
A Location–Time-Aware Factorization Machine Based on Fuzzy Set Theory for Game Perception


Abstract
:1. Introduction
- We use location projection and time projection to extend a QoE dataset, which can mitigate sparse data. The method increases the number of records of services by projecting to the location vector and time vector directions of users and services. There is no additional information introduced into the method while extending the game QoE dataset.
- We construct a similarity calculation based on fuzzy set theory to ensure the robustness of LTFM. A membership module is introduced to enhance the positive feature interactions and reduce the negative feature interactions, ensuring robustness.
- We conduct several experiments on a real QoE dataset derived from experiments set up according to the ITU-T standard to evaluate the performance of the LTFM. The experimental results show that our proposed LTFM exhibits good performance, which performs better than existing methods in the accuracy and robustness of game QoE prediction.
2. Related Work
3. Problem Formulation and Algorithm
3.1. Problem Description
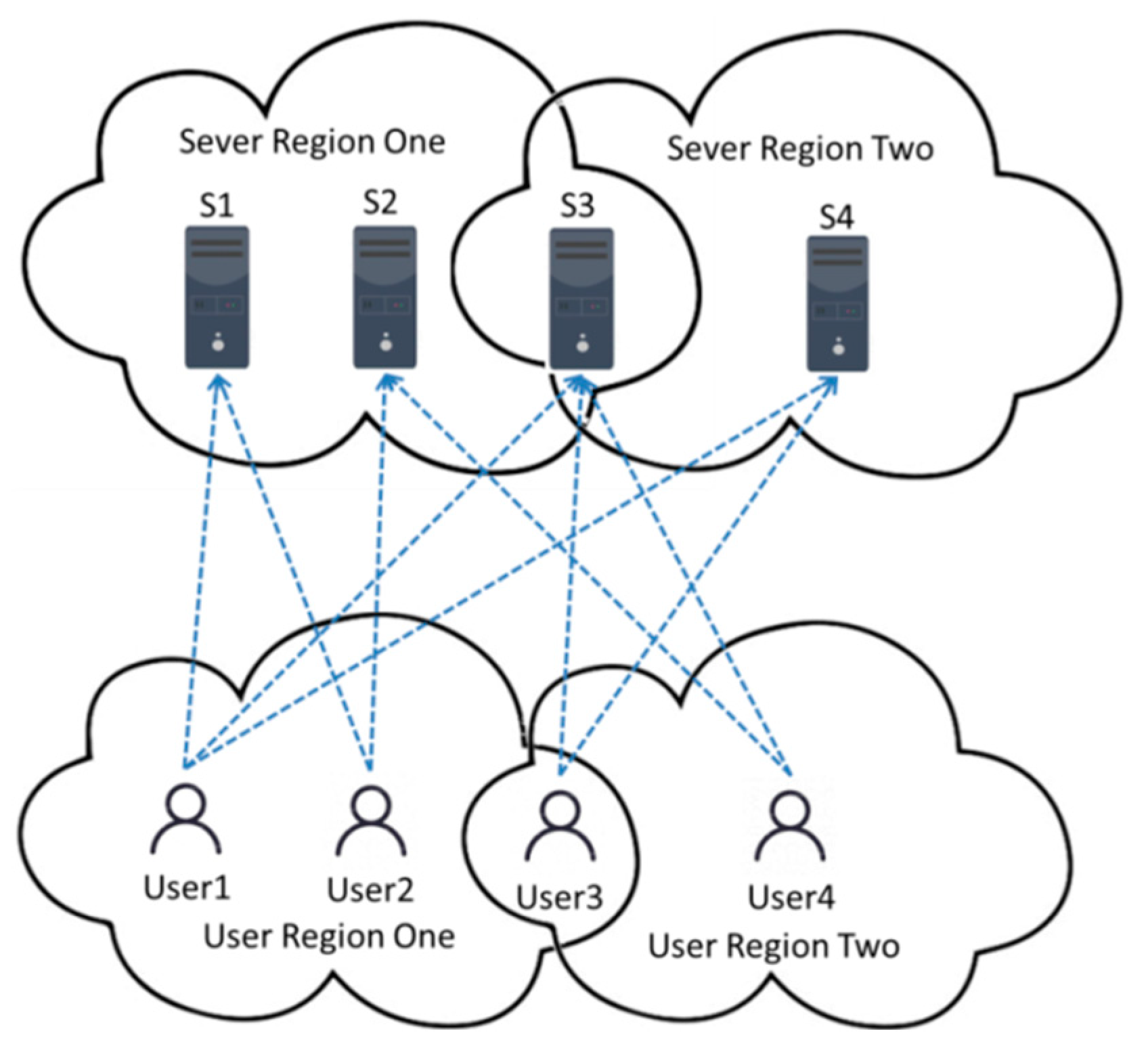
3.2. Location Information and Time Information
3.3. Similarity Calculation
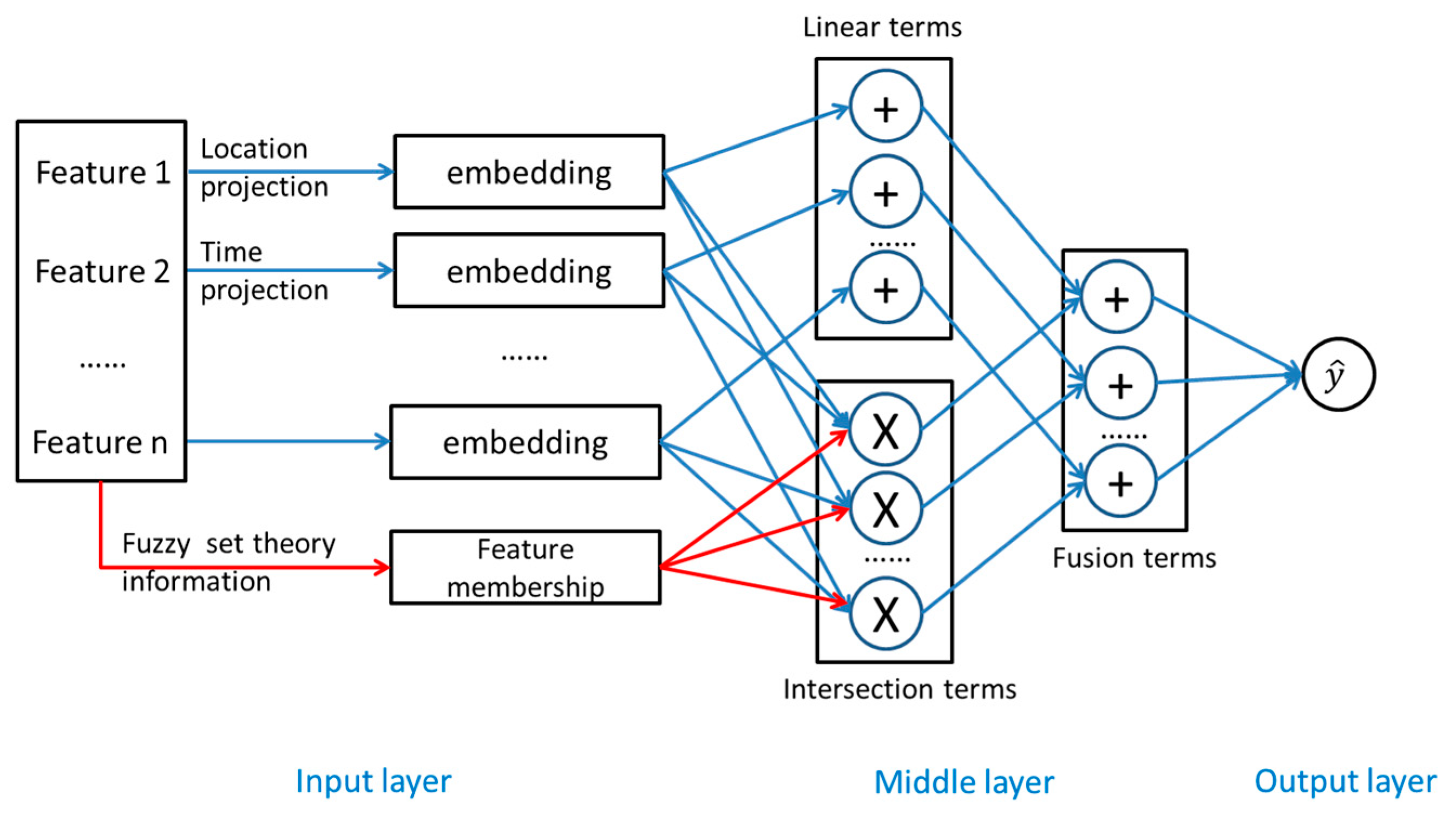
3.4. LTFM Based on Fuzzy Set Theory
4. Experiments and Results in Discussion
4.1. Research Data
4.2. Evaluation Metrics
4.3. Comparison Algorithm
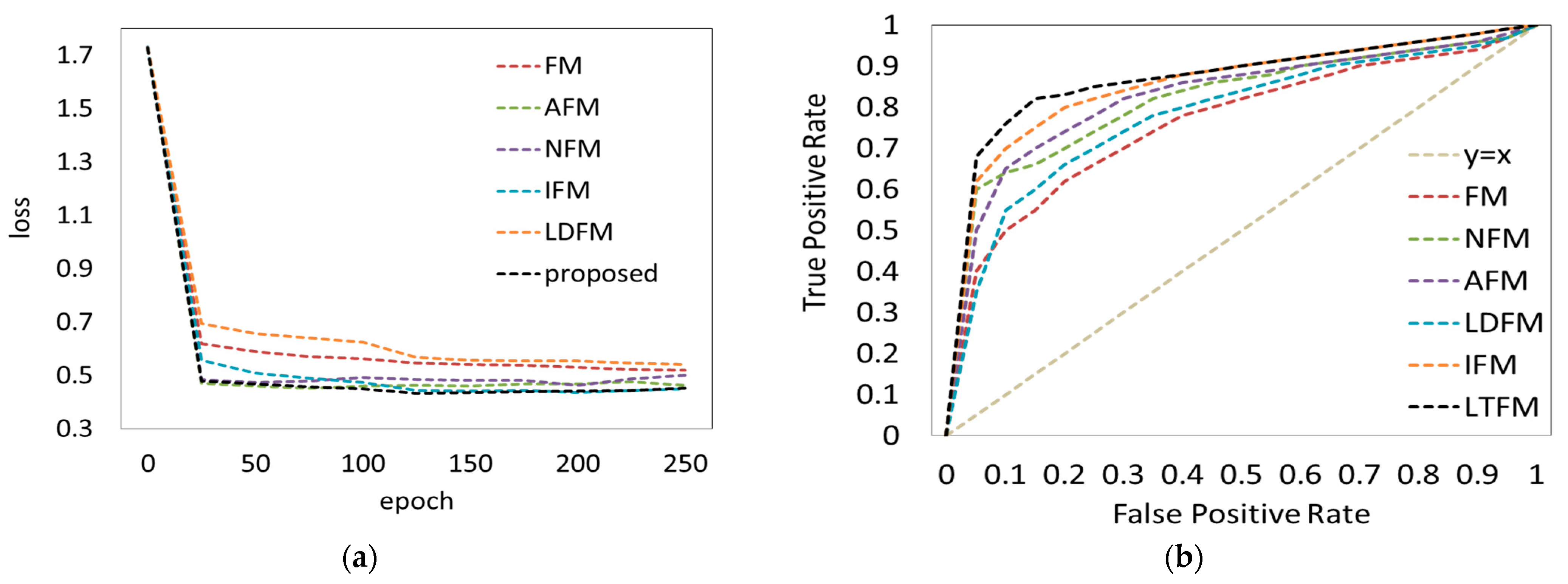
4.4. Experimental Analysis
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LTFM | Location-Time-Aware Factorization Machine |
| QoE | Quality of Experience |
| MOBA | Multiplayer Online Battle Arena |
| IUT-T | ITU-T for ITU Telecommunication Standardization Sector |
| QoS | Quality of Services |
| FM | Factorization Machine |
| NFM | Neural Factorization Machine |
| AFM | Attention Factorization Machine |
| EFMPred | embedding based factorization machine |
| LBFM | Location-based Factorization Machine |
| LANFM | leveraging location information Factorization Machine |
| IFM | Interaction Factorization Machine |
| LDFM | Location-based Deep Factorization Machine |
| User matrix | |
| Service matrix | |
| New service matrix after time and location projections |
References
- Bernhaupt, R. Evaluating User Experience in Games; Springer: London, UK, 2010; pp. 3–7. [Google Scholar]
- Takatalo, J.; Häkkinen, J.; Nyman, G. Game User Experience Evaluation; Springer International Publishing: Cham, Switzerland, 2015; pp. 87–111. [Google Scholar]
- Wattimena, A.F.; Kooij, R.E.; van Vugt, J.M.; Ahmed, O.K. Predicting the perceived quality of a first person shooter: The Quake IV G-model. In Proceedings of the 5th ACM SIGCOMM Workshop on Network and System Support for Games, Singapore, 30–31 October 2006; ACM Press: New York, NY, USA, 2006; p. 42-es. [Google Scholar]
- Koo, D.M.; Lee, S.H.; Chang, H.S. Experimental motives for playing online games. J. Converg. Inf. Technol. 2007, 2, 37–48. [Google Scholar]
- Denieffe, D.; Carrig, B.; Marshall, D.; Picovici, D. A Game Assessment Metric for the Online Gamer. Adv. Electr. Comput. Eng. 2007, 7, 3–6. [Google Scholar] [CrossRef]
- Pornpongtechavanich, P.; Wuttidittachotti, P.; Daengsi, T. QoE Modeling for Audiovisual Associated with MOBA Game Using Subjective Approach. Multimed. Tools Appl. 2022, 81, 37763–37779. [Google Scholar] [CrossRef] [PubMed]
- Suznjevic, M.; Skorin-Kapov, L.; Cerekovic, A.; Matijasevic, M. How to Measure and Model QoE for Networked Games?: A Case Study of World of Warcraft. Multimed. Syst. 2019, 25, 395–420. [Google Scholar] [CrossRef]
- Hong, F.-X.; Zheng, X.-L.; Chen, C.-C. Latent Space Regularization for Recommender Systems. Inf. Sci. 2016, 360, 202–216. [Google Scholar] [CrossRef]
- Rendle, S. Factorization Machines. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; IEEE: Sydney, Australia; pp. 995–1000. [Google Scholar]
- Wu, Y.; Xie, F.; Chen, L.; Chen, C.; Zheng, Z. An Embedding Based Factorization Machine Approach for Web Service QoS Prediction. In Proceedings of the International Conference on Service-Oriented Computing, Malaga, Spain, 13–16 November 2017; Springer International Publishing: Cham, Switzerland, 2017; Volume 10601, pp. 272–286. [Google Scholar]
- Yang, Y.; Zheng, Z.; Niu, X.; Tang, M.; Lu, Y.; Liao, X. A Location-Based Factorization Machine Model for Web Service QoS Prediction. IEEE Trans. Serv. Comput. 2021, 14, 1264–1277. [Google Scholar] [CrossRef]
- Chen, L.; Xie, F.; Zheng, Z.; Wu, Y. Predicting Quality of Service via Leveraging Location Information. Complexity 2019, 2019, 4932030. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, M.; Zhang, Y.; Zhong, J.; Sheng, V.S. Location-Based Deep Factorization Machine Model for Service Recommendation. Appl. Intell. 2022, 52, 9899–9918. [Google Scholar] [CrossRef]
- He, X.; Chua, T.-S. Neural Factorization Machines for Sparse Predictive Analytics. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; ACM: New York, NY, USA; pp. 355–364. [Google Scholar]
- Xiao, J.; Ye, H.; He, X.; Zhang, H.; Wu, F.; Chua, T.-S. Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; International Joint Conferences on Artificial Intelligence Organization: Melbourne, Australia, 2017; pp. 3119–3125. [Google Scholar]
- Hong, F.; Huang, D.; Chen, G. Interaction-Aware Factorization Machines for Recommender Systems. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Association for Computing Machinery: New York, NY, USA, 2019; Volume 33, pp. 3804–3811. [Google Scholar]
- Tang, M.; Jiang, Y.; Liu, J.; Liu, X. Location-Aware Collaborative Filtering for QoS-Based Service Recommendation. In Proceedings of the 2012 IEEE 19th International Conference on Web Services, Honolulu, HI, USA, 24–29 June 2012; IEEE: Honolulu, HI, USA, 2012; pp. 202–209. [Google Scholar]
- Tang, M.; Zhang, T.; Yang, Y.; Zheng, Z. QoS-aware web service recommendation based on factorization machines. Chin. J. Comput. 2018, 41, 1300–1313. [Google Scholar] [CrossRef]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.-S. Neural Collaborative Filtering. In Proceedings of the Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; International World Wide Web Conferences Steering Committee: Perth, Australia, 2017; pp. 173–182. [Google Scholar]
- Zhang, Y.; Schneider, J. Multi-Label Output Codes Using Canonical Correlation Analysis. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 11–13 April 2011. [Google Scholar]
- Harold, H. Breakthroughs in Statistics; Springer: New York, NY, USA, 1992; pp. 162–190. [Google Scholar]
- Zimmermann, H.-J. Fuzzy Set Theory: Fuzzy Set Theory. WIREs Comput. Stat. 2010, 2, 317–332. [Google Scholar] [CrossRef]
- Berkachy, R. Fundamental Concepts on Fuzzy Sets; Springer International Publishing: Cham, Switzerland, 2021; pp. 13–33. [Google Scholar]
- Nadin, M. Concepts and Fuzzy Logic. Int. J. Gen. Syst. 2012, 41, 860–867. [Google Scholar] [CrossRef]
- Scherer, R. Multiple Fuzzy Classification Systems; Springer: Berlin/Heidelberg, Germany, 2012; p. 288. [Google Scholar]
- Coufal, D. Radial Fuzzy Systems. Fuzzy Sets Syst. 2017, 319, 1–27. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhecsky, A.; Sutskever, I. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- ITU-T G. 100 AMD 1-2019; Vocabulary for Performance, Quality of Service and Quality of Experience Amendment 1 (Study Group 12). ITU-T: Geneva, Switzerland, 2019.
- Le Callet, P.; Möller, S.; Perkis, A. Qualinet White Paper on Definitions of Quality of Experience; European Network on Quality of Experience in Multimedia Systems and Services (COST Action IC 1003): Lausanne, Switzerland, 2013. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Time Period | Time Name |
|---|---|
| 2:00–10:00 | Idle time |
| 10:00–14:00 | Morning |
| 14:00–20:00 | Noon |
| 20:00–2:00 | Night |
| Feature | Data Type | Description | Factor Matrix |
|---|---|---|---|
| Player Id | Categorical | Participant number | Users |
| Sex | Binary | Participant sex | Users |
| Skill | Categorical | Skill level of participants | Users |
| Time | Numeric | End time of each game | Services |
| Game IP | Numeric | The IP address of the game server | Services |
| IP Home | Categorical | Home of game server | Services |
| Service Operator | Categorical | The operator of the game server | Services |
| Game Result | Binary | The final result of the game | Services |
| Game Mode | Categorical | Test the different game modes selected | Services |
| Game Team | Categorical | Team of participants entering the game | Services |
| Extra Delay | Numeric | Additional accumulated delay | Services |
| Extra Jitter | Numeric | Additional accumulated jitter | Services |
| Extra Packet Loss | Numeric | Additional accumulated packet loss | Services |
| Delay | Numeric | Total delay per game | Services |
| Jitter | Numeric | Total jitter per game | Services |
| Packet Loss | Numeric | Total packet loss per game | Services |
| Max-Min | Numeric | The difference between the best value of the total delay per game | Services |
| Kill | Numeric | Kill record in the game | Services |
| Death | Numeric | Death record in the game | Services |
| Assistant | Numeric | Assistant record in the game | Services |
| Score | Categorical | Game perception evaluation score | Label |
| Evaluation Metric | Formula |
|---|---|
| Precision | |
| Recall | |
| F-measure |
| Lr | AUC | Precision | Recall | F-Measure | Time (s) |
|---|---|---|---|---|---|
| 0.1 | 0.7572 | 0.7901 | 0.7975 | 0.776 | 16.225 |
| 0.3 | 0.7862 | 0.7842 | 0.7595 | 0.7867 | 14.15 |
| 0.5 | 0.7493 | 0.7903 | 0.7835 | 0.7848 | 14.4 |
| 0.01 | 0.8093 | 0.8328 | 0.8228 | 0.8178 | 16.4 |
| 0.03 | 0.7796 | 0.8235 | 0.7848 | 0.7867 | 15.025 |
| 0.05 | 0.7862 | 0.8089 | 0.7848 | 0.7837 | 15.025 |
| 0.001 | 0.7843 | 0.8256 | 0.7342 | 0.753 | 15.4 |
| 0.003 | 0.7777 | 0.8213 | 0.7468 | 0.7595 | 14.825 |
| 0.005 | 0.7701 | 0.827 | 0.7848 | 0.7735 | 15.25 |
| Model | AUC | Precision | Recall | F-Measure | Time (s) |
|---|---|---|---|---|---|
| RF | 0.7302 | 0.7385 | 0.7595 | 0.7444 | — |
| DTree | 0.722 | 0.7087 | 0.7215 | 0.7133 | — |
| MLP | 0.7422 | 0.7526 | 0.7608 | 0.7538 | — |
| Lightgbm | 0.7164 | 0.7197 | 0.7595 | 0.7283 | — |
| Xgboost | 0.7258 | 0.7324 | 0.7646 | 0.7428 | — |
| Catboost | 0.7319 | 0.7259 | 0.7722 | 0.7174 | — |
| Standard FM | 0.7549 | 0.7189 | 0.7215 | 0.7008 | 16.91 |
| NFM | 0.7721 | 0.7789 | 0.7595 | 0.7778 | 14.6 |
| AFM | 0.7862 | 0.8052 | 0.7848 | 0.7972 | 184.82 |
| IFM | 0.7908 | 0.8158 | 0.7975 | 0.801 | 56.31 |
| LDFM | 0.7288 | 0.796 | 0.7975 | 0.7802 | 18.24 |
| LTFM (time) | 0.8014 | 0.8207 | 0.7975 | 0.8010 | — |
| LTFM (time + location) | 0.8017 | 0.8259 | 0.8101 | 0.8069 | — |
| Proposed | 0.8093 | 0.8328 | 0.8228 | 0.8178 | 16.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, X.; Jia, Z.; Shi, H.; Zhu, X. A Location–Time-Aware Factorization Machine Based on Fuzzy Set Theory for Game Perception. Appl. Sci. 2022, 12, 12819. https://doi.org/10.3390/app122412819
Xie X, Jia Z, Shi H, Zhu X. A Location–Time-Aware Factorization Machine Based on Fuzzy Set Theory for Game Perception. Applied Sciences. 2022; 12(24):12819. https://doi.org/10.3390/app122412819
Chicago/Turabian StyleXie, Xiaoxia, Zhenhong Jia, Hongzhan Shi, and Xianxing Zhu. 2022. "A Location–Time-Aware Factorization Machine Based on Fuzzy Set Theory for Game Perception" Applied Sciences 12, no. 24: 12819. https://doi.org/10.3390/app122412819
APA StyleXie, X., Jia, Z., Shi, H., & Zhu, X. (2022). A Location–Time-Aware Factorization Machine Based on Fuzzy Set Theory for Game Perception. Applied Sciences, 12(24), 12819. https://doi.org/10.3390/app122412819