

A Cloud-Native Web Application for Assisted Metadata Generation and Retrieval: THESPIAN-NER †

 , , , , and
, , , , and
Abstract
:1. Introduction
2. Origin of the Work: A Cloud-Based Services for Cultural Heritage Science
- 1.
- First, we have the front-end, hosting an endpoint furnishing the HTML, CSS, and JavaScript (JS) bundle to be rendered in the client browser.
- 2.
- Secondly, we have the back end, offering a set of representational state transfer (REST)-ful APIs contactable via HTTP/2 protocol, for metadata/data upload and retrieval, and offering a set of tools, based on third-party APIs for metadata standardisation.
- 3.
- Lastly, we have MongoDB, a No-SQL database for storing the metadata entries.
THESPIAN-NER
- 1.
- generate custom THESPIAN-Mask queries; and
- 2.
- fill in THESPIAN-Mask metadata fields.
3. The Natural Language Processing Models
3.1. Training Datasets
- 1.
- a set of Italian archaeological written documents, most of them publications in scientific journals; and
- 2.
- a set of Italian internal scientific reports, produced during the last 15 years at INFN-LABEC in Florence (Laboratorio di tecniche nucleari applicate all’Ambiente e ai BEni Culturali, or the Laboratory of Nuclear Techniques for Environment and Cultural Heritage) [23].
3.2. Model Training and Evaluation
Discussion on the Training Results
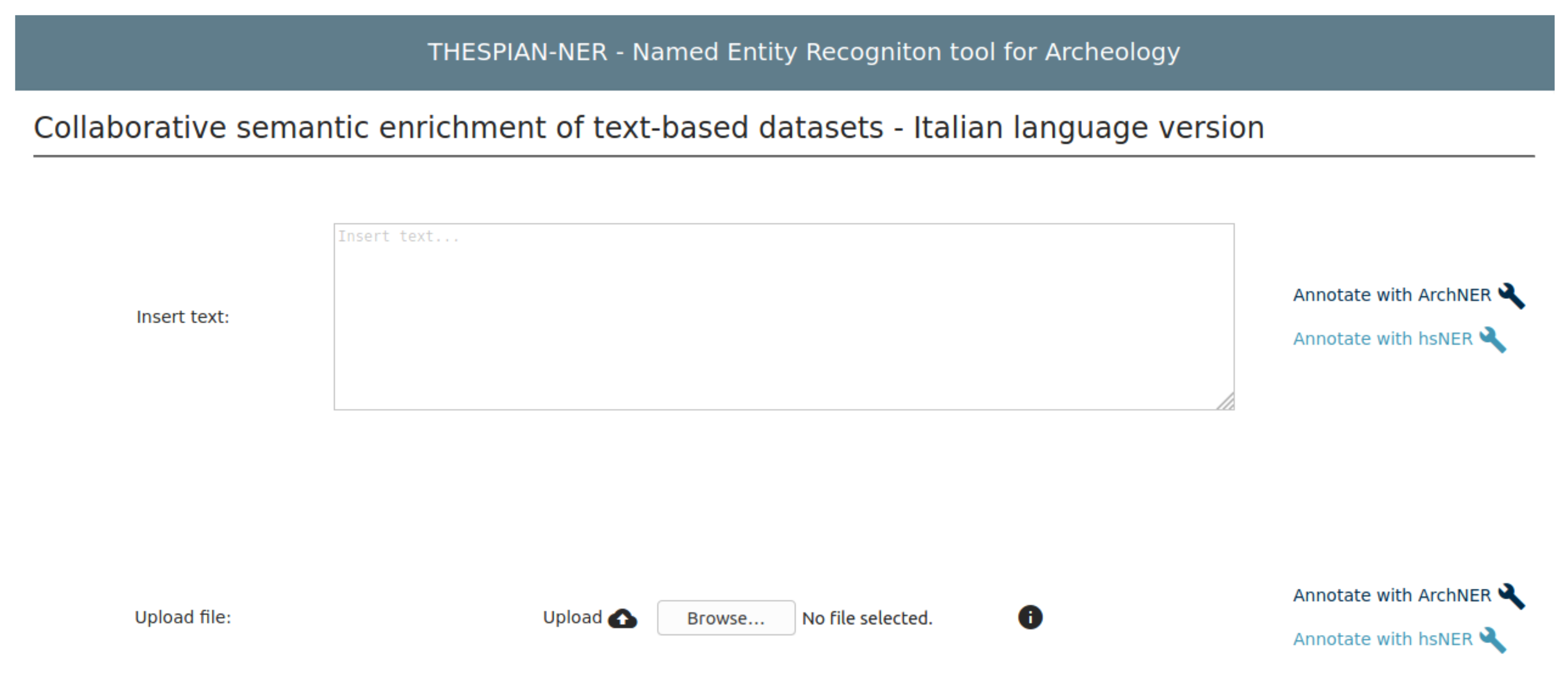
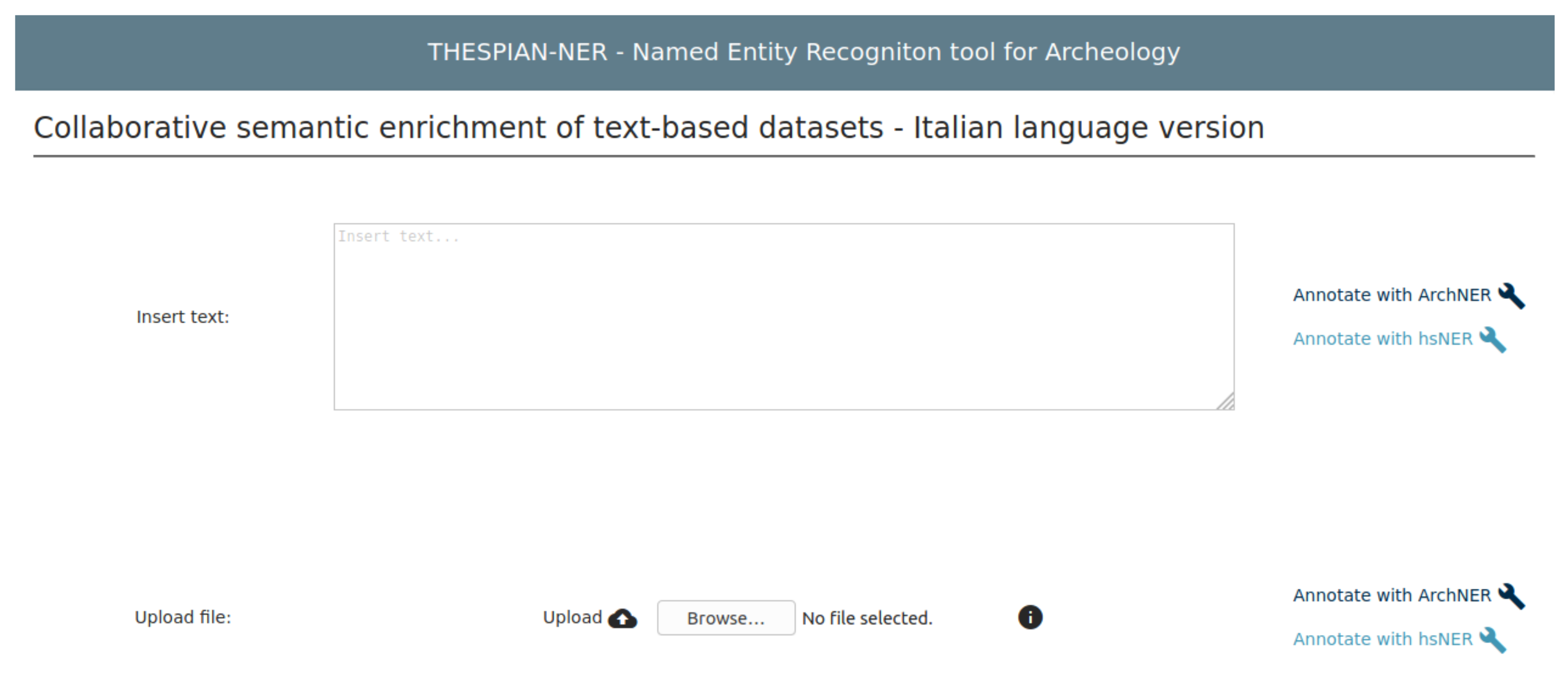
4. The Web Service Description: THESPIAN-NER
- 1.
- cast a query on the THESPIAN-Mask database;
- use a logic OR on the whole labels;
- use a stricter logic AND on the labels; or
- 2.
- generate a (semi)filled-in metadata mask and open it into the THESPIAN-Mask service.
4.1. (Semi)Automatic Query Creation

4.2. (Semi)Automatic Metadata Creation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 |
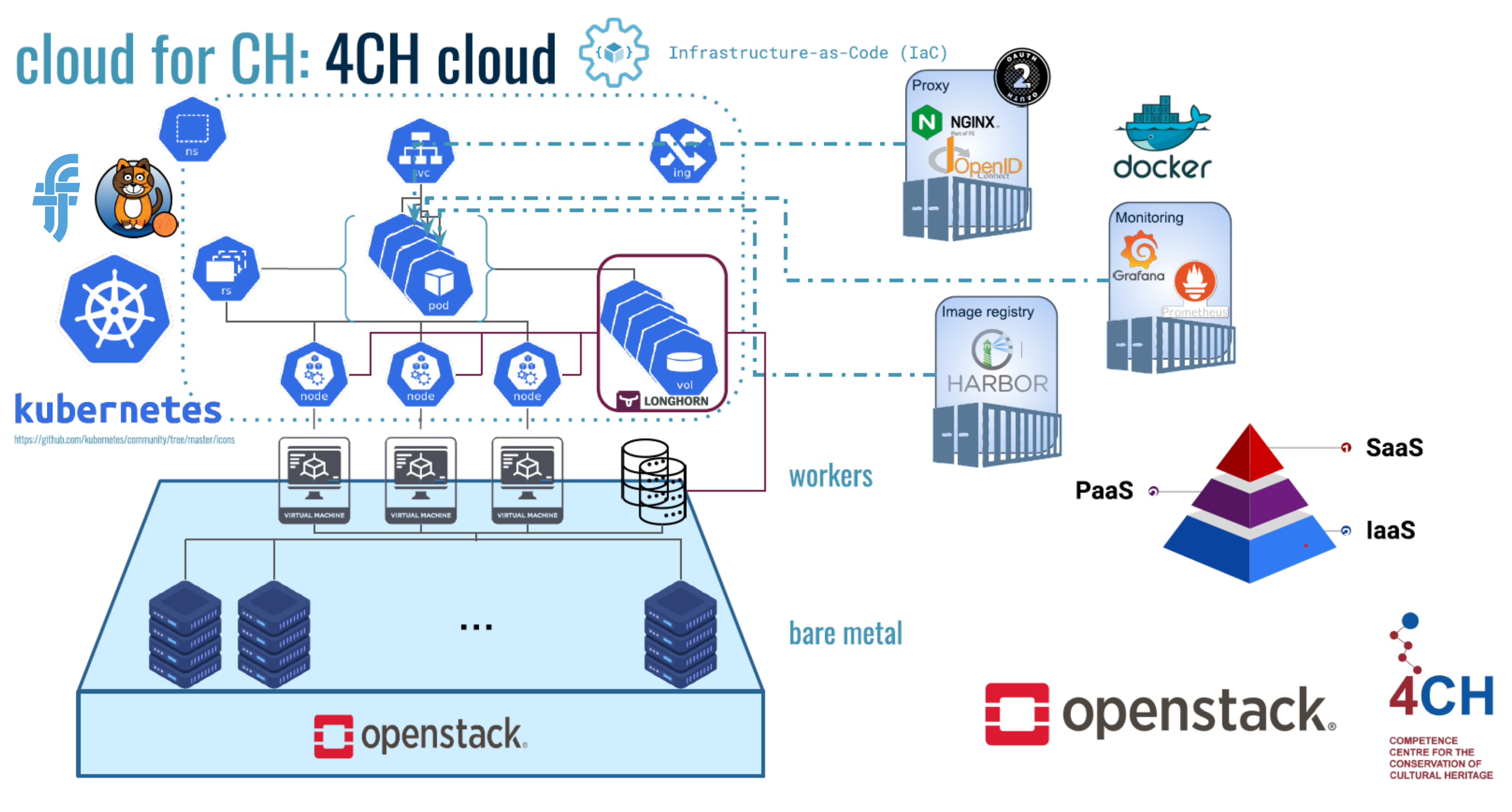
5. Cloud-Oriented Services for the 4CH Framework
5.1. The 4CH Cloud Platform: Design and Approach
5.2. The 4CH Cloud Platform Ancillary Services
Authentication/Authorisation Flow
Image Repository Service
Monitoring Service
5.3. THESPIAN-NER Integration in the 4CH Cloud
- 1.
- Users access the reverse proxy which replies with the platform homepage.
- 2.
- Registered users can perform the authentication procedure; they are redirected to the INDIGO-IAM service.
- 3.
- 4.
- Authenticated users can now access THESPIAN-NER.
- 4a.
- First, users reach NER service’s front end, which gives the the bundled HTML, CSS, and JS, forming the THESPIAN-NER web page. From THESPIAN-NER web page, users may contact the THESPIAN-NER back-end APIs (4b), the THESPIAN-NER back-end APIs (4c), and the THESPIAN-NER front end to get the web page (4c’), always through the reverse proxy.
- 4b.
- Users may send the text they want to elaborate, either to ArcheoNER API or hsNER API.
- 4c.
- Users may cast the (semi)automatically generated query by contacting the appropriate THESPIAN-Mask Back End API.
- 4c’.
- Users may contact the THESPIAN-Mask front-end endpoint, with the generated cookie containing the pre-filling information.
- 5.
- Upon success, the contacted API replies back with the appropriate response.
- 5b.
- The annotated text is sent back to users, together with a summarised text and a list of the labelled nominal entities found.
- 5c.
- The entries found after the query are returned as a JSON.
- 5c’.
- The prefilled page of the THESPIAN-Mask front-end application is opened.
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| INFN | Istituto Nazionale di Fisica Nucleare |
| CHNet | Cultural Heritage Network |
| CH | Cultural Heritage |
| FAIR | Findable, Accessible, Interoperable, Accessible |
| NLP | Natural Language Processing |
| NER | Named Entity Recognition |
| 4CH | Competence Centre for the Conservation of Cultural Heritage |
| CC | Competence Centre |
| EOSC | European Open Science Cloud |
| THESPIAN | Tools for HEritage Science Processing, Integration, and ANalysis |
| UX | User eXperience |
| IaaS | Infrastructure-as-a-Service |
| PaaS | Platform-as-a-Service |
| SaaS | Software-as-a-Service |
| IaC | Infrastructure-as-Code |
| ICT | Information and Communication Technology |
| JWT | JSON Web Token |
References
- Bechhofer, S.; De Roure, D.; Gamble, M.; Goble, C.; Buchan, I. Research Objects: Towards Exchange and Reuse of Digital Knowledge. Nat. Preced. 2010. [CrossRef]
- Roche, D.G.; Kruuk, L.E.; Lanfear, R.; Binning, S.A. Public data archiving in ecology and evolution: How well are we doing? PLoS Biol. 2015, 13, e1002295. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mons, B.; Neylon, C.; Velterop, J.; Dumontier, M.; da Silva Santos, L.O.B.; Wilkinson, M.D. Cloudy, increasingly FAIR; revisiting the FAIR Data guiding principles for the European Open Science Cloud. Inf. Serv. Use 2017, 37, 49–56. [Google Scholar] [CrossRef] [Green Version]
- The 4CH Project—Competence Centre for the Conservation of Cultural Heritage. Available online: https://www.4ch-project.eu/ (accessed on 14 October 2022).
- ARIADNEplus. Available online: https://ariadne-infrastructure.eu/ (accessed on 14 October 2022).
- Julian, R. D5.2 First Report on Data Infrastructure Update and Extension; Zenodo Digital Library, 2020. Available online: https://zenodo.org/record/4922749#.Y5wwsXbMJPZ (accessed on 1 October 2022). [CrossRef]
- European Open Science Cloud—Pillar. Available online: https://www.eosc-pillar.eu/ (accessed on 14 October 2022).
- Castelli, L.; Felicetti, A.; Proietti, F. Heritage Science and Cultural Heritage: Standards and tools for establishing cross-domain data interoperability. Int. J. Digit. Libr. 2019, 22, 279–287. [Google Scholar] [CrossRef]
- Bombini, A.; Castelli, L.; dell’Agnello, L.; Felicetti, A.; Giacomini, F.; Niccolucci, F.; Taccetti, F. CHNet cloud: An EOSC-based cloud for physical technologies applied to cultural heritages. In Proceedings of the Conferenza GARR 2021—Sostenibile/Digitale. Dati e Tecnologie per il Futuro, Online, 7–16 June 2021. [Google Scholar] [CrossRef]
- Bekiari, C.; Bruseker, G.; Doerr, M.; Oreand, C.E.; Stead, S.; Velios, A. CIDOC CRM; Version 7.1.1; Digital Library; International Committee for Documentation (CIDOC) of the International Council of Museums (ICOM): Paris, France, 2021. [Google Scholar] [CrossRef]
- OpenStreetMap Contributors. Planet Dump. 2017. Available online: https://www.openstreetmap.org (accessed on 14 October 2022).
- van Hooland, S.; De Wilde, M.; Verborgh, R.; Steiner, T.; Van de Walle, R. Exploring entity recognition and disambiguation for cultural heritage collections. Digit. Scholarsh. Humanit. 2013, 30, 262–279. [Google Scholar] [CrossRef] [Green Version]
- Mosallam, Y.; Abi-Haidar, A.; Ganascia, J.G. Unsupervised Named Entity Recognition and Disambiguation: An Application to Old French Journals. In Proceedings of the Advances in Data Mining. Applications and Theoretical Aspects, St. Petersburg, Russia, 16–20 July 2014; Perner, P., Ed.; Springer International Publishing: Cham, Switzerland, 2014; pp. 12–23. [Google Scholar] [CrossRef]
- van Dalen-Oskam, K.; de Does, J.; Marx, M.; Sijaranamual, I.; Depuydt, K.; Verheij, B.; Geirnaert, V. Named Entity Recognition and Resolution for Literary Studies. In Proceedings of the Computational Linguistics in the Netherlands Journal, Leiden, The Netherlands, 17 January 2014; Available online: https://hdl.handle.net/11245/1.504898 (accessed on 14 October 2022).
- Jain, N.; Krestel, R. Who is Mona L.? Identifying Mentions of Artworks in Historical Archives. In Proceedings of the Digital Libraries for Open Knowledge, Oslo, Norway, 9–12 September 2019; Doucet, A., Isaac, A., Golub, K., Aalberg, T., Jatowt, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 115–122. [Google Scholar] [CrossRef]
- Honnibal, M.; Johnson, M. An Improved Non-monotonic Transition System for Dependency Parsing. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 1373–1378. [Google Scholar]
- Honnibal, M.; Montani, I.; Honnibal, M.; Peters, H.; Landeghem, S.V.; Samsonov, M.; Geovedi, J.; Regan, J.; Orosz, G.; Kristiansen, S.L.; et al. Explosion/spaCy: V2.1.7: Improved Evaluation, Better Language Factories and Bug Fixes. Zenodo Digital Library. 2019. Available online: https://zenodo.org/record/3358113/export/hx#.Y5vH6X1BxPY (accessed on 5 October 2022). [CrossRef]
- Montani, I.; Honnibal, M.; Landeghem, S.V.; Boyd, A.; Peters, H.; McCann, P.O.; Samsonov, M.; Geovedi, J.; O’Regan, J.; Orosz, G.; et al. Explosion/spaCy: V3.1.4: Python 3.10 Wheels and Support for AppleOps; Zenodo Digital Library, 2021. Available online: https://zenodo.org/record/5617894#.Y5vICX1BxPY (accessed on 12 October 2022). [CrossRef]
- Honnibal, M.; Montani, I.; Van Landeghem, S.; Boyd, A. spaCy: Industrial-Strength Natural Language Processing in Python; Zenodo Digital Library, 2020. Available online: https://zenodo.org/record/7437997#.Y5vIDX1BxPY (accessed on 6 October 2022). [CrossRef]
- Bosco, C.; Lenci, A.; Montemagni, S.; Simi, M. Universal Dependencies 2.9—Italian Corpus; LINDAT/CLARIAH-CZ Digital Library at the Institute of Formal and Applied Linguistics (ÚFAL), Faculty of Mathematics and Physics, Charles University: Prague, Czechia, 2021. [Google Scholar]
- Bosco, C.; Montemagni, S.; Simi, M. Converting Italian Treebanks: Towards an Italian Stanford Dependency Treebank. In Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse, Sofia, Bulgaria, 8–9 August 2013; Association for Computational Linguistics: Sofia, Bulgaria, 2013; pp. 61–69. [Google Scholar]
- Chiari, M.; Barone, S.; Bombini, A.; Calzolai, G.; Carraresi, L.; Castelli, L.; Czelusniak, C.; Fedi, M.E.; Gelli, N.; Giambi, F.; et al. LABEC, the INFN ion beam laboratory of nuclear techniques for environment and cultural heritage. Eur. Phys. J. Plus 2021, 136, 472. [Google Scholar] [CrossRef] [PubMed]
- Klie, J.C.; Bugert, M.; Boullosa, B.; de Castilho, R.E.; Gurevych, I. The INCEpTION Platform: Machine-Assisted and Knowledge-Oriented Interactive Annotation. In Proceedings of the 27th International Conference on Computational Linguistics: System Demonstrations. Association for Computational Linguistics, Santa Fé, Mexico, 20–26 August 2018; pp. 5–9. [Google Scholar]
- Niccolucci, F.; Felicetti, A. A CIDOC CRM-based Model for the Documentation of Heritage Sciences. In Proceedings of the 2018 3rd Digital Heritage International Congress (DigitalHERITAGE) held jointly with 2018 24th International Conference on Virtual Systems Multimedia (VSMM 2018), San Francisco, CA, USA, 26–30 October 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Bombini, A.; Anderlini, L.; dell’Agnello, L.; Giaocmini, F.; Ruberto, C.; Taccetti, F. The AIRES-CH Project: Artificial Intelligence for Digital REStoration of Cultural Heritages Using Nuclear Imaging and Multidimensional Adversarial Neural Networks. In Proceedings of the Image Analysis and Processing—ICIAP, Lecce, Italy, 23–27 May 2022; Sclaroff, S., Distante, C., Leo, M., Farinella, G.M., Tombari, F., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 685–700. [Google Scholar] [CrossRef]
- Bombini, A.; Anderlini, L.; dell’Agnello, L.; Giacomini, F.; Ruberto, C.; Taccetti, F. Hyperparameter Optimisation of Artificial Intelligence for Digital REStoration of Cultural Heritages (AIRES-CH) Models. In Proceedings of the Computational Science and Its Applications—ICCSA 2022 Workshops, Malaga, Spain, 4–7 July 2022; Gervasi, O., Murgante, B., Misra, S., Rocha, A.M.A.C., Garau, C., Eds.; Springer International Publishing: Cham, witzerland, 2022; pp. 91–106. [Google Scholar] [CrossRef]
- Rackspace Hosting; NASA; Open Infrastructure Foundation and Community. Openstack. Version: Yoga, 30-03-2022. Available online: https://www.openstack.org/ (accessed on 11 October 2022).
- Cloud Native Computing Foundation. Kubernetes. Version: 1.25.0, 23-08-2022. Available online: https://kubernetes.io/ (accessed on 11 October 2022).
- Installs Calico for Policy and Flannel (aka Canal) for Networking. Available online: https://projectcalico.docs.tigera.io/ (accessed on 11 October 2022).
- Project Calico. Version: 3.24.1, 26-08-2022. Available online: https://projectcalico.docs.tigera.io/ (accessed on 11 October 2022).
- Flannel. Available online: https://github.com/flannel-io/flannel (accessed on 11 October 2022).
- Cloud Native Computing Foundation. Longhorn. Version: 1.3.1, 11-08-2022. Available online: https://longhorn.io/ (accessed on 11 October 2022).
- Ceccanti, A.; Hardt, M.; Wegh, B.; Millar, A.; Caberletti, M.; Vianello, E.; Licehammer, S. The INDIGO-Datacloud Authentication and Authorization Infrastructure. J. Phys. Conf. Ser. 2017, 898, 102016. [Google Scholar] [CrossRef] [Green Version]
- OpenID Foundation. OpenID Connect. Version: 1.0, 04-02-2014. 2022. Available online: https://openid.net/ (accessed on 11 October 2022).
- Cloud Native Computing Foundation. Harbor. Version: 1.10.13, 26-08-2022. Available online: https://goharbor.io/ (accessed on 11 October 2022).
- Grafana Labs. Grafana. Version: 9.1.1, 23-08-2022. Available online: https://www.grafana.com/ (accessed on 11 October 2022).
- Cloud Native Computing Foundation. Prometheus. Version: 2.37.0, 14-07-2022. Available online: https://prometheus.io/ (accessed on 11 October 2022).
- Google. Angular. Version: 14.1.0, 20-07-2022. Available online: https://angular.io/ (accessed on 11 October 2022).
- Merkel, D. Docker: Lightweight linux containers for consistent development and deployment. Linux J. 2014, 2014, 2. Available online: https://www.docker.com/ (accessed on 14 October 2022).
- Django Software Foundation. Django. Version: 2.2, 2019-05-05. Available online: https://djangoproject.com (accessed on 11 October 2022).
- Fielding, R.T.; Taylor, R.N. Architectural Styles and the Design of Network-Based Software Architectures. PhD Thesis, University of California, San Diego, CA, USA, 2000. [Google Scholar]
- Igor Sysoevn. NGINX. Version: 1.23.1, 19-07-2022. Available online: https://nginx.org/ (accessed on 11 October 2022).
- Hardt, D. The OAuth 2.0 Authorization Framework. 1-10-2010. Available online: https://www.rfc-editor.org/rfc/rfc6749 (accessed on 11 October 2022).
- Jones, M.; Bradley, J.; Sakimura, N. JSON Web Token (JWT). RFC Editor, Digital library. [CrossRef]
- Cloud Native Computing Foundation. Open Policy Agent (OPA). Version: 0.43.0, 23-08-2022. Available online: https://www.openpolicyagent.org (accessed on 11 October 2022).







| ArcheoNER | hsNER | THESPIAN-Mask JSON Keys | |
|---|---|---|---|
| ACT | ✓ | ✓ | sample.preparation.method |
| ANL | ✓ | analysis.category.type | |
| ART | ✓ | ✓ | studyObject.name |
| BIO | ✓ | studyObject.name | |
| DEV | ✓ | analysis.device | |
| LOC | ✓ | ✓ | studyObject.locationLabel |
| MAT | ✓ | sample.material | |
| MET | ✓ | sample.preparation.method | |
| NAT | ✓ | studyObject.name | |
| ORG | ✓ | ✓ | studyObject.owner |
| PER | ✓ | ✓ | studyObject.author |
| PRD | ✓ | studyObject.periodLabel | |
| SAM | ✓ | sample.type | |
| SIT | ✓ | studyObject.provenanceLabel | |
| SOF | ✓ | analysis.device.software | |
| RES | ✓ | analysis.result | |
| TSP | ✓ | ✓ | analysis.startDate(endDate) |
| ArcheoNER | P | R | F |
|---|---|---|---|
| CNN | 34.63 | 35.78 | 35.19 |
| Transformer | 30.75 | 38.94 | 34.36 |
| hsNER | P | R | F |
|---|---|---|---|
| CNN | 80.13 | 63.02 | 70.55 |
| Transformer | 70.91 | 76.82 | 73.75 |
| CRMhs Entry (C, P) | THESPIAN-Mask JSON Key | NER Label |
|---|---|---|
| HS_Study_Object, has_name | studyObject.Name | ART, BIO |
| HS_Study_Object, was_created_by | studyObject.author | PER |
| HS_Study_Object, has_period | studyObject.period | PRD |
| HS_Period, has_start_date(has_end_date) | studyObject.periodStart(periodEnd) | TSP |
| HS_Study_Object, has_location | studyObject.locationLabel | LOC |
| HS_Study_Object, was_found_at | studyObject.provenanceLabel | SIT |
| HS_Study_Object, has_owner | studyObject.owner | ORG |
| HS_Analysis, was_performed_by | analysis.institution | ORG |
| HS_Analysis, was_performed_at | analysis.location | LOC |
| HS_Analysis, was_performed_during | analysis.startDate(endData) | TSP |
| HS_Sample_Preparation, used_method | sample.preparation.method | ACT |
| Label | Entity | |
|---|---|---|
| NER | PER | Leonardo da Vinci |
| MongoDB | studyObject.author | Leonardo da Vinci |
| key | value |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bombini, A.; Alkhansa, A.; Cappelli, L.; Felicetti, A.; Giacomini, F.; Costantini, A. A Cloud-Native Web Application for Assisted Metadata Generation and Retrieval: THESPIAN-NER. Appl. Sci. 2022, 12, 12910. https://doi.org/10.3390/app122412910
Bombini A, Alkhansa A, Cappelli L, Felicetti A, Giacomini F, Costantini A. A Cloud-Native Web Application for Assisted Metadata Generation and Retrieval: THESPIAN-NER. Applied Sciences. 2022; 12(24):12910. https://doi.org/10.3390/app122412910
Chicago/Turabian StyleBombini, Alessandro, Ahmad Alkhansa, Laura Cappelli, Achille Felicetti, Francesco Giacomini, and Alessandro Costantini. 2022. "A Cloud-Native Web Application for Assisted Metadata Generation and Retrieval: THESPIAN-NER" Applied Sciences 12, no. 24: 12910. https://doi.org/10.3390/app122412910
APA StyleBombini, A., Alkhansa, A., Cappelli, L., Felicetti, A., Giacomini, F., & Costantini, A. (2022). A Cloud-Native Web Application for Assisted Metadata Generation and Retrieval: THESPIAN-NER. Applied Sciences, 12(24), 12910. https://doi.org/10.3390/app122412910