
Enhancing Food Ingredient Named-Entity Recognition with Recurrent Network-Based Ensemble (RNE) Model

Abstract
:1. Introduction
- Proposing a novel approach to extract food-related entities using an ensemble method with recurrent networks models such as RNN, GRU, and LSTM. To the best of the authors’ knowledge, this is the first work to explore a model that benefits from a deep learning-based ensemble method applied to a food-related NER task.
- Preparing a carefully annotated dataset for food ingredient entities, namely the FINER dataset.
- Achieving better results on the proposed NER task approach compared to single models for food-related NER.
2. Related Works
2.1. Food-Related NER
2.2. Recurrent Networks Model for NER
2.3. Ensemble Methods for NER
3. Proposed Methods
3.1. Dataset Construction
- (a)
- Data preparation. We start with raw texts obtained by scraping the Allrecipes website and arranging it so that the format and structure of the data match the desired input. Several pre-processing steps are taken, such as: tokenizing the text, converting it into lowercase, removing all special characters, white spaces, stop words, punctuation, and lemmatization. We also define additional rules as follows:
- ▪
- Since our dataset is a list of ingredients, stop words and punctuations are not always meaningless to the intention of the text but can potentially help interpret entities. Thus, we have developed custom stop words and punctuation lists. For example, the sentence “1 (2 ounces) package butter” means 1 package of butter equals 2 ounces. Although the word “2 ounces” is in brackets, we keep the parentheses because they carry clues for converting the amount of ingredient into standard units.
- ▪
- We standardized the measurements for units and quantities. For example, in units, we convert all abbreviations into their original form, such as “tbsp” becomes “tablespoon”; and in quantities, we convert all numbers from fractions into a decimal, such as “½” becomes “0.5”.
- ▪
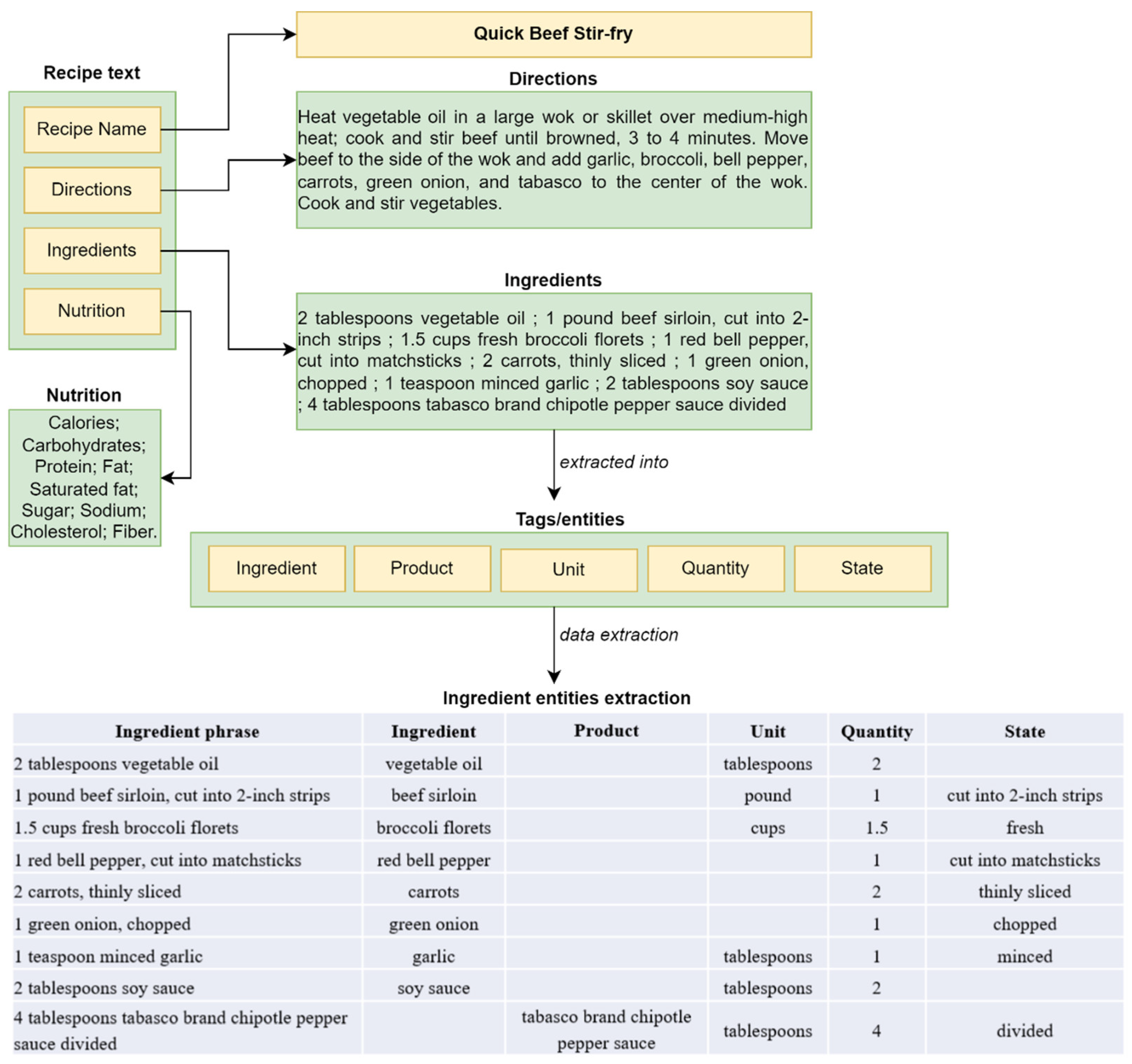
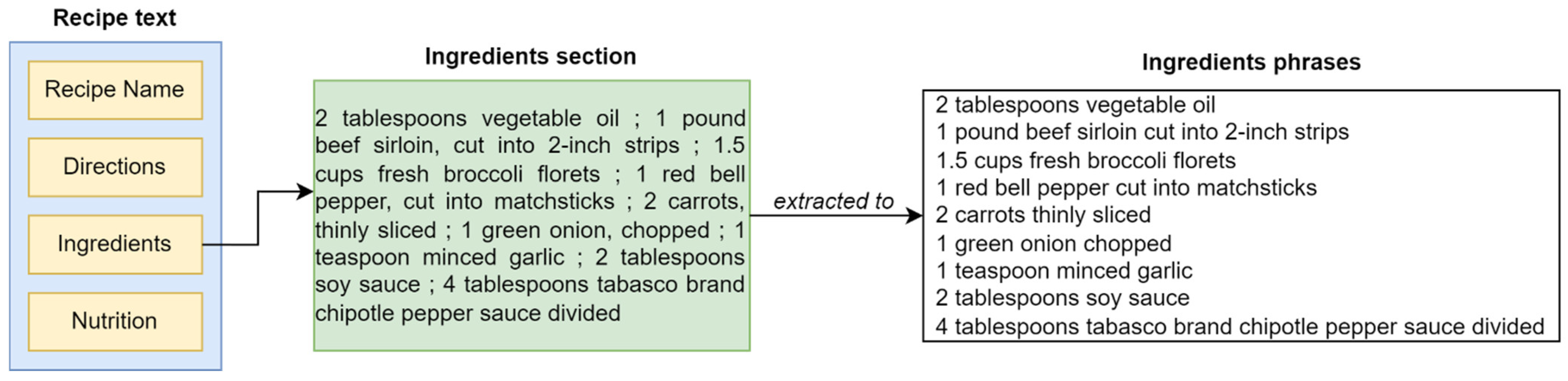
- In addition, to simplify the extraction process, we segment each phrase in the ingredients section into individual phrases. Figure 1 illustrates the process of extracting the ingredient entity from the text recipe. It can be observed that the recipe text consists of multiple sections, such as recipe name, directions, ingredients, and nutrition. In our experiment, only the ingredients section was utilized. This section contains a list of ingredients required for a particular recipe. Each list is then divided into ingredient phrases, as depicted in Figure 3. Finally, the resulting dataset consists of 181,970 phrases in total after the pre-processing step.
- (b)
- Manual data annotation. We start with a small set of 2000 instances that have been manually labeled and divide it in half. One is for initial training, and the other for evaluation. The initial training set is used to develop a baseline NER annotator and the evaluation set is kept for the final evaluation of the complete dataset.
- (c)
- Model training and automatic labeling. In this step, we create baseline models using the initial training set from the previous stage. We develop a semi-supervised method called SMPT (semi-supervised multi-model prediction technique) to annotate and create our dataset. SMPT adopts the self-training concept that builds on pre-trained models in the iterative data labeling process [48]. After a number of repetitions, the resulting dataset is re-appended to the training set, which grows rapidly to the desired size. Figure 4 depicts the architecture of the SMPT method. Initially, we create a small dataset of manually labeled instances and then train a set of base classifiers built on pretrained language models from spaCy, BERT, and DistilBERT. Through the SMPT, we extract all entities in the ingredient section of the text and then annotate them into five entities: ingredient, product, quantity, unit, and state. These are applied to unlabeled sets to obtain additional named entities using a voting scheme for improved prediction. The resulting models are then employed to predict the remaining unlabeled instances. Once we have generated new labeled data, some of it is promoted into the existing labeled set. This procedure is repeated until we run out of unlabeled data.
- (d)
- Dataset evaluation. After several repetitions, we end up with the Food Ingredient NER (FINER) dataset. We indirectly evaluate the dataset’s quality using a set of classifiers such as CRF, Bi-LSTM, and BERT. We evaluate their performance on the evaluation set that has been reserved.
3.2. Recurrent Networks Classifiers
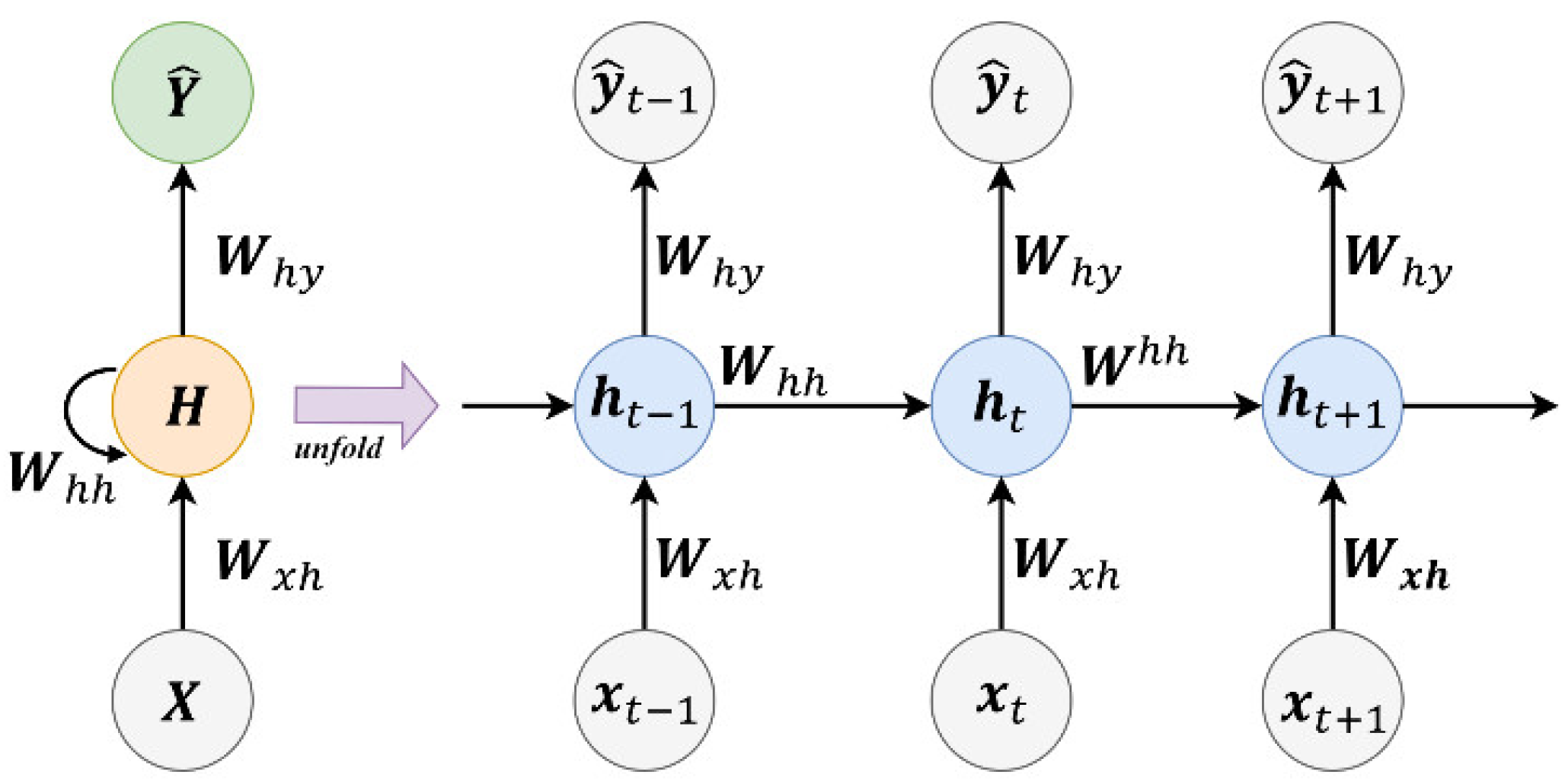
3.2.1. Recurrent Neural Networks
3.2.2. Long Short-Term Memory
3.2.3. Gated-Recurrent Unit
3.3. Recurrent Network-Based Ensemble Method (RNE)
4. Experiments
4.1. Experimental Setup
4.2. Evaluation Metrics
- ▪
- Precision is the ratio of true positives and total predicted positives;
- ▪
- Recall is the ratio of true positives and total actual positives;
- ▪
- F1 Score is the harmonic mean of precision and recall.
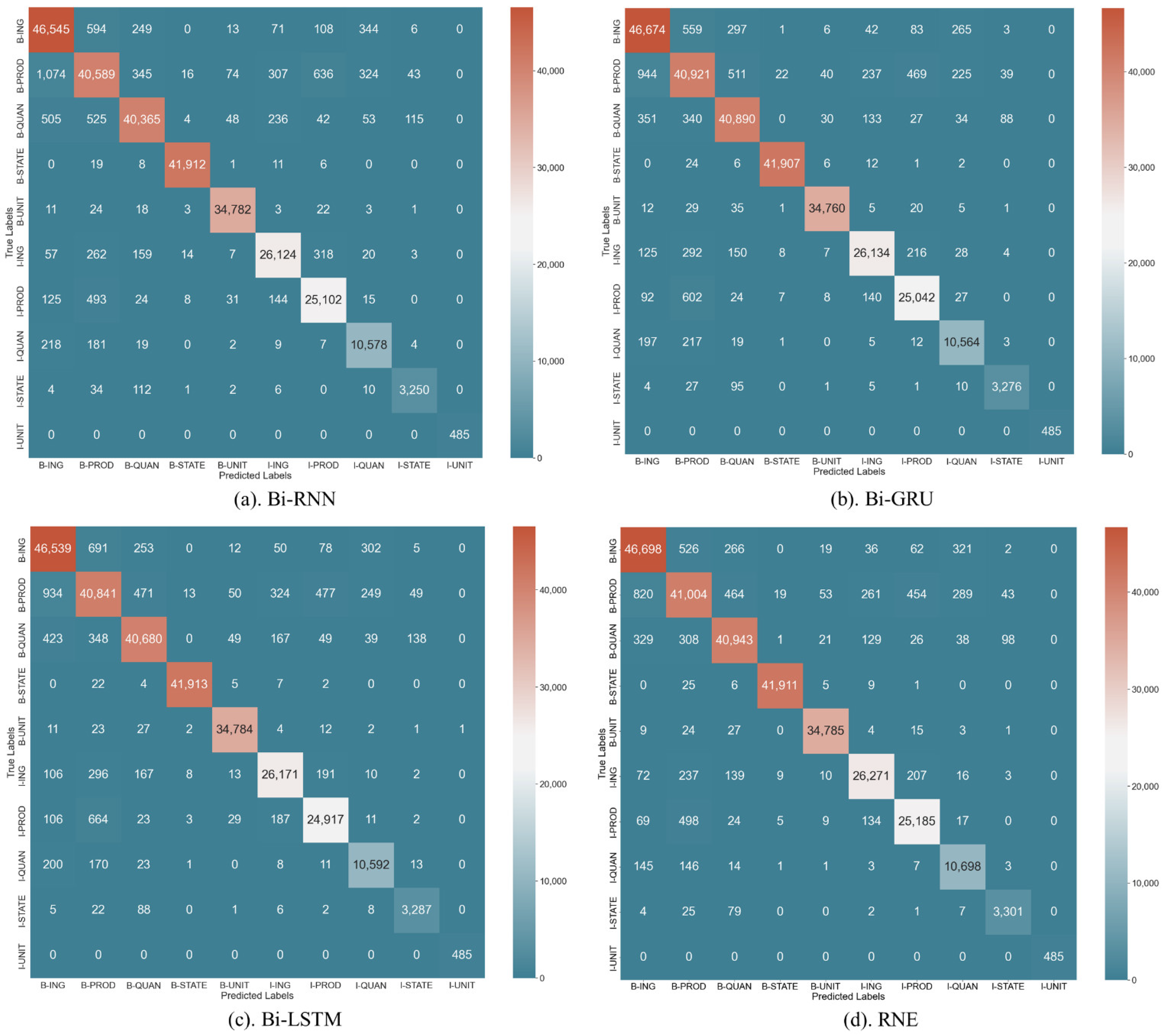
4.3. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| NER | Named-Entity Recognition |
| NLP | Natural Language Processing |
| RNE | Recurrent Network-based Ensemble |
| FINER | Food Ingredient NER |
| RNN | Recurrent Neural Network |
| GRU | Gated-Recurrent Unit |
| LSTM | Long Short-Term Memory |
| Bi-LSTM | Bidirectional Long Short-Term Memory |
| BERT | Bidirectional Encoder Representations from Transformers |
| MLP | Multilayer Perceptron |
| ABM1 | AdaBoostM1 |
| ME | Maximum Entropy |
| CRF | Conditional Random Field |
| SVM | Support Vector Machine |
| CNN | Convolutional Neural Network |
| HMM | Hidden Markov Model |
| MEM | Maximum Entropy Model |
| GloVe | Global Vector |
| TP | True Positive |
| FP | False Positive |
| FN | False Negative |
References
- Syed, M.H.; Chung, S.-T. MenuNER: Domain-Adapted BERT Based NER Approach for a Domain with Limited Dataset and Its Application to Food Menu Domain. Appl. Sci. 2021, 11, 6007. [Google Scholar] [CrossRef]
- Komariah, K.S.; Sin, B.-K. Nutrition-Based Food Recommendation System for Prediabetic Person. In Proceedings of the 2020 Korea Software Congress, Pyeongchang, Korea, 21–23 December 2021; pp. 660–662. [Google Scholar]
- Kalra, J.S.; Batra, D.; Diwan, N.; Bagler, G. Nutritional Profile Estimation in Cooking Recipes. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering Workshops (ICDEW), Dallas, TX, USA, 20–24 April 2020; pp. 82–87. [Google Scholar]
- Pellegrini, C.; Özsoy, E.; Wintergerst, M.; Groh, G. Exploiting Food Embeddings for Ingredient Substitution. In Proceedings of the HEALTHINF, Online, 11–13 February 2021. [Google Scholar]
- Popovski, G.; Seljak, B.K.; Eftimov, T. A Survey of Named-Entity Recognition Methods for Food Information Extraction. IEEE Access 2020, 8, 31586–31594. [Google Scholar] [CrossRef]
- Krishnan, V.; Ganapathy, V. Named Entity Recognition. Available online: http://cs229.stanford.edu/proj2005/KrishnanGanapathy-NamedEntityRecognition.pdf (accessed on 4 February 2021).
- Wen, Y.; Fan, C.; Chen, G.; Chen, X.; Chen, M. A Survey on Named Entity Recognition. In Communications, Signal Processing, and Systems; Lecture Notes in Electrical Engineering; Liang, Q., Wang, W., Liu, X., Na, Z., Jia, M., Zhang, B., Eds.; Springer: Singapore, 2020; Volume 571, pp. 1803–1810. ISBN 9789811394089. [Google Scholar]
- Li, J.; Sun, A.; Han, J.; Li, C. A Survey on Deep Learning for Named Entity Recognition. IEEE Trans. Knowl. Data Eng. 2022, 34, 50–70. [Google Scholar] [CrossRef] [Green Version]
- Speck, R.; Ngonga Ngomo, A.-C. Ensemble Learning for Named Entity Recognition. In The Semantic Web—ISWC 2014; Lecture Notes in Computer Science; Mika, P., Tudorache, T., Bernstein, A., Welty, C., Knoblock, C., Vrandečić, D., Groth, P., Noy, N., Janowicz, K., Goble, C., Eds.; Springer International Publishing: Cham, Switzerland, 2014; Volume 8796, pp. 519–534. ISBN 978-3-319-11963-2. [Google Scholar]
- Ekbal, A.; Saha, S. Weighted Vote-Based Classifier Ensemble for Named Entity Recognition: A Genetic Algorithm-Based Approach. ACM Trans. Asian Lang. Inf. Process. 2011, 10, 9. [Google Scholar] [CrossRef]
- Canale, L.; Lisena, P.; Troncy, R. A Novel Ensemble Method for Named Entity Recognition and Disambiguation Based on Neural Network. In The Semantic Web—ISWC 2018; Lecture Notes in Computer Science; Vrandečić, D., Bontcheva, K., Suárez-Figueroa, M.C., Presutti, V., Celino, I., Sabou, M., Kaffee, L.-A., Simperl, E., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11136, pp. 91–107. ISBN 978-3-030-00670-9. [Google Scholar]
- Wang, H.; Zhao, T.; Tan, H.; Zhang, S. Biomedical Named Entity Recognition Based on Classifiers Ensemble. Int. J. Comput. Sci. Appl. 2008, 5, 1–11. [Google Scholar]
- Won, M.; Murrieta-Flores, P.; Martins, B. Ensemble Named Entity Recognition (NER): Evaluating NER Tools in the Identification of Place Names in Historical Corpora. Front. Digit. Humanit. 2018, 5, 2. [Google Scholar] [CrossRef] [Green Version]
- Naderi, N.; Knafou, J.; Copara, J.; Ruch, P.; Teodoro, D. Ensemble of Deep Masked Language Models for Effective Named Entity Recognition in Health and Life Science Corpora. Front. Res. Metr. Anal. 2021, 6, 689803. [Google Scholar] [CrossRef]
- Nayel, H.; Shashirekha, H.L. Improving NER for Clinical Texts by Ensemble Approach Using Segment Representations. In Proceedings of the 14th International Conference on Natural Language Processing (ICON-2017), Kolkata, India, 18–21 December 2017; pp. 197–204. [Google Scholar]
- Copara, J.; Naderi, N.; Knafou, J.; Ruch, P.; Teodoro, D. Named Entity Recognition in Chemical Patents Using Ensemble of Contextual Language Models. arXiv 2020, arXiv:2007.12569. [Google Scholar]
- Jiang, Z. The Application of Ensemble Learning on Named Entity Recognition for Legal Knowledgebase of Properties Involved in Criminal Cases. In Proceedings of the 2020 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 25–27 August 2020; IEEE: Dalian, China, 2020; pp. 701–705. [Google Scholar]
- Yadav, V.; Bethard, S. A Survey on Recent Advances in Named Entity Recognition from Deep Learning Models. In Proceedings of the 27th International Conference on Computational Linguistics, Association for Computational Linguistics, Santa Fe, NM, USA, 21–25 August 2018; pp. 2145–2158. [Google Scholar]
- Chiu, J.P.C.; Nichols, E. Named Entity Recognition with Bidirectional LSTM-CNNs. Trans. Assoc. Comput. Linguist. 2016, 4, 357–370. [Google Scholar] [CrossRef]
- Ma, X.; Hovy, E. End-to-End Sequence Labeling via Bi-Directional LSTM-CNNs-CRF. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics; Long Papers; Association for Computational Linguistics: Berlin, Germany, 2016; Volume 1, pp. 1064–1074. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional Recurrent Neural Networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, C.C. (Ed.) Data Classification: Algorithms and Applications; Chapman & Hall/CRC Data Mining and Knowledge Discovery Series; Taylor & Francis Group: Boca Raton, FL, USA; CRC Press: Abingdon, UK, 2014; ISBN 978-1-4665-8674-1. [Google Scholar]
- Popovski, G.; Kochev, S.; Seljak, B.; Eftimov, T. FoodIE: A Rule-Based Named-Entity Recognition Method for Food Information Extraction. In Proceedings of the 8th International Conference on Pattern Recognition Applications and Methods; SCITEPRESS—Science and Technology Publications: Prague, Czech Republic, 2019; pp. 915–922. [Google Scholar]
- Eftimov, T.; Koroušić Seljak, B.; Korošec, P. A Rule-Based Named-Entity Recognition Method for Knowledge Extraction of Evidence-Based Dietary Recommendations. PLoS ONE 2017, 12, e0179488. [Google Scholar] [CrossRef] [Green Version]
- Diwan, N.; Batra, D.; Bagler, G. A Named Entity Based Approach to Model Recipes. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering Workshops (ICDEW), Dallas, TX, USA, 20–24 April 2020; pp. 88–93. [Google Scholar]
- Popovski, G.; Seljak, B.K.; Eftimov, T. FoodBase Corpus: A New Resource of Annotated Food Entities. Database 2019, 2019, baz121. [Google Scholar] [CrossRef]
- Cenikj, G.; Popovski, G.; Stojanov, R.; Seljak, B.K.; Eftimov, T. BuTTER: BidirecTional LSTM for Food Named-Entity Recognition. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 3550–3556. [Google Scholar]
- Stojanov, R.; Popovski, G.; Cenikj, G.; Koroušić Seljak, B.; Eftimov, T. A Fine-Tuned Bidirectional Encoder Representations from Transformers Model for Food Named-Entity Recognition: Algorithm Development and Validation. J. Med. Internet Res. 2021, 23, e28229. [Google Scholar] [CrossRef] [PubMed]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent Trends in Deep Learning Based Natural Language Processing. CoRR 2017, 13, 55–75. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics: San Diego, CA, USA, 2016; pp. 260–270. [Google Scholar]
- Panchendrarajan, R.; Amaresan, A. Bidirectional LSTM-CRF for Named Entity Recognition. In Proceedings of the 32nd Pacific Asia Conference on Language, Information and Computation, Hong Kong, China, 1–3 December 2018; Association for Computational Linguistics: Hong Kong, China, 2018. [Google Scholar]
- Goyal, A.; Gupta, V.; Kumar, M. Recurrent Neural Network-Based Model for Named Entity Recognition with Improved Word Embeddings. IETE J. Res. 2021, 1–7. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, R.; Zhou, E. Stock Prediction Based on Optimized LSTM and GRU Models. Sci. Program. 2021, 2021, 4055281. [Google Scholar] [CrossRef]
- Banik, N.; Rahman, M.H.H. GRU Based Named Entity Recognition System for Bangla Online Newspapers. In Proceedings of the 2018 International Conference on Innovation in Engineering and Technology (ICIET); IEEE: Dhaka, Bangladesh, 2018; pp. 1–6. [Google Scholar]
- Yan, S.; Chai, J.; Wu, L. Bidirectional GRU with Multi-Head Attention for Chinese NER. In Proceedings of the 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 12–14 June 2020; pp. 1160–1164. [Google Scholar]
- Yang, Z.; Salakhutdinov, R.; Cohen, W.W. Multi-Task Cross-Lingual Sequence Tagging from Scratch. arXiv 2016, arXiv:1603.06270. [Google Scholar]
- Soltau, H.; Shafran, I.; Wang, M.; Shafey, L.E. RNN Transducers for Nested Named Entity Recognition with Constraints on Alignment for Long Sequences. arXiv 2022, arXiv:2203.03543. [Google Scholar]
- Chowdhury, S.; Dong, X.; Qian, L.; Li, X.; Guan, Y.; Yang, J.; Yu, Q. A Multitask Bi-Directional RNN Model for Named Entity Recognition on Chinese Electronic Medical Records. BMC Bioinform. 2018, 19, 499. [Google Scholar] [CrossRef] [Green Version]
- Maclin, R.; Opitz, D.W. Popular Ensemble Methods: An Empirical Study. arXiv 2011, arXiv:1106.0257. [Google Scholar]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Multiple Classifier Systems; MCS 2000. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2000; Volume 1857. [Google Scholar] [CrossRef] [Green Version]
- Sarkar, D.; Natarajan, V. Ensemble Machine Learning Cookbook: Over 35 Practical Recipes to Explore Ensemble Machine Learning Techniques Using Python; Packt: Birmingham/Mumbai, India, 2019; ISBN 978-1-78913-660-9. [Google Scholar]
- Zhou, Z.-H. Ensemble Methods: Foundations and Algorithms; Chapman & Hall/CRC Machine Learning & Pattern Recognition Series; Taylor & Francis: Boca Raton, FL, USA, 2012; ISBN 978-1-4398-3003-1. [Google Scholar]
- Allrecipes. Available online: https://www.allrecipes.com/ (accessed on 10 September 2021).
- SpaCy. Available online: https://spacy.io/ (accessed on 5 March 2022).
- Loper, E.; Bird, S. NLTK: The Natural Language Toolkit. arXiv 2002, arXiv:cs/0205028. [Google Scholar]
- Doccano: Text Annotation Tool for Human. Available online: https://github.com/doccano/doccano (accessed on 5 March 2022).
- Boushehri, S.S.; Qasim, A.B.; Waibel, D.; Schmich, F.; Marr, C. Annotation-Efficient Classification Combining Active Learning, Pre-Training and Semi-Supervised Learning for Biomedical Images. bioRxiv 2020, 414235. [Google Scholar] [CrossRef]
- Ramshaw, L.A.; Marcus, M.P. Text Chunking Using Transformation-Based Learning. In Natural Language Processing Using Very Large Corpora; Text Speech and Language Technology; Armstrong, S., Church, K., Isabelle, P., Manzi, S., Tzoukermann, E., Yarowsky, D., Eds.; Springer: Dordrecht, The Netherlands, 1999; Volume 11, pp. 157–176. ISBN 978-90-481-5349-7. [Google Scholar]
- Understanding LSTM Networks—Colah’s Blog. Available online: http://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 3 May 2022).
- Williams, R.J.; Peng, J. An Efficient Gradient-Based Algorithm for On-Line Training of Recurrent Network Trajectories. Neural Comput. 1990, 2, 490–501. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning Long-Term Dependencies with Gradient Descent Is Difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 103–111. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Deng, Y.; Jiao, Y.; Lu, B.-L. Driver Sleepiness Detection Using LSTM Neural Network. In Neural Information Processing; Lecture Notes in Computer Science; Cheng, L., Leung, A.C.S., Ozawa, S., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11304, pp. 622–633. ISBN 978-3-030-04211-0. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1724–1734. [Google Scholar]
- Alizadeh, H.; Yousefnezhad, M.; Bidgoli, B.M. Wisdom of Crowds Cluster Ensemble. IDA 2015, 19, 485–503. [Google Scholar] [CrossRef]
- Oza, N.C.; Russell, S. Online Ensemble Learning. Ph.D. Thesis, University of California, Berkeley, CA, USA, 2001. [Google Scholar]
- Pennington, J.; Socher, R.; Maning, C.D. GloVe: Global Vectors for Word Representation. Available online: https://nlp.stanford.edu/projects/glove/ (accessed on 3 May 2022).
- Sokolova, M.; Lapalme, G. A Systematic Analysis of Performance Measures for Classification Tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Allwein, E.L.; Schapire, R.E.; Singer, Y. Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers. J. Mach. Learn. Res. 2001, 1, 113–141. [Google Scholar] [CrossRef]
- Fumera, G.; Roli, F. A Theoretical and Experimental Analysis of Linear Combiners for Multiple Classifier Systems. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 942–956. [Google Scholar] [CrossRef]
- Komariah, K.S.; Sin, B.-K.; Purnomo, A.T. FINER: Food Ingredient NER Dataset (Version 3). Figshare. 2022. Available online: https://doi.org/10.6084/m9.figshare.20222361.v3 (accessed on 5 May 2022).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Ensemble Scheme | Classifiers | Dataset | Performance Metrics |
|---|---|---|---|---|
| [9] | Voting | MLP, ABM1, J48 | Reuters corpus | Recall, Precision, Error rate, MCC, F1 score |
| [10] | Weighted Voting | ME, CRF, SVM | Bengali News corpus, NERSSEAL, CoNLL-2003 | F1 score |
| [11] | Concatenation | Neural Networks | OKE2016, AIDA/CoNLL, NexGenTV corpus | Recall, Precision, F1 score |
| [12] | Arbitration Rules, Stacked Generalization, Cascade Generalization | Generalized Winnow, ME, SVM, CRF | GENIA, JNLPBA | Recall, Precision, F1 score |
| [13] | Voting | 5 NER systems: Stanford NER, NER-Tagger, Edinburgh Geoparser, spaCy NER, Polyglot | The Marry Hamilton Papers, The Samuel Hartlib Papers | Recall, Precision, F1 score |
| [14] | Majority Voting | BERT, CNN, CamemBERT, CamemBERT-bio, XL-Net, RoBERTa, BioBERT, Bio + ClinicalBERT, PubMedBERT, BioMed RoBERTa | ChEMU 2020, DEFT 2020, WNUT 2020 | F1 score |
| [15] | Majority Voting, Stacking | SVM, CRF, ME | i2b2 2010 corpus | Recall, Precision, F1 score |
| [16] | Majority Voting | BERT-base-cased, BERT-based-uncased, CNN | ChEMU NER Task | Recall, Precision, F1 score |
| [17] | Plurality Voting, Weighted Voting | HMM, CRF, MEM, BiLSTM | Private (Authors private data) | F1 score |
| Total number of words | 1,397,960 |
| Total number of sentences | 181,970 |
| Total number of entities (without O tags) | 1,177,660 |
| Total number of tags (without O tags) | 10 |
| Class | Description | Example |
|---|---|---|
| INGREDIENT | Name of the food or ingredient. | Carrots, garlic, vegetable oil, etc. |
| PRODUCT | Food or ingredient from specific brand mention. | Tabasco-brand chipotle pepper sauce, Archer farms dark chocolate hot cocoa mix, etc. |
| QUANTITY | Measurement unit. | Gram, pound, tablespoon, etc. |
| STATE | Processing state of the food or ingredient. | Minced, chopped, cut into 2-inch strips, etc. |
| UNIT | Measurements of the food or ingredient associated with the unit. | 1 ½, 25, 0.5, etc. |
| Tag | Definition |
|---|---|
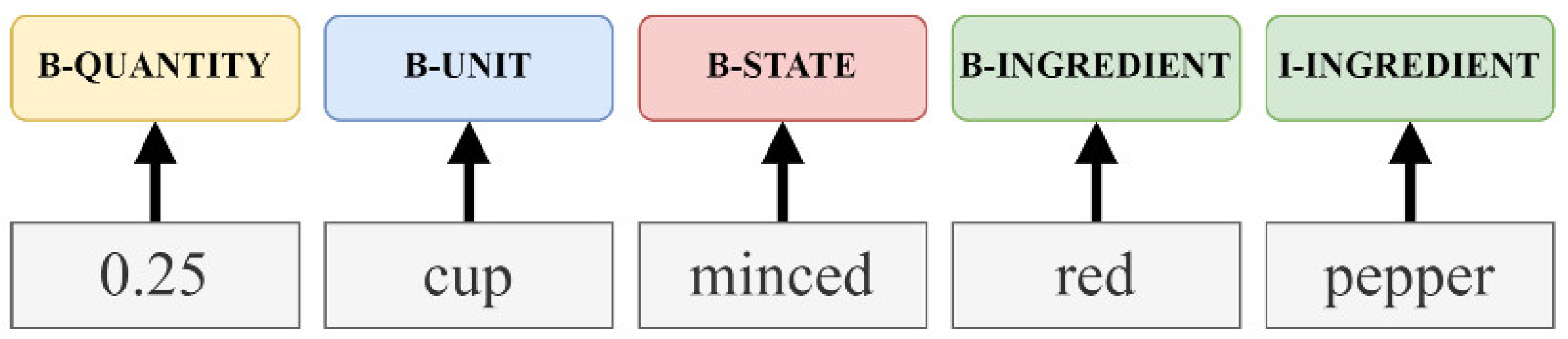
| B (Begin) | Prefix before a tag indicates that the tag is the beginning of a chunk. |
| I (Inside) | Prefix before a tag indicates that the tag is inside a chunk. |
| O (Outside) | Tag indicates that a token belongs to a non-chunk (outside). |
| Named-Entity Type | Count | Ratio (%) |
|---|---|---|
| B-INGREDIENT | 210,082 | 15.03 |
| B-PRODUCT | 17,325 | 1.24 |
| B-QUANTITY | 209,867 | 15.01 |
| B-STATE | 135,315 | 9.68 |
| B-UNIT | 174,993 | 12.52 |
| I-INGREDIENT | 240,436 | 17.20 |
| I-PRODUCT | 55,212 | 3.95 |
| I-QUANTITY | 1919 | 0.14 |
| I-STATE | 130,158 | 9.31 |
| I-UNIT | 2353 | 0.17 |
| O (outside or non-entity chunk) | 220,300 | 15.76 |
| Total | 1,397,960 | 100 |
| Model | F1 Score (%) | |
|---|---|---|
| Unidirectional | Bidirectional | |
| RNN | 94.57 | 95.53 |
| GRU | 94.95 | 95.85 |
| LSTM | 94.98 | 95.70 |
| RNE | 95.17 | 96.09 |
| Class | Bi-RNN | Bi-GRU | Bi-LSTM | RNE | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| B-INGREDIENT | 0.948 | 0.971 | 0.960 | 0.954 | 0.974 | 0.964 | 0.956 | 0.971 | 0.964 | 0.958 | 0.977 | 0.968 |
| B-PRODUCT | 0.887 | 0.935 | 0.910 | 0.890 | 0.943 | 0.916 | 0.885 | 0.941 | 0.912 | 0.891 | 0.946 | 0.917 |
| B-QUALITY | 0.977 | 0.964 | 0.970 | 0.967 | 0.976 | 0.972 | 0.971 | 0.971 | 0.971 | 0.975 | 0.976 | 0.975 |
| B-STATE | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 |
| B-UNIT | 0.995 | 0.998 | 0.996 | 0.997 | 0.997 | 0.997 | 0.995 | 0.998 | 0.997 | 0.997 | 0.997 | 0.997 |
| I-INGREDIENT | 0.970 | 0.969 | 0.996 | 0.978 | 0.969 | 0.974 | 0.971 | 0.971 | 0.971 | 0.979 | 0.974 | 0.977 |
| I-PRODUCT | 0.937 | 0.968 | 0.952 | 0.951 | 0.965 | 0.958 | 0.947 | 0.961 | 0.954 | 0.952 | 0.970 | 0.961 |
| I-QUALITY | 0.911 | 0.960 | 0.935 | 0.936 | 0.959 | 0.947 | 0.928 | 0.961 | 0.945 | 0.937 | 0.967 | 0.951 |
| I-STATE | 0.943 | 0.951 | 0.947 | 0.922 | 0.958 | 0.940 | 0.906 | 0.961 | 0.933 | 0.937 | 0.968 | 0.953 |
| I-UNIT | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.998 | 1.000 | 0.999 | 1.000 | 1.000 | 1.000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Komariah, K.S.; Sin, B.-K. Enhancing Food Ingredient Named-Entity Recognition with Recurrent Network-Based Ensemble (RNE) Model. Appl. Sci. 2022, 12, 10310. https://doi.org/10.3390/app122010310
Komariah KS, Sin B-K. Enhancing Food Ingredient Named-Entity Recognition with Recurrent Network-Based Ensemble (RNE) Model. Applied Sciences. 2022; 12(20):10310. https://doi.org/10.3390/app122010310
Chicago/Turabian StyleKomariah, Kokoy Siti, and Bong-Kee Sin. 2022. "Enhancing Food Ingredient Named-Entity Recognition with Recurrent Network-Based Ensemble (RNE) Model" Applied Sciences 12, no. 20: 10310. https://doi.org/10.3390/app122010310
APA StyleKomariah, K. S., & Sin, B. -K. (2022). Enhancing Food Ingredient Named-Entity Recognition with Recurrent Network-Based Ensemble (RNE) Model. Applied Sciences, 12(20), 10310. https://doi.org/10.3390/app122010310