

Vision Transformer in Industrial Visual Inspection


Abstract
:1. Introduction
2. Related Work
2.1. Transformer Models in NLP
2.2. Transformer Models in CV
2.3. Recent Visual Inspection Examples Utilizing Deep Learning
Model Selection Based on Benchmarks and Recent Applications
3. Learning Task Description
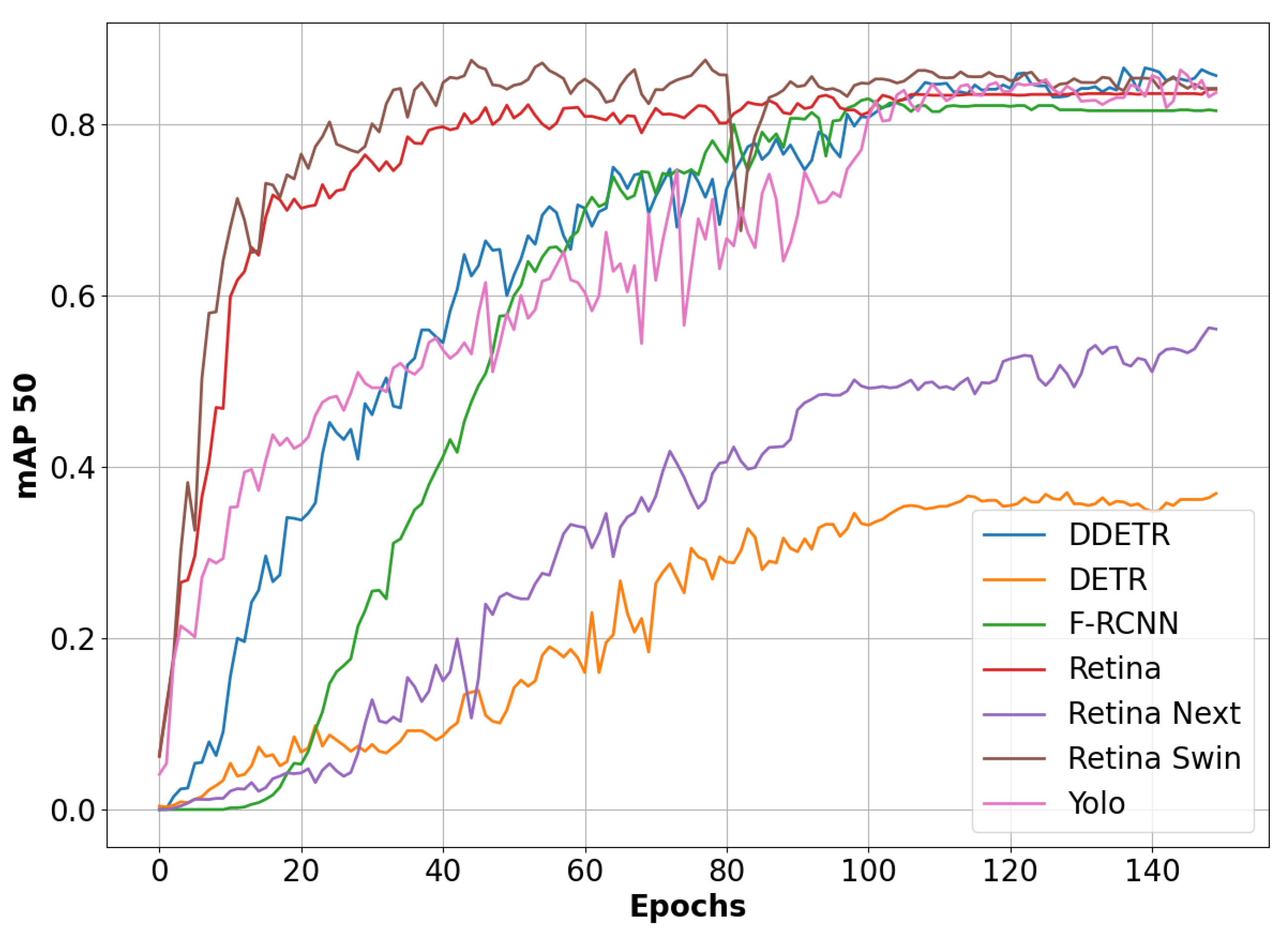
4. Experiments and Results
4.1. Experiment Settings
4.2. Results
4.2.1. Full Images
4.2.2. Sliding Window Approach
5. Conclusions and Outlook
- Perform better than typically used CNN models;
- Show no significant difference in convergence speed compared to CNNs;
- Handle small datasets commonly utilized in industrial VI well.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BERT | Bidirectional encoder representations from transformers |
| CNN | Convolutional neural network |
| COCO | Common objects in context (object detection) dataset |
| CR | Character recognition |
| CV | Computer vision |
| DETR | Detection transformer |
| DDETR | Deformable detection transformer |
| FLOPS | Floating-point operations per second |
| FPN | Feature pyramid network |
| F-RCNN | Faster regional convolutional neural network |
| GPU | Graphics processing unit |
| GPT | Generative Pre-trained Transformer |
| GRU | Gated recurrent unit |
| mAP | Mean average precision (Common object detection performance metric) |
| NLP | Natural language processing |
| NMS | Non-maximum suppression |
| Pascal VOC | Pascal visual object classes (object detection dataset) |
| RNN | Recurrent neural network |
| SM | Sheet metal |
| SOTA | State-of-the-art |
| VI | Visual inspection |
| WLS | Wooden load spaces |
| Yolo | You only look once (Object detection model) |
References
- Steger, C.; Ulrich, M.; Wiedemann, C. Machine Vision Algorithms and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Sheehan, J.J.; Drury, C.G. The analysis of industrial inspection. Appl. Ergon. 1971, 2, 74–78. [Google Scholar] [CrossRef] [PubMed]
- Swain, A.D.; Guttmann, H.E. Handbook of Human-Reliability Analysis with Emphasis on Nuclear Power Plant Applications; Final Report; Sandia National Labs.: Albuquerque, NM, USA, 1983. [Google Scholar] [CrossRef] [Green Version]
- Drury, C.G.; Fox, J.G. Human Reliability in Quality Control: Papers; Taylor & Francis: London, UK, 1975. [Google Scholar]
- Zheng, X.; Zheng, S.; Kong, Y.; Chen, J. Recent advances in surface defect inspection of industrial products using deep learning techniques. Int. J. Adv. Manuf. Technol. 2021, 113, 35–58. [Google Scholar] [CrossRef]
- Kalyan, K.S.; Rajasekharan, A.; Sangeetha, S. AMMUS: A Survey of Transformer-based Pretrained Models in Natural Language Processing. arXiv 2021, arXiv:2108.05542. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in Vision: A Survey. ACM Comput. Surv. 2022, 2, T2. [Google Scholar] [CrossRef]
- Xu, Y.; Wei, H.; Lin, M.; Deng, Y.; Sheng, K.; Zhang, M.; Tang, F.; Dong, W.; Huang, F.; Xu, C. Transformers in computational visual media: A survey. Comput. Vis. Media 2022, 8, 33–62. [Google Scholar] [CrossRef]
- Liu, H.; Miao, X.; Mertz, C.; Xu, C.; Kong, H. CrackFormer: Transformer Network for Fine-Grained Crack Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Wang, T.; Zhang, Z.; Yang, F.; Tsui, K.L. Automatic Rail Component Detection Based on AttnConv-Net. IEEE Sens. J. 2022, 22, 2379–2388. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Kitaev, N.; Kaiser, Ł.; Levskaya, A. Reformer: The Efficient Transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Wang, S.; Li, B.Z.; Khabsa, M.; Fang, H.; Ma, H. Linformer: Self-Attention with Linear Complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic Head: Unifying Object Detection Heads with Attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Xu, M.; Zhang, Z.; Hu, H.; Wang, J.; Wang, L.; Wei, F.; Bai, X.; Liu, Z. End-to-End Semi-Supervised Object Detection with Soft Teacher. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. arXiv 2017, arXiv:1703.06211. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar] [CrossRef]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. You Only Learn One Representation: Unified Network for Multiple Tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Zou, X.; Zeng, Z.; Cheng, Z.; Zhang, L.; Hoi, S.C.H. Exploring Structural Knowledge for Automated Visual Inspection of Moving Trains. IEEE Trans. Cybern. 2022, 52, 1233–1246. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Everingham, M.; van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Opara, J.N.; Thein, A.B.B.; Izumi, S.; Yasuhara, H.; Chun, P.J. Defect Detection on Asphalt Pavement by Deeplearning. Int. J. Geomate 2021, 21, 87–94. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. arXiv 2015, arXiv:1511.00561. [Google Scholar] [CrossRef]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. DeepCrack: Learning Hierarchical Convolutional Features for Crack Detection. IEEE Trans. Image Process. 2018, 28, 1498–1512. [Google Scholar] [CrossRef]
- König, J.; Jenkins, M.; Mannion, M.; Barrie, P.; Morison, G. Optimized Deep Encoder-Decoder Methods for Crack Segmentation. Digit. Signal Process. 2021, 108, 102907. [Google Scholar] [CrossRef]
- Chen, J.; Liu, Z.; Wang, H.; Nunez, A.; Han, Z. Automatic Defect Detection of Fasteners on the Catenary Support Device Using Deep Convolutional Neural Network. IEEE Trans. Instrum. Meas. 2018, 67, 257–269. [Google Scholar] [CrossRef]
- Sun, X.; Gu, J.; Huang, R.; Zou, R.; Giron Palomares, B. Surface Defects Recognition of Wheel Hub Based on Improved Faster R-CNN. Electronics 2019, 8, 481. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Lyu, Y.; Wang, L.; Han, Z. Detection Approach Based on an Improved Faster RCNN for Brace Sleeve Screws in High-Speed Railways. IEEE Trans. Instrum. Meas. 2020, 69, 4395–4403. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv 2016, arXiv:1611.05431. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. UP-DETR: Unsupervised Pre-training for Object Detection with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin Transformer V2: Scaling up Capacity and Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Yang, J.; Li, C.; Zhang, P.; Dai, X.; Xiao, B.; Yuan, L.; Gao, J. Focal Self-attention for Local-Global Interactions in Vision Transformers. arXiv 2021, arXiv:2107.00641. [Google Scholar]
- Dai, Z.; Liu, H.; Le V, Q.; Tan, M. CoAtNet: Marrying Convolution and Attention for All Data Sizes. Adv. Neural Inf. Process. Syst. 2021, 34, 3965–3977. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Bao, J.; Yao, Z.; Dai, Q.; Hu, H. SimMIM: A Simple Framework for Masked Image Modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Damage Type | Number of Occurences |
|---|---|
| Load support bearing | 8 |
| Damaged wooden filling | 56 |
| Damaged board | 206 |
| Task | # Images | # Annotations | # Classes | Input Size (w, h) | Step Size |
|---|---|---|---|---|---|
| Sheet metal flooring | 192 | 394 | 1 | (3072, *) | - |
| Sheet metal flooring, | |||||
| windowed | 219 | 223 | 1 | (1024, 1024) | 800, 800 |
| Wooden load space | 156 | 255 | 3 | (3072, *) | - |
| Wood load space, | |||||
| windowed | 746 | 957 | 3 | (512, 1024) | 400, 400 |
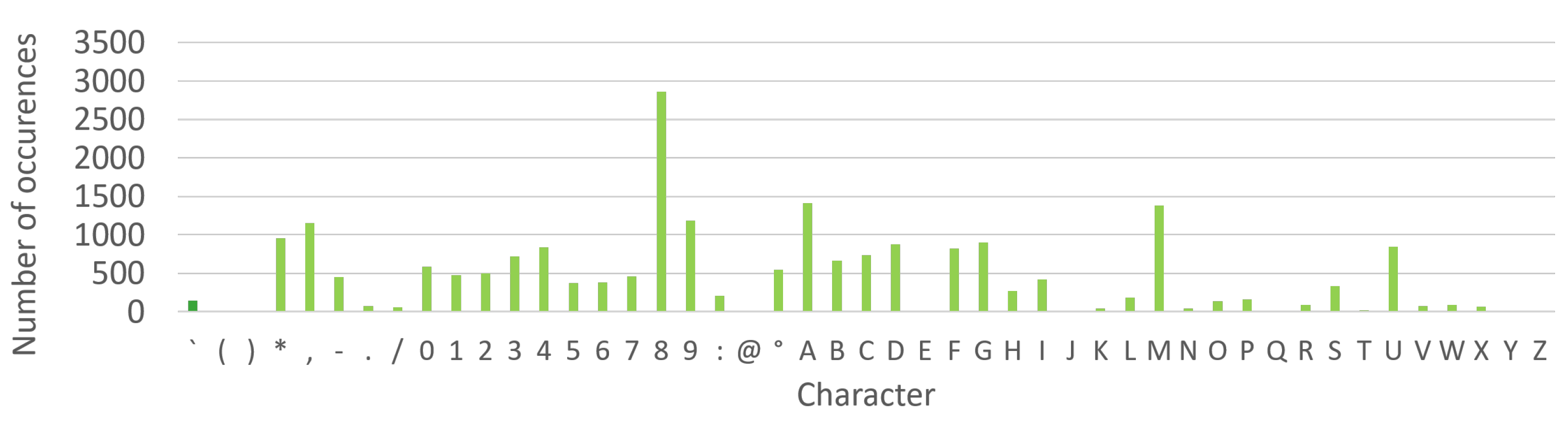
| Characters | 200 | 21.571 | 43 | (3072, *) | - |
| Characters, | |||||
| windowed | 1871 | 27.81 | 43 | (1024, 1024) | 800, 800 |
| Model | Epoch | Batch Size | IoU | ||||
|---|---|---|---|---|---|---|---|
| Sheet metal | DDETR | 120 | 1 × 8 | 0.699 | 0.640 | 0.704 | 0.25 |
| DETR | 130 | 1 × 8 | 0.061 | 0.098 | 0.164 | 0.1 | |
| F-RCNN | 80 | 5 × 8 | 0.245 | 0.340 | 0.472 | 0.2 | |
| Retina | 100 | 20 × 8 | 0.511 | 0.645 | 0.813 | 0.1 | |
| Yolo V3 | 120 | 3 × 8 | 0.595 | 0.574 | 0.713 | 0.2 | |
| RetinaNext | 150 | 2 × 8 | 0.112 | 0.240 | 0.380 | 0.2 | |
| Retina Swin | 130 | 2 × 8 | 0.532 | 0.705 | 0.791 | 0.25 | |
| Wooden load space | DDETR | 110 | 1 × 8 | 0.414 | 0.491 | 0.526 | 0.25 |
| DETR | 110 | 1 × 8 | 0.047 | 0.135 | 0.157 | 0.4 | |
| F-RCNN | 70 | 5 × 8 | 0.393 | 0.415 | 0.453 | 0.3 | |
| Retina | 60 | 7 × 8 | 0.389 | 0.475 | 0.644 | 0.2 | |
| Yolo V3 | 150 | 2 × 8 | 0.522 | 0.531 | 0.571 | 0.3 | |
| RetinaNext | 150 | 2 × 8 | 0.056 | 0.195 | 0.244 | 0.4 | |
| Retina Swin | 70 | 2 × 8 | 0.335 | 0.407 | 0.556 | 0.1 | |
| Sheet metal window | DDETR | 150 | 4 × 8 | 0.998 | 0.927 | - | - |
| DETR | 130 | 4 × 8 | 0.886 | 0.833 | - | - | |
| F-RCNN | 120 | 18 × 8 | 0.931 | 0.826 | 0.913 | 0.3 | |
| Retina | 60 | 7 × 8 | 0.938 | 0.913 | - | - | |
| Yolo V3 | 80 | 12 × 8 | 0.895 | 0.872 | - | - | |
| RetinaNext | 150 | 6 × 8 | 0.727 | 0.773 | 0.818 | - | |
| Retina Swin | 70 | 6 × 8 | 0.899 | 0.870 | 0.913 | 0.4 | |
| Wooden load space window | DDETR | 150 | 6 × 8 | 0.928 | 0.878 | 0.898 | 0.3 |
| DETR | 150 | 6 × 8 | 0.433 | 0.613 | 0.639 | 0.2 | |
| F-RCNN | 110 | 24 × 8 | 0.926 | 0.887 | 0.906 | 0.4 | |
| Retina | 100 | 28 × 8 | 0.942 | 0.913 | 0.922 | 0.4 | |
| Yolo V3 | 110 | 14 × 8 | 0.862 | 0.779 | 0.802 | 0.4 | |
| RetinaNext | 150 | 6 × 8 | 0.498 | 0.759 | 0.802 | 0.1 | |
| Retina Swin | 70 | 6 × 8 | 0.949 | 0.907 | 0.927 | 0.3 | |
| Character recognition window | DDETR | 150 | 6 × 8 | 0.676 | 0.779 | 0.912 | 0.2 |
| DETR | 150 | 10 × 8 | 0.383 | 0.522 | 0.616 | 0.2 | |
| F-RCNN | 140 | 18 × 8 | 0.62 | 0.764 | 0.879 | 0.1 | |
| Retina | 70 | 20 × 8 | 0.581 | 0.744 | 0.821 | 0.1 | |
| Yolo V3 | 120 | 10 × 8 | 0.621 | 0.776 | 0.885 | 0.1 | |
| RetinaNext | 150 | 6 × 8 | 0.492 | 0.725 | 0.788 | 0.2 | |
| Retina Swin | 90 | 6 × 8 | 0.617 | 0.773 | 0.885 | 0.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hütten, N.; Meyes, R.; Meisen, T. Vision Transformer in Industrial Visual Inspection. Appl. Sci. 2022, 12, 11981. https://doi.org/10.3390/app122311981
Hütten N, Meyes R, Meisen T. Vision Transformer in Industrial Visual Inspection. Applied Sciences. 2022; 12(23):11981. https://doi.org/10.3390/app122311981
Chicago/Turabian StyleHütten, Nils, Richard Meyes, and Tobias Meisen. 2022. "Vision Transformer in Industrial Visual Inspection" Applied Sciences 12, no. 23: 11981. https://doi.org/10.3390/app122311981
APA StyleHütten, N., Meyes, R., & Meisen, T. (2022). Vision Transformer in Industrial Visual Inspection. Applied Sciences, 12(23), 11981. https://doi.org/10.3390/app122311981