
An Energy-Efficient Convolutional Neural Network Processor Architecture Based on a Systolic Array

 ,
, 
Abstract
:1. Introduction
2. System Architecture
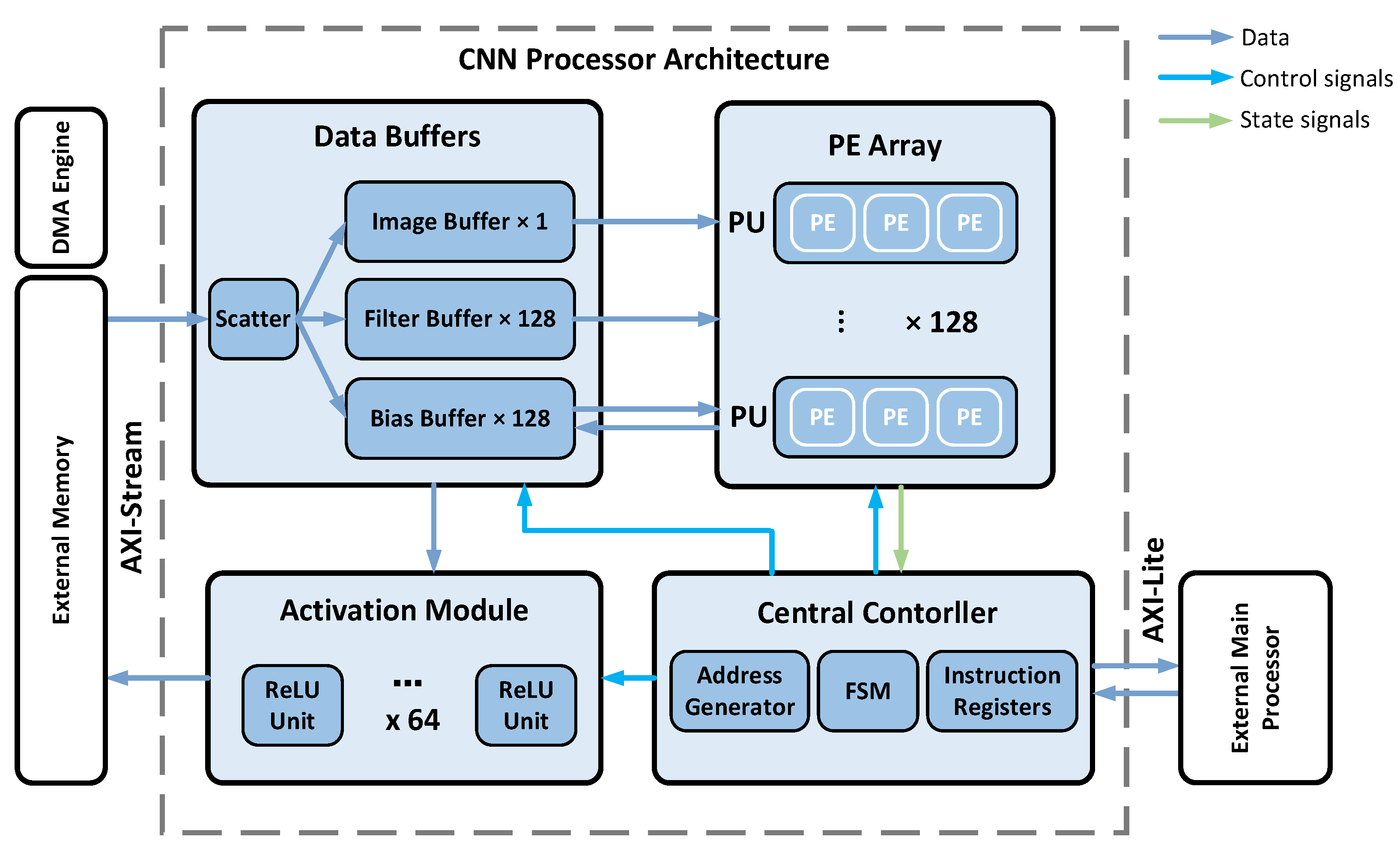
2.1. Overall Architecture of the Processor
2.2. Systolic Array-Based Computing Strategy
psum01 = i_row1 ∗ w_row1 + psum00,
p_row0 = psum02 = i_row2 ∗ w_row2 + psum01,
psum01ch2 = i_row1ch2 ∗ w_row1ch2 + psum00ch2,
p_row0ch2 = psum02ch2 = i_row2ch2 ∗ w_row2ch2 + psum01ch2
2.3. Analysis of the Configurability of the Systolic Array
- (1)
- Configurable image size: We can simply realize the configuration of the image size in the systolic array by broadcasting the image rows with different lengths to the PEs without changing the hardware structure.
- (2)
- Configurable filter size: We note that the number of PEs in the above systolic array is required to be equal to the size of the filters. For example, a systolic array with three PEs cannot complete the convolution with the filter size of five in one computing process due to an insufficient number of PEs. We can solve this problem by performing two computing processes, as shown in Figure 7. The processing sequence is horizontally split into upper and lower parts. The upper part completes the convolution of the first three weight rows, and the output intermediate values are stored in FIFO2. The lower part completes the convolution of the last two weight rows, the intermediate values stored in FIFO2 are regarded as the bias values in this process.
- (3)
- Configurable 3D convolution: The convolution with multiple input channels discussed in Section 2.2 is limited to the computing of one output feature map. One systolic array can complete the convolution with multiple filters serially if the time overhead is not considered. A more common method is to expand the number of systolic arrays to support parallel computing between filters, i.e., between the output feature map channels, and the operation throughput increases accordingly with the number of systolic arrays.
- (4)
- Fully connected computation: The fully connected computation can be regarded as a special kind of convolution due to the input image size being equal to the filter size, which can be completed by configuring the systolic array to reuse some of the PEs. For an output neuron result, only the first PE in the systolic array is needed to perform the multiplication of the image values and the weight values and accumulate the product. The operation can be expressed as follows:where OUTn denotes the n-th output neuron; H, W and C denote the height, width and number of channels of the input image, respectively; and ij and w[n]j denotes the j-th data of the input image and the j-th weight value of the n-th filter, respectively. Similar to convolution, fully connected computation can also use multiple systolic arrays to compute output neurons in parallel.
2.4. Analysis of the Low Power design
- (1)
- Hardware overhead: According to the feature of dataflows, we can summarize acceleration into the following three categories: weight stationary (WS) [6,10,11,14], row stationary (RS) [3] and output stationary (OS) [4,5]. We take the convolution with image size = 5 and filter size = 3 as an example to evaluate the number of PEs required for each computing strategy. The WS architecture needs nine PEs due to each weight value being fixed on one PE. In the RS strategy, a 2D convolution is decomposed into many 1D convolution primitives, and each PE completes its corresponding single 1D convolution primitive, so it occupies nine PEs to meet the needs of computing. The OS architecture adopts the strategy that each PE completes the computation of a fixed output feature map value, which needs nine PEs if segmentation is not applied. The proposed strategy based on a systolic array is somewhat similar to the RS. The difference is that each PE completes all 1D convolution primitives of one weight row, so PEs are reused, and only three PEs are required to complete the 2D convolution of the example, and the power decreases accordingly with fewer PEs.
- (2)
- Data reuse: Supposing a PE array contains N systolic arrays composed of three PEs, since image rows are broadcast to all PEs simultaneously, image values can be reused 3 × N times. In practical applications, it is usual to use register files (RF) to temporarily store the weight rows read from SRAM for each PE in the systolic array to realize local data reuse. The weight values in RF are updated after the convolution of the current channel is completed, so the weight values are reused by (image size—filter size)/step + 1 times. In other words, it is equal to the number of rows of the output feature map. The data reuse mentioned above can effectively reduce the number of memory access, thus achieving low power in computing.
2.5. Working Process of the Processor
3. System Modules
3.1. PE and PU
3.2. Data Buffers System
- (1)
- Image buffer: The image buffer is used to transfer image data to the PE array. It consists of two levels of memory. The first level is SRAM, which can store up to 1 Mbit of image values. The second level are the register files (RF), implemented by distributed storage, which stores one image row. Compared with SRAM, RF has lower power per bit access and can, therefore, reuse image values with less energy. The data read from RF is broadcast to all PEs, and the address generator produces the read address of RF. For example, if the length of an image row is 5, the read address sequence is 1-2-3-2-3-4-3-4-5 when the convolution step is 1.
- (2)
- Filter buffer: Each PU has its corresponding filter buffer, which contains three sub-buffers that provide weight values to the three PEs in the PU, respectively. The sub-filter buffer also includes SRAM and RF, which can store 32 kbit weight values. Each sub-filter buffer stores one weight row in each channel of the filters that is assigned to this buffer. For example, for one conventional layer with 256 filters with a size of 3 × 3 and channels with a size of 4, each sub-filter buffer will store (256/128) × 4 = 8 weight rows, i.e., 8 × 3 = 24 values. Similar to the image data, the RF stores one row of weight values used in the current computation to achieve low power data reuse. The read addresses of all filter buffers are consistent, so only one address generator is required.
- (3)
- Bias buffer: The bias buffer is used to transmit bias values to the PE array and temporarily store the partial sum and the results of operation. Each PU has its corresponding bias buffer, which is composed of FIFO. There are two main reasons for this design: (1) since the computation of each output feature map only needs to add the initial bias values once, the initial bias values will no longer be used in the subsequent operation after the convolution of the first channel; and (2) according to the proposed computing strategy, the i-th psum row produced by the last channel convolution will be used as the bias values in the computation of the i-th psum row of the next channel convolution, which is consistent with the first-in-first-out rule of FIFO.
3.3. Activation Module
3.4. Central Controller
4. Hardware Implementation and Evaluation
4.1. Image Segmentation Strategy
C × (M/N) × K × 16 bit < filterbuf_cap,
(L − K + 1) × (W − K + 1) × (M/N) × 16 bit < biasbuf_cap
NW = ROUNDUP((W − K + 1)/(W’ − 2)),
NC = ROUNDUP((C − K + 1)/(C’ − 2))
4.2. Hardware Verification
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, C.-C.; Ding, Y.-C.; Chiu, C.-T.; Huang, C.-T.; Cheng, Y.-Y.; Sun, S.-Y.; Cheng, C.-H.; Kuo, H.-K. Real-Time Block-Based Embedded CNN for Gesture Classification on an FPGA. IEEE Trans. Circuits Syst. I Reg. Pap. 2021, 68, 4182–4193. [Google Scholar] [CrossRef]
- Chen, Y.-H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An Energy-Efficient Reconfigurable Processor for Deep Convolutional Neural Networks. IEEE J. Solid State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Du, Z.; Fasthuber, R.; Chen, T.; Ienne, P.; Li, L.; Luo, T.; Feng, X.; Chen, Y.; Temam, O. ShiDianNao: Shifting vision processing closer to the sensor. In Proceedings of the ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA), Portland, OR, USA, 13–17 June 2015; pp. 92–104. [Google Scholar]
- Yin, S.; Ouyang, P.; Tang, S.; Tu, F.; Li, X.; Zheng, S.; Lu, T.; Gu, J.; Liu, L.; Wei, S. A High Energy Efficient Reconfigurable Hybrid Neural Network Processor for Deep Learning Applications. IEEE J. Solid State Circuits 2018, 53, 968–982. [Google Scholar] [CrossRef]
- Wong, D.L.T.; Li, Y.; John, D.; Ho, W.K.; Heng, C.-H. An Energy Efficient ECG Ventricular Ectopic Beat Classifier Using Binarized CNN for Edge AI Devices. IEEE Trans. Bio. Circuits Syst. 2022, 16, 222–232. [Google Scholar] [CrossRef] [PubMed]
- Yiğit, E.; Özkaya, U.; Öztürk, Ş.; Singh, D.; Gritli, H. Automatic Detection of Power Quality Disturbance Using Convolutional Neural Network Structure with Gated Recurrent Unit. Mob. Info. Syst. 2021, 2021, 7917500. [Google Scholar] [CrossRef]
- Peemen, M.; Setio, A.A.A.; Mesman, B.; Corporaal, H. Memory-centric processor design for Convolutional Neural Networks. In Proceedings of the 2013 IEEE 31st International Conference on Computer Design (ICCD), Asheville, NC, USA, 6–9 October 2013; pp. 13–19. [Google Scholar]
- Moon, S.; Lee, H.; Byun, Y.; Park, J.; Joe, J.; Hwang, S.; Lee, S.; Lee, Y. FPGA-Based Sparsity-Aware CNN Processor for Noise-Resilient Edge-Level Image Recognition. In Proceedings of the 2019 IEEE Asian Solid-State Circuits Conference (A-SSCC), Macau, China, 4–6 November 2019; pp. 205–208. [Google Scholar]
- Chang, X.; Pan, H.; Lin, W.; Gao, H. A Mixed-Pruning Based Framework for Embedded Convolutional Neural Network Acceleration. IEEE Trans. Circuits Syst. I Reg. Pap. 2021, 68, 1706–1715. [Google Scholar] [CrossRef]
- Chen, K.-C.; Huang, Y.-W.; Liu, G.-M.; Liang, J.-W.; Yang, Y.-C.; Liao, Y.-H. A Hierarchical K-Means-Assisted Scenario-Aware Reconfigurable Convolutional Neural Network. IEEE Trans. VLSI Syst. 2021, 29, 176–188. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Li, F.; Cheng, J. Block Convolution: Toward Memory-Efficient Inference of Large-Scale CNNs on FPGA. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2022, 41, 1436–1447. [Google Scholar] [CrossRef]
- Wang, J.; Fang, S.; Wang, X.; Ma, J.; Wang, T.; Shan, Y. High-Performance Mixed-Low-Precision CNN Inference Accelerator on FPGA. IEEE Micro. 2021, 41, 31–38. [Google Scholar] [CrossRef]
- Wu, X.; Ma, Y.; Wang, M.; Wang, Z. A Flexible and Efficient FPGA Accelerator for Various Large-Scale and Lightweight CNNs. IEEE Trans. Circuits Syst. I Reg. Pap. 2022, 69, 1185–1198. [Google Scholar] [CrossRef]
- Kim, T.-H.; Shin, J. A Resource-Efficient Inference Accelerator for Binary Convolutional Neural Networks. IEEE Trans. Circuits Syst. II Exp. Briefs 2021, 68, 451–455. [Google Scholar] [CrossRef]
- Nguyen, V.C.; Nakashima, Y. Analysis of Fully-Pipelined CNN Implementation on FPGA and HBM2. In Proceedings of the Ninth International Symposium on Computing and Networking Workshops (CANDARW), Matsue, Japan, 23–26 November 2021; pp. 134–137. [Google Scholar]
- Jiang, J.; Jiang, M.; Zhang, J.; Dong, F. A CPU-FPGA Heterogeneous Acceleration System for Scene Text Detection Network. IEEE Trans. Circuits Syst. II Exp. Briefs 2022, 69, 2947–2951. [Google Scholar] [CrossRef]
- Guo, Y.; Jiang, M.; Dong, F.; Yu, K.; Chen, K.; Qu, W.; Jiang, J. A CPU-FPGA Based Heterogeneous Accelerator for RepVGG. In Proceedings of the IEEE 14th International Conference on ASIC (ASICON), Kunming, China, 26–29 October 2021; pp. 1–4. [Google Scholar]
- Cavigelli, L.; Benini, L. Origami: A 803-GOP/s/W Convolutional Network Processor. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 2461–2475. [Google Scholar] [CrossRef] [Green Version]
- Sankaradas, M.; Jakkula, V.; Cadambi, S.; Chakradhar, S.; Durdanovic, I.; Cosatto, E.; Graf, H.P. A Massively Parallel Coprocessor for Convolutional Neural Networks. In Proceedings of the 2009 20th IEEE International Conference on Application-Specific Systems, Architectures and Processors, Boston, MA, USA, 7–9 July 2009; pp. 53–60. [Google Scholar]
- Luo, T.; Liu, S.; Li, L.; Wang, Y.; Zhang, S.; Chen, T.; Xu, Z.; Temam, O.; Chen, Y. DaDianNao: A Neural Network Supercomputer. IEEE Trans. Comput. 2017, 66, 73–88. [Google Scholar] [CrossRef]
- O’Leary, D.P. Systolic Arrays for Matrix Transpose and Other Reorderings. IEEE Trans. Comput. 1987, C–36, 117–122. [Google Scholar] [CrossRef]
- Qiu, S.; Xu, X.; Cai, B. FReLU: Flexible Rectified Linear Units for Improving Convolutional Neural Networks. In Proceedings of the 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1223–1228. [Google Scholar]
- Qiu, J.; Wang, J.; Yao, S.; Guo, K.; Li, B.; Zhou, E.; Yu, J.; Tang, T.; Xu, N.; Song, S.; et al. Going Deeper with Embedded FPGA Platform for Convolutional Neural Network. In Proceedings of the ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21 February 2016; pp. 26–35. [Google Scholar]
- Liang, Y.; Lu, L.; Xiao, Q.; Yan, S. Evaluating Fast Algorithms for Convolutional Neural Networks on FPGAs. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2020, 39, 857–870. [Google Scholar] [CrossRef]
- Li, X.; Huang, H.; Chen, T.; Gao, H.; Hu, X.; Xiong, X. A hardware-efficient computing engine for FPGA-based deep convolutional neural network accelerator. Microelectron. J. 2022, 128, 105547. [Google Scholar] [CrossRef]
- Guo, K.; Sui, L.; Qiu, J.; Yu, J.; Wang, J.; Yao, S.; Han, S.; Wang, Y.; Yang, H. Angel-Eye: A Complete Design Flow for Mapping CNN Onto Embedded FPGA. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2018, 37, 35–47. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | PE0 | FIFO0 | PE1 | FIFO1 | PE2 | FIFO2 |
|---|---|---|---|---|---|---|
| t0 | i_row0 ∗ w_row0 + b_row0 | psum00 | ||||
| t1 | i_row1 ∗ w_row0 + b_row1 | psum10 | i_row1 ∗ w_row1 + psum00 | psum01 | ||
| t2 | i_row2 ∗ w_row0 + b_row2 | psum20 | i_row2 ∗ w_row1 + psum10 | psum11 | i_row2 ∗ w_row2 + psum01 | psum02 (p_row0) |
| t3 | i_row3 ∗ w_row1 + psum20 | psum21 | i_row3 ∗ w_row2 + psum11 | psum12 (p_row1) | ||
| t4 | i_row4 ∗ w_row2 + psum21 | psum22 (p_row2) |
| Buffer | Bit Width (Bits) | Storage Structure | Capacity (Bits) | Number |
|---|---|---|---|---|
| Image Buffer | 16 | SRAM + RF | 1 M | 1 |
| Filter Buffer | 16 | 3 SRAM + 3 RF | 3 × 32 K | 128 |
| Bias Buffer | 16 | FIFO | 32 K | 128 |
| Registers | Address (In Hex) | Direction | Description |
|---|---|---|---|
| input_channel | 00 | Input | Number of input channels |
| output_channel | 04 | Input | Number of output channels |
| ifmap_size | 08 | Input | Input feature map size |
| filter_size | 0C | Input | Filter size |
| convfc_sel | 10 | Input | CONV/FC selection 1 |
| base_addr | 14 | Input | Image values base address |
| acc_start | 18 | Input | Operation start: f0000000 |
| complete_fb | 1C | Output | Operation completion feedback |
| CONV Layer | Image Size | L’ | NL | W’ | NW | C’ | NC |
|---|---|---|---|---|---|---|---|
| CONV1 | 224 × 224 × 3 | 34 | 7 | 34 | 7 | 3 | 1 |
| CONV2 | 224 × 224 × 64 | 34 | 7 | 34 | 7 | 64 | 1 |
| CONV3 | 112 × 112 × 64 | 34 | 4 | 34 | 4 | 64 | 1 |
| CONV4 | 112 × 112 × 128 | 34 | 4 | 34 | 4 | 128 | 1 |
| CONV5 | 56 × 56 × 128 | 22 | 3 | 22 | 3 | 128 | 1 |
| CONV6 | 56 × 56 × 256 | 22 | 3 | 22 | 3 | 256 | 1 |
| CONV7 | 56 × 56 × 256 | 22 | 3 | 22 | 3 | 256 | 1 |
| CONV8 | 28 × 28 × 256 | 18 | 2 | 18 | 2 | 128 | 2 |
| CONV9 | 28 × 28 × 512 | 18 | 2 | 18 | 2 | 128 | 4 |
| CONV10 | 28 × 28 × 512 | 18 | 2 | 18 | 2 | 128 | 4 |
| CONV11 | 14 × 14 × 512 | 14 | 1 | 14 | 1 | 128 | 4 |
| CONV12 | 14 × 14 × 512 | 14 | 1 | 14 | 1 | 128 | 4 |
| CONV13 | 14 × 14 × 512 | 14 | 1 | 14 | 1 | 128 | 4 |
| Reference | [24] | [25] | [26] | [27] | [2] | This Work |
|---|---|---|---|---|---|---|
| Platform | Zynq ZC706 | Zynq ZC706 | Zynq ZC706 | Zynq XC7Z020 | Arria 10 GX1150 | Zynq ZC706 |
| Frequency (MHz) | 150 | 166 | 200 | 214 | 240 | 150 |
| Technology | 28 nm | 28 nm | 28 nm | 28 nm | 20 nm | 28 nm |
| Precision | 16 bits fixed | 16 bits fixed | 16 bits fixed | 8 bits fixed | 16 bits fixed | 16 bits fixed |
| Throughput (GOP/s) | 136.97 | 201.1 | 107.9 | 84.3 | 968.03 | 115.2 |
| Power (W) | 9.63 | 9.4 | 6.23 | 3.5 | 40 | 3.8 |
| Energy EFF (GOP/s/W) | 14.22 | 21.39 | 17.32 | 24.09 | 24.20 | 30.32 |
| DSP Used | 900 | 900 | 448 | 571 | 3136 | 449 |
| DSP EFF (GOP/s/DSP) | 0.15 | 0.23 | 0.24 | 0.15 | 0.30 | 0.26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Wang, X.; Yong, S.; Zhang, Y.; Li, Q.; Wang, C. An Energy-Efficient Convolutional Neural Network Processor Architecture Based on a Systolic Array. Appl. Sci. 2022, 12, 12633. https://doi.org/10.3390/app122412633
Zhang C, Wang X, Yong S, Zhang Y, Li Q, Wang C. An Energy-Efficient Convolutional Neural Network Processor Architecture Based on a Systolic Array. Applied Sciences. 2022; 12(24):12633. https://doi.org/10.3390/app122412633
Chicago/Turabian StyleZhang, Chen, Xin’an Wang, Shanshan Yong, Yining Zhang, Qiuping Li, and Chenyang Wang. 2022. "An Energy-Efficient Convolutional Neural Network Processor Architecture Based on a Systolic Array" Applied Sciences 12, no. 24: 12633. https://doi.org/10.3390/app122412633