
Multi-Relational Graph Convolution Network for Service Recommendation in Mashup Development



Abstract
:1. Introduction
- We construct a multi-relational graph that incorporates the composition history, functional descriptions, and annotated tags of the mashup and service;
- We propose to fuse the multi-relational graph and utilize the graph convolutional network to capture the high-order relation for service recommendation;
- We conduct a series of experiments on real-world services from ProgrammableWeb, and the results demonstrate the effectiveness of our proposed approach;
2. Related Work
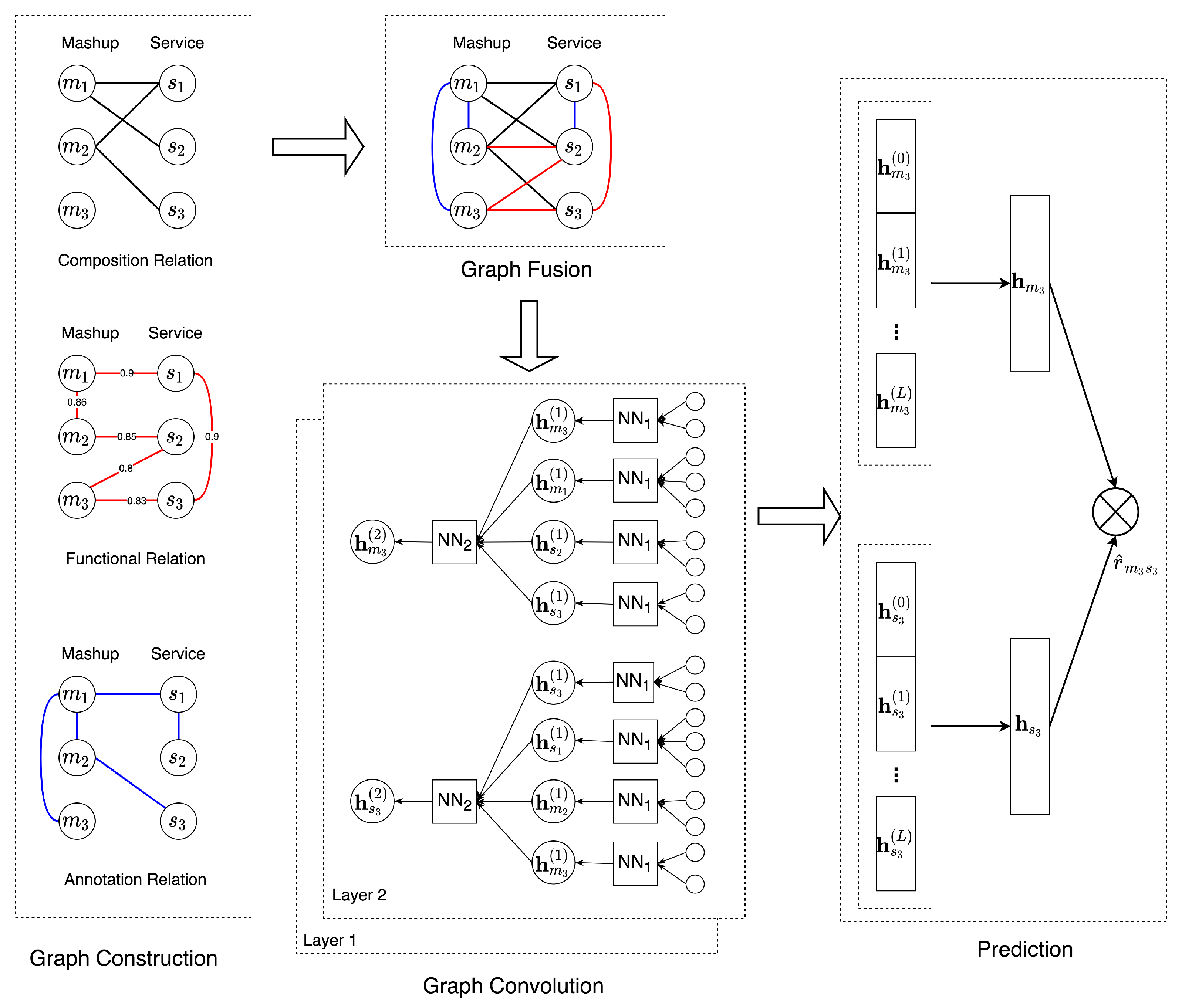
3. Multi-Relational GCN Based Service Recommendation Model
3.1. Problem Definition
3.2. Overall Framework
3.2.1. Graph Construction
- Composition Relation. The composition relation between the mashup and service can be modeled as a bipartite graph, where an edge of type exists between mashup m and service s if appears in . The composition relation is represented as an adjacency matrix with if nodes i and j have a composition relation in and 0 otherwise. Note that the matrix is extremely sparse as most mashups typically only invoke a few services to meet their demands. In addition, there exist some mashups and services that have no composition history, i.e., the rows and columns of matrix of the cold-start mashups and services are zero vectors. To mitigate the sparsity and cold-start issues of the composition relation, other features of services and mashups such as textual descriptions and tags are utilized.
- Functional Relation. The textual descriptions of mashups and services provide functional properties and can alleviate the sparsity and cold-start problem of the composition relation. For instance, for a new mashup, m has no composition record, and we can still recommend a possible service s if mashup is functionally similar to m and invokes service s. We represent the functional relation as a graph where two nodes are connected with type if their textual descriptions are similar to each other. It is crucial to measure the similarities of textual descriptions between mashups and services. In this paper, we adopt two approaches for learning the feature representations from textual descriptions and the similarity between them:
- –
- LDA [29]. Latent Dirichlet Allocation (LDA) is an unsupervised generative model that can discover topics in a collection of documents and assign topic distributions to each document. We collect the textual descriptions of all mashups and services as a document corpus. After training, the textual description of each mashup/service will have a distribution over all topics, and each topic will have a distribution over all words. Specifically, each mashup/service is mapped to a latent topic space and represented as a topic distribution , where is the number of topics.
- –
- Doc2vec [30]. Different from LDA that processes documents as “bag-of-words” where the order of words is ignored, the doc2vec model learns a distributed vector representation for a piece of document. It follows the idea of word2vec where the target word is predicted given context words. Concretely, it concatenates the document vector with several word vectors from the document and predicts the following word in a context window. Compared to word2vec, the only change is the addition of the document vector that acts as a memory of the topic of the document. After training, the textual description of the mashup/service is represented as a dense vector , where is the dimension size.
We denote the description embedding matrix as or , where each row represents the vector representation of the textual description of mashup or service learned from LDA or doc2vec model. The cosine similarity is used to measure the similarity between vectors. We denote the weight matrix for the functional relation as , and the functional similarity between any two nodes i and j is measured as . In this case, each node is connected to all other nodes in the graph of relation type with weights equal to their functional similarity. However, modeling the functional relation as a complete graph is unfavorable as a mashup or service is generally only similar to a few mashups and services, as such, a large proportion of edges with small weights will introduce a lot of noise and increase the memory and computation costs. Therefore, we prune the graph where only edges with the largest weights for each node are retained. In this way, each mashup/service is connected to at least most similar mashups and services in terms of textual descriptions, and the edge weights are the degrees of similarity. The functional relation is represented as an adjacency matrix , which only preserves the significant values of . - Tagging Relation. There is a tagging relation between the nodes if two nodes share at least one common tag. The tagging relation is represented as an adjacency matrix with if nodes i and j have at least a common tag, i.e., , and otherwise 0. As some popular tags are annotated by a lot of mashups and services, a service may possess a large number of tagging relations. To reduce the computational burden in the graph convolution, for each node, we randomly sample nodes that share the same tag. In this case, the tagging relation can still be preserved as the graph convolution process can learn the indirect tagging relation between services.
3.2.2. Graph Convolution
3.2.3. Prediction
3.3. Model Learning
| Algorithm 1 Training algorithm of MRGCN |
|
4. Experiments
- How does the proposed MRGCN model for service recommendation perform compared to the state-of-the-art methods?
- Does incorporating the functional relation and tagging relation into the model improve the performance of the model?
- Which graph fusion method has better performance in service recommendation?
4.1. Dataset Description
4.2. Evaluation Metrics
4.3. Baseline Methods
- CF [36]. This is the basic collaborative filtering technique to recommend services by identifying similar mashups. Given a new mashup m, we first calculate its textual description similarity to other existing mashups using the doc2vec model and cosine similarity measure, and select top-similar mashups of m. The recommendation score between m and a candidate service s is calculated as:where is the cosine similarity between m and , if composes s and 0 otherwise.
- CMF [6]. This approach builds multi-dimensional relationships among mashups, services and topics with a set of coupled matrices, and performs a coupled matrices factorization algorithm to predict unobserved relationships.
- LDA [29]. It learns the representations of textual descriptions of mashups and services with the LDA model and calculates the cosine similarity between mashup request and service contents.
- Doc2vec [30]. It learns the representations of textual descriptions of mashups and services with the doc2vec model and calculates the cosine similarity between mashup request and service contents.
- PaSRec [7]. It is a CF-based approach where it builds a heterogeneous information network (HIN) with mashups, services, content, tags, etc., defines meaningful meta-paths, and calculates the similarities between mashups using the meta-path-based similarity measurement. It uses a Bayesian personalized ranking (BPR) algorithm to learn the weights of meta-paths.
- DHSR [18]. It combines collaborative filtering and textual content with a multilayer perceptron to capture the complex invocation relations between mashups and services. It computes semantic similarities between contents with three kinds of feature extractors and incorporates several pre-trained word embeddings.
- MRGCN. It is the proposed model in the paper, in which we implement two variants for functional content modeling: MRGCN_LDA in which LDA is used for content feature representation, and MRGCN_D2V in which Doc2vec is used for content feature representation.
4.4. Implementation Details
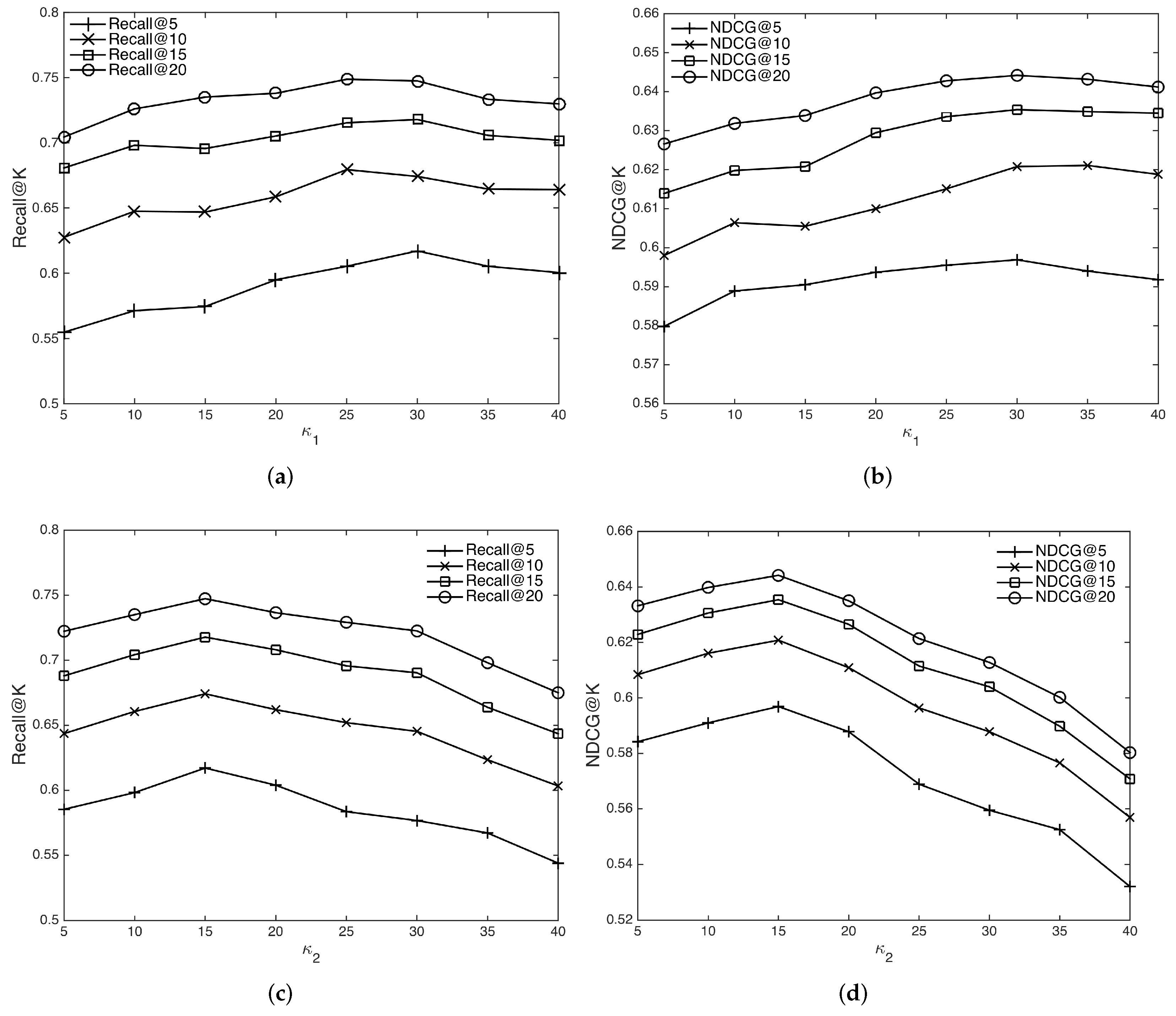
- In learning the vector representations of textual descriptions of mashups and services, we aggregate the textual descriptions of all 6300 mashups and 21,474 services into one big corpus, and perform a series of pre-processing steps: (1) Tokenization, which splits sentences into words; (2) Stop-words removal, which remove the insignificant words and infrequent words that appear less than 5 times; (3) Lemmatization, which transform words to their root forms. All pre-processing is done using the NLTK library. After pre-processing, we feed the dataset to the LDA and doc2vec model in the gensim library. The number of topics in LDA model and the vector size in doc2vec model are both set to 64. The other parameters are set as the default value of the gensim API. In building the functional and tagging relations, is set to 30, and is set to 15.
- For each positive mashup-service pair, we sample negative pairs. In training the GCN model, the initial node features are set as the document representations learned with the doc2vec model, and the parameters in GCN are initialized from a Gaussian distribution . The batch size is set to 256, the learning rate is set to 0.005, and the regularization term is set to . The number of GCN layers L is set to 2, and in each layer, the feature dimension is set to 64. We stop the training process when NDCG@20 on the test set does not increase for 10 successive epochs.
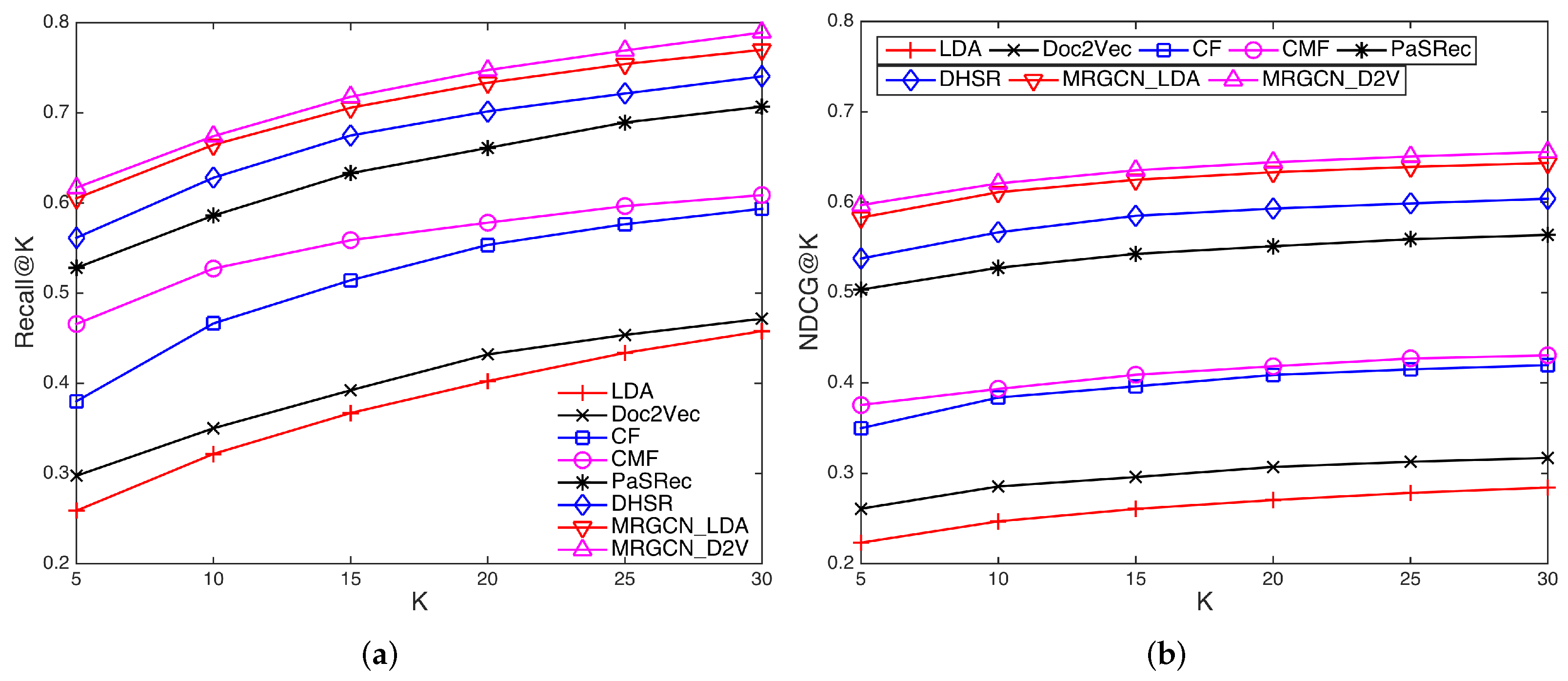
4.5. Experimental Results
- LDA and Doc2vec methods only exploit textual similarity to match mashup requirements and candidate services, and ignore the existing mashup-service composition patterns. Therefore, they perform worse than the other methods that utilize both content similarity and composition relation. Moreover, Doc2vec performs better than LDA, indicating that learning the semantics of content with a distributed representation is better than the traditional bag-of-words model.
- CF and CMF methods achieve better performance than LDA and Doc2vec, due to the simultaneous use of mashup-service composition history and textual relations between mashups and services. Moreover, CMF performs better than CF. The reason could be that CMF implicitly considers the semantic relations between mashups and services through the shared topics, while only the semantic similarities between mashups are considered in CF.
- PaSRec is a CF-based method that evaluates the similarities between mashups. Different from the plain CF model, it considers diverse kinds of relations (captured as meta-paths) between mashups including mashups with similar contents, tags as well as services, and combines them with a different set of weights learned from data. It unsurprisingly achieves a better performance than CF.
- DHSR is a state-of-the-art method for service recommendation. It uses a deep neural network to combine the mashup and service features learned from the CF component and content component. Its performance improvement could be attributed to the use of deep networks to characterize the complex relations between mashups and services.
- Finally, our method MRGCN outperforms all these models in both Recall and NDCG. For instance, the Recall@5, NDCG@5, Recall@10, and NDCG@10 of our model were higher than DHSR by 9.9%, 13.1%, 7.3%, and 9.5%, respectively. On the one hand, it effectively combines different kinds of relations between both mashups and services, as opposed to PaSRec that only considers the relations between mashups; on the other hand, it can propagate and aggregate higher-order features of mashups and services with GCN, which can effectively deal with the problem of data sparsity. Moreover, MRGCN_D2V outperforms MRGCN_LDA, which is consistent with the baseline models and shows that empirically doc2vec has an advantage in modeling service functionality.
4.6. Discussion
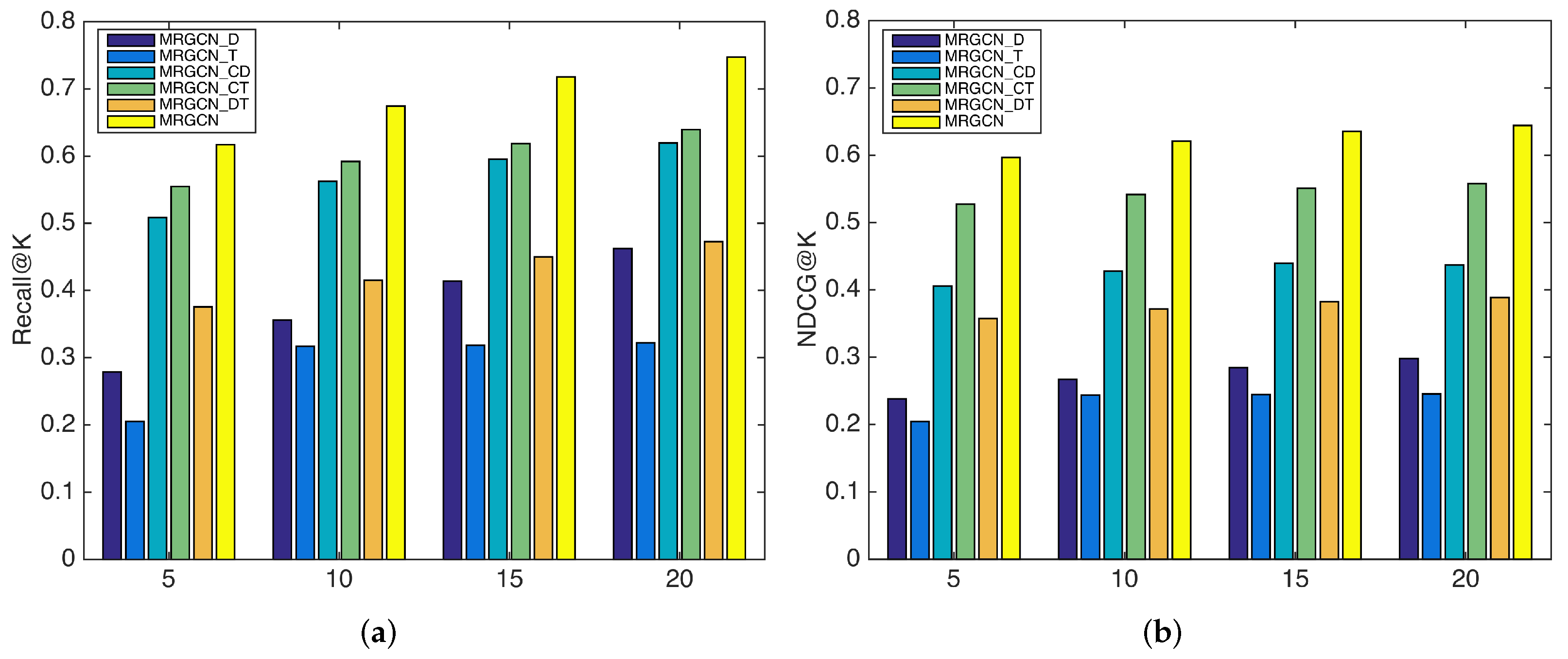
4.6.1. Impact of Different Relations
4.6.2. Impact of Different Fusion Strategies
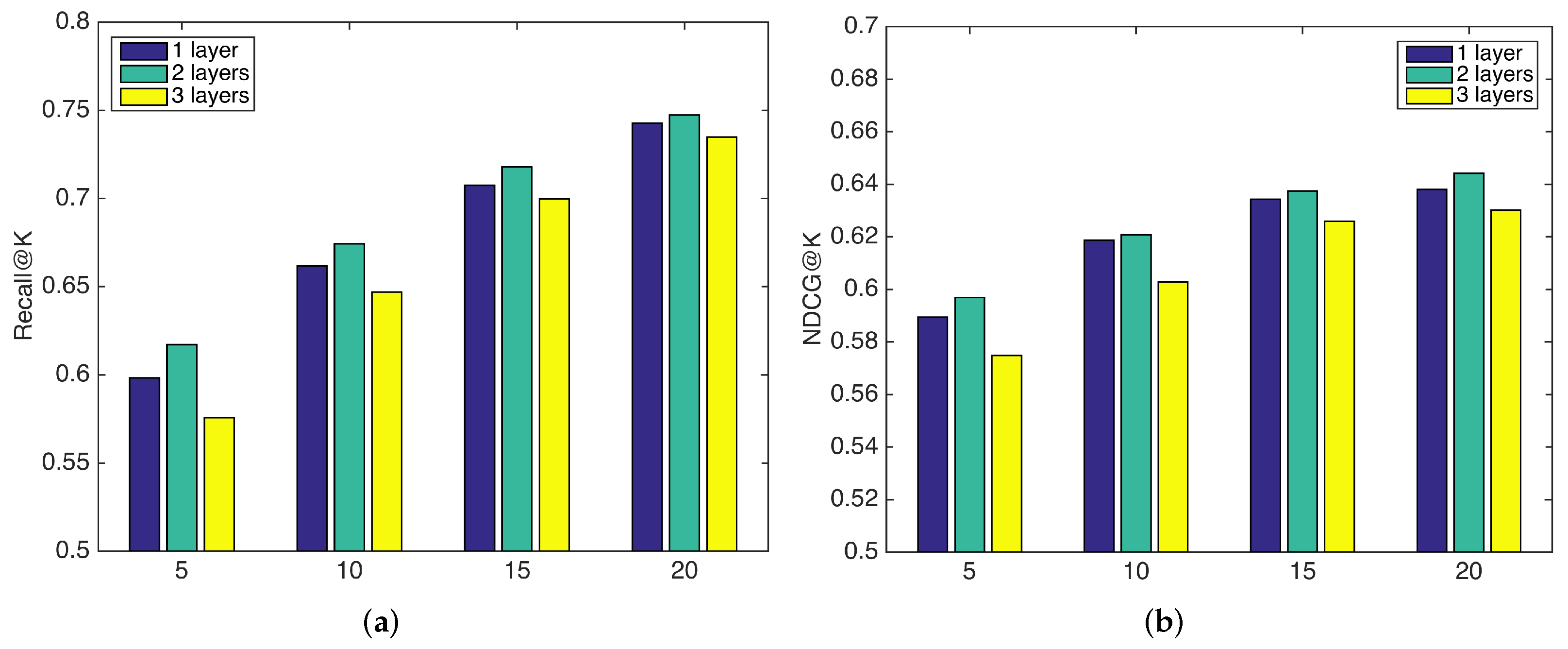
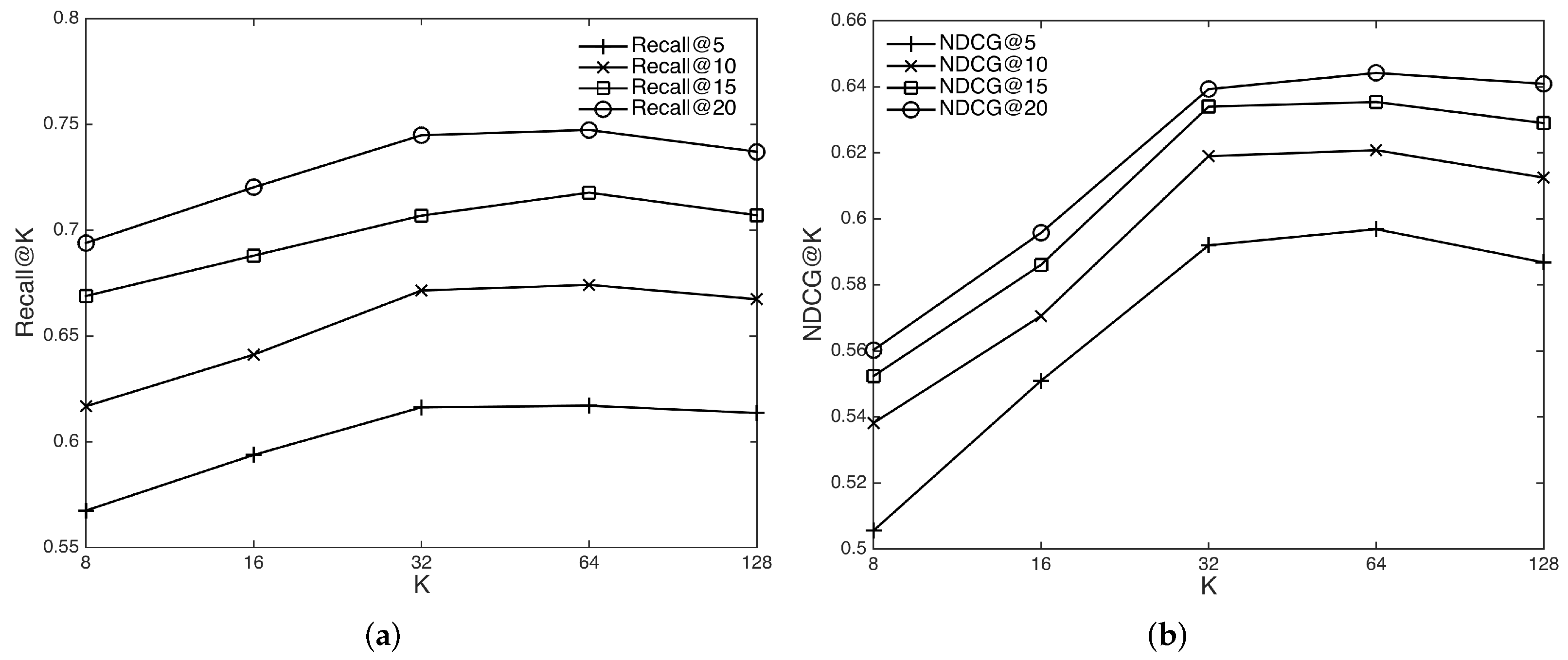
4.6.3. Impact of the Number of Layers and Layer Dimensions
4.6.4. Impact of the Threshold
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bouguettaya, A.; Singh, M.P.; Huhns, M.N.; Sheng, Q.Z.; Dong, H.; Yu, Q.; Neiat, A.G.; Mistry, S.; Benatallah, B.; Medjahed, B.; et al. A service computing manifesto: The next 10 years. Commun. ACM 2017, 60, 64–72. [Google Scholar] [CrossRef]
- Tan, W.; Fan, Y.; Ghoneim, A.; Hossain, M.A.; Dustdar, S. From the Service-Oriented Architecture to the Web API Economy. IEEE Internet Comput. 2016, 20, 64–68. [Google Scholar] [CrossRef]
- Im, J.; Kim, S.H.; Kim, D. IoT Mashup as a Service: Cloud-Based Mashup Service for the Internet of Things. In Proceedings of the 2013 IEEE International Conference on Services Computing, Santa Clara, CA, USA, 28 June–3 July 2013; pp. 462–469. [Google Scholar] [CrossRef]
- Yu, J.; Benatallah, B.; Casati, F.; Daniel, F. Understanding Mashup Development. IEEE Internet Comput. 2008, 12, 44–52. [Google Scholar] [CrossRef]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl. Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Xu, W.; Cao, J.; Hu, L.; Wang, J.; Li, M. A Social-Aware Service Recommendation Approach for Mashup Creation. In Proceedings of the 2013 IEEE 20th International Conference on Web Services, Santa Clara, CA, USA, 28 June–3 July 2013; pp. 107–114. [Google Scholar] [CrossRef] [Green Version]
- Liang, T.; Chen, L.; Wu, J.; Dong, H.; Bouguettaya, A. Meta-Path Based Service Recommendation in Heterogeneous Information Networks. In Proceedings of the Service-Oriented Computing—14th International Conference (ICSOC 2016), Banff, AB, Canada, 10–13 October 2016; Lecture Notes in Computer Science. Sheng, Q.Z., Stroulia, E., Tata, S., Bhiri, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9936, pp. 371–386. [Google Scholar] [CrossRef]
- Xie, F.; Wang, J.; Xiong, R.; Zhang, N.; Ma, Y.; He, K. An integrated service recommendation approach for service-based system development. Expert Syst. Appl. 2019, 123, 178–194. [Google Scholar] [CrossRef]
- Xie, F.; Chen, L.; Lin, D.; Zheng, Z.; Lin, X. Personalized Service Recommendation With Mashup Group Preference in Heterogeneous Information Network. IEEE Access 2019, 7, 16155–16167. [Google Scholar] [CrossRef]
- Xie, F.; Chen, L.; Ye, Y.; Zheng, Z.; Lin, X. Factorization Machine Based Service Recommendation on Heterogeneous Information Networks. In Proceedings of the 2018 IEEE International Conference on Web Services (ICWS 2018), San Francisco, CA, USA, 2–7 July 2018; pp. 115–122. [Google Scholar] [CrossRef]
- Meng, S.; Dou, W.; Zhang, X.; Chen, J. KASR: A Keyword-Aware Service Recommendation Method on MapReduce for Big Data Applications. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 3221–3231. [Google Scholar] [CrossRef]
- Aznag, M.; Quafafou, M.; Jarir, Z. Leveraging Formal Concept Analysis with Topic Correlation for Service Clustering and Discovery. In Proceedings of the 2014 IEEE International Conference on Web Services (ICWS 2014), Anchorage, AK, USA, 27 June–2 July 2014; pp. 153–160. [Google Scholar] [CrossRef]
- Bai, B.; Fan, Y.; Tan, W.; Zhang, J. DLTSR: A Deep Learning Framework for Recommendations of Long-Tail Web Services. IEEE Trans. Serv. Comput. 2020, 13, 73–85. [Google Scholar] [CrossRef]
- Shi, M.; Tang, Y.; Liu, J. Functional and Contextual Attention-Based LSTM for Service Recommendation in Mashup Creation. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 1077–1090. [Google Scholar] [CrossRef]
- Yao, L.; Sheng, Q.Z.; Segev, A.; Yu, J. Recommending Web Services via Combining Collaborative Filtering with Content-Based Features. In Proceedings of the 2013 IEEE 20th International Conference on Web Services, Santa Clara, CA, USA, 28 June–3 July 2013; pp. 42–49. [Google Scholar] [CrossRef]
- Yao, L.; Sheng, Q.Z.; Ngu, A.H.H.; Yu, J.; Segev, A. Unified Collaborative and Content-Based Web Service Recommendation. IEEE Trans. Serv. Comput. 2015, 8, 453–466. [Google Scholar] [CrossRef]
- Jain, A.; Liu, X.; Yu, Q. Aggregating Functionality, Use History, and Popularity of APIs to Recommend Mashup Creation. In Proceedings of the Service-Oriented Computing—13th International Conference (ICSOC 2015), Goa, India, 16–19 November 2015; Lecture Notes in Computer Science. Barros, A., Grigori, D., Narendra, N.C., Dam, H.K., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9435, pp. 188–202. [Google Scholar] [CrossRef]
- Xiong, R.; Wang, J.; Zhang, N.; Ma, Y. Deep hybrid collaborative filtering for Web service recommendation. Expert Syst. Appl. 2018, 110, 191–205. [Google Scholar] [CrossRef]
- Ma, Y.; Geng, X.; Wang, J. A Deep Neural Network With Multiplex Interactions for Cold-Start Service Recommendation. IEEE Trans. Eng. Manag. 2021, 68, 105–119. [Google Scholar] [CrossRef]
- Gao, W.; Chen, L.; Wu, J.; Gao, H. Manifold-Learning Based API Recommendation for Mashup Creation. In Proceedings of the 2015 IEEE International Conference on Web Services (ICWS 2015), New York, NY, USA, 27 June–2 July 2015; pp. 432–439. [Google Scholar] [CrossRef]
- Gao, W.; Chen, L.; Wu, J.; Bouguettaya, A. Joint Modeling Users, Services, Mashups, and Topics for Service Recommendation. In Proceedings of the IEEE International Conference on Web Services, ICWS 2016, San Francisco, CA, USA, 27 June–2 July 2016; Reiff-Marganiec, S., Ed.; pp. 260–267. [Google Scholar] [CrossRef]
- Wei, X.; Zhao, W.; Bing, L.; Bo, H. Automating Mashup service recommendation via semantic and structural features. Math. Probl. Eng. 2020, 2020, 4960439. [Google Scholar] [CrossRef]
- Wang, X.; Wu, H.; Hsu, C. Mashup-Oriented API Recommendation via Random Walk on Knowledge Graph. IEEE Access 2019, 7, 7651–7662. [Google Scholar] [CrossRef]
- Wang, X.; Liu, X.; Liu, J.; Chen, X.; Wu, H. A novel knowledge graph embedding based API recommendation method for Mashup development. World Wide Web 2021, 24, 869–894. [Google Scholar] [CrossRef]
- Dang, D.; Chen, C.; Li, H.; Yan, R.; Guo, Z.; Wang, X. Deep knowledge-aware framework for web service recommendation. J. Supercomput. 2021, 77, 14280–14304. [Google Scholar] [CrossRef]
- Nguyen, M.; Yu, J.; Nguyen, T.; Han, Y. Attentional matrix factorization with context and co-invocation for service recommendation. Expert Syst. Appl. 2021, 186, 115698. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, H.; Kuang, L. A Web API Recommendation Method with Composition Relationship Based on GCN. In Proceedings of the IEEE International Conference on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom 2020), Exeter, UK, 17–19 December 2020; pp. 601–608. [Google Scholar] [CrossRef]
- Lian, S.; Tang, M. API recommendation for Mashup creation based on neural graph collaborative filtering. Connect. Sci. 2021, 1–15. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Le, Q.V.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the 31th International Conference on Machine Learning (ICML 2014), Beijing, China, 21–26 June 2014; Volume 32, pp. 1188–1196. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Chen, L.; Xie, Y.; Zheng, Z.; Zheng, H.; Xie, J. Friend Recommendation Based on Multi-Social Graph Convolutional Network. IEEE Access 2020, 8, 43618–43629. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 39. [Google Scholar]
- Järvelin, K.; Kekäläinen, J. Cumulated gain-based evaluation of IR techniques. ACM Trans. Inf. Syst. 2002, 20, 422–446. [Google Scholar] [CrossRef]
- Su, X.; Khoshgoftaar, T.M. A Survey of Collaborative Filtering Techniques. Adv. Artif. Intell. 2009, 2009, 421425. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics | Value |
|---|---|
| Number of mashups | 6300 |
| Number of services | 21,474 |
| Number of services composed by mashup | 1609 |
| Average number of services in mashup | 2.07 |
| Sparsity of mashup-service composition matrix | 99.87% |
| Number of tags | 312 |
| Average number of tags in mashups and services | 3.4 |
| Number of mashup-service interaction | 13,219 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, W.; Wu, J. Multi-Relational Graph Convolution Network for Service Recommendation in Mashup Development. Appl. Sci. 2022, 12, 924. https://doi.org/10.3390/app12020924
Gao W, Wu J. Multi-Relational Graph Convolution Network for Service Recommendation in Mashup Development. Applied Sciences. 2022; 12(2):924. https://doi.org/10.3390/app12020924
Chicago/Turabian StyleGao, Wei, and Jian Wu. 2022. "Multi-Relational Graph Convolution Network for Service Recommendation in Mashup Development" Applied Sciences 12, no. 2: 924. https://doi.org/10.3390/app12020924
APA StyleGao, W., & Wu, J. (2022). Multi-Relational Graph Convolution Network for Service Recommendation in Mashup Development. Applied Sciences, 12(2), 924. https://doi.org/10.3390/app12020924