


Mitigating Sensor and Acquisition Method-Dependence of Fingerprint Presentation Attack Detection Systems by Exploiting Data from Multiple Devices




Abstract
:1. Introduction
2. Fingerprint Presentation Attack Detection and Interoperability
2.1. FPAD
2.2. The Interoperability and Generalization Problem
3. Interoperability Scenarios for the Design of Fingerprint PAD
- Intra-sensor and intra-method: this is the standard and optimal application scenario. The PAD is used to analyze and classify images acquired with the same sensor used in the training phase. The type of PAI used to attack the system is known by the system;
- Intra-sensor and cross-method: this is a standard, but unfavorable application scenario. The PAD is used to analyze and classify images acquired with the same sensor used in the training phase. The type of PAI used to attack the system are unknown to the system. Such a scenario is unpredictable by the designer as new replication methods can be discovered and used after the PAD has been designed and trained;
- Cross-sensor and intra-method: the designer/manufacturer decides, knowing the risks, to use a PAD trained on a sensor on a AFIS consisting of a different acquisition sensor. This choice is not optimal, but is made for economic reasons or in the absence of data to retrain/fine-tune a new PAD. The type of PAI used to attack the system is known by the system, but since the acquisition sensor is different, the resulting images could be very different;
- Cross-sensor and cross-method: as in the previous scenario, the designer uses a PAD trained on a sensor on an AFIS consisting of a different acquisition sensor. Moreover, the type of PAI used to attack the system is unknown to the system.
Experimental Protocol
- Intra-sensor and intra-method: the training set is partially or totally composed of data belonging to the target sensor. The PAIs are created with the same method in the two sets;
- Intra-sensor and cross-method: the training set is partially or totally composed of data belonging to the target sensor. The spoofs of the training set were created with a different method than the test set ones;
- Cross-sensor and intra-method: the training set does not contain data on the target sensor. The PAIs are created with the same method in the two sets;
- Cross-sensor and cross-method: the training set does not contain information on the target sensor. The spoofs of the training set were created with a different method than the test set ones.
- Pre-trained: some competitors from the eighth edition of the Fingerprint Liveness Detection Competition have been selected (Table 1). Certain of them used additional data for training, although the use of only the LivDet 2021 training dataset was recommended. This experiment is strongly representative of the current state of the art, but it is not completely controlled, since the implementation details are unknown;
- Self-trained: the experiments are fully controlled and the details and training data are known. In particular, (i) two hand-crafted PADs have been implemented consisting of a feature extractor via BSIF and LBP, respectively, followed by a linear SVM classifier and (ii) one deep-learning based PAD. The Spoof Buster method is implemented.
4. Results
4.1. Dataset
4.2. Pre-Trained Analysis
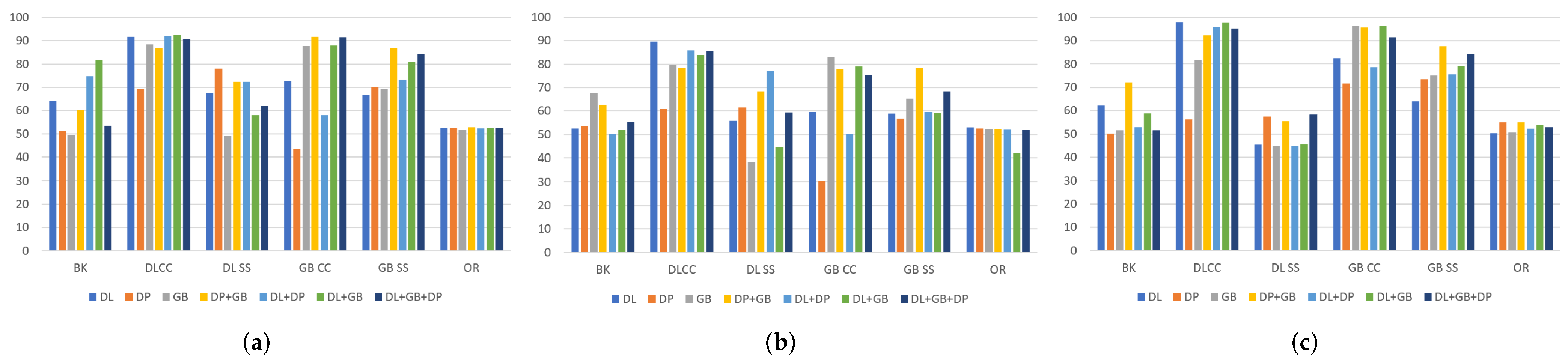
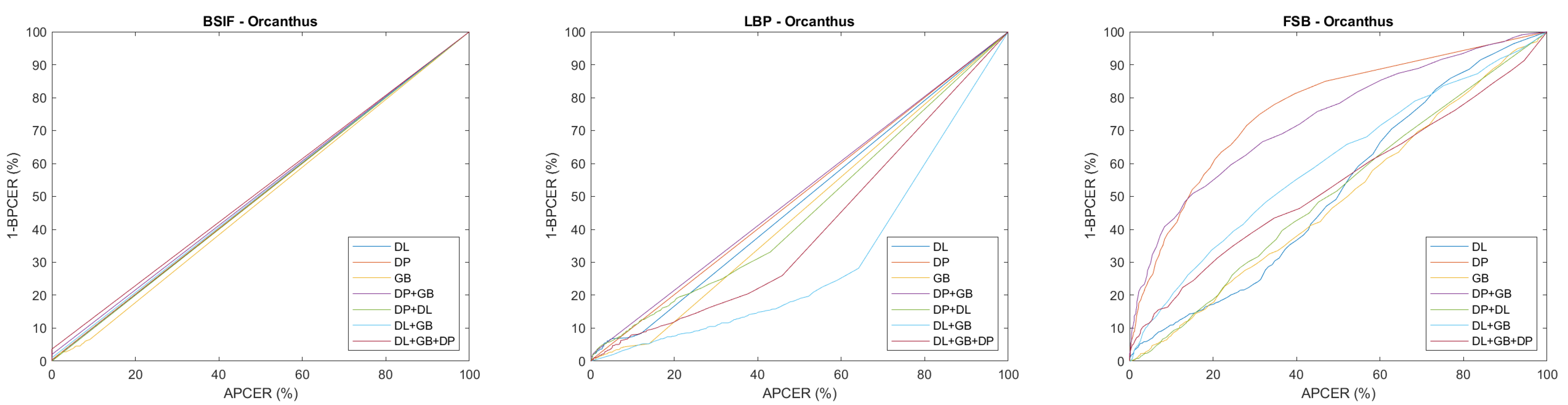
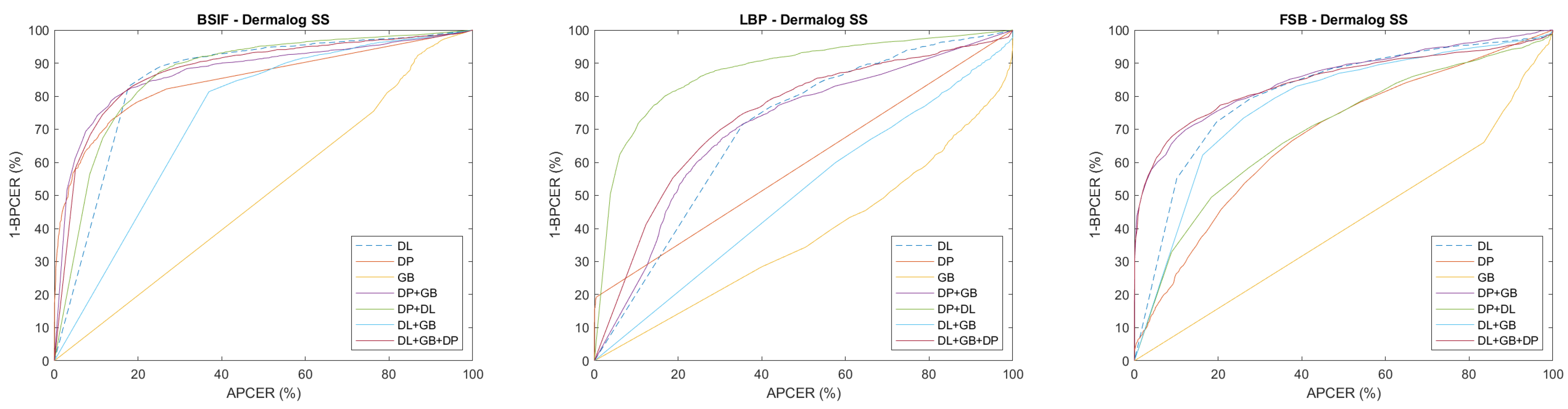
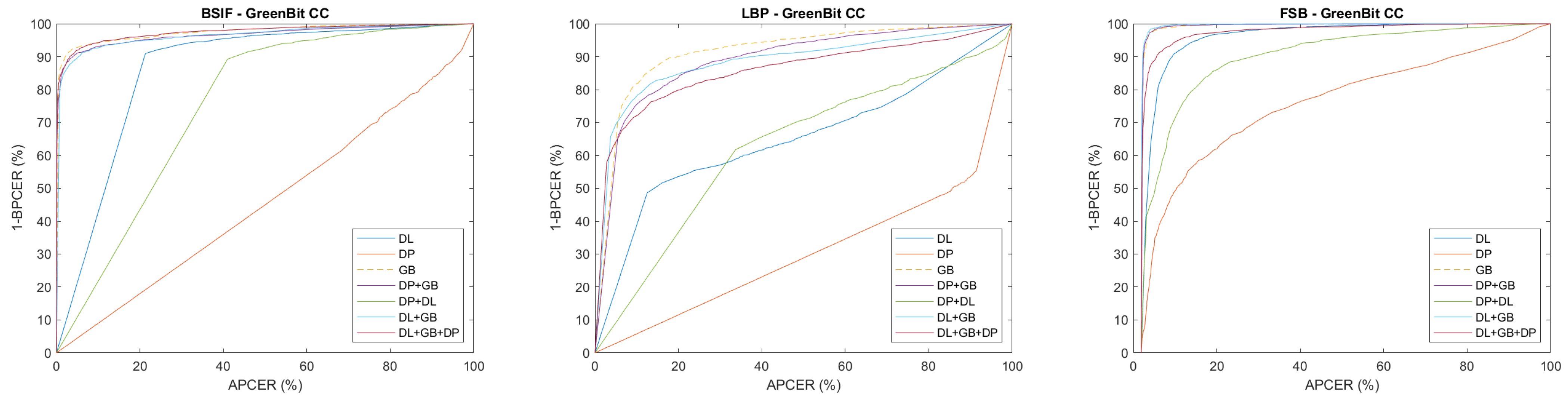
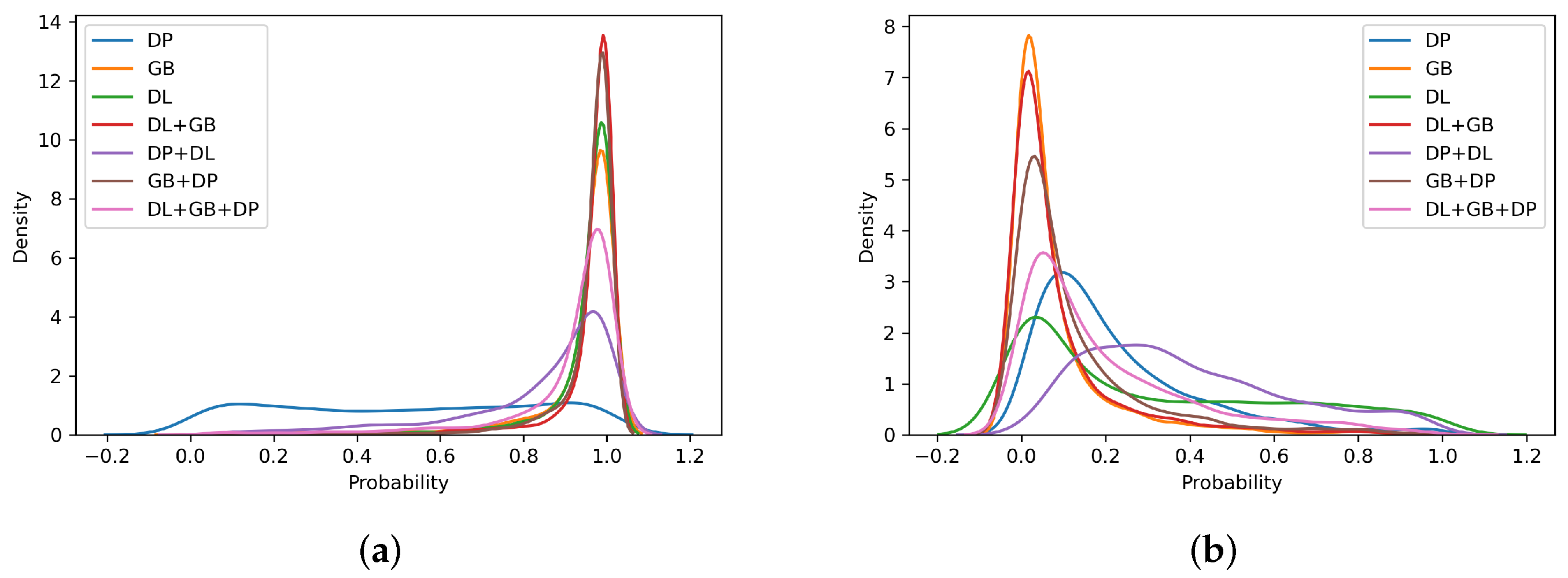
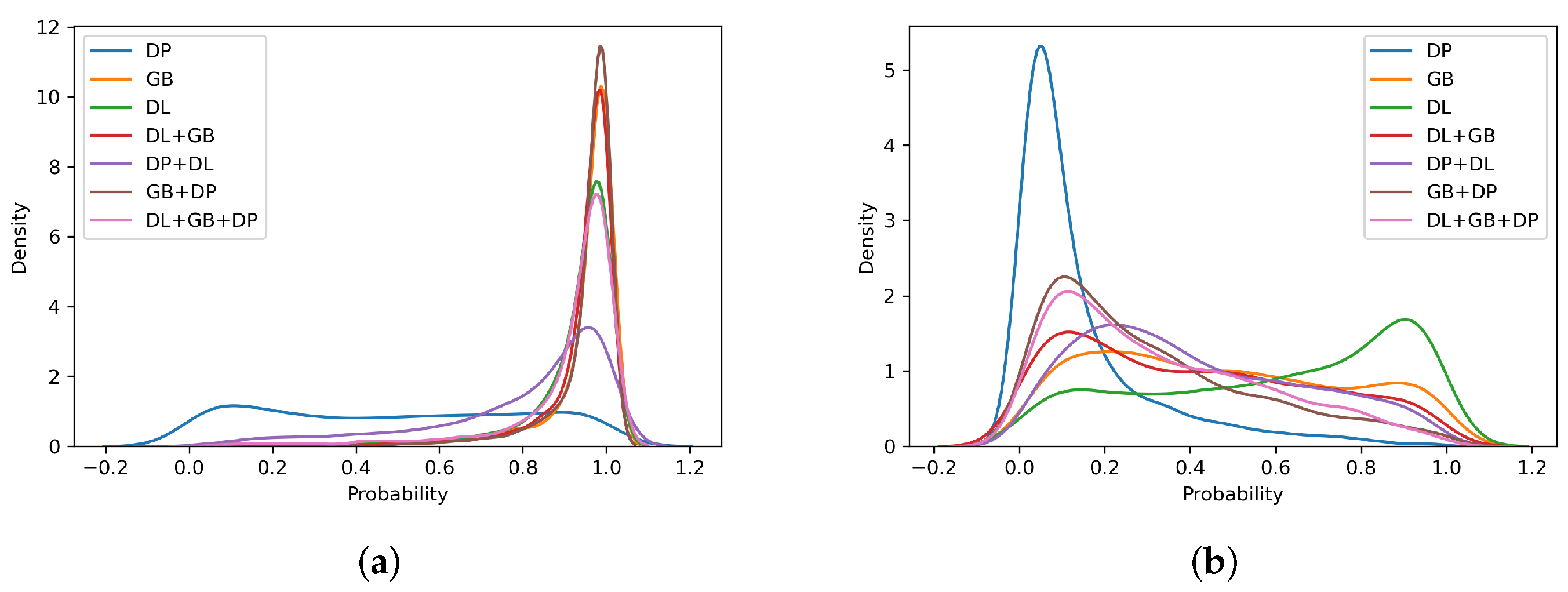
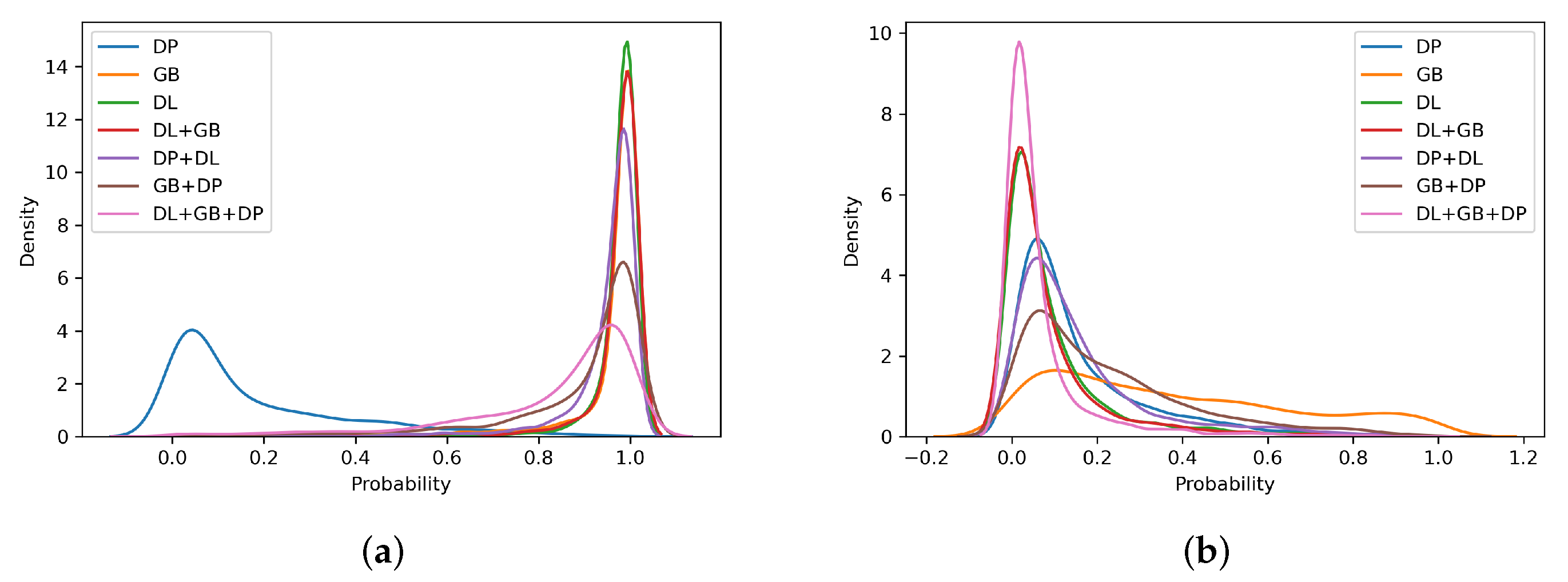
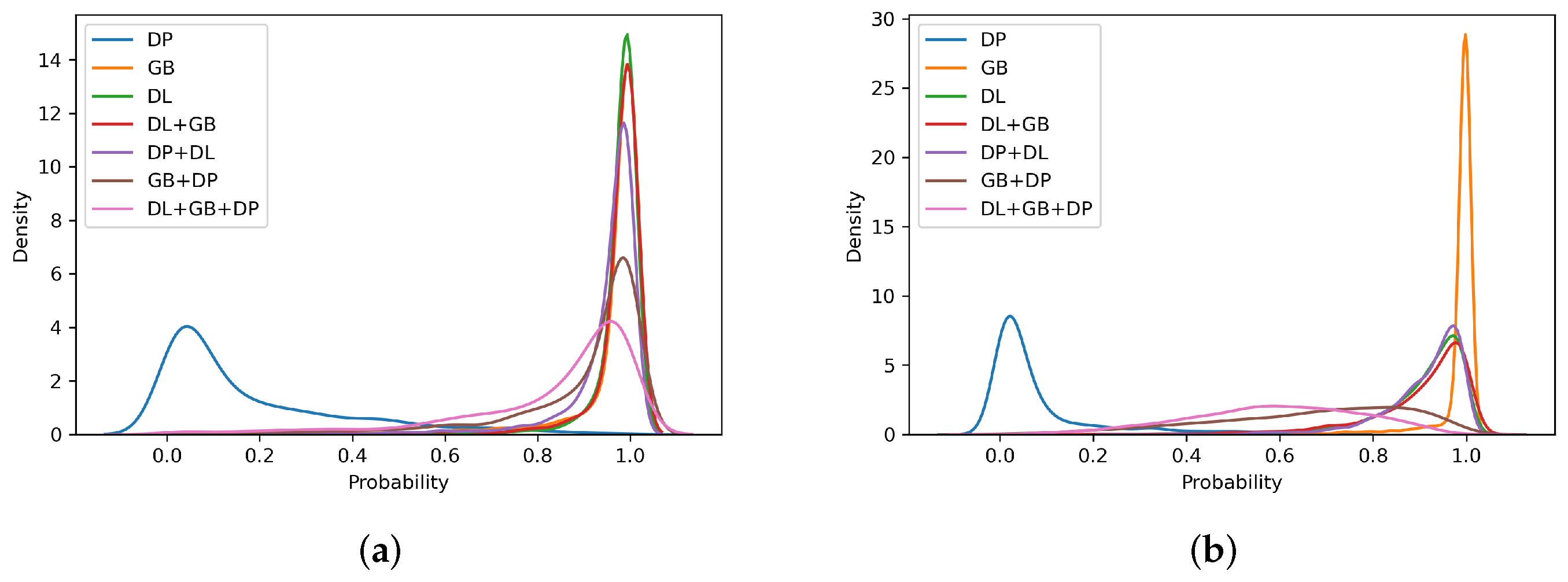
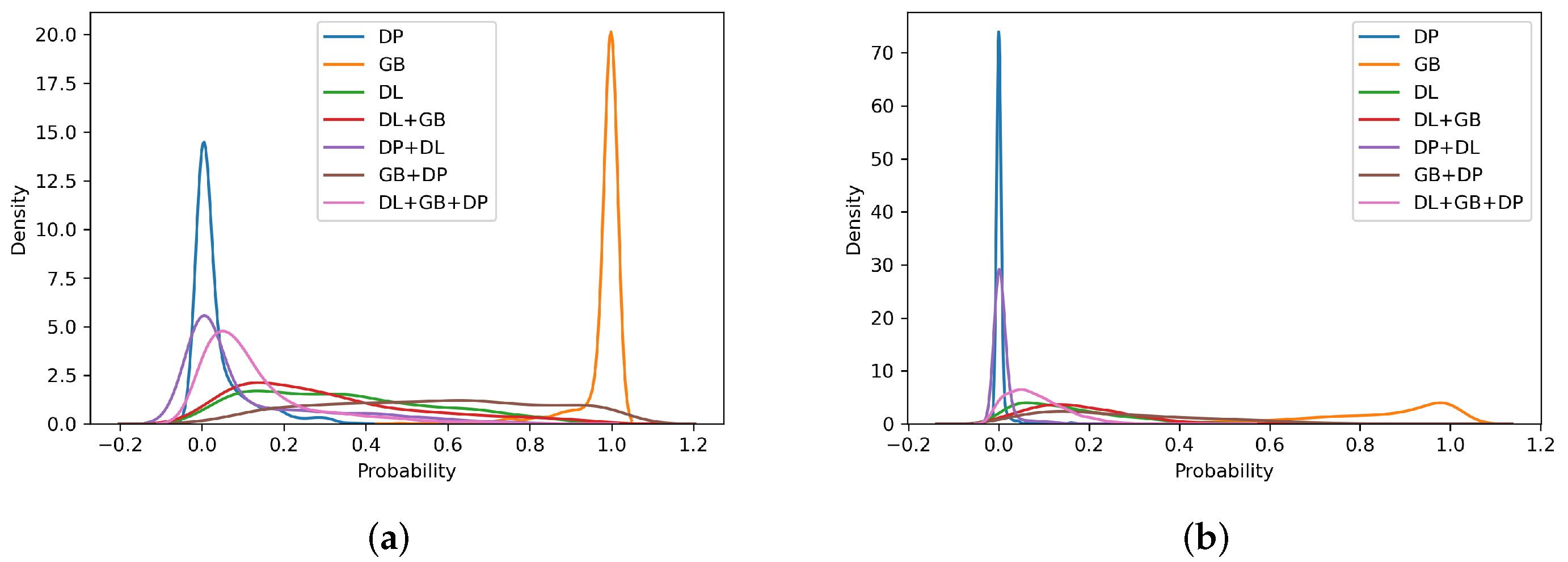
4.3. Self-Trained Analysis
5. Discussion and Conclusions
- For intra-method and intra-sensor experiments, training on the target sensor is preferable; however, training on multiple sensors does not significantly worsen the results;
- For cross-method experiments, training on different types of images allows obtaining better results for operational points relative to low APCERs. In general, using numerous data for ScreenSpoof tests at the EER is comparable to or better than the single best training;
- For the cross-sensor experiments, it is not possible to detect a benefit related to the use of training on multiple sensors. However, even single-sensor training does not result in effective PADs, showing that the interoperability problem is still open, and it is not possible to solve it without references from the target sensor. In particular, the need to use in training =the same sensing technology for data acquisition with respect to that expected during system operation was highlighted.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PAD | Presentation Attack Detection |
| FPAD | Fingerprint Presentation Attack Detection |
| SIFS | Scale Invariant Feature Transformation |
| BSIF | Binarized Statistical Image Features |
| LBP | Local Binary Pattern |
| LPQ | Local Phase Quantization |
| SVM | Support Vector Machine |
| CNN | Convolutional Neural Networks |
| APCER | Attack Presentation Classification Error Rate |
| BPCER | Bona fide Presentation Classification Error Rate |
| ROC | Receiver Operating Characteristic |
| GB | GreenBit dataset—LivDet 2021 train |
| GB CC | GreenBit consensual dataset—LivDet 2021 test |
| GB SS | GreenBit ScreenSpoof dataset—LivDet 2021 test |
| DL | Dermalog dataset—LivDet 2021 train |
| DL CC | Dermalog consensual dataset—LivDet 2021 test |
| DL SS | Dermalog ScreenSpoof dataset—LivDet 2021 test |
| BK | Biometrika dataset—LivDet 2013 test |
| OR | Orcanthus dataset—LivDet 2019 test |
| DP | DigitalPersona dataset—LivDet 2019 train |
References
- Chugh, T.; Jain, A.K. Fingerprint spoof detector generalization. IEEE Trans. Inf. Forensics Secur. 2020, 16, 42–55. [Google Scholar] [CrossRef]
- Casula, R.; Orrù, G.; Angioni, D.; Feng, X.; Marcialis, G.L.; Roli, F. Are spoofs from latent fingerprints a real threat for the best state-of-art liveness detectors? In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3412–3418. [Google Scholar]
- Sharma, D.; Selwal, A. FinPAD: State-of-the-art of fingerprint presentation attack detection mechanisms, taxonomy and future perspectives. Pattern Recognit. Lett. 2021, 152, 225–252. [Google Scholar] [CrossRef]
- Willis, D.; Lee, M. Six Biometric Devices Point the Finger at Security. Netw. Comput. 1998, 9, 84–96. [Google Scholar]
- Kallo, P.; Kiss, I.; Podmaniczky, A.; Losi, J. Detector for Recognizing the Living Character of a Finger in a Fingerprint Recognizing Apparatus. U.S. Patent 6,175,641, 16 January 2001. [Google Scholar]
- Schuckers, S.A.C. Spoofing and anti-spoofing measures. Inf. Secur. Tech. Rep. 2002, 7, 56–62. [Google Scholar] [CrossRef]
- Ghiani, L.; Hadid, A.; Marcialis, G.L.; Roli, F. Fingerprint liveness detection using binarized statistical image features. In Proceedings of the 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 29 September–2 October 2013; pp. 1–6. [Google Scholar]
- Gragnaniello, D.; Poggi, G.; Sansone, C.; Verdoliva, L. Fingerprint liveness detection based on weber local image descriptor. In Proceedings of the 2013 IEEE Workshop on Biometric Measurements and Systems for Security and Medical Applications, Napoli, Italy, 9 September 2013; pp. 46–50. [Google Scholar]
- Rattani, A.; Scheirer, W.J.; Ross, A. Open Set Fingerprint Spoof Detection Across Novel Fabrication Materials. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2447–2460. [Google Scholar] [CrossRef]
- Grosz, S.A.; Chugh, T.; Jain, A.K. Fingerprint presentation attack detection: A sensor and material agnostic approach. In Proceedings of the 2020 IEEE International Joint Conference on Biometrics (IJCB), Houston, TX, USA, 28 September–1 October 2020; pp. 1–10. [Google Scholar]
- Chugh, T.; Cao, K.; Jain, A.K. Fingerprint spoof buster: Use of minutiae-centered patches. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2190–2202. [Google Scholar] [CrossRef]
- Lugini, L.; Marasco, E.; Cukic, B.; Gashi, I. Interoperability in fingerprint recognition: A large-scale empirical study. In Proceedings of the 2013 43rd Annual IEEE/IFIP Conference on Dependable Systems and Networks Workshop (DSN-W), Budapest, Hungary, 24–27 June 2013; pp. 1–6. [Google Scholar]
- Alshehri, H.; Hussain, M.; Aboalsamh, H.A.; Emad-Ul-Haq, Q.; AlZuair, M.; Azmi, A.M. Alignment-free cross-sensor fingerprint matching based on the co-occurrence of ridge orientations and Gabor-HoG descriptor. IEEE Access 2019, 7, 86436–86452. [Google Scholar] [CrossRef]
- Marasco, E.; Sansone, C. On the Robustness of Fingerprint Liveness Detection Algorithms against New Materials used for Spoofing. Biosignals 2011, 8, 553–555. [Google Scholar]
- Gajawada, R.; Popli, A.; Chugh, T.; Namboodiri, A.; Jain, A.K. Universal material translator: Towards spoof fingerprint generalization. In Proceedings of the 2019 International Conference on Biometrics (ICB), Crete, Greece, 4–7 June 2019; pp. 1–8. [Google Scholar]
- Tuveri, P.; Ghiani, L.; Zurutuza, M.; Mura, V.; Marcialis, G.L. Interoperability among capture devices for fingerprint presentation attacks detection. In Handbook of Biometric Anti-Spoofing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 71–108. [Google Scholar]
- ISO/IEC 30107-3:2017(en). Information Technology-Biometric Presentation Attack Detection-Part 3: Testing and Reporting. 2017. Available online: https://www.iso.org/obp/ui/#iso:std:iso-iec:30107:-3:ed-1:v1:en (accessed on 19 September 2022).
- Micheletto, M.; Orrù, G.; Casula, R.; Yambay, D.; Marcialis, G.L.; Schuckers, S.C. Review of the Fingerprint Liveness Detection (LivDet) competition series: From 2009 to 2021. arXiv 2022, arXiv:2202.07259. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Participant | Algorithm Name | Type | Acronym |
|---|---|---|---|
| Dermalog | LivDet21ColC2 | Deep-learning | Col |
| LivDet21DobC2 | Deep-learning | Dob | |
| Unesp | contreras | Hand-crafted | con |
| Hangzhou Jinglianwen Tech. Co., Ltd. | JLWLivDetL | Hybrid | JLW |
| MEGVII (BEIJING) Technology Co., Ltd. | megvii_single | Deep-learning | m_s |
| megvii_ensemble | Deep-learning | m_e | |
| University of Applied Sciences Darmstadt | PADUnk | Hand-crafted | PAD |
| Chosun University | B_ld2 | Deep-learning | bld |
| Anonymous | bb8 | Hybrid | bb8 |
| r2d2 | Hybrid | r2d2 |
| Scanner | Model | Resolution [dpi] | Image Size [px] | Format | Type |
|---|---|---|---|---|---|
| Biometrika | FX2000 | 569 | 315x372 | PNG | Optical |
| Orcanthus | Certis2 Image | 500 | 300xN | PNG | Thermal swipe |
| DigitalPersona | U.are.U 5160 | 500 | 252x324 | PNG | Optical |
| GreenBit | DactyScan84C | 500 | 500x500 | BMP | Optical |
| Dermalog | LF10 | 500 | 500x500 | PNG | Optical |
| Training Sets | Live | Latex | RProFast | WoodGlue | Ecoflex | Gelatine |
|---|---|---|---|---|---|---|
| LivDet 2021 GreenBit Training | 1250 | 750 | 750 | - | - | - |
| LivDet 2021 Dermalog Training | 1250 | 750 | 750 | - | - | - |
| LivDet 2019 DigitalPersona Training | 1000 | 250 | - | 250 | 250 | 250 |
| Dataset | Test Set | |||||
|---|---|---|---|---|---|---|
| LivDet 2021 GreenBit CC/SS | Live | Mix1 | BodyDouble | ElmersGlue | ||
| 2050 | 820 | 820 | 820 | |||
| LivDet 2021 Dermalog CC/SS | Live | GLS20 | RFast30 | |||
| 2050 | 1230 | 1230 | ||||
| LivDet 2019 Orchantus | Live | Mix1 | Mix2 | Liquid Ecoflex | ||
| 990 | 384 | 308 | 396 | |||
| LivDet 2013 Biometrika | Live | Ecoflex | Gelatine | Latex | Modasil | WoodGlue |
| 1000 | 200 | 200 | 200 | 200 | 200 | |
| Alg. | Trained on GB and Tested on GB CC | Trained on DL and Tested on GB CC | Trained on GB and Tested on GB SS | Trained on DL and Tested on GB SS | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BPCER [%] | APCER [%] | Liv. Acc. [%] | BPCER [%] | APCER [%] | Liv. Acc. [%] | BPCER [%] | APCER [%] | Liv. Acc. [%] | BPCER [%] | APCER [%] | Liv. Acc. [%] | |
| Col (**) | 0.20 | 29.88 | 83.61 | 0.24 | 23.78 | 86.92 | 0.20 | 24.76 | 86.41 | 0.24 | 21.38 | 88.23 |
| Dob (**) | 0.59 | 25.41 | 85.88 | 0.44 | 29.84 | 83.53 | 0.59 | 3.25 | 97.96 | 0.44 | 4.72 | 97.23 |
| con | 8.98 | 3.94 | 93.77 | 1.85 | 80.69 | 55.14 | 8.98 | 26.67 | 81.37 | 1.85 | 94.55 | 47.58 |
| JLW | 2.59 | 8.21 | 94.35 | 0.20 | 87.76 | 52.04 | 2.59 | 54.11 | 69.31 | 0.20 | 79.76 | 56.41 |
| m_s (*) | 0.29 | 6.30 | 96.43 | 0.29 | 6.30 | 96.43 | 0.29 | 13.94 | 92.26 | 0.29 | 13.95 | 92.26 |
| m_e (*) | 0.05 | 2.72 | 98.49 | 0.05 | 2.72 | 98.49 | 0.05 | 13.62 | 92.55 | 0.05 | 13.62 | 92.55 |
| PAD (*) | 1.46 | 37.20 | 79.05 | 1.46 | 37.20 | 79.05 | 1.46 | 18.42 | 89.29 | 1.46 | 18.42 | 89.29 |
| Bld | 3.61 | 5.37 | 95.43 | 6.49 | 86.18 | 50.04 | 3.61 | 27.56 | 83.32 | 6.49 | 89.47 | 48.25 |
| bb8 | 3.46 | 7.85 | 94.15 | 2.29 | 98.25 | 45.37 | 3.46 | 39.8 | 76.72 | 2.29 | 91.54 | 49.02 |
| r2d2 | 2.20 | 12.36 | 92.26 | 1.66 | 96.34 | 46.70 | 2.20 | 57.93 | 67.06 | 1.66 | 89.02 | 50.69 |
| Alg. | Trained on DL and Tested on DL CC | Trained on GB and Tested on DL CC | Trained on DL and Tested on DL SS | Trained on GB and Tested on DL SS | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BPCER [%] | APCER [%] | Liv. Acc. [%] | BPCER [%] | APCER [%] | Liv. Acc. [%] | BPCER [%] | APCER [%] | Liv. Acc. [%] | BPCER [%] | APCER [%] | Liv. Acc. [%] | |
| Col (**) | 1.61 | 26.71 | 99.18 | 1.51 | 0.29 | 99.16 | 1.61 | 58.86 | 67.16 | 1.51 | 61.5 | 65.76 |
| Dob (**) | 1.07 | 0.16 | 99.37 | 1.27 | 0.20 | 99.31 | 1.07 | 31.34 | 82.41 | 1.27 | 26.59 | 84.92 |
| con | 5.27 | 0.28 | 93.46 | 36.44 | 0.16 | 83.35 | 5.27 | 73.94 | 57.27 | 36.44 | 45.50 | 58.07 |
| JLW | 0.68 | 30.65 | 98.16 | 5.51 | 25.08 | 83.81 | 0.68 | 95.12 | 45.41 | 5.51 | 99.92 | 43.00 |
| m_s (*) | 0.83 | 2.80 | 99.20 | 0.83 | 0.77 | 99.20 | 0.83 | 29.07 | 83.77 | 0.83 | 29.07 | 83.77 |
| m_e (*) | 0.24 | 0.77 | 99.87 | 0.24 | 0.04 | 99.87 | 0.24 | 28.66 | 84.26 | 0.24 | 28.66 | 84.26 |
| PAD (*) | 2.68 | 13.13 | 96.16 | 2.68 | 4.80 | 96.16 | 2.68 | 24.72 | 85.30 | 2.68 | 24.72 | 85.30 |
| Bld | 2.59 | 4.80 | 94.28 | 5.85 | 0.37 | 97.14 | 2.59 | 77.97 | 56.30 | 5.85 | 22.03 | 85.32 |
| bb8 | 2.39 | 8.33 | 96.58 | 3.61 | 49.59 | 71.31 | 2.39 | 69.51 | 46.03 | 3.61 | 99.88 | 43.88 |
| r2d2 | 1.27 | 4.27 | 98.03 | 0.73 | 68.29 | 62.42 | 1.27 | 82.11 | 45.85 | 0.73 | 100.00 | 45.12 |
| Alg. | Trained on GB and Tested on BK 2013 | Trained on DL and Tested on BK 2013 | Trained on GB and Tested on OR 2019 | Trained on DL and Tested on OR 2019 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BPCER [%] | APCER [%] | Liv. Acc. [%] | BPCER [%] | APCER [%] | Liv. Acc. [%] | BPCER [%] | APCER [%] | Liv. Acc. [%] | BPCER [%] | APCER [%] | Liv. Acc. [%] | |
| con | 16.30 | 5.70 | 89.00 | 0.00 | 100.00 | 50.00 | 98.18 | 22.89 | 41.24 | 83.23 | 62.87 | 27.43 |
| JLW | 70.40 | 4.40 | 62.60 | 52.90 | 2.20 | 72.45 | 89.80 | 22.61 | 45.38 | 74.85 | 65.81 | 29.88 |
| m_s | 0.30 | 11.10 | 94.30 | 0.30 | 11.10 | 94.30 | 93.54 | 0.46 | 55.20 | 93.54 | 0.46 | 55.20 |
| m_e | 0.30 | 0.20 | 99.75 | 0.30 | 0.20 | 99.75 | 97.27 | 0.37 | 53.46 | 97.27 | 0.37 | 53.46 |
| PAD (*) | 0.00 | 92.40 | 53.80 | 0.00 | 92.40 | 53.80 | 53.64 | 39.34 | 53.85 | 53.64 | 39.34 | 53.85 |
| Bld | 18.17 | 34.00 | 73.65 | 16.10 | 97.70 | 43.10 | 99.80 | 0 | 52.45 | 81.21 | 10.02 | 56.06 |
| Scanner | DL CC | DL SS | GB CC | GB SS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BPCER | APCER | Accuracy | BPCER | APCER | Accuracy | BPCER | APCER | Accuracy | BPCER | APCER | Accuracy | ||
| BSIF | DL | 4.93 | 11.02 | 91.75 | 4.93 | 55.85 | 67.29 | 3.56 | 47.11 | 72.68 | 3.56 | 58.25 | 66.61 |
| DP | 42.63 | 20.89 | 69.22 | 42.63 | 4.76 | 78.03 | 19.56 | 87.36 | 43.46 | 19.56 | 38.25 | 70.24 | |
| GB | 8.49 | 14.31 | 88.34 | 8.49 | 86.50 | 48.96 | 4.49 | 18.98 | 87.61 | 4.49 | 52.64 | 69.25 | |
| DL+GB | 4.83 | 10.00 | 92.35 | 4.83 | 73.05 | 57.96 | 5.46 | 17.68 | 87.87 | 5.46 | 30.41 | 80.93 | |
| DL+DP | 5.66 | 9.96 | 92.00 | 5.66 | 45.77 | 72.46 | 2.39 | 75.16 | 57.92 | 2.39 | 46.95 | 73.30 | |
| DP+GB | 9.76 | 15.57 | 87.07 | 9.76 | 42.64 | 72.31 | 7.07 | 9.35 | 91.69 | 7.07 | 18.41 | 86.74 | |
| DL+GB+DP | 4.39 | 13.21 | 90.80 | 4.39 | 66.22 | 61.88 | 5.17 | 11.34 | 91.46 | 5.17 | 24.47 | 84.30 | |
| LBP | DL | 5.80 | 14.15 | 89.65 | 5.80 | 76.26 | 55.76 | 37.02 | 43.17 | 59.62 | 37.02 | 44.59 | 58.85 |
| DP | 84.93 | 1.10 | 60.80 | 84.93 | 0.04 | 61.37 | 49.17 | 86.87 | 30.27 | 49.17 | 38.13 | 56.85 | |
| GB | 24.83 | 16.59 | 79.67 | 24.83 | 92.03 | 38.51 | 8.59 | 23.90 | 83.06 | 8.59 | 56.54 | 65.25 | |
| DL+GB | 6.73 | 24.02 | 83.84 | 6.73 | 96.30 | 44.41 | 12.63 | 28.09 | 78.94 | 12.63 | 64.47 | 59.09 | |
| DL+DP | 11.27 | 16.50 | 85.88 | 11.27 | 32.64 | 77.07 | 15.95 | 78.29 | 50.04 | 15.95 | 60.61 | 59.69 | |
| DP+GB | 37.56 | 7.97 | 78.58 | 37.56 | 26.67 | 68.38 | 10.68 | 31.59 | 77.92 | 10.68 | 31.10 | 78.18 | |
| DL+GB+DP | 11.02 | 17.32 | 85.54 | 11.02 | 65.53 | 59.25 | 15.51 | 32.64 | 75.14 | 15.51 | 45.20 | 68.29 | |
| SpoofBuster | DL | 1.22 | 2.60 | 98.03 | 1.22 | 99.23 | 45.32 | 1.71 | 30.57 | 82.55 | 2.83 | 63.37 | 64.15 |
| DP | 90.49 | 4.76 | 56.27 | 90.49 | 2.64 | 57.42 | 48.24 | 11.67 | 71.71 | 51.12 | 5.89 | 73.55 | |
| GB | 1.36 | 32.15 | 81.84 | 1.37 | 99.80 | 44.94 | 2.34 | 4.71 | 96.36 | 2.14 | 43.82 | 75.12 | |
| DL+GB | 1.37 | 2.89 | 97.80 | 1.37 | 98.54 | 45.63 | 1.27 | 5.45 | 96.45 | 1.41 | 36.91 | 79.22 | |
| DL+DP | 1.02 | 6.54 | 95.96 | 1.02 | 99.88 | 45.05 | 8.93 | 31.50 | 78.76 | 12.54 | 34.39 | 75.54 | |
| DP+GB | 4.24 | 10.61 | 92.28 | 4.24 | 77.80 | 55.63 | 1.12 | 6.91 | 95.72 | 1.12 | 21.50 | 87.76 | |
| DL+GB+DP | 8.00 | 1.95 | 95.30 | 8.00 | 69.67 | 58.36 | 4.05 | 12.52 | 91.33 | 4.10 | 25.45 | 84.26 | |
| Scanner | BK 2013 | OR 2019 | |||||
|---|---|---|---|---|---|---|---|
| BPCER | APCER | Accuracy | BPCER | APCER | Accuracy | ||
| BSIF | DL | 71.80 | 0.10 | 64.05 | 99.90 | 0.00 | 52.41 |
| DP | 98.00 | 0.00 | 51.00 | 99.90 | 0.00 | 52.41 | |
| GB | 3.10 | 98.20 | 49.35 | 96.67 | 4.41 | 51.64 | |
| DL+GB | 33.00 | 3.20 | 81.90 | 99.70 | 0.00 | 52.50 | |
| DL+DP | 49.30 | 1.30 | 74.70 | 100.00 | 0.00 | 52.36 | |
| DP+GB | 7.30 | 72.30 | 60.20 | 99.29 | 0.00 | 52.69 | |
| DL+GB+DP | 0.50 | 92.70 | 53.40 | 99.90 | 0.00 | 52.41 | |
| LBP | DL | 0.00 | 95.00 | 52.50 | 96.57 | 2.11 | 52.89 |
| DP | 92.50 | 0.70 | 53.40 | 99.80 | 0.00 | 52.45 | |
| GB | 30.50 | 34.10 | 67.70 | 99.09 | 1.19 | 52.17 | |
| DL+GB | 0.00 | 96.30 | 51.85 | 89.49 | 29.50 | 41.92 | |
| DL+DP | 0.00 | 99.60 | 50.20 | 91.41 | 8.36 | 52.07 | |
| DP+GB | 43.20 | 31.50 | 62.65 | 100.00 | 0.00 | 52.36 | |
| DL+GB+DP | 0.30 | 89.00 | 55.35 | 95.25 | 5.24 | 51.88 | |
| SpoofBuster | DL | 74.50 | 1.10 | 62.20 | 83.23 | 18.84 | 50.48 |
| DP | 99.70 | 0.00 | 50.15 | 93.93 | 0.37 | 55.05 | |
| GB | 0.20 | 96.70 | 51.55 | 80.60 | 20.86 | 50.67 | |
| DL+GB | 80.60 | 1.50 | 58.95 | 94.14 | 2.48 | 53.85 | |
| DL+DP | 94.00 | 0.00 | 53.00 | 99.80 | 0.28 | 52.31 | |
| DP+GB | 42.20 | 13.50 | 72.15 | 93.84 | 0.46 | 55.05 | |
| DL+GB+DP | 96.70 | 0.10 | 51.60 | 98.38 | 0.18 | 53.03 | |
| Scanner | DL CC | DL SS | GB CC | GB SS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| APCER (%)@ BPCER = 5% | BPCER (%)@ APCER = 5% | EER | APCER (%)@ BPCER = 5% | BPCER (%)@ APCER = 5% | EER | APCER (%)@ BPCER = 5% | BPCER (%)@ APCER = 5% | EER | APCER (%)@ BPCER = 5% | BPCER (%)@ APCER = 5% | EER | ||
| BSIF | DL | 100.00 | 17.07 | 6.32 | 100.00 | 100.00 | 17.40 | 75.49 | 100.00 | 15.16 | 83.82 | 100.00 | 16.34 |
| DP | 100.00 | 72.00 | 35.18 | 100.00 | 62.39 | 20.78 | 100.00 | 100.00 | 53.42 | 100.00 | 100.00 | 28.83 | |
| GB | 100.00 | 100.00 | 11.00 | 100.00 | 100.00 | 50.42 | 57.85 | 14.05 | 6.57 | 80.28 | 100.00 | 16.28 | |
| DL+GB | 100.00 | 18.63 | 6.48 | 100.00 | 100.00 | 27.79 | 60.89 | 17.32 | 8.03 | 70.24 | 100.00 | 11.93 | |
| DL+DP | 65.24 | 23.27 | 6.92 | 86.71 | 100.00 | 19.28 | 88.86 | 100.00 | 25.88 | 61.46 | 100.00 | 14.19 | |
| DP+GB | 100.00 | 48.39 | 11.41 | 100.00 | 100.00 | 17.85 | 72.76 | 17.66 | 7.87 | 74.27 | 24.63 | 9.96 | |
| DL+GB+DP | 62.97 | 21.95 | 6.67 | 96.14 | 100.00 | 17.81 | 60.20 | 15.37 | 6.79 | 68.01 | 29.90 | 10.84 | |
| LBP | DL | 61.67 | 23.22 | 9.04 | 94.27 | 100.00 | 32.00 | 100.00 | 100.00 | 38.78 | 100.00 | 100.00 | 39.83 |
| DP | 100.00 | 85.27 | 42.80 | 100.00 | 80.68 | 40.61 | 100.00 | 100.00 | 67.33 | 100.00 | 100.00 | 44.29 | |
| GB | 100.00 | 60.20 | 21.73 | 100.00 | 100.00 | 58.45 | 100.00 | 100.00 | 13.73 | 100.00 | 100.00 | 23.01 | |
| DL+GB | 100.00 | 40.05 | 12.27 | 100.00 | 100.00 | 48.85 | 100.00 | 100.00 | 16.63 | 100.00 | 100.00 | 29.11 | |
| DL+DP | 81.22 | 37.66 | 12.63 | 86.38 | 100.00 | 18.66 | 100.00 | 100.00 | 35.97 | 100.00 | 100.00 | 33.59 | |
| DP+GB | 100.00 | 61.85 | 25.95 | 100.00 | 100.00 | 31.79 | 76.10 | 100.00 | 17.83 | 70.69 | 100.00 | 18.11 | |
| DL+GB+DP | 100.00 | 44.73 | 12.98 | 100.00 | 100.00 | 30.11 | 100.00 | 100.00 | 20.07 | 100.00 | 100.00 | 24.79 | |
| SpoofBuster | DL | 3.98 | 2.20 | 1.78 | 99.51 | 100.00 | 24.22 | 41.26 | 100.00 | 9.43 | 86.99 | 77.80 | 21.46 |
| DP | 100.00 | 96.34 | 51.09 | 100.00 | 93.27 | 35.58 | 97.20 | 100.00 | 29.57 | 100.00 | 76.83 | 24.50 | |
| GB | 36.79 | 33.95 | 8.75 | 99.92 | 100.00 | 58.74 | 9.88 | 100.00 | 3.55 | 62.64 | 60.49 | 12.39 | |
| DL+GB | 5.69 | 3.56 | 1.95 | 99.51 | 100.00 | 26.35 | 6.14 | 100.00 | 3.40 | 43.09 | 57.12 | 9.81 | |
| DL+DP | 6.54 | 5.80 | 2.80 | 99.88 | 100.00 | 34.83 | 84.51 | 100.00 | 16.87 | 87.89 | 73.12 | 21.10 | |
| DP+GB | 33.25 | 22.88 | 6.71 | 95.20 | 56.29 | 22.66 | 7.20 | 100.00 | 3.57 | 28.01 | 38.24 | 6.21 | |
| DL+GB+DP | 24.27 | 12.49 | 4.38 | 99.80 | 53.32 | 22.25 | 43.70 | 100.00 | 7.51 | 62.64 | 35.80 | 9.09 | |
| Scanner | BK 2013 | OR 2019 | |||||
|---|---|---|---|---|---|---|---|
| APCER (%)@ BPCER = 5% | BPCER (%)@ APCER = 5% | EER | APCER (%)@ BPCER = 5% | BPCER (%)@ APCER = 5% | EER | ||
| BSIF | DL | 100.00 | 62.50 | 31.50 | 100.00 | 99.49 | 49.84 |
| DP | 100.00 | 93.00 | 46.50 | 100.00 | 99.60 | 49.80 | |
| GB | 99.30 | 100.00 | 50.45 | 100.00 | 98.59 | 51.27 | |
| DL+GB | 100.00 | 45.40 | 18.40 | 100.00 | 98.89 | 49.49 | |
| DL+DP | 100.00 | 53.10 | 20.70 | 100.00 | 100.00 | 50.00 | |
| DP+GB | 100.00 | 100.00 | 28.60 | 100.00 | 97.98 | 48.99 | |
| DL+GB+DP | 89.70 | 100.00 | 38.65 | 100.00 | 96.36 | 48.18 | |
| LBP | DL | 90.80 | 100.00 | 45.55 | 100.00 | 97.68 | 51.83 |
| DP | 100.00 | 91.90 | 45.90 | 100.00 | 99.80 | 49.90 | |
| GB | 100.00 | 100.00 | 32.95 | 100.00 | 99.49 | 54.36 | |
| DL+GB | 100.00 | 100.00 | 46.30 | 100.00 | 100.00 | 67.99 | |
| DL+DP | 100.00 | 100.00 | 49.50 | 100.00 | 97.78 | 54.94 | |
| DP+GB | 100.00 | 100.00 | 35.25 | 100.00 | 97.07 | 49.09 | |
| DL+GB+DP | 85.20 | 100.00 | 42.45 | 100.00 | 98.99 | 59.95 | |
| SpoofBuster | DL | 95.20 | 75.50 | 31.15 | 100.00 | 97.58 | 50.18 |
| DP | 100.00 | 87.20 | 32.25 | 100.00 | 91.41 | 28.26 | |
| GB | 87.60 | 100.00 | 21.65 | 98.90 | 99.70 | 51.09 | |
| DL+GB | 100.00 | 84.50 | 39.55 | 100.00 | 97.17 | 42.72 | |
| DL+DP | 100.00 | 79.60 | 37.45 | 100.00 | 99.60 | 49.01 | |
| DP+GB | 92.70 | 74.70 | 28.05 | 94.03 | 88.69 | 32.62 | |
| DL+GB+DP | 100.00 | 87.30 | 46.60 | 100.00 | 94.65 | 47.65 | |
| Scenario | Property | Multi-Sensor Training Pros | Multi-Sensor Training Cons | |
|---|---|---|---|---|
| Intra-sensor and intra-method |
| - |
| |
| Intra-sensor and cross-method |
|
| - | |
| Cross-sensor and intra-method | Intra-sensing |
|
|
|
| Cross-sensing |
| - |
| |
| Cross-sensor and cross-method | Intra-sensing |
|
| - |
| Cross-sensing |
| Not evaluated. | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Micheletto, M.; Orrù, G.; Casula, R.; Marcialis, G.L. Mitigating Sensor and Acquisition Method-Dependence of Fingerprint Presentation Attack Detection Systems by Exploiting Data from Multiple Devices. Appl. Sci. 2022, 12, 9941. https://doi.org/10.3390/app12199941
Micheletto M, Orrù G, Casula R, Marcialis GL. Mitigating Sensor and Acquisition Method-Dependence of Fingerprint Presentation Attack Detection Systems by Exploiting Data from Multiple Devices. Applied Sciences. 2022; 12(19):9941. https://doi.org/10.3390/app12199941
Chicago/Turabian StyleMicheletto, Marco, Giulia Orrù, Roberto Casula, and Gian Luca Marcialis. 2022. "Mitigating Sensor and Acquisition Method-Dependence of Fingerprint Presentation Attack Detection Systems by Exploiting Data from Multiple Devices" Applied Sciences 12, no. 19: 9941. https://doi.org/10.3390/app12199941
APA StyleMicheletto, M., Orrù, G., Casula, R., & Marcialis, G. L. (2022). Mitigating Sensor and Acquisition Method-Dependence of Fingerprint Presentation Attack Detection Systems by Exploiting Data from Multiple Devices. Applied Sciences, 12(19), 9941. https://doi.org/10.3390/app12199941