
Contribution of Vocal Tract and Glottal Source Spectral Cues in the Generation of Acted Happy and Aggressive Spanish Vowels †




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
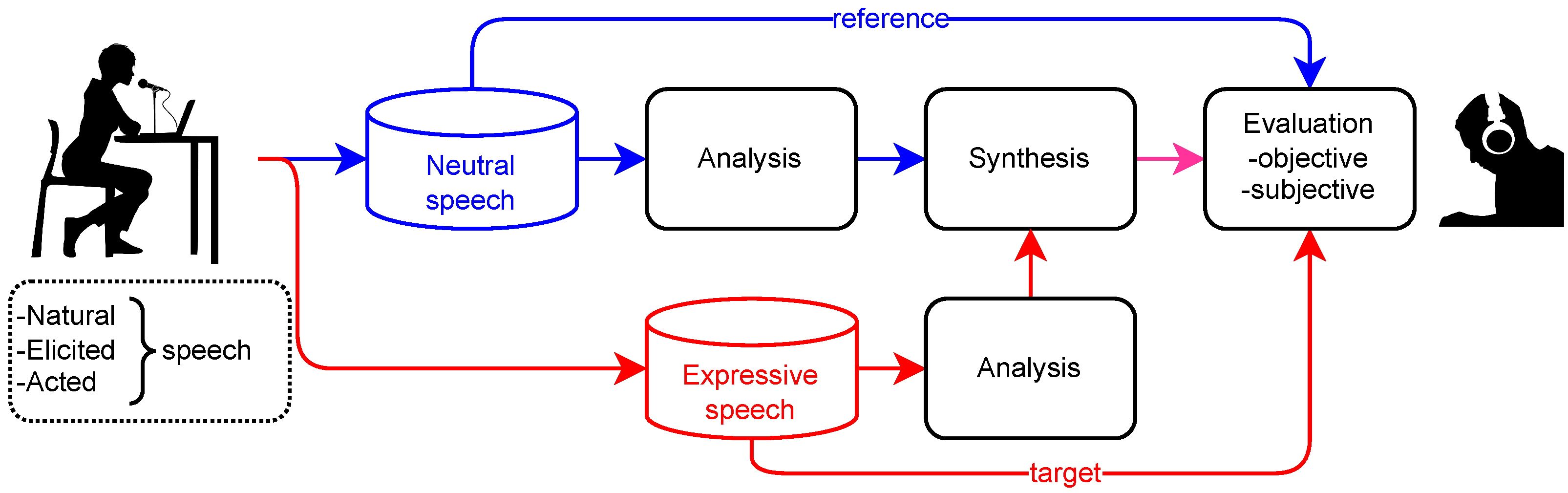
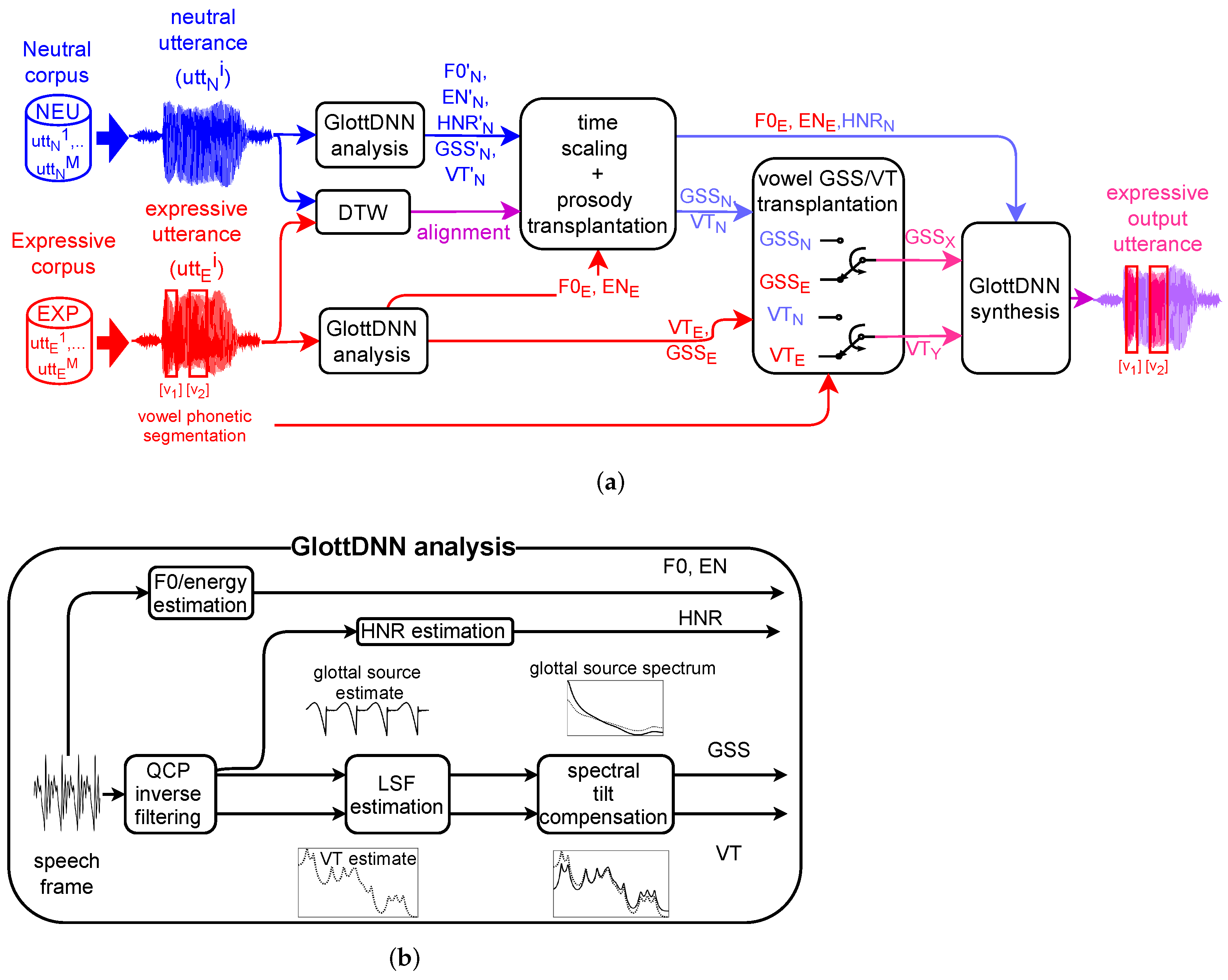
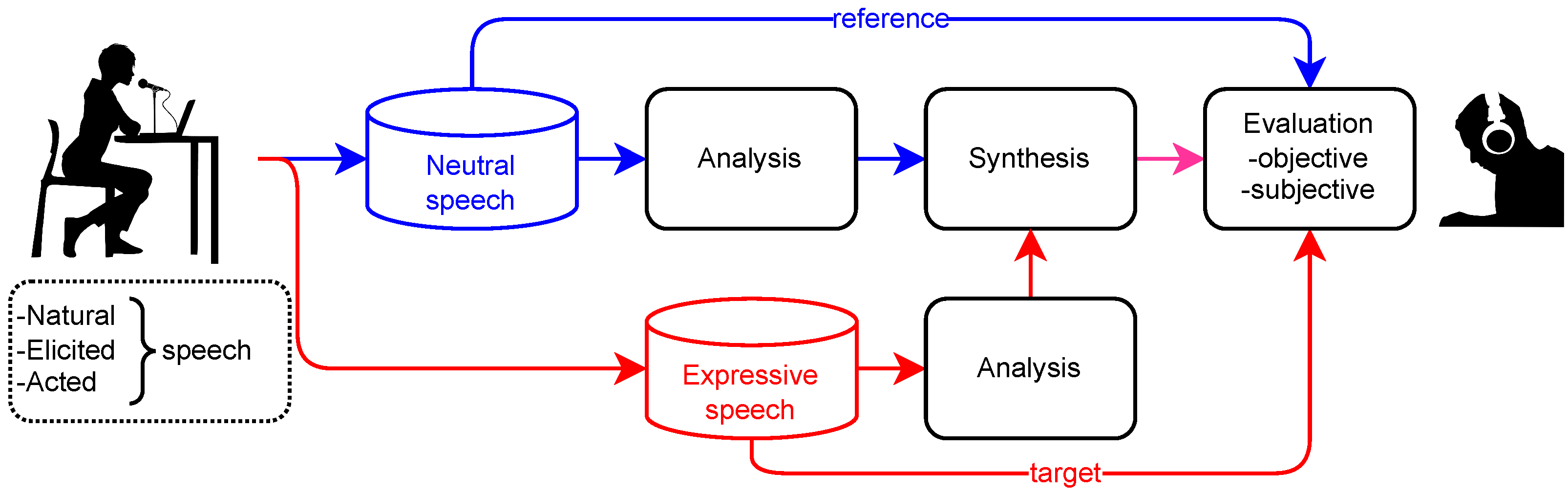
2. Analysis-by-Synthesis Methodology
3. Experiments
4. Results and Discussion
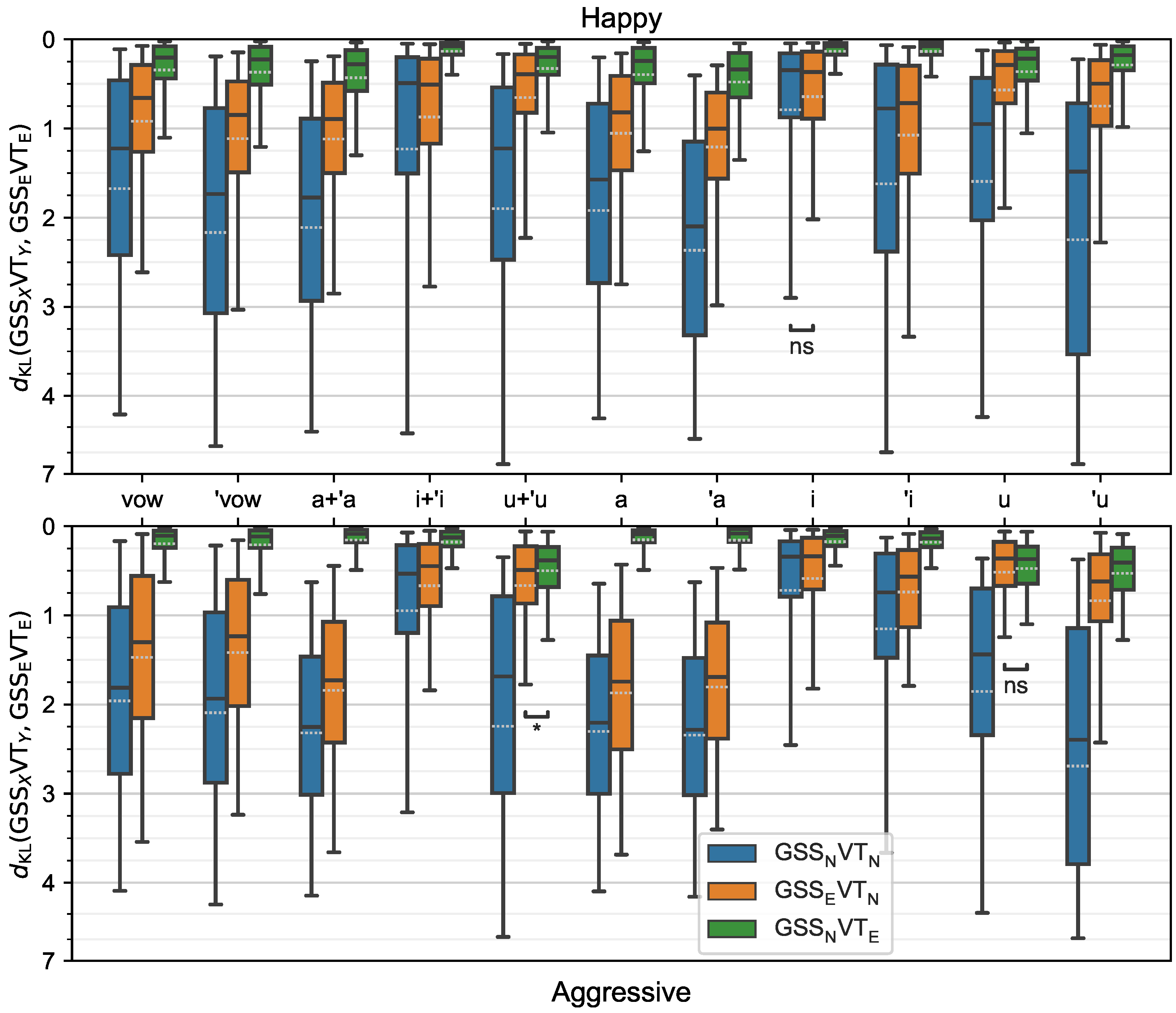
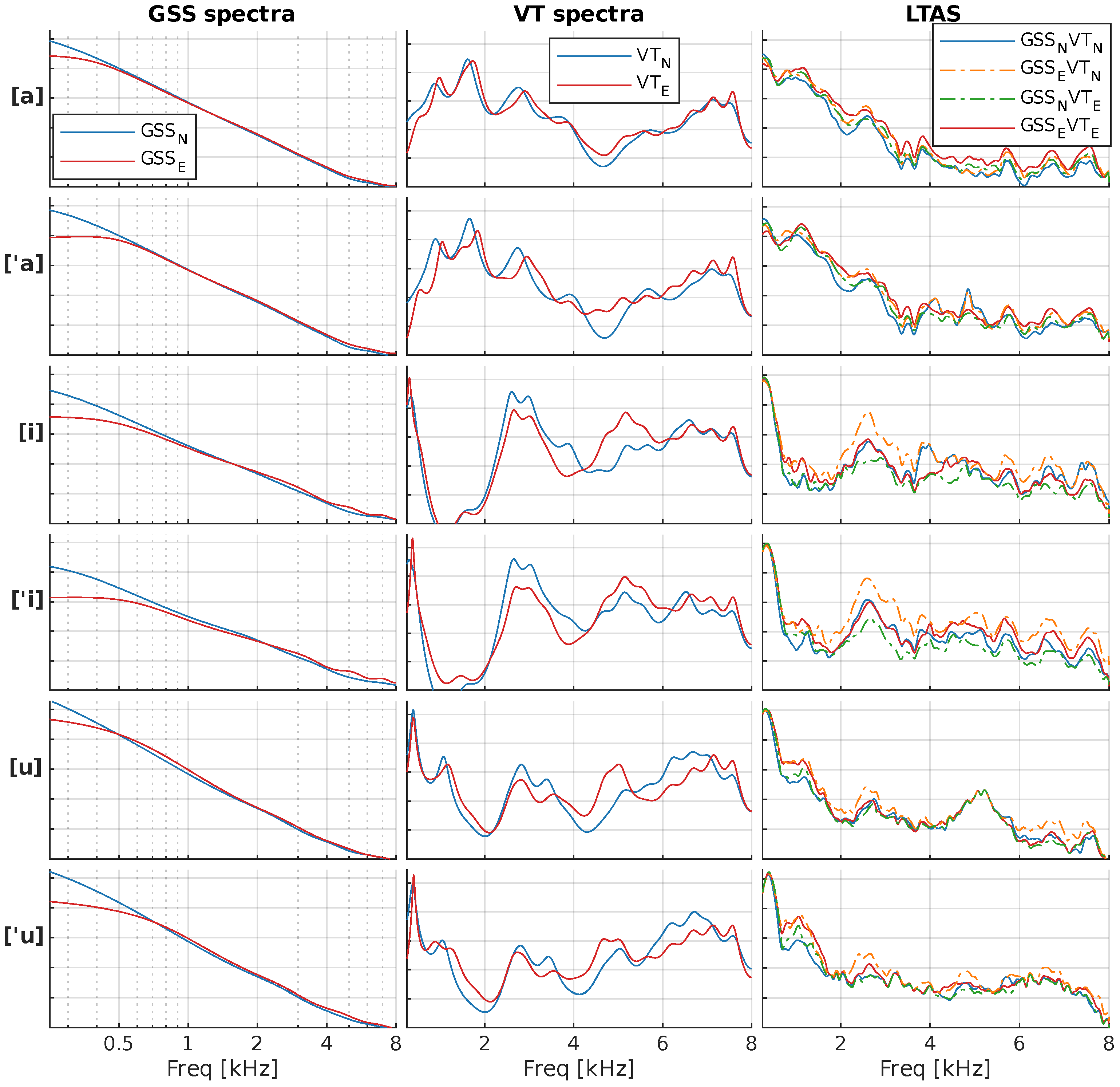
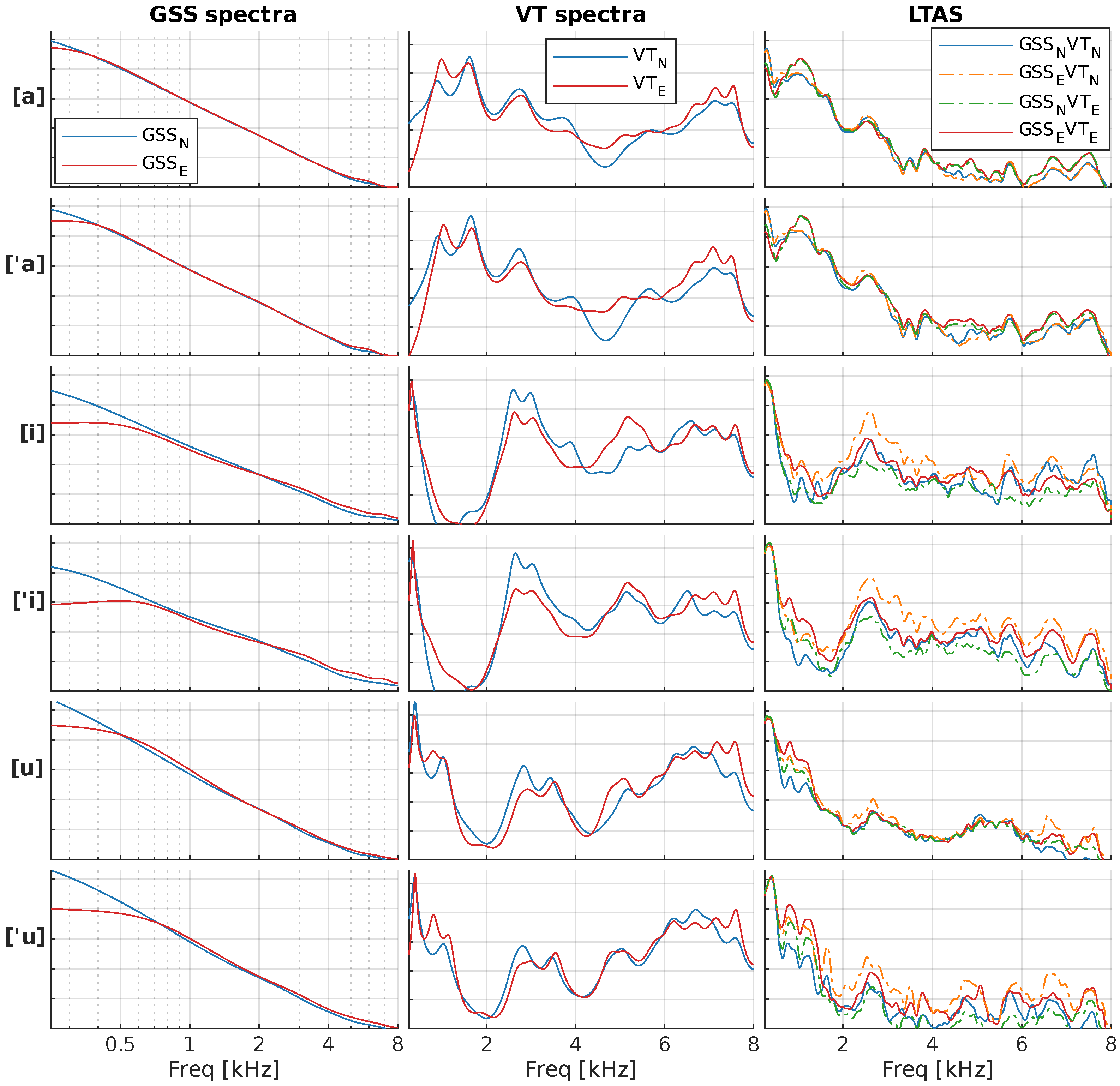
4.1. Objective Results
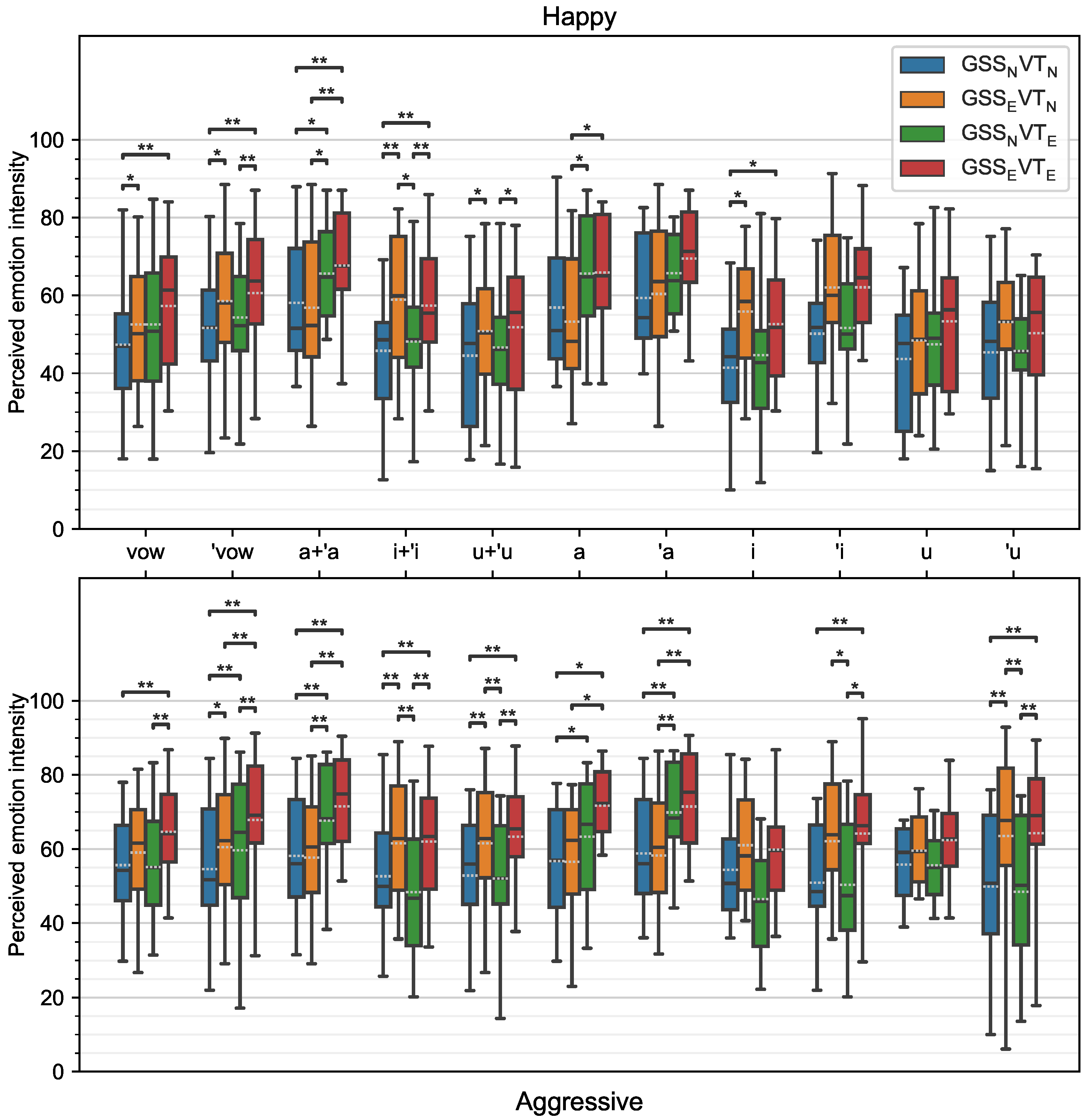
4.2. Perceptual Evaluation Results
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Sample Availability
Abbreviations
| DNN | Deep Neural Networks |
| DTW | Dynamic Time Warping |
| FEM | Finite element Method |
| GSS | Glottal Source Spectra |
| HMM | Hidden Markov Models |
| HNR | Harmonic-to-Noise Ratio |
| LF | Liljencrants–Fant model |
| LPC | Linear Predictive Coding |
| LSF | Line Spectral Frequencies |
| LTAS | Long-Term Average Spectrum |
| MUSHRA | MUltiple Stimuli with Hidden Reference and Anchor |
| QCP | Quasi-Closed Phase |
| VT | Vocal Tract |
References
- Schuller, D.M.; Schuller, B.W. A Review on Five Recent and Near-Future Developments in Computational Processing of Emotion in the Human Voice. Emot. Rev. 2021, 13, 44–50. [Google Scholar] [CrossRef]
- Wani, T.M.; Gunawan, T.S.; Qadri, S.A.A.; Kartiwi, M.; Ambikairajah, E. A Comprehensive Review of Speech Emotion Recognition Systems. IEEE Access 2021, 9, 47795–47814. [Google Scholar] [CrossRef]
- Zhou, K.; Sisman, B.; Liu, R.; Li, H. Emotional voice conversion: Theory, databases and ESD. Speech Commun. 2022, 137, 1–18. [Google Scholar] [CrossRef]
- Russell, J.A. A circumplex model of affect. J. Personal. Soc. Psychol. 1980, 39, 1161. [Google Scholar] [CrossRef]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Eyben, F.; Scherer, K.R.; Schuller, B.W.; Sundberg, J.; Andre, E.; Busso, C.; Devillers, L.Y.; Epps, J.; Laukka, P.; Narayanan, S.S.; et al. The Geneva Minimalistic Acoustic Parameter Set (GeMAPS) for Voice Research and Affective Computing. IEEE Trans. Affect. Comput. 2016, 7, 190–202. [Google Scholar] [CrossRef] [Green Version]
- Scherer, K.R. Vocal communication of emotion: A review of research paradigms. Speech Commun. 2003, 40, 227–256. [Google Scholar] [CrossRef]
- Arias, P.; Rachman, L.; Liuni, M.; Aucouturier, J.J. Beyond Correlation: Acoustic Transformation Methods for the Experimental Study of Emotional Voice and Speech. Emot. Rev. 2021, 13, 12–24. [Google Scholar] [CrossRef]
- Taylor, P. Text-to-Speech Synthesis; Cambridge University Press: Cambridge, UK, 2009; pp. 1–626. [Google Scholar] [CrossRef]
- Birkholz, P.; Martin, L.; Willmes, K.; Kröger, B.J.; Neuschaefer-Rube, C. The contribution of phonation type to the perception of vocal emotions in German: An articulatory synthesis study. J. Acoust. Soc. Am. 2015, 137, 1503–1512. [Google Scholar] [CrossRef]
- Birkholz, P. Modeling Consonant-Vowel Coarticulation for Articulatory Speech Synthesis. PLoS ONE 2013, 8, e60603. [Google Scholar] [CrossRef] [Green Version]
- Burkhardt, F. Rule-Based Voice Quality Variation with Formant Synthesis. In Proceedings of the InterSpeech 2009, Brighton, UK, 6–10 September 2009; pp. 2659–2662. [Google Scholar]
- Fant, G.; Liljencrants, J.; Lin, Q. A four-parameter model of glottal flow. Speech Transm. Lab. Q. Prog. Status Rep. (STL-QPSR) 1985, 26, 1–13. [Google Scholar] [CrossRef]
- Yanushevskaya, I.; Gobl, C.; Ní Chasaide, A. Cross-language differences in how voice quality and f0 contours map to affect. J. Acoust. Soc. Am. 2018, 144, 2730–2750. [Google Scholar] [CrossRef] [PubMed]
- Murphy, A.; Yanushevskaya, I.; Ní Chasaide, A.; Gobl, C. Rd as a Control Parameter to Explore Affective Correlates of the Tense-Lax Continuum. In Proceedings of the InterSpeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 3916–3920. [Google Scholar] [CrossRef] [Green Version]
- Fant, G. The LF-model revisited. Transformations and frequency domain analysis. Speech Transm. Lab. Q. Prog. Status Rep. (STL-QPSR) 1995, 36, 119–156. [Google Scholar]
- Li, Y.; Li, J.; Akagi, M. Contributions of the glottal source and vocal tract cues to emotional vowel perception in the valence-arousal space. J. Acoust. Soc. Am. 2018, 144, 908–916. [Google Scholar] [CrossRef] [PubMed]
- Drugman, T.; Alku, P.; Alwan, A.; Yegnanarayana, B. Glottal source processing: From analysis to applications. Comput. Speech Lang. 2014, 28, 1117–1138. [Google Scholar] [CrossRef] [Green Version]
- Perrotin, O.; McLoughlin, I. GFM-Voc: A Real-Time Voice Quality Modification System. In Proceedings of the InterSpeech 2019, Graz, Austria, 15–19 September 2019; pp. 3685–3686. [Google Scholar]
- Lorenzo-Trueba, J.; Barra-Chicote, R.; Raitio, T.; Obin, N.; Alku, P.; Yamagishi, J.; Montero, J.M. Towards Glottal Source Controllability in Expressive Speech Synthesis. In Proceedings of the InterSpeech 2012, Portland, OR, USA, 9–13 September 2012; pp. 1620–1623. [Google Scholar]
- Airaksinen, M.; Juvela, L.; Bollepalli, B.; Yamagishi, J.; Alku, P. A Comparison between STRAIGHT, Glottal, and Sinusoidal Vocoding in Statistical Parametric Speech Synthesis. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1658–1670. [Google Scholar] [CrossRef] [Green Version]
- Seshadri, S.; Juvela, L.; Räsänen, O.; Alku, P. Vocal Effort based Speaking Style Conversion using Vocoder Features and Parallel Learning. IEEE Access 2019, 7, 17230–17246. [Google Scholar] [CrossRef]
- Story, B.H.; Titze, I.R.; Hoffman, E.A. Vocal tract area functions from magnetic resonance imaging. J. Acoust. Soc. Am. 1996, 100, 537–554. [Google Scholar] [CrossRef]
- Story, B.H. Phrase-level speech simulation with an airway modulation model of speech production. Comput. Speech Lang. 2013, 27, 989–1010. [Google Scholar] [CrossRef] [Green Version]
- Stone, S.; Marxen, M.; Birkholz, P. Construction and evaluation of a parametric one-dimensional vocal tract model. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1381–1392. [Google Scholar] [CrossRef]
- Blandin, R.; Arnela, M.; Laboissière, R.; Pelorson, X.; Guasch, O.; Hirtum, A.V.; Laval, X. Effects of higher order propagation modes in vocal tract like geometries. J. Acoust. Soc. Am. 2015, 137, 832–843. [Google Scholar] [CrossRef] [Green Version]
- Vampola, T.; Horáček, J.; Švec, J.G. FE Modeling of Human Vocal Tract Acoustics. Part I: Production of Czech vowels. Acta Acust. United Acust. 2008, 94, 433–447. [Google Scholar] [CrossRef]
- Takemoto, H.; Adachi, S.; Mokhtari, P.; Kitamura, T. Acoustic interaction between the right and left piriform fossae in generating spectral dips. J. Acoust. Soc. Am. 2013, 134, 2955–2964. [Google Scholar] [CrossRef] [PubMed]
- Arnela, M.; Dabbaghchian, S.; Blandin, R.; Guasch, O.; Engwall, O.; Van Hirtum, A.; Pelorson, X. Influence of vocal tract geometry simplifications on the numerical simulation of vowel sounds. J. Acoust. Soc. Am. 2016, 140, 1707–1718. [Google Scholar] [CrossRef] [Green Version]
- Freixes, M.; Arnela, M.; Socoró, J.C.; Alías, F.; Guasch, O. Glottal Source Contribution to Higher Order Modes in the Finite Element Synthesis of Vowels. Appl. Sci. 2019, 9, 4535. [Google Scholar] [CrossRef] [Green Version]
- Arnela, M.; Dabbaghchian, S.; Guasch, O.; Engwall, O. MRI-based vocal tract representations for the three-dimensional finite element synthesis of diphthongs. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 2173–2182. [Google Scholar] [CrossRef]
- Arnela, M.; Guasch, O. Finite element simulation of /asa/ in a three-dimensional vocal tract using a simplified aeroacoustic source model. In Proceedings of the 23rd International Congress on Acoustics (ICA), Aachen, Germany, 9–13 September 2019; pp. 1802–1809. [Google Scholar]
- Pont, A.; Guasch, O.; Arnela, M. Finite element generation of sibilants /s/ and /z/ using random distributions of Kirchhoff vortices. Int. J. Numer. Methods Biomed. Eng. 2020, 36, e3302. [Google Scholar] [CrossRef]
- Schoder, S.; Maurerlehner, P.; Wurzinger, A.; Hauser, A.; Falk, S.; Kniesburges, S.; Döllinger, M.; Kaltenbacher, M. Aeroacoustic sound source characterization of the human voice production-perturbed convective wave equation. Appl. Sci. 2021, 11, 2614. [Google Scholar] [CrossRef]
- Guasch, O.; Arnela, M.; Pont, A. Resonance tuning in vocal tract acoustics from modal perturbation analysis instead of nonlinear radiation pressure. J. Sound Vib. 2021, 493, 115826. [Google Scholar] [CrossRef]
- Arnela, M.; Guasch, O.; Freixes, M. Finite element generation of sung vowels tuning 3D MRI-based vocal tracts. In Proceedings of the 27th International Congress on Sound and Vibration (ICSV27), Graz, Austria, 11–16 July 2021; pp. 1–8. [Google Scholar]
- Freixes, M.; Arnela, M.; Alías, F.; Socoró, J.C. GlottDNN-based spectral tilt analysis of tense voice emotional styles for the expressive 3D numerical synthesis of vowel [a]. In Proceedings of the 10th ISCA Speech Synthesis Workshop (SSW), Vienna, Austria, 20–22 September 2019; pp. 132–136. [Google Scholar] [CrossRef]
- Guasch, O.; Alías, F.; Arnela, M.; Socoró, J.C.; Freixes, M.; Pont, A. GENIOVOX Project: Computational generation of expressive voice. In Proceedings of the IberSPEECH2021, Valladolid, Spain, 24–25 March 2021. [Google Scholar]
- Moulines, E.; Charpentier, F. Pitch-synchronous waveform processing techniques for text-to-speech synthesis using diphones. Speech Commun. 1990, 9, 453–467. [Google Scholar] [CrossRef]
- Iriondo, I.; Planet, S.; Socoró, J.C.; Martínez, E.; Alías, F.; Monzo, C. Automatic refinement of an expressive speech corpus assembling subjective perception and automatic classification. Speech Commun. 2009, 51, 744–758. [Google Scholar] [CrossRef] [Green Version]
- Alías, F.; Sevillano, X.; Socoró, J.C.; Gonzalvo, X. Towards high-quality next-generation text-to-speech synthesis: A multidomain approach by automatic domain classification. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 1340–1354. [Google Scholar] [CrossRef]
- Rabiner, L.; Biing-Hwang, J. Fundamentals of Speech Recognition; Prentice Hall: Englewood Cliffs, NJ, USA, 1993. [Google Scholar]
- Klabbers, E.; Veldhuis, R. Reducing audible spectral discontinuities. IEEE Trans. Speech Audio Process. 2001, 9, 39–51. [Google Scholar] [CrossRef]
- ITU-R. ITU-R BS.1534-1: Method for the Subjective Assessment of Intermediate Quality Level of Coding Systems; International Telecommunication Union: Geneva, Switzerland, 2003. [Google Scholar]
- Jillings, N.; De Man, B.; Moffat, D.; Reiss, J.D. Web audio evaluation tool: A browser-based listening test environment. In Proceedings of the 12th International Conference in Sound and Music Computing (SMC 2015), Maynooth, Ireland, 26 July–1 August 2015; pp. 147–152. [Google Scholar]
- Wilcoxon, F. Individual Comparisons by Ranking Methods. Biom. Bull. 1945, 1, 80–83. [Google Scholar] [CrossRef]
- Perrotin, O.; McLoughlin, I. A Spectral Glottal Flow Model for Source-filter Separation of Speech. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7160–7164. [Google Scholar] [CrossRef] [Green Version]
- Arnela, M.; Guasch, O. Tuning MRI-based vocal tracts to modify formants in the three-dimensional finite element production of vowels. In Proceedings of the 12th International Conference on Voice Physiology and Biomechanics, Grenoble, France, 18–20 March 2020. [Google Scholar]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Freixes, M.; Socoró, J.C.; Alías, F. Contribution of Vocal Tract and Glottal Source Spectral Cues in the Generation of Acted Happy and Aggressive Spanish Vowels. Appl. Sci. 2022, 12, 2055. https://doi.org/10.3390/app12042055
Freixes M, Socoró JC, Alías F. Contribution of Vocal Tract and Glottal Source Spectral Cues in the Generation of Acted Happy and Aggressive Spanish Vowels. Applied Sciences. 2022; 12(4):2055. https://doi.org/10.3390/app12042055
Chicago/Turabian StyleFreixes, Marc, Joan Claudi Socoró, and Francesc Alías. 2022. "Contribution of Vocal Tract and Glottal Source Spectral Cues in the Generation of Acted Happy and Aggressive Spanish Vowels" Applied Sciences 12, no. 4: 2055. https://doi.org/10.3390/app12042055
APA StyleFreixes, M., Socoró, J. C., & Alías, F. (2022). Contribution of Vocal Tract and Glottal Source Spectral Cues in the Generation of Acted Happy and Aggressive Spanish Vowels. Applied Sciences, 12(4), 2055. https://doi.org/10.3390/app12042055