Abstract
This article builds a systematic and reliable site selection prediction model for a chain of convenience stores (CVSs) to improve the existing decision method of using experienced managers to select sites. Specifically, this study used an artificial neural network (ANN) technique—back-propagation neural network (BPN)—to build the prediction model. To achieve optimization in executing the BPN, the Taguchi method (TM) was adopted to find the optimal parameters for the BPN. The actual data from a chain of CVSs was employed to validate the model. The results indicated that the prediction accuracy rate and decision quality of the proposed model were higher than those of the existing manager-directed decision method. With intense retail competition, the accurate determination of the location of a new convenience store (CVS) is vital to its success. This study asserts that with systematic and scientific assessment, the site selection decision for new chain CVSs will be less human-biased in nature if the prediction model is used as an auxiliary decision-making tool.
1. Introduction
In general, the selection of the site of a new retail store is markedly different from the selection of a site for manufacturing facilities. The decision over the latter is primarily focused on cost minimization. Retail stores, however, generally seek to maximize revenues.
A review of the limited literature on store site selection revealed that most germane studies use the following methods for site selection: analytic network process (ANP) [1,2], analytic hierarchy process (AHP) [3,4], quantitative methods, such as regression models [5], and weighted scores with the use of checklists [6]. This previous work mainly attempts to identify the influencing factors and obtain the weights of these influencing factors when establishing new stores. In addition, the results of these investigations provide limited assistance vis-à-vis the practical site selection problem. In recent years, use of artificial neural networks (ANNs) for site selection has been shown to be especially effective in various venues, such as the locations of wind farms [7], landfills [8], water waste [9], and CVSs [10]. Currently, the selection of a specific site is comprehensive in practice. The location selection techniques that use ANNs solve the problem for a region but not for a specific site. Therefore, the results obtained from an ANN are not comprehensive, and the reference value they provide is limited.
Our study employed an ANN technique—a back-propagation neural network (BPN)—to generate suitable CVS site selection criteria from various inputs collected from a well-known CVS chain in Taiwan. To establish a set of robust site selection prediction models with the BPN, the Taguchi method (TM) [11] was adopted to identify the optimal parameters for performing the BPN.
2. Literature Review
Site selection is a crucial decision for most businesses, including those in retailing, the service industry, and manufacturing [12]. It has a consequential impact on profitability and is a valuable strategic tool for chain store operations. Site selection involves more than merely selecting a site with good visibility and accessibility [13]; accordingly, it requires a thorough evaluation process.
Competition, demographics (i.e., prospective customers in the area), and market demands must also be considered [14]. For example, a site requires an adequate number of vehicles to pass by each day. Additionally, the availability of convenient parking is often an essential consideration, well as the definition and evaluation of competition near the proposed site. In fact, the number of competitors near a site can be a double-edged sword: competitors may attract crowds to the area yet also offer severe competition [15]. There may also be neighborhood changes, traffic changes, natural barriers, and human-made obstacles at the site [16]. Therefore, a robust and systematic design system for a store’s, site selection is essential, especially because of the dynamism in the store and business environments.
In addition to the above issues, the impact of site location on a firm’s financial metrics is important. Ganesha et al. [17] and Aversa et al. [18] investigated the variance in store performance with respect to customer expenditure, as well as store operating costs, earnings, profits, and legal/fiscal factors. They found that these data significantly reflected the different commercial sectors of retail stores.
Kuo et al. [6] proposed three traditional assessment methods for determining and selecting store location: the checklist method, the simulation method, and multiple regression analysis. These methods can provide systematic steps for screening store locations. However, they fail to consider the relationship among all the influential factors involved in the decision. Recently, analytic solutions through the use of big data have been prevalent in solving business problems, including retail store site selection. Focusing on data-driven decisions—due to the advent of ICT (Information and Communication Technology)—enables decision makers to overcome the traditional challenges of brick-and-mortar retail store site selection. Moreover, data on customer behaviors sourced from social media, customer surveillance data within stores, and customer mobile data through use of retailers’ mobile applications, as well as street varieties, should also be considered in site selection, yet it tends to receive less attention [19,20,21].
Mendes and Themido [22] emphasized that the most important decision a retailer makes is the selection of an appropriate location to ensure retailing success. However, Hernández and Bennison [5] argued that, although techniques for locational analysis have been available for over 50 years, regrettably, most retailers traditionally do not apply these techniques in practice. Instead, they chiefly rely on intuition and judgment guided by experience and “common sense”. Compounding the problem are the fact that the operation of a retail store is heavily affected by site factors and that the quality of decision-making skills in choosing the trade area are related to the extent of their development [23].
The above discussion suggests that the determination of site-selection criteria for CVSs is not definite. Rather, it is dependent on store structure, store environment, business district, choice of inventory, corporate culture, and business model [4,13,24]. As noted above, the conventional approaches in this field include managers’ judgment—based simply on knowledge and experience—the checklist approach, the analog method, regression models, and simulation [16,25,26]. These alternatives only provide a set of systematic steps for problem-solving but do not adequately deal with the relationship among the decision factors. Their weaknesses are described below.
With the checklist approach, managers use several criteria that may influence store performance and/or be determined from business strategies [27]. The focus of the determination of these criteria is on potential sales at the site. Consequently, the values for all criteria are evaluated based on either a company “rule” (e.g., standard operating policy, previous benchmarks, ex ante decision) or subjective judgments by decision makers. A decision might thus be made by assessing the tradeoffs among all the candidate sites or simply using judgment.
The analog method [28] searches for similarities based on a variety of pre-determined properties observed in existing stores and considers the requisite criteria from all these sites. The selected site is the one matching the criteria in extant successful outlets. Although the analog approach follows a systematic guideline to select worthy sites [6], the procedure generally relies on personal experience and instinct [5]. Because there are variations in the circumstances of the sites, identifying similarities, or presumed similarities, for the various locations is infeasible.
Regression models are another alternative for use in site selection. To identify statistically the factors that influence pre-determined business performance, this method provides a sound framework for site selection. However, it has several key limitations: the potential ignorance of multicollinearity among the independent variables, the requirement for sufficient data size, concerns about the validity of the distribution assumption, and an imbalance problem between different data sources, all of which can lead to analytical bias or skewness from unrevealed facts.
The simulation model inputs predefined variables with parameters into a framed system—such as pedestrian behavior—to discover their relationship with store sites and transports for the purpose of finding recurring patterns of customer links to business establishments. The major drawback of simulation is the associated difficulty of framing all the variables in practical cases—in particular, the firm’s customers’ behaviors and environments.
As discussed above, an increasing number of site studies employ multi-criteria decision-making procedures, such as AHP, ANP, and ANN. Recent research has shown that the applications of ANN techniques in the decision-making domain are promising (e.g., [6]). By overcoming the multicollinearity problem, the ANN model achieves good results in evaluating and ranking alternatives. The trainability and applicability of ANN techniques to address the problems of multi-attribute utility have also been confirmed.
Erbıyık et al. [3] defined the location selection criteria of a retail store and used the AHP to establish a selection model. Roig-Tiern et al. [4] developed a methodology for the process of selecting a retail site location that combined geographic information systems (GIS) with the AHP. They found that the success factors for a supermarket were related to its location and competition. Some scholars have focused on ascertaining the weights of the factors influencing site selection by using the AHP [3,4] or ANP [1,2]. These two methods were mainly used to identify factors influencing site selection or determine the weights of these factors. Such methods are relatively subjective, and their reference value is limited.
In the application of an ANN in site location selection, Abujayyab et al. [8] proposed a model of a four-stage geospatial site selection (GSS) theory and architecture and used ANN techniques with two metrics, a confusion matrix and receiver operational characteristics, to verify the model. The findings indicated that the ANN provides reasonable and effective results. An example is given by Fallah et al. [9]. They found that the location of a wastewater treatment plant required the consideration of multiple spatial data. They constructed a multi-level criteria table with reference to various spatial data and then used the AHP to weigh the criteria according to expert opinions. They then applied the ANN for each criterion test. The results showed that a very high correlation coefficient of the neural network was able to identify suitable regions. In selecting the right region for a wind farm, Pokonieczny [7] utilized the ANN by taking into account the criteria related to the profitability of the power plant and the assumption of public interest. Studies have shown that a properly trained neural network can process an automation area classification in terms of placement on wind turbines. Moreover, based on an assessment of the relationship between the environmental attributes of existing retail stores and their financial rankings, Satman and Altunbey [10] combined Google Places API and ANN to resolve the selection of the locations of retail stores within a given radius. They then applied this method to the location selection of a Turkish retail chain. They found that this method was highly applicable in similar situations.
Although the above work, using the location selection method established using ANN technology, is valuable, it discerned the selected location for a region rather than a specific site selection. This selection needs to consider the situation of the trading area, including the site area’s target market income, competition, and people flow, as well as whether the values of these metrics satisfy the expected performance after opening the store. It is notable that the factors considered in site selection entail a comprehensive analysis, but the information obtained in the aforementioned literature fails to provide such comprehensiveness. This situation may well explain why site selection continues to be predicated on experienced mangers’ evaluation efforts.
Current site selection processes thus need enhancement and marked improvement. Therefore, in this paper, we develop an objective site selection prediction model store expansion. The data from a chain of CVSs are used to verify the accuracy rate by using the established prediction model.
3. Methodology
ANNs have been widely applied to build prediction models in various fields [29,30]. The BPN network of an ANN is a typical prediction model application. Therefore, we adopted the BPN network to calculate the results. This required considerable time to set the parameters. Therefore, to obtained the best parameter design; the TM was also applied in combination with BPN to analyze the data.
3.1. BPN Network
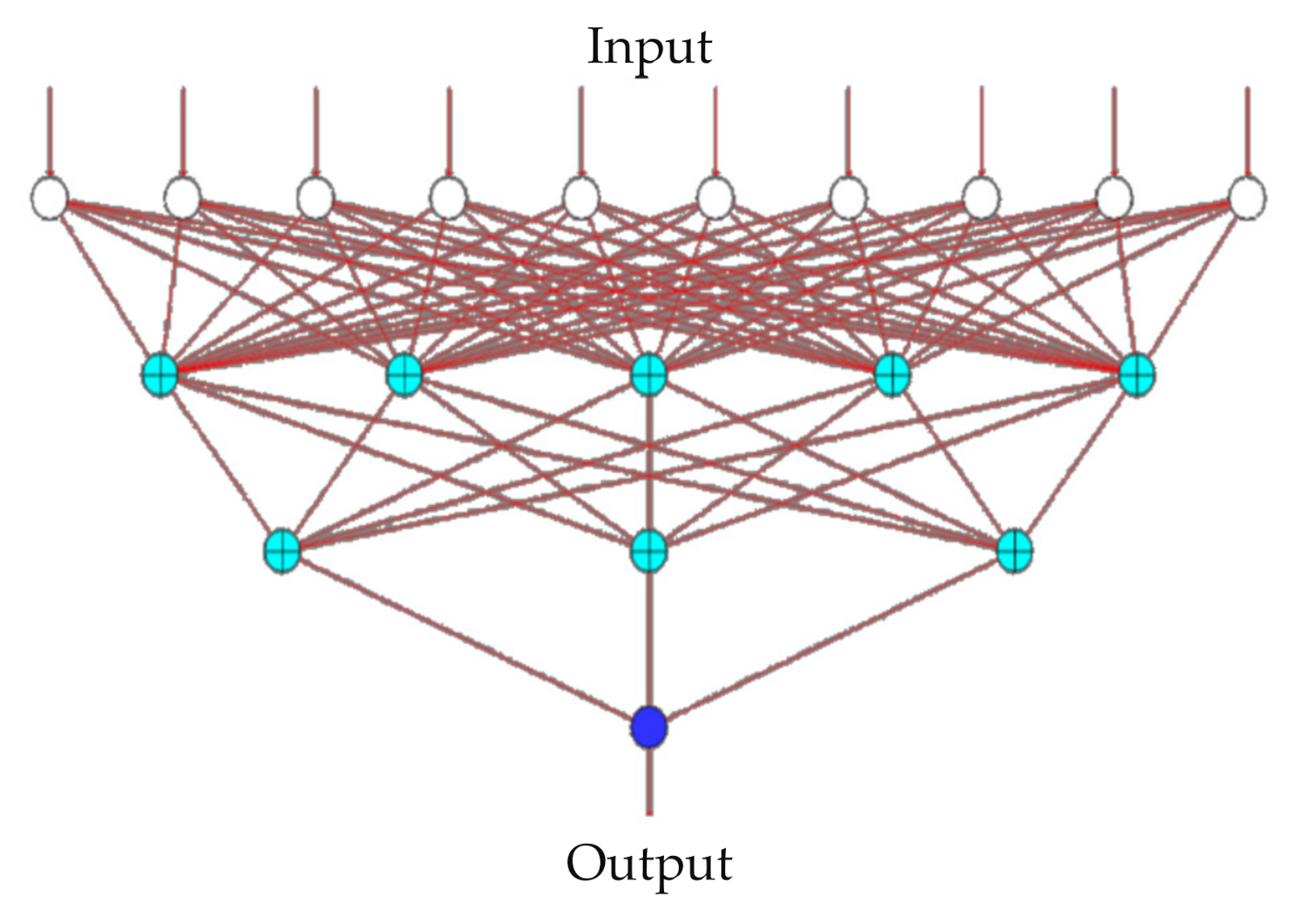
ANNs generally consist of input, output, and procession layers (called hidden layers, as depicted in Figure 1). The basic settings used to construct a BPN are the procession units: the number of hidden layers with the number of nodes at each one.
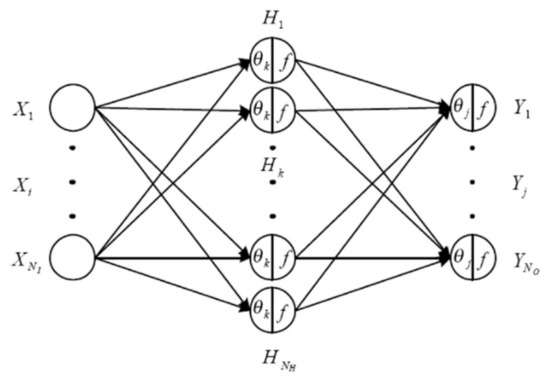
Figure 1.
Illustration of BPN.
Several indicators—usually root-mean-square error (RMSE) and error rate—are used to test the reliability of a network and the validity of its structure. Its learning process is used to adjust network-linking weights by applying the learning algorithm from the input data, as well as the error function, which is adopted to measure the learning effect of the BPN. When the BPN’s leaning process finishes, the minimum error—which represents the maximum predicting accuracy—is expected. Its architecture is shown in Figure 1 [31].
- Yj: output data;
- f: transfer function;
- Wij: weighting of connecting node i to node j;
- Xi: input data;
- θj: threshold.
The learning process of a neural network requires the collection of data in advance. Collected samples must be divided into two parts: samples for training and samples for testing. In the network learning phase, learning can be conducted repeatedly until it converges with the network training. In terms of the network test, some indicators may be used as a basis, such as the root-mean-square error (RMSE) and the error rate.
A neural network consists of the above-mentioned input layer, a hidden layer, and an output layer. The learning process is used to adjust the weights of the network links using the learning algorithm from the learning samples. The error function is used to measure the network learning effect. The network learning process is also a process of minimizing the error function, as the smaller the error, the higher the prediction accuracy. Furthermore, the error is generally expected to be minimized as much as possible.
In terms of the BPN, five important parameters must be set: neural network design, learning iterations, learning rate, momentum term, and transfer function. These parameters do not have a clear set of values. Only approximate guidance can be provided, based on the complexity of the issues and the level of noise. The parameters are generally set through trial and error and other data-mining methods. The setting of all parameter values causes a considerable impact on the performance of the network, which is described below.
3.2. TM
The TM, otherwise known as the process robustness study [32] or design of experiment (DOE), in the West, are prevalent in the field of quality engineering and have been shown to be capable of identifying critical factors influencing poor product quality in manufacturing processes. The TM is a low-cost and high-benefit experimental method that provides improvement of product quality through design rather than testing. It allows the design of fewer experimental profiles and conducts experiments using less time and with lower costs to achieve quality optimization. To reduce the number of experiments, an appropriate experiment orthogonal array table based on control factors and the number of levels must be chosen. The objective of the design is to seek optimization and maintain the robustness of the research content by minimizing the effects of the variation of the influencing factors [33].
In particular, the S/N ratio is defined as the ratio of the average value (signal) to the standard deviation (noise). The larger the value, the better the quality. The S/N ratio can be used as a statistical measurement in the Taguchi experiment, and it can also be employed to examine the impact on product quality under different level factors and noise factors. It can be divided into the following three different patterns in terms of different engineering issues: nominal-the-best (NTB), smaller-the-best (STB), and larger-the-best (LTB) [34].
For the NTB, the S/N ratio is , where , , and is the average for all experiments. The NTB index is applicable to the cases that are expected to obtain certain performance characteristics.
For LTB, the S/N ratio is . The LTB index is for the cases of maximizing the performance characteristics.
For STB, the S/N ratio is . The STB index is suitable for the cases of minimizing the performance characteristics. The STB index is adopted in this study, as the smallest RMSE is the best for the BPN models.
After calculating the S/N ratio for each experiment, each criterion is obtained by taking the average of all the S/Ns within the criterion in accordance with the designed orthogonal array.
The main purpose of the TM is to acquire the best information based on fewer experiments, choose the appropriate orthogonal array table based on the control factors and number of levels, and plan a complete experimental scheme to execute the data from the information obtained. The symbol of an orthogonal array table is generally , where L refers to the Latin square; a to the number of experiments; b to the number of levels of control factors; and c to the total number of control factors. The inner product in any two lines in the orthogonal array table is zero, and the average effect between factors reaches an equilibrium state. In the application of the orthogonal array table, experiments were conducted based on the configured profiles in the table; the experiments were performed repeatedly to show objectivity. In the case of uncontrollable interference factors, the combination of two orthogonal array tables was applied to place interference factors in the external table and enhance the accuracy of the experiment. For a more detailed description of TM, please refer to Wu [18].
4. Case Study
In this section, a CVS site selection prediction model is established—based on actual collected data—by applying BPN in accordance with the research architecture and the method described in Section 3. To establish a robust prediction model, the TM is applied to identify the optimal parameters for the execution of the BPN.
4.1. Data Collection
First, the determinate factors for a new chain of convenience stores in this real case included nine input data items: trade area characteristics (A) (A1—residential area and A2—commercial area), competitiveness of other CVSs (B), competitiveness of supermarkets (C), people flow (D), major customer type (E), number of households within a radius of 100 m (F), store location (G), visibility (H), and usable area (I) (as defined in Table 1). We then collected the data of the nine factors from 96 new stores of a well-known CVS chain store in Taiwan (see Table 2).

Table 1.
Definitions of site selection assessment indicators.
Table 2.
Training network data table.
The existing evaluated model was based on the idea that the initial prediction turnover of a new store is obtained based on the sum of each of the actual data factors of the nine determinants times the given weight of each determinant. Whether a new store is a success is based the actual turnover. If the value of the predicted turnover/average actual turnover per day over an operational period of six months is higher than 90% (0.9), then the new store is defined as a success; otherwise, it is a failure. For instance, the prediction score form of Store 1 is shown in Table 2. The scores for factors B, C, D, E, F, G, and H are 100, 60 × (20 + 35 + 5), 11.7 × (6.6 + 5.1), 100, 17.2, 80 × (30 + 50), and 50 respectively (Table 3), and we can estimate the number of visitors at 914.5—based on the weightings of the residential area (Factor A) (Table 4). Therefore, the predicted turnover/per day is 914.5 × 70 (customer price of residential area) × 1.1 (Factor I: the area of store 1 is greater than 100 square meter) = 70,400. Finally, we can predict the daily turnover of each store and collect the average actual daily turnover for six months from the 96 new stores, as summarized in Table 5.
Table 3.
Scores of the factors.
Table 4.
Prediction of the number of visitors.
Table 5.
Difference between predicted daily turnover and actual daily turnover.
As shown in Table 5, the average actual daily turnover per month over six months in Store 1 is 55,023, and the ratio of the predicted daily turnover/average actual daily turnover is 0.78. If this value is smaller than 0.9, then the new store is defined as a failure. As depicted, the average difference between the actual daily turnover and the predicted daily turnover was $NTD 12,061/per store and the RMSE reached $NTD 10,188. A total of 53 stores were successful (defined as the predicted turnover/actual turnover is higher than 0.9), and the success rate (or prediction accuracy rate) was 55% (as shown in Table 5). This study used a BPN network to validate whether further reducing the error and improving the prediction accuracy rate for a new store would be possible. The major differences between the predicted and actual turnovers can be attributed to one major set of reasons. Based on one of the managers involved in the site selection decision in this CVS company, the store personnel’s operating stabilities, the store’s management style, and the inventory principles essentially contributed to the turnover of their CVSs. However, at the time of data analysis, such variation was not yet recognized in the data sources for the CVS site selection. This issue is discussed in the last section of this paper.
4.2. Neural Network Parameter Design
BPN networks are nonlinear models. Therefore, algorithm mode was used to approach the best linked weighted value and the bias value by means of performing iterations. In the experiment, a computer program was developed using a Qnet BPN with 10 types of input data: residential area (X1), commercial area (X2), competitiveness of CVSs (X3), competitiveness of supermarkets (X4), people flow (X5), major customer type (X6), number of households within a radius of 100 m (X7), store location (X8), visibility (X9), and usable area (X10). The output data were the actual daily turnover (Y1). The five most important factors influencing the BPN network design were (A); learning iterations (B); learning rate (C); momentum term (D); and transfer function (E). In terms of the prediction result of the BPN network, the smaller the error, the better the result. Therefore, the smaller-the-better (STB) of the S/N ratio of TM was used. In the TM, an orthogonal array table of (as in Table 6) was chosen, and the above five control factors were placed into Table 6 to shorten the time for the experiment.
Table 6.
L16(45) Orthogonal Array.
Because there was no defined method for setting the parameters of the neural network, the distribution principles of the levels of factors were as follows:
- Neural network design (number of units in the hidden layer)
Based on the specified principle, the number of first hidden nodes was designed by applying the method of averaging (number of units in the input layer + the number of units in the output layer)/2, the method of summation (the number of units in the input layer + the number of units in the output layer), and the number of second hidden nodes, designed by applying a radical of the number of input layers × the number of output layers.
- 2.
- Learning iterations
Based on general principles, 1000; 3000; 6000; 10,000; and other intervals were set as the average value.
- 3.
- Learning rate and momentum term
The learning rate and the momentum term would affect the correction of the weighted value of the network and cause adverse effects on the convergence effect of the network if they were too big or too small. Based on the experience values, the learning rate was set between 0.1 and 1. Values with equal intervals, such as 0.1, 0.4, 0.7, and 0.9, were adopted in this research.
- 4.
- Transfer function
The transfer function was designed based on the four functions provided in the Qnet97 for Window Software (Version 1.0).
The distribution of the levels of the factors is shown in Table 7.
Table 7.
Distribution list of the levels of factors of the neural network.
4.3. TM Analytical Results
In this study, the “bigger-the-best” characteristic was employed, as the MD between the normal and abnormal groups was the “larger-the-better” in order to be significantly distinguished. For each test, followed by the factor setting in the orthogonal array (as in Table 6), an S/N ratio was obtained (listed in Table 8). The factorial effect of each factor was hence calculated and shown in Table 9. A total of three folders were created, and three sets of data were used to calculate the S/N (signal-to-noise ratio) value. The root-mean-square error (RMSE) of the results of each experiment was calculated using the RMSE of the test set; ten-folder cross validation for the ANN was then used repeatedly to calculate the S/N. In total, 16 experiments were conducted, as shown in Table 8, to respectively record the errors of the simulation results for the BPN network. The RMSE of the test data was used to obtain the average value of the error, and the S/N ratio in each experiment was obtained based on the STB characteristic (see Table 8).
Table 8.
Experiment error data.
Table 9.
S/N ratio factor response list.
According to Table 8, the highest S/N ratio (23.6575) was observed in the third experiment and involved factors A1, B3, C3, D3, and E3. However, from the S/N ratio factor response list (Table 9), the transfer function was mostly affected by effect and rank factors and levels, followed by the learning rate.
As shown in Table 9, the optimal parameter combination consisted of A3, B2, C3, D2, and E3. According to the combination of A3, B2, C3, D2, and E3, we split the training network data in Table 5 into three sets in the order 1–25, 26–50, 51–75, and carried out the optimal combination of BPN three times. The S/N ratio was 16.2946 and the 95% confidence interval was calculated as 14.253997–18.415372, which was confirmed to be within the confidence interval. The data are shown in Table 10.
Table 10.
The results of experience of optimal parameters.
Therefore, to verify the combination of the optimal parameters, we utilized the two combinations to obtain the S/N ratio (see Table 11). As shown in Table 11, we found that the combination of A3, B2, C3, D2, and E3 had a larger S/N ratio.
Table 11.
S/N ratio of reverification.
Therefore, the optimal parameter combination consisted of A3, B2, C3, D2, and E3, respectively, including the neural network design (five nodes in the first hidden layer and three nodes in the second hidden layer), learning iterations (3000), learning rate (0.7), momentum term (0.4), and transfer function (hyperbolic tangent), respectively. Based on the above optimal parameter design result of the BPN, the network architecture was, therefore, designed (see Figure 2).
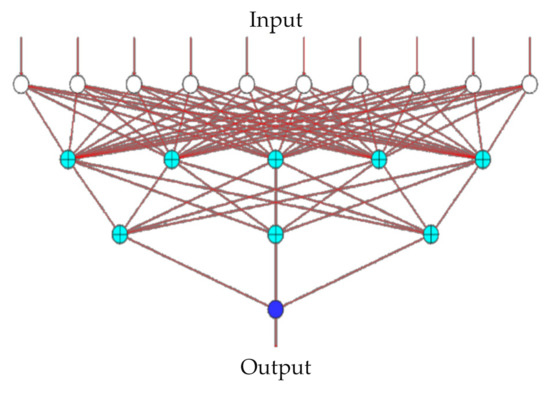
Figure 2.
Network design architecture diagram.
4.4. Experimental Results and Validation
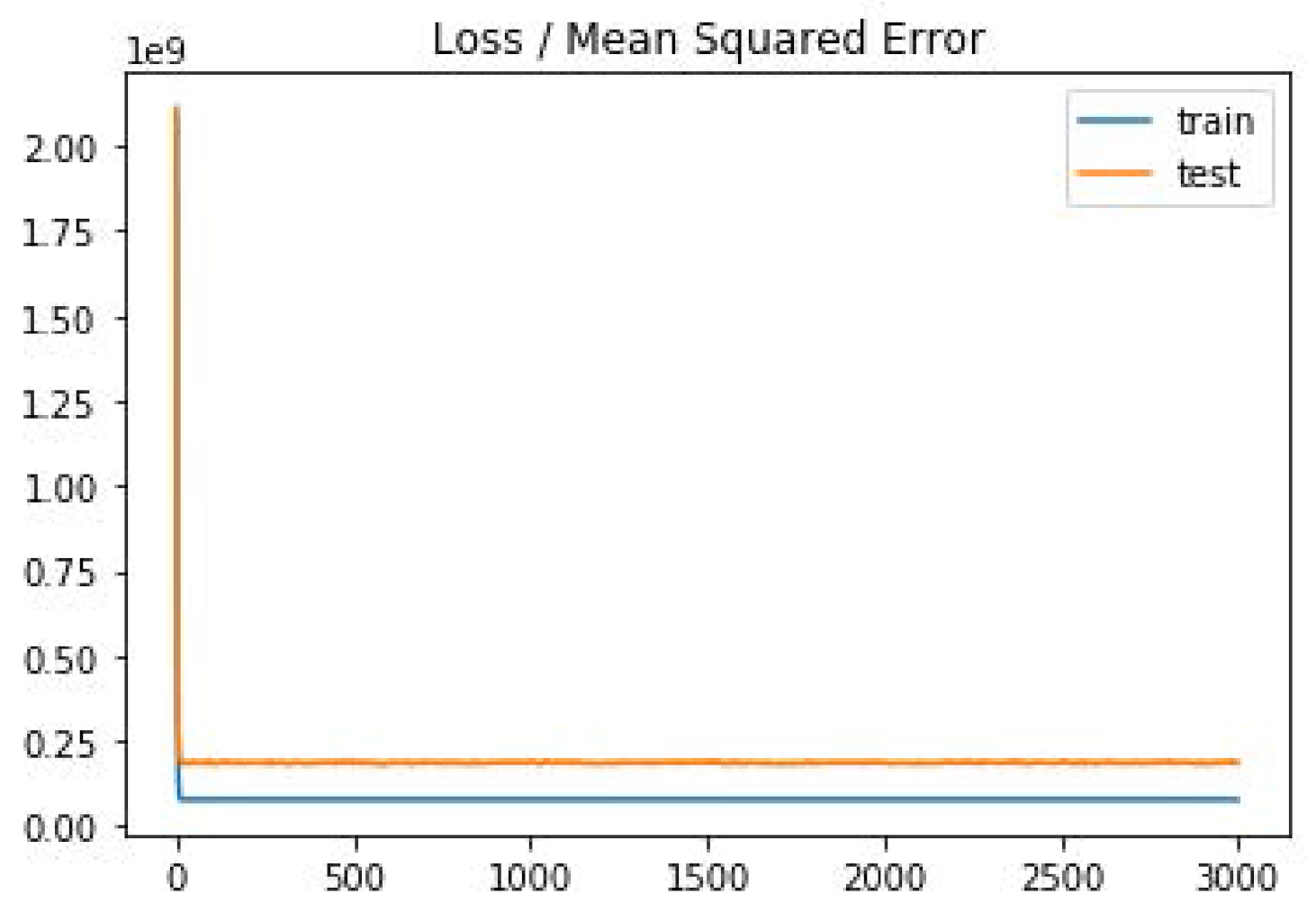
This research obtained the weights and deltas from the BPN Software (Qnet97 for Window, Version 1.0) according to the above-mentioned best parameter conditions and training and imported 96 sets of data for validation. It then deduced the results, as shown in Figure 3 and Table 12. As shown in Figure 3, the MSE became stable with reasonable convergence, so there was no over-fitting problem. As shown in Table 12, the RMSE, MAE, and MSE of the 96 sets of data obtained and validated with optimized weighted values and biases were reduced to 9810, 7750, and 96,229,425, respectively. Compared with the RMSE (15,791), MAE (12,155), and MSE (249,363,237) of the original data, the error rate was reduced by 38% (RMSE), 36% (MAE), and 61% (MSE), respectively. A total of 62 stores was thus successful in the prediction, resulting in an accuracy rate of up to 65%. Compared with the accuracy rate (55%) of the original data, the accuracy rate increased by 18.2%. Therefore, the results indicated that the proposed prediction model had a higher success rate and lower RMES value; the proposed prediction model therefore provides a valuable reference for the industry. In summary, we found that the chances of success in establishing a new store were improved through the analysis of the objective data using the store site selection prediction model established in this research.
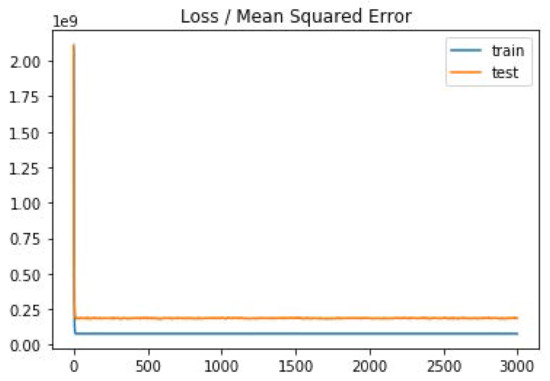
Figure 3.
Mean squared error. (Note: le9 = 1 × 109).
Table 12.
Actual deduction results.
4.5. Robustness Evaluation
To evaluate the robustness of the proposed method, different numbers of training instances were used to assess the performance of the ANN-TM prediction models. The results were evaluated based on four considered numbers of training examples: 16, 32, 48, and 64, respectively. Table 13 summarizes the “success rate” for the prediction data of the ANN-TM method. As shown in the table, when there were more training samples, the success rate increased. However, the increase in the success rate gradually decreased.
Table 13.
Robustness evaluation.
5. Conclusions
The structure of the parameters of a neural network determines the network’s predictive reliability and validity. This study employed a robust experimental design, the TM, to BPN training to efficiently derive the optimal CVS site-selection decision model for the case company. Site-selection methods developed solely using an ANN methodology require time- and cost-intensive effort. In this study, combined with the TM’s experimental design and the S/N ratios to evaluate performance, the BPN decision model confirmed that valid results can be obtained with fewer experiments. The TM can reduce the number of times required for the determination of the BPN for improved convergence and fewer network errors. We assert that with systematic assessment, site selection for a new chain of CVSs can be performed with reduced human bias. The actual operational data of a well-known chain of CVSs was used here to validate the site selection prediction model built in this paper. The results indicated that the predicted accuracy rate and the decision quality of the proposed prediction model were higher than those obtained from the existing decision method of using experienced managers.
The combined application of ANN and TM to a retail business in this study represented a pilot in both the TM application and site selection literature. This study adopted the TM to identify important criteria for the BPN site selection prediction model. By using data from a well-known Taiwanese CVS chain, we provided a valuable and practical alternative and thus contributed knowledge about chain CVS site-selection decision-making. The deviation of the case company’s actual sales from its sales forecast implied an unsuccessful site selection decision. For chain corporations in Taiwan, site selection criteria are usually employed using similar principles for each criterion—such as types of patron, business area, and location environment. Since the advent of analytical techniques, Taiwanese retailers have tended to apply contemporary advanced data analysis methodologies in their practices; ANNs, for example, are popular. However, with limited knowledge regarding such analytic solutions and a keen desire to achieve efficiency and effectiveness in retail businesses, this study proposed an approach that can enable Taiwanese chain CVSs to appropriately solve site-selection problems.
The managerial implication of applying retail site selection studies is that companies should make efforts to review the feasibility and applicability of the requisite factors for building ANN prediction models. This study demonstrated this in the case company. It is necessary to debrief and re-examine current CVS site location evaluation procedures, including the effective criteria and their scales, based on the predictive accuracy of the ANN procedure. Nonetheless, the definition of successful and unsuccessful CVSs is not unique within the case company. Generally, a successful CVS is defined as one that achieves its revenue and/or other goals. Some unsuccessful CVSs may be considered successes when their actual sales are much higher than the original forecast. Hence, classifying successful and unsuccessful retail stores for BPN analysis is crucial. The approach presented in this study assists in building a systematic design of the BPN predictive model to reduce the cost, time, and personnel involved in the site selection process. The purpose of this study was not to determine the “definite” predictive model for CVS site selection across all CVSs. Other criteria may be more salient in site selection in other business areas or cities.
In addition, as shown in Table 5, there were major differences between the actual turnover and the predictions. This demonstrates the limitation that the source data were collected or encoded by subjective judgements, as the data fields were still treated as important and indicative of store site-location determinants. For future work, this study can be extended by using other prediction tools to build the prediction model to observe the difference. Furthermore, this study was based on one chain CVS in Taiwan; different chain CVSs might have different prediction models. Therefore, this study can be extended by using data from various sources: big data, direct customer behaviors from the Internet of Things (e.g., actual traffic, types of patron, customer travel routes within stores), indirect customer behaviors (e.g., responses on social media, customer mobile behaviors via apps), and store operations (e.g., store personnel working mode, management style, stocking strategy).
Author Contributions
All authors contributed to this manuscript. Conceptualization, T.-H.C.; methodology, T.-H.C., H.-P.Y. and H.-P.F.; writing—original draft preparation, H.-P.F.; writing—review and editing, T.-H.C., H.-P.Y. and H.-P.F.; investigation, Y.-H.T. and C.-C.T.; data curation, Y.-H.T.; visualization, C.-C.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially supported by the Ministry of Science and Technology, Taiwan, R.O.C. (MOST-106-2410-H-327-008).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sharing not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lee, W.I. The Use of Analytical Network Process (ANP) in Selecting the Location of Convenience Stores. Master’s Thesis, National Chin-Yi University of Technology, Taichung, Taiwan, 2011. [Google Scholar]
- Chou, S.P. Analysis of Chinese Restaurant Location in Taipei Urban Area. Master’s Thesis, National Taipei University of Technology, Taipei, Taiwan, 2011. [Google Scholar]
- Erbıyık, H.; Özcan, S.; Karaboğa, K. Retail Store Location Selection Problem with Multiple Analytical Hierarchy Process of Decision Making an Application in Turkey. Procedia-Soc. Behav. Sci. 2012, 58, 1405–1414. [Google Scholar] [CrossRef] [Green Version]
- Roig-Tierno, N.; Baviera-Puig, A.; Buitrago-Vera, J.; Mas-Verdu, F. The retail site location decision process using GIS and the analytical hierarchy process. Appl. Geogr. 2013, 40, 191–198. [Google Scholar] [CrossRef]
- Hernández, T.; Bennison, D. The art and science of retail location decisions. Int. J. Retail Distrib. Manag. 2000, 28, 357–367. [Google Scholar] [CrossRef]
- Kuo, R.J.; Chi, S.C.; Kao, S.S. A decision support system for selecting convenience store location through integration of fuzzy AHP and artificial neural network. Comput. Ind. 2002, 47, 199–214. [Google Scholar] [CrossRef]
- Pokonieczny, K. Using artificial neural networks to determine the location of wind farms: Miedzna district case study. J. Water Land Dev. 2016, 30, 101–111. [Google Scholar] [CrossRef]
- Abujayyab, S.K.M.; Ahamad, M.S.S.; Yahyac, A.S.; Saad, A.M.H.Y. A new framework for geospatial site selection using artificial neural networks as decision rule: A case study on landfill sites. In Proceedings of the Joint International Geoinformation Conference, Kuala Lumpur, Malaysia, 28–30 October 2015; pp. 28–30. [Google Scholar]
- Fallah, M.; Vagharfard, H.; Farajzadeh, M.; Kheslat, N. Assessment of Spatial multi-criteria decision-making with process of the artificial neural networks Method to Site Selection of the Wastewater Treatment Plant (Case study: Qeshm Island). Int. J. Adv. Biol. Biomed. Res. 2014, 2, 2061–2066. [Google Scholar]
- Satman, M.H.; Altunbey, M. Selecting Location of Retail Stores Using Artificial Neural Networks and Google Places API. Int. J. Stat. Probab. 2014, 3, 67–77. [Google Scholar] [CrossRef]
- Khaw, J.F.C.; Lim, B.S.; Lim, L.E.N. Optimal design of neural networks using the Taguchi method. Neurocomputing 1995, 7, 225–245. [Google Scholar] [CrossRef]
- Rajiv, P.D.; Grünhagen, M. International franchising research: Some thoughts on the what, where, when, and how. J. Mark. Channels 2014, 21, 124–132. [Google Scholar]
- Teller, C.; Reutterer, T. The evolving concept of retail attractiveness: What makes retail agglomerations attractive when customers shop at them? J. Retail. Consum. Serv. 2008, 15, 127–143. [Google Scholar] [CrossRef] [Green Version]
- Widaningrum, D.L. A GIS-based approach for Catchment area analysis of convenience store. Procedia Comput. Sci. 2015, 72, 511–518. [Google Scholar] [CrossRef] [Green Version]
- Kaufmann, P.J.; Donthu, N.; Brooks, C.M. Multi-unit retail site selection processes: Incorporating opening delays and unidentified competition. J. Retail. 2000, 76, 113–127. [Google Scholar] [CrossRef]
- Goodchild, M.F. ILACS: A location-allocation model for retail site selection. J. Retail. 1984, 60, 84–100. [Google Scholar]
- Ganesha, H.R.; Aithal, P.S.; Kirubadevi, P. Ideal store locations for Indian retailers—An empirical study. Int. J. Manag. Technol. Soc. Sci. 2002, 5, 215–226. [Google Scholar] [CrossRef]
- Ahedo, V.; Santos, J.I.; Galán, J.M. Knowledge transfer in commercial feature extraction for the retail store location problem. IEEE Access 2021, 9, 132967–132979. [Google Scholar] [CrossRef]
- Aversa, J.; Doherty, S.; Hernandez, T. Big data analytics: The new boundaries of retail location decision making. Appl. Geogr. 2018, 4, 390–408. [Google Scholar] [CrossRef]
- Lin, G.; Chen, X.; Liang, Y. The location of retail stores and street centrality in Guangzhou, China. Appl. Geogr. 2018, 100, 12–20. [Google Scholar] [CrossRef]
- Rohani, A.M.B.M.; Chua, F.-F. Location analytics for optimal business retail site selection. In Proceedings of the Computational Science and Its Applications, ICCSA 2018, Melbourne, VIC, Australia, 2–5 July 2018. [Google Scholar] [CrossRef]
- Mendes, A.B.; Themido, I.H. Multi-outlet retail site location assessment. Int. Trans. Oper. Res. 2004, 11, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z.X.; Wang, M.Y.; Wang, Q.B. Retail Management; Wu Nan Publishing Co., Ltd.: Taipei, Taiwan, 2009. [Google Scholar]
- Li, L. Data visualization and retrieval based convenience store location model of fresh products. J. Digit. Inf. Manag. 2017, 15, 125–134. [Google Scholar]
- Achabal, D.D.; Gorr, W.L.; Mahajan, V. MULTILOC: A multiple store location decision model. J. Retail. 1982, 58, 5–25. [Google Scholar]
- Johnston, R.J.; Kissling, C.C. Establishment use patterns within central places. Aust. Geogr. Stud. 1971, 9, 116–132. [Google Scholar] [CrossRef]
- McArthur, E.; Weaven, S.; Dant, R. The evolution of retailing: A meta review of the literature. J. Macromark. 2016, 36, 272–286. [Google Scholar] [CrossRef] [Green Version]
- Applebaum, W. The analog method for estimating potential store sales. In Guild to Store Location Research; Kornblau, Ed.; Addison-Wesley: Boston, MA, USA, 1968. [Google Scholar]
- Chen, K.; Kuang, C.; Wang, L.; Chen, K.; Han, X.; Fan, J. Storm Surge Prediction Based on Long Short-Term Memory Neural Network. Appl. Sci. 2022, 12, 181. [Google Scholar] [CrossRef]
- Yang, X.; Chen, Y.; Teng, S.; Chen, G. Method for Predicting Local Site Amplification Factors Using 1-D Convolutional Neural Networks. Appl. Sci. 2021, 11, 11650. [Google Scholar] [CrossRef]
- Yeh, Y.C. Neural Network Mode Application and Implementation; Scholars Books Co., Ltd.: Taipei, Taiwan, 2009. [Google Scholar]
- Montgomery, D.C. Design and Analysis of Experiments, 6th ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2005. [Google Scholar]
- Thakur, A.G.; Rao, T.E.; Mukhedkar, M.S.; Nandedkar, V.M. Application of Taguchi Method for Resistance Spot Welding of Galvanized Steel. J. Eng. Appl. Sci. 2010, 5, 22–26. [Google Scholar]
- Taguchi, G.; Chowdhury, S.; Wu, Y. Taguchi’s Quality Engineering Handbook; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).