
TDO-Spider Taylor ChOA: An Optimized Deep-Learning-Based Sentiment Classification and Review Rating Prediction





Abstract
:1. Introduction
- Designed TD-Spider Taylor ChoA model for Sentiment Classification: The GRU architecture was applied for performing Sentiment Classification. Additionally, the GRU model was trained by a developed optimization algorithm, named TD-Spider Taylor ChoA, which is newly designed by the combination of ChoA, Taylor series, TDO and SMO algorithms.
- Developed Jaya TDO-HAN approach for Review Rating Prediction: Here, the HAN model was applied for predicting review ratings from extracted features. Moreover, the HAN model was trained by the proposed Jaya-TDO algorithm. Accordingly, the designed Jaya-TDO was designed by integrating Jaya optimization and the TDO algorithm.
2. Related Work
- It is essential to detect and understand the user’s feelings in a sensitive complex environment for efficient Sentiment Classification. Moreover, it is not effective to implement semantic classification approaches in the event directly because of the restrictions, such as the standard emotion thesaurus.
- An attention-based Bi-GRU neural network technique was designed in [12] for Sentiment Classification. However, it failed to utilize a publicity balanced database for the training process, and also did not include a combination of clustering and over sampling methods to generate samples as more balanced.
- The sequence encoding with the CNN model was designed in [12] for Sentiment Classification, although it did not consider fine-tuned granularity with multi aspects and the attention model to generate adjusted sentiment sequence encoding.
- Word embedding and deep learning were introduced in [18] for classifying the sentiment, even though it failed to perform word embeddings training on informal dialects to improve the performance.
- In [3], an SMCA-driven DeepRNN was developed for Sentiment Classification and Review Rating Prediction, but, still, the advanced features, including feature weighting and n-grams, were not considered in this approach for improving the system performance.
3. Proposed Method
3.1. Acquisition of Input Data
3.2. Pre-Processing Using Stop Word Removal and Stemming Method
3.3. Feature Extraction
3.4. Sentiment Classification
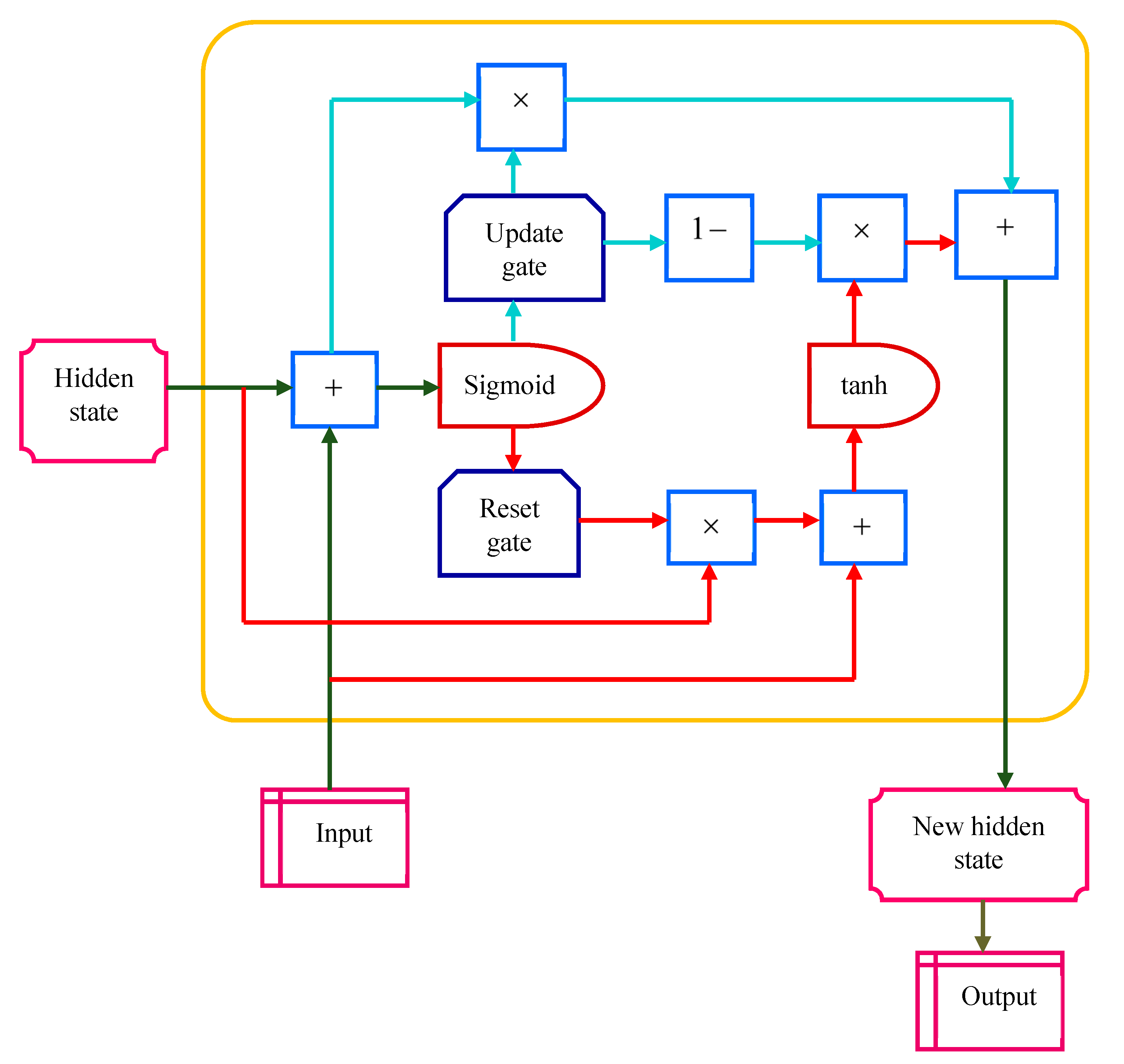
3.4.1. Structure of GRU
3.4.2. Training of GRU Based on Developed TD-Spider Taylor ChOA
| Algorithm 1 Pseudo-code of proposed TD-Spider Taylor ChOA. |
Input: Population of spider monkey S Output: Optimum solution Begin Initialize the population randomly Evaluate fitness rate based on expression (17) Select the local and global leader using greedy selection method. While (stopping norm is not fulfilled) do Formulate new position with local leader using Equation (18) Produce novel position with global leader through Equation (29) Re-compute the fitness measure by using Equation (17) Perform greedy selection scheme and choose the optimum one Compute the probability of every member Produce the new location of each group member Update global and local position of leader Redirect every member by Equation (30) when local group leader does not update position. If global leader has not updated the location, then separate the group into small groups. End while Return the best solution End |
3.5. Review Rating Prediction
3.5.1. Architecture of HAN
3.5.2. Training Process of HAN Using Developed Jaya-TDO Approach
4. Systems Implementation and Evaluation
4.1. Description of Datasets
4.2. Experimental Setup
4.3. Evaluation Metrics
4.4. Baseline Methods
5. Results and Discussion
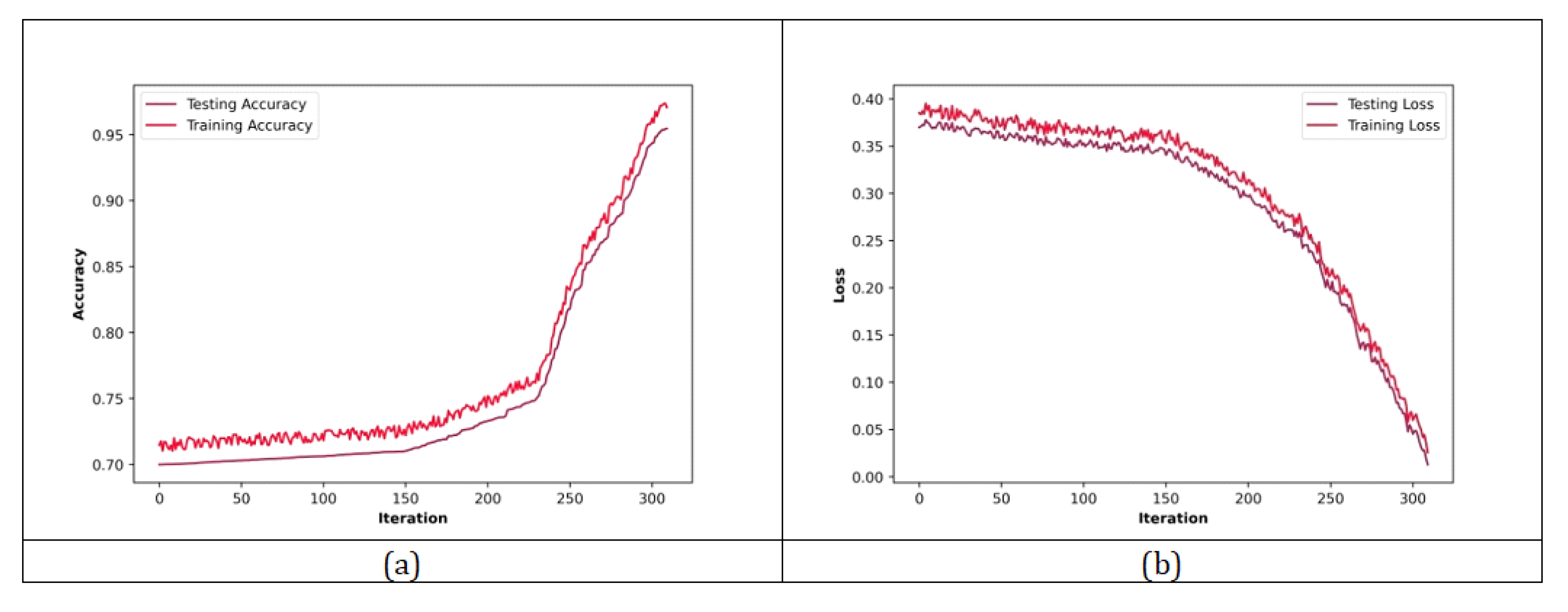
5.1. Sentiment Classification
5.1.1. Results Based on IMDB Dataset
5.1.2. Results Based on Yelp 2013 Dataset
5.1.3. Results Based on Yelp 2014 Dataset
5.1.4. Social Media App Review Dataset
5.2. Review Rating Prediction
5.2.1. Results Based on Yelp IMDB Dataset
5.2.2. Results Based on Yelp 2013 Dataset
5.2.3. Results Based on Yelp 2014 Dataset
5.2.4. Social Media App Review Dataset
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ChOA | Chimp Optimization Algorithm |
| DCBVN | Demand-aware Collaborative Bayesian Variational Network |
| DÉCOR | Deep-Learning-Enabled Course Recommender System |
| DNN | Deep Neural Networks |
| GRU | Gated Recurrent Unit |
| HSACN | Hierarchical Self-Attentive Convolution Network |
| LSTM | Long Short-Term Memory |
| MCNN | Multi-model Convolutional Neural Network |
| NLP | Natural Language Processing |
| RMDL | Random Multi-model Deep Learning |
| RNN | Recurrent Neural Network |
| TDO | Tasmanian Devil Optimization |
References
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. Multimed. Tools Appl. 2022, 1–32. [Google Scholar] [CrossRef]
- Rajput, A. Natural language processing, sentiment analysis, and clinical analytics. In Innovation in Health Informatics; Elsevier: Amsterdam, The Netherlands, 2020; pp. 79–97. [Google Scholar]
- Chugh, A.; Sharma, V.K.; Kumar, S.; Nayyar, A.; Qureshi, B.; Bhatia, M.K.; Jain, C. Spider monkey crow optimization algorithm with deep learning for Sentiment Classification and information retrieval. IEEE Access 2021, 9, 24249–24262. [Google Scholar] [CrossRef]
- Zheng, T.; Wu, F.; Law, R.; Qiu, Q.; Wu, R. Identifying unreliable online hospitality reviews with biased user-given ratings: A deep learning forecasting approach. Int. J. Hosp. Manag. 2021, 92, 102658. [Google Scholar] [CrossRef]
- Basiri, M.E.; Nemati, S.; Abdar, M.; Cambria, E.; Acharya, U.R. ABCDM: An attention-based bidirectional CNN-RNN deep model for sentiment analysis. Future Gener. Comput. Syst. 2021, 115, 279–294. [Google Scholar] [CrossRef]
- Xia, Y.; Cambria, E.; Hussain, A.; Zhao, H. Word polarity disambiguation using bayesian model and opinion-level features. Cogn. Comput. 2015, 7, 369–380. [Google Scholar] [CrossRef]
- Chandra, Y.; Jana, A. Sentiment analysis using machine learning and deep learning. In Proceedings of the 2020 7th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 12–14 March 2020; pp. 1–4. [Google Scholar]
- Jemai, F.; Hayouni, M.; Baccar, S. Sentiment Analysis Using Machine Learning Algorithms. In Proceedings of the 2021 International Wireless Communications and Mobile Computing (IWCMC), Harbin, China, 28 June–2 July 2021; pp. 775–779. [Google Scholar]
- Zhou, X.; Liang, W.; Huang, S.; Fu, M. Social recommendation with large-scale group decision-making for cyber-enabled online service. IEEE Trans. Comput. Soc. Syst. 2019, 6, 1073–1082. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; Kevin, I.; Wang, K.; Shimizu, S. Multi-modality behavioral influence analysis for personalized recommendations in health social media environment. IEEE Trans. Comput. Soc. Syst. 2019, 6, 888–897. [Google Scholar] [CrossRef]
- Jin, N.; Wu, J.; Ma, X.; Yan, K.; Mo, Y. Multi-task learning model based on multi-scale CNN and LSTM for Sentiment Classification. IEEE Access 2020, 8, 77060–77072. [Google Scholar] [CrossRef]
- Liu, S.; Lee, I. Sequence encoding incorporated CNN model for Email document sentiment classification. Appl. Soft Comput. 2021, 102, 107104. [Google Scholar] [CrossRef]
- Jianqiang, Z.; Xiaolin, G.; Xuejun, Z. Deep convolution neural networks for twitter sentiment analysis. IEEE Access 2018, 6, 23253–23260. [Google Scholar] [CrossRef]
- Zainuddin, N.; Selamat, A.; Ibrahim, R. Hybrid Sentiment Classification on twitter aspect-based sentiment analysis. Appl. Intell. 2018, 48, 1218–1232. [Google Scholar] [CrossRef]
- Kalaivani, P.; Shunmuganathan, K. Feature reduction based on genetic algorithm and hybrid model for opinion mining. Sci. Program. 2015, 2015, 12. [Google Scholar] [CrossRef]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Li, L.; Yang, L.; Zeng, Y. Improving Sentiment Classification of restaurant reviews with attention-based bi-GRU neural network. Symmetry 2021, 13, 1517. [Google Scholar] [CrossRef]
- Alamoudi, E.S.; Alghamdi, N.S. Sentiment Classification and aspect-based sentiment analysis on yelp reviews using deep learning and word embeddings. J. Decis. Syst. 2021, 30, 259–281. [Google Scholar] [CrossRef]
- Feng, S.; Song, K.; Wang, D.; Gao, W.; Zhang, Y. InterSentiment: Combining deep neural models on interaction and sentiment for Review Rating Prediction. Int. J. Mach. Learn. Cybern. 2021, 12, 477–488. [Google Scholar] [CrossRef]
- Ahmed, B.H.; Ghabayen, A.S. Review Rating Prediction framework using deep learning. J. Ambient. Intell. Humaniz. Comput. 2020, 13, 3423–3432. [Google Scholar] [CrossRef]
- Sadiq, S.; Umer, M.; Ullah, S.; Mirjalili, S.; Rupapara, V.; Nappi, M. Discrepancy detection between actual user reviews and numeric ratings of Google App store using deep learning. Expert Syst. Appl. 2021, 181, 115111. [Google Scholar] [CrossRef]
- Hong, T.P.; Lin, C.W.; Yang, K.T.; Wang, S.L. Using TF-IDF to hide sensitive itemsets. Appl. Intell. 2013, 38, 502–510. [Google Scholar] [CrossRef]
- Santur, Y. Sentiment analysis based on gated recurrent unit. In Proceedings of the 2019 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 21–22 September 2019; pp. 1–5. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Khishe, M.; Mosavi, M.R. Chimp optimization algorithm. Expert Syst. Appl. 2020, 149, 113338. [Google Scholar] [CrossRef]
- Bansal, J.C.; Sharma, H.; Jadon, S.S.; Clerc, M. Spider monkey optimization algorithm for numerical optimization. Memetic Comput. 2014, 6, 31–47. [Google Scholar] [CrossRef]
- Mangai, S.A.; Sankar, B.R.; Alagarsamy, K. Taylor series prediction of time series data with error propagated by artificial neural network. Int. J. Comput. Appl. 2014, 89, 41–47. [Google Scholar]
- Rao, R. Jaya: A simple and new optimization algorithm for solving constrained and unconstrained optimization problems. Int. J. Ind. Eng. Comput. 2016, 7, 19–34. [Google Scholar]
- Dehghani, M.; Hubálovskỳ, Š.; Trojovskỳ, P. Tasmanian devil optimization: A new bio-inspired optimization algorithm for solving optimization algorithm. IEEE Access 2022, 10, 19599–19620. [Google Scholar] [CrossRef]
- Chen, H.; Sun, M.; Tu, C.; Lin, Y.; Liu, Z. Neural Sentiment Classification with user and product attention. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1650–1659. [Google Scholar]
- Zeng, H.; Ai, Q. A hierarchical self-attentive convolution network for review modeling in recommendation systems. arXiv 2020, arXiv:2011.13436. [Google Scholar]
- Da’u, A.; Salim, N.; Rabiu, I.; Osman, A. Recommendation system exploiting aspect-based opinion mining with deep learning method. Inf. Sci. 2020, 512, 1279–1292. [Google Scholar]
- Wang, C.; Zhu, H.; Zhu, C.; Zhang, X.; Chen, E.; Xiong, H. Personalized employee training course recommendation with career development awareness. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1648–1659. [Google Scholar]
- Banbhrani, S.K.; Xu, B.; Lin, H.; Sajnani, D.K. Spider Taylor-ChOA: Optimized Deep Learning Based Sentiment Classification for Review Rating Prediction. Appl. Sci. 2022, 12, 3211. [Google Scholar] [CrossRef]
- Zhang, K.; Qian, H.; Liu, Q.; Zhang, Z.; Zhou, J.; Ma, J.; Chen, E. Sifn: A sentiment-aware interactive fusion network for review-based item recommendation. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Online, 1–5 November 2021; pp. 3627–3631. [Google Scholar]
- Chambua, J.; Niu, Z. Review text based rating prediction approaches: Preference knowledge learning, representation and utilization. Artif. Intell. Rev. 2021, 54, 1171–1200. [Google Scholar] [CrossRef]
- Bu, J.; Ren, L.; Zheng, S.; Yang, Y.; Wang, J.; Zhang, F.; Wu, W. ASAP: A chinese review dataset towards aspect category sentiment analysis and rating prediction. arXiv 2021, arXiv:2103.06605. [Google Scholar]
- Shrestha, N.; Nasoz, F. Deep learning sentiment analysis of amazon. com reviews and ratings. arXiv 2019, arXiv:1904.04096. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Data (%) | HSACN | MCNN | DCBVN | [3] | [34] | [17] | Proposed |
|---|---|---|---|---|---|---|---|---|
| Precision | 60% | 0.785 | 0.825 | 0.855 | 0.869 | 0.895 | 0.900 | 0.904 |
| 70% | 0.805 | 0.835 | 0.865 | 0.888 | 0.903 | 0.908 | 0.914 | |
| 80% | 0.824 | 0.854 | 0.885 | 0.898 | 0.925 | 0.929 | 0.935 | |
| 90% | 0.852 | 0.874 | 0.905 | 0.927 | 0.941 | 0.943 | 0.949 | |
| Recall | 60% | 0.795 | 0.835 | 0.865 | 0.877 | 0.905 | 0.908 | 0.914 |
| 70% | 0.814 | 0.841 | 0.885 | 0.898 | 0.914 | 0.919 | 0.925 | |
| 80% | 0.841 | 0.865 | 0.895 | 0.908 | 0.937 | 0.939 | 0.941 | |
| 90% | 0.865 | 0.885 | 0.914 | 0.937 | 0.965 | 0.968 | 0.970 | |
| F-measure | 60% | 0.790 | 0.830 | 0.860 | 0.873 | 0.900 | 0.904 | 0.909 |
| 70% | 0.809 | 0.838 | 0.875 | 0.893 | 0.908 | 0.913 | 0.920 | |
| 80% | 0.833 | 0.860 | 0.890 | 0.903 | 0.931 | 0.934 | 0.938 | |
| 90% | 0.859 | 0.880 | 0.910 | 0.932 | 0.953 | 0.955 | 0.959 |
| Metrics | Data (%) | HSACN | MCNN | DCBVN | [3] | [34] | [17] | Proposed |
|---|---|---|---|---|---|---|---|---|
| Precision | 60% | 0.754 | 0.775 | 0.814 | 0.825 | 0.842 | 0.848 | 0.857 |
| 70% | 0.765 | 0.785 | 0.825 | 0.848 | 0.865 | 0.868 | 0.875 | |
| 80% | 0.795 | 0.814 | 0.847 | 0.865 | 0.904 | 0.908 | 0.914 | |
| 90% | 0.825 | 0.841 | 0.885 | 0.907 | 0.933 | 0.938 | 0.947 | |
| Recall | 60% | 0.775 | 0.795 | 0.833 | 0.858 | 0.875 | 0.879 | 0.887 |
| 70% | 0.785 | 0.796 | 0.854 | 0.875 | 0.896 | 0.898 | 0.901 | |
| 80% | 0.801 | 0.825 | 0.875 | 0.898 | 0.914 | 0.918 | 0.925 | |
| 90% | 0.833 | 0.865 | 0.895 | 0.916 | 0.941 | 0.948 | 0.950 | |
| F-measure | 60% | 0.765 | 0.785 | 0.823 | 0.841 | 0.858 | 0.863 | 0.872 |
| 70% | 0.775 | 0.791 | 0.840 | 0.861 | 0.880 | 0.883 | 0.888 | |
| 80% | 0.798 | 0.820 | 0.860 | 0.881 | 0.909 | 0.913 | 0.920 | |
| 90% | 0.829 | 0.853 | 0.890 | 0.911 | 0.937 | 0.943 | 0.949 |
| Metrics | Data (%) | HSACN | MCNN | DCBVN | [3] | [34] | [17] | Proposed |
|---|---|---|---|---|---|---|---|---|
| Precision | 60% | 0.775 | 0.799 | 0.833 | 0.858 | 0.875 | 0.878 | 0.887 |
| 70% | 0.785 | 0.804 | 0.848 | 0.865 | 0.895 | 0.899 | 0.905 | |
| 80% | 0.801 | 0.824 | 0.865 | 0.884 | 0.914 | 0.918 | 0.925 | |
| 90% | 0.833 | 0.854 | 0.895 | 0.917 | 0.947 | 0.950 | 0.952 | |
| Recall | 60% | 0.785 | 0.801 | 0.854 | 0.865 | 0.885 | 0.890 | 0.899 |
| 70% | 0.795 | 0.824 | 0.875 | 0.887 | 0.905 | 0.910 | 0.914 | |
| 80% | 0.814 | 0.835 | 0.885 | 0.898 | 0.925 | 0.929 | 0.937 | |
| 90% | 0.848 | 0.865 | 0.903 | 0.917 | 0.955 | 0.960 | 0.965 | |
| F-measure | 60% | 0.780 | 0.800 | 0.843 | 0.862 | 0.880 | 0.884 | 0.893 |
| 70% | 0.790 | 0.814 | 0.861 | 0.876 | 0.900 | 0.904 | 0.910 | |
| 80% | 0.808 | 0.830 | 0.875 | 0.891 | 0.920 | 0.923 | 0.931 | |
| 90% | 0.840 | 0.860 | 0.899 | 0.917 | 0.951 | 0.955 | 0.959 |
| Metrics | Data (%) | HSACN | MCNN | DCBVN | [3] | [34] | [17] | Proposed |
|---|---|---|---|---|---|---|---|---|
| Precision | 60% | 0.741 | 0.769 | 0.807 | 0.816 | 0.834 | 0.848 | 0.858 |
| 70% | 0.768 | 0.785 | 0.821 | 0.837 | 0.854 | 0.865 | 0.875 | |
| 80% | 0.785 | 0.807 | 0.841 | 0.859 | 0.864 | 0.875 | 0.887 | |
| 90% | 0.798 | 0.814 | 0.865 | 0.869 | 0.874 | 0.887 | 0.897 | |
| Recall | 60% | 0.754 | 0.778 | 0.814 | 0.827 | 0.841 | 0.858 | 0.865 |
| 70% | 0.778 | 0.799 | 0.829 | 0.848 | 0.862 | 0.876 | 0.887 | |
| 80% | 0.798 | 0.814 | 0.832 | 0.859 | 0.878 | 0.887 | 0.897 | |
| 90% | 0.801 | 0.825 | 0.848 | 0.865 | 0.887 | 0.898 | 0.906 | |
| F-measure | 60% | 0.748 | 0.774 | 0.811 | 0.821 | 0.838 | 0.853 | 0.862 |
| 70% | 0.773 | 0.791 | 0.825 | 0.842 | 0.858 | 0.870 | 0.881 | |
| 80% | 0.791 | 0.811 | 0.837 | 0.859 | 0.871 | 0.881 | 0.892 | |
| 90% | 0.800 | 0.820 | 0.856 | 0.867 | 0.881 | 0.892 | 0.902 |
| Metrics | Data (%) | DNN | CNN+LSTM | Bi-GRU | CNN | [3] | [34] | [17] | Proposed |
|---|---|---|---|---|---|---|---|---|---|
| Precision | 60% | 0.635 | 0.685 | 0.741 | 0.845 | 0.858 | 0.865 | 0.877 | 0.887 |
| 70% | 0.648 | 0.703 | 0.765 | 0.860 | 0.869 | 0.885 | 0.889 | 0.897 | |
| 80% | 0.685 | 0.745 | 0.785 | 0.885 | 0.898 | 0.919 | 0.920 | 0.925 | |
| 90% | 0.695 | 0.765 | 0.805 | 0.901 | 0.916 | 0.931 | 0.937 | 0.943 | |
| Recall | 60% | 0.654 | 0.699 | 0.754 | 0.850 | 0.869 | 0.885 | 0.889 | 0.897 |
| 70% | 0.675 | 0.714 | 0.785 | 0.870 | 0.887 | 0.905 | 0.908 | 0.914 | |
| 80% | 0.695 | 0.754 | 0.804 | 0.908 | 0.916 | 0.933 | 0.938 | 0.941 | |
| 90% | 0.724 | 0.775 | 0.825 | 0.928 | 0.948 | 0.954 | 0.959 | 0.965 | |
| F-measure | 60% | 0.645 | 0.692 | 0.748 | 0.847 | 0.863 | 0.875 | 0.883 | 0.892 |
| 70% | 0.661 | 0.708 | 0.775 | 0.847 | 0.878 | 0.895 | 0.898 | 0.906 | |
| 80% | 0.690 | 0.750 | 0.795 | 0.847 | 0.907 | 0.925 | 0.929 | 0.933 | |
| 90% | 0.709 | 0.770 | 0.815 | 0.847 | 0.932 | 0.943 | 0.948 | 0.954 |
| Metrics | Data (%) | DNN | CNN+LSTM | Bi-GRU | CNN | [3] | [34] | [17] | Proposed |
|---|---|---|---|---|---|---|---|---|---|
| Precision | 60% | 0.633 | 0.665 | 0.704 | 0.799 | 0.808 | 0.841 | 0.848 | 0.855 |
| 70% | 0.654 | 0.696 | 0.737 | 0.824 | 0.848 | 0.865 | 0.875 | 0.887 | |
| 80% | 0.696 | 0.733 | 0.754 | 0.865 | 0.887 | 0.895 | 0.900 | 0.905 | |
| 90% | 0.741 | 0.765 | 0.799 | 0.895 | 0.909 | 0.925 | 0.928 | 0.933 | |
| Recall | 60% | 0.654 | 0.699 | 0.741 | 0.801 | 0.826 | 0.854 | 0.859 | 0.865 |
| 70% | 0.675 | 0.714 | 0.754 | 0.835 | 0.859 | 0.875 | 0.879 | 0.885 | |
| 80% | 0.714 | 0.741 | 0.785 | 0.895 | 0.900 | 0.902 | 0.908 | 0.915 | |
| 90% | 0.769 | 0.804 | 0.841 | 0.901 | 0.917 | 0.935 | 0.939 | 0.941 | |
| F-measure | 60% | 0.643 | 0.682 | 0.722 | 0.800 | 0.817 | 0.848 | 0.853 | 0.860 |
| 70% | 0.664 | 0.705 | 0.745 | 0.830 | 0.853 | 0.870 | 0.877 | 0.886 | |
| 80% | 0.705 | 0.737 | 0.769 | 0.880 | 0.893 | 0.899 | 0.904 | 0.910 | |
| 90% | 0.755 | 0.784 | 0.819 | 0.898 | 0.913 | 0.930 | 0.933 | 0.937 |
| Metrics | Data (%) | DNN | CNN+LSTM | Bi-GRU | CNN | [3] | [34] | [17] | Proposed |
|---|---|---|---|---|---|---|---|---|---|
| Precision | 60% | 0.641 | 0.695 | 0.741 | 0.785 | 0.808 | 0.841 | 0.848 | 0.854 |
| 70% | 0.685 | 0.714 | 0.765 | 0.802 | 0.837 | 0.865 | 0.869 | 0.875 | |
| 80% | 0.701 | 0.775 | 0.825 | 0.865 | 0.876 | 0.895 | 0.907 | 0.914 | |
| 90% | 0.725 | 0.799 | 0.841 | 0.895 | 0.908 | 0.914 | 0.919 | 0.925 | |
| Recall | 60% | 0.665 | 0.714 | 0.754 | 0.801 | 0.836 | 0.854 | 0.859 | 0.866 |
| 70% | 0.701 | 0.732 | 0.775 | 0.814 | 0.859 | 0.875 | 0.880 | 0.885 | |
| 80% | 0.714 | 0.795 | 0.833 | 0.875 | 0.888 | 0.901 | 0.908 | 0.914 | |
| 90% | 0.733 | 0.814 | 0.854 | 0.912 | 0.927 | 0.933 | 0.939 | 0.941 | |
| F-measure | 60% | 0.653 | 0.704 | 0.748 | 0.793 | 0.821 | 0.848 | 0.853 | 0.860 |
| 70% | 0.693 | 0.723 | 0.770 | 0.808 | 0.848 | 0.870 | 0.874 | 0.880 | |
| 80% | 0.708 | 0.785 | 0.829 | 0.870 | 0.882 | 0.898 | 0.907 | 0.914 | |
| 90% | 0.729 | 0.806 | 0.848 | 0.904 | 0.917 | 0.923 | 0.928 | 0.933 |
| Metrics | Data (%) | DNN | CNN+LSTM | Bi-GRU | CNN | [34] | Proposed |
|---|---|---|---|---|---|---|---|
| Precision | 60% | 0.659 | 0.678 | 0.704 | 0.754 | 0.778 | 0.807 |
| 70% | 0.678 | 0.685 | 0.725 | 0.778 | 0.799 | 0.814 | |
| 80% | 0.699 | 0.714 | 0.741 | 0.789 | 0.814 | 0.829 | |
| 90% | 0.701 | 0.733 | 0.754 | 0.799 | 0.825 | 0.841 | |
| Recall | 60% | 0.678 | 0.690 | 0.715 | 0.769 | 0.785 | 0.814 |
| 70% | 0.687 | 0.699 | 0.735 | 0.778 | 0.799 | 0.824 | |
| 80% | 0.699 | 0.704 | 0.745 | 0.787 | 0.814 | 0.848 | |
| 90% | 0.704 | 0.715 | 0.755 | 0.807 | 0.825 | 0.865 | |
| F-measure | 60% | 0.668 | 0.684 | 0.709 | 0.761 | 0.782 | 0.811 |
| 70% | 0.683 | 0.692 | 0.730 | 0.778 | 0.799 | 0.819 | |
| 80% | 0.699 | 0.709 | 0.743 | 0.788 | 0.814 | 0.838 | |
| 90% | 0.703 | 0.723 | 0.754 | 0.803 | 0.825 | 0.853 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banbhrani, S.K.; Xu, B.; Soomro, P.D.; Jain, D.K.; Lin, H. TDO-Spider Taylor ChOA: An Optimized Deep-Learning-Based Sentiment Classification and Review Rating Prediction. Appl. Sci. 2022, 12, 10292. https://doi.org/10.3390/app122010292
Banbhrani SK, Xu B, Soomro PD, Jain DK, Lin H. TDO-Spider Taylor ChOA: An Optimized Deep-Learning-Based Sentiment Classification and Review Rating Prediction. Applied Sciences. 2022; 12(20):10292. https://doi.org/10.3390/app122010292
Chicago/Turabian StyleBanbhrani, Santosh Kumar, Bo Xu, Pir Dino Soomro, Deepak Kumar Jain, and Hongfei Lin. 2022. "TDO-Spider Taylor ChOA: An Optimized Deep-Learning-Based Sentiment Classification and Review Rating Prediction" Applied Sciences 12, no. 20: 10292. https://doi.org/10.3390/app122010292
APA StyleBanbhrani, S. K., Xu, B., Soomro, P. D., Jain, D. K., & Lin, H. (2022). TDO-Spider Taylor ChOA: An Optimized Deep-Learning-Based Sentiment Classification and Review Rating Prediction. Applied Sciences, 12(20), 10292. https://doi.org/10.3390/app122010292