1. Introduction
The advent of the web has had a tremendous impact on information-system growth in almost every aspect of life. Unfortunately, such technological improvements have encouraged new sophisticated techniques to attack and scam users [
1]. Such attacks include fake websites that sell counterfeit goods, financial fraud by tricking users into revealing sensitive information that leads to the theft of money or identity information, or even installing malware on the user’s system. The malicious content inside websites often includes JavaScript (JS) code that hides in a hypertext markup language (HTML) either as an inline JS instruction or external code.
JS has an important role in web development. The Stack Overflow Annual Developer Survey 2022 [
2] showed that JS is the most used programming or scripting language by many professional developers. The performance of JS influences its popularity to support many programmers in developing more interactive websites with fast running times. JS is prevalent because it is lightweight, flexible, and powerful. However, due to its flexibility with many supported frameworks, libraries, and functions, JS has many vulnerabilities that attackers can exploit for malicious activities.
Various malicious scripts are used to implement such attacks. One of the most atrocious attacks is the so-called crypto trojan (e.g., WannaCry [
3]), which often uses JS as a payload in the first stage of infection of the victim’s computer. In addition, a JS-based attack allows an attacker to inject a malicious client-side code into a website [
4]. Cross-site scripting (XSS) allows an almost limitless variety of attacks. However, they commonly include transmitting private data such as cookies or other session information to the attacker, redirecting the victim to a webpage controlled by the attacker, or performing other malicious operations on the user’s machine under the guise of the vulnerable site. Thus, the analysis of malicious JS code detection is crucial for attack site analysis.
In web security, code injection is still the main threat to Internet users when they access certain websites. Most users do not have the knowledge necessary to distinguish between malicious and legitimate websites. As many legitimate websites are injected with malicious code (e.g., JS), whether any given website is malicious or not is usually unknowable. Even some web security systems fail to detect such websites. Thus, we cannot fully trust a legitimate website due to this code injection threat, and the ability to analyze a malicious webpage is an advantage when an antivirus system faces a code injection threat.
To detect code injection, analyzing the JS code in a webpage is crucial. Some recent works have proposed many ways to identify malicious webpages by extracting enough features to avoid overlooking malicious code in a webpage. Previously proposed detection features include lexical features [
5], image capture [
6], HTML [
7], host-based information [
8], and JS [
9]. However, the analysis of JS content still lacks semantic meaning, as JS analyzers only extract static information such as character string length, the number of JS functions, and the length of the array used in the code. To address this shortcoming, we seek an additional approach to enrich the features extracted from a webpage to improve the detection system’s performance.
To solve this problem, we propose a new webpage feature extraction program— abstract syntax tree-JavaScript (AST-JS)—that recognizes the semantic meaning of the JS code embedded in HTML content. AST-JS-based extraction represents JS code in way that can achieve good performance for detecting malicious JS [
10]. The AST is a tree representation of the abstract syntactic structure of source code written in a programming language. Many researchers use AST as the main feature of JS code for some source code analysis tasks. An AST assigns each statement in a source code to a syntactic unit category. The AST structure defines the program’s style, which can be useful to discerning the signature feature of the source code. Due to the complexity of the obfuscation problem, we bring the structure-based analysis of AST-JS to capture the whole structure of AST into a low-dimensional representation that retains the semantic meaning of the original JS code. In this study, we used graph2vec [
11] as an unsupervised learning model to create a vector representation that is then combined with other feature categories.
Moreover, we give some analysis of the influence of our proposed feature on prediction results. The aim is to understand AST-JS better and improve malicious webpage detection. In summary, the contributions of this study are as follows:
We present a structure-based analysis of AST-JS for enriching webpage content features to improve the performance of malicious webpage detection.
We analyze the importance of AST-JS representation for detecting malicious webpages by demonstrating a feature influence analysis of all feature categories using a Shapley additive explanation (SHAP) method.
We bring the influence analysis to a particular group of webpages to know the benefits of certain features for detecting specific attacks.
The organization of this paper proceeds as follows.
Section 2 summarizes related works on webpage detection and the use of AST as the representation of JS.
Section 3 presents our proposed approach for improving the current webpage detection system using the AST feature.
Section 4 gives details of our experimental setup and dataset.
Section 5 explains details of our evaluation of the performance with some result discussions. Finally, we conclude our study in
Section 6 by giving some limitations and the future direction of our approach.
2. Related Works
We summarize the previous works most relevant to ours and find the differences with ours. First, the study of malicious webpage detection has been ongoing for quite a long time, since Internet webpages became a source of information that users can access. Simple approaches to block malicious URLs or webpages, such as blacklisting, remain popular. Many websites and communities provide this service for free, such as PhishTank [
12], jwSpamSpy [
13], and DNS-BH [
14]. Alternatively, some companies offer commercial products for this mechanism, such as McAfee’s SiteAdvisor [
15], Cisco IronPort Web Reputation [
16], and Trend Micro Web Reputation [
17].
Moreover, machine-learning-based approaches for malicious webpage detection have been rapidly developing. Most of them have explored many features of webpages, such as lexicon-based features that include mostly static features, host-based features that use host information, or content-based ones such as HTML and JS. We can find some research that works on the same features with specific phishing URLs or websites that also consider the webpage’s information. Some recent works on phishing detection, such as [
18,
19], used light gradient boosting to capture the pattern of phishing URLs. The exploration of deep learning models is also an interesting way to create a more complex model that focuses on representing every detail of webpage text or URL characters [
20,
21,
22,
23]. Additionally, some research with the latest cloud technology uses machine learning to detect specific conditions [
24,
25] or analyze phishing URLs based on multi-domain study [
26].
Furthermore, the existence of JS code on malicious webpages has prompted some researchers to work on detecting malicious code injected into a webpage that probably can be a threat, such as XSS. Most of them use a machine learning approach, such as ensemble classifiers [
27]; or deep learning models, e.g., convolutional neural networks [
28], deep belief networks [
29,
30], and graph neural networks [
31].
Table 1 summarizes some related works that have been working close to malicious webpage detection.
Meanwhile, regarding AST representation, the use of ASTs for JS feature representation has been adopted as the leading and best way to capture the semantic meaning of a program. We can find some studies that used AST for defect prediction of JS code [
32,
33,
34], vulnerability detection [
35], or code summarization [
36]. AST representation is useful for determining how the programmers wrote the code to help us find defects or vulnerabilities. In addition, we can use the AST representation to summarize the semantics of the code and evaluate its maliciousness. We can use machine learning or deep learning for a detection model in which an AST is considered as a list of tokens [
37] or graph representation [
10,
38]. We hope to extend the scope of the research for AST representation for malicious websites [
39] or webpages.
3. Overview of Malicious Webpage Detection
In this section, we briefly discuss the background of the cybersecurity risks that we specifically address here, that is, malicious webpages. Then we explain our proposed method for improving previous works with a JS feature-based approach. We also emphasize a discussion about feature analysis using SHAP values as a method to clarify the transparency and interpretability of a machine learning model.
3.1. Malicious Webpages
Due to the advancement of the Internet, many vulnerabilities and attacks threaten users. Attackers or hackers create malicious websites to perform actions such as stealing credentials or data, or installing malware on the target’s computer. Installing malware is still the most effective way to gain unauthorized access to a server, a hosting control panel, or even the admin panel of the content management system.
A malicious webpage is hosted on a website to attack users. The malicious activity can take many different forms, including extracting data from a user, taking control of a browsing device, or using the device as an entry point into a network. Generally, there are two common types of malicious webpages, phishing webpages and malware webpages. For phishing webpages, the attackers try to make a website that looks legitimate, so the target will not recognize it as a risk. Meanwhile, malware webpages refer to a webpage containing malicious payloads that can direct the user’s computer to execute the payload code, which may install malware or any intermediary apps. The webpage can be either made by the attacker or by a legitimate webpage with hidden malicious code.
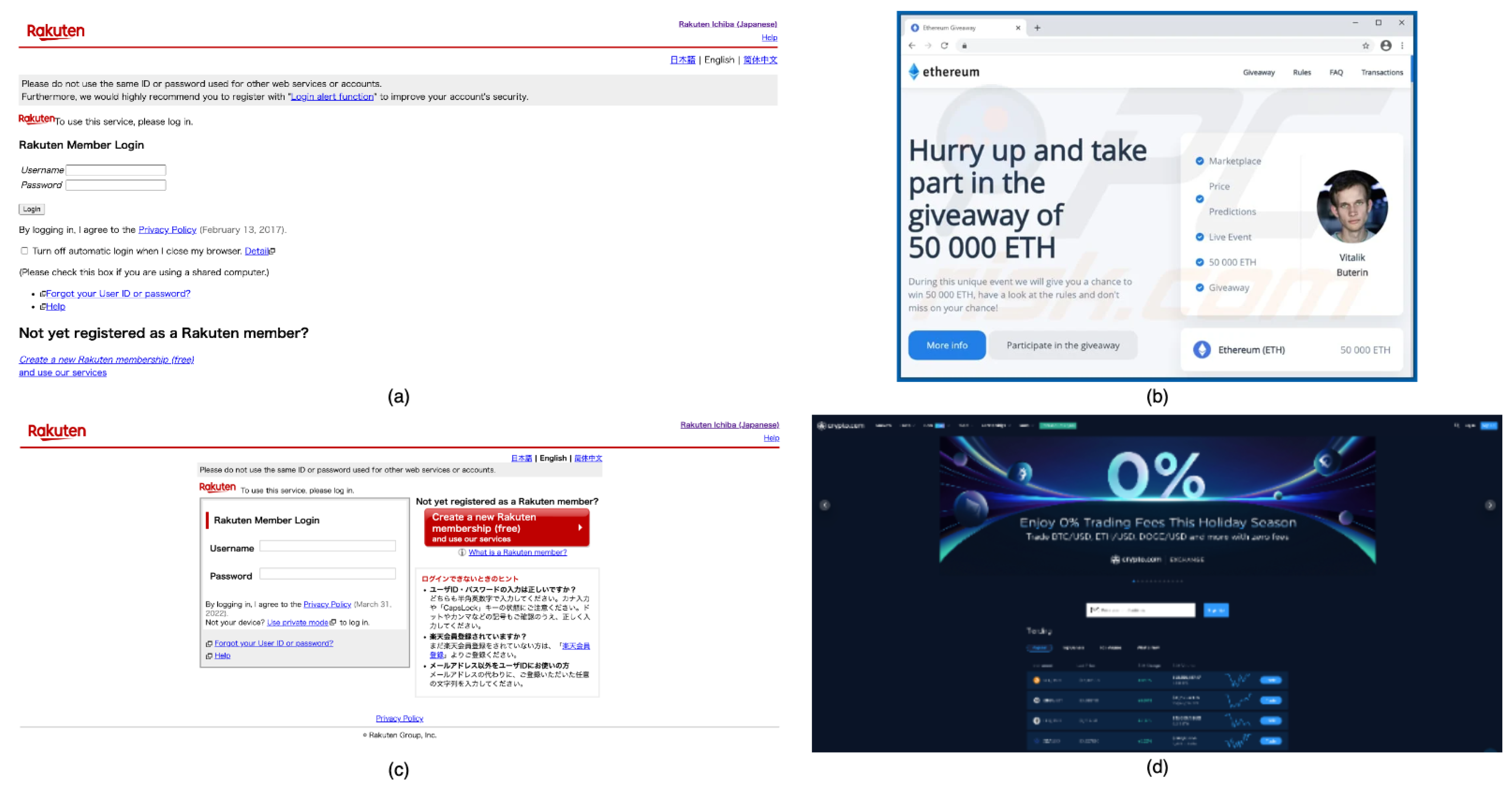
We show two examples of malicious webpages.
Figure 1a is an example of a phishing webpage, and
Figure 1b is a fake website made with malicious code. A phishing webpage is created to look very similar to a known legitimate site. It tries to imitate every aspect of a legitimate website (e.g., logo, position, and content) so the target users will not recognize that the website is fake. Attackers will make it more promising by sending a fake email recommending that a user access the webpage to fill out a credential information form.
Figure 1c is a legitimate website that
Figure 1a tries to imitate.
Meanwhile, the attacker-created fake webpage will likely build its brand entirely from fictitious information, including the logo, address, and content. It mrakes little attempt to resemble a legitimate webpage, but instead poses as a new legitimate company. Furthermore, an attacker can inject a malicious payload using a fake webpage on a legitimate website. This is the most difficult malicious page to detect, and it can send information to the original (legitimate) server while also sending it secretly to the attacker’s server.
Figure 1d is one of the counter examples for the fake website in
Figure 1b.
3.2. AST-JS
The AST is a tree representation of code that interprets how the programmers wrote the source code. Like human language, we can parse a sentence into a syntax tree representation that explains language grammar, and the AST representation is the output of how we represent a program written in a programming language with a specific syntax rule.
An AST captures the input’s essential structure in a tree form while omitting unnecessary syntactic details [
40]. We can distinguish it from concrete syntax trees by skipping tree nodes to represent punctuation marks, such as semicolons, to terminate statements or commas to separate function arguments. The AST also omits tree nodes that represent unary operands in the grammar. Such information is directly represented in an AST by the structure of the tree. We can create ASTs with a hand-written parser or code produced by parser generators, generally with a bottom-up approach.
An AST is usually the result of a compiler’s syntax analysis phase, a fundamental part of compiler functions. Many programs apply AST in the transforming process. It is not strictly applied in JS environments, such as node.js or a browser. We can find ASTs in Java with Netscape as well. The AST is used intensively during semantic analysis, during which the compiler checks for correct usage of the program’s elements and the language. The compiler also generates symbol tables based on the AST during semantic analysis. A complete traversal of the tree verifies the program’s correctness. After verifying correctness, the AST serves as the base for code generation. The AST is often used to generate an intermediate representation, sometimes called an intermediate language, for code generation.
Some characteristics of an AST can support subsequent steps of the compilation process. We can edit and enhance an AST with information such as properties and annotations for every element it contains. Such editing and annotations are impossible with the source code of a program because they would change the instructions in the code. An AST does not include unimportant punctuation and delimiters (braces, semicolons, and parentheses) if we compare it to the source code. An AST usually contains extra information about the program due to the compiler’s consecutive stages of analysis.
For example, we present simple JS code in Listing 1. We can derive from it the AST in the JSON format file that is shown in Listing 2. If we illustrate the AST as a graph structure, we can represent it as shown in
Figure 2, where each node of the graph denotes a construct occurring in the source code, and the edge is the hierarchical relation between nodes. There are many types of syntax tree formats for the AST representation depending on the language’s environment. For the JS environment, we have ESTree [
41], an organization that creates the standard specification for ASTs. The format is originally from the Mozilla Parser application interface (API) that previously exposed the SpiderMonkey engine’s JS parser as a JS API. They formalized and expanded the previous AST’s form as the AST’s primary reference in any AST-JS parser.
| Listing 1. Example JavaScript code. |
![Applsci 12 12916 i001]() |
| Listing 2. Output of an AST parser (in JSON format) applied to the code in Listing 1. |
![Applsci 12 12916 i002a]() ![Applsci 12 12916 i002b]() |
The AST parser engine will parse a JS code statement into syntactic units. Each node in the resulting syntax tree is a regular JS object that implements a particular node interface object. This interface has a “type” property in strings that contain various types of nodes as syntactic units. Based on the ESTree specification, the standard AST has 69 types of syntactic units. They represent the type of JS code for each statement or block of code, such as a variable expression, looping expression, or if–else statement.
3.3. AST Graph Features
A graph is a collection of objects including a set of interactions between pairs of objects [
42]. It is a ubiquitous data structure and a universal language to describe a complex system. There are many systems that use graph representation. For instance, to encode a social network as a graph, we might use nodes to represent individuals and use edges to express the friendships.
In mathematical notation, a graph
is defined by a set of nodes
and a set of edges
between these nodes. We denote an edge going from node
to node
as
[
42]. An adjacency matrix
is a way to represent graphs. We can order the nodes in the graph to index a particular row and column in the adjacency matrix. We can then represent the presence of edges as entries in this matrix:
if
, and
otherwise. If the graph contains only undirected edges,
will be a symmetric matrix, but if the graph is directed (i.e., the edge direction contains information),
will not necessarily be symmetric. Some graphs can also have weighted edges, where the entries in the adjacency matrix are arbitrary real values rather than
.
Furthermore, in many cases, attributes or feature information are associated with a graph. These are node-level attributes that we represent using a real-valued matrix , where m is the feature size of nodes and we assume that the ordering of the nodes is consistent with the ordering in the adjacency matrix. In heterogeneous graphs, we commonly assume that each different type of node has a distinct set of attributes. In some cases, we have to consider graphs with real-valued edge features in addition to discrete edge types, and we even associate real-valued features with entire graphs.
We often find problems that need a graph-based approach to understand them better and solve them. One example is generating a graph structure of AST features to simplify the representation of JS code in different ways. By representing the structure and content of an AST as tree-graph data, we can use the graph-based approach to find the signature of malicious AST through some features of the graph. We may consider the AST graph structure as the overall JS program code representation that shows the attackers’ obfuscation technique, which is generally implemented with nonstandard tools that the average programmer would tend not to use. Even though benign code may contain some obfuscation, we assume that malicious code always has this characteristic. Therefore, we want to analyze the AST graph’s structure feature to detect malicious JS code signatures using a graph-based approach.
3.4. Proposed Method
Figure 3 shows the overall process for our analysis method. We propose improving malicious webpage detection by enriching the feature extraction with AST-JS representation of JS content. Using the structure analysis of AST-JS, we identified the semantic information of a malicious JS program that was embedded in or injected into certain parts of the HTML content. We also evaluated our proposed AST-JS feature analysis to determine whether it significantly enhances the current malicious webpage detection system. We obtained information about the contribution of a feature to the detection model using SHAP [
43].
3.4.1. Framework Overview
Starting with an input of a webpage, we can extract all of its features, such as HTML, images, the URL, and the JS code. Then, we preprocess all features to represent each one numerically. To enrich the features, we add one more process that makes a semantic representation of the JS code based on the AST-JS structure. Using the JS content that we already have, we first parse the JS code dataset to obtain the AST representation for each JS file. This first output is in the form of JSON format files containing all the JS AST representation information. Next, we construct the graph structure of the AST information. We assume each syntactic unit as a single graph node and each edge as a hierarchical relationship between two syntactic units. We use graph2vec [
11], a representation learning model, to create a low-dimensional representation of the AST-JS graph. After that, we combine our representation with other feature vectors to create a complete webpage representation. Then, we can use any machine learning model to predict whether it is malicious or benign.
3.4.2. Current Malicious Webpage Detection System
This research aims to improve on previous work on malicious webpage detection, which lacked the exploration of the semantic meaning of JS content. Specifically, we tried to improve on the previous work of Chaiban et al. [
44], which used almost all components or features of a webpage, from the URL to HTML and JS content. We can see the detailed feature information used in this research in the original paper. However, overall they used seven feature categories:
Lexical features (L): This feature category is about all URL-related information, and we extract many features based on that. There are various features for this category. It can be just the length of the URL character string or the number of specific symbols or characters in the URL, such as semicolons, underscores, ampersands, and equal signs.
Host-based features (H): This category has five features: IP address, geographic location, WHOIS information, the type of protocol, and the inclusion of the Alexa top domain.
Content-based features (C): This category is based on HTML content that also has JS content embedded in the script tag. This feature category includes any lexical exploration of HTML and JS content, such as the number of suspicious JS functions, the length of JS and HTML code, the number of script tags in HTML, or the average and maximum arrays we can find in the JS code.
Image embedding (IM): After we capture the webpage, we can represent it using MobileNetV2 [
45].
Content embedding (CE): This category uses the HTML content to make vector embedding with CodeBERT [
46].
URL embedding with Longformer (UL): We use the Longformer transformer [
47] to transform URL text into a low-dimensional representation.
URL embedding with BERT (UB): We use the Distilbert transformer [
48] to transform URL text into a low-dimensional representation.
The reason for improving on the work of Chaiban et al. [
44] is that their work covers all kinds of features of a webpage, from the URL to the JS code. They also proposed a good dataset that is quite challenging for building a model to separate malicious and benign webpages. However, their work did not sufficiently explore a webpage’s JS content, which is the critical point of maliciousness code. Most web security threats, such as drive-by download, XSS, or injection, use JS as the payload for their attack. Therefore, we need an additional extraction for JS content to improve detection performance, especially for specific threats related to JS.
3.4.3. AST Parsing
We start with the JS code file in Listing 1. We can then parse each statement from top to bottom to break it into smaller source code components. We have to check the syntactic category to which the code belongs. For example, in Listing 1, the first code line is a “VariableDeclaration” object consisting of one “VariableDeclarator” object. This object has two main properties: “BinaryExpression” and “Identifier”. For binary expression, we will have two literal values, 6 and 7, as the property of that object.
Figure 4 depicts how we can parse one line of JS code into an AST.
There are many tools for representing JS code files as ASTs. We used the popular open-source AST-JS parser Esprima [
49]. This tool performs lexical and syntactical analysis of JS programs running in some JS environments, including web browsers (including Edge, Firefox, Chrome, and Safari), node.js, and a JS engine in Java (e.g., Rhino). The Esprima parser takes a string representing an accurate JS program and generates a syntax tree, an ordered tree that defines its syntactic structure. Esprima acquires the syntax tree format originating from the Mozilla Parser API, formalized and expanded as the ESTree specification.
3.4.4. AST Graph Construction and Node Reduction
The Esprima parser transforms JS code into an AST representation. However, in the JSON format, its elements are a list of syntactic unit objects with some properties depending on the type of syntactic unit, such as an “AssignmentPattern” with three properties: type, left, and right. Nevertheless, every object always has a type property that indicates the name of the syntactic type. Thus, we have to generate graph objects that describe the structure and attributes of the AST representation.
Let
be a set of AST files that we want to use to generate the graph object. Each of them has a list of the syntactic unit types that construct the AST object. As the number of units is finite, we can create the syntactic units’ vocabulary
T as the node type. We use a recursion algorithm to generate all nodes of the AST. The detailed recursive algorithm is presented as Algorithm 1. We assign the parent input as the “root” node for the starting node.
| Algorithm 1: Generating a graph from an AST. |
![Applsci 12 12916 i003]() |
Reducing the number of nodes in an AST graph is necessary because a large number of nodes within a graph increases the burden of the graph representation learning model when obtaining its optimal value. It will take much time to visit all nodes within the graph, making detection inefficient. If we consider all possible nodes, the memory consumption will exceed the capacity of typical computing systems. Therefore, to solve this problem, we omit some nodes within the graph without removing the semantic meaning of either the structure or node attributes.
Thus, omitting some nodes can give some advantages to our detection system. The first advantage is that it can reduce the time spent processing the input data because it does not need to visit (examine) all nodes within the graph, which can have more than 100,000 nodes. In addition, node omission can reduce the memory used to train all parameters in our model. We cannot ignore that memory capacity limits training, especially if we want to train with a large dataset. The final advantage is that it prevents our model from overfitting due to too many parameters, which would happen if we consider an AST graph with a relatively large number of nodes. Han et al. [
50] proved that the lightweight AST, which reduces the number of nodes in the AST graph, can have higher accuracy and time efficiency than the conventional AST.
Furthermore, we cannot reduce the number of AST graph nodes randomly. We need to choose nodes that are “safe” to remove without compromising our purpose. We use a breadth-first search (BFS) tree algorithm to select nodes for removal. BFS refers to the method in which we traverse a graph by examining all children of a node before moving on to that child’s children
Figure 5. The BFS algorithm visits all graph nodes that traverse the graph layerwise, thereby exploring the neighboring nodes. As we can see, BFS provides a layerwise algorithm that fits our problem. The AST graph has a top-down structure in which the parent nodes sufficiently represent the child nodes under the parents. We can consider the bottom node as the top node’s detailed information, described by the node type.
3.5. Representation Learning
In this study, we used graph2vec [
11] for representation learning to obtain a low-dimensional vector. After we had a set of graphs
, which was the result of AST-JS transformation, we used graph2vec to encode each graph to closely represent the AST graph’s characteristics. This unsupervised learning process produced a vocabulary embedding vector to store all AST-JS representations for building a malicious webpage detection model.
For a more detailed explanation, let
, where
N is a set of nodes,
E is a set of edges, and
f is a function for mapping each node with a label
l. Then, a rooted subgraph can be written as
. In a graph
, a rooted subgraph of degree
D around node
contains all the nodes reachable in
d hops from
n. We identify all the neighbors of
using the BFS algorithm where
. Using all rooted subgraphs, we can train an unsupervised model such as doc2vec [
51], where a set of AST graphs
and a sequence of rooted subgraphs
are sampled from AST graph
. The graph2vec skip-gram learns
F-dimensional embeddings of the graph
, and each rooted subgraph
sampled from
. This model considers a rooted subgraph
to be occurring in the context of graph
and maximizes the following log-likelihood:
where the probability of
is defined as
where
is the vocabulary of all the rooted subgraph across all graphs in
G.
3.6. SHAP Values
SHAP is a unified framework for interpreting predictions by assigning an importance value for each feature that influences a particular prediction [
43]. This method addresses one of the concerns in machine learning, namely, interpretability, where researchers try to explain how their model makes predictions. In addition, SHAP can also give more perspective on the influences of specific features, whether they are essential or not.
To implement this method, we need to calculate the SHAP values that define how each datum influences the entire prediction. SHAP values are the framework that unifies Shapley regression, Shapley sampling, and the quantitative input that influences feature attributions while allowing for connections with LIME [
52], DeepLIFT [
53], and layer-wise relevance propagation. We can then retrieve information on how high or low feature values can support negative or positive prediction results based on a summary of these values.
5. Evaluation
In this section, we present the performance of the proposed method for detecting malicious webpages with a new approach based on AST-JS information. We describe its overall performance, analyze the manual features’ influences, and provide an analysis of webpage features and AST-JS structures that correlate with webpage types based on clustering results.
5.1. Overall Performance
We tested our proposed approach with several conditions based on the parameter settings and the inclusion of the AST-JS feature.
Table 4 shows the accuracy performance for each condition with the best combination of feature categories. We experimented with new settings based on
Table 4 and compared them with the original settings from previous work [
44]. We also experimented with the inclusion of AST-JS to compare the performance before and after adding the proposed feature. We had to find the best combination of feature categories for every condition to get the optimum result.
The experiments showed that our new settings give better results: around 84.75% accuracy, higher by 1.08% than the original setup. We can achieve those results by using the combination of feature categories L, H, C, and UL, which is fewer features than in the combination used in the original setup. Moreover, when adding AST-JS as our proposed feature, we can get a better result of around 84.84% accuracy with the best combination of feature categories of L, H, C, UL, IM, CE, UB, and AST-JS.
AST-JS enriches webpage features that better represent the characteristics of JS code that probably contains the payload that attackers try to inject into the webpage. To test our hypothesis, we divided the dataset into two groups: webpages without JS and webpages with JS. This treatment can strengthen the performance because the model will focus more on learning these features, so it is not distracted with webpages without JS.
Table 5 shows the experimental results. We achieved higher performance, around 86.10% accuracy, when all learning data contained JS information. Compared to webpages without JS coding, we obtained lower performance, around 81.63% accuracy, with our new model settings. Both the original and new settings can achieve better performance when we have JS information as a webpage feature. This is because the model should generalize and consider the webpage without JS, influencing the precision for obtaining more true positives.
Table 6 shows the performance with different machine learning models.
Not all webpages have JS information. Attackers could use WebAssembly to install malware if the browser “sandbox” holds up, or they could perform other attacks [
55]. Even though JS is widely used for malware infection, attackers can run any vulnerable extension. Further, if the browser uses outdated libraries, then a carefully crafted element can lead to code execution even without JS.
5.2. Influences of Feature Categories
We determined the absolute mean SHAP value for each feature category, representing the influence on prediction output. The aim was to determine how our proposed feature can help the performance improvement after adding it to the other features. However, due to the existence of JS in a webpage, AST-JS features only help process a webpage with JS information, so we tried to calculate the SHAP values for two datasets: the full dataset and webpages with JS.
Figure 6 reports the absolute mean SHAP values for two datasets, showing that AST-JS contributes much to the prediction output. It can be observed that the proposed feature, AST-JS, has a clear influence on producing the predicted labels. AST-JS is one of the top three feature categories in the whole dataset that mixes webpages with and without JS information. This result is understandable because in the whole dataset, we found that around 60% (60,939) of webpages do not have AST-JS features. This condition may influence how AST-JS contributes more to malicious code detection. This also reveals that URL information is a critical feature for achieving higher performance in malicious webpage prediction when we cannot find JS content.
Despite that, we still need to consider JS information, where most attackers apply their efforts. Furthermore, AST-JS successfully captures JS information via a low-dimensional representation that can enrich the features to identify a malicious webpage. In
Figure 7, we also can see that when the model focuses on webpages with JS, the AST-JS feature has the most influence among all feature categories and can even have more influence than URL information.
5.3. Comparison with Other JavaScript-Related Features
The original GAWAIN dataset [
44] contains JS information that can be extracted as syntactical features. However, these features do not truly capture the whole semantic meaning of JS code, so the model fails to benefit from the existence of JS code. Even though it catches the code’s most crucial information (e.g., the number of suspicious JS functions), those features are still insufficient due to some obfuscation techniques that may be applied to evade a detection system and security analyst. To ensure that our proposed approach to extracting the JS information is better than using other JS-related features, we calculated the SHAP values for all those features and compared them with AST-JS’s embedding representation. The other features were excluded from this analysis to focus more on features extracted from JS code in a webpage and to make a fair comparison.
Figure 8 shows the results. There are two summaries of SHAP values for two different datasets, a full dataset and a dataset where the webpages have JS information. These two datasets show how the existence of JS can affect the distribution of the influence of each feature for prediction. In
Figure 9, we can see that in the top 20 feature influences, AST-JS representation dominates the list compared to other JS-related features. Nevertheless, JS length (“js-length”) and the average length of JS code (“js_array_length_avg”) still rank number one and two, respectively, for SHAP value distribution.
5.4. AST Feature Influence
In this experiment, we evaluated the influence of each feature category on a particular group of webpages that probably have a different contribution distributions for detecting malicious webpages. This analysis consisted of two main steps: clustering and feature importance analysis. The clustering step aimed to obtain some group clusters with similar features in the vector space to analyze the influence of feature categories based on SHAP values. Another consideration for clustering instead of webpage type labeling is that we need the ground truth, which is challenging. In addition, many webpages in the dataset are offline, which makes it hard to access them and identify their type.
Table 7 shows the clustering results using the BIRCH algorithm [
54]. Clusters 0 and 2 have many similar webpages compared to clusters 1, 3, and 4. We also identified each cluster based on the percentage of unique hostnames per total number of URLs in each cluster. In
Table 8, we can see how attackers try to attack the target with a single webpage or inject the payload into some webpages with the same hostname. The high percentage in cluster 2 indicates that most webpages are single webpages, where attackers probably create the webpages randomly without making a complex website.
For the following analysis, we evaluated the influences of all feature categories to determine whether they are beneficial for building a detection model. In
Figure 10, we show a summary of the total average SHAP value for each feature category. As we can see in the graph for cluster 2, even though the AST has the most significant influence, URL information still has a strong influence because we can find many single webpages that tend to have a randomized or unique URL name. We did not analyze clusters 3 and 4 due to a lack of data.
6. Conclusions
This study involved the development of a new approach for improving malicious webpage detection based on analyzing the AST structure of JS coding. This addition supports a deeper analysis of the semantic meaning of JS code, whereas the previous work [
44] did not include that feature for building the model. Our evaluation shows that adding an AST-JS feature representation can improve the performance of the detection model, especially for webpages with JS content. Furthermore, our evaluation shows the significant influence of AST-JS on the detection model to detect either benign or malicious webpages, and it also is dominant compared to other JS-related features. We found that the AST-JS and URL features share a strong influence on some webpages that tend to be single websites that may have randomized URLs.
However, our proposed approach only works well on webpages with JS content, which is the limitation of this study. Many malicious webpages without JS content probably focus on phishing attacks, which do not need complicated payloads. Moreover, this study did not include real-time application analysis as a plug-in in web browsers to check the actual performance in real conditions. In addition, due to the use of a machine learning model, our proposed approach is susceptible to an adversarial attack that can affect network parameters, making our model produce many false negatives.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}