
Weakly Supervised Learning with Positive and Unlabeled Data for Automatic Brain Tumor Segmentation

 , , , , and
, , , , and
Abstract
:Featured Application
Abstract

1. Introduction
- A random-forest based PU-learning algorithm for medical image data segmentation;
- A class-prior estimation algorithm with integrated domain-shift correction;
- A image-wise batch-mode for PU-learning;
- A study-based assessment of different tumor volume estimation approaches.
2. Methods
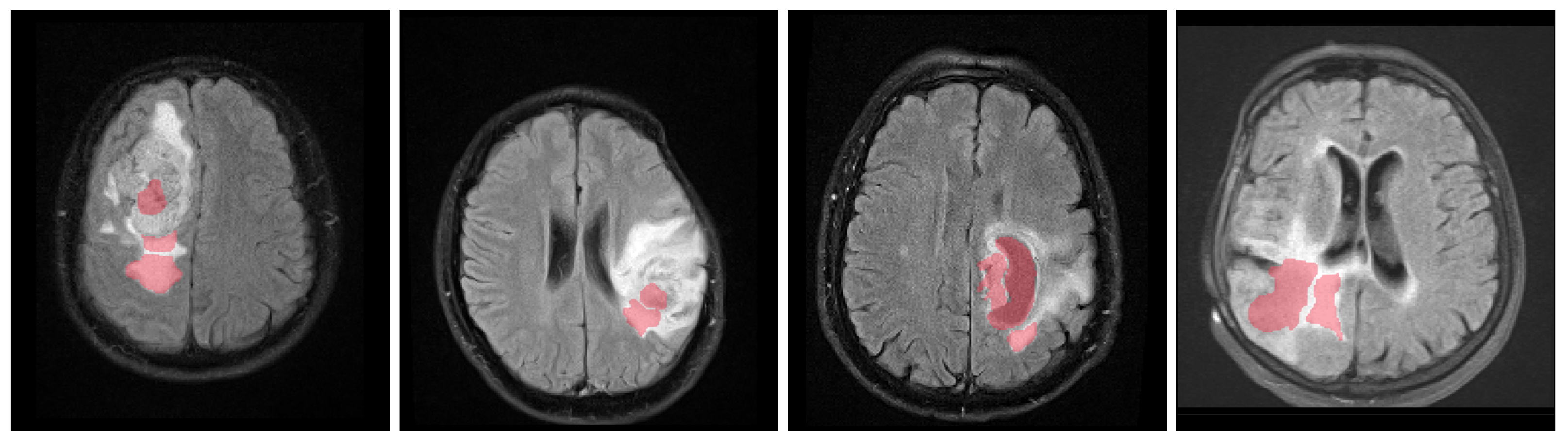
2.1. Labeling and Preprocessing
2.2. Learning from Positive Samples
2.3. Estimating Missing Class Priors
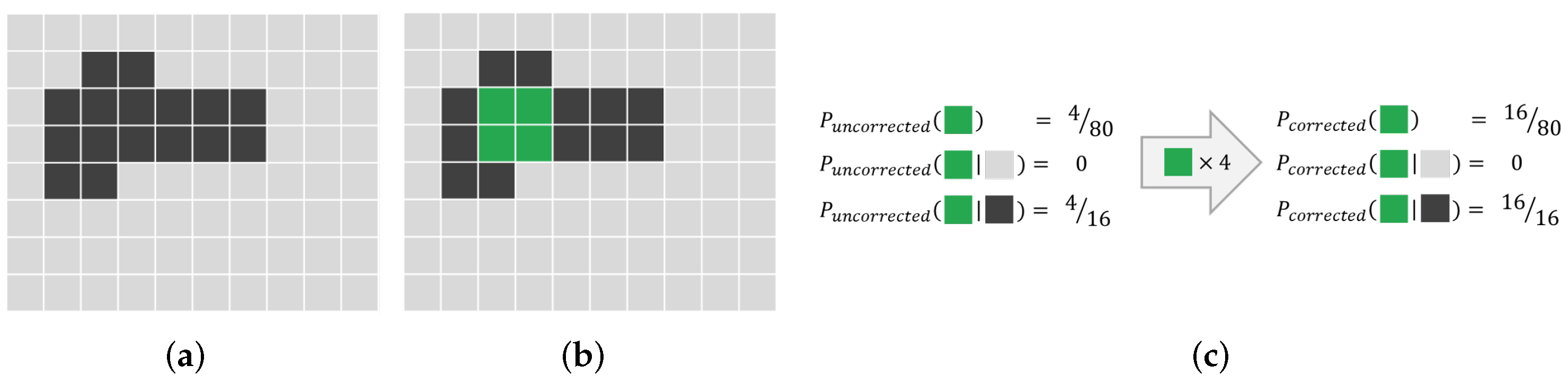
2.4. Correction for Non-i.i.d Data
2.5. Benchmark Methods
3. Experiments and Results
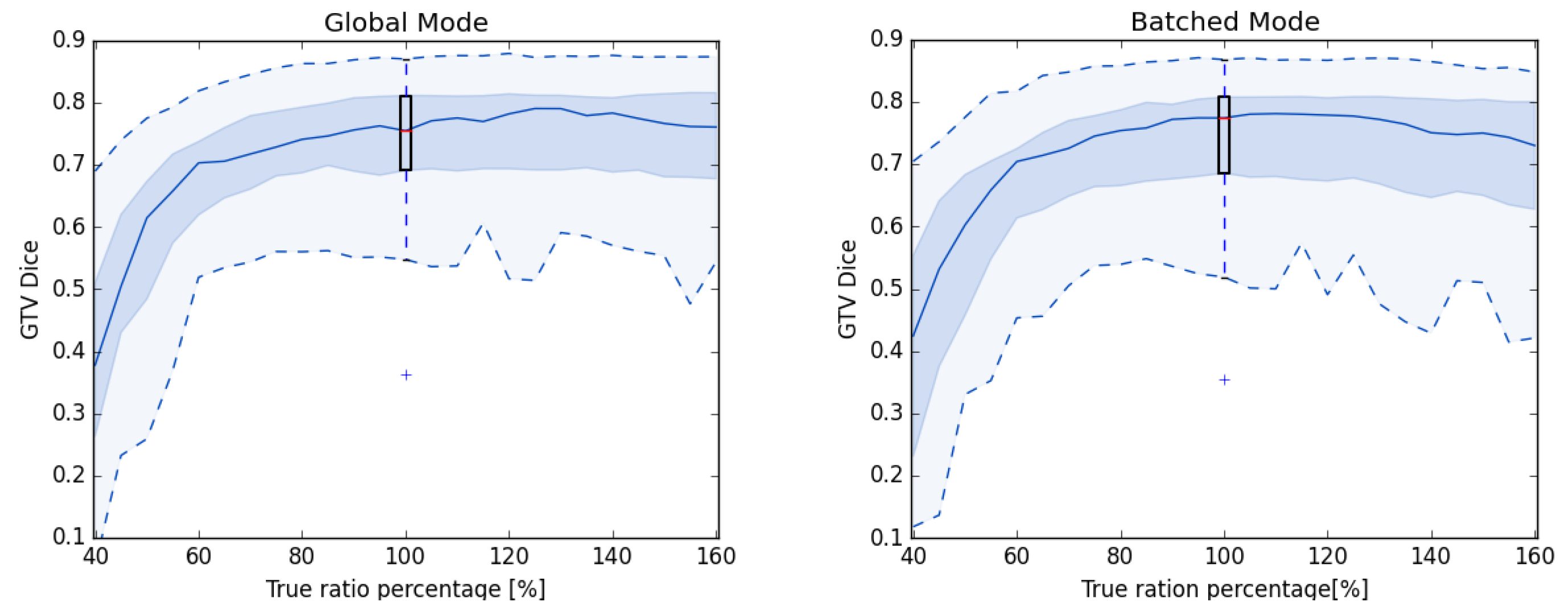
3.1. Estimation of
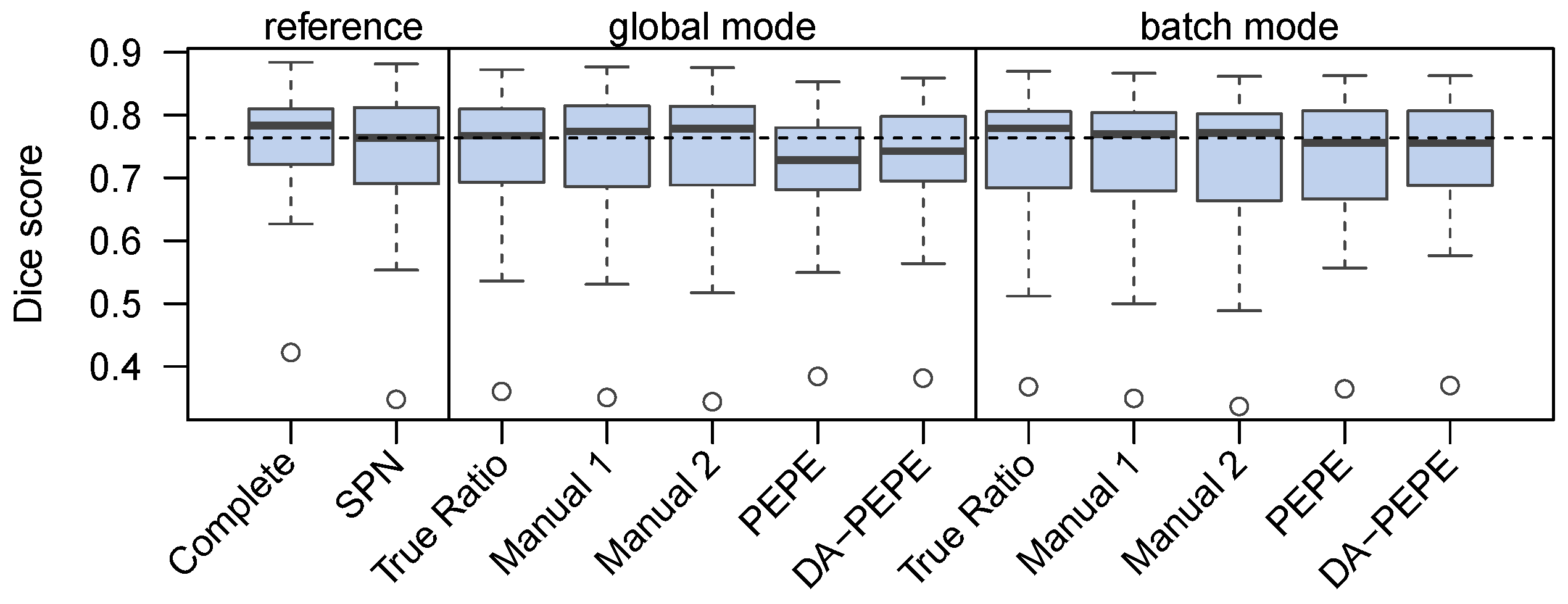
3.2. Segmentation Results
3.3. Validation on the Second Dataset
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ROI | Region of interest; |
| MRI | Magnetic resonance imaging |
| PU-learning | Learning from positive and unlabeled data; |
| DALSA | Domain adaptation for learning from sparse annotations; |
| GTV | Gross tumor bolume; |
| PE | Pearson divergence; |
| PEPE | Pearson divergence prior estimation; |
| DA-PEPE | Domain-adapted Pearson divergence prior estimation; |
| i.i.d | Independently and identically distributed; |
| DTI | Diffusion tensor imaging; |
| CSF | Cerebrospinal fluid; |
| SPN | Learning from sparse positive and negative samples. |
References
- Perthen, J.E.; Ali, T.; McCulloch, D.; Navidi, M.; Phillips, A.W.; Sinclair, R.C.F.; Griffin, S.M.; Greystoke, A.; Petrides, G. Intra- and interobserver variability in skeletal muscle measurements using computed tomography images. Eur. J. Radiol. 2018, 109, 142–146. [Google Scholar] [CrossRef] [PubMed]
- Kocak, B.; Durmaz, E.S.; Kaya, O.K.; Ates, E.; Kilickesmez, O. Reliability of Single-Slice–Based 2D CT Texture Analysis of Renal Masses: Influence of Intra- and Interobserver Manual Segmentation Variability on Radiomic Feature Reproducibility. Am. J. Roentgenol. 2019, 213, 377–383. [Google Scholar] [CrossRef] [PubMed]
- Götz, M.; Nolden, M.; Maier-Hein, K. MITK Phenotyping: An open-source toolchain for image-based personalized medicine with radiomics. Radiother. Oncol. 2019, 131, 108–111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bendfeldt, K.; Hofstetter, L.; Kuster, P.; Traud, S.; Mueller-Lenke, N.; Naegelin, Y.; Kappos, L.; Gass, A.; Nichols, T.E.; Barkhof, F.; et al. Longitudinal gray matter changes in multiple sclerosis—Differential scanner and overall disease-related effects. Hum. Brain Mapp. 2012, 33, 1225–1245. [Google Scholar] [CrossRef]
- Hammarstedt, L.; Thil er-Klang, A.; Muth, A.; Wängberg, B.; Odén, A.; Hellström, M. Adrenal lesions: Variability in attenuation over time, between scanners, and between observers. Acta Radiol. 2013, 54, 817–826. [Google Scholar] [CrossRef]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.A.; Petersen, J.; Maier-Hein, K.H. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 2021, 18, 203–211. [Google Scholar] [CrossRef]
- Deike-Hofmann, K.; Dancs, D.; Paech, D.; Schlemmer, H.P.; Maier-Hein, K.; Bäumer, P.; Radbruch, A.; Götz, M. Pre-examinations Improve Automated Metastases Detection on Cranial MRI. Investig. Radiol. 2021, 56, 320–327. [Google Scholar] [CrossRef]
- Hatamizadeh, A.; Tang, Y.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B.; Roth, H.R.; Xu, D. UNETR: Transformers for 3D Medical Image Segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 574–584. [Google Scholar] [CrossRef]
- Roth, H.R.; Yang, D.; Xu, Z.; Wang, X.; Xu, D. Going to Extremes: Weakly Supervised Medical Image Segmentation. Mach. Learn. Knowl. Extr. 2021, 3, 26. [Google Scholar] [CrossRef]
- Chan, L.; Hosseini, M.S.; Plataniotis, K.N. A Comprehensive Analysis of Weakly-Supervised Semantic Segmentation in Different Image Domains. Int. J. Comput. Vis. 2021, 129, 361–384. [Google Scholar] [CrossRef]
- Goetz, M.; Weber, C.; Stieltjes, B.; Maier-Hein, K. Learning from Small Amounts of Labeled Data in a Brain Tumor Classification Task. In Proceedings of the NIPS Workshop on Transfer and Multi-task learning: Theory Meets Practice, Montreal, QC, Canada, 13 December 2014. [Google Scholar]
- Goetz, M.; Weber, C.; Binczyk, F.; Polanska, J.; Tarnawski, R.; Bobek-Billewicz, B.; Koethe, U.; Kleesiek, J.; Stieltjes, B.; Maier-Hein, K.H. DALSA: Domain Adaptation for Supervised Learning From Sparsely Annotated MR Images. IEEE Trans. Med. Imaging 2016, 35, 184–196. [Google Scholar] [CrossRef]
- Li, L.; Wei, M.; Liu, B.; Atchaneeyasakul, K.; Zhou, F.; Pan, Z.; Kumar, S.A.; Zhang, J.Y.; Pu, Y.; Liebeskind, D.S.; et al. Deep Learning for Hemorrhagic Lesion Detection and Segmentation on Brain CT Images. IEEE J. Biomed. Health Inf. 2021, 25, 1646–1659. [Google Scholar] [CrossRef] [PubMed]
- Lejeune, L.; Sznitman, R. A positive/unlabeled approach for the segmentation of medical sequences using point-wise supervision. Med. Image Anal. 2021, 73, 102185. [Google Scholar] [CrossRef] [PubMed]
- Belkin, M.; Hsu, D.; Ma, S.; Mandal, S. Reconciling modern machine-learning practice and the classical bias–variance trade-off. Proc. Natl. Acad. Sci. USA 2019, 116, 15849–15854. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kiryati, N.; Landau, Y. Dataset Growth in Medical Image Analysis Research. J. Imaging 2021, 7, 155. [Google Scholar] [CrossRef]
- Kleesiek, J.; Biller, A.; Urban, G.; Kothe, U.; Bendszus, M.; Hamprecht, F. Ilastik for Multi-modal Brain Tumor Segmentation. In Proceedings of the MICCAI-BRATS, Boston, MA, USA, 14 September 2014. [Google Scholar]
- Thayumanavan, M.; Ramasamy, A. An efficient approach for brain tumor detection and segmentation in MR brain images using random forest classifier. Concurr. Eng. 2021, 29, 266–274. [Google Scholar] [CrossRef]
- Csaholczi, S.; Kovács, L.; Szilágyi, L. Automatic Segmentation of Brain Tumor Parts from MRI Data Using a Random Forest Classifier. In Proceedings of the 2021 IEEE 19th World Symposium on Applied Machine Intelligence and Informatics (SAMI), Herlany, Slovakia, 21–23 January 2021; pp. 471–476. [Google Scholar] [CrossRef]
- Mirmohammadi, P.; Ameri, M.; Shalbaf, A. Recognition of acute lymphoblastic leukemia and lymphocytes cell subtypes in microscopic images using random forest classifier. Phys. Eng. Sci. Med. 2021, 44, 433–441. [Google Scholar] [CrossRef]
- Hartmann, D.; Müller, D.; Soto-Rey, I.; Kramer, F. Assessing the Role of Random Forests in Medical Image Segmentation. arXiv 2021, arXiv:2103.16492. [Google Scholar]
- Li, Z.; Feng, N.; Pu, H.; Dong, Q.; Liu, Y.; Liu, Y.; Xu, X. PIxel-Level Segmentation of Bladder Tumors on MR Images Using a Random Forest Classifier. Technol. Cancer Res. Treat. 2022, 21, 15330338221086395. [Google Scholar] [CrossRef]
- Götz, M.; Heim, E.; März, K.; Norajitra, T.; Hafezi, M.; Fard, N.; Mehrabi, A.; Knoll, M.; Weber, C.; Maier-Hein, L.; et al. A learning-based, fully automatic liver tumor segmentation pipeline based on sparsely annotated training data. SPIE Med. Imaging 2016, 9784, 405–410. [Google Scholar] [CrossRef]
- Götz, M.; Skornitzke, S.; Weber, C.; Fritz, F.; Mayer, P.; Knoll, M.; Stiller, W.; Maier-Hein, K.H. Machine-Learning based Comparison of CT-Perfusion maps and Dual Energy CT for Pancreatic Tumor Detection. SPIE Med. Imaging Int. Soc. Opt. Photonics 2016, 9785, 450–455. [Google Scholar] [CrossRef]
- Criminisi, A.; Shotton, J. Decision Forests for Computer Vision and Medical Image Analysis; Springer Science & Business Media: Cham, Switzerland, 2013. [Google Scholar] [CrossRef]
- Elkan, C.; Noto, K. Learning classifiers from only positive and unlabeled data. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008. [Google Scholar]
- Elkan, C. The foundations of cost-sensitive learning. In Proceedings of the International Joint Conference on Artificial Intelligence, Seattle, WA, USA, 4–10 August 2001. [Google Scholar]
- Du Plessis, M.C.; Niu, G.; Sugiyama, M. Analysis of Learning from Positive and Unlabeled Data. Advances in Neural Information Processing Systems 27. 2014. Available online: https://proceedings.neurips.cc/paper/2014/file/35051070e572e47d2c26c241ab88307f-Paper.pdf (accessed on 4 October 2022).
- Du Plessis, M.C.; Sugiyama, M. Class Prior Estimation from Positive and Unlabeled Data. IEICE Trans. Inf. Syst. 2014, 97, 1358–1362. [Google Scholar] [CrossRef] [Green Version]
- Shimodaira, H. Improving predictive inference under covariate shift by weighting the log-likelihood function. J. Stat. Plan. Inference 2000, 97, 1358–1362. [Google Scholar] [CrossRef]
- Sugiyama, M.; Kawanabe, M. Machine Learning in Non-Stationary Environments: Introduction to Covariate Shift Adaptation; MIT Press: Cambridge, MA, USA, 2012; ISBN 9780262301220. [Google Scholar]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Trans. Med. Imaging 2015, 34, 1993–2024. [Google Scholar] [CrossRef]
- Kistler, M.; Bonaretti, S.; Pfahrer, M.; Niklaus, R.; Büchler, P. The Virtual Skeleton Database: An Open Access Repository for Biomedical Research and Collaboration. J. Med. Internet Res. 2013, 15, e245. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dice, L.R. Measures of the Amount of Ecologic Association Between Species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Prastawa, M.; Bullitt, E.; Ho, S.; Gerig, G. A brain tumor segmentation framework based on outlier detection. Med. Image Anal. 2004, 8, 275–283. [Google Scholar] [CrossRef] [PubMed]
- Pereira, S.; Pinto, A.; Alves, V.; Silva, C.A. Brain Tumor Segmentation using Convolutional Neural Networks in MRI Images. IEEE Trans. Med. Imaging 2016, 35, 1240–1251. [Google Scholar] [CrossRef] [PubMed]
- Jiménez, G.; Racoceanu, D. Deep Learning for Semantic Segmentation vs. Classification in Computational Pathology: Application to Mitosis Analysis in Breast Cancer Grading. Front. Bioeng. Biotechnol. 2019, 7, 145. [Google Scholar] [CrossRef]
- Kontschieder, P.; Fiterau, M.; Criminisi, A.; Bulo, S.R. Deep Neural Decision Forests. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1467–1475. [Google Scholar] [CrossRef]
- Hou, Y.; Fan, H.; Li, L.; Li, B. Adaptive learning cost-sensitive convolutional neural network. IET Comput. Vision 2021, 15, 346–355. [Google Scholar] [CrossRef]
- Galanis, E.; Buckner, J.C.; Maurer, M.J.; Sykora, R.; Castillo, R.; Ballman, K.V.; Erickson, B.J.; North Central Cancer Treatment Group. Validation of neuroradiologic response assessment in gliomas: Measurement by RECIST, two-dimensional, computer-assisted tumor area, and computer-assisted tumor volume methods1. Neuro-Oncol. 2006, 8, 156–165. [Google Scholar] [CrossRef]
- Jaffe, C.C. Measures of Response: RECIST, WHO, and New Alternatives. J. Clin. Oncol. 2006, 24, 3245–3251. [Google Scholar] [CrossRef] [PubMed]
- Rai, R.; Holloway, L.C.; Brink, C.; Field, M.; Christiansen, R.L.; Sun, Y.; Barton, M.B.; Liney, G.P. Multicenter evaluation of MRI-based radiomic features: A phantom study. Med. Phys. 2020, 47, 3054–3063. [Google Scholar] [CrossRef] [PubMed]
- Wennmann, M.; Bauer, F.; Klein, A.; Chmelik, J.; Grözinger, M.; Rotkopf, L.T.; Neher, P.; Gnirs, R.; Kurz, F.T.; Nonnenmacher, T.; et al. In Vivo Repeatability and Multiscanner Reproducibility of MRI Radiomics Features in Patients With Monoclonal Plasma Cell Disorders: A Prospective Bi-institutional Study. Investig. Radiol. 2022. online ahead of print. [Google Scholar] [CrossRef] [PubMed]
- Van Timmeren, J.E.; Leijenaar, R.T.; van Elmpt, W.; Wang, J.; Zhang, Z.; Dekker, A.; Lambin, P. Test–Retest Data for Radiomics Feature Stability Analysis: Generalizable or Study-Specific? Tomography 2016, 2, 361–365. [Google Scholar] [CrossRef]
- Götz, M.; Maier-Hein, K.H. Optimal Statistical Incorporation of Independent Feature Stability Information into Radiomics Studies. Sci. Rep. 2020, 10, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Orlhac, F.; Boughdad, S.; Philippe, C.; Stalla-Bourdillon, H.; Nioche, C.; Champion, L.; Soussan, M.; Frouin, F.; Frouin, V.; Buvat, I. A Postreconstruction Harmonization Method for Multicenter Radiomic Studies in PET. J. Nucl. Med. 2018, 59, 1321–1328. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zwanenburg, A.; Vallières, M.; Abdalah, M.A.; Aerts, H.J.W.L.; Andrearczyk, V.; Apte, A.; Ashrafinia, S.; Bakas, S.; Beukinga, R.J.; Boellaard, R.; et al. The Image Biomarker Standardization Initiative: Standardized Quantitative Radiomics for High-Throughput Image-based Phenotyping. Radiology 2020, 295, 328–338. [Google Scholar] [CrossRef] [PubMed]
- Larue, R.T.H.M.; Defraene, G.; De Ruysscher, D.; Lambin, P.; van Elmpt, W. Quantitative radiomics studies for tissue characterization: A review of technology and methodological procedures. Br. J. Radiol. 2017, 90, 20160665. [Google Scholar] [CrossRef]
- Wennmann, M.; Klein, A.; Bauer, F.; Chmelik, J.; Grözinger, M.; Uhlenbrock, C.; Lochner, J.; Nonnenmacher, T.; Rotkopf, L.T.; Sauer, S.; et al. Combining Deep Learning and Radiomics for Automated, Objective, Comprehensive Bone Marrow Characterization From Whole-Body MRI: A Multicentric Feasibility Study. Investig. Radiol. 2022, 57, 752–763. [Google Scholar] [CrossRef] [PubMed]
- Lisson, C.S.; Lisson, C.G.; Achilles, S.; Mezger, M.F.; Wolf, D.; Schmidt, S.A.; Thaiss, W.M.; Bloehdorn, J.; Beer, A.J.; Stilgenbauer, S.; et al. Longitudinal CT Imaging to Explore the Predictive Power of 3D Radiomic Tumour Heterogeneity in Precise Imaging of Mantle Cell Lymphoma (MCL). Cancers 2022, 14, 393. [Google Scholar] [CrossRef] [PubMed]
- Lisson, C.S.; Lisson, C.G.; Mezger, M.F.; Wolf, D.; Schmidt, S.A.; Thaiss, W.M.; Tausch, E.; Beer, A.J.; Stilgenbauer, S.; Beer, M.; et al. Deep Neural Networks and Machine Learning Radiomics Modelling for Prediction of Relapse in Mantle Cell Lymphoma. Cancers 2022, 14, 2008. [Google Scholar] [CrossRef] [PubMed]
- Maier-Hein, L.; Mersmann, S.; Kondermann, D.; Bodenstedt, S.; Sanchez, A.; Stock, C.; Kenngott, H.G.; Eisenmann, M.; Speidel, S. Can Masses of Non-Experts Train Highly Accurate Image Classifiers? In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 438–445. [Google Scholar] [CrossRef]
- Maier-Hein, L.; Ross, T.; Gröhl, J.; Glocker, B.; Bodenstedt, S.; Stock, C.; Heim, E.; Götz, M.; Wirkert, S.; Kenngott, H.; et al. Crowd-algorithm collaboration for large-scale endoscopic image annotation with confidence. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2016; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Real Ratio | Manual 1 | Manual 2 | PEPE | DA-PEPE | |
|---|---|---|---|---|---|
| Mean Tumor Volume | 10.5% | 11.1% | 11.7% | 7.6% | 8.5% |
| Mean absolute error | 0% | 16.8% | 20.1% | 51.2% | 55.6% |
| Pearson Correlation | 1 | 0.95 | 0.95 | 0.41 | 0.34 |
| Labeling Time | 4 h | 1 min | 1 min | 0 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wolf, D.; Regnery, S.; Tarnawski, R.; Bobek-Billewicz, B.; Polańska, J.; Götz, M. Weakly Supervised Learning with Positive and Unlabeled Data for Automatic Brain Tumor Segmentation. Appl. Sci. 2022, 12, 10763. https://doi.org/10.3390/app122110763
Wolf D, Regnery S, Tarnawski R, Bobek-Billewicz B, Polańska J, Götz M. Weakly Supervised Learning with Positive and Unlabeled Data for Automatic Brain Tumor Segmentation. Applied Sciences. 2022; 12(21):10763. https://doi.org/10.3390/app122110763
Chicago/Turabian StyleWolf, Daniel, Sebastian Regnery, Rafal Tarnawski, Barbara Bobek-Billewicz, Joanna Polańska, and Michael Götz. 2022. "Weakly Supervised Learning with Positive and Unlabeled Data for Automatic Brain Tumor Segmentation" Applied Sciences 12, no. 21: 10763. https://doi.org/10.3390/app122110763
APA StyleWolf, D., Regnery, S., Tarnawski, R., Bobek-Billewicz, B., Polańska, J., & Götz, M. (2022). Weakly Supervised Learning with Positive and Unlabeled Data for Automatic Brain Tumor Segmentation. Applied Sciences, 12(21), 10763. https://doi.org/10.3390/app122110763