1. Introduction
Neural network optimization algorithms continue to be a well-studied subject among researchers [
1,
2,
3,
4,
5,
6,
7]. Training a deep neural network could largely be termed an optimization problem and is usually trained using stochastic gradient descent-based optimization algorithms. The main goals of researchers are to minimize the error function and accelerate convergence to an optimal global solution, with the overall objective of improving the model’s performance and its generalization ability. In this regard, optimizers are an important hyperparameter that affect the training performance of deep neural networks. Hence, it is important to choose the right optimizer for any given dataset problem that is being investigated, since the overall objective of neural network training is to minimize the prediction error by locating the global optimum on the loss surface. However, there is no consensus on this, so researchers are left with the task of experimenting with different optimization algorithms.
Several well-known optimization algorithms are used in training neural networks and can be broadly categorized into two: the classic stochastic gradient descent (SGD), which uses a static learning rate, and the adaptive stochastic learning rate such as ADAM and ADAGrad, which use adaptive learning rates. The learning rate is a key and central hyperparameter used by the optimizers for training neural networks and controls how fast a given model adapts to the problem it seeks to solve by helping the model to respond to the estimated error or loss each time the weights and biases values are updated. For instance, too large a learning rate could result in too fast a weights update, which may lead to instability in the training process and cause the model to converge prematurely to a suboptimal solution, whereas too small a learning rate may result in very tiny updates to the weights and a longer training process that could cause the model to be stuck in the local optima.
Researchers developed the adaptive learning rate optimizers as an improvement to the classic SGD because of the latter’s perceived slowness in arriving at an optimal solution and manually tuning the learning rate. However, one of the challenges still faced by these adaptive learning rate optimization algorithms is being trapped in local minima as against the desirable global minima [
8], sometimes even exhibiting inferior performance in comparison to the classic SGD in some machine learning settings and problems [
8], which has resulted in using a warm-up heuristic to mitigate these effects [
9] and other ongoing improvements published in the literature. Among the adaptive learning rate optimizers, ADAM is the most popular among researchers due to its suitability in most problem cases. Because there is no consensus on the right optimizer to choose for a given task, as shown in a comparative study conducted in [
10], researchers continue to work to address the issues with ADAM and other well-known optimization algorithms bordering around learning rate, stabilizing training, faster convergence, and improved generalization [
6,
11].
There have been two recent developments in optimization research for deep neural networks. First is a study that sought to develop an improved variant of ADAM called rADAM (rectified ADAM) [
7]. The authors sought to address the underlying causes of sub-optimal convergence to local optima by rectifying the undesirable large variance of adaptive learning rate usually observed during the early stage of training in various neural network architectures and models. The root cause, they argue, is because of the limited training data at the initial training stage compared to the later stage. They advocated the use of a lower learning rate during the first few training epochs as a solution to alleviate the convergence problem.
Secondly, another recent study saw the development of the
Lookahead optimization algorithm published by the authors in [
6], which iteratively updates two weights, with the faster weights exploring or ‘looking ahead’, while the slower weights maintain the overall training stability of the neural network. The study was inspired by advances made in neural network loss surface research that allows a robust way to accelerate convergence and training stability All this is achieved with less hyperparameter tuning and minimal computational cost.
The backpropagation algorithm is key to fast learning in neural networks [
12]. Backpropagation is a term that is used to compute the partial derivatives ∂C/∂w and ∂C/∂b of the cost function
C, concerning any weight
w and bias
b in the network [
13]. It gives insights into the overall behavior of the neural network in terms of how changing the weights and biases minimizes the cost function, which is determined by the gradients of the cost function. One of the factors that determine the stability and speed of network converge is the optimization algorithm; hence, it is worth examining how each optimizer’s update rule could make convergence faster, while at the same time maintaining high accuracy and low loss based on any given dataset-specific problem and the neural network architecture.
This paper extends the work in [
14] in which the authors performed a comparative evaluation of the seven most commonly used first-order stochastic gradient-based optimization algorithms on a simple convolutional neural network architecture. In this current work, we go further to probe the impact of optimization algorithms on increasing CNN network sizes to understand their performance behavior. Accordingly, we pose the following questions: (1) How do different optimizers impact the learning performance of CNN architectures with variations in width, depth and width/depth on image classification problems? (2) Are there significant differences in the performance outputs?
Thus, we formulate a hypothesis for this study that given a non-convex problem, different optimization algorithms can find completely different solutions when initialized from the same point. We achieve this through an empirical study of different CNN architectures with varying network sizes to find out if we observe any discernable learning performance.
This leads us to the main contributions of the present paper, summarized as follows:
We implemented three different wider, deeper, and wider/deeper simple CNN architectures.
We conducted extensive experiments and analyzed the effects of nine different optimizers on increasing deepness, wideness, and deepness/wideness of the CNN architectures on three benchmark image classification datasets (Cats and Dogs, Natural Images, and Fashion MNIST).
We provided insights into the effects of optimizers on CNN depth, width and depth/width architectures to inform optimal problem-specific CNN model design.
The remainder of the paper is organized in the following way:
Section 2 presents a review of related works;
Section 3 describes the different optimizers investigated in this study; and
Section 4 presents the methodology of the study, including the experimental setup, summary of the dataset characteristics, and an overview of the CNN architectures studied. The experimental results and discussions are presented in
Section 5.
Section 6 concludes the paper. For clarity regarding the reminder of this paper, all acronyms adopted and used are provided in
Table A1 of
Appendix D.
2. Related Works
This section discusses briefly the fundamentals of CNN while analyzing the effects of optimizers on varying width and depth in deep neural networks and specifically on convolutional neural networks.
CNNs are deep learning algorithms that are widely used for image classification, image segmentation, and several other computer image tasks. They take in images and assign weights and biases to features of the input image. CNNs are popular because they require much lower pre-processing when compared to other image-classification algorithms. They have been employed in several image-processing tasks such as in detection of glaucoma [
15,
16], torsional evaluation of reinforced concrete beams [
17], concrete crack detection [
18], and other tasks.
Studies into how optimization algorithms impact the learning performance on varying depth and width in neural network models is a very active research area [
19,
20,
21]. These studies aim to try to understand such behaviors both through theoretical and empirical perspectives across numerous application-specific problems [
22]. In neural networks, model complexity has been achieved and analyzed by varying the network’s width and depth, or varying width while keeping depth constant, or vice versa [
21,
23]. However, this leads to an increasing number of parameters on one hand, but on the other hand achieves solutions that generalize well on training data, in contrast to the arguments in traditional statistical learning theory that increasing the number of parameters in machine-learning models will most likely overfit training data and therefore generalize poorly to unseen test data [
24]. The double descent risk curve proposed by [
20] sought to reconcile this apparent conflict in neural networks, where they observed that beyond the fitting threshold, the risk decreases as model complexity increases.
The authors [
25] analyzed the bias-variance effect of deep CNNs and observed that as depth increases, bias decreases greater than the increase in variance, and suggested the possibility for deeper networks to have increased risk.
The authors [
21] went further to critically analyze the effect of increasing depth on CNN test performance, specifically using ResNets and fully-convolutional networks model on CIFAR10 and the ImageNet32 dataset, while holding the network’s width constant. They observed that the test performance of the networks worsens when increasing network depth beyond a critical point, in contrast to increasing model complexity through width. They also suggested that double descent happens only through width and not through depth, and that deeper networks can have an increased risk of generalizing poorly to unseen data. They trained their models using ADAM, SGD and SGD with momentum optimizers.
In the work of [
22] the authors studied the effects of depth and width on the learned internally hidden representations, aimed at finding characteristics of the block structure in the hidden representations with varying network capacity of wider or deeper neural network models. They show that block structure arises when the model capacity is large relative to the size of the training dataset. They observed that the features learned by different models outside the block structure are often similar across architectures with varying widths and depths, but the block structure is unique to each model. Upon analyzing the prediction outputs of the different architectures, they concluded that even when the overall accuracy is similar, wide and deep models exhibit distinctive error patterns and variations across classes. The study was carried out using a family of ResNet models with varying depths and widths, and trained on CIFAR-10, CIFAR-100 and ImageNet datasets using SGD with momentum.
Other works such as [
26] studied the effect of depth on CNN models with two variations of depths, while the authors of [
27] examined the role of depth in CNNs, and another study [
28] studied optimization in deep CNNs where the authors observed that increasing depth increases representational power while increasing width smoothes the optimization landscape. A paper by [
19] looked at the potential pitfall of adaptive gradient methods finding solutions that generalize worse than SGD despite having the same training loss, and argued against the increasing use of adaptive gradient methods, specifically ADAM, by the deep learning community in all scenarios. The authors of that paper also observed that adaptive learning rate methods often exhibit faster initial progress during training, but their learning performance quickly reaches a critical saturation point on the test set. This has led to some researchers advocating the use of both adaptive methods such as ADAM at the initial stages of training and switching to non-adaptive SGD at a later stage to improve generalization [
29]. However, the works of [
30] observed that with sufficiently tuned hyperparameters, adaptive methods would never underperform momentum or SGD, while [
31] concludes that with sufficiently tuned hyperparameters, standard optimizers such as SGD and ADAM would never underperform state-of-art optimizers for large batch size settings. However, it all comes at the expense of higher computing costs. While all of these works acknowledged that optimizers do impact the performances of different neural network architectures across various theoretical and empirical settings, they did not provide an explicit connection on the effect that different optimizers have had on the increasing complexity of CNN architectures in terms of varying width, depth and width/depth, which is the focus of the current work.
Table 1 is a summary of the most relevant works referenced in this study in terms of the models, optimizers, image dataset used and their contributions.
3. Optimization Techniques
Optimizer is an important hyperparameter needed for training deep learning models They are broadly categorized into two for non-convex optimization problems, namely, non-adaptive learning rate (classical SGD), and adaptive learning rate optimization algorithms [
5,
32]. Although there is also a second-order optimization algorithm for convex problems, the main difference between convex and non-convex optimization problems is that for convex optimization problems there is only one global optimum, with no notion of local optima, whereas the non-convex optimization problem has multiple local optima across the neural network loss surface, with only one global optimum [
32]. The focus of this paper is on first-order optimization algorithms for non-convex problems. This is because non-convex optimization problems are the most prevalent in neural network research. The nature of the loss surface for non-convex problems determines the complexity and difficulty in locating the global optimum [
33]. An optimizer is therefore used to reduce the cost function which is calculated by cross-entropy, while the loss function is used to calculate the error which is the metric that indicates the efficiency of the model.
A brief overview of the examined optimizers is described as follows:
Non-adaptive SGD and its enhanced variants are based on the gradient descent approach. Gradient descent is a means to minimise an objective function
f (
x) parameterised by a model’s parameters
x ℝ, by updating the parameters in the opposite direction of the gradient of the objective function
with regard to the parameters reaching the local minimum which is determined by the learning rate [
3]. SGD uses a single training dataset, one row after another, and then followed by iteration adjustment of weights for each row. Oscillation because of stochastic noise in SGD is one of its problems, resulting from updates not capturing curvature information and thereby slowing down SGD when loss surface curvature is high. Momentum is a technique, when applied to SGD, that dampens these oscillations [
32,
34]. This is achieved by accelerating the gradient descent towards reducing the objective function across iterations through tailoring the accumulated velocity vector towards that objective. Given an objective function
f (
x)
, momentum is defined as [
9]:
where
= learning rate;
= momentum coefficient; and
= gradient at
xt; when
;
.
In SGD with momentum, the gradient-based velocity vector is first corrected/updated in the current position
, and then a big step is taken based on this new velocity vector value. In contrast, in SGD with Nesterov momentum, the first step is taken along the direction of the velocity and then correction and update to the velocity vector value is made based on the new location
. Hence, Nesterov momentum is given (taking into account the new velocity vector update) as [
9]:
ADAGrad was designed as an improvement to the non-adaptive SGD optimization when the gradient vectors are sparse, particularly in the online learning setting [
35]. Generally, with the overall objective of achieving faster convergence time [
11], most of the adaptive learning rate techniques developed over the years are variants of ADAGrad, as they seek to address some inherent and notable weaknesses in ADAGrad, such as the rapid decrease in the learning rate in non-convex settings due to the accumulated squared gradient over time [
11].
RMSProp is a modification of ADAGrad to improve performance in non-convex situations. It is based on the idea that dividing the vector gradient by the root mean square for each weight improves learning [
36].
ADAM combines the strengths of RMSProp and SGD with momentum [
37]. It uses the squared gradient method as in RSMProp for scaling the learning rate as well as the moving average of the gradient leveraging on momentum [
37]. ADAM also combines the advantages of ADAGrad and RMSProp, and works well in settings with sparse gradients and online settings [
35,
36]. This is the reason why ADAM can perform well across numerous problem domains and datasets.
ADADelta is a method developed to combat the issue with the accumulation of all past squared gradients in ADAGrad, which affects the learning rate by decreasing it towards zero and eventually terminating training. ADADelta is a remedy to prevent the continual decay of learning rates and to avoid the need to select the global learning rate manually [
37,
38].
ADAMax is a variation of ADAM that uses the L-infinity (
norm rule to update present and past gradients, resulting in stable behavior. Given a generalised
norm-based update rule, the ADAM algorithm becomes numerically unstable in situations for norms with large
values [
37].
NADAM is a combination of RMSProp and Nesterov momentum. It builds on the work of [
36] by incorporating Nesterov momentum into ADAM, rather than using only momentum to estimate the exponential moving average of the gradient [
39], and thus making NADAM an improved variant of ADAM.
A brief explanation of the optimizers update rule is provided in
Table 2:
6. Conclusions
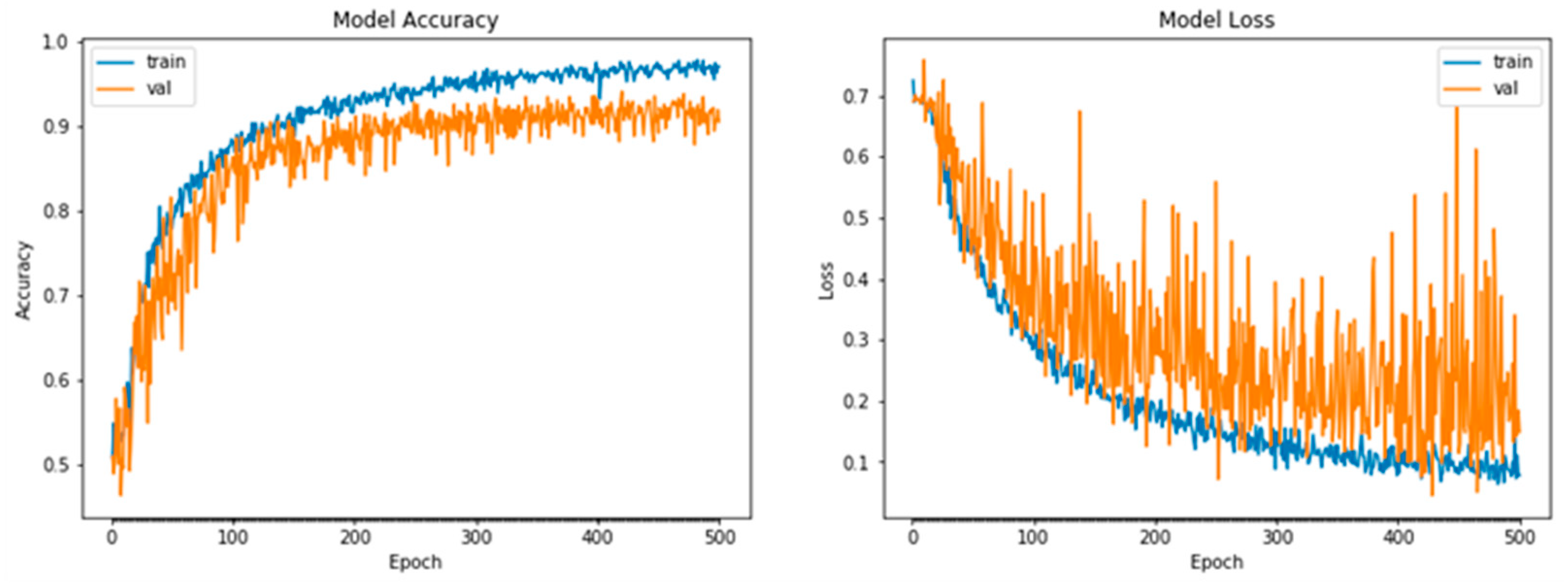
The objective of the paper was to assess the effects of different optimizers on varying depth and width of CNN architectures. To this end, we conducted an empirical comparison of nine stochastic gradient-based optimization algorithms against three simple CNN architectures of varying depth, width and depth/width, using three image classification dataset problems. Our study reveals that for the Cats and Dogs data problems, ADAM performed remarkably well, much better than its closest rival, NADAM, even though ADAM had a slightly higher convergence time. For the Natural Images data problem, NADAM consistently performed better across all the CNN models. Overall, the worst performer by far was ADADelta across all the models and datasets. For the Fashion MNIST data problem, NADAM was the better performer, but once again, with a slightly higher convergence time than its closest rival ADAM. On the whole, considering the three image classification datasets evaluated, ADAM and NADAM with wider or deeper/wider CNN models were the better performers in terms of accuracy, but at the expense of higher convergence time, while the deeper CNN models generally showed increased performance risk. In this paper, we only looked at three datasets, default settings for the optimizers, and simple CNN architectures. An interesting future direction to pursue is to consider several image classification dataset problems in terms of structure, size, and the number of classes, in addition to hyperparameter tuning of the optimizers and modern CNN architectures. It will also be of interest to investigate the effect of noise from the data images on the prediction accuracies of CNN models, and how robust the CNN models are against noise. However, from the initial results and empirical evidence obtained in this study, we suggest a careful balance between increasing depth and width during the design of deeper/wider CNN architectures, and to try ADAM, NADAM, ADAMax, and SGD with Nesterov momentum as a starting point for image classification problems.
































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


