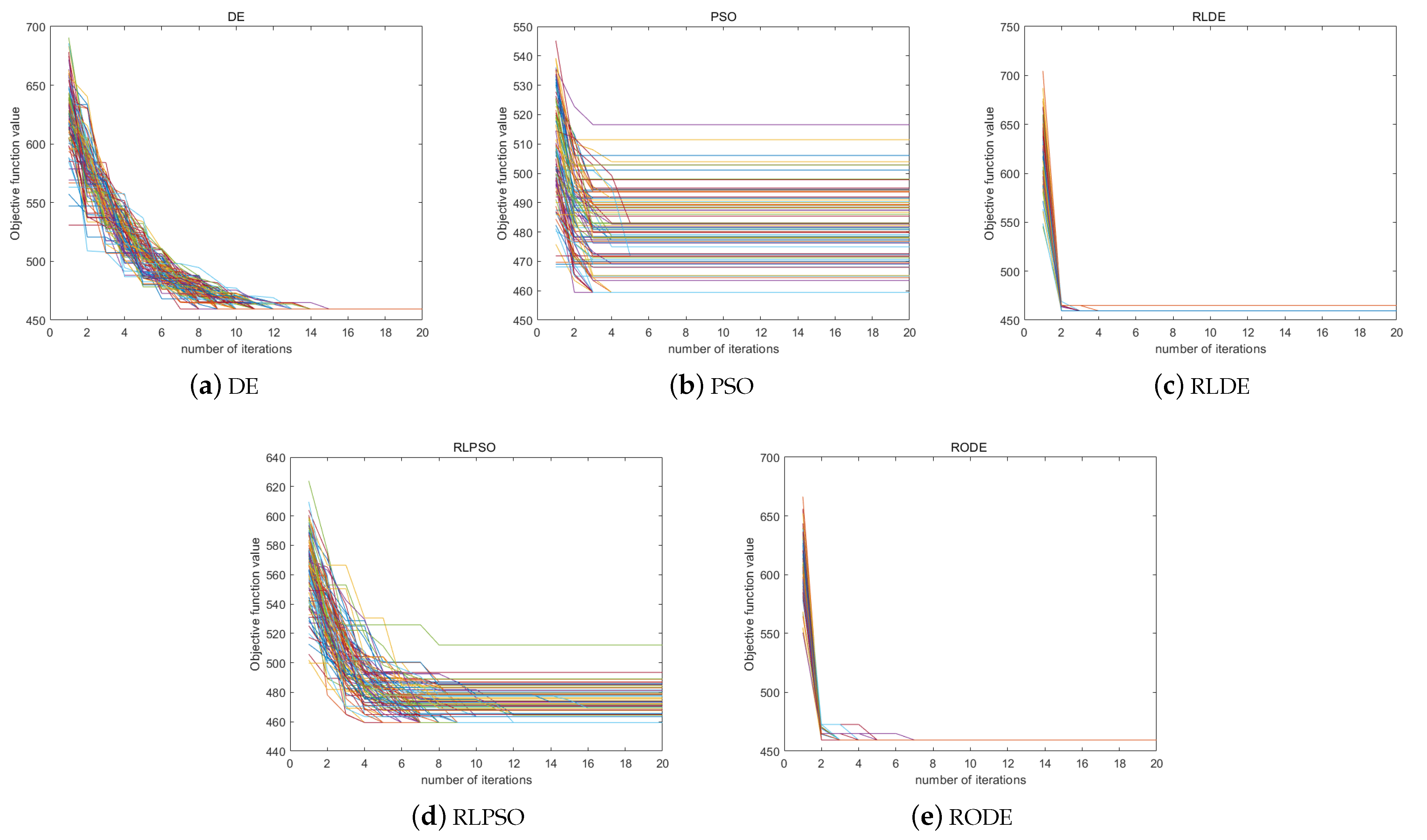
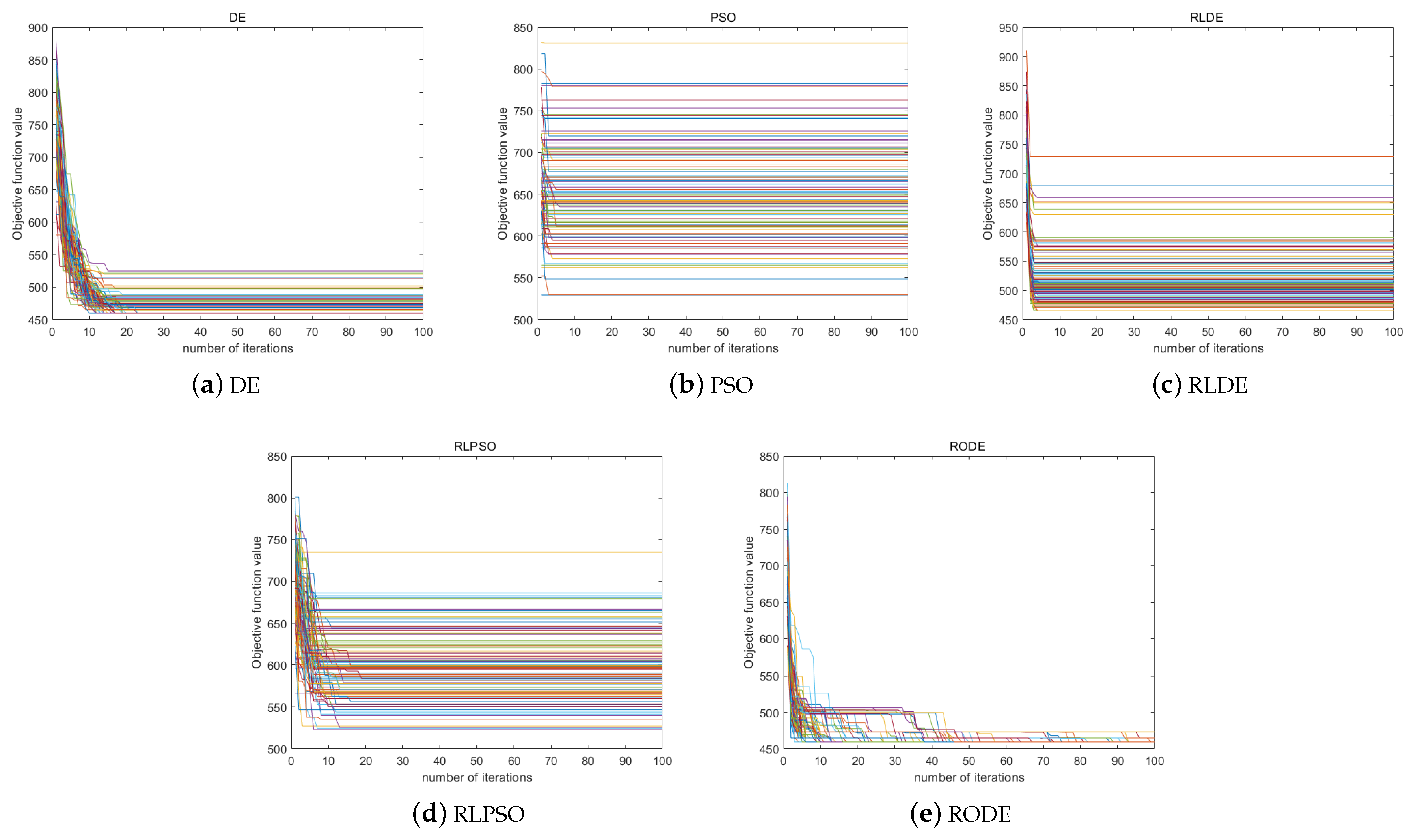
6.4. Result Analysis
6.5. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Protective Strategies | Protective Action | Cost | |
|---|---|---|---|
| Disconnect 192.168.0.1-192.168.0.10 | 20 | 0.25 | |
| Disconnect Disconnect 192.168.0.2-192.168.0.10 | 20 | 0.25 | |
| Disconnect Internet 192.168.0.10 | 30 | 0.30 | |
| Disconnect Internet 192.168.0.2 | 30 | 0.30 | |
| Disconnect Internet | 70 | 0.40 | |
| Disable Internet | 60 | 0.35 | |
| Disable Internet direct network access | 55 | 0.32 | |
| Disconnect Internet 192.168.0.1 | 30 | 0.30 | |
| Disable multi-hop access 192.168.0.10 | 25 | 0.20 | |
| Disable udp | 90 | 0.60 | |
| Disable direct network access 192.168.0.10 | 35 | 0.33 | |
| Disable direct network access 192.168.0.2 | 30 | 0.30 | |
| Disable direct network access 192.168.0.1 | 30 | 0.30 | |
| Disable netAccess 192.168.0.10 | 31 | 0.40 | |
| Disable networkService 192.168.0.10 | 31 | 0.40 | |
| Patch CVE-1999-0517 192.168.0.10 | 80 | 0.75 | |
| Disable service programs | 18 | 0.20 | |
| Disconnect 192.168.0.10-192.168.0.1 | 20 | 0.25 | |
| Disable execCode 192.168.0.10 | 18 | 0.20 | |
| Disconnect 192.168.0.10 | 20 | 0.30 | |
| Disconnect 192.168.0.10-192.168.0.2 | 38 | 0.40 | |
| Disconnect 192.168.0.1-192.168.0.2 | 38 | 0.40 | |
| Disable multi-hop access 192.168.0.1 | 26 | 0.35 | |
| Disable multi-hop access 192.168.0.2 | 26 | 0.35 | |
| Disable netAccess 192.168.0.2 | 20 | 0.30 | |
| Disable netAccess | 35 | 0.45 | |
| Disable networkService 192.168.0.2 | 38 | 0.40 | |
| Patch CVE-1999-0517 192.168.0.2 | 110 | 0.75 | |
| Disable execCode 192.168.0.2 | 60 | 0.55 | |
| Disable multi-hop access | 10 | 0.20 | |
| Disconnect 192.168.0.2-192.168.0.1 | 90 | 0.38 | |
| Disable netAccess 192.168.0.1 | 80 | 0.36 | |
| Disable service program 192.168.0.1 | 80 | 0.36 | |
| Disable networkService 192.168.0.1 | 190 | 0.48 | |
| Patch CVE-1999-0517 192.168.0.1 | 200 | 0.70 | |
| Install ids | 300 | 0.60 |
References
- Chen, T.M.; Abu-Nimeh, S. Lessons from Stuxnet. Computer 2011, 44, 91–93. Available online: https://ieeexplore.ieee.org/abstract/document/5742014 (accessed on 17 September 2022). [CrossRef]
- Case, D.U. Analysis of the cyber attack on the Ukrainian power grid. Electr. Inf. Shar. Anal. Cent. (E-ISAC) 2016, 388, 1–29. Available online: https://africautc.org/wp-content/uploads/2018/05/E-ISAC_SANS_Ukraine_DUC_5.pdf (accessed on 17 September 2022).
- Nespoli, P.; Papamartzivanos, D.; Mármol, F.G.; Kambourakis, G. Optimal countermeasures selection against cyber attacks: A comprehensive survey on reaction frameworks. IEEE Commun. Surv. Tutorials 2017, 20, 1361–1396. Available online: https://ieeexplore.ieee.org/abstract/document/8169023 (accessed on 17 September 2022). [CrossRef]
- Zhao, D.; Wang, L.; Wang, Z.; Xiao, G. Virus propagation and patch distribution in multiplex networks: Modeling, analysis, and optimal allocation. IEEE Trans. Inf. Forensics Secur. 2018, 14, 1755–1767. Available online: https://ieeexplore.ieee.org/abstract/document/8565928 (accessed on 17 September 2022). [CrossRef]
- Lee, C.; Han, S.M.; Chae, Y.H.; Seong, P.H. Development of a cyberattack response planning method for nuclear power plants by using the Markov decision process model. Ann. Nucl. Energy 2022, 166, 108725. Available online: https://www.sciencedirect.com/science/article/pii/S0306454921006010 (accessed on 17 September 2022). [CrossRef]
- Dewri, R.; Ray, I.; Poolsappasit, N.; Whitley, D. Optimal security hardening on attack tree models of networks: A cost-benefit analysis. Int. J. Inf. Secur. 2012, 11, 167–188. Available online: https://linkspringer.53yu.com/article/10.1007/s10207-012-0160-y (accessed on 17 September 2022). [CrossRef]
- Poolsappasit, N.; Dewri, R.; Ray, I. Dynamic security risk management using bayesian attack graphs. IEEE Trans. Dependable Secur. Comput. 2011, 9, 61–74. Available online: https://ieeexplore.ieee.org/abstract/document/5936075 (accessed on 17 September 2022). [CrossRef]
- Yang, X.S. A new metaheuristic bat-inspired algorithm. In Nature Inspired Cooperative Strategies for Optimization (NICSO 2010); Springer: Berlin/Heidelberg, Germany, 2010; pp. 65–74. Available online: https://linkspringer.53yu.com/chapter/10.1007/978-3-642-12538-6_6 (accessed on 17 September 2022).
- Meng, Z.; Yang, C. Two-stage differential evolution with novel parameter control. Inf. Sci. 2022, 596, 321–342. Available online: https://www.sciencedirect.com/science/article/pii/S0020025522002547 (accessed on 17 September 2022). [CrossRef]
- Dixit, A.; Mani, A.; Bansal, R. An adaptive mutation strategy for differential evolution algorithm based on particle swarm optimization. Evol. Intell. 2022, 15, 1571–1585. Available online: https://linkspringer.53yu.com/article/10.1007/s12065-021-00568-z (accessed on 17 September 2022). [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. Available online: https://www.jair.org/index.php/jair/article/view/10166 (accessed on 17 September 2022). [CrossRef]
- Xu, Z.; Han, G.; Liu, L.; Martínez-García, M.; Wang, Z. Multi-energy scheduling of an industrial integrated energy system by reinforcement learning-based differential evolution. IEEE Trans. Green Commun. Netw. 2021, 5, 1077–1090. Available online: https://ieeexplore.ieee.org/abstract/document/9361643 (accessed on 17 September 2022). [CrossRef]
- Liao, Z.; Li, S. Solving Nonlinear Equations Systems with an Enhanced Reinforcement Learning Based Differential Evolution. Complex Syst. Model. Simul. 2022, 2, 78–95. Available online: https://ieeexplore.ieee.org/abstract/document/9770100 (accessed on 17 September 2022). [CrossRef]
- Tizhoosh, H.R. Opposition-based learning: A new scheme for machine intelligence. In Proceedings of the International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC’06, Vienna, Austria, 28–30 November 2005; Volume 1, pp. 695–701. Available online: https://ieeexplore.ieee.org/abstract/document/1631345 (accessed on 17 September 2022).
- Deng, W.; Ni, H.; Liu, Y.; Chen, H.; Zhao, H. An adaptive differential evolution algorithm based on belief space and generalized opposition-based learning for resource allocation. Appl. Soft Comput. 2022, 127, 109419. Available online: https://www.sciencedirect.com/science/article/pii/S1568494622005518 (accessed on 17 September 2022). [CrossRef]
- Abed-alguni, B.H.; Paul, D. Island-based Cuckoo Search with elite opposition-based learning and multiple mutation methods for solving optimization problems. Soft Comput. 2022, 26, 3293–3312. Available online: https://linkspringer.53yu.com/article/10.1007/s00500-021-06665-6 (accessed on 17 September 2022). [CrossRef]
- Tubishat, M.; Idris, N.; Shuib, L.; Abushariah, M.A.; Mirjalili, S. Improved Salp Swarm Algorithm based on opposition based learning and novel local search algorithm for feature selection. Expert Syst. Appl. 2020, 145, 113122. Available online: https://www.sciencedirect.com/science/article/abs/pii/S0957417419308395 (accessed on 17 September 2022). [CrossRef]
- Hussien, A.G.; Amin, M. A self-adaptive Harris Hawks optimization algorithm with opposition-based learning and chaotic local search strategy for global optimization and feature selection. Int. J. Mach. Learn. Cybern. 2022, 13, 309–336. Available online: https://linkspringer.53yu.com/article/10.1007/s13042-021-01326-4 (accessed on 17 September 2022). [CrossRef]
- Rahnamayan, S.; Tizhoosh, H.R.; Salama, M.M. Opposition-based differential evolution algorithms. In Proceedings of the 2006 IEEE International Conference on Evolutionary Computation, Vancouver, BC, Canada, 16–21 July 2006; pp. 2010–2017. Available online: https://ieeexplore.ieee.org/abstract/document/1688554 (accessed on 17 September 2022).
- Fister, I.; Fister, D. Reinforcement Learning-Based Differential Evolution for Global Optimization. In Differential Evolution: From Theory to Practice; Springer: Berlin/Heidelberg, Germany, 2022; pp. 43–75. Available online: https://linkspringer.53yu.com/chapter/10.1007/978-981-16-8082-3_3 (accessed on 17 September 2022).
- Hu, Z.; Gong, W.; Li, S. Reinforcement learning-based differential evolution for parameters extraction of photovoltaic models. Energy Rep. 2021, 7, 916–928. Available online: https://www.sciencedirect.com/science/article/pii/S2352484721000974 (accessed on 17 September 2022). [CrossRef]
- Huynh, T.N.; Do, D.T.; Lee, J. Q-Learning-based parameter control in differential evolution for structural optimization. Appl. Soft Comput. 2021, 107, 107464. Available online: https://www.sciencedirect.com/science/article/abs/pii/S1568494621003872 (accessed on 17 September 2022). [CrossRef]
- Roy, A.; Kim, D.S.; Trivedi, K.S. Scalable optimal countermeasure selection using implicit enumeration on attack countermeasure trees. In Proceedings of the IEEE/IFIP International Conference on Dependable Systems and Networks (DSN 2012), Boston, MA, USA, 25–28 June 2012; Available online: https://ieeexplore.ieee.org/abstract/document/6263940 (accessed on 17 September 2022).
- Wang, S.; Zhang, Z.; Kadobayashi, Y. Exploring attack graph for cost-benefit security hardening: A probabilistic approach. Comput. Secur. 2013, 32, 158–169. Available online: https://www.sciencedirect.com/science/article/pii/S0167404812001496 (accessed on 17 September 2022). [CrossRef]
- Khosravi-Farmad, M.; Ghaemi-Bafghi, A. Bayesian decision network-based security risk management framework. J. Netw. Syst. Manag. 2020, 28, 1794–1819. Available online: https://linkspringer.53yu.com/article/10.1007/s10922-020-09558-5 (accessed on 17 September 2022). [CrossRef]
- Gallon, L.; Bascou, J.J. Using CVSS in attack graphs. In Proceedings of the 2011 Sixth International Conference on Availability, Reliability and Security, Vienna, Austria, 22–26 August 2011; pp. 59–66. Available online: https://ieeexplore.ieee.org/abstract/document/6045939 (accessed on 17 September 2022).
- Qin, A.K.; Huang, V.L.; Suganthan, P.N. Differential evolution algorithm with strategy adaptation for global numerical optimization. IEEE Trans. Evol. Comput. 2008, 13, 398–417. Available online: https://ieeexplore.ieee.org/abstract/document/4632146 (accessed on 17 September 2022). [CrossRef]
- Hansen, N.; Ostermeier, A. Completely derandomized self-adaptation in evolution strategies. Evol. Comput. 2001, 9, 159–195. Available online: https://ieeexplore.ieee.org/abstract/document/6790628 (accessed on 17 September 2022). [CrossRef]
- Samma, H.; Lim, C.P.; Saleh, J.M. A new reinforcement learning-based memetic particle swarm optimizer. Appl. Soft Comput. 2016, 43, 276–297. Available online: https://www.sciencedirect.com/science/article/abs/pii/S1568494616000132 (accessed on 17 September 2022). [CrossRef]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. Available online: https://linkspringer.53yu.com/article/10.1007/BF00992698 (accessed on 17 September 2022). [CrossRef]
- O’Donoghue, B.; Osband, I.; Munos, R.; Mnih, V. The uncertainty bellman equation and exploration. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 3836–3845. Available online: http://proceedings.mlr.press/v80/o-donoghue18a/o-donoghue18a.pdf (accessed on 17 September 2022).
- Ming, H.; Wang, M.; Liang, X. An improved genetic algorithm using opposition-based learning for flexible job-shop scheduling problem. In Proceedings of the 2016 2nd International Conference on Cloud Computing and Internet of Things (CCIOT), Dalian, China, 22–23 October 2016; pp. 8–15. Available online: https://ieeexplore.ieee.org/abstract/document/7868294 (accessed on 17 September 2022).
- Agarwal, M.; Srivastava, G.M.S. Opposition-based learning inspired particle swarm optimization (OPSO) scheme for task scheduling problem in cloud computing. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 9855–9875. Available online: https://linkspringer.53yu.com/article/10.1007/s12652-020-02730-4 (accessed on 17 September 2022). [CrossRef]
- Gämperle, R.; Müller, S.D.; Koumoutsakos, P. A parameter study for differential evolution. Adv. Intell. Syst. Fuzzy Syst. Evol. Comput. 2002, 10, 293–298. Available online: https://www.cse-lab.ethz.ch/wp-content/uploads/2008/04/gmk_wseas_2002.pdf (accessed on 17 September 2022).
- Si, T.; Miranda, P.B.; Bhattacharya, D. Novel enhanced Salp Swarm Algorithms using opposition-based learning schemes for global optimization problems. Expert Syst. Appl. 2022, 207, 117961. Available online: https://www.sciencedirect.com/science/article/abs/pii/S0957417422011940 (accessed on 17 September 2022). [CrossRef]
- Anderson, H. Introduction to Nessus. SecurityFocus Printable INFOCUS 2003. Available online: http://cryptomex.org/SlidesSeguRedes/TutNessus.pdf (accessed on 17 September 2022).
- Marini, F.; Walczak, B. Particle swarm optimization (PSO). A tutorial. Chemom. Intell. Lab. Syst. 2015, 149, 153–165. Available online: https://www.sciencedirect.com/science/article/abs/pii/S0169743915002117 (accessed on 17 September 2022). [CrossRef]
- Liu, Y.; Lu, H.; Cheng, S.; Shi, Y. An adaptive online parameter control algorithm for particle swarm optimization based on reinforcement learning. In Proceedings of the 2019 IEEE Congress on Evolutionary Computation (CEC), Wellington, New Zealand, 10–13 June 2019; pp. 815–822. Available online: https://ieeexplore.ieee.org/abstract/document/8790035 (accessed on 17 September 2022).
- Ades, S.; Herrera, D.A.; Lahey, T.; Thomas, A.A.; Jasra, S.; Barry, M.; Sprague, J.; Dittus, K.; Plante, T.B.; Kelly, J.; et al. Cancer care in the wake of a cyberattack: How to prepare and what to expect. JCO Oncol. Pract. 2022, 18, 23–34. Available online: https://www.sciencedirect.com/science/article/abs/pii/S1879850021002757 (accessed on 17 September 2022). [CrossRef]
- Teoh, A.A.; Ghani, N.B.A.; Ahmad, M.; Jhanjhi, N.; Alzain, M.A.; Masud, M. Organizational data breach: Building conscious care behavior in incident response. Comput. Syst. Sci. Eng. 2022, 40, 505–515. Available online: https://eprints.um.edu.my/33609/ (accessed on 17 September 2022). [CrossRef]
- Li, X.; Zhou, C.; Tian, Y.C.; Qin, Y. A dynamic decision-making approach for intrusion response in industrial control systems. IEEE Trans. Ind. Inform. 2018, 15, 2544–2554. Available online: https://ieeexplore.ieee.org/abstract/document/8443136 (accessed on 17 September 2022). [CrossRef]











| Index | Rank | Score |
|---|---|---|
| Access Vector (AV) | local access | 0.55 |
| adjacent network access | 0.62 | |
| network accessible | 0.85 | |
| Access Complexity (AC) | high | 0.44 |
| low | 0.77 | |
| Authentication (AU) | multiple instances of authentication | 0.50 |
| single instance of authentication | 0.62 | |
| no authentication | 0.85 |
| Index | Rank | Score |
|---|---|---|
| Exploit Code Maturity (E) | Unproven (U) | 0.91 |
| Proof-of-Conc (POC) | 0.94 | |
| Functional (F) | 0.97 | |
| High (H) | 1 | |
| Remediation Level (RL) | Official (O) | 0.95 |
| Temporary Fix (T) | 0.96 | |
| Workaround (W) | 0.97 | |
| Unavailable (U) | 1 | |
| Report Confidence (RC) | Unknown (U) | 0.92 |
| Reasonable (R) | 0.96 | |
| Confirmed (C) | 1 |
| State | A1 | A2 | A3 |
|---|---|---|---|
| 1 | |||
| 2 |
| Attribute Notes | Priori Probability | Attribute Notes | Priori Probability | Attribute Notes | Priori Probability |
|---|---|---|---|---|---|
| S1 | 0.5000 | S2 | 0.1811 | S3 | 0.5000 |
| S4 | 1.0000 | S5 | 1.0000 | S6 | 1.0000 |
| S7 | 0.3967 | S8 | 0.5100 | S9 | 1.0000 |
| S10 | 1.0000 | S11 | 1.0000 | S12 | 1.0000 |
| S13 | 1.0000 | S14 | 0.3890 | S15 | 0.5297 |
| S16 | 1.0000 | S17 | 1.0000 | S18 | 1.0000 |
| S19 | 1.0000 | S20 | 1.0000 | S21 | 1.0000 |
| S22 | 1.0000 | S23 | 1.0000 | S24 | 0.0801 |
| S25 | 1.0000 | S26 | 1.0000 | S27 | 1.0000 |
| S28 | 0.0800 | S29 | 1.0000 | S30 | 1.0000 |
| S31 | 1.0000 | S32 | 1.0000 | S33 | 1.0000 |
| S34 | 0.0336 |
| Algorithm | Parameter Settings | Value |
|---|---|---|
| PSO | w | 0.9 |
| c1 | 0.5 | |
| c2 | 2.5 | |
| RLPSO | 0.9 | |
| 0.1 | ||
| DE | F | 0.8 |
| CR | 0.6 | |
| RLDE | 0.8 | |
| RODE | 0.8 |
| Algorithm | 200 | 10 |
| PSO | 91 | 100 |
| RLPSO | 76 | 99 |
| DE | 0 | 75 |
| RLDE | 4 | 99 |
| RODE | 0 | 16 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, Y.; Zhou, Y.; Xu, L.; Zhao, D. Optimal Defense Strategy Selection Algorithm Based on Reinforcement Learning and Opposition-Based Learning. Appl. Sci. 2022, 12, 9594. https://doi.org/10.3390/app12199594
Yue Y, Zhou Y, Xu L, Zhao D. Optimal Defense Strategy Selection Algorithm Based on Reinforcement Learning and Opposition-Based Learning. Applied Sciences. 2022; 12(19):9594. https://doi.org/10.3390/app12199594
Chicago/Turabian StyleYue, Yiqun, Yang Zhou, Lijuan Xu, and Dawei Zhao. 2022. "Optimal Defense Strategy Selection Algorithm Based on Reinforcement Learning and Opposition-Based Learning" Applied Sciences 12, no. 19: 9594. https://doi.org/10.3390/app12199594
APA StyleYue, Y., Zhou, Y., Xu, L., & Zhao, D. (2022). Optimal Defense Strategy Selection Algorithm Based on Reinforcement Learning and Opposition-Based Learning. Applied Sciences, 12(19), 9594. https://doi.org/10.3390/app12199594