

The Effects of High-Performance Cloud System for Network Function Virtualization

Abstract
1. Introduction
- Proposing a comprehensive testing framework to investigate a practical cloud system on different areas of performance effects.
- Conducting performance comparisons between the generic and the enhanced cloud system for NFV.
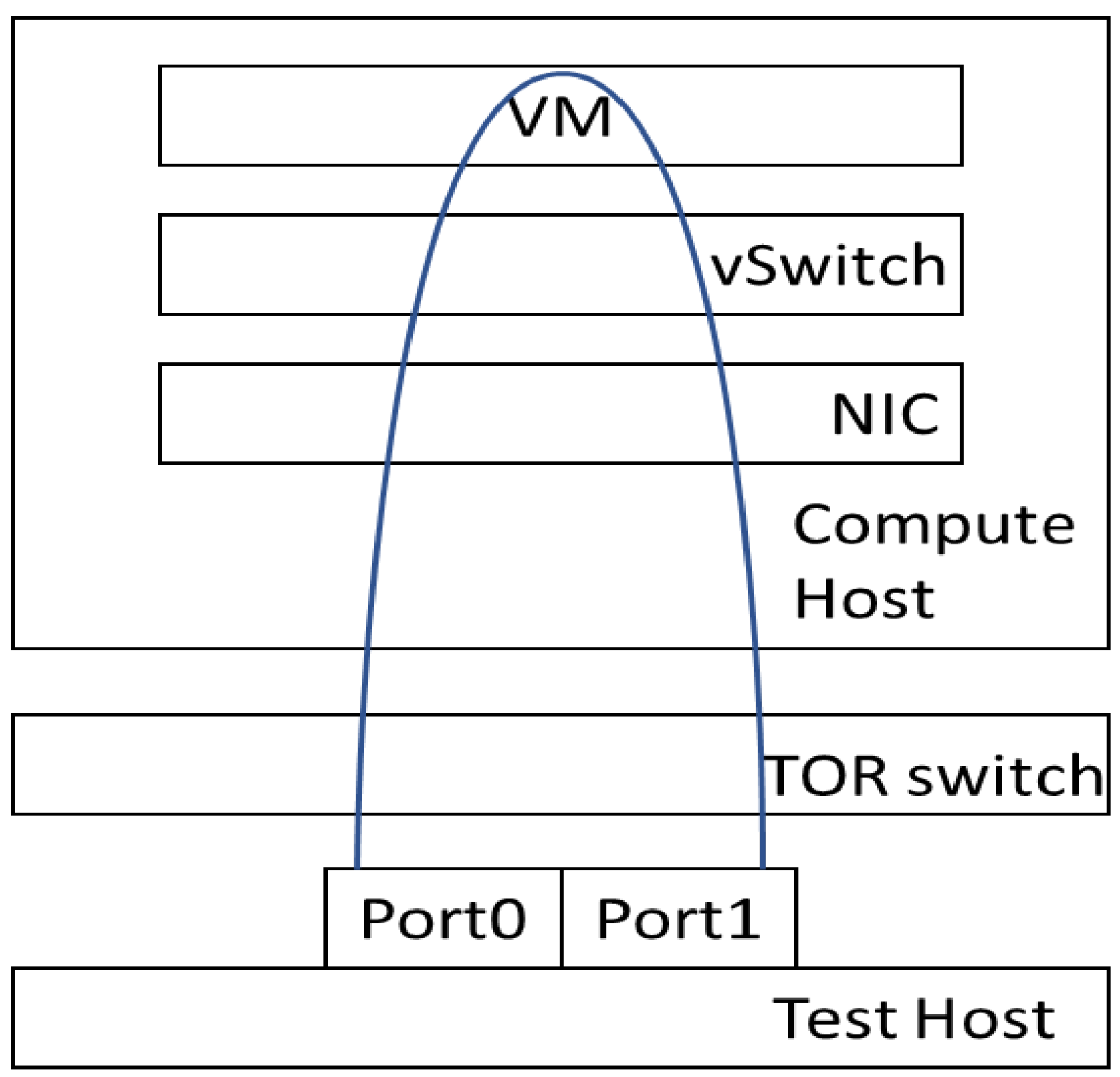
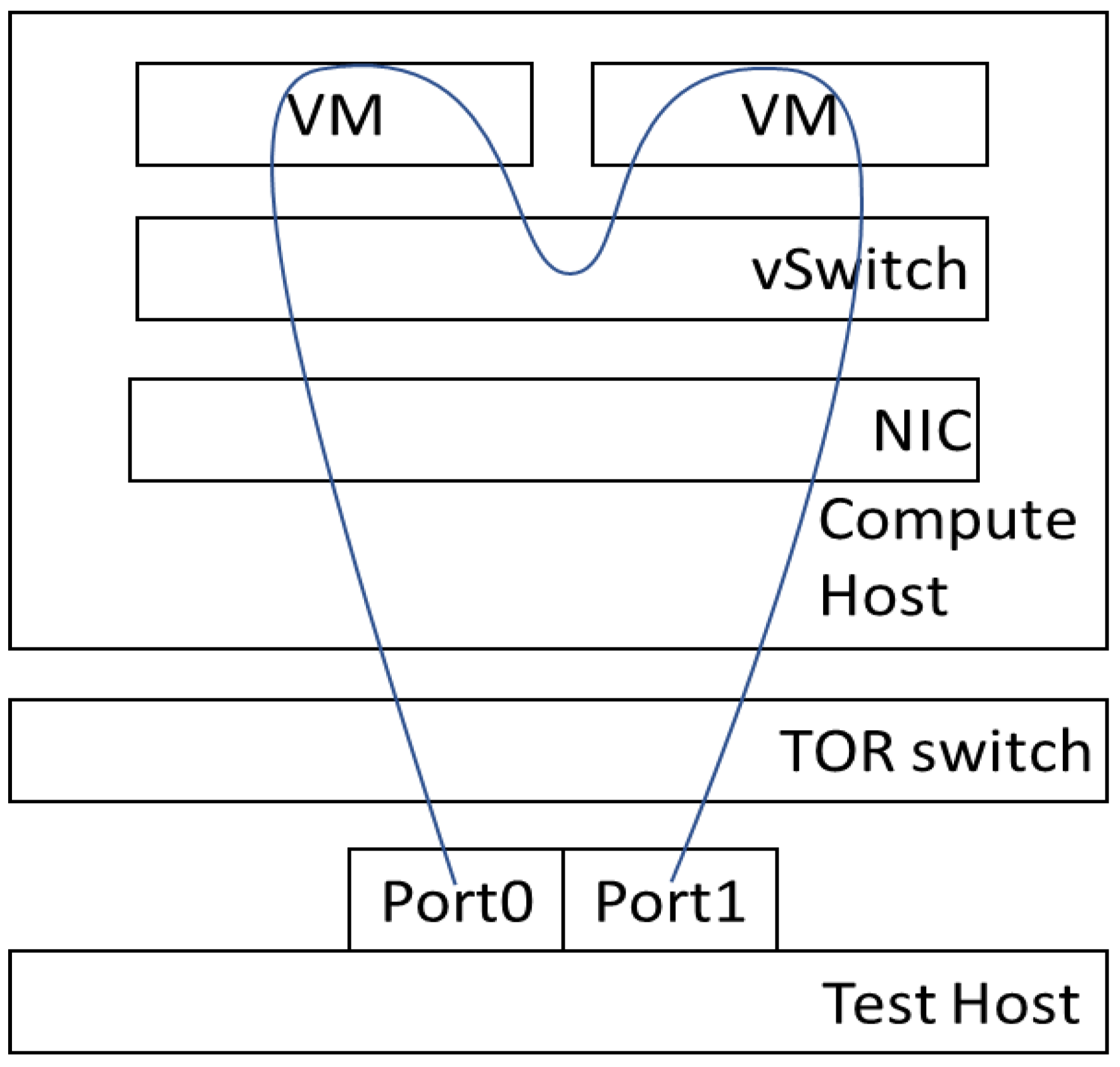
- Considering both PVP and PVVP packet paths for different SFC scenarios.
- Deploying the vIMS application on the enhanced cloud system to show effective performance.
2. Background and Related Works
2.1. Background
- CPU Isolation
- CPU Pinning
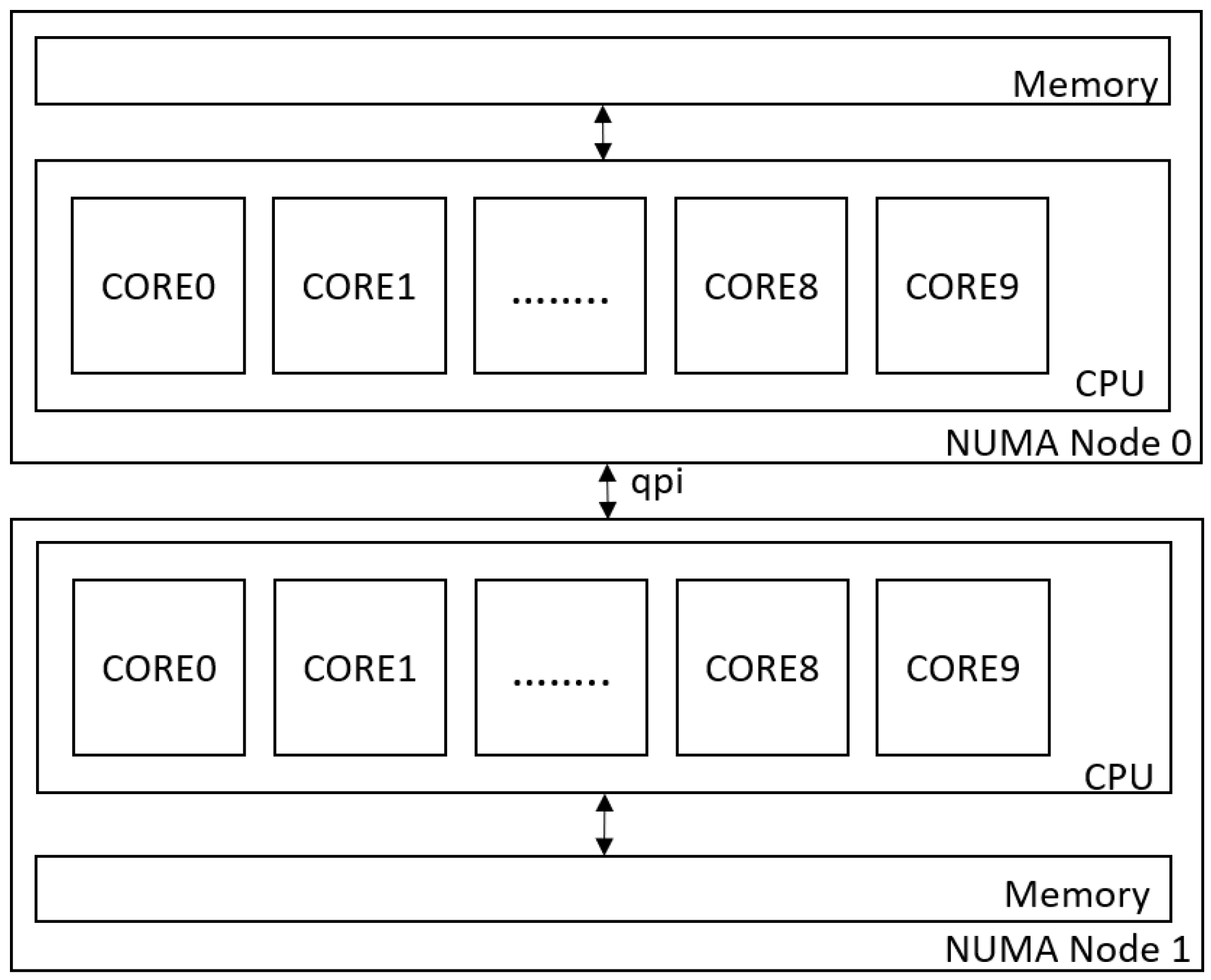
- Nonuniform Memory Access
- Hugepage
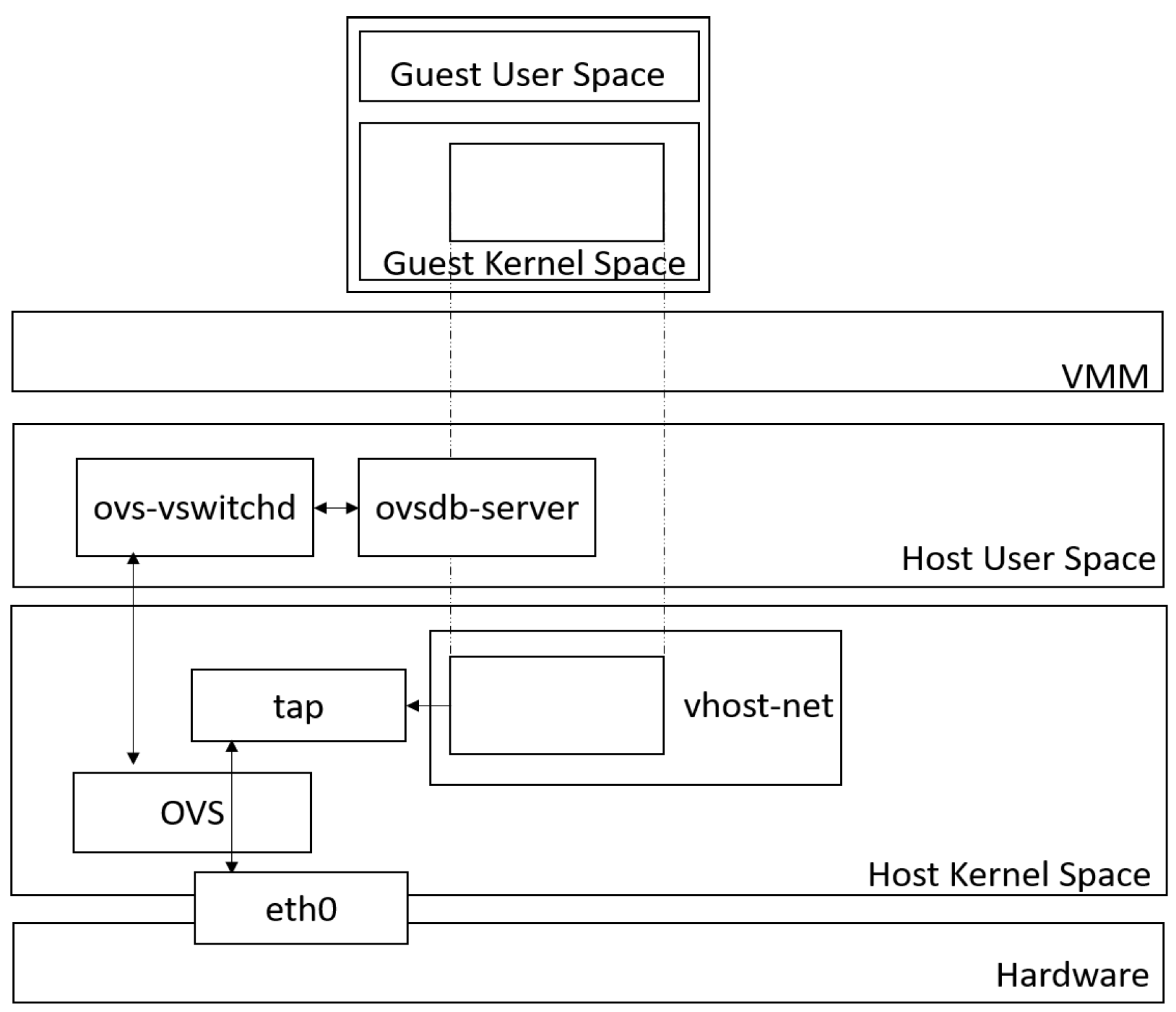
- OVS
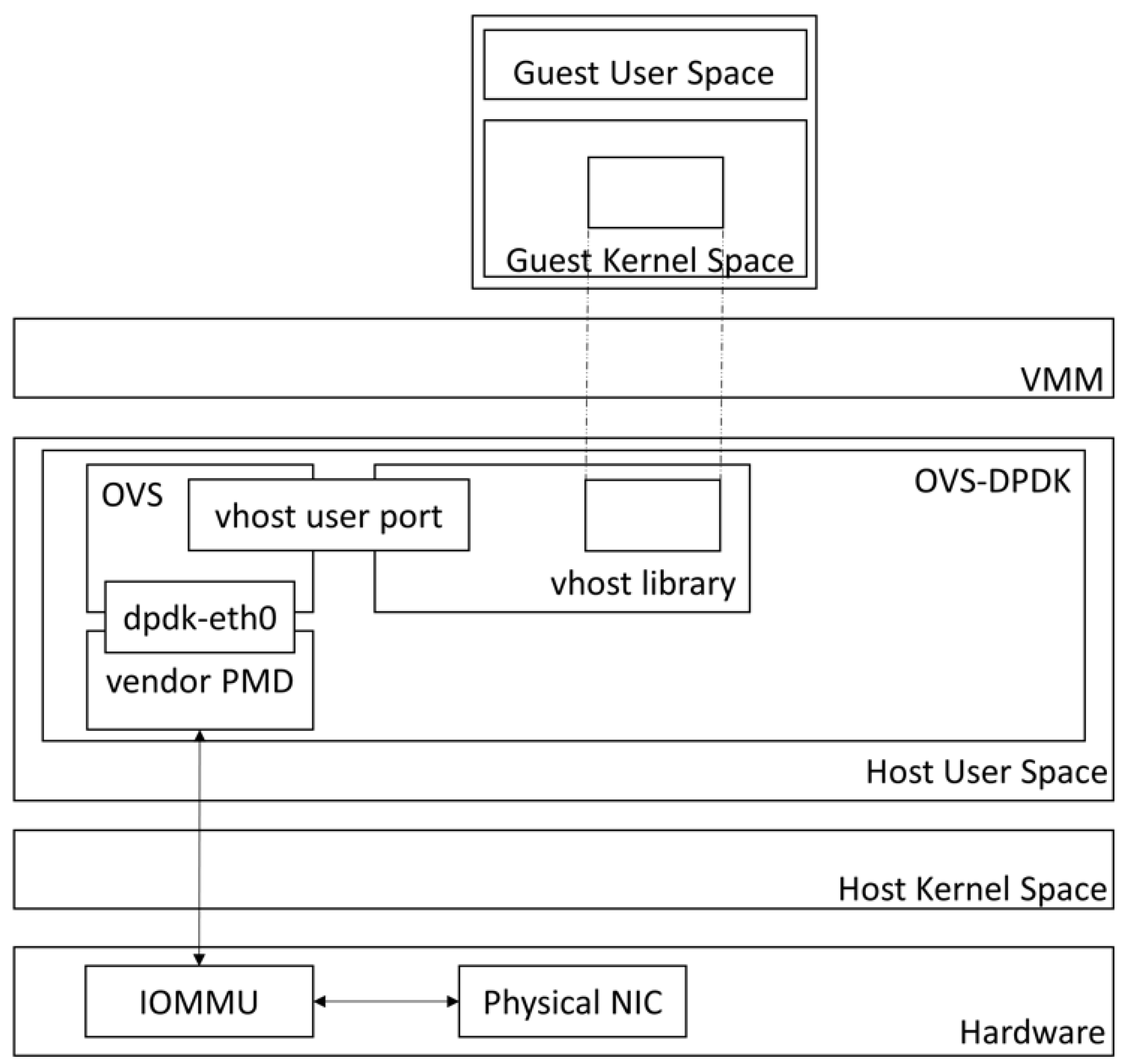
- OVS-DPDK
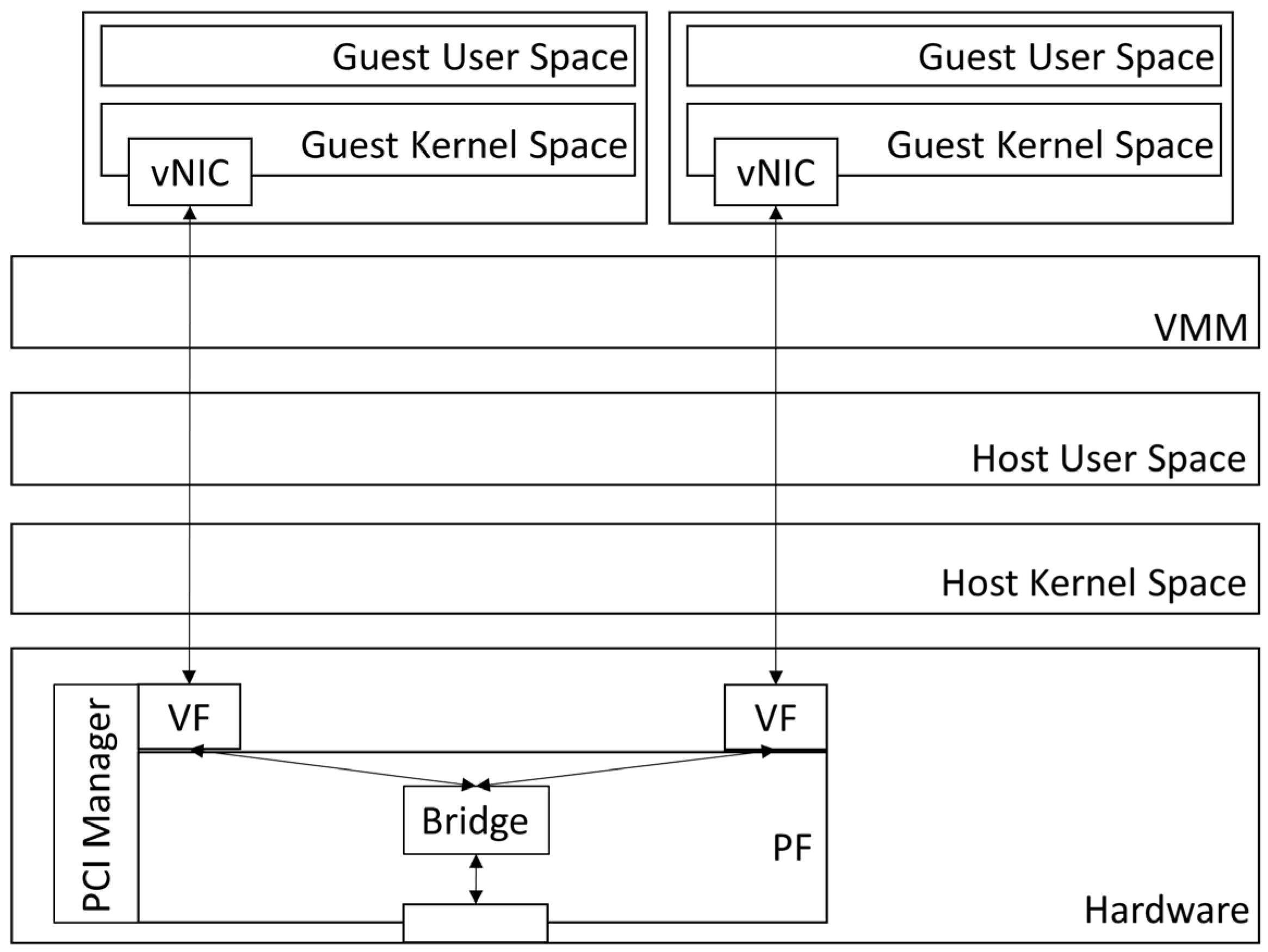
- SR-IOV
2.2. Related Works
3. Methodology
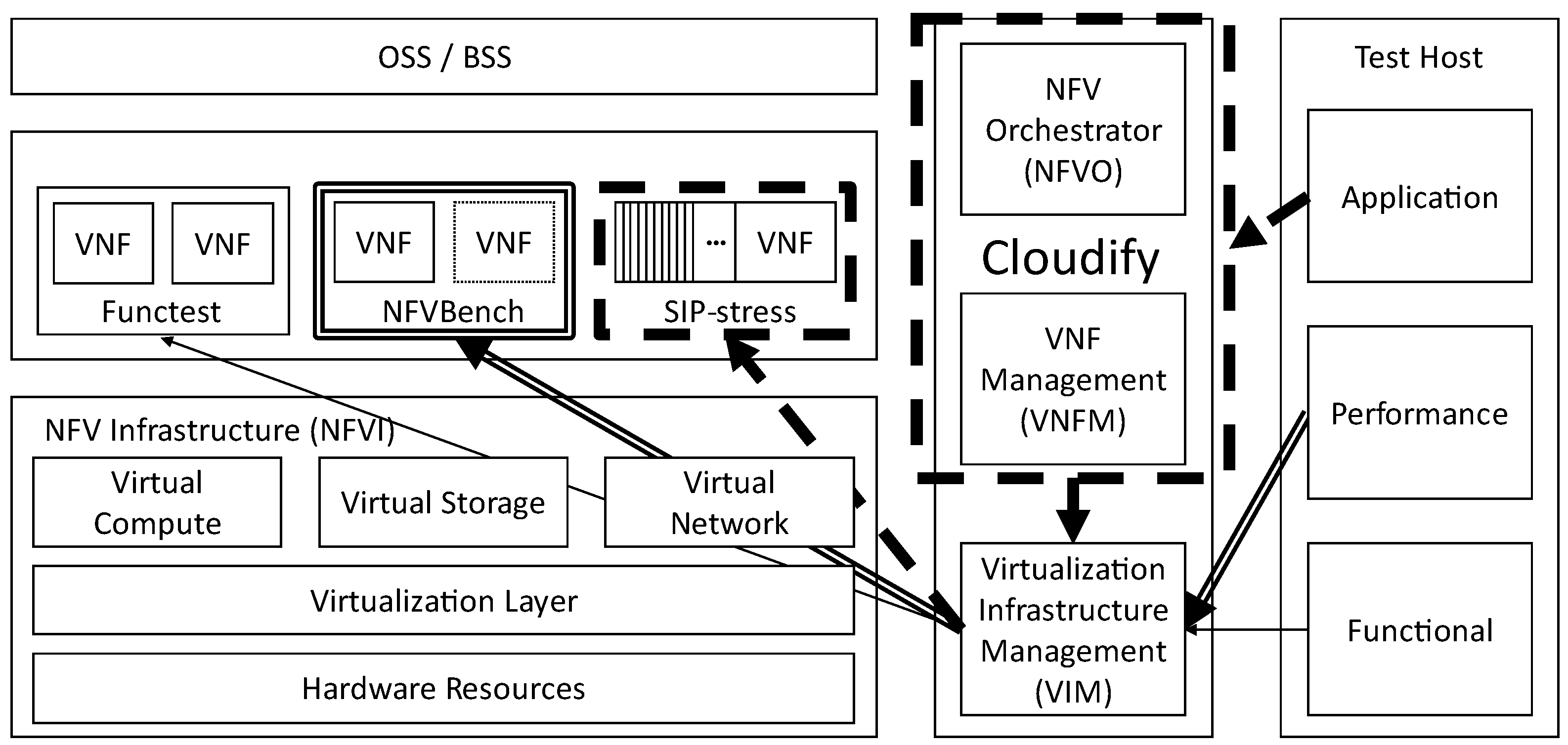
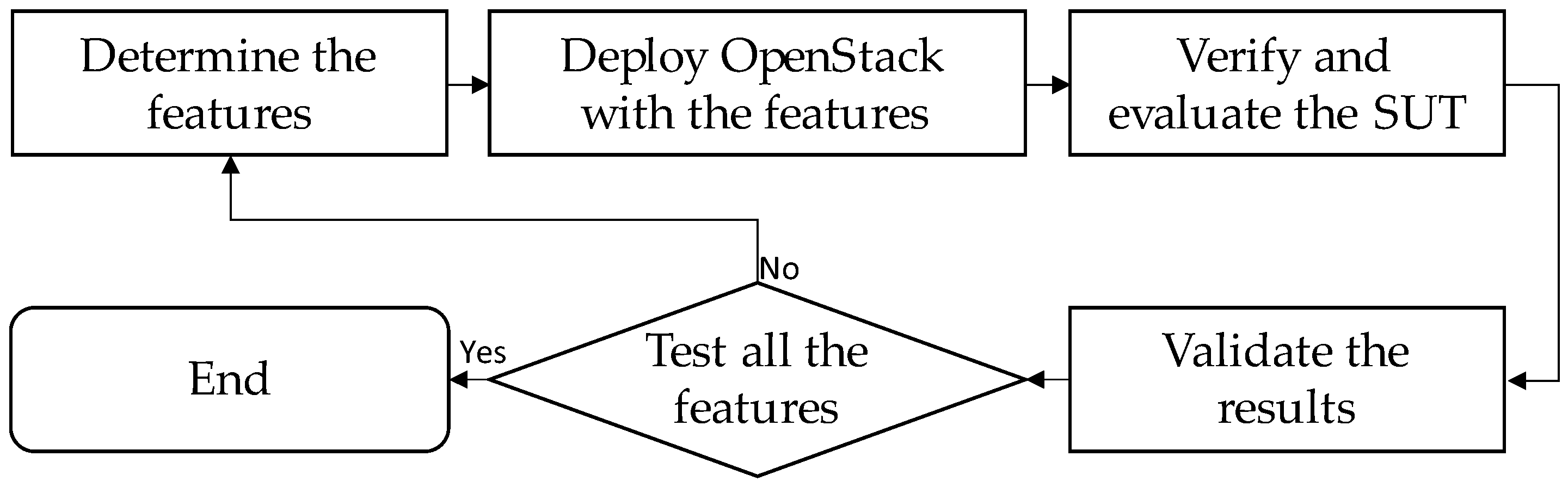
3.1. Overview of Testing Framework
3.1.1. Functionality Verification
3.1.2. Performance Verification
3.1.3. Application Verification
3.2. Verification Procedures and Factors
- Packet Size
- VM Size
- Call Rate
4. Experiments and Evaluations
4.1. Testbed Environment
4.2. Results of Functional Verifications
4.3. Results of Performance Verifications
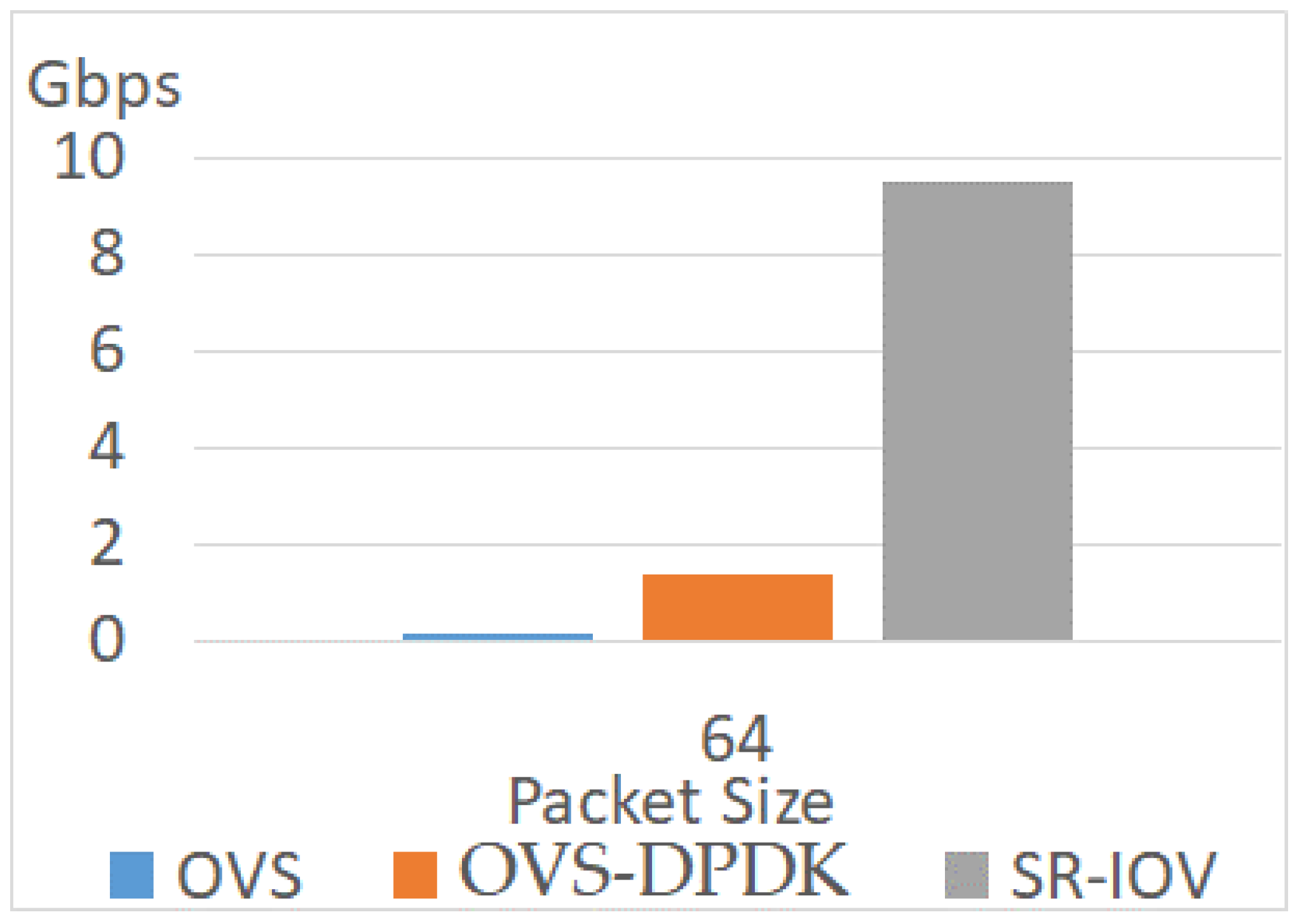
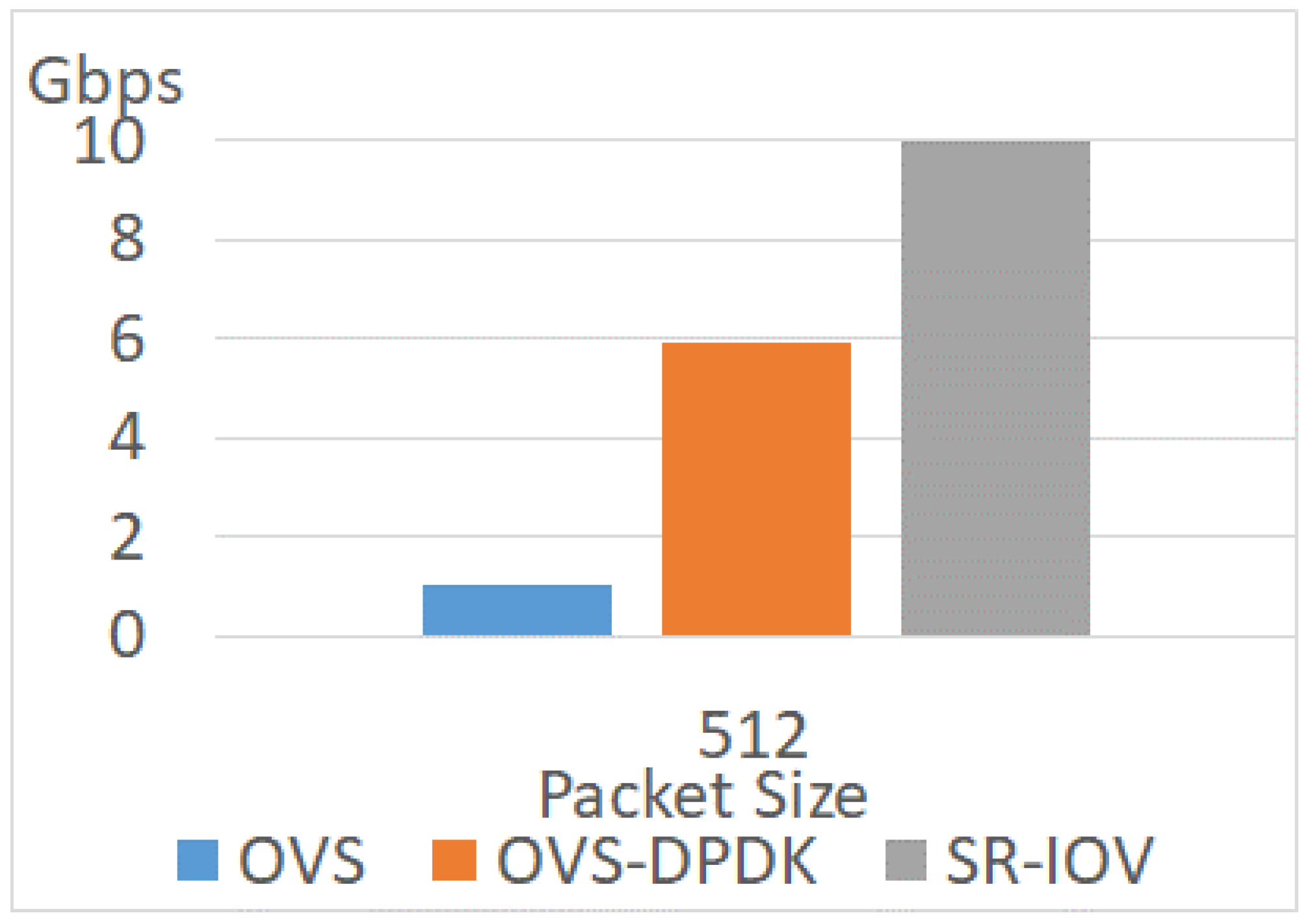
4.3.1. Different Network Techniques
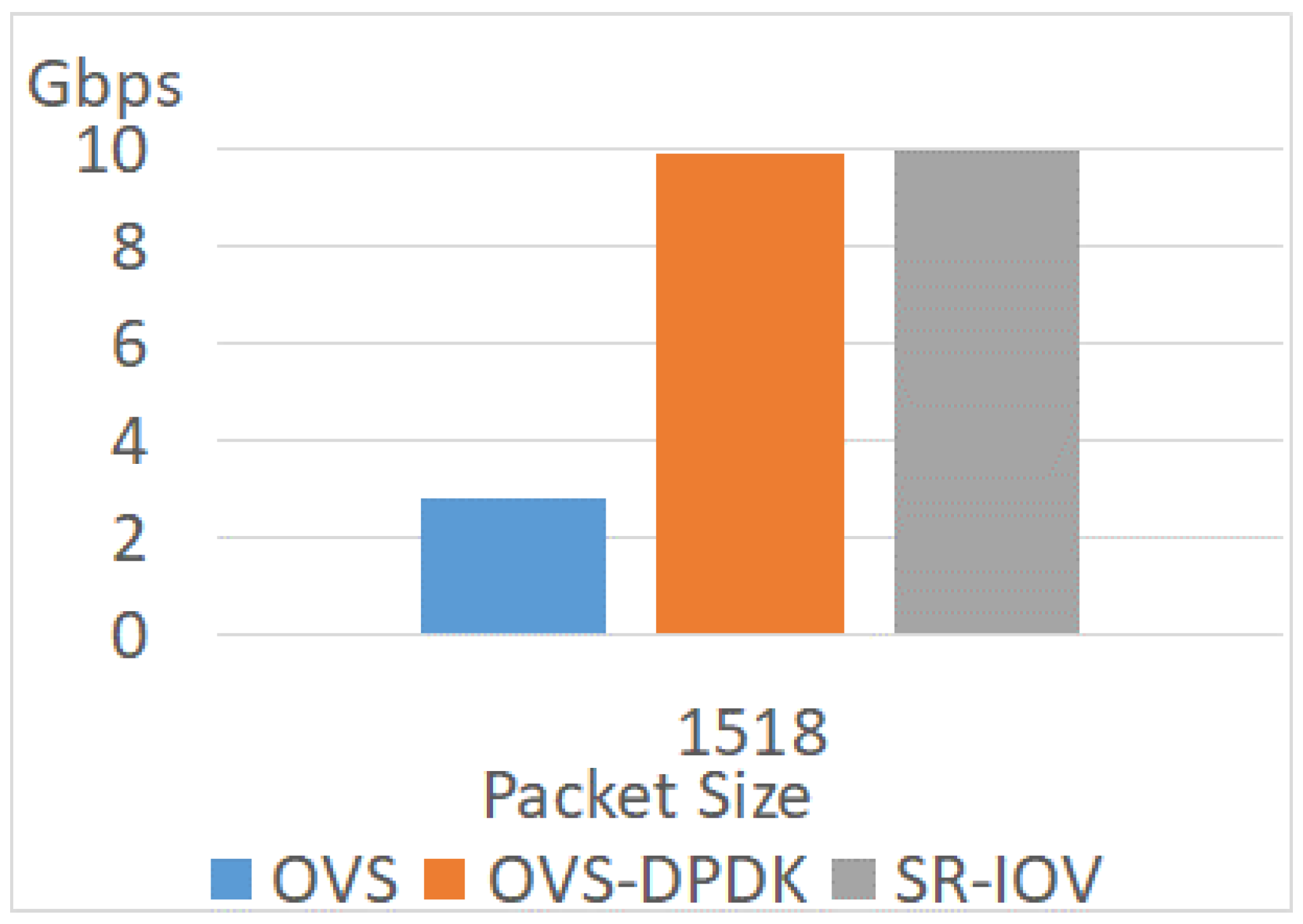
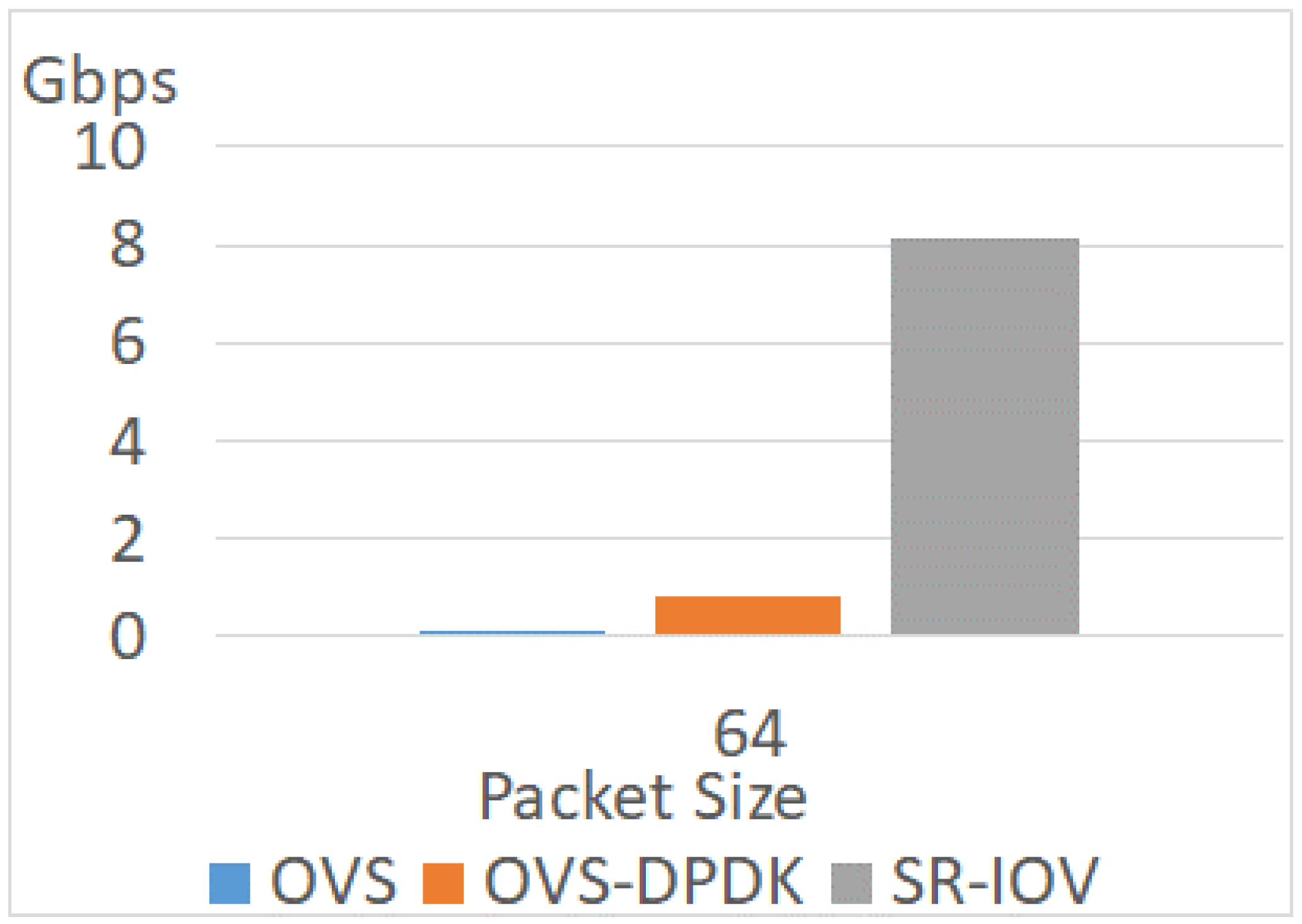
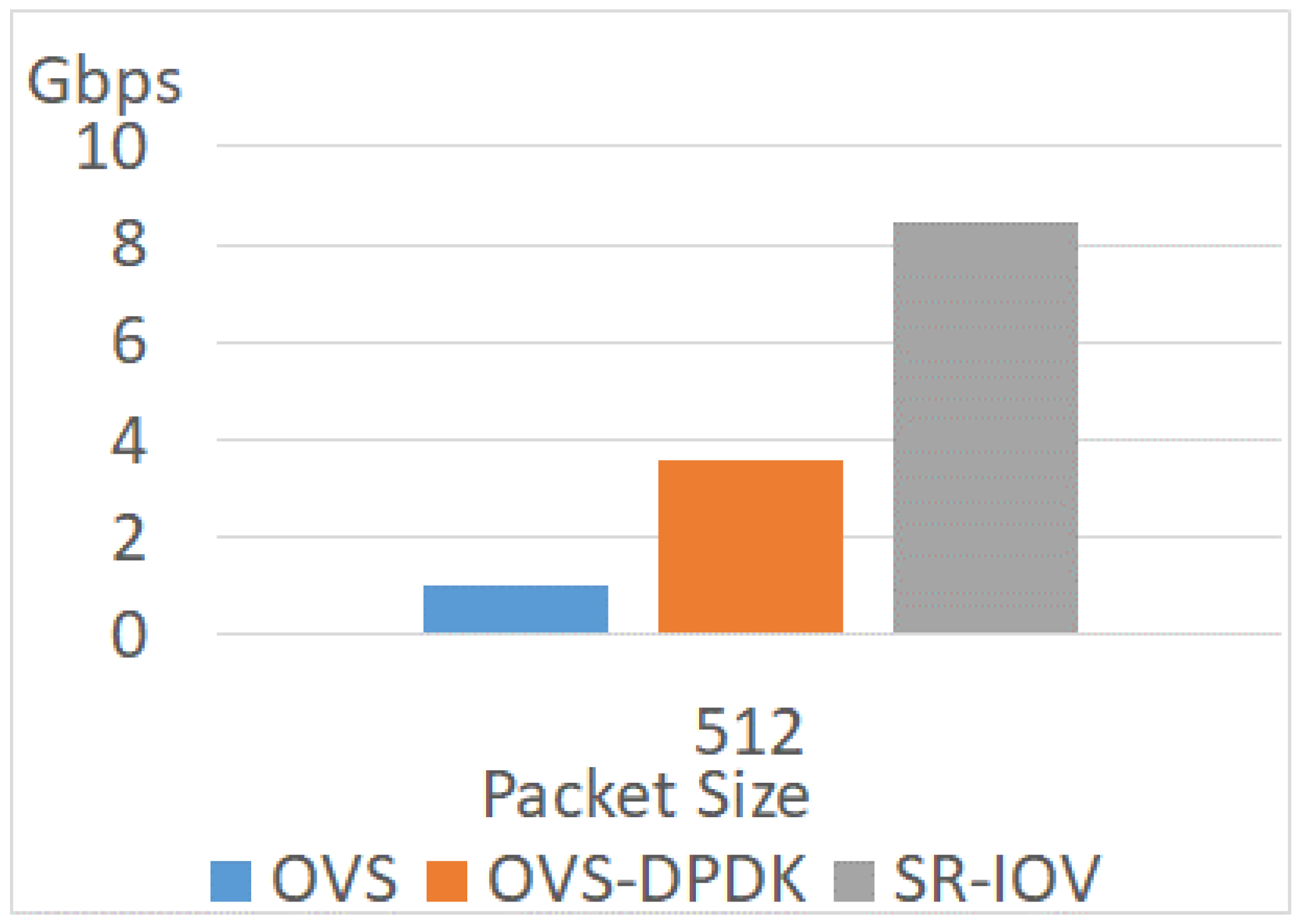
4.3.2. Different Packet Sizes
4.3.3. Different VM Sizes
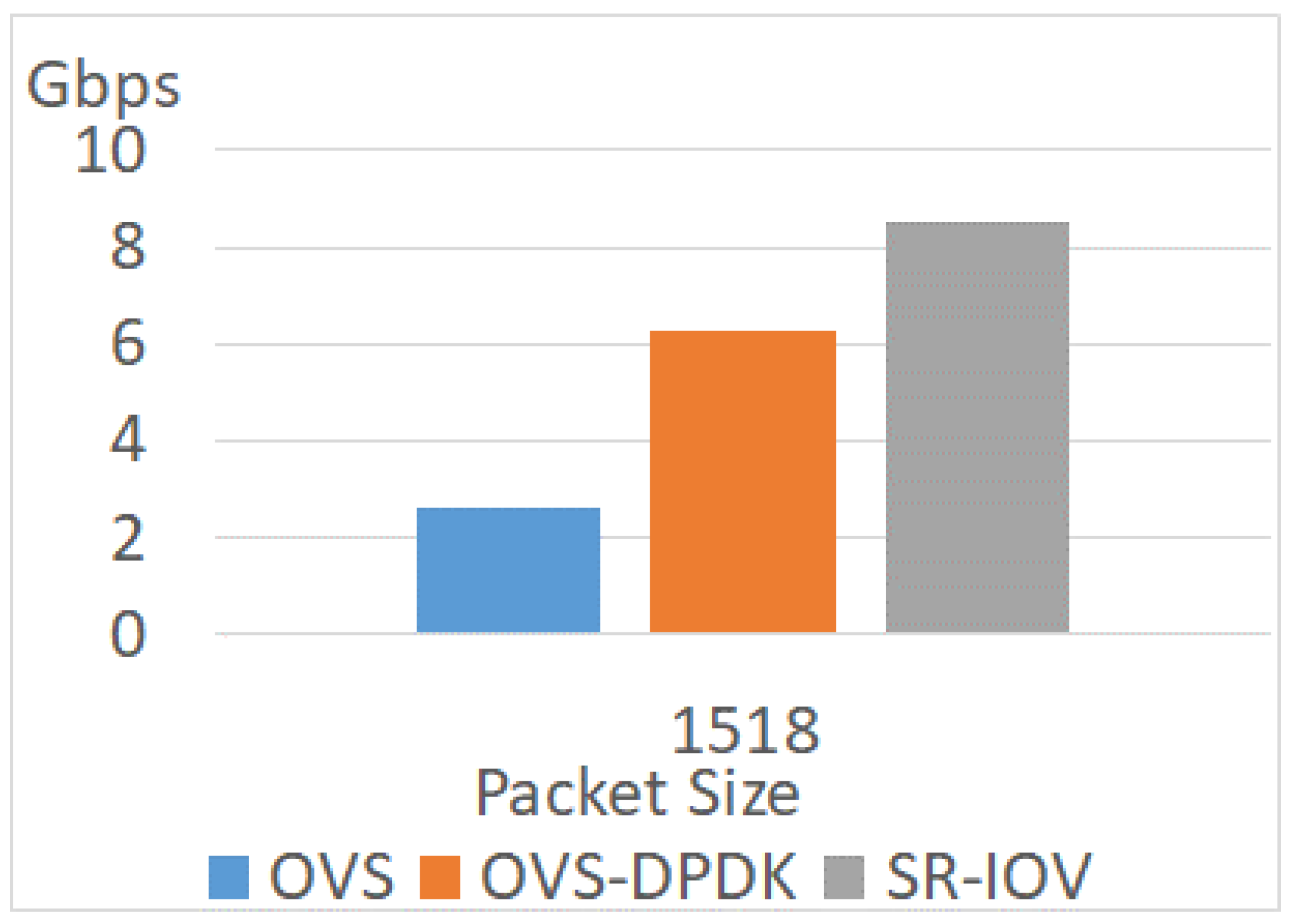
4.3.4. Different Traffic Flows
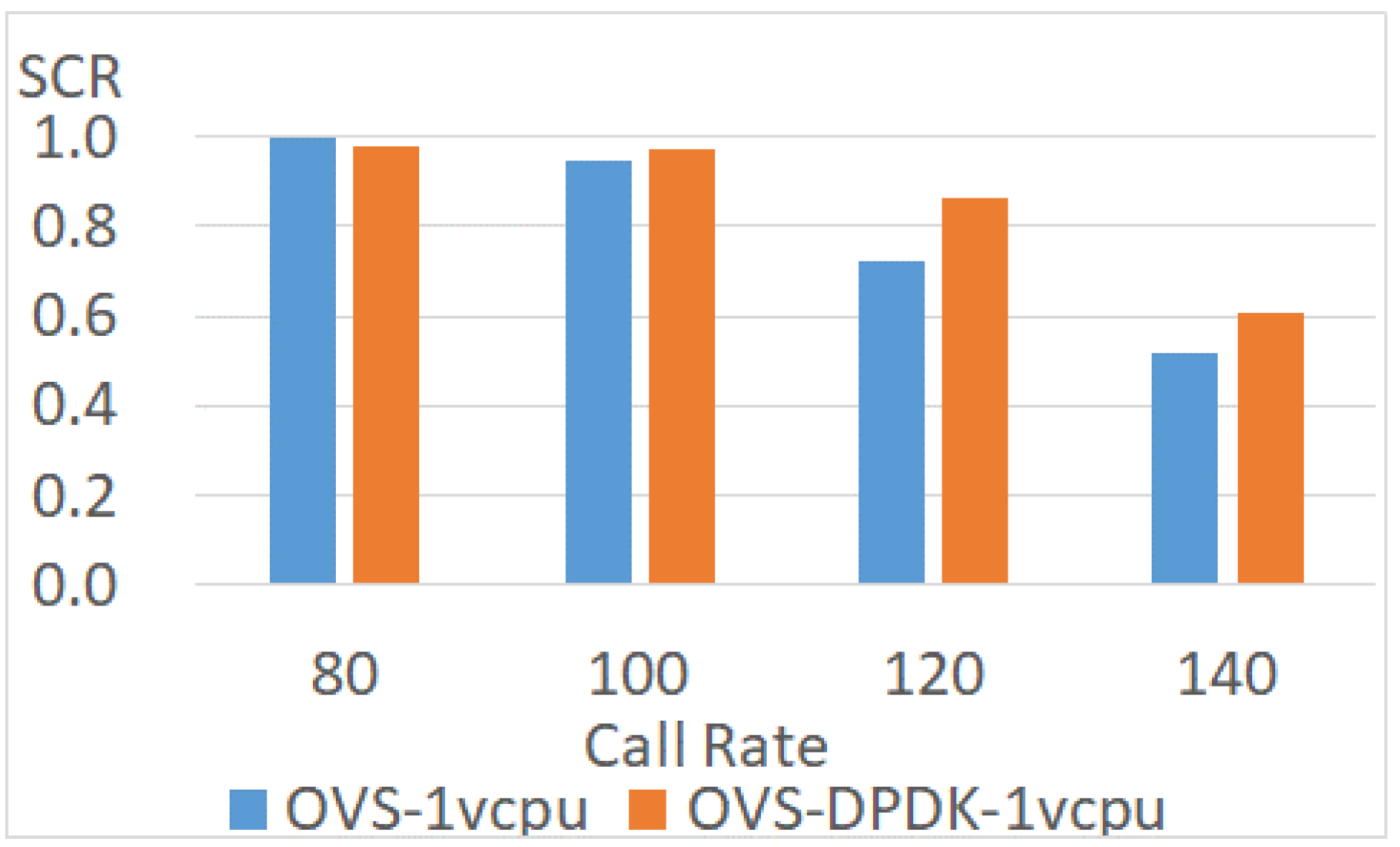
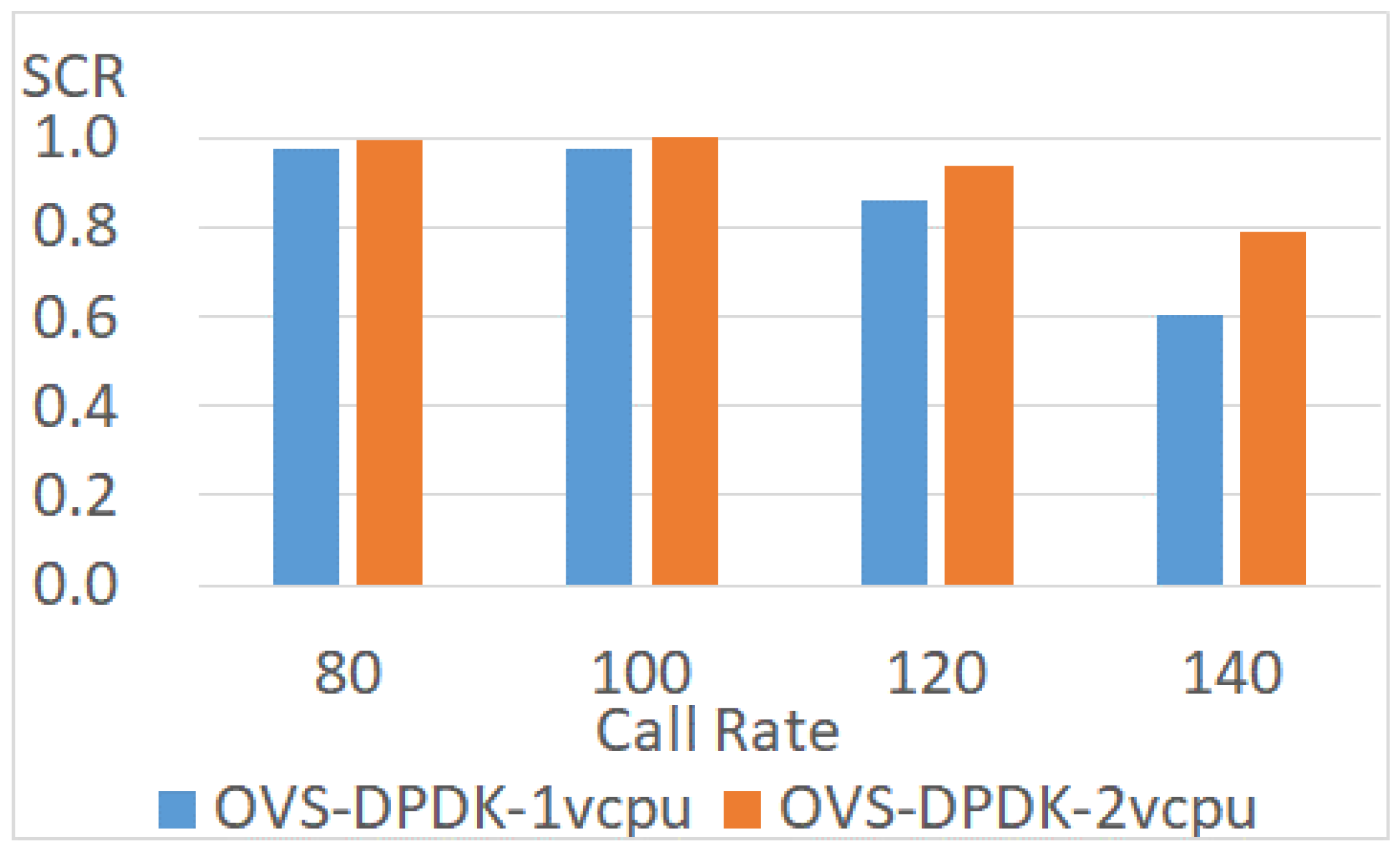
4.3.5. Enhanced Data Plane
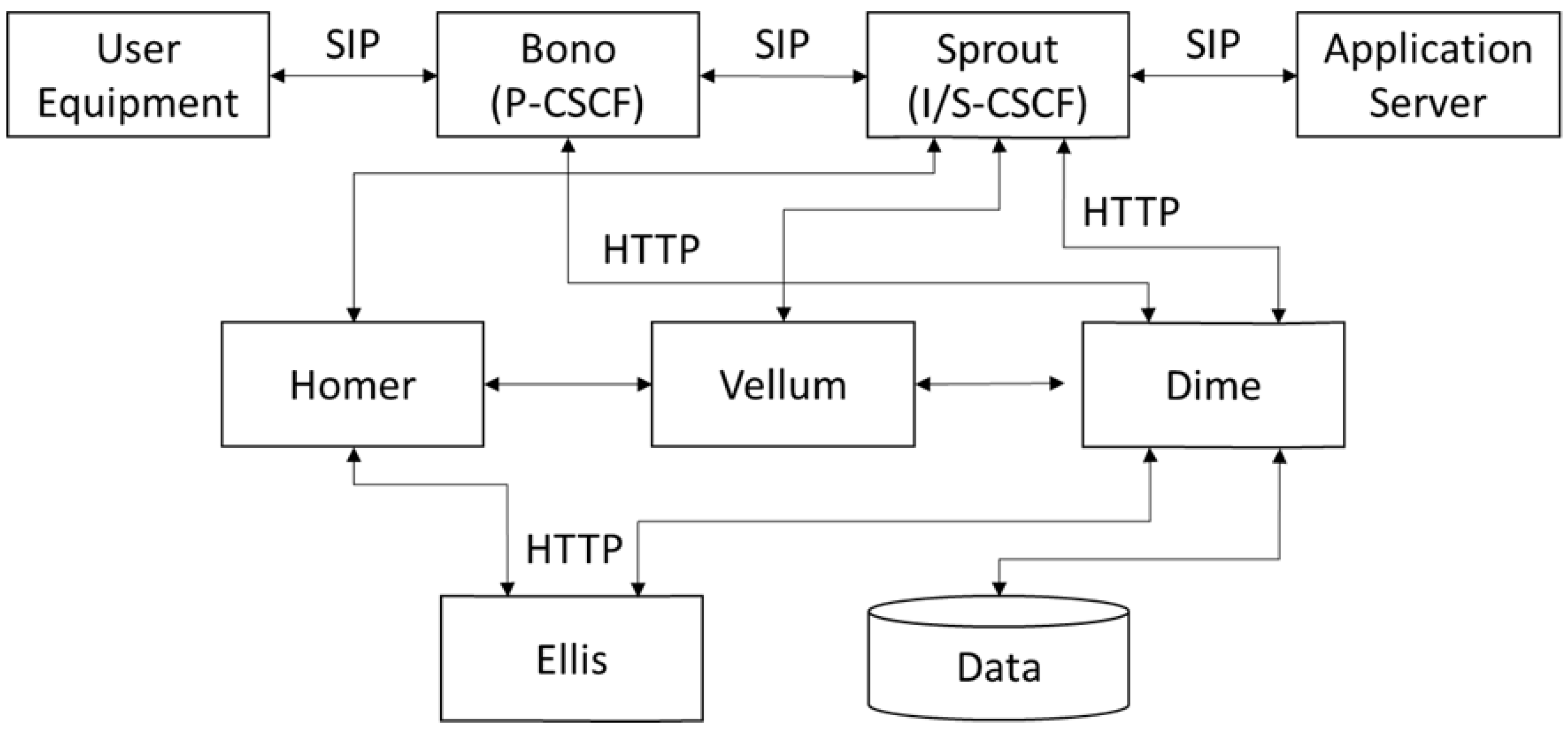
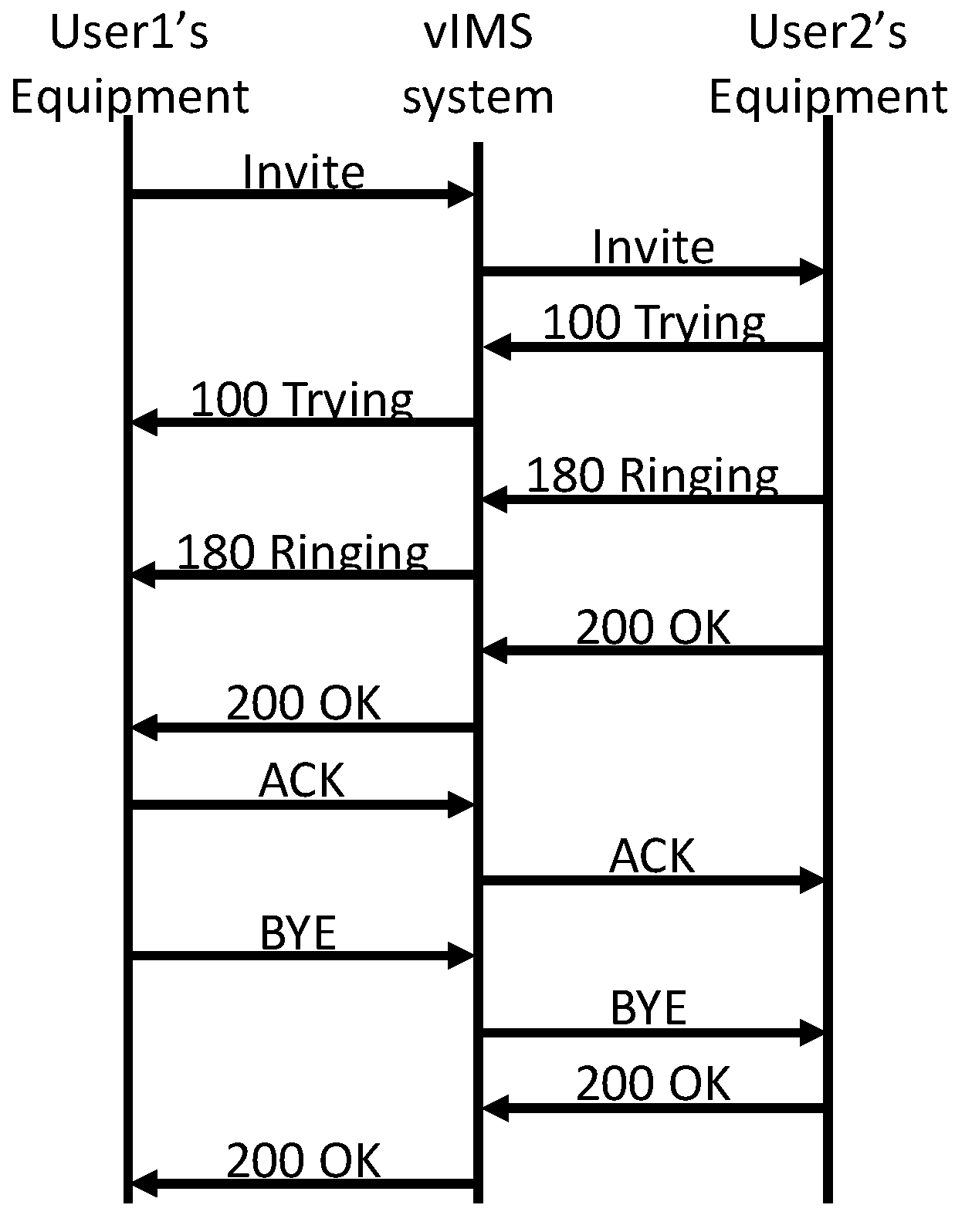
4.4. Results of Application Verifications
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Cases | Project | Tier | Result |
|---|---|---|---|
| connection_check | functest | healthcheck | PASS |
| tenantnetwork1 | functest | healthcheck | PASS |
| tenantnetwork2 | functest | healthcheck | PASS |
| vmready1 | functest | healthcheck | PASS |
| vmready2 | functest | healthcheck | PASS |
| singlevm1 | functest | healthcheck | PASS |
| singlevm2 | functest | healthcheck | PASS |
| vping_ssh | functest | healthcheck | PASS |
| vping_userdata | functest | healthcheck | PASS |
Appendix B
| Scenario | Errors | Success (SLA) |
|---|---|---|
| Authenticate.keystone | 0 | ✔ |
| Authenticate.validate_cinder | 0 | ✔ |
| Authenticate.validate_glance | 0 | ✔ |
| Authenticate.validate_heat | 0 | ✔ |
| Authenticate.validate_neutron | 0 | ✔ |
| Authenticate.validate_nova | 0 | ✔ |
| CinderQos.create_and_list_qos | 0 | ✔ |
| CinderQos.create_and_set_qos | 0 | ✔ |
| CinderVolumes.create_and_delete_snapshot | 0 | ✔ |
| CinderVolumes.create_and_delete_volume | 0 | ✔ |
| CinderVolumes.create_and_delete_volume-2 | 0 | ✔ |
| CinderVolumes.create_and_delete_volume-3 | 0 | ✔ |
| CinderVolumes.create_and_extend_volume | 0 | ✔ |
| CinderVolumes.create_from_volume_and_delete_volume | 0 | ✔ |
| CinderVolumeTypes.create_and_list_volume_types | 0 | ✔ |
| CinderVolumeTypes.create_volume_type_and_encryption_type | 0 | ✔ |
| GlanceImages.create_and_delete_image | 0 | ✔ |
| GlanceImages.create_and_list_image | 0 | ✔ |
| GlanceImages.create_image_and_boot_instances | 0 | ✔ |
| GlanceImages.list_images | 0 | ✔ |
| HeatStacks.create_check_delete_stack | 0 | ✔ |
| HeatStacks.create_suspend_resume_delete_stack | 0 | ✔ |
| HeatStacks.create_update_delete_stack | 0 | ✔ |
| HeatStacks.list_stacks_and_resources | 0 | ✔ |
| KeystoneBasic.add_and_remove_user_role | 0 | ✔ |
| KeystoneBasic.create_add_and_list_user_roles | 0 | ✔ |
| KeystoneBasic.create_and_delete_role | 0 | ✔ |
| KeystoneBasic.create_and_delete_service | 0 | ✔ |
| KeystoneBasic.create_and_list_tenants | 0 | ✔ |
| KeystoneBasic.create_and_list_users | 0 | ✔ |
| KeystoneBasic.create_tenant | 0 | ✔ |
| KeystoneBasic.create_tenant_with_users | 0 | ✔ |
| KeystoneBasic.create_update_and_delete_tenant | 0 | ✔ |
| KeystoneBasic.create_user | 0 | ✔ |
| KeystoneBasic.get_entities | 0 | ✔ |
| NeutronNetworks.create_and_delete_networks | 0 | ✔ |
| NeutronNetworks.create_and_delete_ports | 0 | ✔ |
| NeutronNetworks.create_and_delete_routers | 0 | ✔ |
| NeutronNetworks.create_and_delete_subnets | 0 | ✔ |
| NeutronNetworks.create_and_list_networks | 0 | ✔ |
| NeutronNetworks.create_and_list_ports | 0 | ✔ |
| NeutronNetworks.create_and_list_routers | 0 | ✔ |
| NeutronNetworks.create_and_list_subnets | 0 | ✔ |
| NeutronNetworks.set_and_clear_router_gateway | 0 | ✔ |
| NeutronSecurityGroup.create_and_delete_security_group_rule | 0 | ✔ |
| NeutronSecurityGroup.create_and_delete_security_groups | 0 | ✔ |
| NovaKeypair.boot_and_delete_server_with_keypair | 0 | ✔ |
| NovaServerGroups.create_and_delete_server_group | 0 | ✔ |
| NovaServers.boot_server_and_list_interfaces | 0 | ✔ |
| NovaServers.boot_server_associate_and_dissociate_floating_ip | 0 | ✔ |
| NovaServers.boot_server_from_volume_and_delete | 0 | ✔ |
| NovaServers.pause_and_unpause_server | 0 | ✔ |
| Quotas.cinder_update | 0 | ✔ |
| Quotas.cinder_update_and_delete | 0 | ✔ |
| Quotas.neutron_update | 0 | ✔ |
| Quotas.nova_update | 0 | ✔ |
References
- Network Functions Virtualisation (NFV). Available online: https://www.etsi.org/technologies/689-network-functions-virtualisation (accessed on 17 September 2022).
- Hwang, J.; Ramakrishnan, K.K.; Wood, T. NetVM: High performance and flexible networking using virtualization on commodity platforms. IEEE Trans. Netw. Serv. Manag. 2015, 12, 34–47. [Google Scholar] [CrossRef]
- Ferrari, C.; Kovács, B.; Tóth, M.; Horváth, Z.; Reale, A. Edge computing for communication service providers: A review on the architecture, ownership and governing models. In Proceedings of the 2021 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Hvar, Croatia, 23–25 September 2021; pp. 1–6. [Google Scholar]
- Google Cloud, Nokia Partner to Accelerate Cloud-Native 5G Readiness for Communication Service Providers. Available online: https://www.nokia.com/about-us/news/releases/2021/01/14/google-cloud-nokia-partner-to-accelerate-cloud-native-5g-readiness-for-communication-service-providers/ (accessed on 17 September 2022).
- ETSI GS NFV; Network Functions Virtualisation (NFV): Architectural Framework. European Telecommunications Standards Institute: Sophia-Antipolis, France. Available online: https://www.etsi.org/deliver/etsi_gs/nfv/001_099/002/01.01.01_60/gs_nfv002v010101p.pdf (accessed on 10 October 2022).
- Bourguiba, M.; Haddadou, K.; Korbi, I.E.; Pujolle, G. Improving network I/O virtualization for cloud computing. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 673–681. [Google Scholar] [CrossRef]
- Aziza, H.; Krichen, S. A hybrid genetic algorithm for scientific workflow scheduling in cloud environment. Neural Comput. Appl. 2020, 32, 15263–15278. [Google Scholar] [CrossRef]
- Mohammadzadeh, A.; Masdari, M.; Gharehchopogh, F.S.; Jafarian, A. Improved chaotic binary grey wolf optimization algorithm for workflow scheduling in green cloud computing. Evol. Intell. 2021, 14, 1997–2025. [Google Scholar] [CrossRef]
- Mohammadzadeh, A.; Masdari, M.; Gharehchopogh, F.S.; Jafarian, A. A hybrid multi-objective metaheuristic optimization algorithm for scientific workflow scheduling. Clust. Comput. 2021, 24, 1479–1503. [Google Scholar] [CrossRef]
- Tolia, N.; Wang, Z.; Marwah, M.; Bash, C.; Ranganathan, P.; Zhu, X. Delivering energy proportionality with non energy-proportional systems-optimizing the ensemble. In Proceedings of the 2008 Conference on Power Aware Computing and Systems, San Diego, CA, USA, 7 December 2008; p. 2. [Google Scholar]
- Fu, X.; Zhou, C. Virtual machine selection and placement for dynamic consolidation in cloud computing environment. Front. Comput. Sci. 2015, 9, 322–330. [Google Scholar] [CrossRef]
- Gharehpasha, S.; Masdari, M.; Jafarian, A. Power efficient virtual machine placement in cloud data centers with a discrete and chaotic hybrid optimization algorithm. Clust. Comput. 2021, 24, 1293–1315. [Google Scholar] [CrossRef]
- Gharehpasha, S.; Masdari, M.; Jafarian, A. Virtual machine placement in cloud data centers using a hybrid multi-verse optimization algorithm. Artif. Intell. Rev. 2021, 54, 2221–2257. [Google Scholar] [CrossRef]
- Gharehpasha, S.; Masdari, M.; Jafarian, A. The placement of virtual machines under optimal conditions in cloud datacenter. Inf. Technol. Control. 2019, 48, 545–556. [Google Scholar] [CrossRef]
- Carpio, F.; Dhahri, S.; Jukan, A. VNF placement with replication for load balancing in NFV networks. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar]
- You, C.; Li, L.M. Efficient load balancing for the VNF deployment with placement constraints. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Wang, T.; Xu, H.; Liu, F. Multi-resource load balancing for virtual network functions. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 1322–1332. [Google Scholar]
- Ghorab, A.H.; Kusedghi, A.; Nourian, M.A.; Akbari, A. Joint VNF load balancing and service auto-scaling in NFV with multimedia case study. In Proceedings of the 2020 25th International Computer Conference, Computer Society of Iran (CSICC), Tehran, Iran, 1–2 January 2020; pp. 1–7. [Google Scholar]
- Zamani, A.; Bakhshi, B.; Sharifian, S. An efficient load balancing approach for service function chain mapping. Comput. Electr. Eng. 2021, 90, 106890. [Google Scholar] [CrossRef]
- OpenStack Enhanced Platform Awareness. Available online: https://networkbuilders.intel.com/docs/ice-house-openstack-enhanced-platform-awareness.pdf (accessed on 17 September 2022).
- Tsai, M.H.; Liang, H.T.; Wang, Y.H.; Chung, W.C. Enhanced OpenStack cloud for network function virtualization. In Proceedings of the 2020 International Computer Symposium (ICS), Tainan, Taiwan, 17–19 December 2020; pp. 185–190. [Google Scholar]
- Kourtis, M.A.; Xilouris, G.; Riccobene, V.; McGrath, M.J.; Petralia, G.; Koumaras, H.; Gardikis, G.; Liberal, F. Enhancing VNF performance by exploiting SR-IOV and DPDK packet processing acceleration. In Proceedings of the 2015 IEEE Conference on Network Function Virtualization and Software Defined Network (NFV-SDN), San Francisco, CA, USA, 18–21 November 2015; pp. 74–78. [Google Scholar]
- Bonafiglia, R.; Cerrato, I.; Ciaccia, F.; Nemirovsky, M.; Risso, F. Assessing the performance of virtualization technologies for NFV: A preliminary benchmarking. In Proceedings of the 2015 Fourth European Workshop on Software Defined Networks, Bilbao, Spain, 30 September–2 October 2015; pp. 67–72. [Google Scholar]
- Gallenmuller, S.; Emmerich, P.; Wohlfart, F.; Raumer, D.; Carle, G. Comparison of frameworks for high-performance packet IO. In Proceedings of the 2015 ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), Oakland, CA, USA, 7–8 May 2015; pp. 29–38. [Google Scholar]
- Kawashima, R.; Nakayama, H.; Hayashi, T.; Matsuo, H. Evaluation of forwarding efficiency in NFV-nodes toward predictable service chain performance. IEEE Trans. Netw. Serv. Manag. 2017, 14, 920–933. [Google Scholar] [CrossRef]
- Halpern, J.; Pignataro, C. (Eds.) Service Function Chaining (SFC) Architecture. RFC 7665. Available online: https://www.rfc-editor.org/info/rfc7665 (accessed on 17 September 2022).
- ETSI GS NFV-TST 001. Network Functions Virtualisation (NFV); Pre-Deployment Testing. Report on Validation of NFV Environments and Services. Available online: https://www.etsi.org/deliver/etsi_gs/NFV-TST/001_099/001/01.01.01_60/gs_nfv-tst001v010101p.pdf (accessed on 10 October 2022).
- Huang, Y.X.; Chou, J. Evaluations of network performance enhancement on cloud-native network function. In Proceedings of the 30th International Symposium on High-Performance Parallel and Distributed Computing, Virtual Event, 21 June 2021; pp. 3–8. [Google Scholar]
- Processor Affinity or CPU Pinning. Available online: https://www.intel.com/content/www/us/en/docs/programmable/683013/current/processor-affinity-or-cpu-pinning.html (accessed on 17 September 2022).
- Wang, X.L.; Luo, T.W.; Hu, J.Y.; Wang, Z.L.; Luo, Y.W. Evaluating the impacts of hugepage on virtual machines. Sci. China Inf. Sci. 2017, 60, 012103. [Google Scholar] [CrossRef][Green Version]
- Paolino, M.; Nikolaev, N.; Fanguede, J.; Raho, D. SnabbSwitch user space virtual switch benchmark and performance optimization for NFV. In Proceedings of the 2015 IEEE Conference on Network Function Virtualization and Software Defined Network (NFV-SDN), San Francisco, CA, USA, 18–21 November 2015; pp. 86–92. [Google Scholar]
- Linux Drivers. Available online: https://doc.dpdk.org/guides/linux_gsg/linux_drivers.html (accessed on 17 September 2022).
- Poll Mode Driver. Available online: https://doc.dpdk.org/guides/prog_guide/poll_mode_drv.html (accessed on 17 September 2022).
- Yao, J.; Zimmer, V.J.; Zeng, S. A Tour beyond BIOS: Using IOMMU for DMA Protection in UEFI Firmware. Available online: https://www.intel.com/content/dam/develop/external/us/en/documents/intel-whitepaper-using-iommu-for-dma-protection-in-uefi-820238.pdf (accessed on 17 September 2022).
- Usha Devi, G.; Peduru, K.T.; Mallikarjuna Reddy, B. A novel approach to gain high throughput and low latency through SR-IOV. Int. J. Eng. Technol. 2013, 5, 1245–1251. [Google Scholar]
- Rojas-Cessa, R.; Salehin, K.M.; Egoh, K. Evaluation of switching performance of a virtual software router. In Proceedings of the 2012 35th IEEE Sarnoff Symposium, Newark, NJ, USA, 21–22 May 2012; pp. 1–5. [Google Scholar]
- Rizzo, L. Netmap: A novel framework for fast packet I/O. In Proceedings of the 21st USENIX Security Symposium, Bellevue, WA, USA, 8–10 August 2012; pp. 101–112. [Google Scholar]
- Shanmugalingam, S.; Ksentini, A.; Bertin, P. DPDK Open vSwitch performance validation with mirroring feature. In Proceedings of the 2016 23rd International Conference on Telecommunications (ICT), Thessaloniki, Greece, 16–18 May 2016; pp. 1–6. [Google Scholar]
- Xu, C.; Wang, H.; Shea, R.; Wang, F.; Liu, J. On multiple virtual NICs in cloud computing: Performance bottleneck and enhancement. IEEE Syst. J. 2018, 12, 2417–2427. [Google Scholar] [CrossRef]
- Pitaev, N.; Falkner, M.; Leivadeas, A.; Lambadaris, I. Characterizing the performance of concurrent virtualized network functions with OVS-DPDK, FD.IO VPP and SR-IOV. In Proceedings of the ACM/SPEC International Conference on Performance Engineering, Berlin, Germany, 9–13 April 2018; pp. 285–292. [Google Scholar]
- Ara, G.; Cucinotta, T.; Abeni, L.; Vitucci, C. Comparative evaluation of kernel bypass mechanisms for high-performance inter-container communications. In Proceedings of the 10th International Conference on Cloud Computing and Services Science (CLOSER), Prague, Czech Republic, 7–9 May 2020; pp. 44–55. [Google Scholar]
- Wang, G.; Ng, T.S.E. The impact of virtualization on network performance of amazon ec2 data center. In Proceedings of the 2010 Proceedings IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010; pp. 1–9. [Google Scholar]
- Callegati, F.; Cerroni, W.; Contoli, C. Virtual networking performance in OpenStack platform for network function virtualization. J. Electr. Comput. Eng. 2016, 2016, 15. [Google Scholar] [CrossRef][Green Version]
- OPNFV Functest. Available online: https://functest.readthedocs.io/en/latest/testing/user/configguide/configguide.html#functest-dockers-for-openstack-deployment (accessed on 17 September 2022).
- NFVbench: A Network Performance Benchmarking Tool for NFVi Full Stacks. Available online: https://docs.opnfv.org/projects/nfvbench/en/latest/testing/user/userguide/readme.html (accessed on 17 September 2022).
- Prerequisites for Installing a Cloudify Manager. Available online: https://docs.cloudify.co/4.4.0/install_maintain/installation/prerequisites/ (accessed on 17 September 2022).
- Sengupta, S.; Yadav, V.K.; Saraf, Y.; Gupta, H.; Ganguly, N.; Chakraborty, S.; De, P. MoViDiff: Enabling Service Differentiation for Mobile Video Apps. In Proceedings of the 2017 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Lisbon, Portugal, 8–12 May 2017; pp. 537–543. [Google Scholar]




















| Works | Hugepage | CPU Pinning | OVS | OVS-DPDK | SR-IOV | In Cloud |
|---|---|---|---|---|---|---|
| Tsai et al. [21] | v | v | v | |||
| Kourtis et al. [22] | v | |||||
| Gallenmuller et al. [24] | v | |||||
| Kawashima et al. [25] | v | v | v | |||
| Huang et al. [28] | v | v | ||||
| Paolino et al. [31] | v | v | v | v | ||
| Shanmugalingam et al. [38] | v | v | ||||
| Pitaev et al. [40] | v | v | ||||
| Ara et al. [41] | v | v | ||||
| Callegati et al. [43] | v | v | ||||
| Ours | v | v | v | v | v | v |
| Test Host | Control Host | Compute Host | |
|---|---|---|---|
| CPU | Intel i7-3770 | Xeon(R) Silver 4210 × 2 | Xeon(R) Silver 4210 × 2 |
| Cores | 4 | 10 × 2 | 10 × 2 |
| Memory | 4 G × 4 | 16 G × 10 | 16 G × 10 |
| Host OS | Ubuntu 18.04 Server | Ubuntu 18.04 Server | Ubuntu 18.04 Server |
| Physical NIC | XXV710 | XXV710 | XXV710 |
| Network Technique | Generic OVS/OVS-DPDK/SR-IOV |
|---|---|
| Scenario | PVP/PVVP |
| Packet Size | 64/128/256/512/1024/1280/1518 |
| vCPU (DPDK) | 2/4 |
| lcore + pmd-cpu (DPDK) | 2 + 2/4 + 4 |
| Enhancement Tech | Generic OVS/OVS-DPDK |
|---|---|
| vCPU | 1/2 |
| Call Rate | 80/100/120/140 |
| lcore + pmd-cpu (DPDK) | 4 + 4 |
| Test Suite | Pass/Total | Result of Test Cases |
|---|---|---|
| Healthcheck | 9/9 | Appendix A |
| Rally_Sanity | 56/56 | Appendix B |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chung, W.-C.; Wang, Y.-H. The Effects of High-Performance Cloud System for Network Function Virtualization. Appl. Sci. 2022, 12, 10315. https://doi.org/10.3390/app122010315
Chung W-C, Wang Y-H. The Effects of High-Performance Cloud System for Network Function Virtualization. Applied Sciences. 2022; 12(20):10315. https://doi.org/10.3390/app122010315
Chicago/Turabian StyleChung, Wu-Chun, and Yun-He Wang. 2022. "The Effects of High-Performance Cloud System for Network Function Virtualization" Applied Sciences 12, no. 20: 10315. https://doi.org/10.3390/app122010315
APA StyleChung, W.-C., & Wang, Y.-H. (2022). The Effects of High-Performance Cloud System for Network Function Virtualization. Applied Sciences, 12(20), 10315. https://doi.org/10.3390/app122010315