
No-Reference Image Quality Assessment Based on Image Multi-Scale Contour Prediction

Abstract
:1. Introduction
- (1)
- Using multi-scale contour features as the one-stage regression target to solve the problem of too few data sets.
- (2)
- Designing the different learning labels of different layers of the model to simulate the evaluation of human eyes on images at different distances.
- (3)
- Designing a central attention peripheral inhibition module to simulate the mechanism of the receptive field of retinal ganglion cells.
2. Related Work
3. Approach
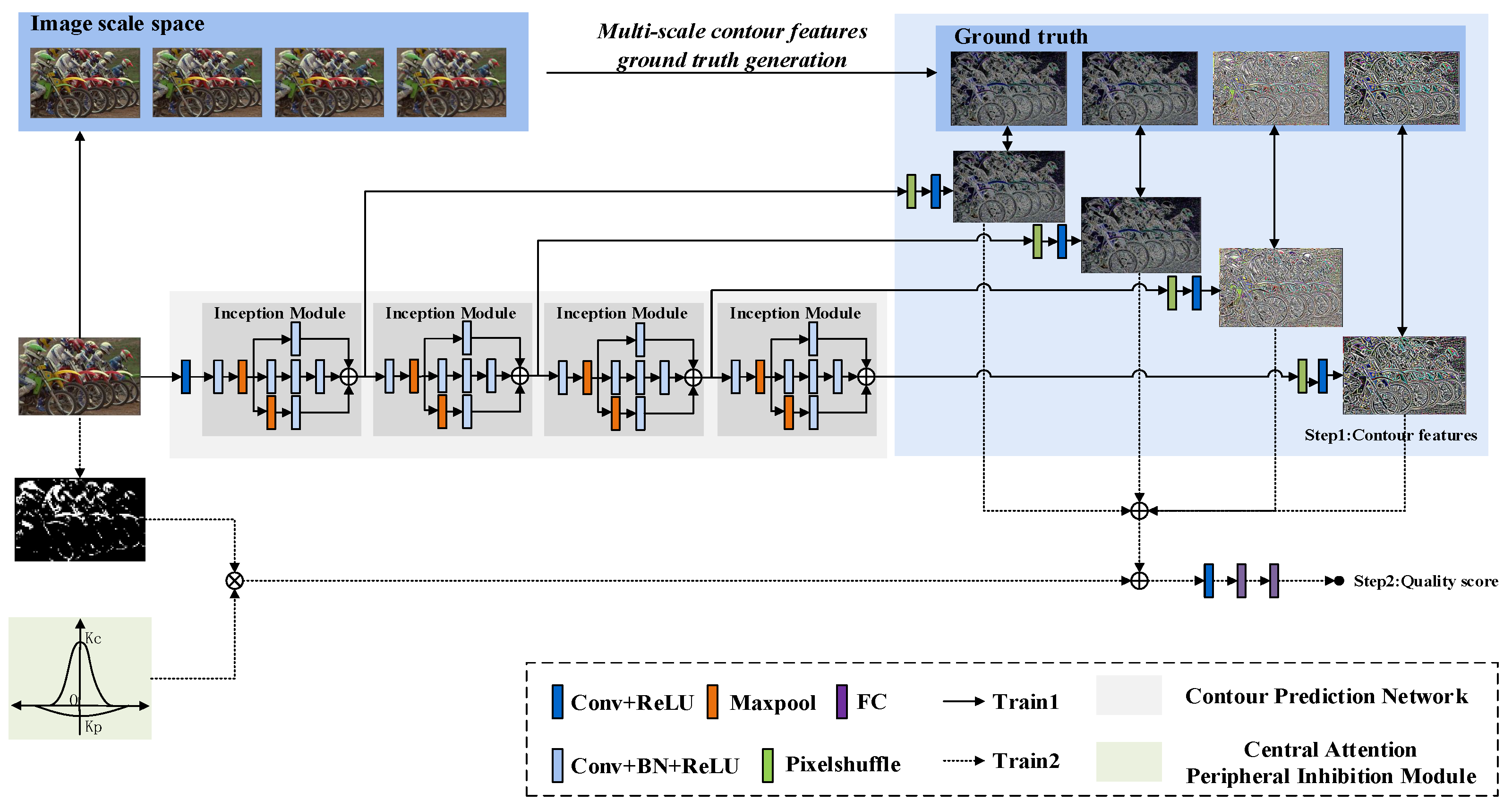
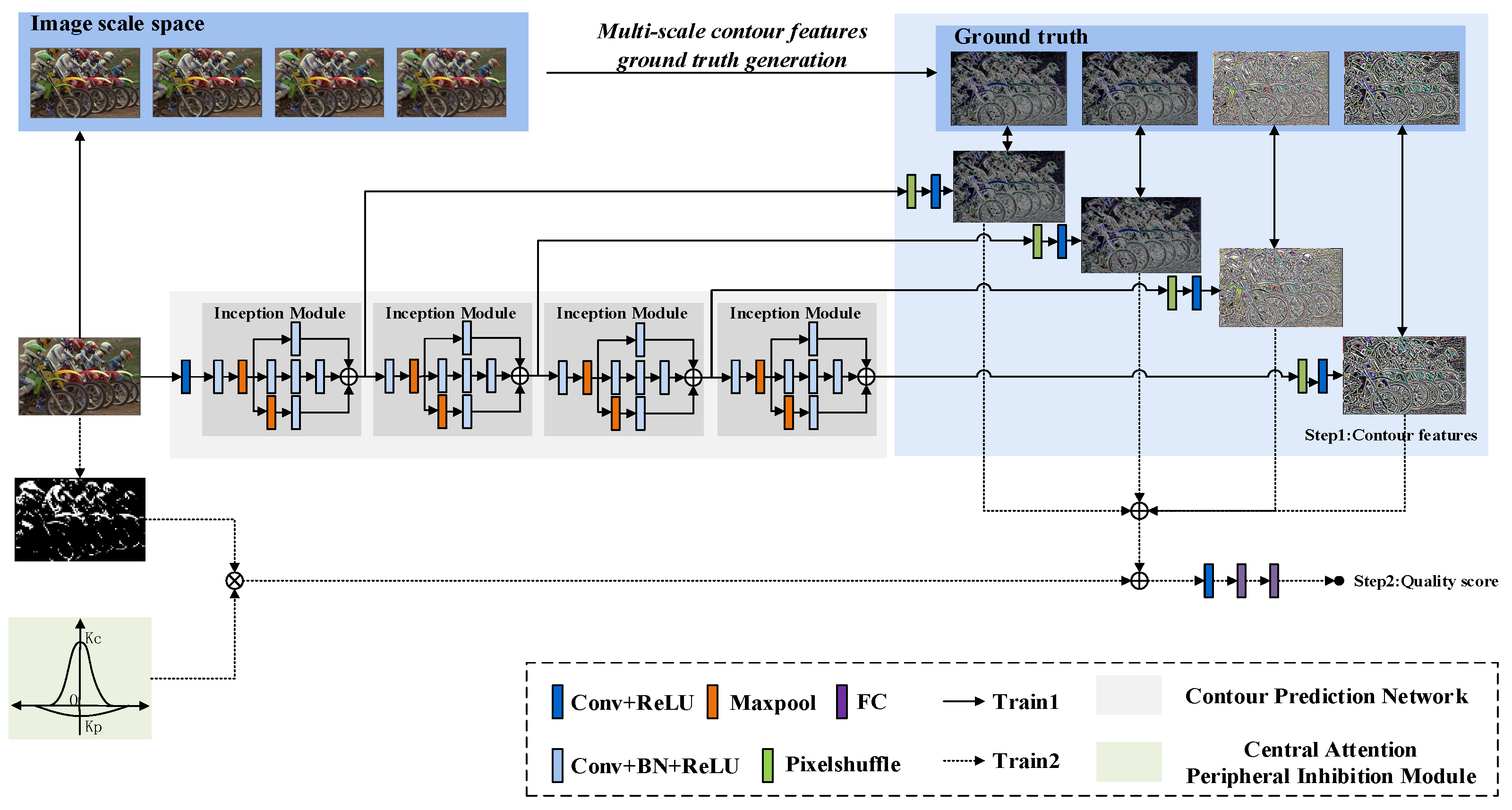
3.1. Model Architecture
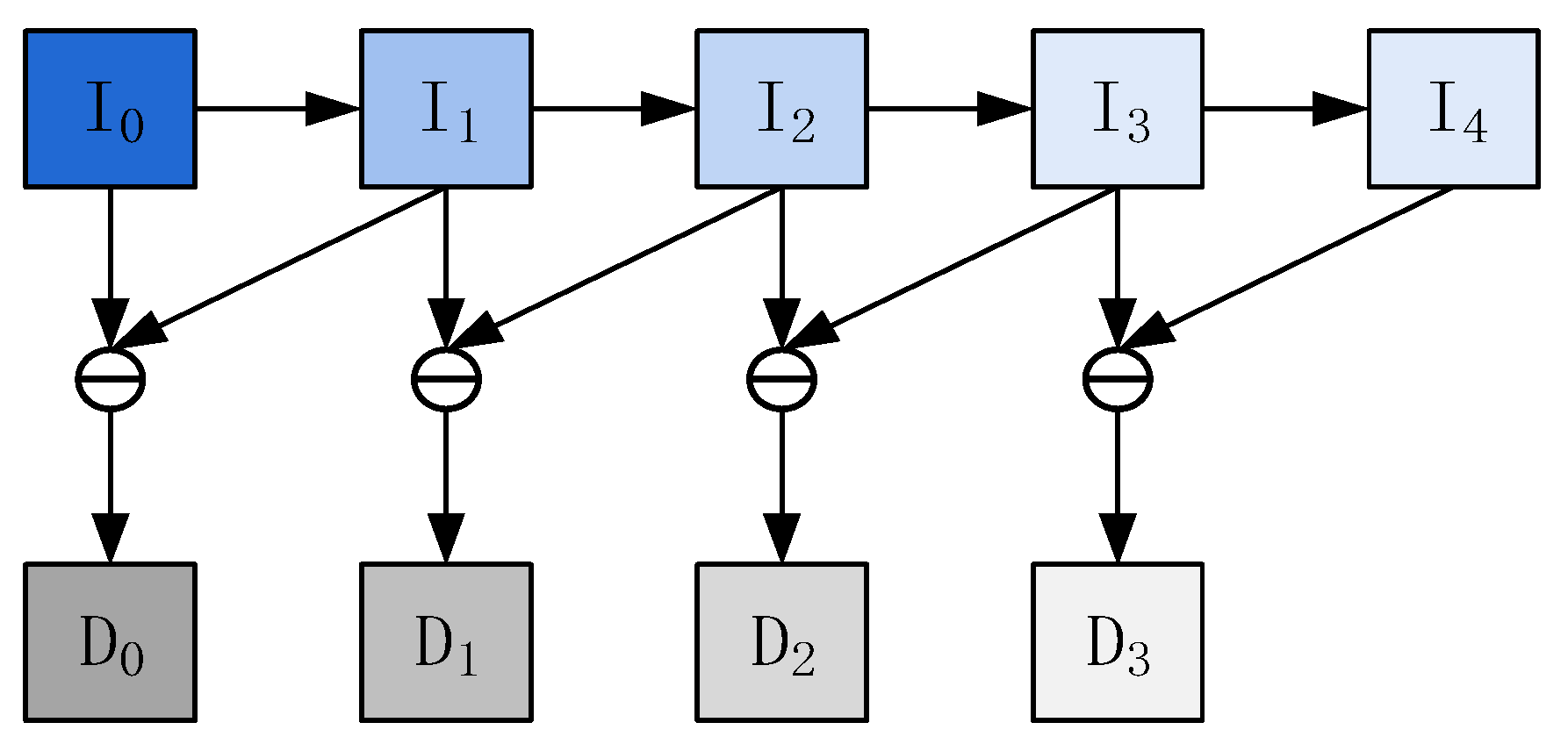
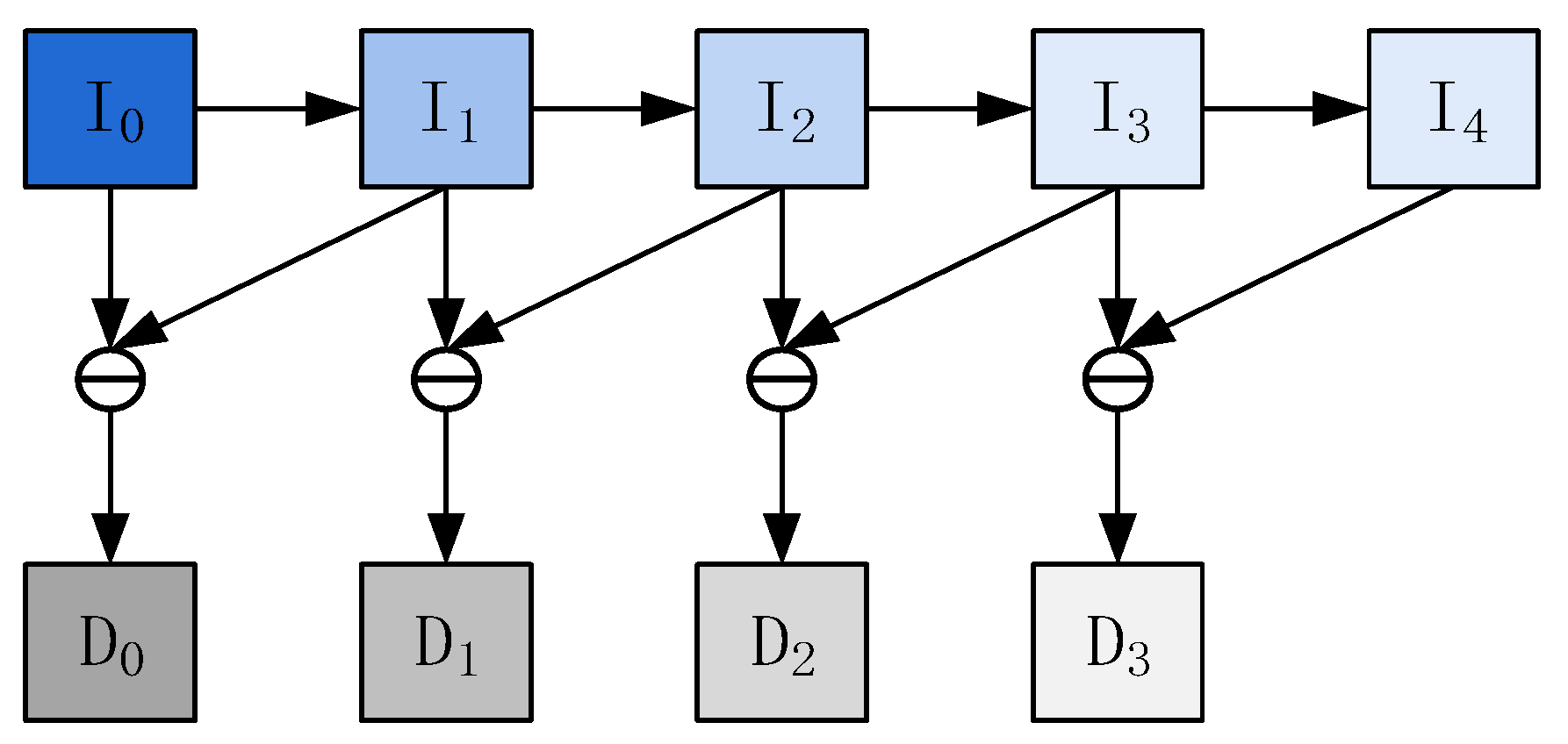
3.2. Multi-Scale Contour Features
3.3. Quality Score Prediction
3.4. Training
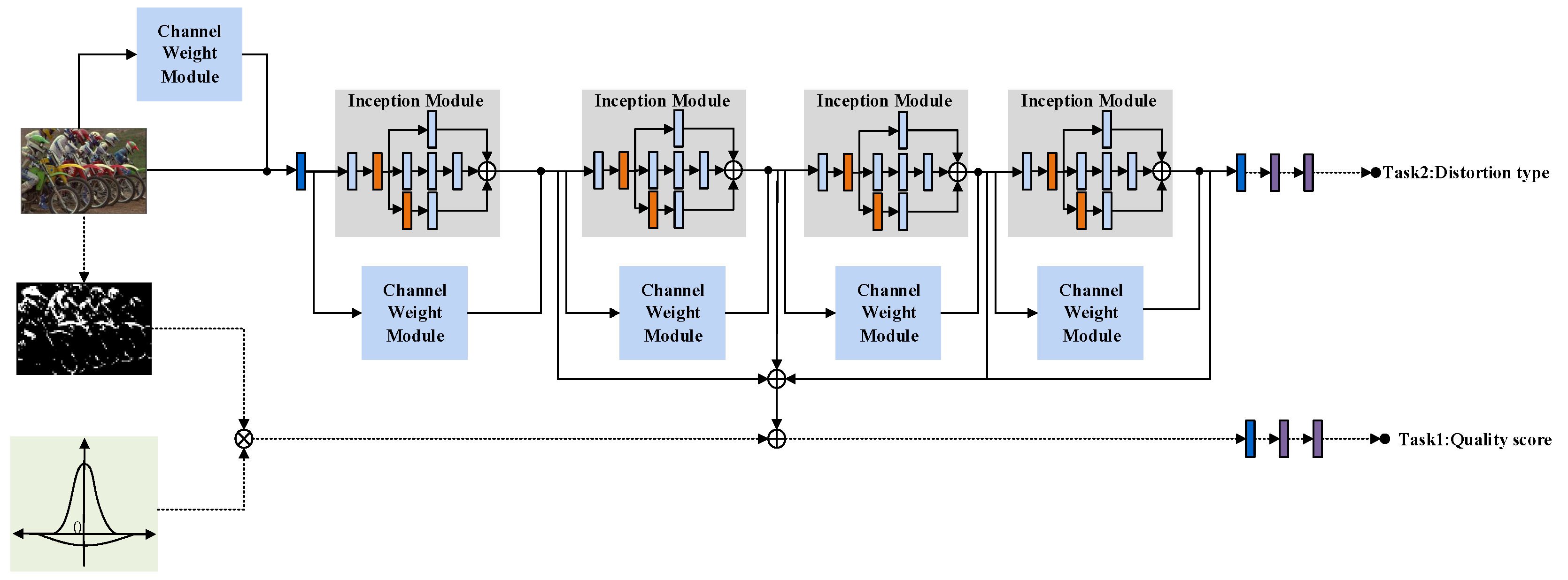
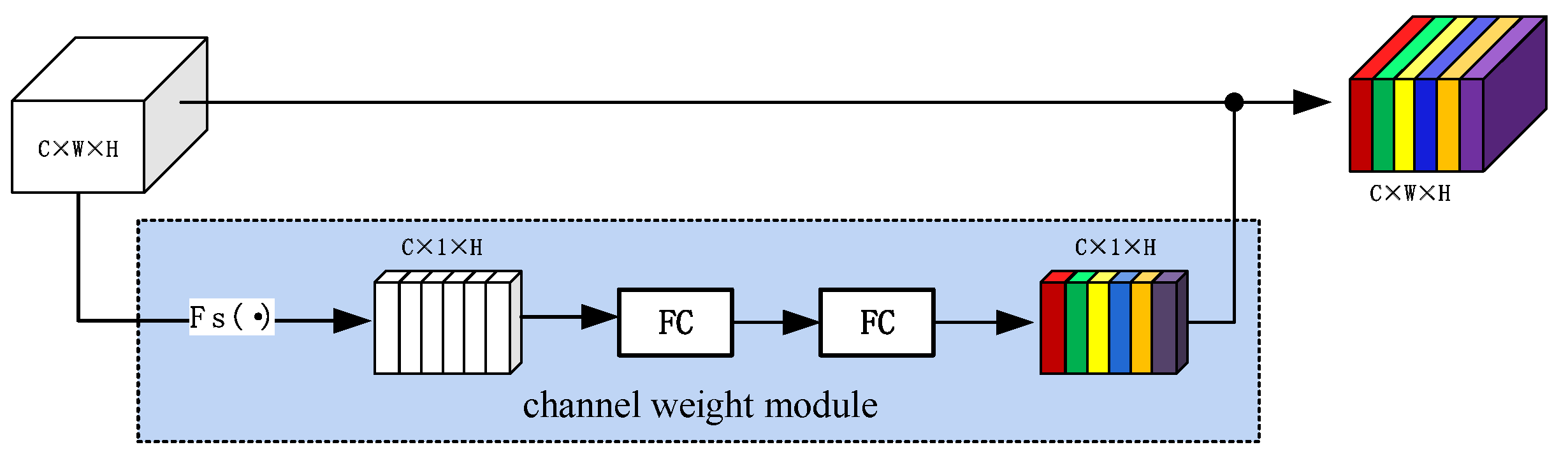
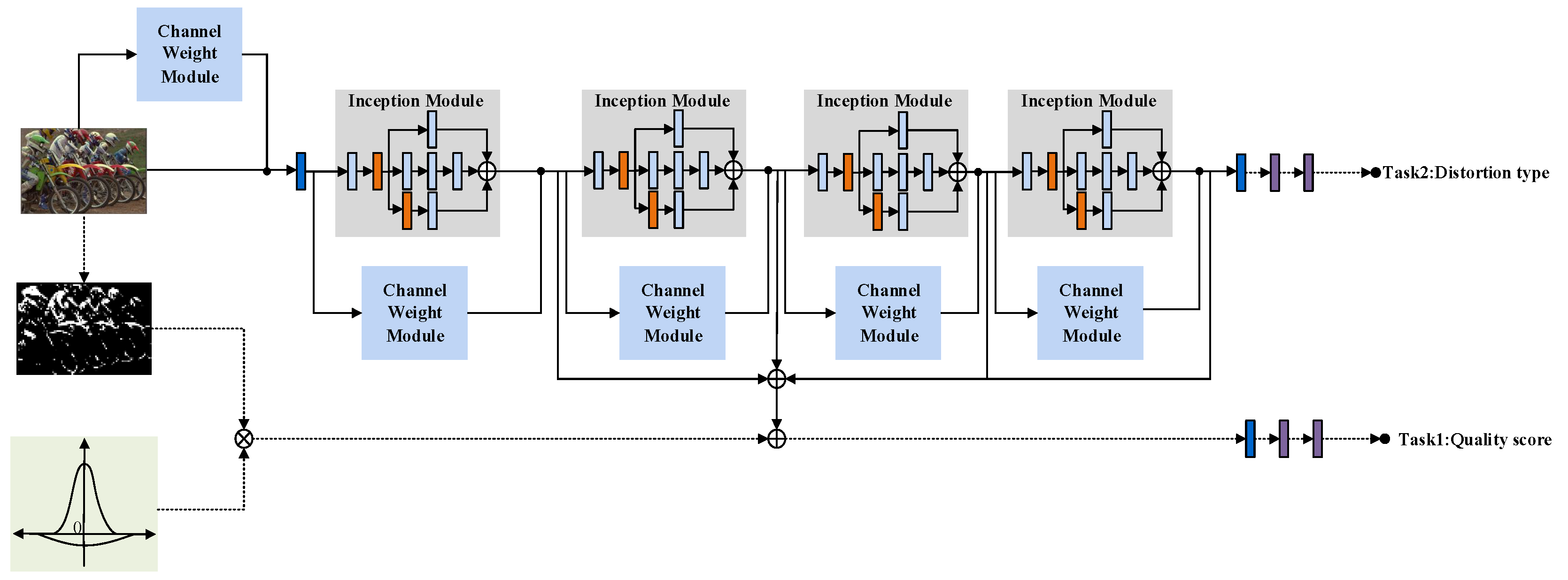
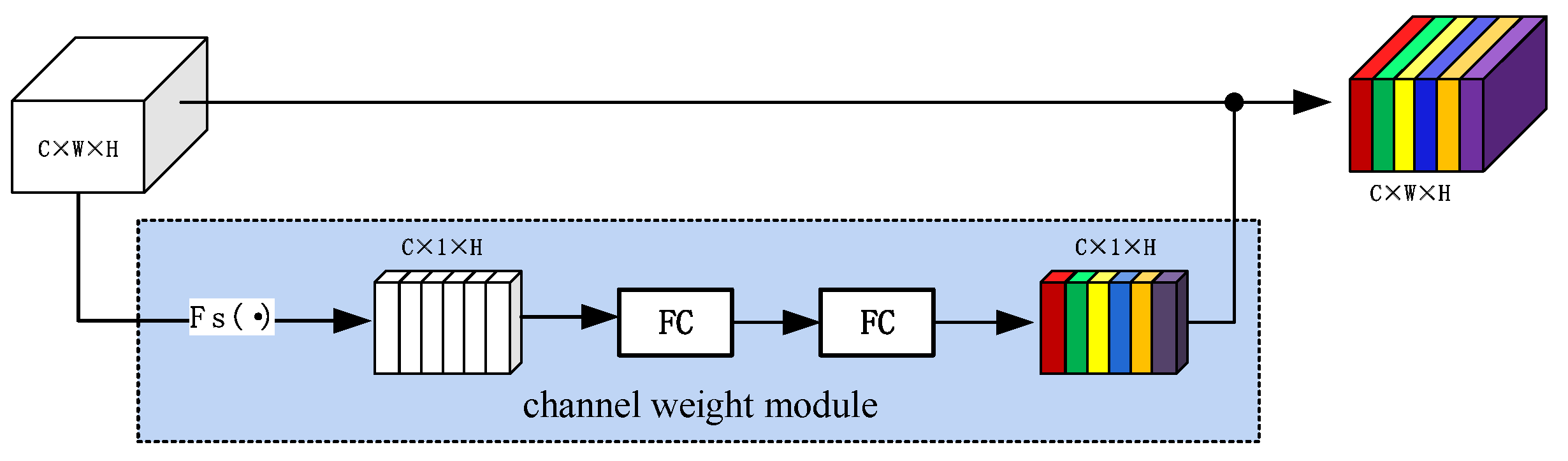
3.5. Multi-Task Model
4. Experiments and Analysis
4.1. Database and Evaluation Metrics
4.2. Convergence Test
4.3. Effect of Patch Size
4.4. Performances Comparison
4.5. Multi-Task Model Test
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zheng, H.; Sherazi, S.W.A.; Son, S.H.; Lee, J.Y. A Deep Convolutional Neural Network-Based Multi-Class Image Classification for Automatic Wafer Map Failure Recognition in Semiconductor Manufacturing. Appl. Sci. 2021, 11, 9769. [Google Scholar] [CrossRef]
- Wang, F.; Ai, Y.; Zhang, W. Detection of Early Dangerous State in Deep Water of Indoor Swimming Pool Based on Surveillance Video. Signal Image Video Process. 2021, 16, 29–37. [Google Scholar] [CrossRef]
- Chen, J.; Wang, F.; Li, C.; Zhang, Y.; Ai, Y.; Zhang, W. Online Multiple Object Tracking Using a Novel Discriminative Module for Autonomous Driving. Electronics 2021, 10, 2479. [Google Scholar] [CrossRef]
- Jimenez, V.J.; Bouhmala, N.; Gausdal, A.H. Developing a Predictive Maintenance Model for Vessel Machinery. J. Ocean Eng. Sci. 2020, 5, 358–386. [Google Scholar] [CrossRef]
- Zhou, T.; Wang, W.; Liang, Z.; Shen, J. Face Forensics in the Wild. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 5774–5784. [Google Scholar]
- Adebayo, A.-A.; Atinuke, O.; Onashoga, S.; Misra, S.; Arogundade, O.; Abayomi-Alli, O. Facial Image Quality Assessment Using an Ensemble of Pre-Trained Deep Learning Models (EFQnet). In Proceedings of the 2020 20th International Conference on Computational Science and Its Applications (ICCSA), Cagliari, Italy, 1–4 July 2020; pp. 1–8. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z.; Lei, Z.; Mou, X.; Zhang, D. FSIM: A Feature Similarity Index for Image Quality Assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind Image Quality Assessment: A Natural Scene Statistics Approach in the DCT Domain. IEEE Trans. Image Process. 2012, 21, 3339–3352. [Google Scholar] [CrossRef] [PubMed]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Simoncelli, E. Reduce-Reference Image Quality Assessment Using a Wavelet-Domain Natural Image Statistic Model. In Proceedings of the SPIE Elecronic Imaging Conference, San Jose, CA, USA, 16–20 January 2005; Volume 5666. [Google Scholar] [CrossRef] [Green Version]
- Soundararajan, R.; Bovik, A.C. RRED Indices: Reduced Reference Entropic Differencing for Image Quality Assessment. IEEE Trans. Image Process. 2012, 21, 517–526. [Google Scholar] [CrossRef] [Green Version]
- Wei, L.; Zhao, L.; Peng, J. Reduced Reference Quality Assessment for Image Retargeting by Earth Mover’s Distance. Appl. Sci. 2021, 11, 9776. [Google Scholar] [CrossRef]
- Kim, J.; Lee, S. Fully Deep Blind Image Quality Predictor. IEEE J. Sel. Top. Signal Process. 2017, 11, 206–220. [Google Scholar] [CrossRef]
- Kim, J.; Nguyen, A.-D.; Lee, S. Deep CNN-Based Blind Image Quality Predictor. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 11–24. [Google Scholar] [CrossRef] [PubMed]
- Moorthy, A.K.; Bovik, A.C. A Two-Step Framework for Constructing Blind Image Quality Indices. IEEE Signal Process. Lett. 2010, 17, 513–516. [Google Scholar] [CrossRef]
- Xue, W.; Mou, X.; Zhang, L.; Bovik, A.C.; Feng, X. Blind Image Quality Assessment Using Joint Statistics of Gradient Magnitude and Laplacian Features. IEEE Trans. Image Process. 2014, 23, 4850–4862. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Bovik, A.C. A Feature-Enriched Completely Blind Image Quality Evaluator. IEEE Trans. Image Process. 2015, 24, 2579–2591. [Google Scholar] [CrossRef] [Green Version]
- Wu, Q.; Wang, Z.; Li, H. A Highly Efficient Method for Blind Image Quality Assessment. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec, QC, Canada, 27–30 September 2015; pp. 339–343. [Google Scholar]
- Wu, Q.; Li, H.; Meng, F.; Ngan, K.N.; Luo, B.; Huang, C.; Zeng, B. Blind Image Quality Assessment Based on Multichannel Feature Fusion and Label Transfer. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 425–440. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]
- Ye, P.; Kumar, J.; Kang, L.; Doermann, D. Unsupervised Feature Learning Framework for No-Reference Image Quality Assessment. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1098–1105. [Google Scholar]
- Sheikh, H.R. LIVE Image Quality Assessment Database. 2003. Available online: http://live.ece.utexas.edu/research/quality (accessed on 4 April 2021).
- Ponomarenko, N.; Jin, L.; Ieremeiev, O.; Lukin, V.; Egiazarian, K.; Astola, J.; Vozel, B.; Chehdi, K.; Carli, M.; Battisti, F.; et al. Image Database TID2013: Peculiarities, Results and Perspectives. Signal Process. Image Commun. 2015, 30, 57–77. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Zeng, H.; Ghadiyaram, D.; Lee, S.; Zhang, L.; Bovik, A.C. Deep Convolutional Neural Models for Picture-Quality Prediction: Challenges and Solutions to Data-Driven Image Quality Assessment. IEEE Signal Process. Mag. 2017, 34, 130–141. [Google Scholar] [CrossRef]
- Le, K.; Peng, Y.; Yi, L.; Doermann, D. Convolutional Neural Networks for No-Reference Image Quality Assessment. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1733–1740. [Google Scholar]
- Bosse, S.; Maniry, D.; Muller, K.-R.; Wiegand, T.; Samek, W. Deep Neural Networks for No-Reference and Full-Reference. IEEE Trans. Image Process. 2018, 27, 206–219. [Google Scholar] [CrossRef] [Green Version]
- Bianco, S.; Celona, L.; Napoletano, P.; Schettini, R. On the Use of Deep Learning for Blind Image Quality Assessment. Signal Image Video Process. 2018, 12, 355–362. [Google Scholar] [CrossRef]
- Liu, X.; Weijer, J.; Bagdanov, A.D. RankIQA: Learning from Rankings for No-Reference Image Quality Assessment. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1040–1049. [Google Scholar]
- Talebi, H.; Milanfar, P. NIMA: Neural Image Assessment. IEEE Trans. Image Process. 2018, 27, 3998–4011. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 17–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. PixelShuffle: Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 18–20 June 2016; pp. 1874–1883. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Lin, K.; Wang, G. Hallucinated-IQA: No-Reference Image Quality Assessment via Adversarial Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 732–741. [Google Scholar]
- Golestaneh, S.A.; Kitani, K. No-Reference Image Quality Assessment via Feature Fusion and Multi-Task Learning. arXiv 2020, arXiv:2006.03783. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TID2013 | LIVE | Distortion Types |
|---|---|---|
| √ | √ | Additive Gaussian noise |
| √ | Additive noise in color components | |
| √ | Spatially correlated noise | |
| √ | Masked noise | |
| √ | High-frequency noise | |
| √ | Impulse noise | |
| √ | Quantization noise | |
| √ | √ | Gaussian blur |
| √ | Image denoising | |
| √ | √ | JPEG compression |
| √ | √ | JPEG2000 compression |
| √ | JPEG transmission errors | |
| √ | JPEG2000 transmission errors | |
| √ | Non- eccentricity pattern noise | |
| √ | Local block-wise distortions of different intensity | |
| √ | Mean shift (intensity shift) | |
| √ | Contrast change | |
| √ | Change of color saturation | |
| √ | Multiplicative Gaussian noise | |
| √ | Comfort noise | |
| √ | Lossy compression of noisy images | |
| √ | Image color quantization with dither | |
| √ | Chromatic aberrations | |
| √ | Sparse sampling and reconstruction | |
| √ | Fast-fading |
| Epoch Numbers in Step 1 | 5 | 10 | 15 | 20 | |
|---|---|---|---|---|---|
| Performance in step 2 | SRCC | 0.980 | 0.983 | 0.982 | 0.979 |
| PLCC | 0.985 | 0.988 | 0.986 | 0.982 | |
| Patch Size | 64 | 112 | 224 | 384 |
|---|---|---|---|---|
| SRCC | 0.983 | 0.983 | 0.979 | 0.963 |
| PLCC | 0.988 | 0.988 | 0.985 | 0.968 |
| Database | LIVE | TID2013 | |||
|---|---|---|---|---|---|
| Metrics | SRCC | PLCC | SRCC | PLCC | |
| FR | PSNR | 0.876 | 0.872 | 0.687 | 0.706 |
| SSIM | 0.948 | 0.945 | 0.775 | 0.790 | |
| FSIMc | 0.963 | 0.960 | 0.851 | 0.877 | |
| NR | BLINDS-II | 0.912 | 0.916 | 0.536 | 0.628 |
| BRISQUE | 0.939 | 0.942 | 0.573 | 0.651 | |
| CORNIA | 0.942 | 0.943 | 0.549 | 0.613 | |
| Kang | 0.956 | 0.953 | - | - | |
| BIECON | 0.961 | 0.962 | - | - | |
| Bosse | 0.960 | 0.972 | 0.835 | 0.855 | |
| DIQA | 0.975 | 0.977 | 0.825 | 0.850 | |
| Hallucinated | 0.982 | 0.982 | 0.879 | 0.880 | |
| QualNet | 0.980 | 0.984 | 0.890 | 0.901 | |
| MSIQA | 0.983 | 0.988 | 0.877 | 0.880 | |
| Type | PSNR | SSIM | FSIM | BRISQUE | CORNIA | BIECON | DIQA | MSIQA |
|---|---|---|---|---|---|---|---|---|
| JP2K | 0.895 | 0.961 | 0.972 | 0.914 | 0.921 | 0.965 | 0.961 | 0.983 |
| JPEG | 0.881 | 0.972 | 0.979 | 0.965 | 0.938 | 0.987 | 0.976 | 0.984 |
| WN | 0.985 | 0.969 | 0.971 | 0.977 | 0.957 | 0.970 | 0.988 | 0.998 |
| GB | 0.782 | 0.952 | 0.968 | 0.951 | 0.957 | 0.945 | 0.962 | 0.980 |
| FF | 0.891 | 0.956 | 0.950 | 0.877 | 0.906 | 0931 | 0.912 | 0.972 |
| Database | LIVE | TID2013 | ||||
|---|---|---|---|---|---|---|
| SRCC | PLCC | Accuracy | SRCC | PLCC | Accuracy | |
| MSIQA | 0.983 | 0.988 | - | 0.877 | 0.880 | - |
| MSIQA (multi-task) | 0.988 | 0.996 | 0.846 | 0.879 | 0.881 | 0.811 |
| Database | JP2K | JPEG | WN | GB | FF |
|---|---|---|---|---|---|
| LIVE | 0.987 | 0.760 | 0.833 | 0.846 | 0.836 |
| TID2013 | 0.887 | 0.701 | 0.812 | 0.801 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Chen, J.; Zhong, H.; Ai, Y.; Zhang, W. No-Reference Image Quality Assessment Based on Image Multi-Scale Contour Prediction. Appl. Sci. 2022, 12, 2833. https://doi.org/10.3390/app12062833
Wang F, Chen J, Zhong H, Ai Y, Zhang W. No-Reference Image Quality Assessment Based on Image Multi-Scale Contour Prediction. Applied Sciences. 2022; 12(6):2833. https://doi.org/10.3390/app12062833
Chicago/Turabian StyleWang, Fan, Jia Chen, Haonan Zhong, Yibo Ai, and Weidong Zhang. 2022. "No-Reference Image Quality Assessment Based on Image Multi-Scale Contour Prediction" Applied Sciences 12, no. 6: 2833. https://doi.org/10.3390/app12062833
APA StyleWang, F., Chen, J., Zhong, H., Ai, Y., & Zhang, W. (2022). No-Reference Image Quality Assessment Based on Image Multi-Scale Contour Prediction. Applied Sciences, 12(6), 2833. https://doi.org/10.3390/app12062833