1. Introduction
A typical coal rock dynamic catastrophe experienced during coal mining is rock burst. When rock burst happens, coal and rocks are flung out abruptly, damaging equipment, obstructing traffic, and resulting in injuries [
1]. The issue of rock burst has become worse in coal mines, as mining depths have progressively increased, presenting a major danger to coal mine crew safety and underground production operations [
2,
3]. The beginning and progression of cracks to penetration often accompany the instability failure process of coal and rock mass under impact loads [
4,
5]. In addition to being the most obvious indicator of the coal and rock mass’s present condition, the cracks that are produced on their surfaces are also a sign of their impending breakdown under dynamic impact [
6,
7,
8].
With the quick advancement of computer vision technology, several traditional crack detection methods have been developed, with the main ones including segmentation, region growth, edge detection, support vector machines, and k-nearest neighbor, in digital image correlation technology [
9]. By analyzing cracks in coal CT images, Li et al. [
10] established a crack segmentation technique and crack profile evolution model based on contour evolution and gradient direction consistency, resulting in improved crack segmentation. By using the partial differential method and the improved C-V model during image processing, Chen et al. [
11] improved the coal rock picture and estimated parameters such as the length, area, and spacing of the cracks. Li et al. [
12] suggested a technique for detecting cracks on the surface of coal bodies based on the vibration loading failure test and SVM. Miao et al. [
13] used acoustic emissions and digital image processing technologies to conduct uniaxial compression experiments on sandstone with various dip angles and to identify and categorize the crack shape. These techniques are straightforward and intuitive, and they can quickly and precisely display parameters such as crack propagation, direction, and length. However, they are generally difficult to use, expensive, and unable to be applied in some situations in which high detection accuracy and no contact are required. Future developments will focus on the quick, extensive, and automated analysis of a large number of pictures transmitted on-site against the backdrop of current intelligent mine construction.
Different from traditional methods, which need to design and extract features manually, deep learning obtains features through automatic learning, which can improve the accuracy of model recognition [
14,
15]. At present, deep learning algorithms are the mainstream technology for image recognition, with examples including the two-stage target detection algorithm based on candidate frames and the one-stage regression-based target detection algorithm [
16,
17,
18]. The two-stage algorithm detection method, which uses algorithms such as RCNN [
19], Fast-RCNN [
20], and Faster-RCNN [
21], involves the target item being detected and then classified. End-to-end neural networks that can anticipate item categories and bounding boxes are known as one-stage detection algorithms. Examples include the SSD [
22] and YOLO series [
23,
24,
25,
26]. Compared to other networks, YOLO is extensively used in a variety of sectors and has great generalization capabilities while also showing better performance as well as superior stability. At present, it is one of the most used frameworks for object detection. Cui et al. [
27] improved the YOLOv3 algorithm to identify concrete damage, and the model’s accuracy increased to 75.68% as a result. Zhao et al. [
28] proposed a bauxite sorting model that enhanced YOLOv3 by integrating the SE attention mechanism [
29] with the K-means algorithm to enhance the detection model’s feature extraction and propagation capabilities. In order to discover fabric flaws, Yue et al. [
30] clustered the prediction framework using the K-means algorithm, added the prediction layer, adjusted the loss function, and suggested an enhanced YOLOv4 algorithm. Liu et al. and Yan et al. [
31,
32] provided technological help for automated fruit harvesting by determining the maturity of fruits using the enhanced YOLOv5 model. To find flaws on the surface of aero engine components, Li et al. [
33] suggested the YOLOv5s-KEB model, which combines the representation capabilities of improved networks such as ECA and BiFPN. Breast cancers were identified using the YOLOv5 model by Aqsa Mohiyuddin et al. [
34].
Deep learning can automatically extract high-level semantic data from photos, opening up a new method for intelligent crack detection. With the development of deep learning, tunnel and bridge cracks have received extensive attention in terms of research and development, but at present, the use of YOLOv5 to identify coal and rock cracks has not been studied by scholars. Through the research presented in this paper, we can improve the information extraction of crack features and enrich crack identification research.
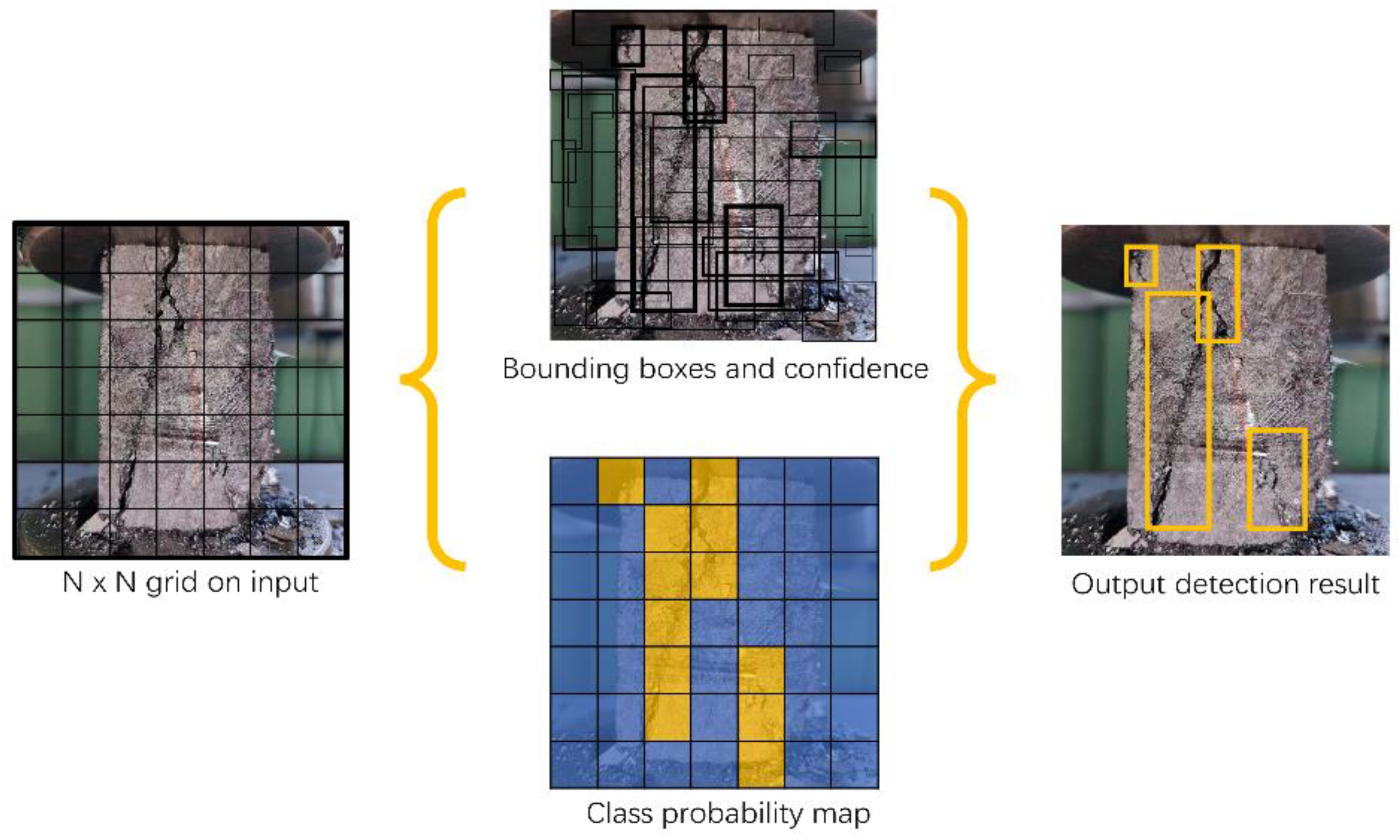
This study introduces an improved YOLOv5 coal rock surface crack detection method that takes into account that the model should have high flexibility, quick detection speed, compact size, cheap deployment cost, and great applicability in practical applications. In the first phase, we replaced the primary network layer with the Ghost [
35] lightweight feature extraction network to minimize the number of network parameters and computations and to speed up the identification of crack targets. In order to strengthen attention to the foreground area, enrich the semantic information of the shallow feature map, and increase the target detection accuracy, we introduced a coordinate attention (CA) [
36] module in the second step. This addressed the issue of the shallow feature map containing more background noise and insufficient semantic information. The final phase involved the use of the enhanced loss function ECIOU_Loss to hasten model convergence and achieve precise crack categorization and location.
2. Materials
2.1. Coal Sample Selection
The coal samples used in this experiment were selected from the #11 coal seam of the Xinliangyou Coal Industry in Pu County, Linfen, and the #9 coal seam of the Shuozhou Xiayao Coal Industry.
The Linfen #11 coal seam’s macroscopic coal rock features mostly include brilliant coal and black coal, with a tiny proportion of mirror coal and silk coal also present. This coal sample is from the semi-bright–semi-dark briquette category. The coal sample has a metamorphic degree of II–III with the following being present in thirds: coking coal, gas coal, and fat coal. The coal has the following features: black in color, pitch-vitreous sheen, hard and brittle, staggered cracks, well-developed cracks, strip-like structure, layered, massive structure, and pyrite nodules in certain places. Existing research demonstrates that when the coal seam is hard and when black coal predominates, rock burst is more likely to occur.
With the exception of bright and dark coal, the Shuozhou #9 coal seam’s macro-coal characteristics are mostly semi-bright coal and dark coal, with the black coal having a high degree of hardness. The coal samples’ degree of metamorphism falls within the I–II metamorphic stage, which is characterized by thick, hard cracks with angular or irregular cracks that are filled with calcite veins.
2.2. Sample Preparation
Coal samples were obtained from the working faces of two coal mines along the trough. The working face’s flat coal wall was where the coal samples were collected. Coal samples were wrapped in plastic wrap and were then placed in a foam box during transit to avoid weathering and collision. Experiments were carried out in the in situ modified mining mechanics laboratory of the Taiyuan University of Technology.
Requirements for sample preparation were as follows: A CNC sand wire cutting machine was used for coal sample processing and production. This machine was used to take two types of test pieces of various sizes: the first were 50 mm × 100 mm coal pillar test pieces, and the second were 50 mm × 25 mm coal pillar specimens.
2.3. Data Collection
Since there was no existing dataset pertaining to coal rock cracks, data collection activities needed to be completed before conducting the study. WDW-100KN microcomputer-controlled electronic universal testing equipment was used in this study to conduct tests on the physical and mechanical parameters of coal samples [
37]. The loading method adopted displacement control, and the loading rate was set to 0.001 mm/s. As soon as a crack appeared on the specimen’s surface, the dataset gathering process was started for the cracks. In total, more than 1600 photographs of coal rock cracks were obtained; 100 of these photos were chosen as the test set, and the other photos were randomly split into training and validation shots in a 7:3 ratio.
Table 1 shows the divide.
2.4. Data Annotation
The LabelImg [
38] software, which is available for Windows, was used. In this experiment, the YOLO data format was used, and each picture’s label information was immediately stored in a text file with the same name as the image.
Table 2 displays a portion of the text file’s content that was saved following data annotation.
5. Conclusions
This study suggested an enhanced target recognition approach for the YOLOv5-G model, with a focus on the issue of coal and rock dynamic catastrophes, by taking into account the real demands of engineering in situations in which there is low model detection accuracy, sluggish speed, and poor portability. Initially, the model employed the Ghost module to lighten the network as a whole, significantly reducing the number of model parameters and speeding up the network. Then, the CA attention mechanism was embedded in the C3Ghost module of the backbone network to improve the model accuracy and learning ability; Finally, through the ECIOU_Loss function, the regression positioning ability of the model was improved. According to experiments, the mAP of YOLOv5-G is up 1.7% from the original model, the detection speed is 1.9 times quicker, and the model weight is just 8 MB. The strong generalization, high detection accuracy, and quick speed of the model make it useful for future hardware replacement and also indicate some practical value in the area of real-time applications.
Given the limits of the detection technique provided in this research, we will continue to develop the model as well as expand its function to extract physical characteristics such as the crack length, width, and propagation speed. Furthermore, the detection network design suggested in this research can also be utilized for other fields, such as for the detection of industrial equipment defects, building damage, and road and bridge cracks.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}