
A Hierarchical Sparse Discriminant Autoencoder for Bearing Fault Diagnosis

 ,
, 
 , ,
, ,
Abstract
:1. Introduction
- (1)
- In this paper, a novel semi-supervised autoencoder (hierarchical sparse discriminant autoencoder) is proposed to extract features for fault diagnosis;
- (2)
- A novel hierarchical sparsity strategy is proposed to enhance the sparsity of autoencoder networks, combining class aggregation and class separability strategy to improve feature extraction performance;
- (3)
- Experimental comparative analysis verifies that the proposed method can achieve reliable fault diagnosis for rotating parts under complex working conditions;
2. Theoretical Background
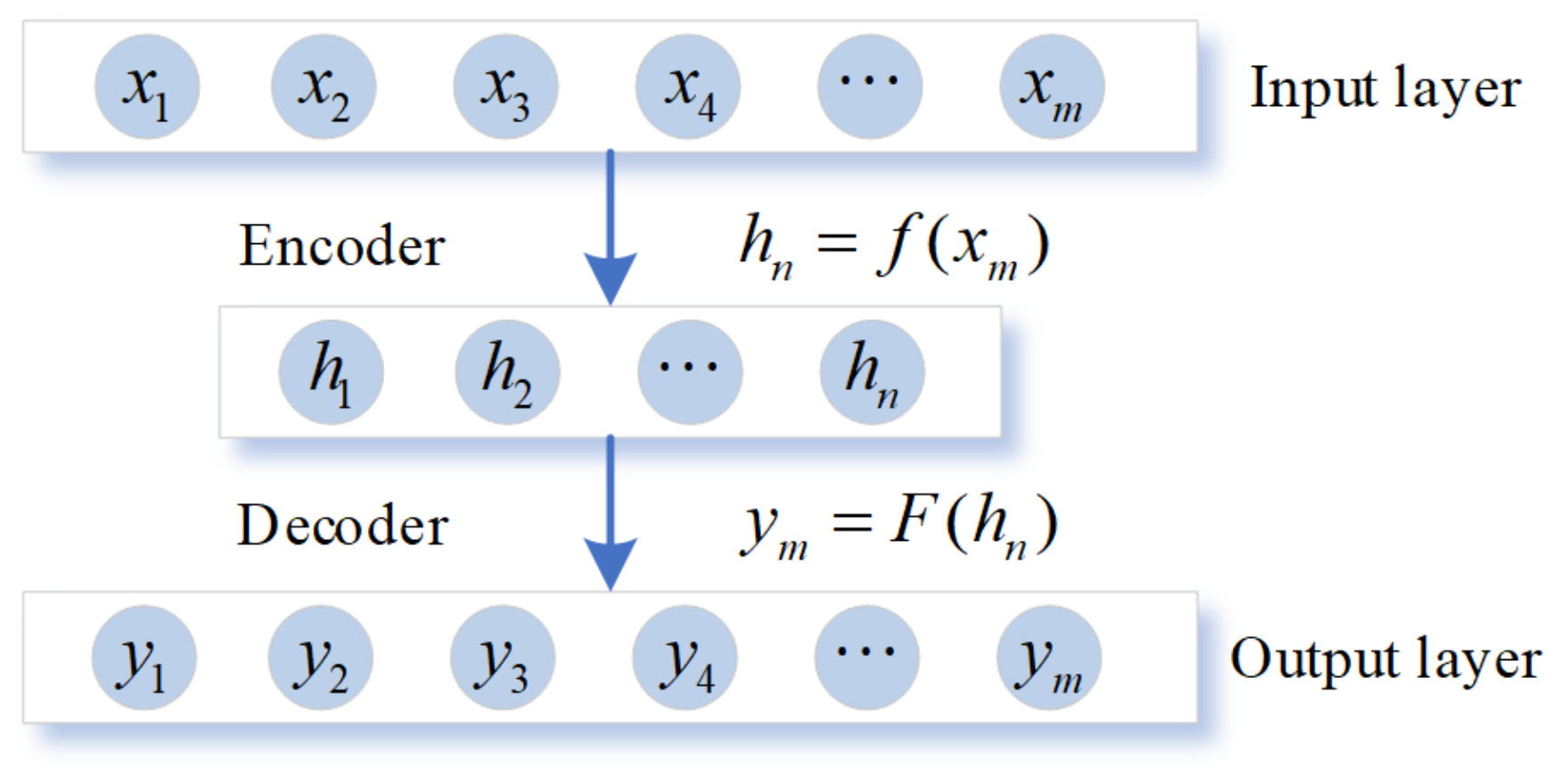
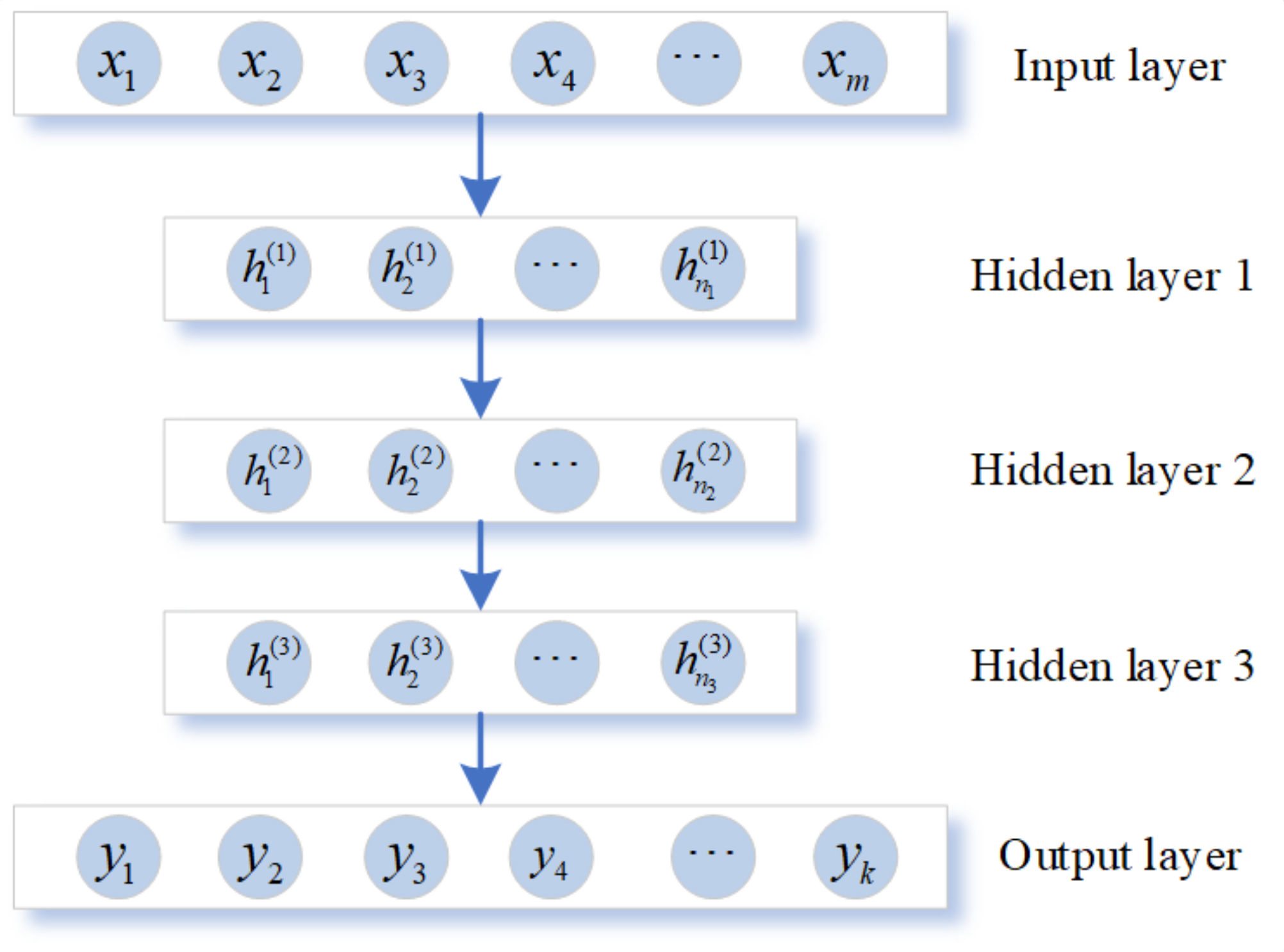
2.1. Stacked Sparse Autoencoder
2.2. Particle Swarm Optimization
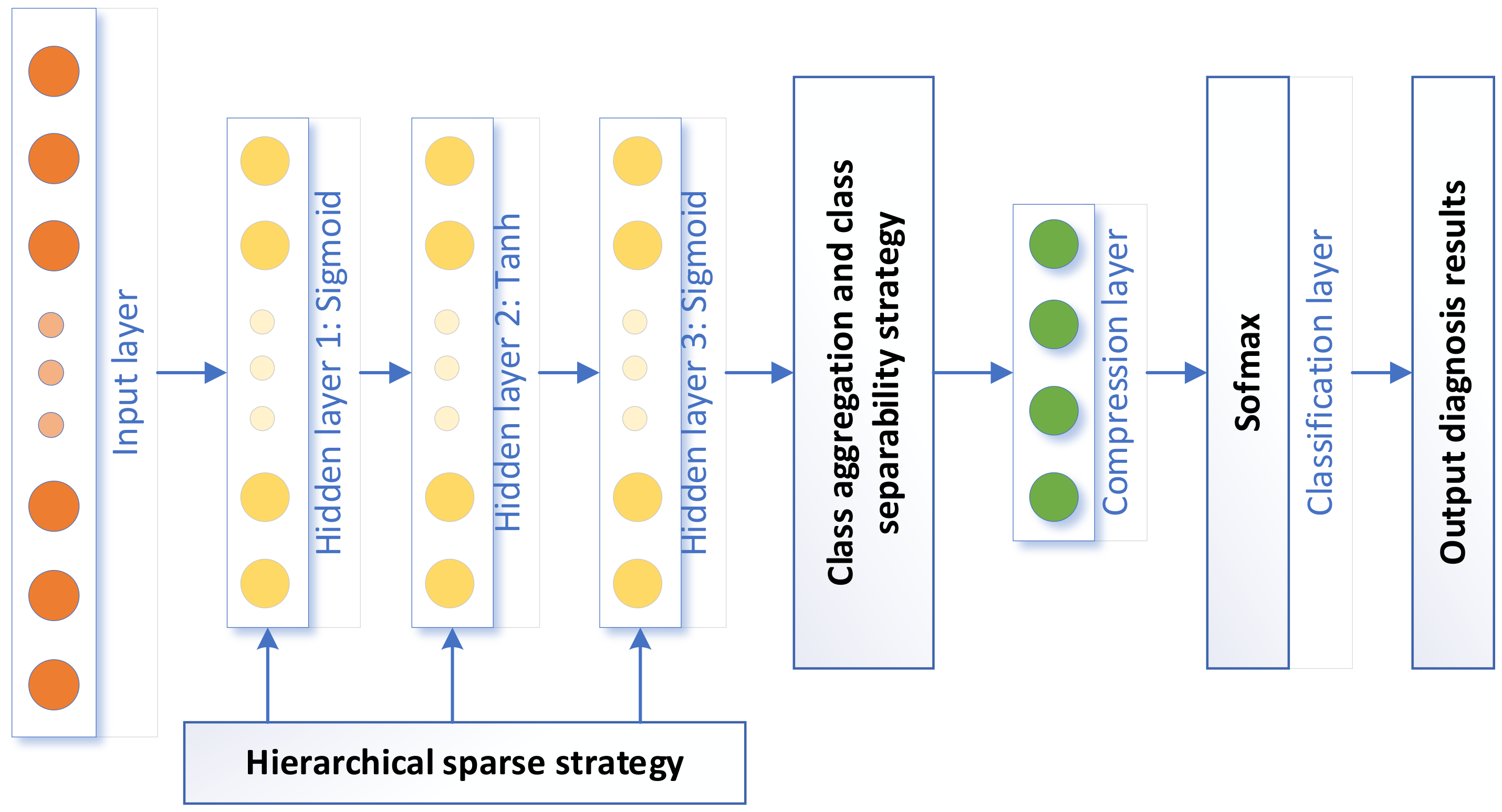
3. Proposed Methodology
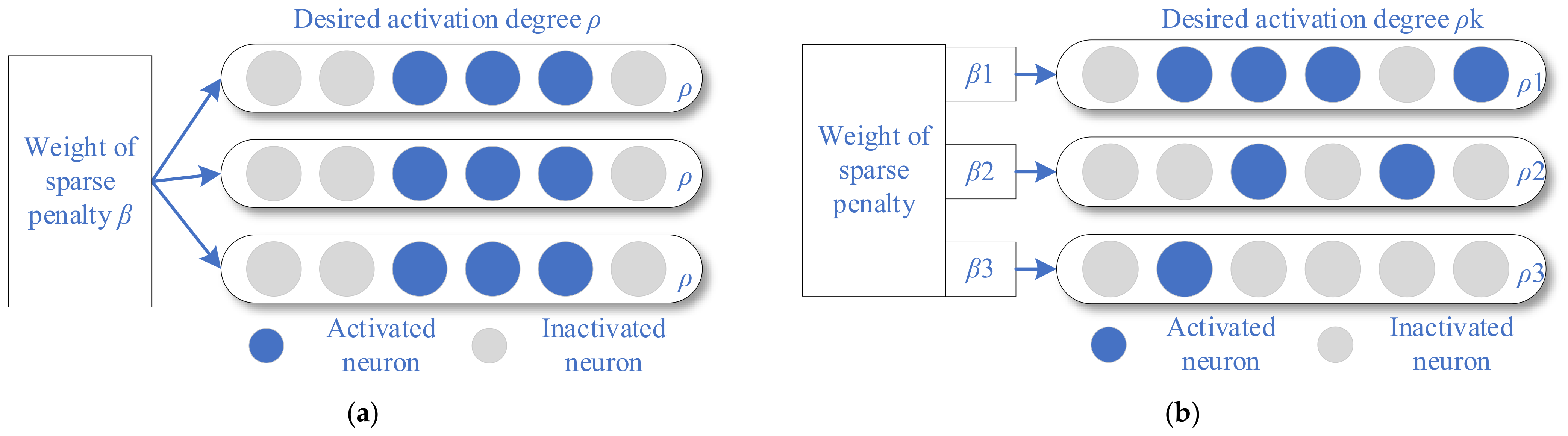
3.1. Hierarchical Sparse Parameter Strategy
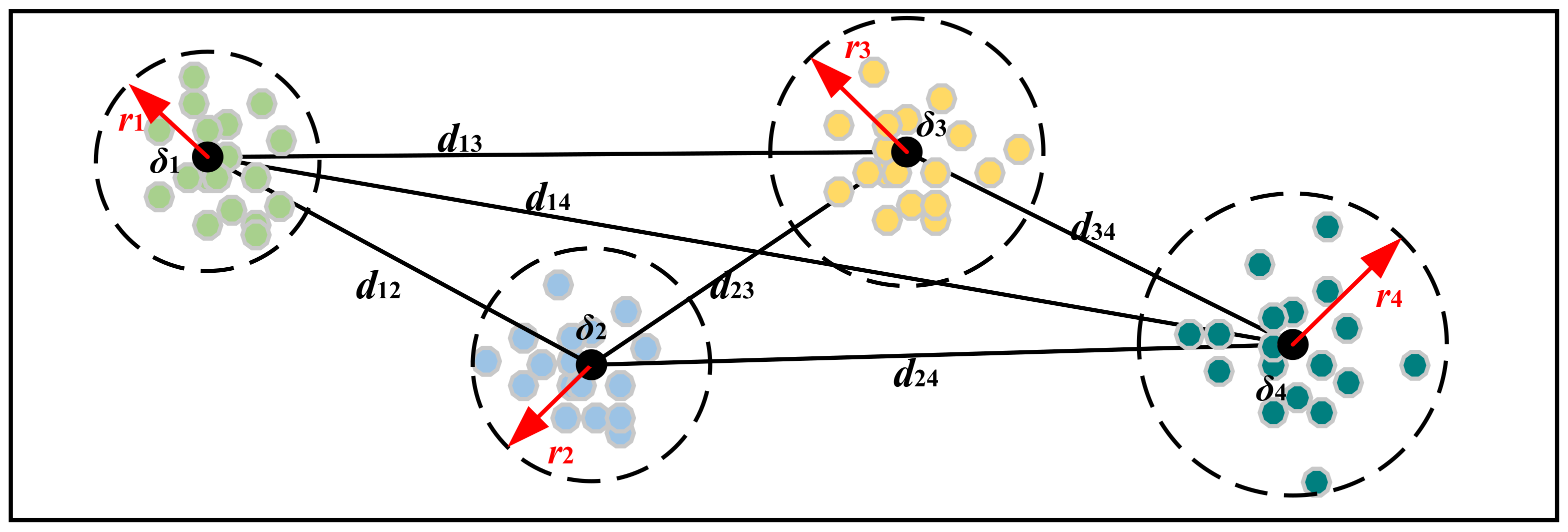
3.2. Class Aggregation and Class Separability Strategy
3.3. Parameter Optimization Strategy
3.3.1. Hierarchical Sparse Parameter Optimization with PSO
3.3.2. Dynamic Optimization of Learning Rate
3.4. HSDAE
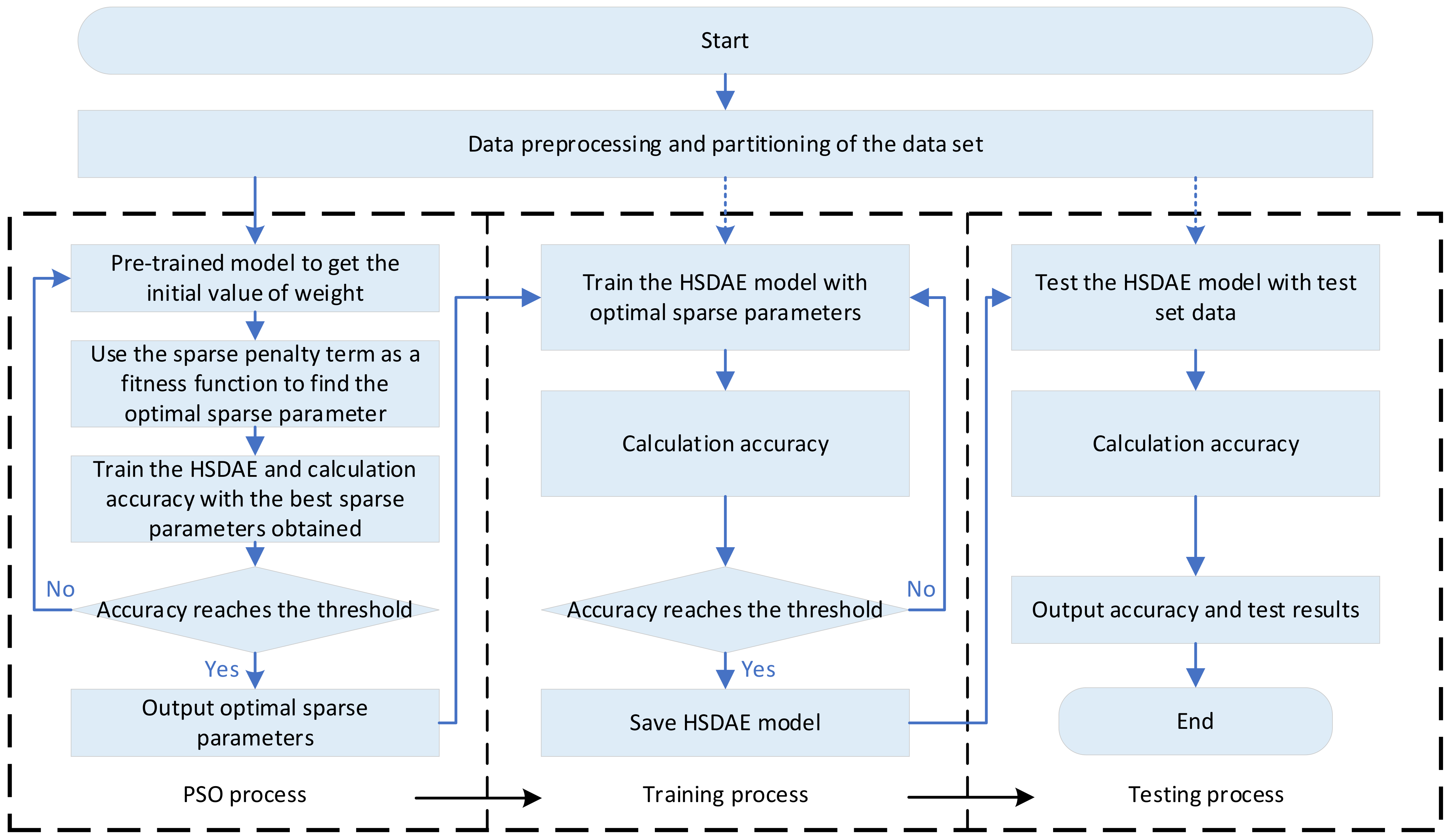
3.5. Overview of the Algorithm
- Obtain the vibration signals of rotating machinery components, perform data preprocessing, convert them into frequency domain data and randomly divide the frequency domain data set into a training set and a testing set;
- Initialize HSDAE parameters and set key hyperparameters, such as the number of neurons in each layer, batch size, number of iterations, etc.;
- PSO parameter initialization, set the optimization boundary, inertia factor, learning factor, total number of particles and number of iterations;
- The HSDAE network uses the training set for pre-training to obtain the initial values of the variables in the network;
- Use the hierarchical sparse loss function as the fitness function of PSO to obtain the optimal sparse parameters. Use the optimal sparse parameters to train the HSDAE and calculate the accuracy. If the accuracy does not meet the conditions, return to step 4 to continue iterating until the accuracy threshold is met, and then the optimal sparsity parameter is output;
- Use the optimal sparse parameters to train the HSDAE, use the testing set to cross-validate, stop training and save the model when the accuracy meets the threshold;
- Use the testing set to test the model and output the diagnosis result.
4. Experimental Verification
4.1. Experimental Test 1
4.1.1. Sparsity Verification
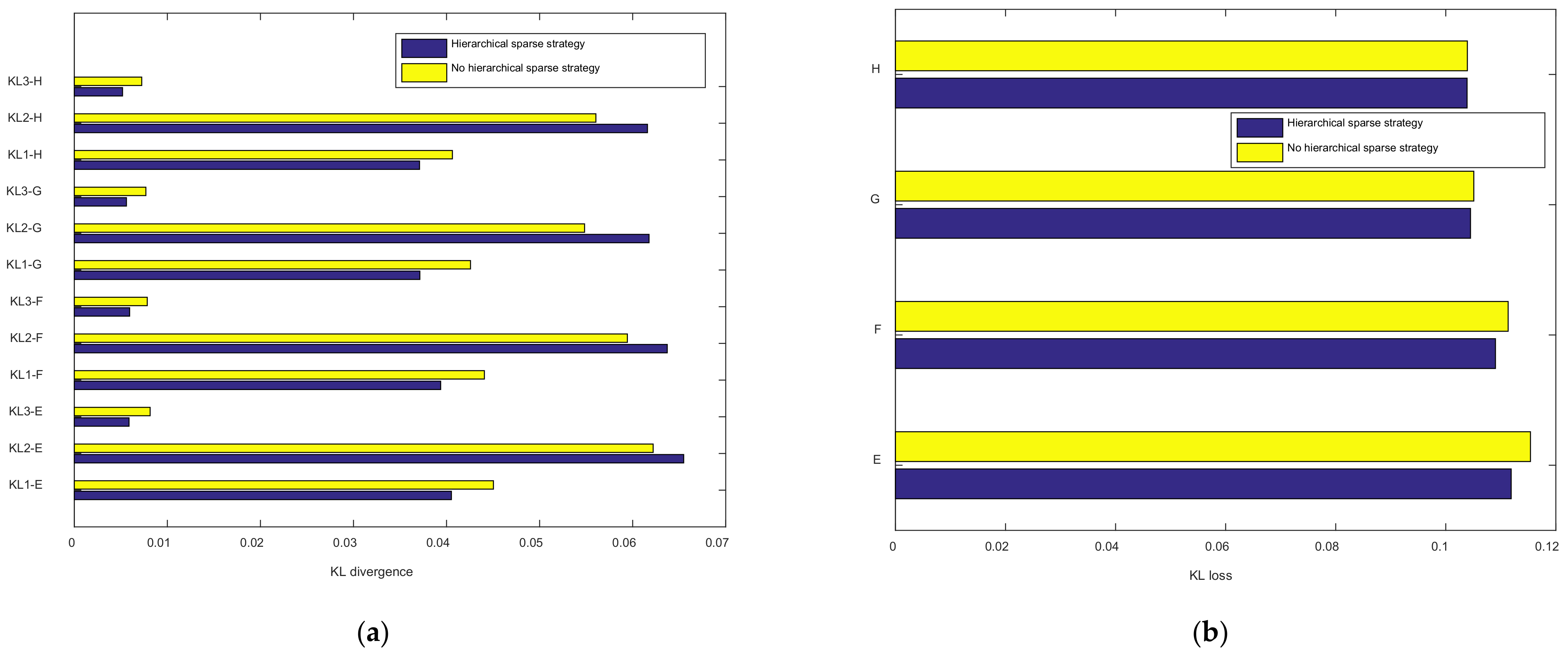
4.1.2. Class Aggregation and Class Separability Verification
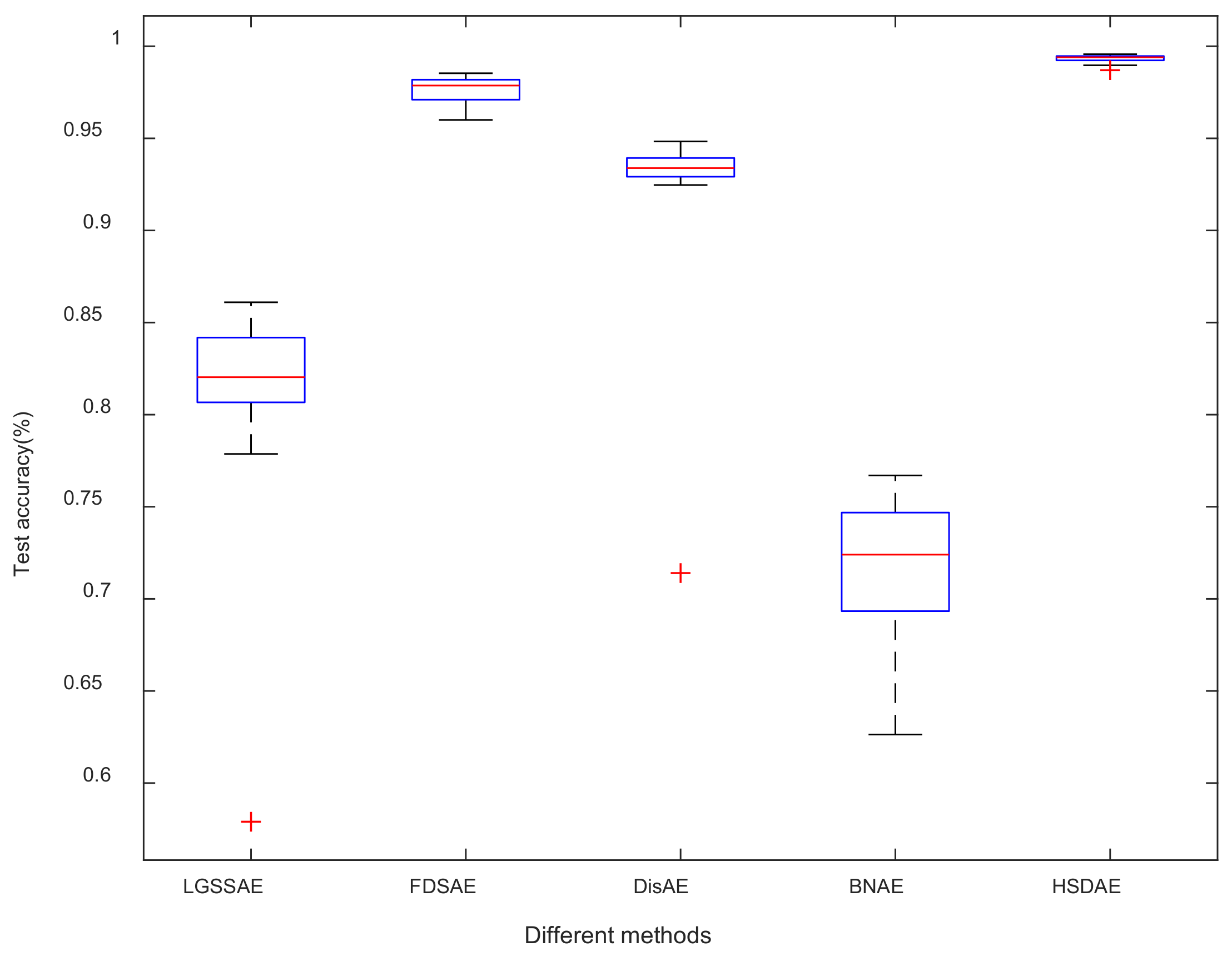
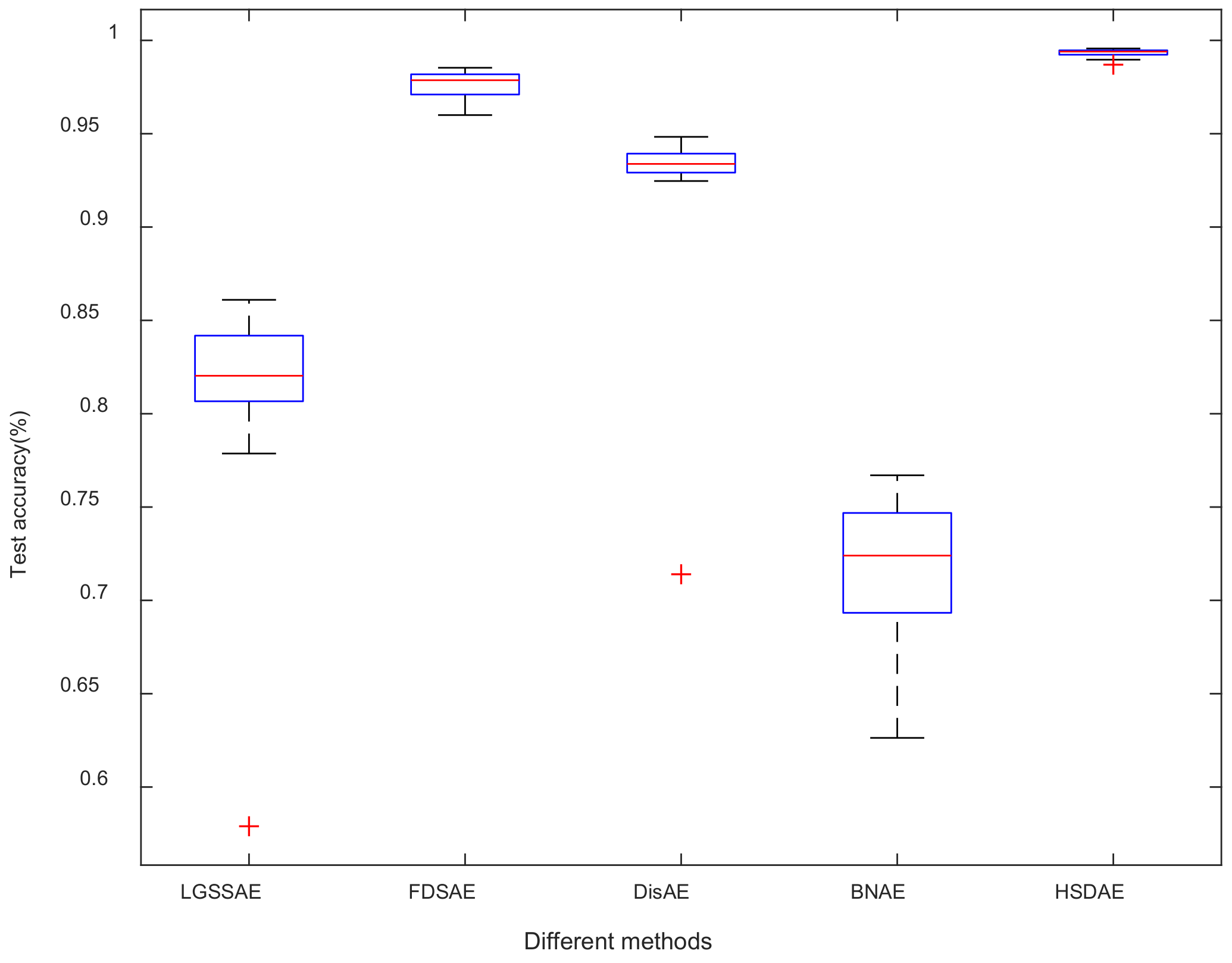
4.1.3. Comparison Results of Different Methods
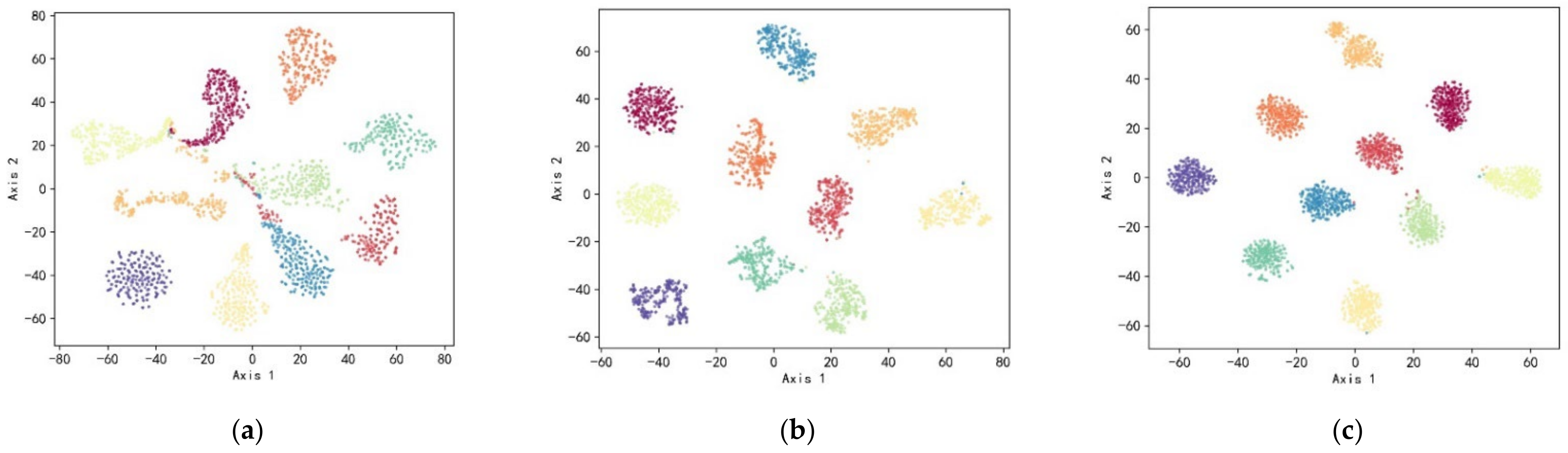
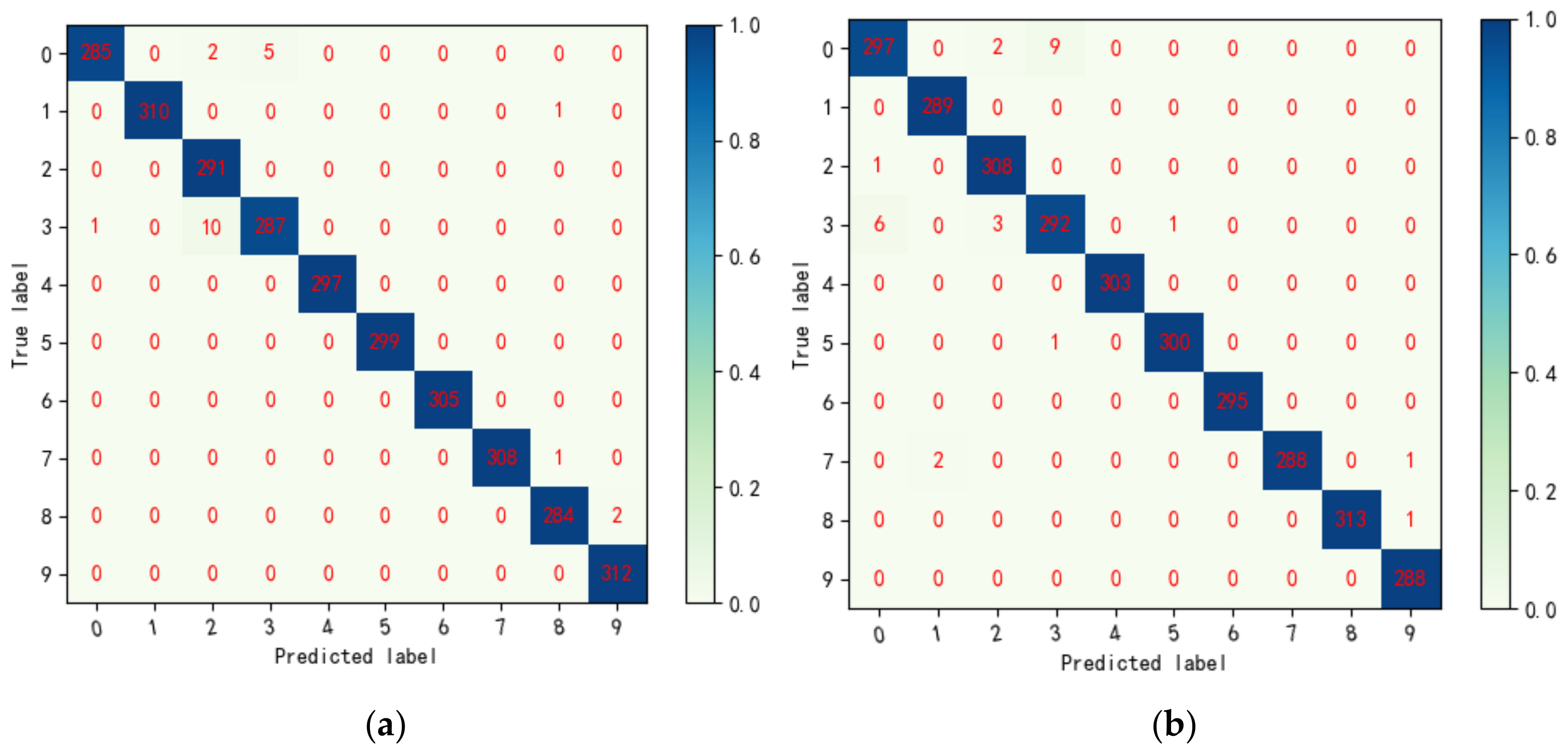
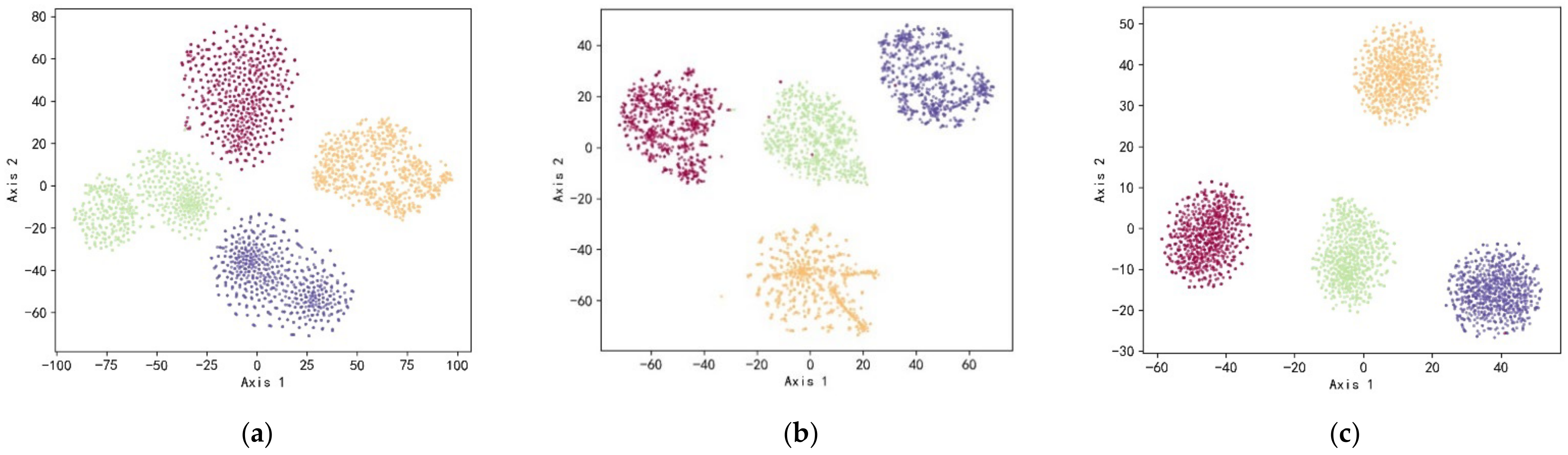
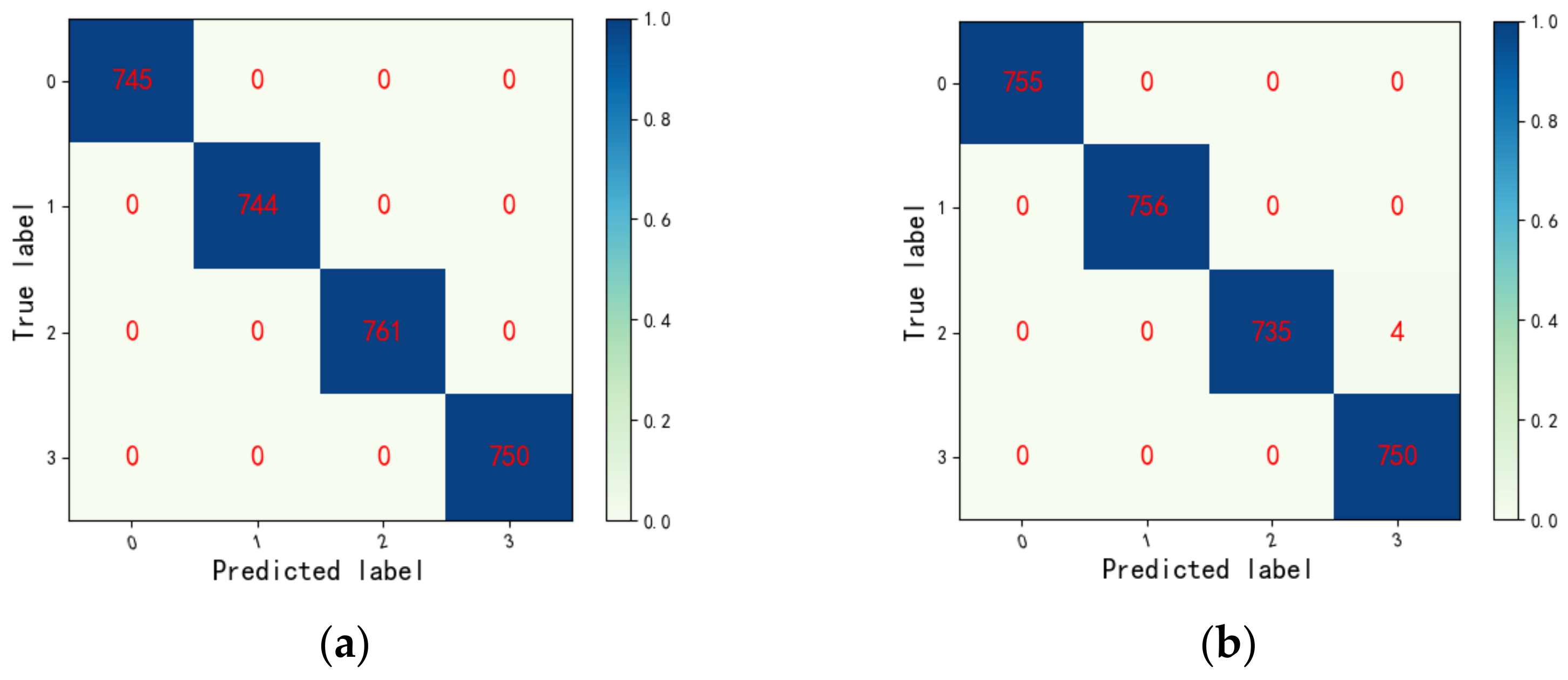
4.1.4. Visual Analysis of the Proposed Method
4.2. Experimental Test 2
4.2.1. Sparsity Verification
4.2.2. Class Aggregation and Class Separability Verification
4.2.3. Comparison Results of Different Methods
4.2.4. Visual Analysis of the Proposed Method
5. Conclusions
- (1)
- The proposed hierarchical sparse strategy is used to optimize the SSAE, giving different sparse activation and sparse regularization weights to the neurons in each layer of SSAE, which enhances the randomness of the network sparseness and achieves better the diagnostic effect. Using the PSO to obtain the best sparse parameters adaptively driven by data can improve network sparseness and avoid the complexity of manual parameter selection;
- (2)
- The class aggregation and class separability strategy can effectively enhance the classification ability of the autoencoder network. It is proved from the side that the proposed method can optimize the feature extraction performance of the autoencoder;
- (3)
- Compared with other methods, the standard deviation of the HSDAE method proposed in this paper is small, and the fault diagnosis accuracy is high, which reflects the effectiveness, reliability and stability of the HSDAE method in fault diagnosis.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, K.; Li, S.; Li, R.; Lu, J.; Li, X.; Zeng, M. Domain Adaptation Network with Double Adversarial Mechanism for Intelligent Fault Diagnosis. Appl. Sci. 2021, 11, 7983. [Google Scholar] [CrossRef]
- Xu, K.; Li, S.; Li, R.; Lu, J.; Zeng, M. Deep domain adversarial method with central moment discrepancy for intelligent transfer fault diagnosis. Meas. Sci. Technol. 2021, 32, 124005. [Google Scholar] [CrossRef]
- Li, R.; Li, S.; Xu, K.; Lu, J.; Teng, G.; Du, J. Deep domain adaptation with adversarial idea and coral alignment for transfer fault diagnosis of rolling bearing. Meas. Sci. Technol. 2021, 32, 094009. [Google Scholar] [CrossRef]
- Li, R.; Li, S.; Xu, K.; Li, X.; Lu, J.; Zeng, M.; Li, M.; Du, J. Adversarial Domain Adaptation of Asymmetric Mapping with Coral Alignment for Intelligent Fault Diagnosis. Meas. Sci. Technol. 2021, 1–16. [Google Scholar] [CrossRef]
- Huo, L.; Zhang, X.Y.; Li, H.D. Bearing Fault Diagnosis Based on BP Neural Network. In Proceedings of the International Conference on Air Pollution and Environmental Engineering (APEE), Hong Kong, China, 26–28 October 2018. [Google Scholar]
- Teh, C.K.; Aziz, A.; Elamvazuthi, I.; Man, Z. Classification of Bearing Faults using Extreme Learning Machine Algorithm. In Proceedings of the 2017 IEEE 3rd International Symposium in Robotics and Manufacturing Automation (ROMA), Kuala Lumpur, Malaysia, 19–21 September 2017. [Google Scholar]
- Zhao, K.; Jiang, H.K.; Li, X.Q.; Wang, R.X. An optimal deep sparse autoencoder with gated recurrent unit for rolling bearing fault diagnosis. Meas. Sci. Technol. 2020, 31, 015005. [Google Scholar] [CrossRef]
- Wang, F.T.; Dun, B.S.; Liu, X.F.; Xue, Y.H.; Li, H.K.; Han, Q.K. An Enhancement Deep Feature Extraction Method for Bearing Fault Diagnosis Based on Kernel Function and Autoencoder. Shock Vib. 2018, 2018, 6024874. [Google Scholar] [CrossRef]
- Zhu, J.; Hu, T.Z.; Jiang, B.; Yang, X. Intelligent bearing fault diagnosis using PCA-DBN framework. Neural Comput. Appl. 2020, 32, 10773–10781. [Google Scholar] [CrossRef]
- Chen, S.; Yu, J.; Wang, S. One-dimensional convolutional auto-encoder-based feature learning for fault diagnosis of multivariate processes. J. Process Control 2020, 87, 54–67. [Google Scholar] [CrossRef]
- Deng, Z.; Li, Y.; Zhu, H.; Huang, K.; Tang, Z.; Wang, Z. Sparse stacked autoencoder network for complex system monitoring with industrial applications. Chaos Solitons Fractals 2020, 137, 109838. [Google Scholar] [CrossRef]
- Zhao, Z.; Li, L.; Yang, S.; Li, Q. A frequency domain feature extraction autoencoder and its application in fault diagnosis. China Mech. Eng. 2021, 32, 2468–2474. (In Chinese) [Google Scholar]
- Li, K.; Xiong, M.; Su, L.; Lu, L.; Chen, S. Research on Mechanical Fault Diagnosis Method Based on Improved Deep Extreme Learning Machine. J. Vib. Meas. Diagn. 2020, 40, 1120–1127. [Google Scholar]
- Jia, F.; Lei, Y.; Guo, L.; Lin, J.; Xing, S. A neural network constructed by deep learning technique and its application to intelligent fault diagnosis of machines. Neurocomputing 2018, 272, 619–628. [Google Scholar] [CrossRef]
- Sun, W.; Shao, S.; Zhao, R.; Yan, R.; Zhang, X.; Chen, X. A sparse auto-encoder-based deep neural network approach for induction motor faults classification. Measurement 2016, 89, 171–178. [Google Scholar] [CrossRef]
- Deng, S.; Du, L.; Li, C.; Ding, J.; Liu, H. SAR Automatic Target Recognition Based on Euclidean Distance Restricted Autoencoder. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3323–3333. [Google Scholar] [CrossRef]
- Liu, G.; Li, L.; Jiao, L.; Dong, Y.; Li, X. Stacked Fisher autoencoder for SAR change detection. Pattern Recognit. 2019, 96, 106971. [Google Scholar] [CrossRef]
- Chen, Z.; Li, W. Multisensor Feature Fusion for Bearing Fault Diagnosis Using Sparse Autoencoder and Deep Belief Network. IEEE Trans. Instrum. Meas. 2017, 66, 1693–1702. [Google Scholar] [CrossRef]
- Kong, D.; Yan, X. Adaptive parameter tuning stacked autoencoders for process monitoring. Soft Comput. 2020, 24, 12937–12951. [Google Scholar] [CrossRef]
- Lei, Y.; Jia, F.; Lin, J.; Xing, S.; Ding, S.X. An Intelligent Fault Diagnosis Method Using Unsupervised Feature Learning Towards Mechanical Big Data. IEEE Trans. Ind. Electron. 2016, 63, 3137–3147. [Google Scholar] [CrossRef]
- Togacar, M.; Ergen, B.; Comert, Z. Waste classification using AutoEncoder network with integrated feature selection method in convolutional neural network models. Measurement 2020, 153, 107459. [Google Scholar] [CrossRef]
- Zhu, H.; Cheng, J.; Zhang, C.; Wu, J.; Shao, X. Stacked pruning sparse denoising autoencoder based intelligent fault diagnosis of rolling bearings. Appl. Soft Comput. 2020, 88, 106060. [Google Scholar] [CrossRef]
- Tian, J.; Wang, S.G.; Zhou, J.; Ai, Y.T.; Zhang, Y.W.; Fei, C.W. Fault Diagnosis of Intershaft Bearing Using Variational Mode Decomposition with TAGA Optimization. Shock Vib. 2021, 2021, 8828317. [Google Scholar] [CrossRef]
- Akl, A.; El-Henawy, I.; Salah, A.; Li, K. Optimizing deep neural networks hyperparameter positions and values. J. Intell. Fuzzy Syst. 2019, 37, 6665–6681. [Google Scholar] [CrossRef]
- Cui, H.; Bai, J. A new hyperparameters optimization method for convolutional neural networks. Pattern Recognit. Lett. 2019, 125, 828–834. [Google Scholar] [CrossRef]
- Zhu, X.T.; Xiong, J.B.; Liang, Q. Fault Diagnosis of Rotation Machinery Based on Support Vector Machine Optimized by Quantum Genetic Algorithm. IEEE Access 2018, 6, 33583–33588. [Google Scholar] [CrossRef]
- Huang, B.; Zhang, Y.; Zhao, L. Research on Fault Diagnosis Method of Rolling Bearings Based on Cuckoo Search Algorithm and Maximum Second Order Cyclostationary Blind Deconvolution. J. Mech. Eng. 2021, 57, 99–107. [Google Scholar]
- Wu, Z.H.; Jiang, H.K.; Zhao, K.; Li, X.Q. An adaptive deep transfer learning method for bearing fault diagnosis. Measurement 2020, 151, 107227. [Google Scholar] [CrossRef]
- Zhou, J.; Wang, F.; Zhang, C.; Zhang, L.; Yin, W.; Li, P. An intelligent method for rolling bearing evaluation using feature optimization and GA-SVM. J. Vib. Shock 2021, 40, 227–234. [Google Scholar]
- Chen, J.; Lu, W.; Zhuang, X.; Tao, S. Bearing fault diagnosis method based on GRNN-SOFTMAX classification model. J. Vib. Shock 2020, 39, 16. [Google Scholar]
- Luo, J.; Tong, J.; Zheng, J.; Pan, H.; Pan, Z. Fault Diagnosis Method for Rolling Bearings Based on EEMD and Stacked Sparse Auto-encoder. Noise Vib. Control 2020, 40, 115–120. [Google Scholar]
- Jiang, L.; Ge, Z.Q.; Song, Z.H. Semi-supervised fault classification based on dynamic Sparse Stacked auto-encoders model. Chemom. Intell. Lab. Syst. 2017, 168, 72–83. [Google Scholar] [CrossRef]
- Zhang, Z.; Ren, X.M.; Lv, H.X. Fault Diagnosis with Feature Representation Based on Stacked Sparse Auto Encoder. In Proceedings of the 2018 33rd Youth Academic Annual Conference of Chinese Association of Automation (Yac), Nanjing, China, 18–20 May 2018; pp. 776–781. [Google Scholar]
- Sousa-Ferreira, I.; Sousa, D. A review of velocity-type PSO variants. J. Algorithms Comput. Technol. 2017, 11, 23–30. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobotics 2013, 7, 21. [Google Scholar] [CrossRef] [Green Version]
- Yin, J.; Yan, X. Stacked sparse autoencoders that preserve the local and global feature structures for fault detection. Trans. Inst. Meas. Control 2021, 43, 3555–3565. [Google Scholar] [CrossRef]
- Cui, M.; Wang, Y.; Lin, X.; Zhong, M. Fault Diagnosis of Rolling Bearings Based on an Improved Stack Autoencoder and Support Vector Machine. IEEE Sens. J. 2021, 21, 4927–4937. [Google Scholar] [CrossRef]
- Luo, X.; Li, X.; Wang, Z.; Liang, J. Discriminant autoencoder for feature extraction in fault diagnosis. Chemom. Intell. Lab. Syst. 2019, 192, 1–10. [Google Scholar] [CrossRef]
- Wang, J.; Li, S.; Han, B.; An, Z.; Xin, Y.; Qian, W.; Wu, Q. Construction of a batch-normalized autoencoder network and its application in mechanical intelligent fault diagnosis. Meas. Sci. Technol. 2019, 30, 015106. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Load (HP) | Type of Failure | Depth of Failure (mm) | Number of Samples | Label |
|---|---|---|---|---|---|
| A/B/C/D | 0/1/2/3 | IF1 | 0.5334 | 600/600/600/600 | 0 |
| IF2 | 0.3556 | 600/600/600/600 | 1 | ||
| IF3 | 0.1778 | 600/600/600/600 | 2 | ||
| OF1 | 0.5334 | 600/600/600/600 | 3 | ||
| OF2 | 0.3556 | 600/600/600/600 | 4 | ||
| OF3 | 0.1778 | 600/600/600/600 | 5 | ||
| RF1 | 0.5334 | 600/600/600/600 | 6 | ||
| RF2 | 0.3556 | 600/600/600/600 | 7 | ||
| RF3 | 0.1778 | 600/600/600/600 | 8 | ||
| N | 0 | 600/600/600/600 | 9 |
| Parameter Name | Number of Hidden Layer Neurons | Activation Function | Compression Layer | Learning Rate | Number of Iterations | γ | λ1 | λ2 | λ3 |
|---|---|---|---|---|---|---|---|---|---|
| HSDAE | 512-256-128 | Sigmoid-Tanh-Sigmoid | 10(ReLU) | Formula (17) | 300 | 0.01 | 0.5 | 1 | 1 |
| Data Sets | A | B | C | D | |
|---|---|---|---|---|---|
| LGSSAE | Average accuracy | 90.23% | 87.31% | 87.86% | 88.11% |
| Standard deviation | 0.0477 | 0.0452 | 0.0375 | 0.0382 | |
| FDSAE | Average accuracy | 95.51% | 89.24% | 88.94% | 88.61% |
| Standard deviation | 0.0230 | 0.0501 | 0.0423 | 0.0328 | |
| DisAE | Average accuracy | 96.12% | 93.81% | 94.73% | 92.80% |
| Standard deviation | 0.0276 | 0.0246 | 0.0099 | 0.0340 | |
| BNAE | Average accuracy | 83.25% | 80.80% | 79.93% | 81.86% |
| Standard deviation | 0.0524 | 0.0518 | 0.0548 | 0.0523 | |
| HSDAE | Average accuracy | 99.39% | 99.11% | 99.11% | 99.09% |
| Standard deviation | 0.0040 | 0.0036 | 0.0030 | 0.0031 | |
| Data Set | Load (rpm) | Type of Failure | Depth of Failure (mm) | Number of Samples | Label |
|---|---|---|---|---|---|
| E/F/G/H | 900/1100/1300/1500 | IF | 0.500 | 1500/1500/1500/1500 | 0 |
| OF | 0.500 | 1500/1500/1500/1500 | 1 | ||
| RF | 0.500 | 1500/1500/1500/1500 | 2 | ||
| N | 0 | 1500/1500/1500/1500 | 3 |
| Parameter Name | Number of Hidden Layer Neurons | Activation Function | Compression Layer | Learning Rate | Number of Iterations | γ | λ1 | λ2 | λ3 |
|---|---|---|---|---|---|---|---|---|---|
| HSDAE | 512-256-128 | Sigmoid-Tanh-Sigmoid | 4(ReLU) | Formula (17) | 300 | 0.01 | 0.5 | 1 | 1 |
| Data Sets | E | F | G | H | |
|---|---|---|---|---|---|
| LGSSAE | Average accuracy | 81.06% | 85.23% | 88.30% | 89.52% |
| Standard deviation | 0.0572 | 0.0484 | 0.0215 | 0.0638 | |
| FDSAE | Average accuracy | 97.66% | 98.71% | 98.73% | 99.01% |
| Standard deviation | 0.0066 | 0.0085 | 0.0109 | 0.0125 | |
| DisAE | Average accuracy | 92.38% | 94.96% | 96.59% | 98.10% |
| Standard deviation | 0.0485 | 0.0116 | 0.0060 | 0.0031 | |
| BNAE | Average accuracy | 71.85% | 74.11% | 76.96% | 85.43% |
| Standard deviation | 0.0346 | 0.0386 | 0.0368 | 0.0261 | |
| HSDAE | Average accuracy | 99.32% | 99.60% | 99.78% | 99.88% |
| Standard deviation | 0.0021 | 0.0012 | 0.0008 | 0.0006 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, M.; Li, S.; Li, R.; Lu, J.; Xu, K.; Li, X.; Wang, Y.; Du, J. A Hierarchical Sparse Discriminant Autoencoder for Bearing Fault Diagnosis. Appl. Sci. 2022, 12, 818. https://doi.org/10.3390/app12020818
Zeng M, Li S, Li R, Lu J, Xu K, Li X, Wang Y, Du J. A Hierarchical Sparse Discriminant Autoencoder for Bearing Fault Diagnosis. Applied Sciences. 2022; 12(2):818. https://doi.org/10.3390/app12020818
Chicago/Turabian StyleZeng, Mengjie, Shunming Li, Ranran Li, Jiantao Lu, Kun Xu, Xianglian Li, Yanfeng Wang, and Jun Du. 2022. "A Hierarchical Sparse Discriminant Autoencoder for Bearing Fault Diagnosis" Applied Sciences 12, no. 2: 818. https://doi.org/10.3390/app12020818
APA StyleZeng, M., Li, S., Li, R., Lu, J., Xu, K., Li, X., Wang, Y., & Du, J. (2022). A Hierarchical Sparse Discriminant Autoencoder for Bearing Fault Diagnosis. Applied Sciences, 12(2), 818. https://doi.org/10.3390/app12020818