
A Multi-Scale Contextual Information Enhancement Network for Crack Segmentation
Abstract
:1. Introduction
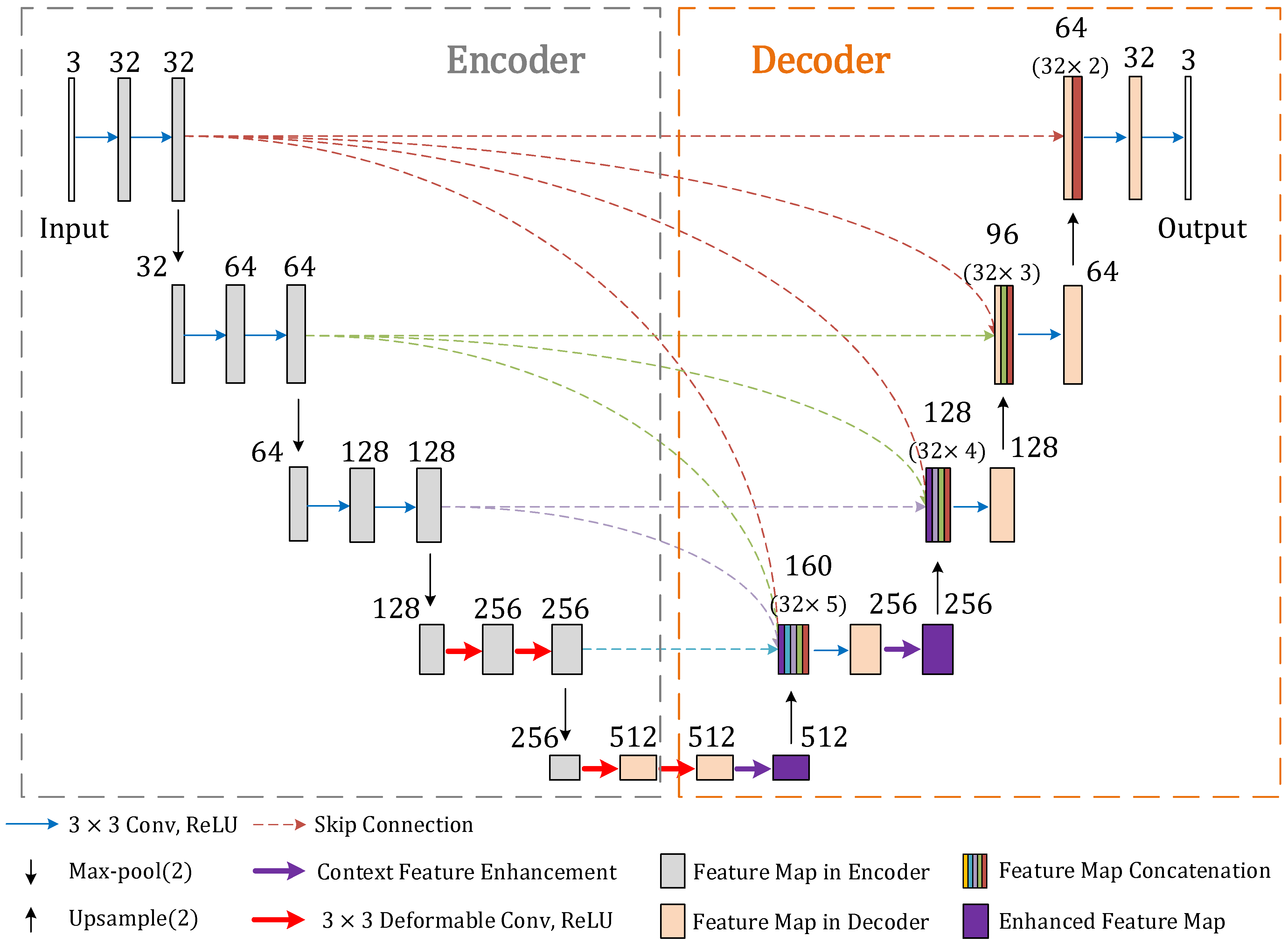
- In order to obtain refined crack segmentation results, a multi-scale skip connection structure is designed to aggregate the multi-level feature information extracted from the decoder and improve the network’s ability to capture the spatial features. The multi-scale skip connection also optimizes the feature aggregation method, which reduces the number of network parameters and lowers the computational cost.
- To accurately distinguish between crack and other interferences in the background, a contextual feature enhancement module is proposed to extract contextual information at multiple scales to improve the context awareness of the network. It consists of a pyramid pooling network and a channel attention mechanism which can recalibrate the channel weights of feature maps to guide the network to focus on important contextual information.
- Since the fixed sampling scale of plain convolution is not conducive to extracting the diverse morphological features of cracks, we improve the feature extraction network by introducing the deformable convolution into the deep layers of the encoder, changing the receptive field size of the network through adaptive sampling area adjustment, and enhancing its feature extraction capability.
2. Related Works
2.1. Traditional Image Processing Methods
2.2. Deep-Learning-Based Methods
3. Proposed Method
3.1. Multi-Scale Skip Connection Structure
3.2. Contextual Feature Enhancement Module
3.3. Introduction of Deformable Convolution
4. Experiments
4.1. Training Configuration
4.2. Datasets and Metrics
4.3. Comparison with Other Methods
4.3.1. Results on DeepCrack-DB
4.3.2. Results on CFD
4.3.3. Results on CCSD
4.3.4. Complexity and Efficiency Comparison
4.4. Ablation Experiments
4.5. Effect of Different Settings of the Network Components
4.5.1. Comparison of Different Skip Connection Structures
4.5.2. Analysis of the Contextual Feature Enhancement Module
4.5.3. Deformable Convolution in Different Encoder Layers
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Salam, M.; Mathavan, S.; Kamal, K.; Rahman, M. Pavement crack detection using the Gabor filter. In Proceedings of the 16th international IEEE conference on intelligent transportation systems, The Hague, Netherlands, 6–9 October 2013. [Google Scholar] [CrossRef]
- Eisenbach, M.; Stricker, R.; Seichter, D.; Amende, K.; Debes, K.; Sesselmann, M.; Ebersbach, D.; Stoeckert, U.; Gross, H.M. How to get pavement distress detection ready for deep learning? A systematic approach. In Proceedings of the 2017 International Joint Conference on Neural Networks, Anchorage, Alaska, 14–19 May 2017. [Google Scholar] [CrossRef]
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. Deepcrack: Learning hierarchical convolutional features for crack detection. IEEE Trans. Image Process. 2019, 28, 1498–1512. [Google Scholar] [CrossRef] [PubMed]
- Li, G. Improved pavement distress detection based on contourlet transform and multi-direction morphological structuring elements. Adv. Mater. Res. 2012, 466, 371–375. [Google Scholar] [CrossRef]
- Su, Z.; Guo, Y. Algorithm on Contourlet Domain in Detection of Road Cracks for Pavement Images. In Proceedings of the 2010 Ninth International Symposium on Distributed Computing and Applications to Business, Engineering and Science, Hong Kong, China, 10–12 August 2010. [Google Scholar] [CrossRef]
- Das, H.C.; Parhi, D.R. Detection of the Crack in Cantilever Structures Using Fuzzy Gaussian Inference Technique. AIAA J. 2009, 47, 105–115. [Google Scholar] [CrossRef]
- Zhang, D.; Qu, S.; He, L.; Shi, S. Automatic ridgelet image enhancement algorithm for road crack image based on fuzzy entropy and fuzzy divergence. Opt. Lasers Eng. 2009, 47, 1216–1225. [Google Scholar] [CrossRef]
- Zuo, Y.; Wang, G.; Zuo, C. Wavelet Packet Denoising for Pavement Surface Cracks Detection. In Proceedings of the 2008 International Conference on Computational Intelligence and Security, Suzhou, China, 13–17 December 2008. [Google Scholar] [CrossRef]
- Zhou, J.; Huang, P.; Chiang, F.P. Wavelet-Based Pavement Distress Classification. Transp. Res. Rec. J. Transp. Res. Board 2005, 1940, 89–98. [Google Scholar] [CrossRef]
- Kirschke, K.R.; Velinsky, S.A. Histogram-Based Approach for Automated Pavement-Crack Sensing. J. Transp. Eng. 1992, 118, 700–710. [Google Scholar] [CrossRef]
- Cheng, H.D.; Shi, X.J.; Glazier, C. Real-Time Image Thresholding Based on Sample Space Reduction and Interpolation Approach. J. Comput. Civ. Eng. 2003, 17, 264–272. [Google Scholar] [CrossRef]
- Zhao, H.; Qin, G.; Wang, X. Improvement of canny algorithm based on pavement edge detection. In Proceedings of the 2010 3rd International Congress on Image and Signal Processing, Yantai, China, 16–18 October 2010. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of Edge-Detection Techniques for Crack Identification in Bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef] [Green Version]
- Jmour, N.; Zayen, S.; Abdelkrim, A. Convolutional neural networks for image classification. In Proceedings of the 2018 International Conference on Advanced Systems and Electric Technologies, Hammamet, Tunisia, 25 March 2018; pp. 397–402. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Pauly, L.; Hogg, D.; Fuentes, R.; Peel, H. Deeper networks for pavement crack detection. In Proceedings of the 34th The International Association for Automation and Robotics in Construction, Taipei, Taiwan, 28 June 2017. [Google Scholar] [CrossRef] [Green Version]
- Tang, J.; Mao, Y.; Wang, J.; Wang, L. Multi-task Enhanced Dam Crack Image Detection Based on Faster R-CNN. In Proceedings of the 2019 IEEE 4th International Conference on Image, Vision and Computing, Xiamen, China, 5–7 July 2019. [Google Scholar] [CrossRef]
- Suh, G.; Cha, Y.J. Deep faster R-CNN-based automated detection and localization of multiple types of damage. In Proceedings of the Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems 2018, Denver, CO, USA, 5–8 March 2018. [Google Scholar] [CrossRef]
- König, J.; Jenkins, M.D.; Mannion, M.; Barrie, P.; Morison, G. Optimized deep encoder-decoder methods for crack segmentation. Digit. Signal Process. 2021, 108, 102907. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Lau, S.L.H.; Chong, E.K.P.; Yang, X.; Wang, X. Automated Pavement Crack Segmentation Using U-Net-Based Convolutional Neural Network. IEEE Access 2020, 8, 114892–114899. [Google Scholar] [CrossRef]
- Han, C.; Ma, T.; Huyan, J.; Huang, X.; Zhang, Y. CrackW-Net: A novel pavement crack image segmentation convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2021. [Google Scholar] [CrossRef]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Chambon, S.; Moliard, J.M. Automatic Road Pavement Assessment with Image Processing: Review and Comparison. Int. J. Geophys. 2011, 2011, 989354. [Google Scholar] [CrossRef] [Green Version]
- Katakam, N. Pavement Crack Detection System Through Localized Thresholding. Doctoral Dissertation, University of Toledo, Toledo, OH, USA, 2009. [Google Scholar]
- Oliveira, H.; Correia, P.L. Automatic road crack segmentation using entropy and image dynamic thresholding. In Proceedings of the 2009 17th European Signal Processing Conference, Glasgow, Scotland, 25 August 2009. [Google Scholar]
- Zhang, D.; Li, Q.; Chen, Y.; Cao, M.; He, L.; Zhang, B. An efficient and reliable coarse-to-fine approach for asphalt pavement crack detection. Image Vis. Comput. 2017, 57, 130–146. [Google Scholar] [CrossRef]
- Wang, K.C.P.; Li, Q.; Gong, W. Wavelet-Based Pavement Distress Image Edge Detection with À Trous Algorithm. Transp. Res. Rec. J. Transp. Res. Board 2007, 2024, 73–81. [Google Scholar] [CrossRef]
- Fernandes, K.; Ciobanu, L. Pavement pathologies classification using graph-based features. In Proceedings of the 2014 IEEE International Conference on Image Processing, Paris, France, 27–30 October 2014. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic Road Crack Detection Using Random Structured Forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Ren, Y.; Huang, J.; Hong, Z.; Lu, W.; Yin, J.; Zou, L.; Shen, X. Image-based concrete crack detection in tunnels using deep fully convolutional networks. Constr. Build. Mater. 2020, 234, 117367. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ran, R.; Xu, X.; Qiu, S.; Cui, X.; Wu, F. Crack-SegNet: Surface Crack Detection in Complex Background Using Encoder-Decoder Architecture. In Proceedings of the 2021 4th International Conference on Sensors, Signal and Image Processing, Nanjing, China, 15–17 October 2021. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. Lect. Notes Comput. Sci. 2018, 833–851. [Google Scholar] [CrossRef] [Green Version]
- Sun, X.; Xie, Y.; Jiang, L.; Cao, Y.; Liu, B. DMA-Net: DeepLab with Multi-Scale Attention for Pavement Crack Segmentation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18392–18403. [Google Scholar] [CrossRef]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar] [CrossRef]
- Zhou, T.; Wang, W.; Konukoglu, E.; Goo, L.V. Rethinking Semantic Segmentation: A Prototype View. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022. [Google Scholar] [CrossRef]
- Zhou, T.; Li, L.; Li, X.; Feng, C.M.; Li, J.; Shao, L. Group-Wise Learning for Weakly Supervised Semantic Segmentation. IEEE Trans. Image Process. 2022, 31, 799–811. [Google Scholar] [CrossRef]
- König, J.; Jenkins, M.D.; Mannion, M.; Barrie, P.; Morison, G. Weakly-Supervised Surface Crack Segmentation by Generating Pseudo-Labels Using Localization with a Classifier and Thresholding. IEEE Trans. Intell. Transp. Syst. 2022, 1–12. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Özgenel, Ç.F. Concrete Crack Segmentation Dataset, Version 1; Mendeley Data. [CrossRef]
- Fan, Z.; Li, C.; Chen, Y.; Di Mascio, P.; Chen, X.; Zhu, G.; Loprencipe, G. Ensemble of deep convolutional neural networks for automatic pavement crack detection and measurement. Coatings 2020, 10, 152. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | IoU (%) | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|
| DeepCrack | 66.49 | 66.67 | 85.28 | 70.01 |
| DeepLab v3+ | 75.95 | 86.18 | 85.04 | 84.52 |
| U-Net | 85.97 | 94.45 | 89.26 | 90.31 |
| UNet++ | 87.68 | 94.82 | 91.89 | 92.36 |
| Unet 3+ | 88.05 | 94.64 | 92.07 | 93.27 |
| MCIE-Net | 91.28 | 95.67 | 94.59 | 94.82 |
| Models | IoU (%) | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|
| DeepCrack | 75.52 | 83.83 | 88.62 | 84.71 |
| DeepLab v3+ | 68.9 | 79.02 | 84.32 | 81.31 |
| U-Net | 73.73 | 98.65 | 74.5 | 83.84 |
| UNet++ | 76.42 | 98.45 | 77.32 | 85.39 |
| Unet 3+ | 77.53 | 98.65 | 78.43 | 86.29 |
| MCIE-Net | 91.32 | 96.32 | 84.02 | 89.47 |
| Models | IoU (%) | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|
| DeepCrack | 78.77 | 83.76 | 90.86 | 87.37 |
| DeepLab v3+ | 76.03 | 96 | 77.22 | 84.91 |
| U-Net | 85.59 | 98.22 | 86.08 | 91.31 |
| UNet++ | 86.31 | 98.43 | 86.67 | 91.77 |
| Unet 3+ | 89.61 | 98.32 | 90.1 | 93.75 |
| MCIE-Net | 90.45 | 98.46 | 92.43 | 94.22 |
| Models | FPS (Frames/s) | ||
|---|---|---|---|
| DeepCrack | 14.72 | 181.11 | 26.28 |
| DeepLab v3+ | 16,385 | 187.69 | 12.4 |
| U-Net | 7.85 | 126.9 | 54.32 |
| UNet++ | 9.16 | 314.13 | 30.48 |
| Unet 3+ | 6.75 | 454.8 | 28.16 |
| MCIE-Net | 7.87 | 107.93 | 24.36 |
| Group | MSSC | CFEM | DConv | IoU (%) | F1 Score (%) |
|---|---|---|---|---|---|
| 1 | 85.97 | 90.31 | |||
| 2 | ✓ | 87.33 | 92.16 | ||
| 3 | ✓ | ✓ | 89.81 | 93.74 | |
| 4 | ✓ | ✓ | ✓ | 91.28 | 94.82 |
| Models | IoU (%) | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|
| Network A | 74.83 | 90.09 | 78.79 | 81.76 |
| MCIE-Net | 83.38 | 89.86 | 91.35 | 90.48 |
| Models | IoU (%) | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|
| Network B | 73.82 | 82.07 | 90.32 | 84.82 |
| MCIE-Net | 86.5 | 95.05 | 90.74 | 92.41 |
| Structures | IoU (%) | F1 Score (%) | ||
|---|---|---|---|---|
| PSC | 85.97 | 90.31 | 7.85 | 126.90 |
| DCSC | 87.68 | 92.36 | 9.16 | 314.13 |
| FSSC | 88.05 | 93.27 | 6.75 | 454.80 |
| MSSC | 87.33 | 92.16 | 5.82 | 101.58 |
| Group | PPM | SEB | IoU (%) | F1 Score (%) | ||
|---|---|---|---|---|---|---|
| 1 | 5.95 | 102.15 | 88.62 | 92.42 | ||
| 2 | ✓ | 7.83 | 107.92 | 89.89 | 93.44 | |
| 3 | ✓ | 5.99 | 102.16 | 89.24 | 93.05 | |
| 4 | ✓ | ✓ | 7.88 | 107.93 | 91.28 | 94.82 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Liao, Y.; Wang, G.; Chen, J.; Wang, H. A Multi-Scale Contextual Information Enhancement Network for Crack Segmentation. Appl. Sci. 2022, 12, 11135. https://doi.org/10.3390/app122111135
Zhang L, Liao Y, Wang G, Chen J, Wang H. A Multi-Scale Contextual Information Enhancement Network for Crack Segmentation. Applied Sciences. 2022; 12(21):11135. https://doi.org/10.3390/app122111135
Chicago/Turabian StyleZhang, Lili, Yang Liao, Gaoxu Wang, Jun Chen, and Huibin Wang. 2022. "A Multi-Scale Contextual Information Enhancement Network for Crack Segmentation" Applied Sciences 12, no. 21: 11135. https://doi.org/10.3390/app122111135