

A Dynamic Heterogeneous Information Network Embedding Method Based on Meta-Path and Improved Rotate Model


Abstract
1. Introduction
- (1)
- A DHIN embedding method based on meta-path and improved Rotate model (MRDE) is proposed, which can perform real-time and heterogeneous information learning;
- (2)
- Each meta-path can only reflect a specific structure and semantic information, and the node may be connected to other nodes through multiple meta-paths. An attention balance mechanism is proposed to learn more comprehensive node embedding;
- (3)
- Experiments on two real datasets show that MRDE can significantly improve the representation quality and achieve a performance improvement of 0.5~41.8% in downstream clustering and node classification tasks. Compared with other mainstream algorithms, it was guaranteed by comparing the experimental results of two datasets with different characteristics, and it is proved to have good generality in different types of networks.
2. Related Works
2.1. Static HIN Embedding
2.2. DHIN Embedding
2.3. Knowledge-Graph-Based DHIN Embedding
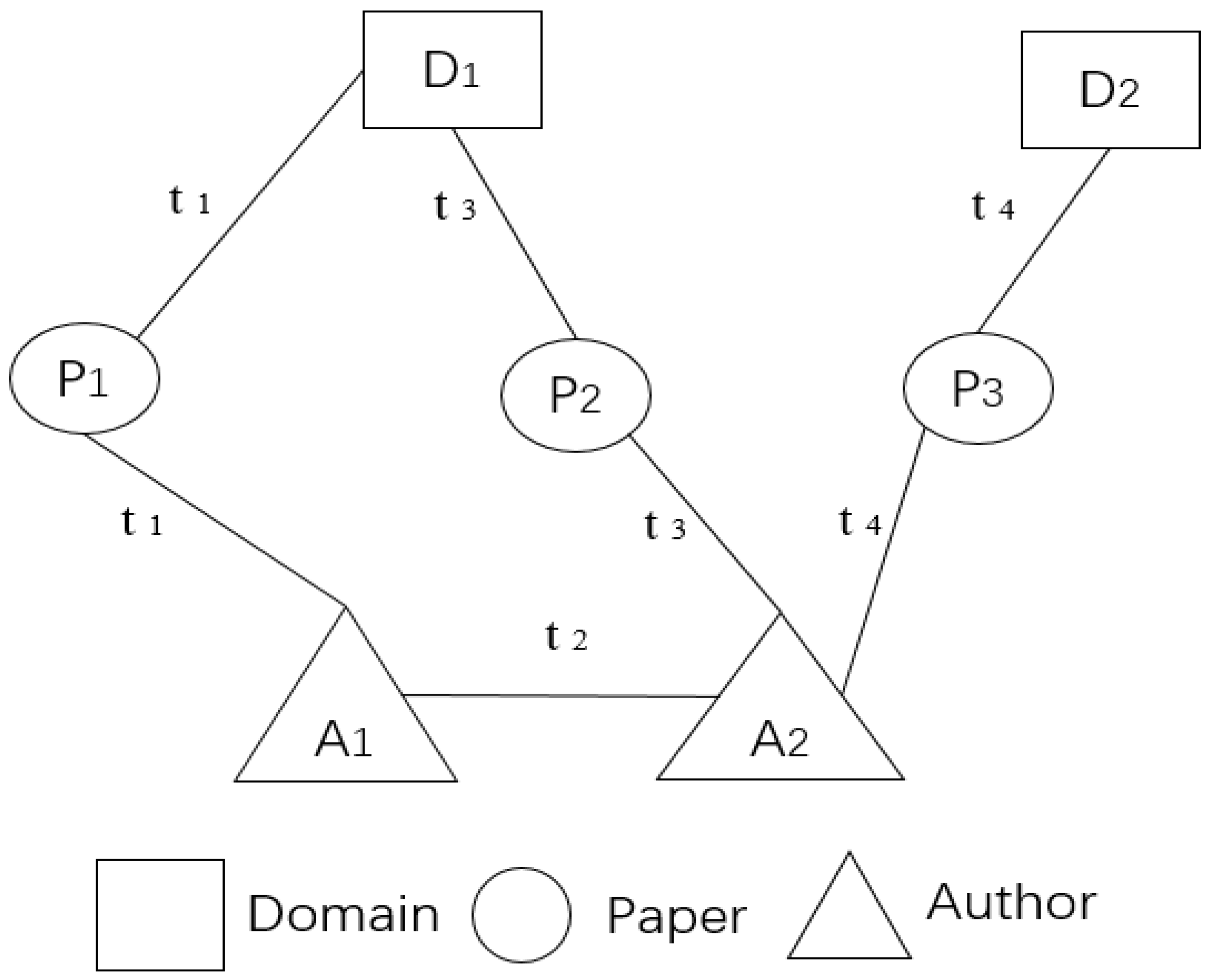
3. Notations and Problem Definition
4. Materials and Methods
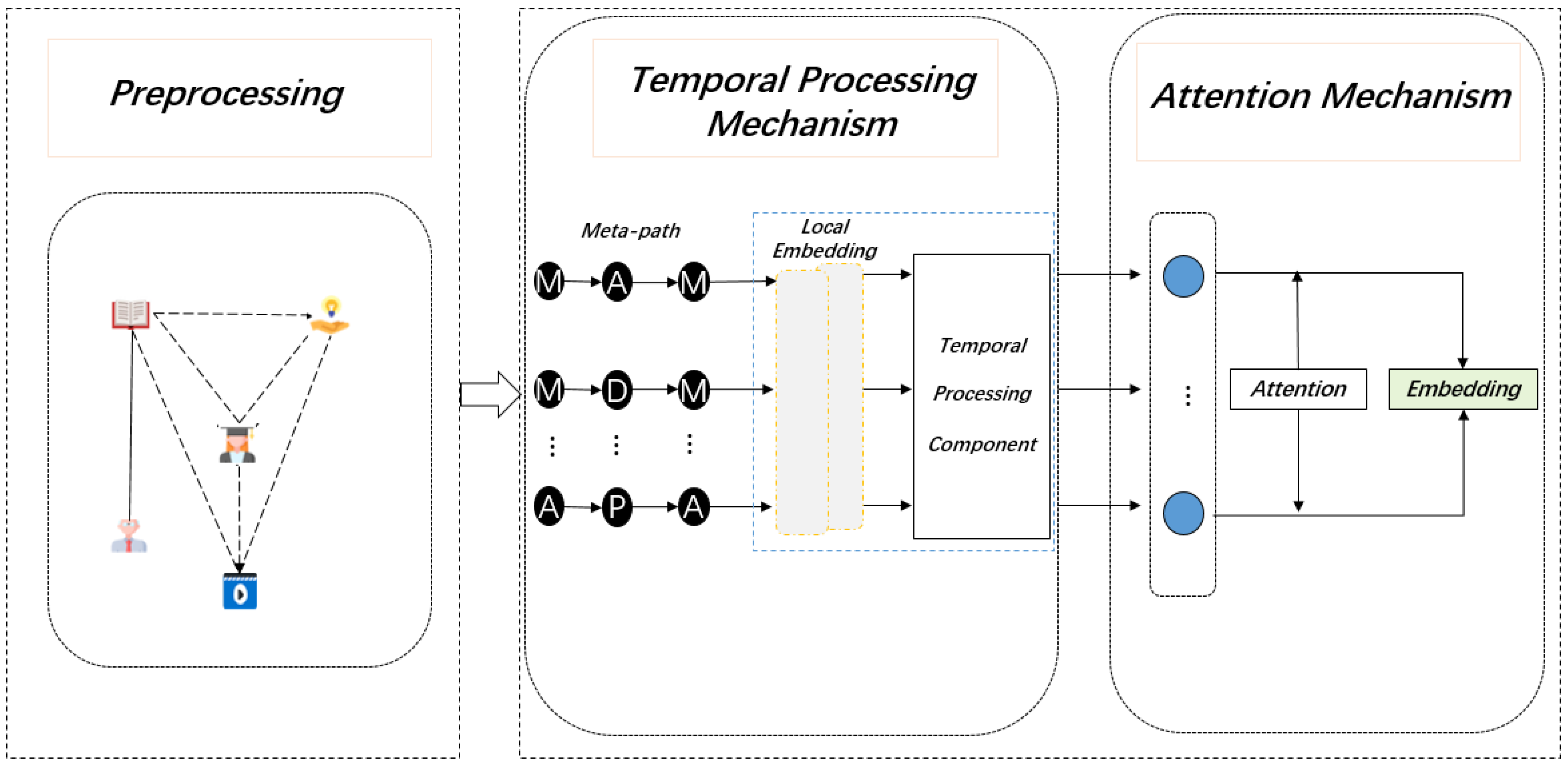
4.1. The Whole Framework
4.2. Data Preprocessing
4.3. DHIN Embedding Based on Meta-Path and Improved Rotate Model
4.3.1. Meta-Path-Based Node Local Representation
4.3.2. Temporal Processing Component Based on Time Decay Function
4.4. Meta-Path-Level Aggregation
5. Experiment and Discussion
5.1. Experimental Data
5.2. Baselines
- Raw Feature, that is, the initial input features are used for node representation;
- GCN [13], a homogeneous neural network model, introduces the neural network into the field of graph learning. Here we adapt standard experimental strategies and parameter settings and construct a meta-path-based adjacency matrix to facilitate its operation according to the requirements of homogeneous graphs;
- GAT [14], a homogeneous neural network model, uses an attention mechanism. Here we adapt standard experimental strategies and parameter settings and construct a meta-path-based adjacency matrix to facilitate its operation according to the requirements of homogeneous graphs;
- Metapath2vec (M2V) [8], a representation learning method for HINs, performs random one-walk based on meta-paths. Here we set the window size to 5, the walk length to 100, and the number of negative samples to 5;
- JUST [49], a static HIN embedding method. Here, the initial stay probability parameter of the walk is set to α = 0.2 so that the algorithm tends to explore new types of nodes through heterogeneous edges during the walk, and the remaining parameters are selected as the default settings in the original text;
- CTDNE [10] is a real-time dynamic homogeneous network embedding method in which random walks are organized with edges as angles, and the next edge is selected according to the strict increasing order of timestamps. Here the minimum length of each walk sequence is 5. The size of the batch update is consistent with the sliding window step size to ensure that the required walking sequence can be generated in the network with a limited number of timestamps and that the sequence is not too short.
- Change2vec (C2V) [50], a DHIN embedding method for snapshots, uses meta-path guidance. In order to ensure the quality of meta-path selection, the meta-paths used in each dataset are selected based on the semantics of the dataset. And considering the influence of selecting different meta-paths, multiple meta-paths are comprehensively considered for random walks in the experiment;
5.3. Experiment Result and Discussion
5.3.1. Node Classification Task
5.3.2. Node Clustering Task
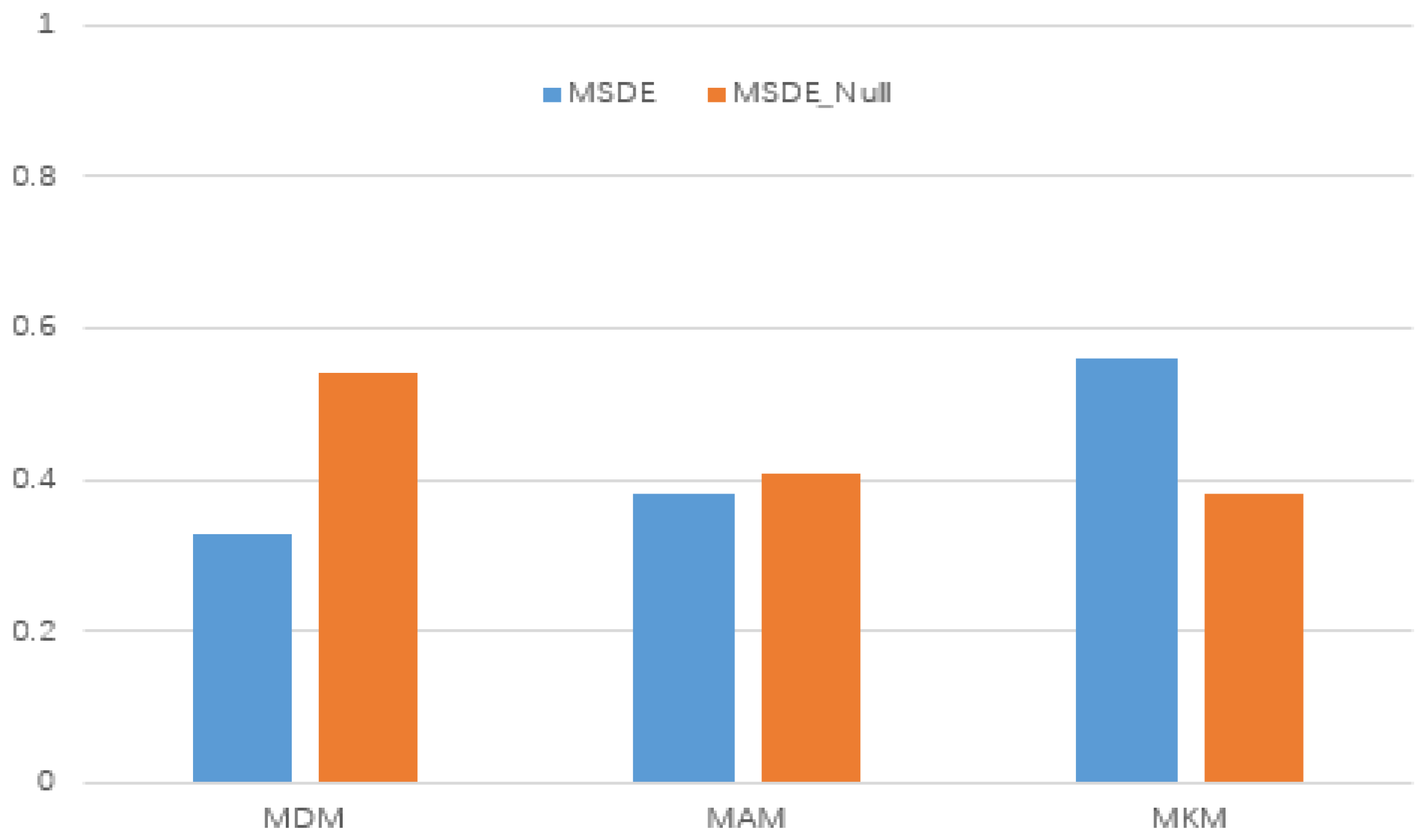
5.3.3. The Effect of Attention Balance Parameter
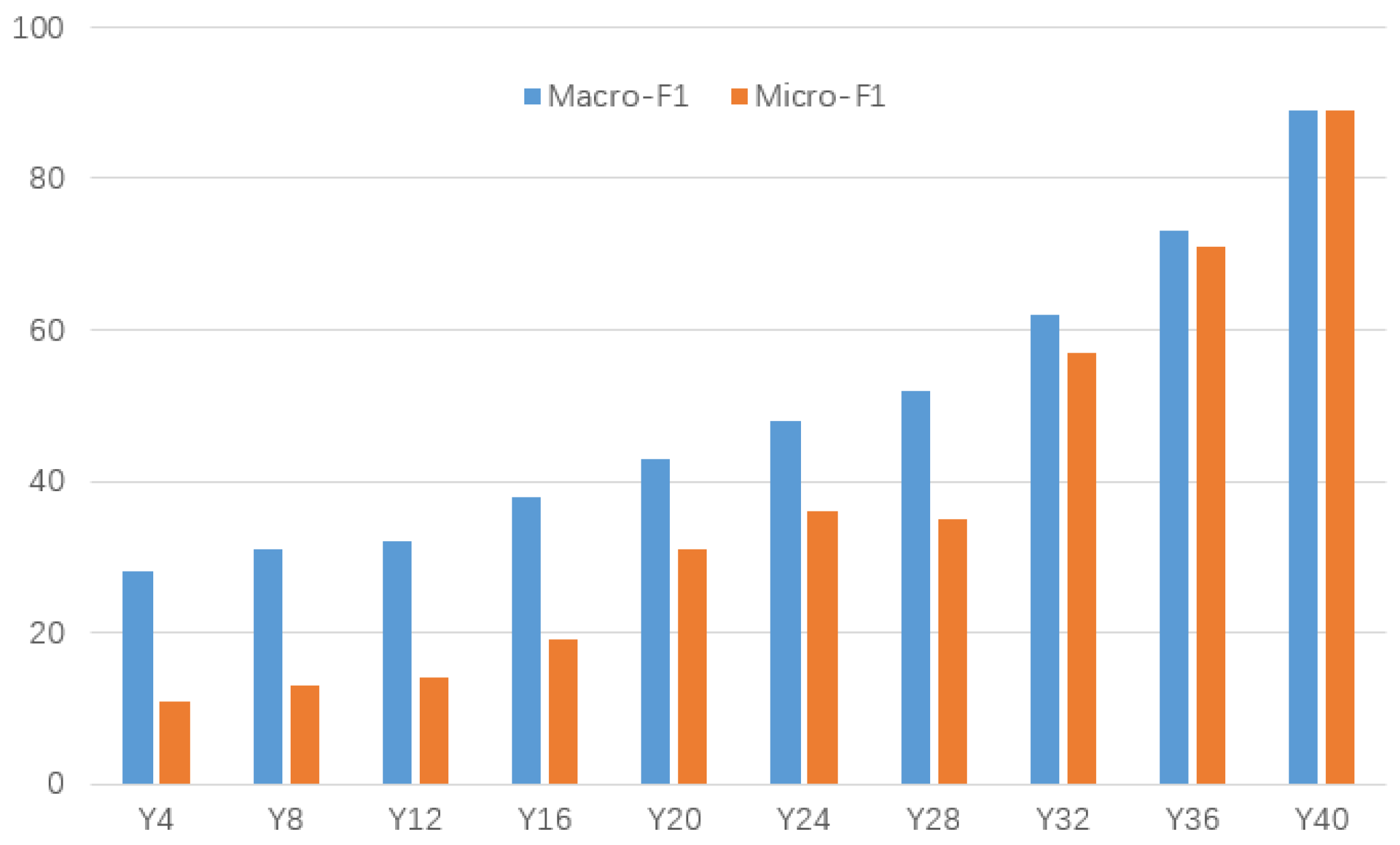
5.3.4. Impact of Time Accumulation
5.3.5. Runtime Comparison
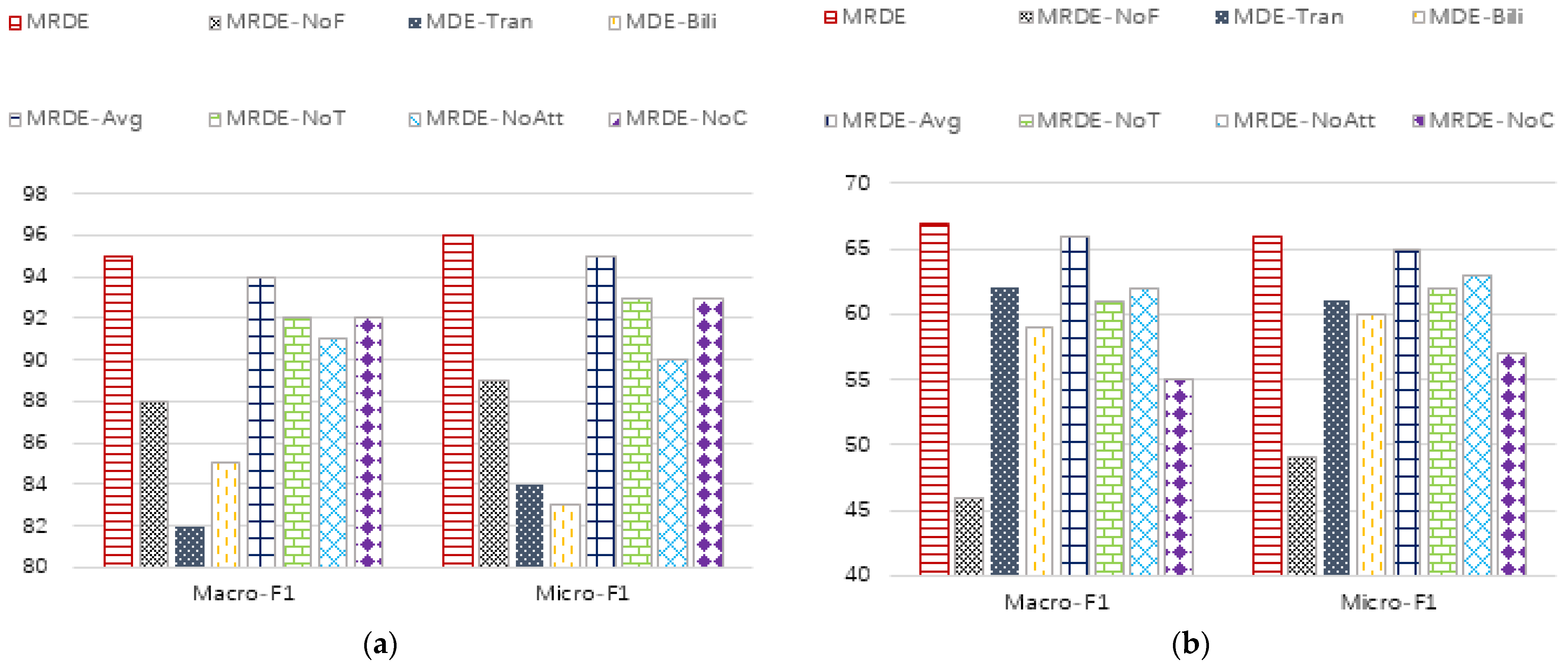
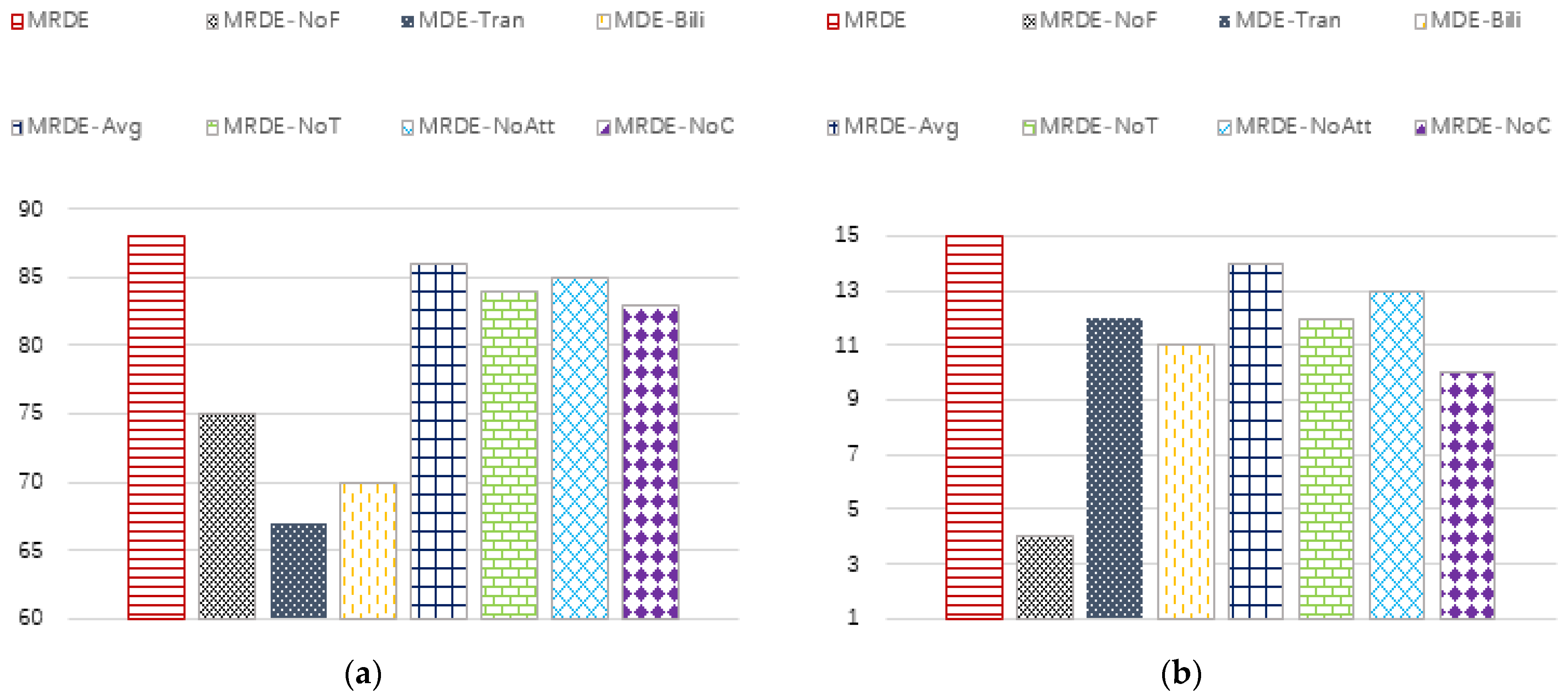
5.3.6. Each Sub Module and Its Parameter Influence
- MRDE, representing the method in this paper;
- MRDE-NoF, indicating that node features are not used;
- MDE-Bili, which means that the meta path instance is encoded with Bilinear [34];
- MDE-Tran, which means that the meta path instance is encoded with TransE [33];
- MRDE-Avg, the coding method of averaging node vectors;
- MRDE-NoT means that the time attribute in the network is not considered, and only the attention mechanism is used to fuse the meta path instances;
- MRDE-NoAtt, which means that only the time attribute in the network is considered, and no attention mechanism is used to fuse meta-path instances;
- MRDE-NoC, which means that the central node of the meta path instance is not considered, and only the node pairs connected by the meta path are used.
- The MRDE-NoF method is the worst or second worst for both classification tasks and clustering tasks, indicating that the attribute information of the node itself has a great impact on the performance of embedding. By observing (a) and (b), the degree of influence in the DBLP dataset is obviously lighter than that in the IMDB dataset. We judge that the core information in the DBLP dataset is structural information and time information, while the core information in the IMDB dataset contains both structural information, time information, and attribute information;
- The performance of the MDE-Bili and MDE-Tran methods on DBLP and IMDB datasets is quite different, which indicates that translation models and bilinear models are more dependent on the matching degree between the data’s internal patterns and models. When the matching degree is high, good results can be achieved. Otherwise, the effects may decline significantly;
- MRDE-NoT has different effects on different classification tasks and different data sets, but it is weaker than MRDE, indicating that the impact of time attribute information is unstable, but it will have a certain impact on the final embedding effect. MRDE-NoAtt, MRDE-Avg, and MRDE-NoC methods have similar characteristics;
- The MRDE model has achieved the best results in all data sets and tasks, indicating the rationality of the embedding framework we have adopted.
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cui, P.; Wang, X.; Pei, J.; Zhu, W. A survey on network embedding. IEEE Trans. Knowl. Data Eng. 2018, 31, 833–852. [Google Scholar] [CrossRef]
- Jacob, Y.; Denoyer, L.; Gallinari, P. Learning latent representations of nodes for classifying in heterogeneous social networks. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014; pp. 373–382. [Google Scholar]
- Liu, F.; Xia, S.T. Link prediction in aligned heterogeneous networks. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Cham, Switzerland, 2015; pp. 33–44. [Google Scholar]
- Luo, C.; Guan, R.; Wang, Z.; Lin, C. Hetpathmine: A novel transductive classification algorithm on heterogeneous information networks. In European Conference on Information Retrieval; Springer: Cham, Switzerland, 2014; pp. 210–221. [Google Scholar]
- Jamali, M.; Lakshmanan, L. Heteromf: Recommendation in heterogeneous information networks using context dependent factor models. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 643–654. [Google Scholar]
- Shi, C.; Li, Y.; Zhang, J.; Sun, Y.; Philip, S.Y. A survey of heterogeneous information network analysis. IEEE Trans. Knowl. Data Eng. 2016, 29, 17–37. [Google Scholar] [CrossRef]
- Yang, C.; Xiao, Y.; Zhang, Y.; Sun, Y.; Han, J. Heterogeneous network representation learning: Survey, benchmark, evaluation, and beyond. arXiv 2020, arXiv:2004.00216v1. [Google Scholar]
- Dong, Y.; Chawla, N.V.; Swami, A. Metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 135–144. [Google Scholar]
- Fu, T.Y.; Lee, W.C.; Lei, Z. Hin2vec: Explore meta-paths in heterogeneous information networks for representation learning. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1797–1806. [Google Scholar]
- Lee, J.B.; Nguyen, G.; Rossi, R.A.; Ahmed, N.K.; Koh, E.; Kim, S. Dynamic node embeddings from edge streams. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 5, 931–946. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. arXiv 2017, arXiv:1706.02216. [Google Scholar]
- Wang, D.; Cui, P.; Zhu, W. Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1225–1234. [Google Scholar]
- Goyal, P.; Ferrara, E. Graph embedding techniques, applications, and performance: A survey. Knowl. Based Syst. 2018, 151, 78–94. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Representation learning on graphs: Methods and applications. arXiv 2017, arXiv:1709.05584. [Google Scholar]
- Shi, C.; Philip, S.Y. Heterogeneous Information Network Analysis and Applications; Springer International Publishing: Cham, Switzerland, 2017. [Google Scholar]
- Zhang, C.; Swami, A.; Chawla, N.V. Shne: Representation learning for semantic-associated heterogeneous networks. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 690–698. [Google Scholar]
- Lu, Y.; Shi, C.; Hu, L.; Liu, Z. Relation structure-aware heterogeneous information network embedding. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4456–4463. [Google Scholar]
- Chen, J.; Hou, H.; Gao, J.; Ji, Y.; Bai, T. RGCN: Recurrent graph convolutional networks for target-dependent sentiment analysis. In International Conference on Knowledge Science, Engineering and Management; Springer: Cham, Switzerland, 2019; pp. 667–675. [Google Scholar]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Ye, Y.; Cui, P.; Yu, P.S. Heterogeneous graph attention network. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2022–2032. [Google Scholar]
- Zhao, Z.; Li, C.; Zhang, X.; Chiclana, F.; Viedma, E.H. An incremental method to detect communities in dynamic evolving social networks. Knowledge-Based Systems 2019, 163, 404–415. [Google Scholar]
- Zhou, L.; Yang, Y.; Ren, X.; Wu, F.; Zhuang, Y. Dynamic network embedding by modeling triadic closure process. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Du, L.; Wang, Y.; Song, G.; Lu, Z.; Wang, J. Dynamic network embedding: An extended approach for skip-gram based network embedding. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; Volume 2018, pp. 2086–2092. [Google Scholar]
- Peng, H.; Li, J.; Yan, H.; Gong, Q.; Wang, S.; Liu, L.; Wang, L.; Ren, X. Dynamic network embedding via incremental skip-gram with negative sampling. Sci. China Inf. Sci. 2020, 63, 202103. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. Node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Jiang, T.; Liu, T.; Ge, T.; Sha, L.; Li, S.; Chang, B.; Sui, Z. Encoding temporal information for time-aware link prediction. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 2350–2354. [Google Scholar]
- Li, J.; Dani, H.; Hu, X.; Tang, J.; Chang, Y.; Liu, H. Attributed network embedding for learning in a dynamic environment. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 387–396. [Google Scholar]
- Wang, X.; Lu, Y.; Shi, C.; Wang, R.; Cui, P.; Mou, S. Dynamic heterogeneous information network embedding with meta-path based proximity. IEEE Trans. Knowl. Data Eng. 2020, 34, 1117–1132. [Google Scholar] [CrossRef]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 2, pp. 2787–2795. [Google Scholar]
- Nickel, M.; Tresp, V.; Kriegel, H.P. A three-way model for collective learning on multi-relational data. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Sun, Z.; Deng, Z.H.; Nie, J.Y.; Tang, J. Rotate: Knowledge Graph embedding by relational rotation in complex space. arXiv 2019, arXiv:1902.10197. [Google Scholar]
- Trivedi, R.; Farajtabar, M.; Wang, Y.; Dai, H.; Zha, H.; Song, L. Know-evolve: Deep reasoning in temporal knowledge graphs. arXiv 2017, arXiv:1705.05742. [Google Scholar]
- Li, Z.; Jin, X.; Li, W.; Guan, S.; Guo, J.; Shen, H.; Wang, Y.; Cheng, X. Temporal knowledge graph reasoning based on evolutional representation learning. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; pp. 408–417. [Google Scholar]
- Qu, M.; Tang, J.; Han, J. Curriculum learning for heterogeneous star network embedding via deep reinforcement learning. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 468–476. [Google Scholar]
- Wan, G.; Du, B.; Pan, S.; Haffari, G. Reinforcement learning based meta-path discovery in large-scale heterogeneous information networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6094–6101. [Google Scholar]
- Jin, W.; Qu, M.; Jin, X.; Ren, X. Recurrent event network: Autoregressive structure inference over temporal knowledge graphs. arXiv 2019, arXiv:1904.05530. [Google Scholar]
- Wang, J.; Chang, V.; Yu, D.; Liu, C.; Ma, X.; Yu, D. Conformance-oriented predictive process monitoring in BPaaS based on combination of neural networks. J. Grid Comput. 2022, 20, 25. [Google Scholar] [CrossRef]
- Ni, P.; Okhrati, R.; Guan, S.; Chang, V. Knowledge graph and deep learning-based text-to-GraphQL model for intelligent medical consultation chatbot. Inf. Syst. Front. 2022. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, G. Real quadratic-form-based graph pooling for graph neural networks. Mach. Learn. Knowl. Extr. 2022, 4, 580–590. [Google Scholar] [CrossRef]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge Graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Sun, Y.; Han, J.; Yan, X.; Yu, P.S.; Wu, T. Pathsim: Meta path-based top-k similarity search in heterogeneous information networks. Proc. VLDB Endow. 2011, 4, 992–1003. [Google Scholar] [CrossRef]
- Hamilton, W.; Bajaj, P.; Zitnik, M.; Jurafsky, D.; Leskovec, J. Embedding logical queries on knowledge graphs. arXiv 2019, arXiv:1806.01445. [Google Scholar]
- Moreira, C.; Calado, P.; Martins, B. Learning to rank academic experts in the DBLP dataset. Expert Syst. 2015, 32, 477–493. [Google Scholar] [CrossRef]
- Yenter, A.; Verma, A. Deep CNN-LSTM with combined kernels from multiple branches for IMDb review sentiment analysis. In Proceedings of the 2017 IEEE 8th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference (UEMCON), New York, NY, USA, 19–21 October 2017; pp. 540–546. [Google Scholar]
- Hussein, R.; Yang, D.; Cudré-Mauroux, P. Are meta-paths necessary? Revisiting heterogeneous graph embeddings. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 437–446. [Google Scholar]
- Bian, R.; Koh, Y.S.; Dobbie, G.; Divoli, A. Network embedding and change modeling in dynamic heterogeneous networks. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 861–864. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Node | Node Number | Edge | Edge Number | Feature Dimension | Meta-Path |
|---|---|---|---|---|---|---|
| DBLP | Author (A) | 4057 | AP AC PT | 19,645 14,328 88,420 | 334 | APA APCPA APTPA |
| Paper (P) | 14,328 | |||||
| Conference (C) | 20 | |||||
| Term (T) | 8789 | |||||
| IMDB | Movie (M) | 4275 | MA MD MK | 12,838 4280 20,529 | 6344 | MAM MDM MKM |
| Actor (A) | 5431 | |||||
| Director (D) | 2082 | |||||
| Keyword (K) | 7313 |
| Dataset | Training Set | Indicator | Raw | GCN | GAT | M2V | JUST | CTDNE | C2V | MRDE |
|---|---|---|---|---|---|---|---|---|---|---|
| DBLP | 20% | Micro-F | 0.715 | 0.699 | 0.819 | 0.593 | 0.824 | 0.899 | 0.906 | 0.930 |
| Macro-F | 0.725 | 0.698 | 0.813 | 0.513 | 0.835 | 0.892 | 0.898 | 0.904 | ||
| 80% | Micro-F | 0.822 | 0.811 | 0.838 | 0.618 | 0.854 | 0.910 | 0.917 | 0.947 | |
| Macro-F | 0.825 | 0.803 | 0.839 | 0.521 | 0.868 | 0.906 | 0.910 | 0.942 | ||
| IMDB | 20% | Micro-F | 0.502 | 0.582 | 0.633 | 0.435 | 0.698 | 0.608 | 0.681 | 0.712 |
| Macro-F | 0.523 | 0.623 | 0.708 | 0.447 | 0.654 | 0.673 | 0.692 | 0.710 | ||
| 80% | Micro-F | 0.585 | 0.679 | 0.707 | 0.452 | 0.734 | 0.720 | 0.725 | 0.738 | |
| Macro-F | 0.592 | 0.687 | 0.736 | 0.487 | 0.725 | 0.739 | 0.737 | 0.745 |
| Method | DBLP | IMDB |
|---|---|---|
| ARI | ARI | |
| Raw | 0.369 | 0.355 |
| GCN | 0.625 | 0.682 |
| GAT | 0.718 | 0.733 |
| M2V | 0.785 | 0.775 |
| JUST | 0.725 | 0.737 |
| CTDNE | 0.805 | 0.827 |
| C2V | 0.798 | 0.905 |
| MRDE | 0.815 | 0.929 |
| Method | Dataset | |
|---|---|---|
| DBLP | IMDB | |
| Raw | 1032.19 | 863.56 |
| GCN | 4563.25 | 2232.41 |
| GAT | 7563.43 | 4509.28 |
| M2V | 1589.68 | 1097.65 |
| JUST | 71,920.86 | 30,122.36 |
| CTDNE | 32,858.93 | 14,118.73 |
| C2V | 256.37 | 187.15 |
| MRDE | 815.06 | 327.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bu, H.; Xia, J.; Wu, Q.; Chen, L. A Dynamic Heterogeneous Information Network Embedding Method Based on Meta-Path and Improved Rotate Model. Appl. Sci. 2022, 12, 10898. https://doi.org/10.3390/app122110898
Bu H, Xia J, Wu Q, Chen L. A Dynamic Heterogeneous Information Network Embedding Method Based on Meta-Path and Improved Rotate Model. Applied Sciences. 2022; 12(21):10898. https://doi.org/10.3390/app122110898
Chicago/Turabian StyleBu, Hualong, Jing Xia, Qilin Wu, and Liping Chen. 2022. "A Dynamic Heterogeneous Information Network Embedding Method Based on Meta-Path and Improved Rotate Model" Applied Sciences 12, no. 21: 10898. https://doi.org/10.3390/app122110898
APA StyleBu, H., Xia, J., Wu, Q., & Chen, L. (2022). A Dynamic Heterogeneous Information Network Embedding Method Based on Meta-Path and Improved Rotate Model. Applied Sciences, 12(21), 10898. https://doi.org/10.3390/app122110898