
YOLO-T: Multitarget Intelligent Recognition Method for X-ray Images Based on the YOLO and Transformer Models

 ,
, 

Abstract
:1. Introduction
2. Principle and Method
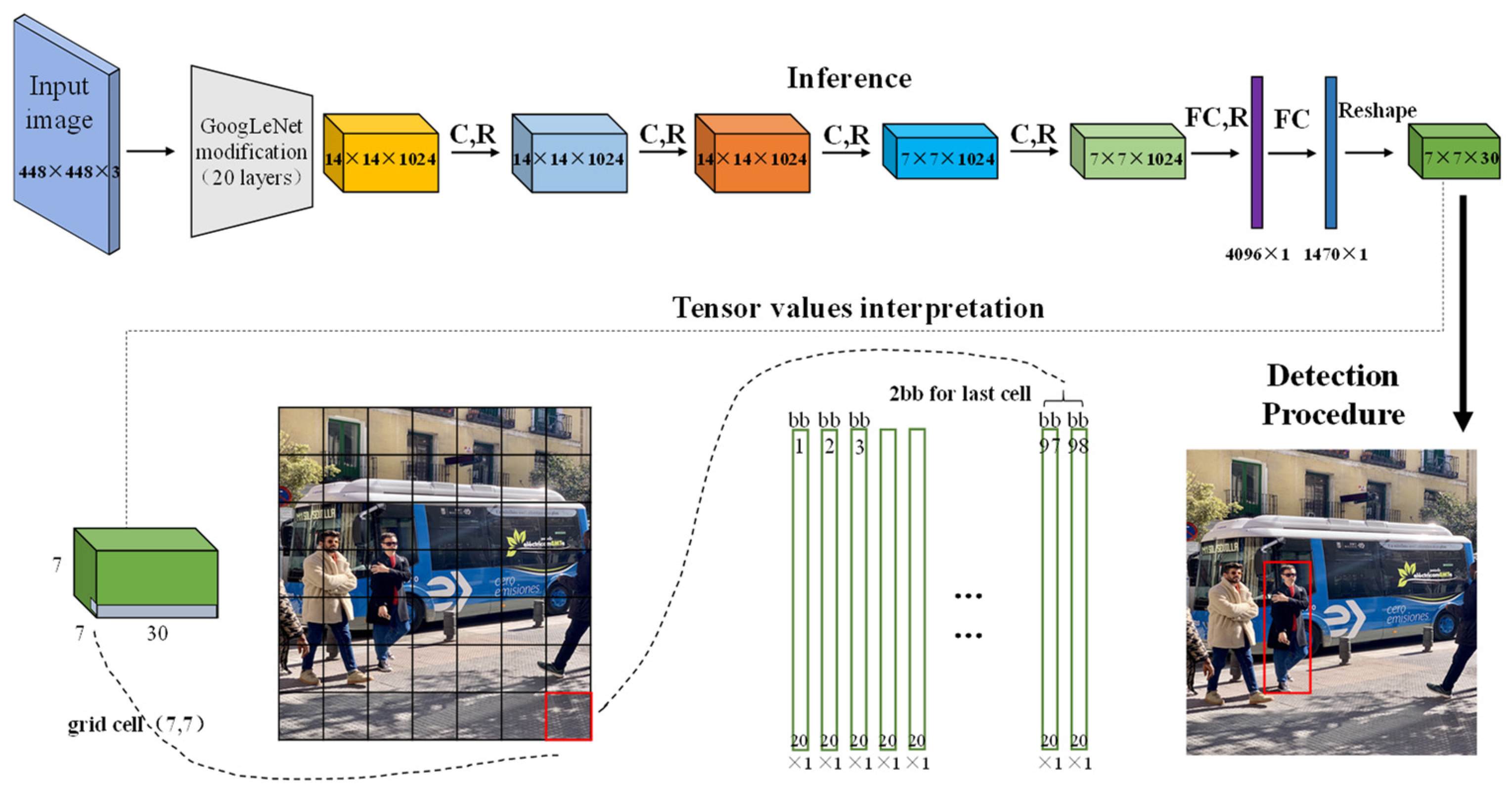
2.1. Object Detection Based on YOLO Deep Learning Network
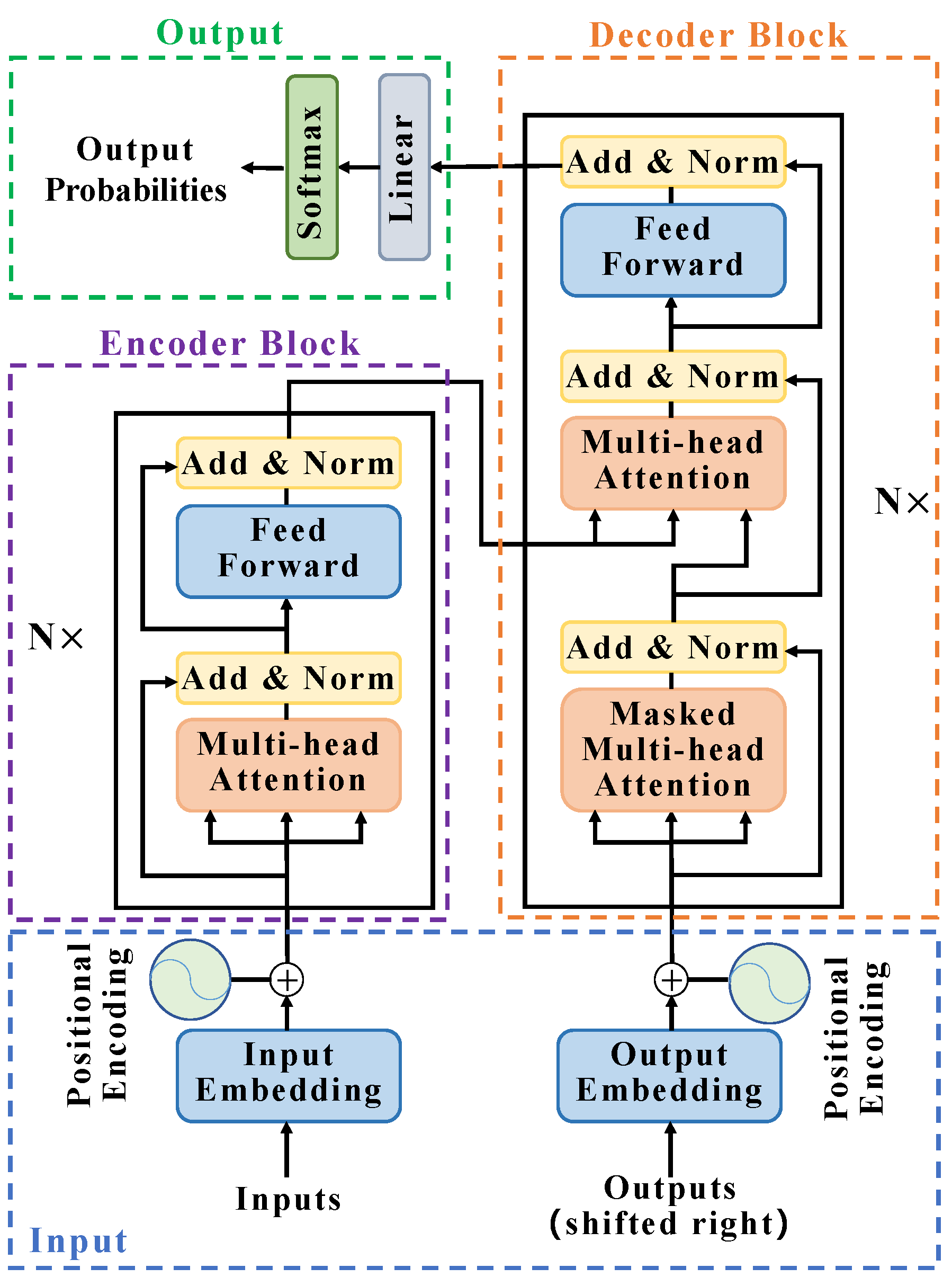
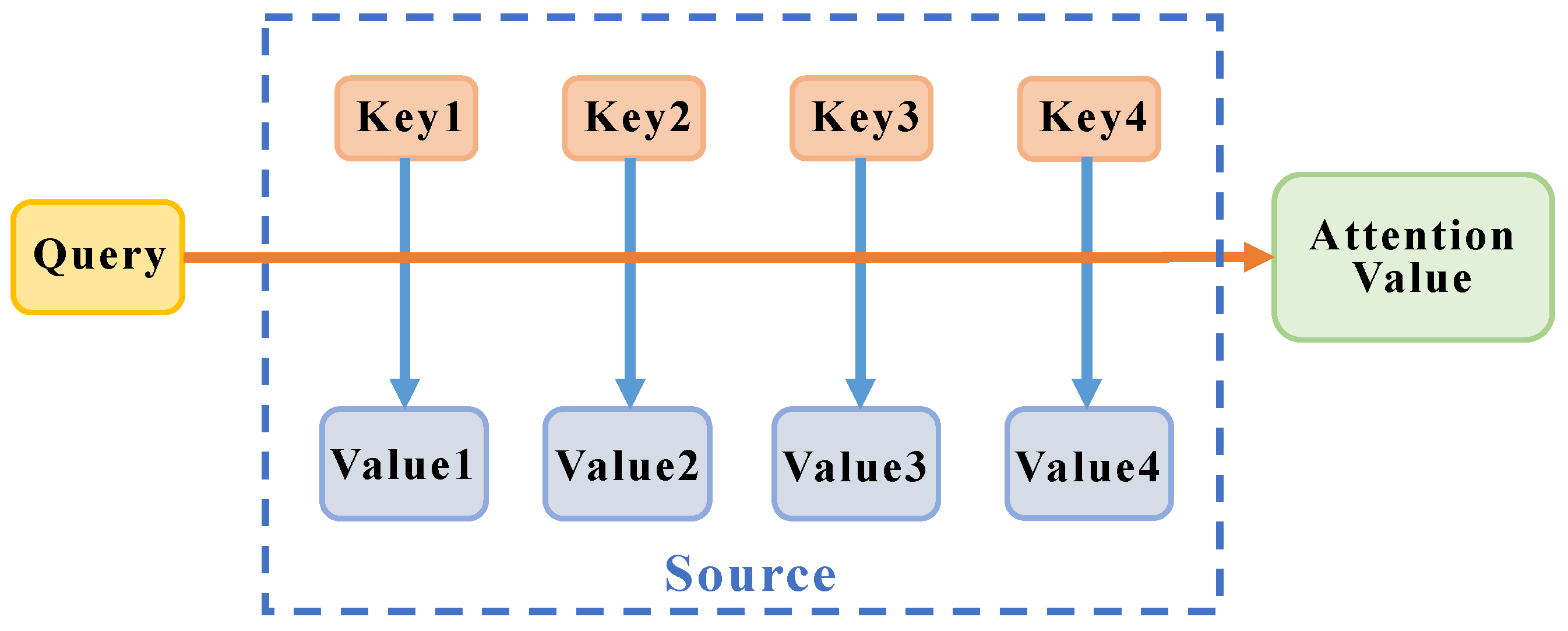
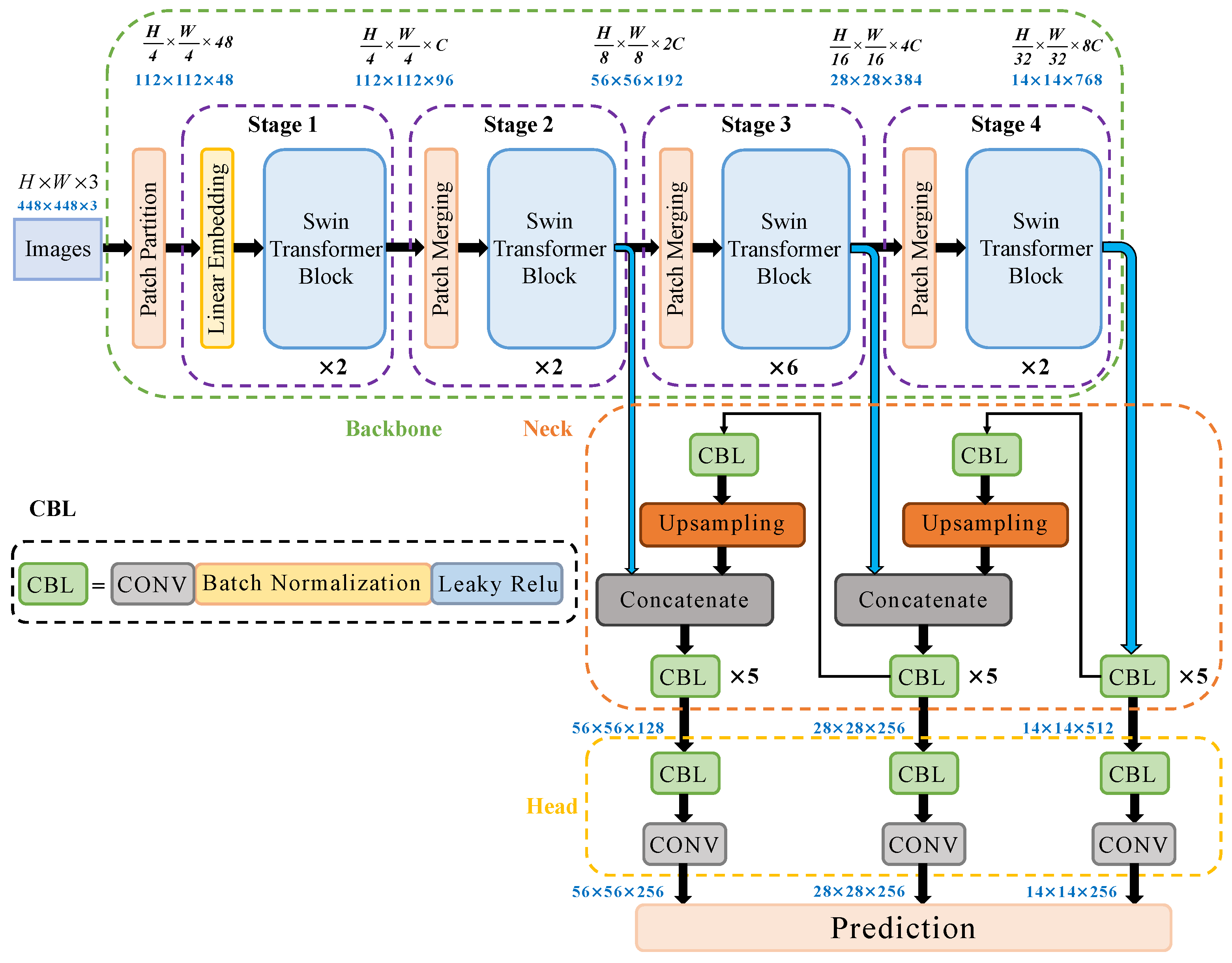
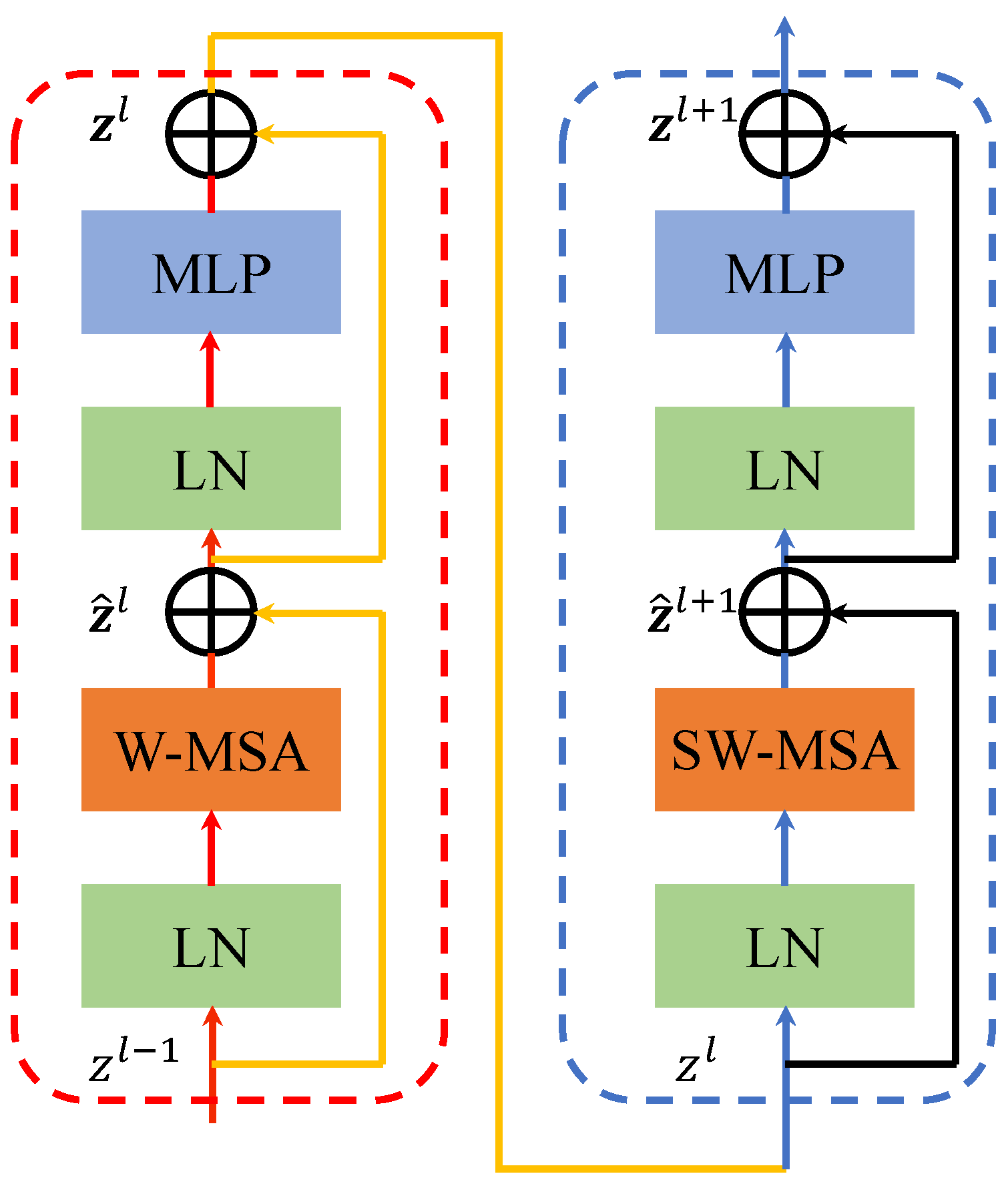
2.2. Build YOLO-T Target Detection Network
3. X-ray Image Recognition Experiment
3.1. Experimental Dataset
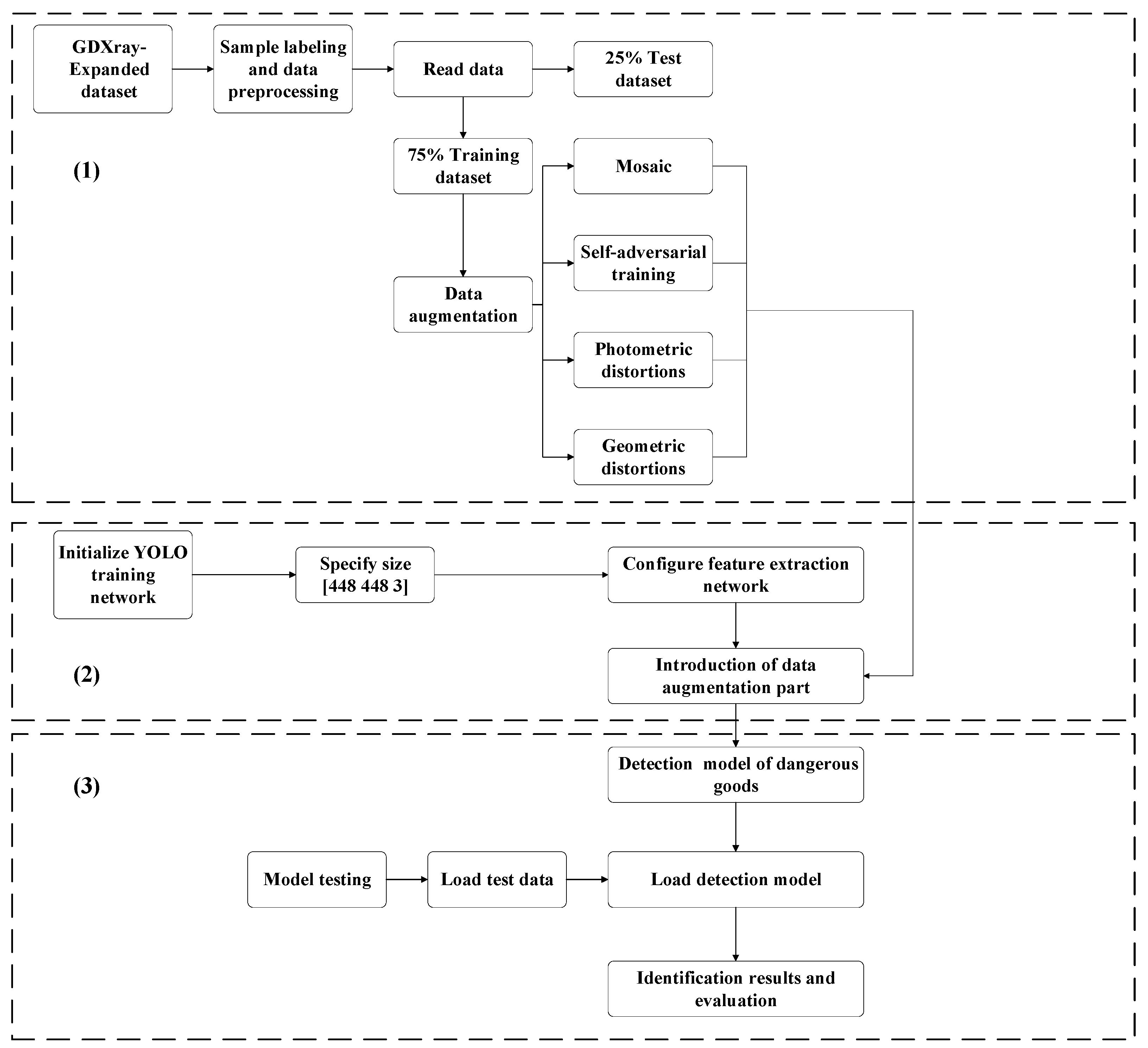
3.2. Data Preparation and Preprocessing
3.3. Experimental Environment
3.4. Object Intelligent Identification Process Based on YOLO-T
4. Experimental Results and Discussion
4.1. YOLO Recognition under Different Learning Rates and Iterations
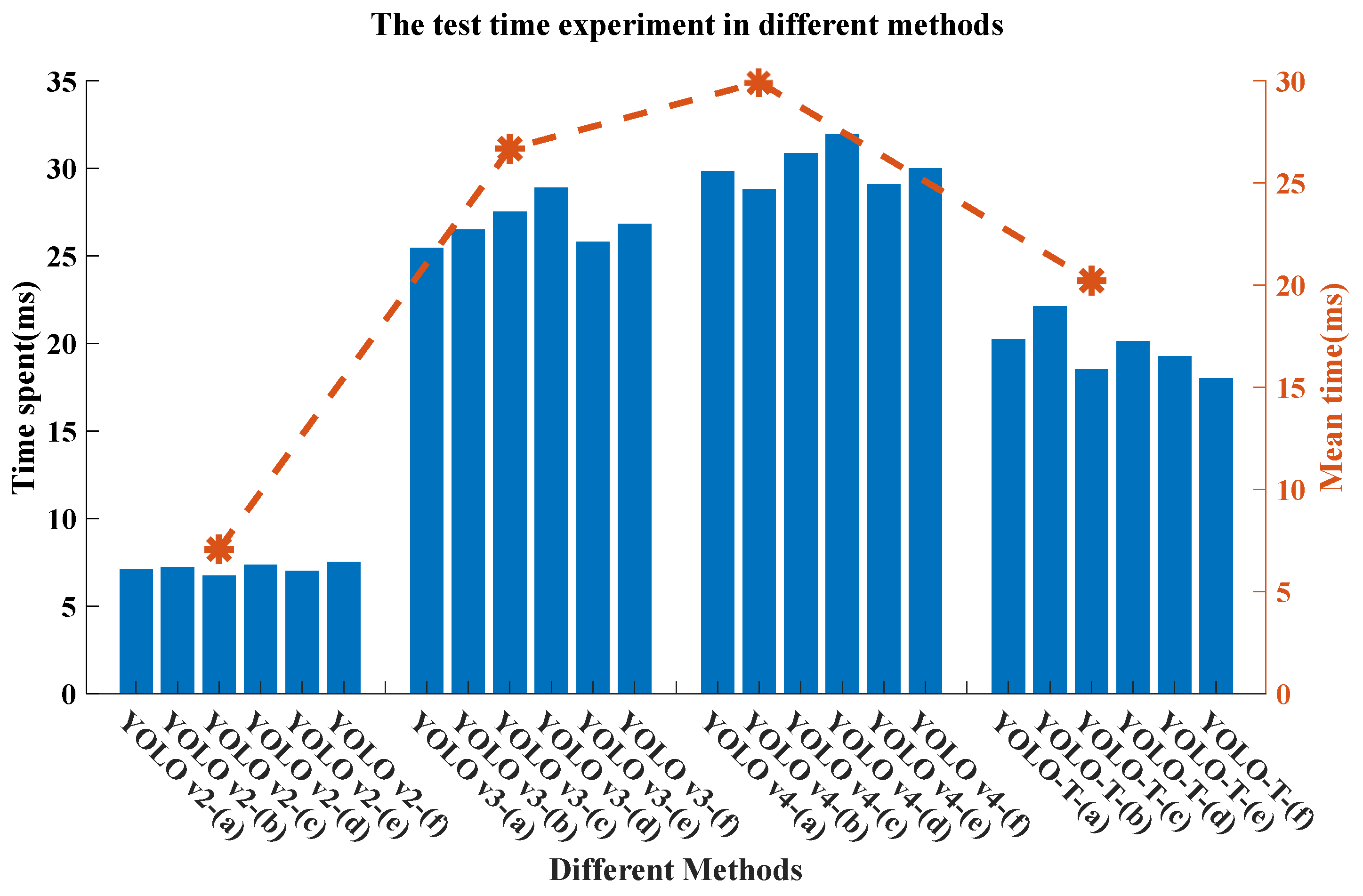
4.2. Comparison of Effects of Various Networks in Dangerous Goods Target Detection
4.3. YOLO-T Deep Learning Network Target Recognition
5. Conclusions
- (1)
- Among the existing YOLO series of deep learning networks, under the background of X-ray security inspection, the deep learning network processing effect of YOLO v2 version is the best, and the optimization of subsequent versions has not significantly improved the detection effect in this research field.
- (2)
- The proposed YOLO-T deep learning network was evaluated experimentally and was compared to existing YOLO network models, which are limited in terms of occlusion recognition and multitarget detection. We found that the proposed YOLO-T network solves these problems by introducing a transformer structure. The YOLO-T deep learning network was able to accurately detect seven different types of dangerous goods.
- (3)
- The YOLO-T deep learning network proposed in this paper can not only detect the seven types of dangerous goods mentioned in GDXray-Expanded. This method can be used to quickly and automatically detect dangerous goods in actual security detection scenarios, which has high engineering application value.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lichorobiec, S.; Barčová, K. Possible IED Threat to Airport Premises During Security X-ray Inspection. Trans. VŠB-Tech. Univ. Ostrav. Saf. Eng. Ser. 2016, 10, 31–37. [Google Scholar] [CrossRef] [Green Version]
- Wei, Z.; Chu, S.; Huang, Z.; Qiu, S.; Zhao, Q. Optimization design of X-ray conveyer belt length for subway security check systems in Beijing, China. Sustainability 2020, 12, 2133. [Google Scholar] [CrossRef] [Green Version]
- Mery, D.; Saavedra, D.; Prasad, M. X-ray Baggage Inspection with Computer Vision: A Survey. IEEE Access 2020, 8, 145620–145633. [Google Scholar] [CrossRef]
- Cañizares, P.C.; Merayo, M.G.; Núñez, A. Fortifier: A formal distributed framework to improve the detection of threatening objects in baggage. J. Inf. Telecommun. 2018, 2, 2–18. [Google Scholar] [CrossRef] [Green Version]
- Gu, B.; Ge, R.; Chen, Y.; Luo, L.; Coatrieux, G. Automatic and Robust Object Detection in X-ray Baggage Inspection Using Deep Convolutional Neural Networks. IEEE Trans. Ind. Electron. 2021, 68, 10248–10257. [Google Scholar] [CrossRef]
- Mery, D.; Svec, E.; Arias, M.; Riffo, V.; Saavedra, J.M.; Banerjee, S. Modern computer vision techniques for X-ray testing in baggage inspection. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 682–692. [Google Scholar] [CrossRef]
- Mery, D.; Svec, E.; Arias, M. Object Recognition in X-ray Testing Using Adaptive Sparse Representations. J. Nondestruct. Eval. 2016, 35, 45. [Google Scholar] [CrossRef]
- Xi, P.; Guan, H.; Shu, C.; Borgeat, L.; Goubran, R. An integrated approach for medical abnormality detection using deep patch convolutional neural networks. Vis. Comput. 2020, 36, 1869–1882. [Google Scholar] [CrossRef]
- Helwan, A.; Uzun Ozsahin, D. Sliding Window Based Machine Learning System for the Left Ventricle Localization in MR Cardiac Images. Appl. Comput. Intell. Soft Comput. 2017, 2017, 3048181. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In European Conference on Computer Vision; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 9905 LNCS; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef] [Green Version]
- Harsha Vardhan, P.; Uma Priyadarsini, P.S. Transfer learning using convolutional neural networks for object classification within X-ray baggage security imagery. Res. J. Pharm. Biol. Chem. Sci. 2016, 7, 222–229. [Google Scholar]
- Akcay, S.; Breckon, T.P. An evaluation of region based object detection strategies within X-ray baggage security imagery. In Proceedings of the International Conference on Image Processing, ICIP, Beijing, China, 17–20 September 2017. [Google Scholar] [CrossRef]
- Akcay, S.; Kundegorski, M.E.; Willcocks, C.G.; Breckon, T.P. Using deep convolutional neural network architectures for object classification and detection within x-ray baggage security imagery. IEEE Trans. Inf. Secur. 2018, 13, 2203–2215. [Google Scholar] [CrossRef] [Green Version]
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. GANomaly: Semi-supervised Anomaly Detection via Adversarial Training. In Asian Conference on Computer Vision; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 11363 LNCS; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef] [Green Version]
- Gaus YF, A.; Bhowmik, N.; Akcay, S.; Guillen-Garcia, P.M.; Barker, J.W.; Breckon, T.P. Evaluation of a Dual Convolutional Neural Network Architecture for Object-wise Anomaly Detection in Cluttered X-ray Security Imagery. In Proceedings of the International Joint Conference on Neural Networks, Budapest, Hungary, 14–19 July 2019. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Leng, X.; Liu, Y. Deep convolutional neural network based object detector for X-ray baggage security imagery. In Proceedings of the International Conference on Tools with Artificial Intelligence, ICTAI, Portland, OR, USA, 4–6 November 2019. [Google Scholar] [CrossRef]
- Hassan, T.; Bettayeb, M.; Akcay, S.; Khan, S.; Bennamoun, M.; Werghi, N. Detecting Prohibited Items in X-ray Images: A Contour Proposal Learning Approach. In Proceedings of the International Conference on Image Processing, ICIP, Abu Dhabi, United Arab Emirates, 25–28 October 2020. [Google Scholar] [CrossRef]
- Li, J.; Liu, Y.; Cui, Z. Segmentation and attention network for complicated X-ray images. In Proceedings of the 2020 35th Youth Academic Annual Conference of Chinese Association of Automation, YAC 2020, Zhanjiang, China, 16–18 October 2020. [Google Scholar] [CrossRef]
- Zhang, Y.; Kong, W.; Li, D.; Liu, X. On Using XMC R-CNN Model for Contraband Detection within X-ray Baggage Security Images. Math. Probl. Eng. 2020, 2020, 1823034. [Google Scholar] [CrossRef]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimed. Tools Appl. 2022, 1, 1–33. [Google Scholar] [CrossRef] [PubMed]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Shen, Z. YOLO-Submarine Cable: An Improved YOLO-V3 Network for Object Detection on Submarine Cable Images. J. Mar. Sci. Eng. 2022, 10, 1143. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, virtual, 11–17 October 2021. [Google Scholar]
- Mery, D.; Riffo, V.; Zscherpel, U.; Mondragón, G.; Lillo, I.; Zuccar, I.; Lobel, H.; Carrasco, M. GDXray: The Database of X-ray Images for Nondestructive Testing. J. Nondestruct. Eval. 2015, 34, 42. [Google Scholar] [CrossRef]
- Miao, C.; Xie, L.; Wan, F.; Su, C.; Liu, H.; Jiao, J.; Ye, Q. Sixray: A large-scale security inspection x-ray benchmark for prohibited item discovery in overlapping images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Net-Name | GN | GH | GT | GR | Gun | Scissors | Knife | mAP |
|---|---|---|---|---|---|---|---|---|
| YOLO v2 | 0.9014 | 0.9039 | 0.9043 | 0.9091 | 0.9081 | 0.8707 | 0.9075 | 0.9007 |
| YOLO v3 | 0.7007 | 0.8008 | 0.7993 | 0.9083 | 0.9013 | 0.6895 | 0.8881 | 0.8126 |
| YOLO v4 | 0.8876 | 0.8994 | 0.9085 | 0.9221 | 0.9080 | 0.8472 | 0.9708 | 0.9062 |
| YOLO-T | 0.9741 | 0.9633 | 0.9841 | 0.9872 | 0.9880 | 0.9512 | 0.9891 | 0.9773 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, M.; Yang, B.; Wang, X.; Yang, C.; Xu, J.; Mu, B.; Xiong, K.; Li, Y. YOLO-T: Multitarget Intelligent Recognition Method for X-ray Images Based on the YOLO and Transformer Models. Appl. Sci. 2022, 12, 11848. https://doi.org/10.3390/app122211848
Wang M, Yang B, Wang X, Yang C, Xu J, Mu B, Xiong K, Li Y. YOLO-T: Multitarget Intelligent Recognition Method for X-ray Images Based on the YOLO and Transformer Models. Applied Sciences. 2022; 12(22):11848. https://doi.org/10.3390/app122211848
Chicago/Turabian StyleWang, Mingxun, Baolu Yang, Xin Wang, Cheng Yang, Jie Xu, Baozhong Mu, Kai Xiong, and Yanyi Li. 2022. "YOLO-T: Multitarget Intelligent Recognition Method for X-ray Images Based on the YOLO and Transformer Models" Applied Sciences 12, no. 22: 11848. https://doi.org/10.3390/app122211848