
MSSA: Constant Time State Search through Multi-Scope State Area

Abstract
:1. Introduction
- We propose the multi-scope state area (MSSA) that stores state in a hierarchical tree structure. MSSA is associated with the switch’s multilevel match–action table structure to split the scope of state sharing packets and reuse state storage space in time. Based on the scope of state sharing, we categorize the state into four types, namely global state, table state, flow state, and packet state, and stores them in different state areas.
- In the MSSA, we also propose the state search and state programming methods. The state search method, according to the state-sharing scope, reduces the state required in packet processing to a limited range, enabling constant-time state search. State programming is accomplished by reusing the switch’s existing functions (match–action table and instructions), thus reducing expansion costs and improving compatibility.
- We built a packet forwarding pipeline that supports MSSA. Moreover, in the MSSA’s state search/insertion time, we evaluated two state-comparison methods and state store-space utilization.
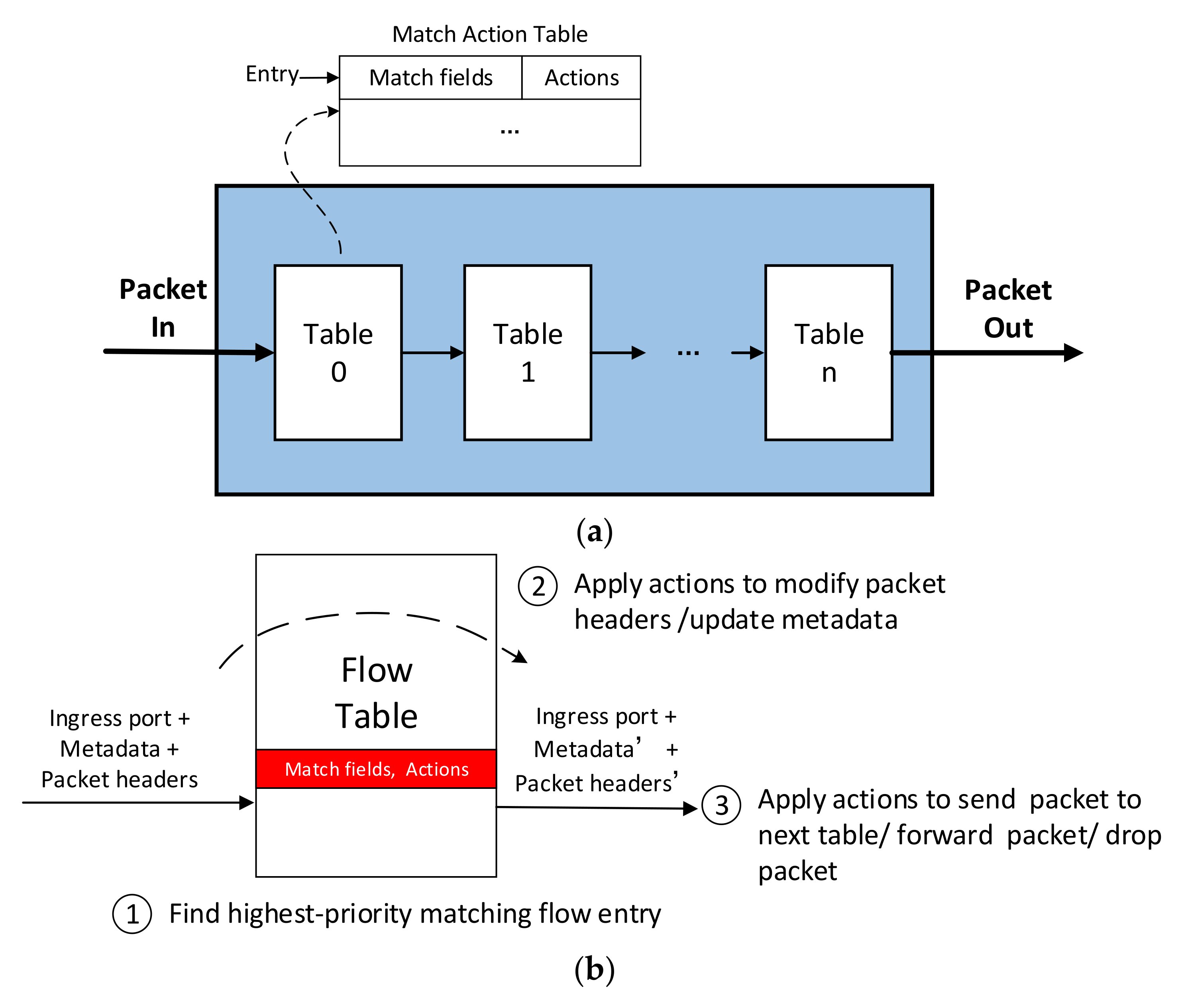
2. Match–Action Model
- (1)
- The state storage structure affects storage space utilization and search speed.
- (2)
- Multi-flow state sharing.
- (3)
- State programming.
3. Multi-Scope State Area (MSSA)
3.1. MSSA Structure
- (1)
- Fine-grained division states.
- (2)
- Any kind of state sharing.
- (3)
- Rapid state space recovery and reuse
3.2. State Lookup
| Algorithm 1. Look up the state |
| Input: state s = {type,name}, global state areas gsa, packet enters table’s state area tsa, packet matches entry’s flow state area fsa, packet state area psa Output: state value 1. If == packet state: 2. Find the state value according to in 3. If s. type == flow state: 4. Find the state value according to s.name in fsa 5. If s. type == table state: 6. Find the state value according to s.name in tsa 7. If s. type == global state: 8. Find the state value according to s.name in gsa 9. Return state value |
3.3. State Programming
3.3.1. State Storage and Update
3.3.2. State-Based Packet Processing
4. Implementation and Evaluation
4.1. Implementation
4.2. Evaluation
4.2.1. State Search and Insertion Time
- (1)
- Number of states
- (2)
- Type of state
- (3)
- Offset of state
- (4)
- Length of state
4.2.2. State Search and Insertion Time
4.2.3. State Search and Insertion Time
- (1)
- There is a fixed space overhead in MSSA. Even if no states are needed to be recorded, the global state area, the table state area, and the flow state area all take up space, and there is some space waste if only a few states are recorded.
- (2)
- MSSA consumes space linearly, with each additional flow increasing the flow state area space. This results in a lot of wasted space because not all flows need to keep states. It is possible to solve this issue by adding configuration to the southbound interface, specifying the size of each table’s table state area and flow state area.
- (3)
- When the flow state area size is 8 bytes, MSSA storing more than 1000 flow states takes up much less space than the hash table. When the flow-state area size is 64 bytes, the MSSA takes up almost the same amount of space as the hash table. The 64 bytes of available space far exceeds the needs of most stateful applications for storing some count values or signs. Furthermore, because MSSA does not require extra space to avoid conflicts, it can use all of the available space to record the state, resulting in a higher space utilization rate than the hash table.
5. Related Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Katabi, D.; Handley, M.; Rohrs, C. Congestion control for high bandwidth-delay product networks. ACM SIGCOMM Comput. Commun. Rev. 2002, 32, 89–102. [Google Scholar] [CrossRef]
- Tai, C.-H.; Zhu, J.; Dukkipati, N. Making large scale deployment of RCP practical for real networks. In Proceedings of the IEEE INFOCOM 2008—The 27th Conference on Computer Communications, Phoenix, AZ, USA, 13–18 April 2008; pp. 2180–2188. [Google Scholar]
- Hong, C.-Y.; Caesar, M.; Godfrey, P.B. Finishing flows quickly with preemptive scheduling. ACM SIGCOMM Comput. Commun. Rev. 2012, 42, 127–138. [Google Scholar] [CrossRef]
- Alizadeh, M.; Greenberg, A.; Maltz, D.A.; Padhye, J.; Patel, P.; Prabhakar, B.; Sengupta, S.; Sridharan, M. Data center tcp (dctcp). In Proceedings of the ACM SIGCOMM 2010 Conference, New York, NY, USA, 30 August–3 September 2010; Association for Computing Machinery: New York, NY, USA, 2010. [Google Scholar]
- Sivaraman, A.; Subramanian, S.; Agrawal, A.; Chole, S.; Chuang, S.-T.; Edsall, T.; Alizadeh, M.; Katti, S.; McKeown, N.; Balakrishnan, H. Towards programmable packet scheduling. In Proceedings of the 14th ACM Workshop on Hot Topics in Networks, Philadelphia, PA, USA, 16–17 November 2015; pp. 1–7. [Google Scholar]
- Yu, M.; Jose, L.; Miao, R. Software Defined Traffic Measurement with OpenSketch. In Proceedings of the 10th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 13), Lombard, IL, USA, 2–5 April 2013; pp. 29–42. [Google Scholar]
- Estan, C.; Varghese, G. New directions in traffic measurement and accounting: Focusing on the elephants, ignoring the mice. ACM Trans. Comput. Syst. 2003, 21, 270–313. [Google Scholar] [CrossRef]
- Estan, C.; Varghese, G.; Fisk, M. Bitmap algorithms for counting active flows on high speed links. In Proceedings of the 3rd ACM SIGCOMM Conference on Internet Measurement, Miami Beach, FL, USA, 27–29 October 2003; pp. 153–166. [Google Scholar]
- Feng, W.-C.; Shin, K.; Kandlur, D.; Saha, D. The BLUE active queue management algorithms. IEEE/ACM Trans. Netw. 2002, 10, 513–528. [Google Scholar] [CrossRef]
- Floyd, S.; Jacobson, V. Random Early Detection Gateways for Congestion Avoidance. IEEE/ACM Trans. Netw. 1993, 1, 397–413. [Google Scholar] [CrossRef]
- Kunniyur, S.; Srikant, R. An adaptive virtual queue (AVQ) algorithm for active queue management. IEEE/ACM Trans. Netw. 2004, 12, 286–299. [Google Scholar] [CrossRef]
- Nichols, K.; Jacobson, V. Controlling queue delay. Commun. ACM 2012, 55, 42–50. [Google Scholar] [CrossRef]
- Pan, R.; Natarajan, P.; Piglione, C.; Prabhu, M.S.; Subramanian, V.; Baker, F.; VerSteeg, B. PIE: A lightweight control scheme to address the bufferbloat problem. In Proceedings of the 2013 IEEE 14th International Conference on High Performance Switching and Routing (HPSR), Taipei, Taiwan, 8–11 July 2013; pp. 148–155. [Google Scholar]
- Bilge, L.; Kirda, E.; Kruegel, C.; Balduzzi, M. EXPOSURE: Finding Malicious Domains Using Passive DNS Analysis. In Proceedings of the Network and Distributed System Security Symposium, NDSS 2011, San Diego, CA, USA, 6–9 February 2011; The Internet Society: Reston, VA, USA, 2011. [Google Scholar]
- Alizadeh, M.; Edsall, T.; Dharmapurikar, S.; Vaidyanathan, R.; Chu, K.; Fingerhut, A.; Lam, V.T.; Matus, F.; Pan, R.; Yadav, N.; et al. CONGA: Distributed congestion-aware load balancing for datacenters. Comput. Commun. Rev. 2015, 44, 503–514. [Google Scholar] [CrossRef]
- Barbette, T.; Tang, C.; Yao, H.; Kostić, D.; Maguire, G.Q., Jr.; Papadimitratos, P.; Chiesa, M. A high-speed load-balancer design with guaranteed per-connection-consistency. In Proceedings of the 17th USENIX Symposium Networked Systems Design Implementation, NSDI 2020, Santa Clara, CA, USA, 25–27 February 2020; pp. 667–683. [Google Scholar]
- Miao, R.; Zeng, H.; Kim, C.; Lee, J.; Yu, M. Silkroad: Making stateful layer-4 load balancing fast and cheap using switching asics. In Proceedings of the SIGCOMM 2017 ACM Special Interest Group Data Communication, Los Angeles, CA, USA, 21–25 August 2017; pp. 15–28. [Google Scholar] [CrossRef]
- Katta, N.; Hira, M.; Kim, C.; Sivaraman, A.; Rexford, J. HULA: Scalable load balancing using programmable data planes. In Proceedings of the SOSR ′16: Symposium on SDN Research, Santa Clara, CA, USA, 14–15 March 2016. [Google Scholar] [CrossRef] [Green Version]
- Sivaraman, A.; Cheung, A.; Budiu, M.; Kim, C.; Alizadeh, M.; Balakrishnan, H.; Varghese, G.; McKeown, N.; Licking, S. Packet transactions: High-level programming for line-rate switches. In Proceedings of the SIGCOMM 2016—2016 ACM Conference of the ACM Special Interest Group on Data Communication, Florianopolis, Brazil, 22–26 August 2016; pp. 15–28. [Google Scholar] [CrossRef] [Green Version]
- Feamster, N.; Rexford, J. Why (and how) networks should run themselves. In Proceedings of the Applied Networking Research Workshop, Montreal, QC, Canada, 16 July 2018; Association for Computing Machinery: New York, NY, USA, 2018. [Google Scholar]
- Kohler, T.; Durr, F.; Rothermel, K. ZeroSDN: A Highly Flexible and Modular Architecture for Full-Range Distribution of Event-Based Network Control. IEEE Trans. Netw. Serv. Manag. 2018, 15, 1207–1221. [Google Scholar] [CrossRef]
- Dargahi, T.; Caponi, A.; Ambrosin, M.; Bianchi, G.; Conti, M. A Survey on the Security of Stateful SDN Data Planes. IEEE Commun. Surv. Tutor. 2017, 19, 1701–1725. [Google Scholar] [CrossRef]
- Zhang, X.; Cui, L.; Wei, K.; Tso, F.P.; Ji, Y.; Jia, W. A survey on stateful data plane in software defined networks. Comput. Netw. 2020, 184, 107597. [Google Scholar] [CrossRef]
- Bianchi, G.; Bonola, M.; Capone, A.; Cascone, C. Openstate: Programming platform-independent stateful openflow applications inside the switch. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 44–51. [Google Scholar] [CrossRef]
- Bianchi, G.; Bonola, M.; Pontarelli, S.; Sanvito, D.; Capone, A.; Cascone, C. Open Packet Processor: A Programmable Architecture for Wire Speed Platform-Independent Stateful in-Network Processing. 2016. Available online: http://arxiv.org/abs/1605.01977 (accessed on 19 November 2021).
- Moshref, M.; Bhargava, A.; Gupta, A.; Yu, M.; Govindan, R. Flow-level state transition as a new switch primitive for SDN. Comput. Commun. Rev. 2014, 44, 377–378. [Google Scholar] [CrossRef]
- Zhu, S.; Bi, J.; Sun, C.; Wu, C.; Hu, H. SDPA: Enhancing stateful forwarding for software-defined networking. In Proceedings of the 2015 IEEE 23rd International Conference on Network Protocols (ICNP), San Francisco, CA, USA, 10–13 November 2015; pp. 323–333. [Google Scholar] [CrossRef]
- Pontarelli, S.; Bifulco, R.; Bonola, M.; Cascone, C.; Spaziani, M.; Bruschi, V.; Huici, F. Flowblaze: Stateful packet processing in hardware. In Proceedings of the 16th USENIX Symposium Networked Systems Design Implementation, NSDI 2019, Boston, MA, USA, 26–28 February 2019; pp. 531–547. [Google Scholar]
- Alagar, V.S.; Periyasamy, K. Extended Finite State Machine. In Specification of Software Systems; Springer: London, UK, 2011; pp. 105–128. [Google Scholar] [CrossRef]
- Bosshart, P.; Daly, D.; Gibb, G.; Izzard, M.; McKeown, N.; Rexford, J.; Schlesinger, C.; Talayco, D.; Vahdat, A.; Varghese, G.; et al. P4: Programming protocol-independent packet processors. Comput. Commun. Rev. 2014, 44, 87–95. [Google Scholar] [CrossRef]
- Hopcroft, J.E.; Motwani, R.; Ullman, J.D. Introduction to automata theory, languages, and computation. ACM Sigact. News. 2001, 32, 60–65. [Google Scholar] [CrossRef]
- Pagh, R.; Rodler, F.F. Cuckoo hashing. Lect. Notes Comput. Sci. 2001, 2161, 121–133. [Google Scholar] [CrossRef]
- Németh, F.; Chiesa, M.; Rétvári, G. Normal forms for match-action programs. In Proceedings of the 15th International Conference on Emerging Networking Experiments and Technologies, Orlando, FL, USA, 9–12 December 2019; pp. 44–50. [Google Scholar]
- Jose, L.; Yan, L.; Varghese, G.; McKeown, N. Compiling packet programs to reconfigurable switches. In Proceedings of the 12th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 15), Oakland, CA, USA, 4–6 May 2015; pp. 103–115. [Google Scholar]
- OpenFlow v1.1. Open Networking Fundation. Available online: https://opennetworking.org/wp-content/uploads/2014/10/openflow-spec-v1.4.0.pdf (accessed on 4 November 2021).
- Bosshart, P.; Gibb, G.; Kim, H.-S.; Varghese, G.; McKeown, N.; Izzard, M.; Mujica, F.; Horowitz, M. Forwarding metamorphosis: Fast programmable match-action processing in hardware for SDN. Comput. Commun. Rev. 2013, 43, 99–110. [Google Scholar] [CrossRef]
- Open vSwitch. Open Networking Fundation. Available online: https://www.openvswitch.org/ (accessed on 4 November 2021).
- Molnár, L.; Pongrácz, G.; Enyedi, G.; Kis, Z.L.; Csikor, L.; Juhász, F.; Kőrösi, A.; Rétvári, G. Dataplane specialization for high-performance OpenFlow software switching. In Proceedings of the SIGCOMM 2016—2016 ACM Conference Special Interest Group on Data Communication, Florianopolis, Brazil, 22–26 August 2016; pp. 539–552. [Google Scholar] [CrossRef] [Green Version]
- “Tipsy: Telco Pipeline Benchmarking System”. Available online: https://github.com/hsnlab/tipsy (accessed on 4 November 2021).
- Barbette, T.; Soldani, C.; Mathy, L. Fast userspace packet processing. In Proceedings of the ANCS 2015—11th 2015 ACM/IEEE Symposium on Architectures for Networking and Communications Systems, Oakland, CA, USA, 7–8 May 2015; pp. 5–16. [Google Scholar] [CrossRef] [Green Version]
- Han, S.; Jang, K.; Panda, A.; Palkar, S.; Han, D.; Ratnasamy, S. SoftNIC: A Software NIC to Augment Hardware; Tech. Rep. UCB/EECS-2015-155; EECS Department, University of California: Berkeley, CA, USA, 2015. [Google Scholar]
- Panda, A.; Han, S.; Jang, K.; Walls, M.; Ratnasamy, S.; Shenker, S. NetBricks: Taking the V out of {NFV}. In Proceedings of the 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16), Savannah, GA, USA, 2–4 November 2016; pp. 203–216. [Google Scholar]
- Bifulco, R.; Retvari, G. A survey on the programmable data plane: Abstractions, architectures, and open problems. In Proceedings of the 2018 IEEE 19th International Conference on High Performance Switching and Routing (HPSR), Bucharest, Romania, 18–20 June 2018. [Google Scholar] [CrossRef]
- Hauser, F.; Häberle, M.; Merling, D.; Lindner, S.; Gurevich, V.; Zeiger, F.; Frank, R.; Menth, M. A Survey on Data Plane Programming with P4: Fundamentals, Advances, and Applied Research. 2021. Available online: http://arxiv.org/abs/2101.10632 (accessed on 19 November 2021).
- Jing, L.; Chen, X.; Wang, J. Design and Implementation of Programmable Data Plane Supporting Multiple Data Types. Electronics 2021, 10, 2639. [Google Scholar] [CrossRef]
- “Cuckoo-hash”. Available online: https://github.com/kroki/Cuckoo-hash (accessed on 16 November 2021).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Flow Key | State |
|---|---|
| IPsrc = … … | OPEN |
| IPsrc = 1.2.3.4 | STAGE-1 |
| IPsrc = 5.6.7.8 | STAGE-2 |
| IPsrc = no match | DEFAULT |
| Type | Sharing Scope | Life Cycle | Amount |
|---|---|---|---|
| Global state | all packets in the switch | = Switch | 1 |
| Table state | packets entering the table | = Table | Number of tables |
| Flow state | packets matching the entry | = Entry | Number of entries |
| Packet state | a single packet | = Packet | Number of packets |
| Category | Actions |
|---|---|
| Arithmetic logic | add, sub, srl, sll, and, or, xor, nor, not, set, insert, del, calculate_checksum |
| Forwarding | goto_table, output, flood |
| Branch | jump, compare_jump |
| CPU | Intel Xeon CPU E7-4809 v4 @2.10 GHz |
| Caches | 32 k L1 i and L1 d, 256 KB L2, 20 MB L3 |
| Memory | 128 G DDR3 @ 1333 MHz, 4-channels |
| NIC | Intel XL710, PCI Express 3.0/x8, 4*10 Gb Intel I350, PCI Express 3.0/x8, 4*1 Gb |
| DPDK | v19.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jing, L.; Wang, J.; Chen, X. MSSA: Constant Time State Search through Multi-Scope State Area. Appl. Sci. 2022, 12, 559. https://doi.org/10.3390/app12020559
Jing L, Wang J, Chen X. MSSA: Constant Time State Search through Multi-Scope State Area. Applied Sciences. 2022; 12(2):559. https://doi.org/10.3390/app12020559
Chicago/Turabian StyleJing, Linan, Jinlin Wang, and Xiao Chen. 2022. "MSSA: Constant Time State Search through Multi-Scope State Area" Applied Sciences 12, no. 2: 559. https://doi.org/10.3390/app12020559
APA StyleJing, L., Wang, J., & Chen, X. (2022). MSSA: Constant Time State Search through Multi-Scope State Area. Applied Sciences, 12(2), 559. https://doi.org/10.3390/app12020559