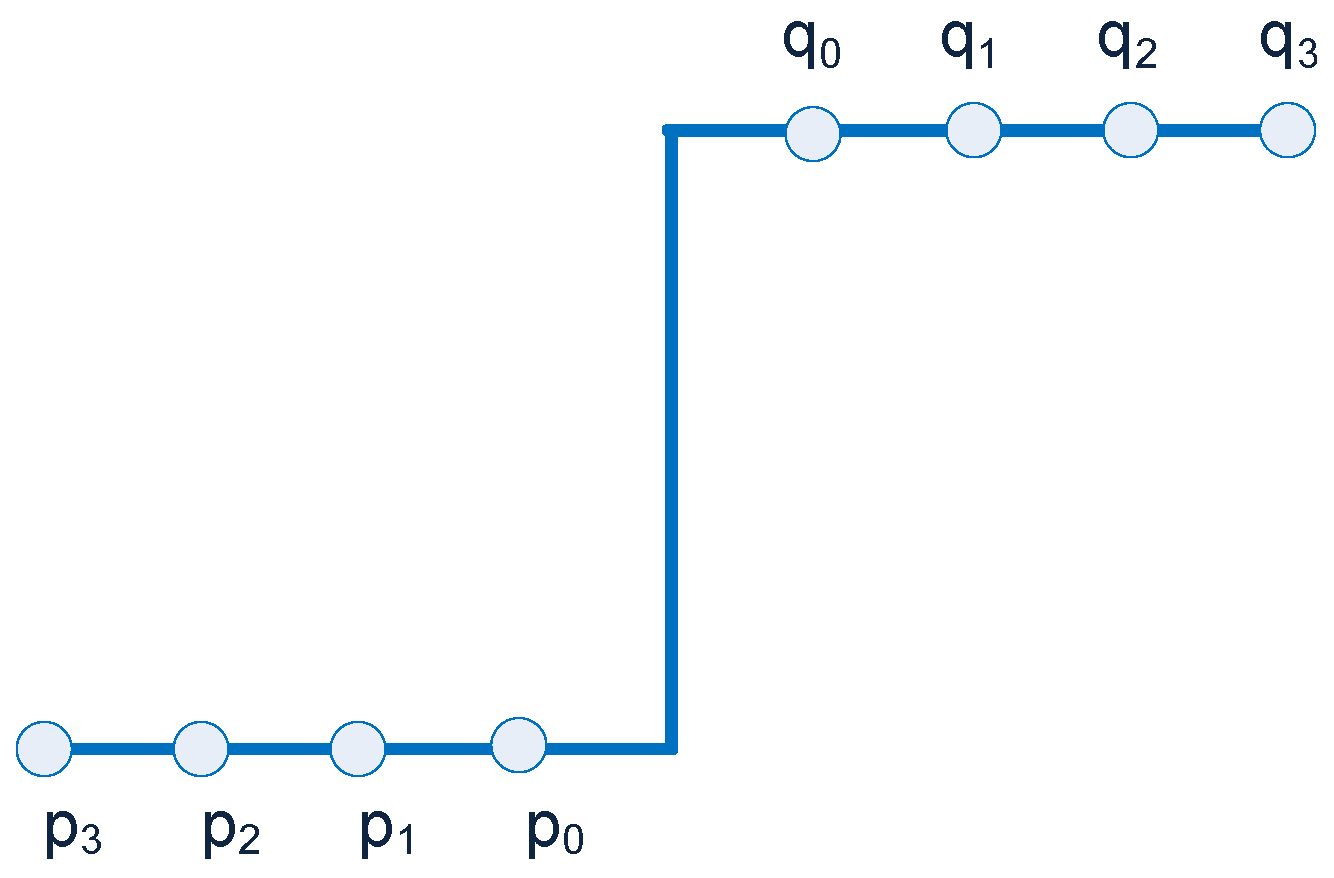
Figure 1.
Variation of pixel intensities between block boundaries.
Figure 1.
Variation of pixel intensities between block boundaries.
Figure 2.
Smoothing of pixel intensities between block boundaries.
Figure 2.
Smoothing of pixel intensities between block boundaries.
Figure 3.
Architecture of V-DPEDBF for HEVC [
40].
Figure 3.
Architecture of V-DPEDBF for HEVC [
40].
Figure 4.
(a) Sequence of read for an LCU; (b,c) sequence of read for a 16 × 16 block.
Figure 4.
(a) Sequence of read for an LCU; (b,c) sequence of read for a 16 × 16 block.
Figure 5.
Boundary strength computation unit.
Figure 5.
Boundary strength computation unit.
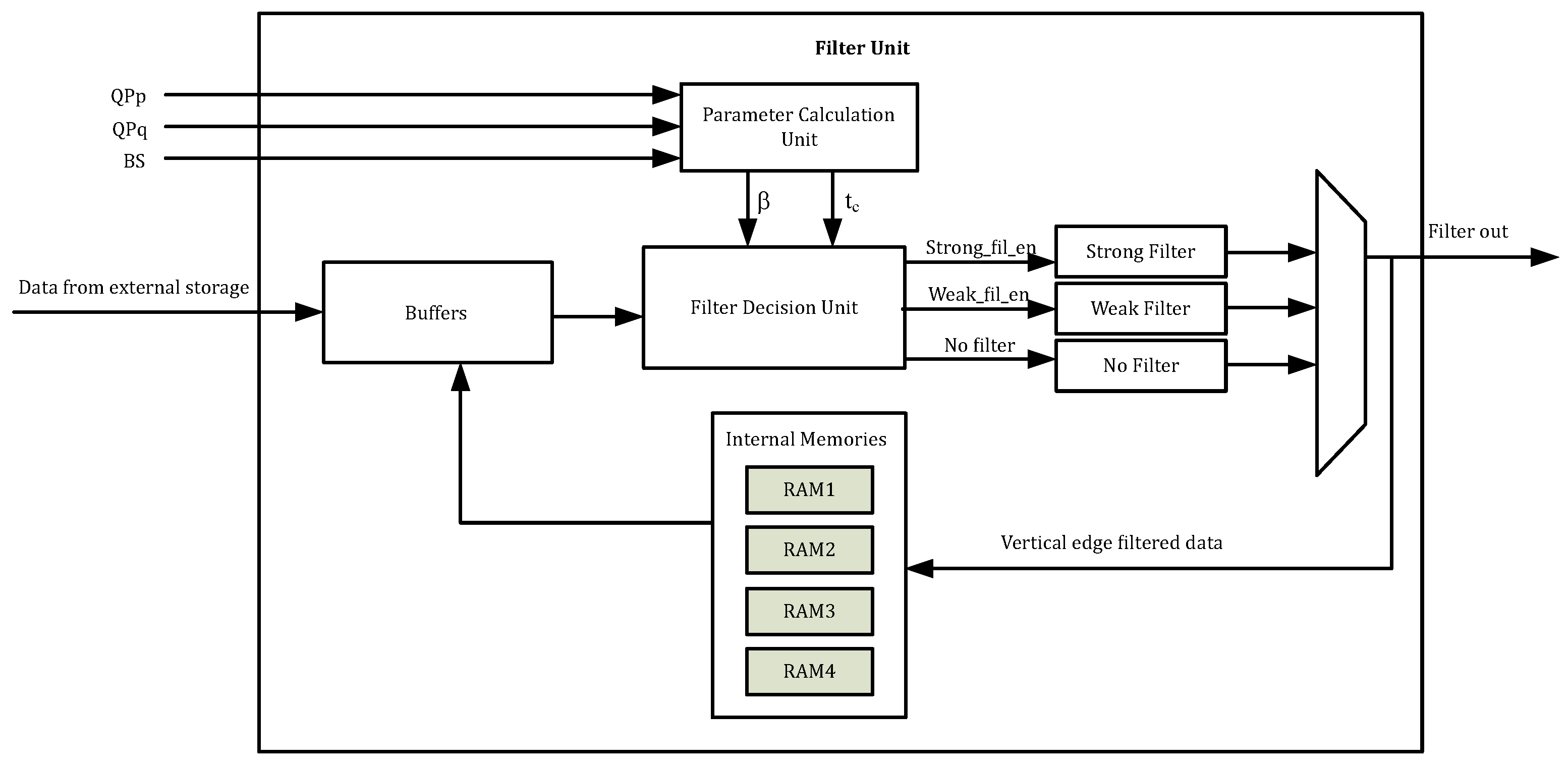
Figure 6.
Filter unit of dual-edge deblocking filter architecture.
Figure 6.
Filter unit of dual-edge deblocking filter architecture.
Figure 7.
Buffers to store the pixel block.
Figure 7.
Buffers to store the pixel block.
Figure 8.
Mapping of pixel blocks to buffers: (a) pixel blocks; (b) buffers.
Figure 8.
Mapping of pixel blocks to buffers: (a) pixel blocks; (b) buffers.
Figure 9.
Mapping of internal memory to buffer before horizontal filtering for luma block.
Figure 9.
Mapping of internal memory to buffer before horizontal filtering for luma block.
Figure 10.
Mapping of internal memory to buffer before horizontal filtering for chroma block.
Figure 10.
Mapping of internal memory to buffer before horizontal filtering for chroma block.
Figure 11.
Resource sharing architecture of strong filter—partial view.
Figure 11.
Resource sharing architecture of strong filter—partial view.
Figure 12.
Flow diagram to perform quality assessment.
Figure 12.
Flow diagram to perform quality assessment.
Figure 13.
Frame of the original input video.
Figure 13.
Frame of the original input video.
Figure 14.
Frame of output video from HM with DBF disabled.
Figure 14.
Frame of output video from HM with DBF disabled.
Figure 15.
Frame of output video from HM with DBF enabled.
Figure 15.
Frame of output video from HM with DBF enabled.
Figure 16.
Frame of output video from dual PEDBF.
Figure 16.
Frame of output video from dual PEDBF.
Figure 17.
Comparison of PSNR with HM for QCIF video sequences using QP = 32.
Figure 17.
Comparison of PSNR with HM for QCIF video sequences using QP = 32.
Figure 18.
Comparison of PSNR with HM for CIF video sequences using QP = 32.
Figure 18.
Comparison of PSNR with HM for CIF video sequences using QP = 32.
Figure 19.
Comparison of processing time with HM for QCIF video sequences using QP = 32.
Figure 19.
Comparison of processing time with HM for QCIF video sequences using QP = 32.
Figure 20.
Comparison of processing time with HM for CIF video sequences using QP = 32.
Figure 20.
Comparison of processing time with HM for CIF video sequences using QP = 32.
Figure 21.
Comparison of PSNR with HM for QCIF video sequences using QP = 37.
Figure 21.
Comparison of PSNR with HM for QCIF video sequences using QP = 37.
Figure 22.
Comparison of PSNR with HM for CIF video sequences using QP = 37.
Figure 22.
Comparison of PSNR with HM for CIF video sequences using QP = 37.
Figure 23.
Comparison of processing time with HM for QCIF video sequences using QP = 37.
Figure 23.
Comparison of processing time with HM for QCIF video sequences using QP = 37.
Figure 24.
Comparison of processing time with HM for CIF video sequences using QP = 37.
Figure 24.
Comparison of processing time with HM for CIF video sequences using QP = 37.
Figure 25.
Comparison of PSNR with HM for QCIF video sequences using QP = 27.
Figure 25.
Comparison of PSNR with HM for QCIF video sequences using QP = 27.
Figure 26.
Comparison of PSNR with HM for CIF video sequences using QP = 27.
Figure 26.
Comparison of PSNR with HM for CIF video sequences using QP = 27.
Figure 27.
Comparison of processing time with HM for QCIF video sequences using QP = 27.
Figure 27.
Comparison of processing time with HM for QCIF video sequences using QP = 27.
Figure 28.
Comparison of processing time with HM for CIF video sequences using QP = 27.
Figure 28.
Comparison of processing time with HM for CIF video sequences using QP = 27.
Table 1.
PSNR of QCIF video sequences with QP = 32.
Table 1.
PSNR of QCIF video sequences with QP = 32.
| Video Sequence | HM (dB) | PEDBF (dB) |
|---|
| Akiyo | 37.3833 | 37.59186 |
| Coastguard | 34.4138 | 36.40767 |
| Foreman | 35.4274 | 36.58643 |
| Mobile Calendar | 32.2366 | 32.85071 |
| Hall | 36.4334 | 37.235 |
| Carphone | 36.1972 | 36.4323 |
| Miss America | 38.8972 | 39.12775 |
Table 2.
PSNR of CIF video sequences with QP = 32.
Table 2.
PSNR of CIF video sequences with QP = 32.
| Video Sequence | HM (dB) | PEDBF (dB) |
|---|
| Akiyo | 38.307737 | 39.2812 |
| Coastguard | 35.03723 | 34.9852 |
| Foreman | 35.8951 | 35.99 |
| Mobile Calendar | 33.04411 | 33.0432 |
| Hall | 36.93208 | 37.4513 |
| Tempete | 34.09227 | 34.224 |
Table 3.
Processing time of QCIF video sequences with QP = 32.
Table 3.
Processing time of QCIF video sequences with QP = 32.
| Video Sequence | HM (Sec) | PEDBF (Sec) |
|---|
| Akiyo | 64.678 | 39.4553 |
| Coastguard | 85.103 | 44.81924 |
| Foreman | 82.368 | 45.6632 |
| Mobile Calendar | 85.673 | 43.21693 |
| Hall | 64.064 | 37.28175 |
| Carphone | 73.358 | 43.57872 |
| Miss America | 23.811 | 13.27997 |
Table 4.
Processing time of CIF video sequences with QP = 32.
Table 4.
Processing time of CIF video sequences with QP = 32.
| Video Sequence | HM (Sec) | PEDBF (Sec) |
|---|
| Akiyo | 264.989 | 165.49741 |
| Coastguard | 376.373 | 196.2231 |
| Foreman | 278.388 | 176.485 |
| Mobile Calendar | 312.898 | 193.3375 |
| Hall | 219.416 | 112.2503 |
| Tempete | 229.776 | 152.46557 |
Table 5.
PSNR of QCIF video sequences with QP = 37.
Table 5.
PSNR of QCIF video sequences with QP = 37.
| Video Sequence | HM (dB) | PEDBF (dB) |
|---|
| Akiyo | 34.0182 | 34.893362 |
| Coastguard | 31.1392 | 33.457211 |
| Foreman | 32.1997 | 33.862149 |
| Mobile Calendar | 28.3189 | 29.568311 |
| Hall | 32.971 | 34.430916 |
| Carphone | 32.9865 | 34.303814 |
| Miss America | 36.4185 | 37.267113 |
Table 6.
PSNR of CIF video sequences with QP = 37.
Table 6.
PSNR of CIF video sequences with QP = 37.
| Video Sequence | HM (dB) | PEDBF (dB) |
|---|
| Akiyo | 36.2985 | 36.716387 |
| Coastguard | 31.8043 | 33.970701 |
| Foreman | 33.0051 | 34.390624 |
| Mobile Calendar | 29.2222 | 30.454212 |
| Hall | 34.5437 | 35.553274 |
| Tempete | 30.6828 | 32.131876 |
Table 7.
Processing time of QCIF video sequences with QP = 37.
Table 7.
Processing time of QCIF video sequences with QP = 37.
| Video Sequence | HM (Sec) | PEDBF (Sec) |
|---|
| Akiyo | 46.354 | 23.904816 |
| Coastguard | 52.02 | 27.976072 |
| Foreman | 48.861 | 28.335635 |
| Mobile Calendar | 70.905 | 38.544973 |
| Hall | 50.138 | 28.943229 |
| Carphone | 63.938 | 33.216266 |
| Miss America | 23.778 | 15.006227 |
Table 8.
Processing time of CIF video sequences with QP = 37.
Table 8.
Processing time of CIF video sequences with QP = 37.
| Video Sequence | HM (Sec) | PEDBF (Sec) |
|---|
| Akiyo | 361.664 | 139.577545 |
| Coastguard | 323.229 | 141.569951 |
| Foreman | 293.987 | 161.030763 |
| Mobile Calendar | 461.949 | 225.603688 |
| Hall | 280.68 | 142.62714 |
| Tempete | 200.476 | 112.878238 |
Table 9.
PSNR of QCIF video sequences with QP = 27.
Table 9.
PSNR of QCIF video sequences with QP = 27.
| Video Sequence | HM (dB) | PEDBF (dB) |
|---|
| Akiyo | 40.8999 | 40.891213 |
| Coastguard | 38.1673 | 39.927605 |
| Foreman | 38.9294 | 39.793245 |
| Mobile Calendar | 36.6292 | 36.744202 |
| Hall | 39.8733 | 40.164219 |
| Carphone | 39.6617 | 39.917189 |
| Miss America | 41.5719 | 41.766507 |
Table 10.
PSNR of CIF video sequences with QP = 27.
Table 10.
PSNR of CIF video sequences with QP = 27.
| Video Sequence | HM (dB) | PEDBF (dB) |
|---|
| Akiyo | 42.2861 | 42.332459 |
| Coastguard | 38.6598 | 40.411503 |
| Foreman | 39.2529 | 40.130872 |
| Mobile Calendar | 37.1378 | 37.29197 |
| Hall | 40.1375 | 40.525791 |
| Tempete | 38.0572 | 38.495716 |
Table 11.
Processing time of QCIF video sequences with QP = 27.
Table 11.
Processing time of QCIF video sequences with QP = 27.
| Video Sequence | HM (Sec) | PEDBF (Sec) |
|---|
| Akiyo | 66.61 | 32.722607 |
| Coastguard | 72.627 | 39.74846 |
| Foreman | 81.681 | 41.068033 |
| Mobile Calendar | 120.716 | 58.555709 |
| Hall | 67.687 | 35.016408 |
| Carphone | 95.34 | 55.400211 |
| Miss America | 24.741 | 13.174376 |
Table 12.
Processing time of CIF video sequences with QP = 27.
Table 12.
Processing time of CIF video sequences with QP = 27.
| Video Sequence | HM (Sec) | PEDBF (Sec) |
|---|
| Akiyo | 205.041 | 100.410937 |
| Coastguard | 277.788 | 150.710927 |
| Foreman | 250.539 | 126.669947 |
| Mobile Calendar | 352.151 | 208.336164 |
| Hall | 228.818 | 117.526938 |
| Tempete | 263.123 | 156.781587 |































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}