1. Introduction
Image captioning is the task of generating the grammatically correct description of an image, which has been attracting much attention in the field of image understanding [
1,
2,
3,
4,
5,
6,
7,
8]. With the success of deep learning, image captioning models have recently achieved great progress. A typical deep neural network for an image captioning model generally follows an encoder–decoder paradigm, where a deep convolutional neural network (CNN) is introduced as the encoder to learn visual representations from the input image, while a recurrent neural network (RNN) serves as the decoder to recursively predict each word. Recently, the transformer-based image captioning models have shown superior performance to the conventional CNN-RNN models by using fully attentive paradigms. Despite great advances made in the model architectures, existing models still have two limitations: (i) they treat the predictions of visual and nonvisual words equally at each time step, leading to ambiguous inference; (ii) they have the tendency to generate minimal sentences, which is common in datasets. Consequently, how to organize phrases and words to accurately express the semantics of an image remains a challenging task.
The neuroscience research on language processing has demonstrated that the brain contains partially separate systems for processing syntax and semantics [
9,
10], which provides us a new prospective to overcome the limitations of existing image captioning models. Naturally, the traditional encoder–decoder framework can be improved by imposing an analogous separation. Considering that in English the part-of-speech (PoS) tag sequences contain rich grammatical rules available to infer the corresponding words (We use the Stanford constituency parser to obtain the PoS tags of captions. URL:
https://www.nltk.org/book/ch05.html (accessed on 15 November 2022), in this paper, we intend to improve the grounding performance of image captioning by using the PoS information.
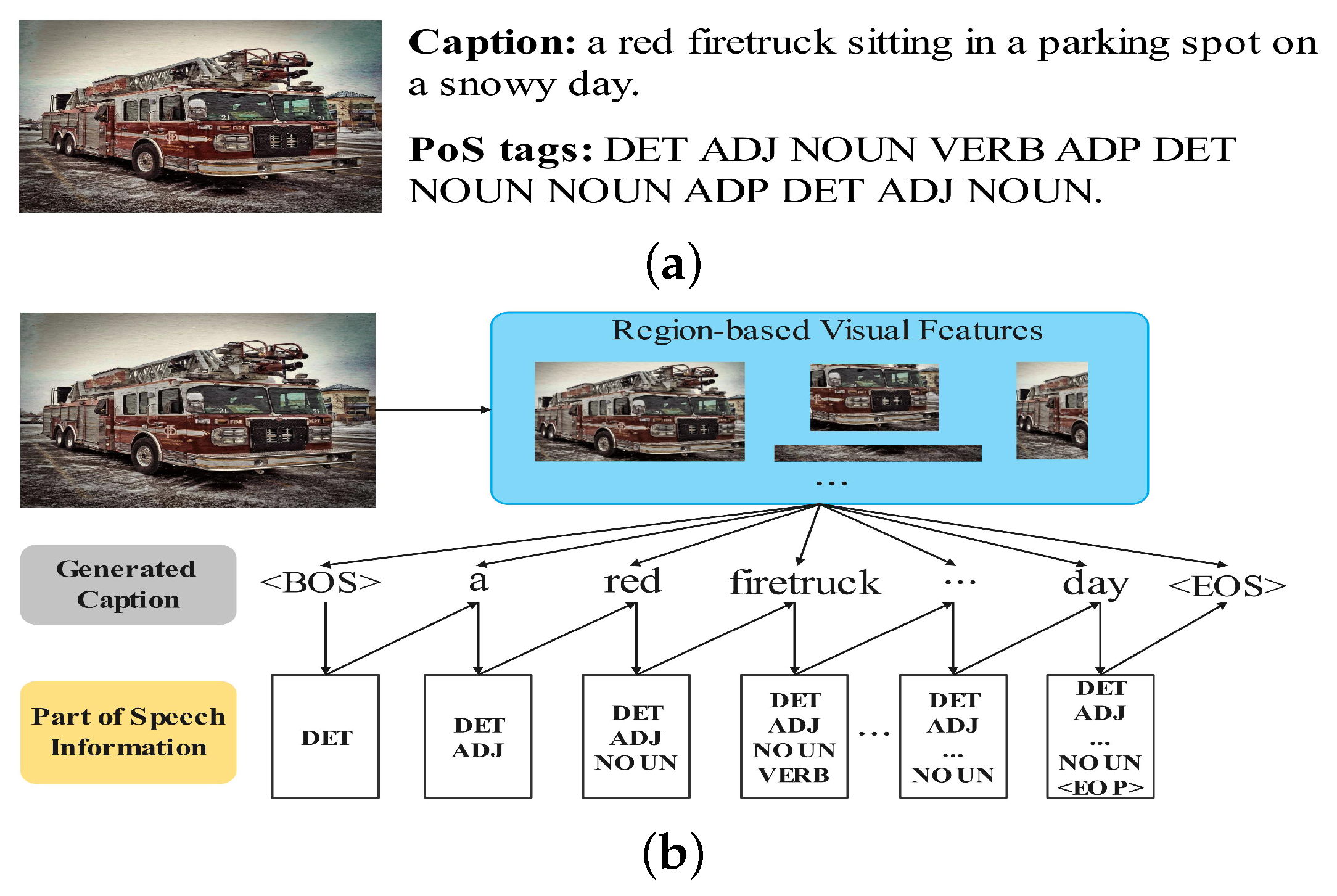
Figure 1a illustrates an example of an image caption with its corresponding PoS tags. From
Figure 1a, we can observe that the different parts of speech of the words play specific grammatical roles in the caption. For example, the determiners (DET) and adjectives (ADJ) are generally used to modify the nouns (NN). The adpositions (ADP), such as
in and
on, play the role of connecting two noun phrases so as to establish their semantic relationship. All the PoS tags play an important role in generating the caption since they correspond to words one by one. Consequently, it is essential to master the PoS of each word for generating grammatically correct sentences. Besides, some PoS tags, such as ADJ and NOUN are closely related to the visual features of the image while some PoS tags, such as the second ADP (corresponding to the word
on) in the PoS tag sequence, are irrelevant to any visual features. As a result, there is a need to find more ways to highlight the PoS information contained in sentences so that they can provide additional guidance for one captioner to distinguish between visual and nonvisual words.
Aiming to obtain the syntactic information contained in the sequence of PoS tags, we first introduce a PoS predictor to predict the PoS tag of the next word, which can be integrated with the image captioning model seamlessly. As shown in
Figure 1b, the PoS tag of the next word is predicted based on the previous words while the PoS information provided by the PoS predictor is utilized to guide the generation of the next word. For instance, after the words
a and
red as well as their PoS tags are generated, the PoS predictor uses the word embeddings of
a and
red as inputs to predict the PoS tag NOUN. Meanwhile, the PoS information of DET, ADJ, and NOUN are utilized by the image caption model to predict the next word
firetruck. Unlike the existing transformer-based captioners that treat all word predictions equally, the sequence of partially generated tags can help evaluate the effect of visual features and language signals on the word prediction. As illustrated in
Figure 1a, when the word
on is to be generated, the visual features are actually not very helpful at the current time step. However, the conventional transformer-based image captioners take no effective measures but simply concatenate attended visual features and language signals in each decoder layer, i.e., the irrelevant visual features are also used to predict the next word. As a result, the captioners are easily distracted by irrelevant visual concepts, leading to the generation of incorrect words. In contrast, after the partial PoS tag ADP of the next word
on is available, the captioners can exploit the information of partially generated PoS tags to balance the effect of visual features and language context, e.g., the language cues would be paid more attention to at the current time step, which facilitates the generation of the correct word
on.
In order to make a transformer-based image captioning model effectively align the generated words with the visual or nonvisual features of an image and further generate the grammatically correct captions with the help of the PoS information, we propose a PoS-Transformer framework based on a new learning paradigm. Specifically, the process of generating captions is divided into two stages: PoS prediction and caption generation. The PoS tag of the next word is predicted in the first stage, which is much easier than predicting the next word directly, since the number of PoS tags is far less than that of words. In the second stage, two different PoS-guided attention modules are proposed on top of the PoS guiding information, visual features, and linguistic context, which enables the decoder to adaptively attend to visual features and language signals. As a result, the PoS predictor, the PoS-guided attention modules, and the encoder–decoder captioning network closely collaborate to enhance the performance of image captioning. The main contributions of our work can be summarized as follows:
We propose two kinds of PoS-guided attention mechanisms based on the PoS information, adaptively adjusting the effect of visual features and language signals on the word prediction, to encourage the generation of more grounded captions.
We incorporate the PoS prediction model and the PoS-guided attention modules into the transformer-based captioning architecture to build a unified end-to-end image captioning framework, boosting the performance of image captioning by separating syntax and semantics for the prediction of each word.
We optimize the proposed PoS-Transformer network by a multitask learning method on the Flickr30k and MSCOCO benchmark datasets, respectively. Extensive experiments demonstrate the effectiveness of our method.
The remainder of this paper is organized as follows.
Section 2 introduces the related work, especially the prevailing deep-learning-based methods. Our proposed framework and its multitask learning for image captioning are detailed in
Section 3. The experimental results are reported in
Section 4. Finally,
Section 5 concludes the paper.
2. Related Work
Image captioning. The mainstream image captioning methods generally follow the encoder–decoder paradigm, where image features extracted by a CNN are fed into an RNN to generate the corresponding sentence. For example, Xu et al. [
11] first utilized soft and hard attention mechanisms to attend to the different CNN grid features of an image when generating each word. Lu et al. [
12] presented an adaptive attention mechanism to determine where to attend to visual features for the word prediction. After that, Anderson et al. [
13] further introduced an attention mechanism over the region-based features extracted by an object detector. Despite progress made on the basis of visual attention mechanism over object features, these approaches suffer from catastrophic forgetting in long-term memory, leading to limited performance improvement. To overcome the limitations of RNN-based image captioning models, plenty of transformer-based models [
14,
15,
16,
17,
18,
19,
20,
21,
22], following fully attentive paradigms, have recently been presented and have improved the performance remarkably. For example, Herdade et al. [
15] developed an object relation transformer (ORT) captioning model, which explicitly incorporated spatial relationships between region features through geometric attention. Li et al. [
23] introduced entangled attention into a transformer-based sequence modeling framework that performs attention over visual features and semantic attributes simultaneously. Recently, a large amount of methods have been explored to improve image understanding with the help of a scene graph, as it contains rich semantic information. For example, Yang et al. [
24] proposed a method that first used the sentence’s scene graph to learn a dictionary, and then incorporated it with the image’s scene graph for the description generation. Yao et al. [
25] presented a model that integrated both the semantic and spatial object relationships as image representation. Since the scene graph constructed a series of semantic relationship information, the model achieved comparable results. Zhao et al. [
26] proposed a multilevel cross-modal alignment (MCA) module to align the image scene graph with the sentence’s scene graph at a different level. Although the existing captioning approaches have achieved impressive results, they still follow the conventional way of modeling language and suffer from the limitations mentioned above.
PoS-based image captioning. Recently, some works have also introduced the PoS information into image captioning models [
27,
28,
29]. However, these methods are all based on long short-term memory (LSTM) networks, while our model exploits the transformer-based captioning architecture and fully attentive paradigm, which is essentially different from them. The model proposed by Zhang et al. [
27] is the most related to ours; they integrated the PoS information with two popular image captioning models. However, their models suffered from dependencies between distant positions since the hidden states of LSTM were used to predict the PoS sequences. He et al. [
28] utilized PoS tags as switches to guide the generation of the visual words. However, they required an external PoS tagger in both the training and test stages, which was limited in practice. In our PoS-Transformer, a PoS prediction network, as a part of the framework, is seamlessly integrated with other parts of PoS-Transformer. Consequently, the captions can be generated word by word at the inference time without any extra PoS taggers. Deshpande et al. [
29] used the part-of-speech information to generate diverse captions. They first predicted a PoS sequence for an image and then employed the PoS sequence as the guiding information to generate image captions. However, they quantized the space of POS tag sequences by using a classification model, which harmed the generation of fine-grained captions. Unlike existing PoS-based image captioning models, our proposed PoS-Transformer framework is able to process both word sequences and PoS sequences in parallel during training. On one hand, by means of cross-attention, PoS-Transformer establishes the relationship between the visual features and PoS information as well as the relationship between the partially generated words and PoS information. On the other hand, PoS-Transformer also captures the self-attention within the PoS information, which is helpful to adaptively adjust the weights between visual features and language signals for the word prediction.
3. Approach
The proposed PoS-Transformer model aims to guide the process of caption generation with the part-of-speech information on top of the Transformer architecture. Notably, our method follows a novel learning paradigm, which maintains the PoS and word information in separate streams for image captioning. Specifically, PoS-Transformer is composed of four parts: (1) a visual subencoder that exploits the deep visual representation on the basis of a self-attention mechanism; (2) a language subencoder that represents language signals; (3) a self-attention PoS predictor (SAPP) which is used to predict the category of PoS and obtain the PoS information for generating the next word in the captioning process; (4) a PoS-guided multimodal decoder which provides two alternative attention mechanisms, i.e., single attention (SAT) and dual attention (DAT), to integrate and decode visual features, language signals, and PoS information.
Figure 2 illustrates the overall architecture of the proposed PoS-Transformer model.
3.1. Dual-Way Encoder
Different from the local operator essence of convolution [
3,
30], the full transformer captioning networks, effectively accessing information globally via self-attention mechanism, have recently been proposed and achieved promising performance. However, the existing transformer-based captioning architectures are still based on the conventional language model, which generates the captions word by word regardless of the grammatical structures, leading to the limitations mentioned above. Consequently, it is essential to construct a novel image captioning architecture, which not only separates syntactic structure and word semantics, but has the ability to guide the usage of visual and language information. To reach this goal, inspired by the ETA model [
23], we first propose a dual-way encoder that contains a visual subencoder and a language subencoder to obtain the visual features and language signals attended to, respectively.
(1) Visual subencoder: In
Figure 3, the region-based visual features of an image extracted by a pretrained Faster-RCNN model are utilized as the input of visual subencoder. Given a set of region-based visual features
extracted from an input image, where
N is the number of visual regions in an image, the visual features
V are first projected to a
d-dimensional space via a fully connected layer to adapt to the visual subencoder’s dimensionality. Then, the projected features
are input into the visual subencoder with
L attention blocks. To be specific, the output of the
lth (
) layer is input into a multihead module (MH) [
31] in the
th layer, which is then followed by an AddNorm operation:
and a positionwise feed-forward network (FFN) [
31] is adopted to further transform the outputs, which is also encapsulated within the AddNorm operation:
Eventually, we can obtain , i.e., the output of our visual subencoder, which represents the considered visual features, on basis of the self-attention mechanism.
(2) Language subencoder: Given a caption
, where
denotes the
ith word in the sentence and
M is the number of words. To adapt the language subencoder’s dimensionality, all tokens are first embedded to
d-dimensional vectors through an embedding matrix and then fed into the positional encoding module for the relative and absolute position information. Finally, we obtain the initial input features
, which are input to the language subencoder with
L attention blocks. Different from the visual subencoder, the output of the
lth (
) layer is passed into the masked multihead (MMH) module [
31] to ensure that the prediction for the
tth word
depends only on the previous words
, and the output of the
th layer is denoted as follows:
Recursively, the output of the Lth layer, denoted as , can be obtained and used as the language signals to be fed into the following decoder.
3.2. Self-Attention PoS Predictor
In the self-attention PoS predictor, we also use a randomly initialized word-embedding matrix and positional encoding to project the input tokens
to
d-dimensional vectors
. The PoS prediction model takes the projected features
as the initial input to
N, the first attention block. Similar to the language subencoder, the output of the (
)th layer can be represented as:
Finally, the output of the
Nth decoder stack is used as the PoS information to predict the probability distribution of the next word’s PoS as follows:
where
denotes the hidden state corresponding to the (
t − 1)th PoS, the embedded matrix
, the bias vector
,
denotes the previously generated words, and
is the class number of PoS. Meanwhile, as shown in
Figure 3, the PoS information
is then passed to the PoS-guided multimodal decoder to guide the caption generation.
3.3. PoS-Guided Multimodal Decoder
(1) PoS-guided single attention: Different from the traditional transformer decoder, we introduce a single cross-attention over the fused features of visual features and language signals by virtue of the PoS information.
As shown in
Figure 3, for the (
)th layer, the input
is fed into an MMH module, followed by the AddNorm operation:
Note that
. Subsequently, the output
is fed into one multihead cross-attention module to perform the attention task over visual features
as follows:
Since the PoS information is beneficial for both visual words and nonvisual words, it is used to attend to the fused features of visual features and language signals during training. Meanwhile, it is also added to the considered fused features, to provide the decoder with the PoS information. To be specific, we utilize the PoS information
as the query vectors to perform the cross-attentions over
as follows:
Finally, the output of the multimodal decoder can be obtained as follows:
(2)
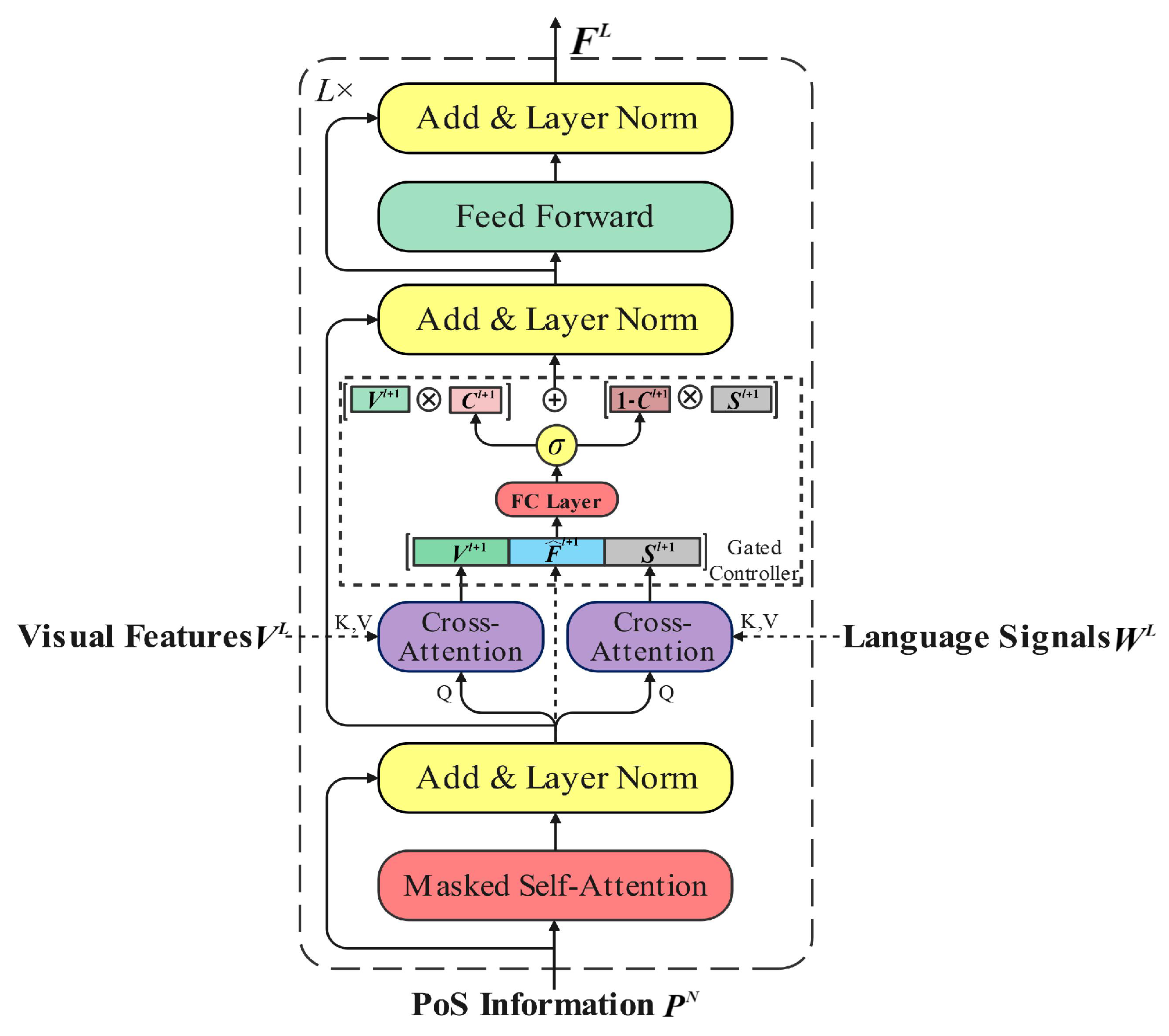
PoS-guided dual attention: Although the single attention mechanism utilizes the POS information to facilitate the generation of grounded captions, it cannot adaptively adjust the weights between visual features and language signals at each decoding time step. Inspired by the ETA model [
23], we first introduce the dual attention mechanism into the multimodal decoder, which employs the PoS information to attend to the visual features and language signals, respectively. In addition, a gated controller module is inserted after the dual attention module, which enables the decoder to dynamically adjust the weights between the visual features and language signals.
As depicted in
Figure 4, the dual attention module is inserted between the MMH and FFN modules, which allows the decoder block to apply attention over the output visual features
and language signals
of the dual-way encoder simultaneously. Similar to the single attention, we have:
where
. Then, the output
is passed into two multihead cross-attention modules to perform the attention task over language signals
and visual features
:
Next, as shown in
Figure 4, the gated controller module is introduced into the decoder to dynamically specify the weights of
and
on the word prediction. Concretely, the context gate
of the gated controller is determined by the visual features
, the language signals
, and the current self-attention output
:
where
,
,
and
denote the vector concatenation and sigmoid function, respectively. The gate value
and its complement part
control the flow of visual features
and language signals
, respectively, we have:
where ⊙ represents the Hadamard product and
denotes the output of the gated controller module.
Finally, the output
of the PoS-guided SAT or DAT module is input into the word classifier to predict the next possible word as follows:
where
is the hidden state corresponding to the (
t − 1)th word, the embedded matrix
, the bias vector
, and
is the size of the vocabulary.
3.4. Training Details
As shown in
Figure 3 and
Figure 4, the SAT-based and DAT-based multimodal decoder have the same input visual features, language signals, and PoS information as well as the same output vectors. The two outputs of our models are utilized to predict the next word and its PoS tag, which, respectively, correspond to two different objective functions. Thus, in practice, the network weights of these two models can be trained concurrently by a supervised multitask learning.
For an input image, assume its region-based visual feature vector as
V, the corresponding ground-truth caption
and the ground-truth PoS tags
. For the self-attention PoS predictor, the cross-entropy (XE) loss for the PoS prediction is:
where
represents the parameters of the SAPP network.
The parameters
of our image captioning model (including dual-way encoder and PoS-guided multimodal decoder) is optimized via minimizing the following cross-entropy loss
between the generated captions and the ground truths:
Combining the word prediction loss
with the PoS prediction loss
, the total loss function for our proposed PoS-Transformer framework can be defined as:
where
is a trade-off factor between the PoS loss and the word loss. Thus, all the parameters of the PoS-Transformer network can be optimized by minimizing the total loss function.
As can be seen from
Figure 2, when minimizing the XE loss
, the parameter
of the SAPP network will also be optimized, which indicates that the word prediction can be considered as the leading task of the whole model. At the same time, when the XE loss
is minimized, only the PoS predictor in the whole framework will be updated. Thus, the training of SAPP plays a role of auxiliary task for the main task. By means of the ground-truth PoS tags, the PoS prediction model can be well optimized, which provides the main task with the auxiliary optimization direction of the parameter
. Consequently, with the guidance of SAPP, the image captioning part of our whole framework can be encouraged to generate more grounded and fine-grained captions.
At inference time, PoS-Transformer needs not employ any PoS tagger to tag each word in the generated sentences since it actually utilizes the current hidden state of the SAPP network as the PoS information to guide the caption generation.
5. Conclusions
In this paper, we presented PoS-Transformer, a novel transformer-based framework for image captioning, to separate the grammatical structures and word semantics of captions and incorporate the PoS guiding information into the modeling. PoS-Transformer seamlessly integrated the PoS prediction module with the transformer-based captioner for a more grounded and fine-grained image captioning. By virtue of two proposed attention mechanisms, the PoS-Transformer decoder effectively exploited the PoS information to guide the caption generation, which not only adaptively adjusted the weights between visual and language signals for more grounded captioning, but leveraged the PoS information to generate more fine-grained sentences. Extensive experiments as well as ablation studies demonstrated that our method could significantly boost the performance of image captioning on top of the transformer-based architecture and substantially outperform other PoS-based image captioning models on the Flickr30k and MSCOCO datasets.
The current PoS-Transformer model focuses on introducing syntactic structures into the conventional language model in image captioning, which can play a better role in robot interaction, preschool education, and other application fields. Additional visual and semantic encoding approaches, such as exploiting the image attributes and the relative geometry relations between the objects, are not integrated with PoS-Transformer. However, it has been validated that these approaches can provide much richer visual and semantic information to facilitate a high-quality caption generation. In our future work, we will further enrich the representations of visual and semantic concepts to boost the performance of PoS-Transformer.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}