
Augmentation of Deep Learning Models for Multistep Traffic Speed Prediction
 , , , , and
, , , , and
Abstract
:1. Introduction
2. Literature Review
3. Methodology
3.1. Input Data
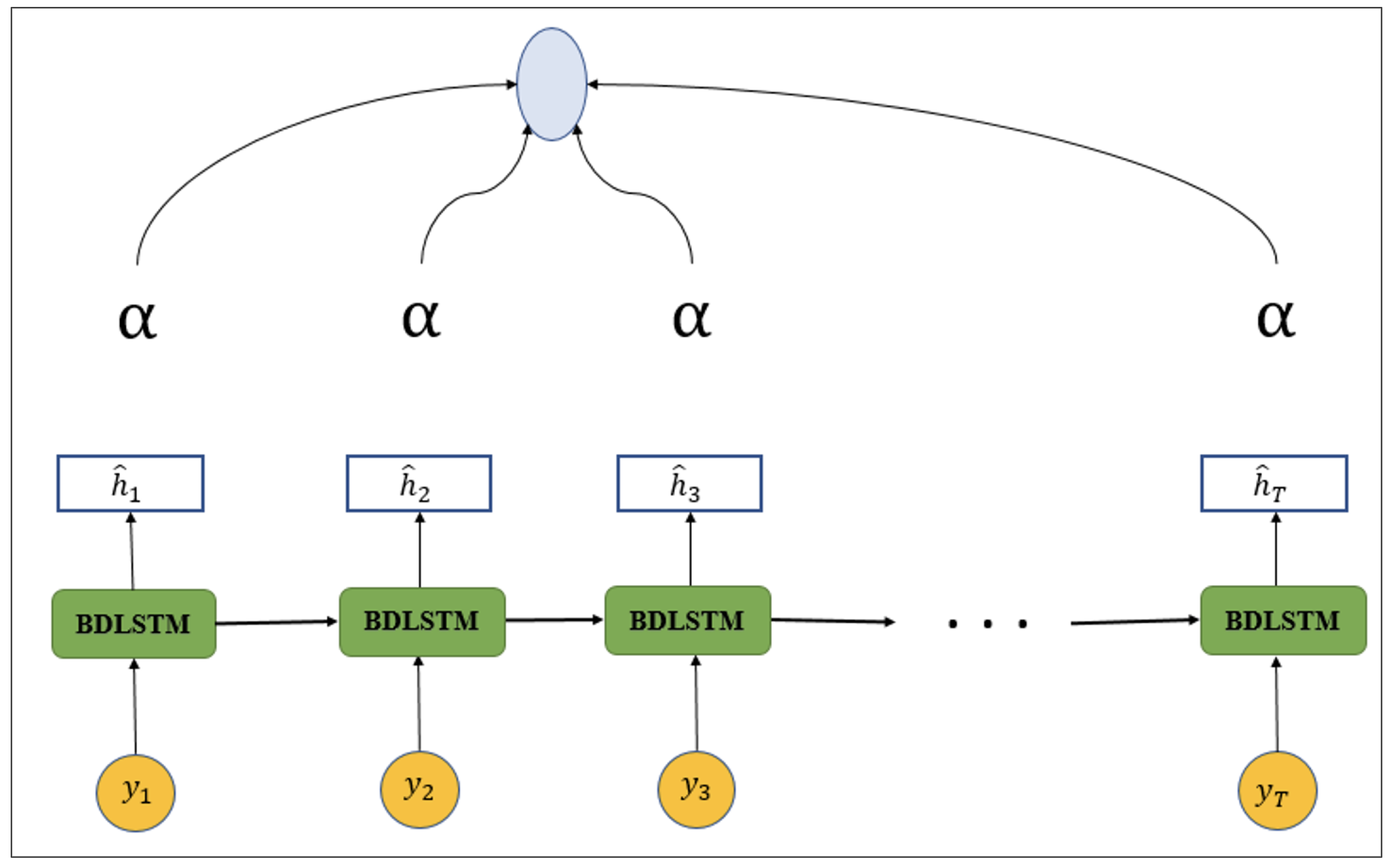
3.2. Bidirectional LSTMs
3.3. Attention
3.4. Fully Convolutional Network (FCN)
3.5. AttBDLSTM-FCN
3.6. Dataset Description
3.7. Experimental Setup
4. Results Analysis and Discussion
Ablation Study
5. Conclusions and Future Work
- We proposed a deep-stacked model studying both forward and backward dependencies of the traffic data. Firstly, it integrates both attention-based BDLSTMs and FCN as an introductory module to capture the spatiotemporal correlation in the network-wide traffic data. We examined the attention layer behavior in our model and concluded that using attention mechanisms can enhance the model performance accordingly.
- The proposed model exploited the benefits of deep-learning-based architectures, e.g., bidirectional long short-term memory and fully convolutional neural networks, to improve prediction performance in this study.
- Our study demonstrated that AttBDLSTM-FCN achieved better performance in network-wide traffic speed prediction when predicting traffic for 15, 30, and 60 min, respectively. Moreover, the proposed model is also competent for multistep network-wide traffic speed prediction in the future.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Van Lint, J.; Van Hinsbergen, C. Short-term traffic and travel time prediction models. Artif. Intell. Appl. Crit. Transp. Issues 2012, 22, 22–41. [Google Scholar]
- Duan, Y.; Yisheng, L.; Wang, F.Y. Travel time prediction with LSTM neural network. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 1053–1058. [Google Scholar]
- Ma, X.; Tao, Z.; Wang, Y.; Yu, H.; Wang, Y. Long short-term memory neural network for traffic speed prediction using remote microwave sensor data. Transp. Res. Part C Emerg. Technol. 2015, 54, 187–197. [Google Scholar] [CrossRef]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU neural network methods for traffic flow prediction. In Proceedings of the 2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar]
- Jiang, X.; Adeli, H. Wavelet packet-autocorrelation function method for traffic flow pattern analysis. Comput.-Aided Civ. Infrastruct. Eng. 2004, 19, 324–337. [Google Scholar] [CrossRef]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Cui, Z.; Ke, R.; Pu, Z.; Wang, Y. Deep bidirectional and unidirectional LSTM recurrent neural network for network-wide traffic speed prediction. arXiv 2018, arXiv:1801.02143. [Google Scholar]
- Fei, X.; Lu, C.C.; Liu, K. A bayesian dynamic linear model approach for real-time short-term freeway travel time prediction. Transp. Res. Part C Emerg. Technol. 2011, 19, 1306–1318. [Google Scholar] [CrossRef]
- Oh, C.; Park, S. Investigating the effects of daily travel time patterns on short-term prediction. KSCE J. Civ. Eng. 2011, 15, 1263–1272. [Google Scholar] [CrossRef]
- Ahmed, M.S.; Cook, A.R. Analysis of Freeway Traffic Time-Series Data by Using Box-Jenkins Techniques; The National Academies of Sciences, Engineering, and Medicine: Washington, DC, USA, 1979; Number 722. [Google Scholar]
- Cai, P.; Wang, Y.; Lu, G.; Chen, P.; Ding, C.; Sun, J. A spatiotemporal correlative k-nearest neighbor model for short-term traffic multistep forecasting. Transp. Res. Part C Emerg. Technol. 2016, 62, 21–34. [Google Scholar] [CrossRef]
- Mingheng, Z.; Yaobao, Z.; Ganglong, H.; Gang, C. Accurate multisteps traffic flow prediction based on SVM. Math. Probl. Eng. 2013, 2013, 418303. [Google Scholar] [CrossRef]
- Park, D.; Rilett, L.R. Forecasting freeway link travel times with a multilayer feedforward neural network. Comput.-Aided Civ. Infrastruct. Eng. 1999, 14, 357–367. [Google Scholar] [CrossRef]
- Yin, H.; Wong, S.; Xu, J.; Wong, C. Urban traffic flow prediction using a fuzzy-neural approach. Transp. Res. Part C Emerg. Technol. 2002, 10, 85–98. [Google Scholar] [CrossRef]
- Van Lint, J.; Hoogendoorn, S.; van Zuylen, H.J. Freeway travel time prediction with state-space neural networks: Modeling state-space dynamics with recurrent neural networks. Transp. Res. Rec. 2002, 1811, 30–39. [Google Scholar] [CrossRef]
- Yu, R.; Li, Y.; Shahabi, C.; Demiryurek, U.; Liu, Y. Deep learning: A generic approach for extreme condition traffic forecasting. In Proceedings of the 2017 SIAM International Conference on Data Mining, Houston, TX, USA, 27–29 April 2017; pp. 777–785. [Google Scholar]
- Wang, P.; Kim, Y.; Vaci, L.; Yang, H.; Mihaylova, L. Short-term traffic prediction with vicinity Gaussian process in the presence of missing data. In Proceedings of the 2018 Sensor Data Fusion: Trends, Solutions, Applications (SDF), Bonn, Germany, 9–11 October 2018. [Google Scholar]
- Kim, Y.; Wang, P.; Zhu, Y.; Mihaylova, L. A capsule network for traffic speed prediction in complex road networks. In Proceedings of the 2018 Sensor Data Fusion: Trends, Solutions, Applications (SDF), Bonn, Germany, 9–11 October 2018. [Google Scholar]
- Koesdwiady, A.; Soua, R.; Karray, F. Improving traffic flow prediction with weather information in connected cars: A deep learning approach. IEEE Trans. Veh. Technol. 2016, 65, 9508–9517. [Google Scholar] [CrossRef]
- Cheng, Q.; Liu, Y.; Wei, W.; Liu, Z. Analysis and forecasting of the day-to-day travel demand variations for large-scale transportation networks: A deep learning approach. In Transportation Analytics Contest; Technical Report; FHWA Resource Center: Atlanta, GA, USA, 2016. [Google Scholar]
- Zhang, J.; Zheng, Y.; Qi, D.; Li, R.; Yi, X.; Li, T. Predicting citywide crowd flows using deep spatio-temporal residual networks. Artif. Intell. 2018, 259, 147–166. [Google Scholar] [CrossRef]
- Zhang, K.; Zheng, L.; Liu, Z.; Jia, N. A deep learning based multitask model for network-wide traffic speed prediction. Neurocomputing 2020, 396, 438–450. [Google Scholar] [CrossRef]
- Riaz, A.; Nabeel, M.; Khan, M.; Jamil, H. SBAG: A hybrid deep learning model for large scale traffic speed prediction. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 287–291. [Google Scholar] [CrossRef]
- Song, X.; Kanasugi, H.; Shibasaki, R. Deeptransport: Prediction and simulation of human mobility and transportation mode at a citywide level. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2618–2624. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Graves, A.; Jaitly, N.; Mohamed, A.R. Hybrid speech recognition with deep bidirectional LSTM. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; pp. 273–278. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- He, C.; Hu, H. Image captioning with visual-semantic double attention. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2019, 15, 1–16. [Google Scholar] [CrossRef]
- Arshad, M.A.; Huang, Z.; Riaz, A.; Hussain, Y. Deep Learning-Based Resolution Prediction of Software Enhancement Reports. In Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 27–30 January 2021; pp. 492–499. [Google Scholar] [CrossRef]
- Li, P.; Song, Y.; McLoughlin, I.V.; Guo, W.; Dai, L.R. An Attention Pooling Based Representation Learning Method for Speech Emotion Recognition; International Speech Communication Association: Baixas, France, 2018. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Li, Q.; Li, L.; Wang, W.; Li, Q.; Zhong, J. A comprehensive exploration of semantic relation extraction via pre-trained CNNs. Knowl.-Based Syst. 2020, 194, 105488. [Google Scholar] [CrossRef]
- Zhang, Y.; Qiu, Z.; Yao, T.; Liu, D.; Mei, T. Fully convolutional adaptation networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6810–6818. [Google Scholar]
- Budak, Ü.; Cömert, Z.; Rashid, Z.N.; Şengür, A.; Çıbuk, M. Computer-aided diagnosis system combining FCN and Bi-LSTM model for efficient breast cancer detection from histopathological images. Appl. Soft Comput. 2019, 85, 105765. [Google Scholar] [CrossRef]
- Karim, F.; Majumdar, S.; Darabi, H.; Chen, S. LSTM fully convolutional networks for time series classification. IEEE Access 2017, 6, 1662–1669. [Google Scholar] [CrossRef]
- Wang, Z.; Yan, W.; Oates, T. Time series classification from scratch with deep neural networks: A strong baseline. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1578–1585. [Google Scholar]
- Khan, M.; Wang, H.; Riaz, A.; Elfatyany, A.; Karim, S. Bidirectional LSTM-RNN-based hybrid deep learning frameworks for univariate time series classification. J. Supercomput. 2021, 77, 7021–7045. [Google Scholar] [CrossRef]
- Schörner, P.; Hubschneider, C.; Härtl, J.; Polley, R.; Zöllner, J.M. Grid-based micro traffic prediction using fully convolutional networks. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 4540–4547. [Google Scholar]
- Yasrab, R.; Jiang, W.; Riaz, A. Fighting Deepfakes Using Body Language Analysis. Forecasting 2021, 3, 303–321. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning. PMLR, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Wang, Y.; Zhang, W.; Henrickson, K.; Ke, R.; Cui, Z. Digital Roadway Interactive Visualization and Evaluation Network Applications to WSDOT Operational Data Usage; Technical Report; Department of Transportation: Washington, DA, USA, 2016.
- Guo, J.; Huang, W.; Williams, B.M. Adaptive Kalman filter approach for stochastic short-term traffic flow rate prediction and uncertainty quantification. Transp. Res. Part C Emerg. Technol. 2014, 43, 50–64. [Google Scholar] [CrossRef]
- Kang, D.; Lv, Y.; Chen, Y.Y. Short-term traffic flow prediction with LSTM recurrent neural network. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Liu, Y.; Wang, Y.; Yang, X.; Zhang, L. Short-term travel time prediction by deep learning: A comparison of different LSTM-DNN models. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017. [Google Scholar]
- Naeem, H.; Bin-Salem, A.A. A CNN-LSTM network with multi-level feature extraction-based approach for automated detection of coronavirus from CT scan and X-ray images. Appl. Soft Comput. 2021, 113, 107918. [Google Scholar] [CrossRef]
- Wang, J.; Chen, R.; He, Z. Traffic speed prediction for urban transportation network: A path based deep learning approach. Transp. Res. Part C Emerg. Technol. 2019, 100, 372–385. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time lags | 3, 6, and 12, respectively |
| Total time steps | 105,120 |
| Activation function | Sigmoid |
| Training process | Mini-batch gradient descent |
| Optimizer | RMSProp |
| Loss | MSE |
| Patience | 20 |
| Training sample | 75,679 |
| Validation samples | 18,920 |
| Number of trainable parameters | 3,491,173 |
| Number of nontrainable parameters | 256 |
| Total parameters | 3,491,429 |
| Time Lags | Models | Error | T + 1 | T + 3 | T + 6 | T + 12 |
|---|---|---|---|---|---|---|
| 3 | FCN | MAE | 6.53 | 5.03 | 5.61 | 7.60 |
| GRU | MAE | 1.89 | 2.45 | 3.43 | 3.30 | |
| LSTM | MAE | 1.94 | 2.64 | 2.83 | 2.67 | |
| LSTM-DNN | MAE | 1.86 | 2.32 | 2.37 | 2.75 | |
| LSTM-FCN | MAE | 1.54 | 2.21 | 2.24 | 2.31 | |
| BDLSTM | MAE | 1.40 | 2.18 | 2.22 | 2.26 | |
| PROPOSED-MODEL | MAE | 1.17 | 2.10 | 2.16 | 2.11 | |
| 6 | FCN | MAE | 6.58 | 5.28 | 5.58 | 8.27 |
| GRU | MAE | 1.80 | 2.66 | 3.80 | 3.53 | |
| LSTM | MAE | 1.74 | 2.87 | 3.14 | 2.69 | |
| LSTM-DNN | MAE | 2.09 | 2.74 | 2.80 | 2.61 | |
| LSTM-FCN | MAE | 1.45 | 2.82 | 2.66 | 2.50 | |
| BDLSTM | MAE | 1.42 | 2.62 | 2.71 | 2.61 | |
| PROPOSED-MODEL | MAE | 1.19 | 2.25 | 2.56 | 2.44 | |
| 12 | FCN | MAE | 8.09 | 5.29 | 7.70 | 12.06 |
| GRU | MAE | 2.17 | 3.36 | 3.77 | 3.52 | |
| LSTM | MAE | 2.29 | 3.51 | 3.54 | 3.11 | |
| LSTM-DNN | MAE | 2.62 | 3.45 | 3.38 | 3.09 | |
| LSTM-FCN | MAE | 1.71 | 3.43 | 3.33 | 2.71 | |
| BDLSTM | MAE | 1.54 | 3.20 | 3.31 | 2.75 | |
| PROPOSED-MODEL | MAE | 1.30 | 3.06 | 3.21 | 2.67 |
| Time Lags | Models | Error | T + 1 | T + 3 | T + 6 | T + 12 |
|---|---|---|---|---|---|---|
| 3 | FCN | MAPE | 18.10 | 16.04 | 16.72 | 20.30 |
| GRU | MAPE | 3.82 | 5.48 | 7.52 | 7.24 | |
| LSTM | MAPE | 4.22 | 5.87 | 6.35 | 6.23 | |
| LSTM-DNN | MAPE | 4.45 | 5.59 | 5.56 | 6.97 | |
| LSTM-FCN | MAPE | 3.62 | 5.18 | 5.29 | 5.59 | |
| BDLSTM | MAPE | 2.99 | 4.99 | 5.26 | 5.15 | |
| PROPOSED-MODEL | MAPE | 2.73 | 4.95 | 5.15 | 5.05 | |
| 6 | FCN | MAPE | 18.99 | 16.26 | 17.14 | 21.87 |
| GRU | MAPE | 3.69 | 6.52 | 8.88 | 8.64 | |
| LSTM | MAPE | 3.90 | 6.96 | 7.53 | 6.28 | |
| LSTM-DNN | MAPE | 5.0 | 7.09 | 7.08 | 6.33 | |
| LSTM-FCN | MAPE | 3.40 | 6.91 | 6.81 | 5.96 | |
| BDLSTM | MAPE | 3.11 | 6.60 | 6.74 | 6.09 | |
| PROPOSED-MODEL | MAPE | 2.75 | 5.39 | 6.66 | 5.80 | |
| 12 | FCN | MAPE | 20.48 | 17.01 | 21.18 | 27.89 |
| GRU | MAPE | 4.37 | 9.06 | 10.04 | 8.53 | |
| LSTM | MAPE | 5.13 | 9.36 | 9.45 | 7.53 | |
| LSTM-DNN | MAPE | 6.63 | 10.07 | 9.52 | 7.80 | |
| LSTM-FCN | MAPE | 4.02 | 9.78 | 9.52 | 6.98 | |
| BDLSTM | MAPE | 3.41 | 8.93 | 9.25 | 7.20 | |
| PROPOSED-MODEL | MAPE | 2.99 | 7.52 | 9.05 | 6.80 |
| Time Lag | Error | FCN | BDLSTM | AttBDLSTM | Proposed Model |
|---|---|---|---|---|---|
| 3 | MAE | 6.73 | 1.40 | 1.29 | 1.17 |
| MAPE | 18.10% | 2.99% | 2.77% | 2.73% | |
| 6 | MAE | 6.58 | 1.42 | 1.34 | 1.19 |
| MAPE | 18.9% | 3.11% | 2.99% | 2.75% | |
| 12 | MAE | 8.09 | 1.54 | 1.39 | 1.30 |
| MAPE | 20.48% | 3.41% | 3.11% | 2.99% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Riaz, A.; Rahman, H.; Arshad, M.A.; Nabeel, M.; Yasin, A.; Al-Adhaileh, M.H.; Eldin, E.T.; Ghamry, N.A. Augmentation of Deep Learning Models for Multistep Traffic Speed Prediction. Appl. Sci. 2022, 12, 9723. https://doi.org/10.3390/app12199723
Riaz A, Rahman H, Arshad MA, Nabeel M, Yasin A, Al-Adhaileh MH, Eldin ET, Ghamry NA. Augmentation of Deep Learning Models for Multistep Traffic Speed Prediction. Applied Sciences. 2022; 12(19):9723. https://doi.org/10.3390/app12199723
Chicago/Turabian StyleRiaz, Adnan, Hameedur Rahman, Muhammad Ali Arshad, Muhammad Nabeel, Affan Yasin, Mosleh Hmoud Al-Adhaileh, Elsayed Tag Eldin, and Nivin A. Ghamry. 2022. "Augmentation of Deep Learning Models for Multistep Traffic Speed Prediction" Applied Sciences 12, no. 19: 9723. https://doi.org/10.3390/app12199723