1. Introduction
Computational linguistics has become a significant area in the domain of linguistics. Computational techniques employed in computational linguistics have their origin in artificial intelligence (AI) or computer science. However, the main objective of computational linguistics will remain the modeling of human language, and thus it lasts as a part of the humanity domain [
1]. Computational linguistics will study how language models should be constructed for better understanding by the computers, that is it not just studies the usage of language in human actions, but even implements particular formal techniques that permit the exact construction of the hypotheses and its successive automated evaluation utilizing linguistic data (corpora) [
2]. The formal component of computational linguistics relies on AI techniques [
3,
4,
5].
Sentiment analysis (SA) turns into a growing domain at the intersection of computer science and linguistics that endeavours to automatically decide the sentiment presented in text. Sentiment is categorized into negative or positive evaluations articulated via languages [
6]. The most appropriate sources for opinionated text were posts from social networking sites and their observation has obtained popularity as many approaches were available for executing SA, evaluating the thoughts articulated regarding public figures or present events, and categorizing them as negative or positive [
7]. SA can be utilized for describing the text categorization as articulating a negative or positive opinion. Emotion detection in text can be projected as a solution for such difficulties. This method does not concentrate on the negative or positive opinions articulated, but rather endeavours to determine the human emotion that can be expressed [
8,
9,
10].
Finding the emotions articulated by an individual becomes a very difficult task that humans may also struggle with [
11]. Trying to devise this identification and establish an automatic way of detecting the expressed emotion is also challenging, not just because of the inadequate accessibility of training data but also the limited data presented in a short text. The emotional categories which are chosen were not exclusively dependent on the research conducted by psychologists with regard to the emotion theory [
12]. Several systems adapt the emotion categories on the basis of their findings, separating or merging emotions, without any concern for the scientific standard. In contrast, many accessible systems constitute their training data on the basis of the presence of particular keywords [
13]. By utilizing merely keywords-related techniques, there is no way for validating the accurateness of the classifier techniques as the classifier was almost exclusively trained for recognizing such keywords and categorizing the text, respectively [
14,
15].
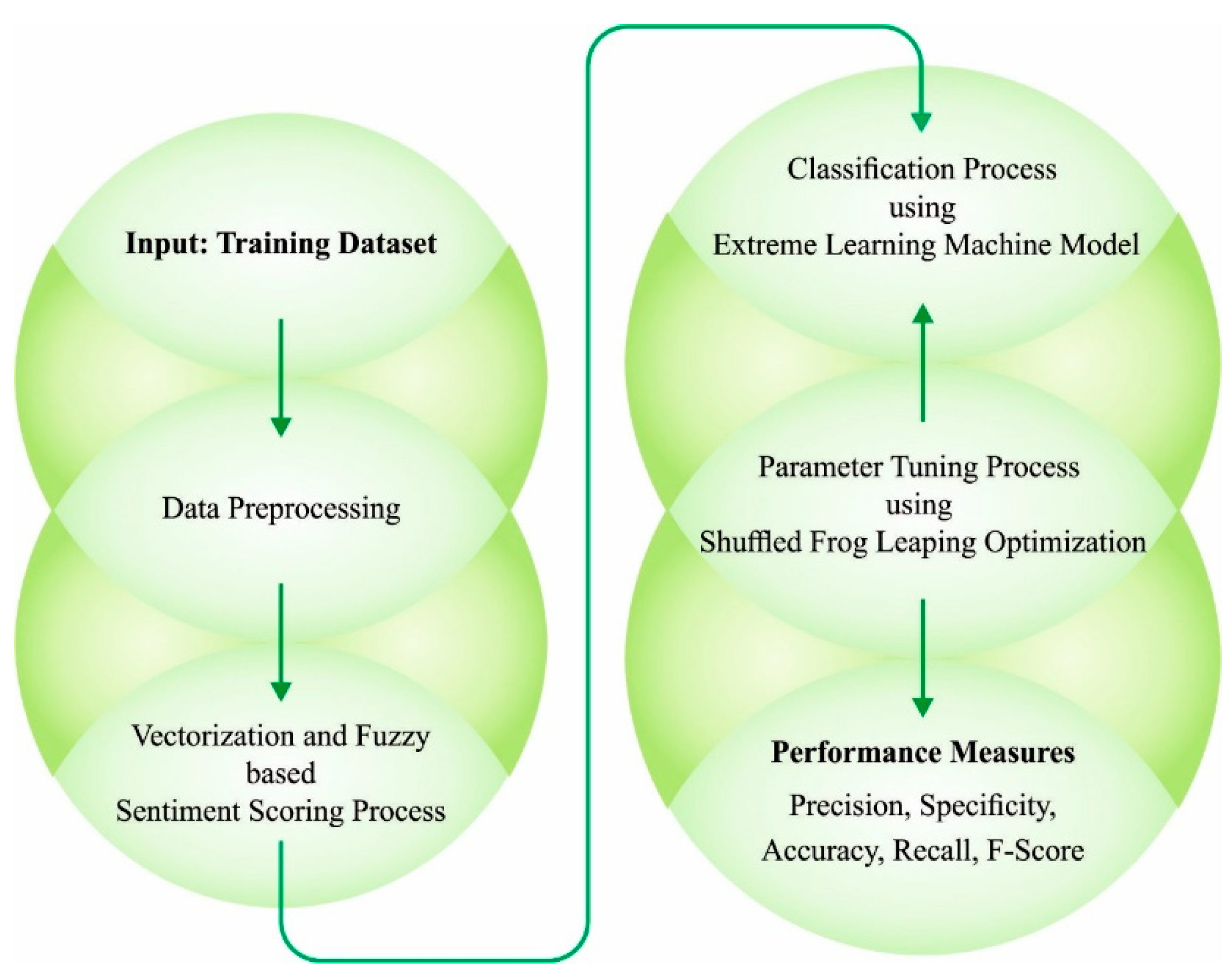
This article develops a computational linguistics-based emotion detection and classification model on social networking data (CLBEDC-SND) technique. The presented CLBEDC-SND technique performs different stages of data pre-processing to make it compatible for further processing. In addition, the CLBEDC-SND model undergoes vectorization and sentiment scoring process using the fuzzy approach. For emotion classification, the presented CLBEDC-SND model employs extreme learning machine (ELM). Finally, the parameters of the ELM model are optimally modified through the use of shuffled frog leaping optimization (SFLO) algorithm. The performance validation of the CLBEDC-SND method can be tested by making use of the benchmark dataset.
2. Related Works
Kabir and Madria [
16] formulated a neural network (NN) method, which makes use of manually labelled data for emotion classification on the COVID-19 tweets. The author provides manually labelled tweets data on COVID-19 emotional responses as well as regular tweets data. The author constituted a customized Q&A roBERTa method for extracting phrases from the tweets that can be mainly accountable for the respective emotions. Zhang et al. [
17] developed a model for emotion detection in online social networks (OSNs) from user level view and creates this issue as a multi-label learning issue. Firstly, the author finds emotion temporal correlations, label correlations, and social correlations from annotated Twitter data. Secondly, depending on the mentioned observations, the author implements factor graph-related emotion recognition method for incorporating emotion temporal, labels, and social correlations into a common structure, and identifies various emotions related to the multi-label learning method.
Vijayvergia and Kumar [
18] devised a new method for emotion identification which is utilized in real time because it is a relatively smaller memory size and much smaller run time. Current effective functioning methods for emotion identification were not utilized in real time because of the integration of large deep learning (DL) methods that make them significantly slower. This study suggests a method to leverage many shallow methods for surpassing the presentation of a single large method by compiling their strengths and ignoring their weakness. Such shallow methods operate independently and this enables them to be run parallelly for ensuring a smaller executing period. Rashid et al. [
19] defined Aimens system that identifies emotions from textual dialogues. This mechanism utilized the LSTM method related to DL for detecting the emotions such as angry, happy, and sad in contextual conversation. The chief input was a mixture of doc2vec and word2vec embedding.
Feng et al. [
20] presented a user group related topic-emotion method called UGTE for topic discovery and detecting emotions that ease the above feature sparsity issue of short texts. To be specific, the features of every user were utilized for discovering group of persons who express same emotions, and UGTE sums up short texts in a crew into long pseudo-documents efficiently. Riza and Charibaldi [
21] work uses the long short term memory (LSTM) technique since the technique proved superior to earlier works. Word embedding fast text is utilized for improving GloVe and Word2Vec that cannot manage the issue of out of vocabulary (OOV). Imran et al. [
22] aimed to examine reaction of citizens from various cultures to the new Coronavirus and individual sentiment regarding successive activities considered by various countries. Deep LSTM methods are utilized to estimate the emotions and sentiment polarity from tweets which are derived. Shrivastava et al. [
23] modelled a sequence-related convolutional neural network (CNN) having word embedding for detecting the emotions. An attention system can be implemented in the presented method that enables CNN to concentrate the part of the features that should be attended more or over the words that contain more effect on the classification. Shelke et al. [
24] develops a Leaky Relu activated Deep Neural Network (LRA-DNN), comprised of pre-processing, feature extraction, ranking and classification. The related ranks are allocated for every extracted feature in the ranking phase and lastly, the data are categorized, and precise output is gained from the classification process.
Although different ML and DL models for emotion classification are available in the literature, it is still needed to enhance the classification performance. Owing to continual deepening of the model, different parameters have a significant impact on the efficiency of the applied model. Since the trial-and-error method for hyperparameter tuning is a tedious and erroneous process, metaheuristic algorithms can be applied. Therefore, in this work, we employ SFLO algorithm for the parameter selection of the ELM model. The ultimate goal of this study was to formulate a structure for generalizing recently accumulated data and support businesses for understanding the mind of customers and mass media monitoring as it enables us to obtain an overview of the wider public opinion behind some topics.
3. The Proposed Model
In this article, a new CLBEDC-SND technique has been developed for the recognition and classification of emotions in social networking data. The presented CLBEDC-SND model performed distinct levels of data pre-processing to make it compatible for further processing. In addition, the CLBEDC-SND model undergoes vectorization and sentiment scoring process using fuzzy approach. At last, the SFLO with ELM model is applied for emotion recognition and classification.
Figure 1 demonstrates the overall working process of presented CLBEDC-SND algorithm.
3.1. Data Pre-Processing
The presented CLBEDC-SND model performed distinct levels of data pre-processing to make it compatible for further processing. In the social media data, there always exists unwanted parts where the pre-processing stage takes place for removing those parts from the comment that eventually assist in improving the performance [
24]. In the study, this stage undergoes six distinct steps, namely stopping word removal, tokenization, punctuation removal, URL removal, and lemmatization. The pre-processing function can be carried out in a mathematical form:
In Equation (1),
indicates the output of pre-processing function.
shows the input dataset and
is denotes pre-processing function as follows
In Equation (2), denotes the tokenization function, indicates the removal of punctuation function, shows the removal of stop word function, refers to the lemmatization function, and indicates the removal of URL function.
At first, the input text is subjected to the tokenization method where the whole text is detached into small unit named token. This technique assists the machine in easily understanding the text and it is expressed as follows:
The removal of the punctuation method is performed afterward the tokenization where the punctuation mark
) is detached from the tokenized dataset for a further examination of the text and it is shown in the following
Stop word is the most commonly used word that barely contributes all meaning in the language such as “the”, “a”, “is”, “are”, “or” and so on. The word has small amount of data for analyzing emotion from the texts that word was removed such that the quality of text is optimized.
The lemmatization procedure takes place afterward the removal of stop words where the root word is analyzed. The root word is just a meaningful base form of the text named the lemma. For instance, excites, excited, exciting, excitement shows a similar meaning where the lemma is root word or “excite”.
Lastly, the URL removal procedure is carried out. It indicates the location of resource that does not give any essential data for analyzing sentiment.
The checking of incomplete dataset is completed, even a smaller amount of incomplete dataset might cause misprediction of emotion in the text to manage these problems. This is the point where they check the existence of irrelevant or incomplete datasets from the pre-processed dataset. When any incomplete dataset is existent, it replaces that dataset with complete meaningful dataset such that the information is correctly synthesized and provides significant emotion.
For instance, tmrw” is replaced by “see you tomorrow”, “gd mrng” is replaced by “good morning”, “b4” is replaced by “before”, “2day” is replaced by “today”, “Lol” is replaced by “Laugh out loud”. Subsequently, the completed dataset undergoes process of feature extraction.
3.2. Vectorization and Sentiment Scoring
At this stage, the CLBEDC-SND model undergoes vectorization and sentiment scoring process using fuzzy approach. Vectorization: the text dataset can be transformed into vector format for the usage of ELM model [
25]. For these purposes, a python library Gensim algorithm is used to implement word embedding that can capture context, learn word relations, syntactic and semantic similarity of words in the document. Word2Vec is used to vectorize the text dataset, and the output can be used as a primary weight for these models. Fuzzy sentiment scoring: the degree of sentiment extracted the features that specify the sentiment degree expressed within the text, the procedure of extracting the degree of sentiment passes by initial recognizing opinionated word, and the linguistic hedge with Part-Of-Speech tagger, then applying WordNet and SentiWordNet dictionaries to relate polarity for this opinionated word as a primary score value
, afterward, it adapts this value according to the type and the existence of linguistic hedges, using the fuzzy logic function developed by Zadeh for getting the concluding sentimental score in the following: An opinion word has a complement hedge (“Not”), the fuzzy score is reformed as:
when the hedge is concentrator (“extremely”), then:
when the hedge is dilator (“somewhat”), then fuzzy score is deduced as:
The last fuzzy score is normalized and applied as sentiment feature in fake news classification algorithm.
3.3. Emotion Classification
For accurate and timely emotion classification, the presented CLBEDC-SND model employed the ELM model. Huang et al. [
26] devised the ELM model for single hidden layer feedforward neural network (SLFN). The algorithm arbitrarily chooses the input weight and empirically defines the output weight of SLFN. Afterward, the input weight and hidden layer bias are selected at random, SLFN is regarded as a linear technique and the output weight of SLFN is empirically defined by a generalized inverse function of the hidden layer output matrix. This model produces a fast-learning speed when compared to classical feedforward network learning algorithms while attaining good performance of generalization. Further, ELM tends to accomplish the minimum norm of weights and the minimum training error. The output weight is evaluated by Moore-Penrose (MP) generalized inverse. The learning speed of ELM is hundreds of times quicker than classical learning algorithm with good performance when compared to the gradient based learning mechanism. Different from the conventional gradient-based learning algorithm that works only for differentiable activation functions, the ELM mechanism is utilized for training SLFN with multiple non-differentiable activation functions.
Figure 2 portrays the infrastructure of ELM.
For a sequence of training instances
with
instances and
classes, the SLFN with activation function
and
hidden nodes is formulated below [
27], where
indicates the input weight,
denotes the bias of
-
hidden nodes,
shows the weight vector linking the
-
hidden and output nodes,
shows the inner products of
and
and
is network output interms of input
The Equation (8) is formulated by Equation (9):
where
In the expression, indicates the hidden layer output matrices of NN system, whereas shows the output weight matrix.
3.4. Hyperparameter Tuning
At the final stage, the parameters of the ELM model are optimally modified by the use of SFLO algorithm. The SFLO algorithm mimics the sub-population coevolution procedure of species of frogs seeking for food locations [
28]. It integrates randomness and deterministic methods and has very effectual computational power and global searching efficiency. The frog population of wetland can be classified into distinct subpopulations, has its own culture, and local search approach is conducted for local optimization within all the subpopulations. Initially, local search is implemented for all the subpopulations, viz., upgrade function is conducted for separate frogs with the worst adaptive values in the sub-population, and the upgrading approach is given below.
The upgraded solution is:
Now, rand signifies an arbitrary integer distributed uniformly within 0 and 1, Ds characterizes the amendment vector of the frog, and Dmax epitomizes the maximum permissible step size of frog individual in every jump.
3.4.1. Global Search Process
Step 1. Initialization. Define the number of frogs in all the subpopulations, overall amount of frogs in population, and subpopulation amount .
Step 2. The early population is arbitrarily produced (many primary solutions are randomly produced), and the fitness values of all the frogs are evaluated In the -dimension, the - frog is signified by
Step 3. Sort the fitness value in descending order, record the equivalent optimal of the existing optimal fitness value
, and the frog population is classified into different sub-populations. Specifically,
frogs are allocated to
subpopulations
encompasses
frogs, which satisfy
:
In Equation (12), indicates the amount of sub-populations, shows the - subpopulations, the initial frog is distributed into the initial sub-population, the secondary frog is dispersed into the secondary sub-population, the - frogs are distributed into the - subpopulations, and the frog is classified into the initial sub-population in descending sequence, and the recursion is recurring until each frog is disseminated.
Step 4. Based on the Equations (10) and (11) of the SFLO algorithm and the constraint of resolving the problems, meta evolution is conducted in every sub-population.
Step 5. Once every sub-population changes to a constrained amount of Lmax, every sub-population is mixed. Afterward a round of meta evolution for all the subpopulations, frogs in every sub-population. Still, it is in descending sequence and sub-population division, and the present global optimal solution is upgraded.
Step 6. Iterative termination condition. Once the convergence condition is met, the implementation procedure ends, or else it proceeds to Step 3.
SFLA generally accepts three approaches to regulate the runtime of the process.
. Afterward endless times global interchange of ideas, the global optimal has not been significantly augmented.
. Reach the function assessment time that is fixed beforehand the procedure is implemented.
. The fitness value of optimum converges to the current test outcomes, and the complete error is lesser than specific thresholding values.
The procedure should be enforced to present the entire searching cycle and output the optimal No matter stopping criteria are fulfilled.
3.4.2. Local Search Process
Step 4-1. If , then represents the count of sub-population to compare to the number of sub-populations. If , then indicates the count of local search progress for comparing to Lmax. The local search algorithm is the comprehensive procedure of step 4 of the global search technique.
Step 4-2. and described in the - populations. Afterward is evaluated based on Equation (10), the worst solution is upgraded in Equation (11) to increase the location of the worst frogs in the sub-population. Once the upgrade fitness number of the worst frog is superior to the existing fitness values, is utilized for replacing if the updated fitness value is inferior to the current fitness value, the global optima is used to replace Furthermore, the local search procedure is accomplished based on Equations (10) and (11), once the upgrade fitness number of the worst frog is superior to the existing one, then is utilized for replacing . Or then, a solution is arbitrarily produced for replacing to the worst frog. The fitness value of the upgraded sub-population is ordered in descending sequence. Set and reiterate these steps until
Step 4-3. Consider , and skip to steps 4-2 until
Step 4-4. The global data exchange is implemented if
The SFLO algorithm makes a derivation of a fitness function (FF) for acquiring enhanced classifier outcomes. It sets a positive value for indicating superior performance of the candidate solutions. In this paper, the reduction in the classifier error rate was taken as the FF, as presented below in Equation (13). The optimum solution comprises the least fault rate whereas the worst one gains a higher fault rate.
4. Results and Discussion
The proposed model is simulated using Python 3.6.5 tool on PC i5-8600k, GeForce 1050Ti 4 GB, 16 GB RAM, 250 GB SSD, and 1TB HDD. The parameter settings are given as follows: learning rate: 0.01, dropout: 0.5, batch size: 5, epoch count: 50, and activation: ReLU. In this study, the emotion classification results of the CLBEDC-SND method are tested using a dataset comprising 3500 samples. The dataset holds samples under 7 different class labels as depicted in
Table 1.
The emotion classifier results of the CLBEDC-SND model are presented in the form of confusion matrix in
Figure 3. The figure implied that the CLBEDC-SND model has properly identified all of the emotions that exist in the dataset.
Table 2 and
Figure 4 provide overall emotion classification outcomes of the CLBEDC-SND method on entire dataset. The experimental values indicated the CLBEDC-SND method has achieved improved results under all classes. For instance, in FEAR class, the CLBEDC-SND model has offered
of 98.49%,
of 93.91%,
of 95.60%,
of 98.97%, and
of 94.75%. Moreover, in JOY class, the CLBEDC-SND approach has rendered
of 99.03%,
of 96.60%,
of 96.60%,
of 99.43%, and
of 96.60%. Likewise, in ANGER class, the CLBEDC-SND algorithm has provided
of 98.54%,
of 95.35%,
of 94.40%,
of 99.23%, and
of 94.87%.
Table 3 and
Figure 5 offer overall emotion classification outcomes of the CLBEDC-SND approach on 70% of training (TR) dataset. The experimental values showed that the CLBEDC-SND method have achieved improved results under all classes. For example, in FEAR class, the CLBEDC-SND algorithm has presented
of 98.57%,
of 94.21%,
of 96.07%,
of 99%, and
of 95.13%. Further, in JOY class, the CLBEDC-SND technique has rendered
of 99.06%,
of 95.89%,
of 97.32%,
of 99.34%, and
of 96.60%. Similarly, in ANGER class, the CLBEDC-SND approach has granted
of 98.37%,
of 94.90%,
of 93.84%,
of 99.14%, and
of 94.37%.
Table 4 and
Figure 6 demonstrate complete emotion classification outcomes of the CLBEDC-SND approach on 30% of testing (TS) dataset. The experimental values specified the CLBEDC-SND technique have gained improved results under all classes. For example, on FEAR class, the CLBEDC-SND approach has offered
of 98.29%,
of 93.15%,
of 94.44%,
of 98.90%, and
of 93.79%. Further, on JOY class, the CLBEDC-SND technique has granted
of 98.95%,
of 98.11%,
of 95.12%,
of 99.66%, and
of 96.59%. Likewise, on ANGER class, the CLBEDC-SND approach has presented
of 98.95%,
of 96.48%,
of 95.80%,
of 99.45%, and
of 96.14%.
The training accuracy (TRA) and validation accuracy (VLA) attained by the CLBEDC-SND algorithm on test dataset is exemplified in
Figure 7. The experimental result implicit the CLBEDC-SND algorithm has gained maximum values of TRA and VLA. Seemingly the VLA is greater than TRA.
The training loss (TRL) and validation loss (VLL) reached by the CLBEDC-SND method on test dataset are given in
Figure 8. The TRL and VLL values needs to be lower for enhanced classification results. The experimental outcome showed the CLBEDC-SND technique has established minimal values of TRL and VLL. Particularly, the VLL is lower than TRL.
A clear precision-recall inspection of the CLBEDC-SND algorithm on test dataset is portrayed in
Figure 9. The precision-recall curve demonstrates the tradeoff between precision and recall for various threshold values. A high area under the curve denotes increased high recall and high precision, where high precision related to a low false positive rate, and high recall related to a low false negative rate. The figure denoted the CLBEDC-SND technique has resulted in enhanced values of precision-recall values under all classes.
A brief ROC study of the CLBEDC-SND algorithm on the test dataset is portrayed in
Figure 10. The outcomes denoted that the CLBEDC-SND method has shown its ability in categorizing distinct classes on test dataset. It is a graph presenting the performance of a classification model at all classification thresholds. It is a probability curve and tells how much the model is capable of distinguishing between classes.
For ensuring the enhanced emotion classification results of the CLBEDC-SND model, a detailed comparative analysis is shown in
Table 5 and
Figure 11 [
24]. The obtained results revealed that the CLBEDC-SND method has accomplished improved results under all measures. For example, with respect to
, the CLBEDC-SND method has reached increased
of 98.72% whereas the LRA-DNN, DNN, CNN, and ANN models have offered decreased
of 94.48%, 92.08%, 89.93%, and 88.05%, respectively. In the meantime, with respect to
, the CLBEDC-SND technique has gained increased
of 95.49% whereas the LRA-DNN, DNN, CNN, and ANN approaches have presented decreased
of 87.96%, 86.74%, 80.47%, and 78.43% correspondingly. Furthermore, with respect to
, the CLBEDC-SND method has attained increased
of 95.53% whereas the LRA-DNN, DNN, CNN, and ANN models have presented decreased
of 91.70%, 90.53%, 87.59%, and 84.75%, correspondingly. Next, with respect to
, the CLBEDC-SND technique has attained increased
of 99.25% whereas the LRA-DNN, DNN, CNN, and ANN methodologies have rendered decreased
of 91.67%, 88.39%, 86.10%, and 83.93%, correspondingly.
From these experimental evaluations, it is concluded that the CLBEDC-SND model has offered superior emotion classification results over other models. The enhanced performance of the CLBEDC-SND model is due to the inclusion of fuzzy based sentiment scoring and SFLO based optimal parameter tuning process. Therefore, the proposed model can be employed in real time social networking sites such as Facebook, Twitter, Instagram, etc. for emotion classification.



 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}