Lightweight Deep Learning for Road Environment Recognition



Abstract
:Featured Application
Abstract
1. Introduction
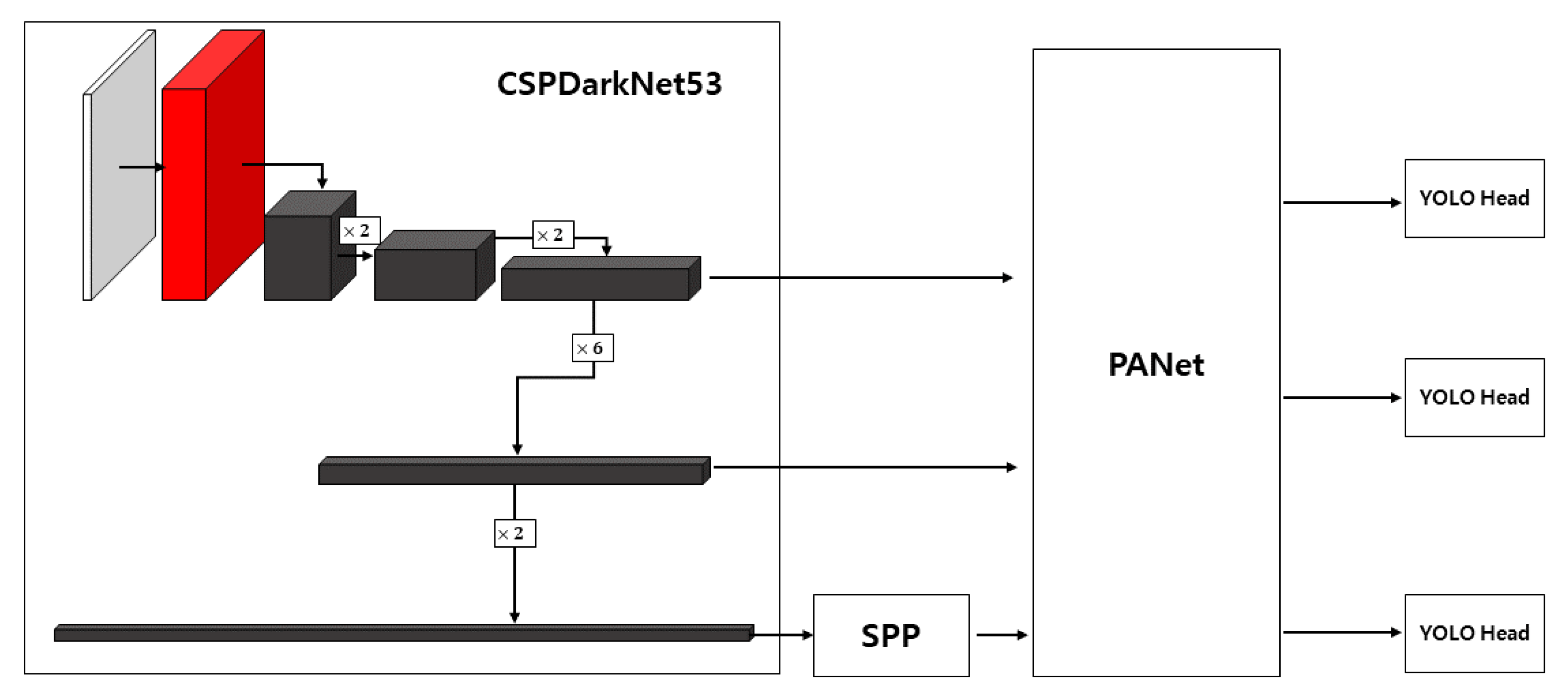
2. Related Work
3. Proposed Method
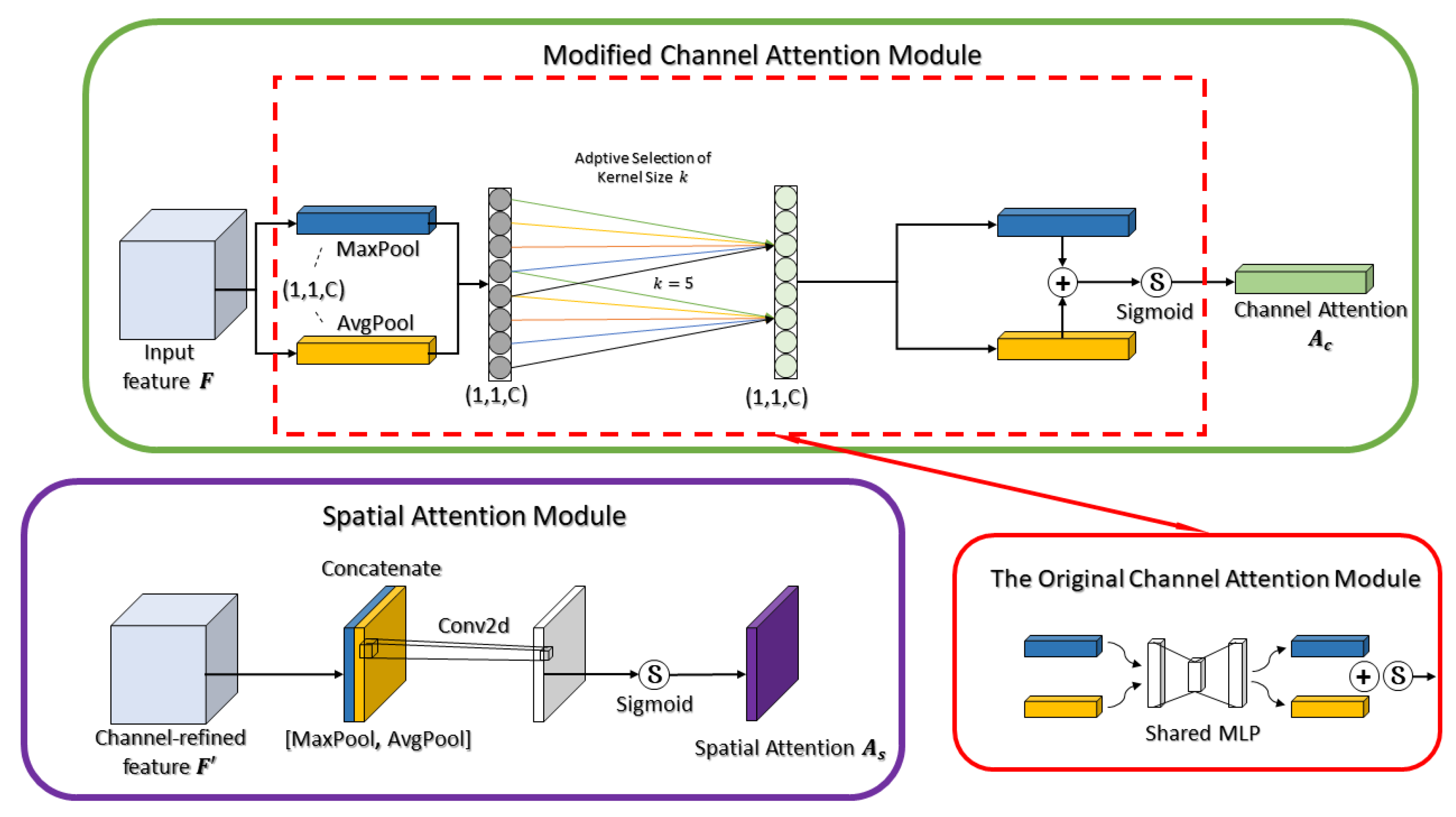
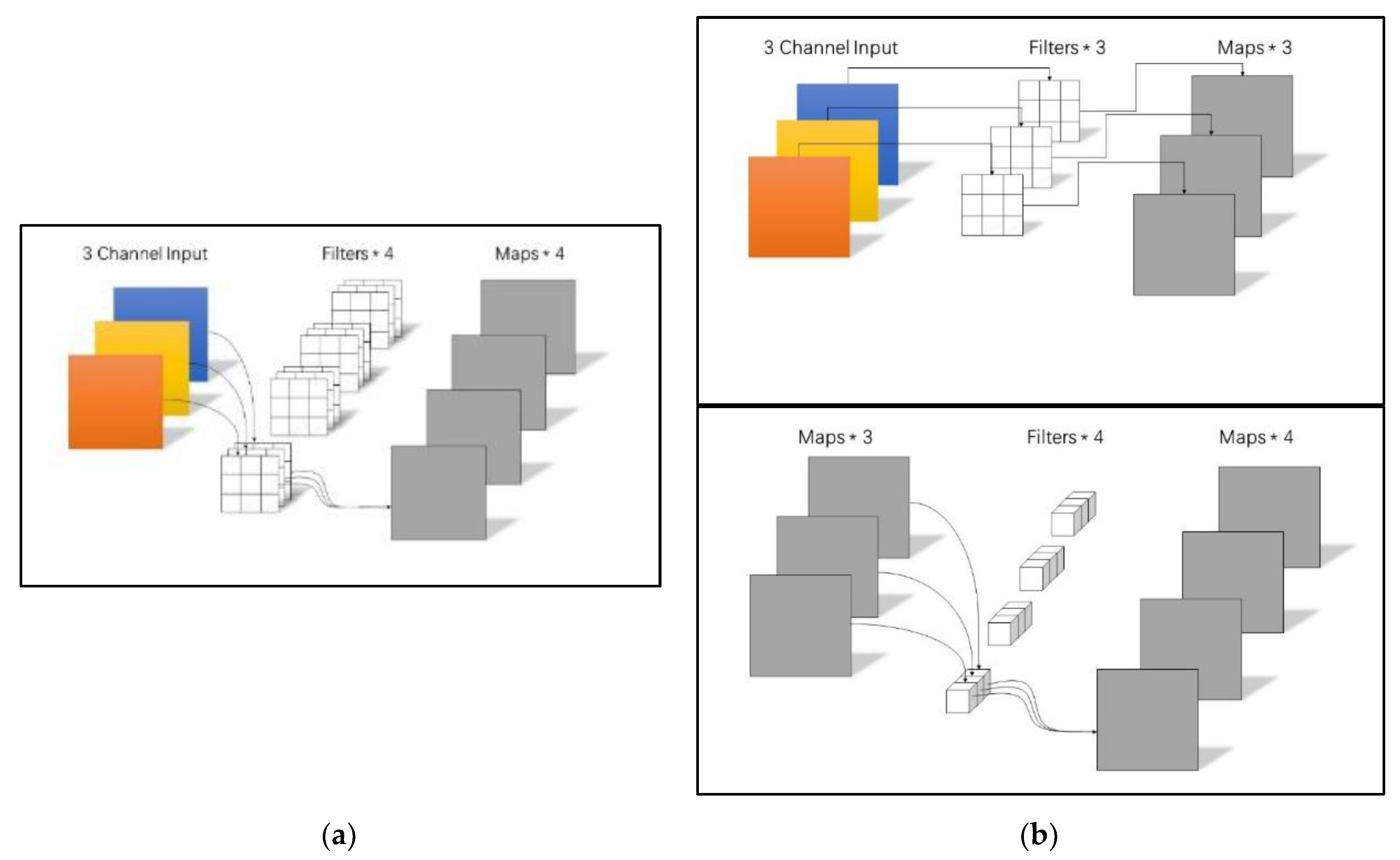
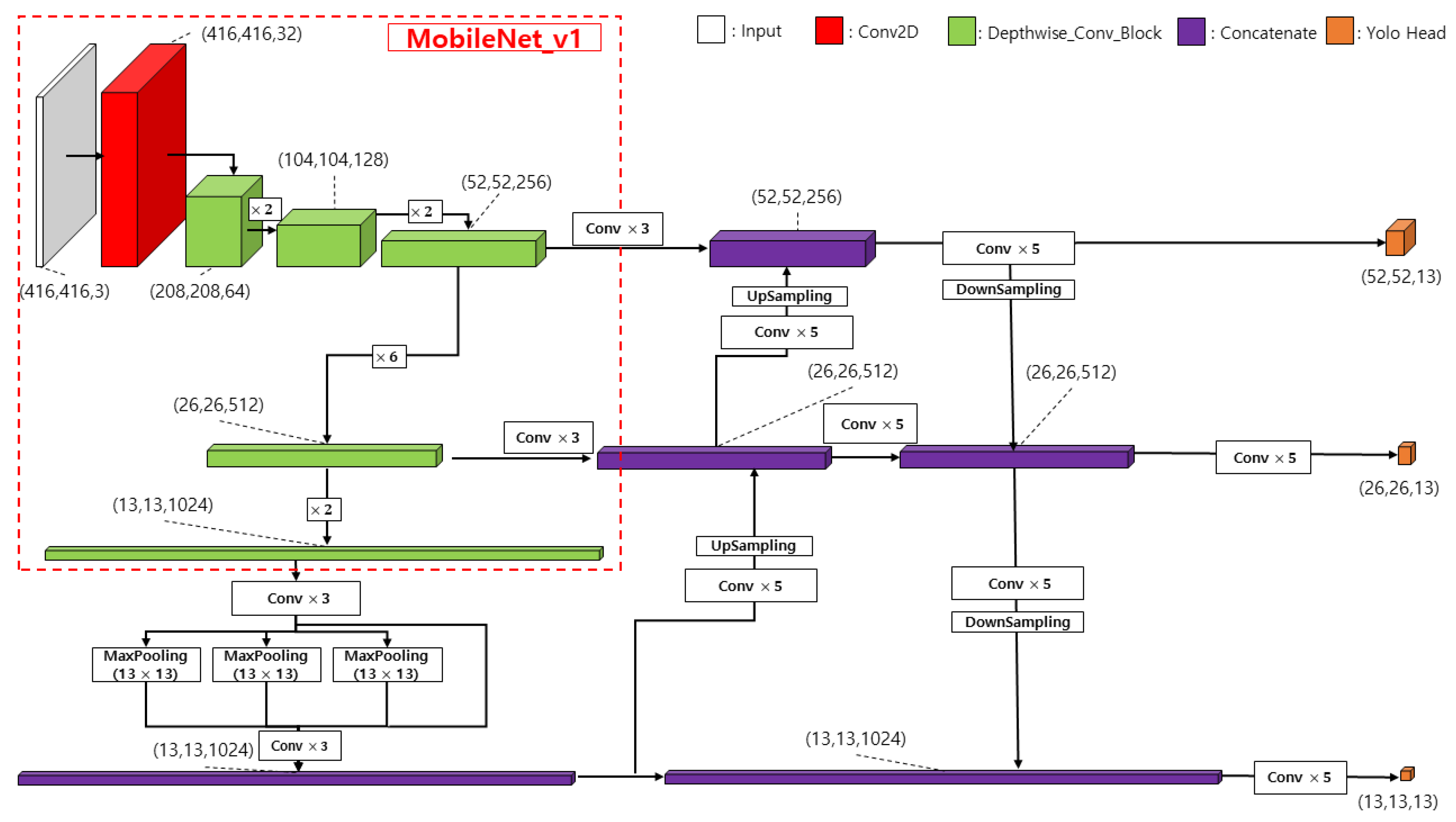
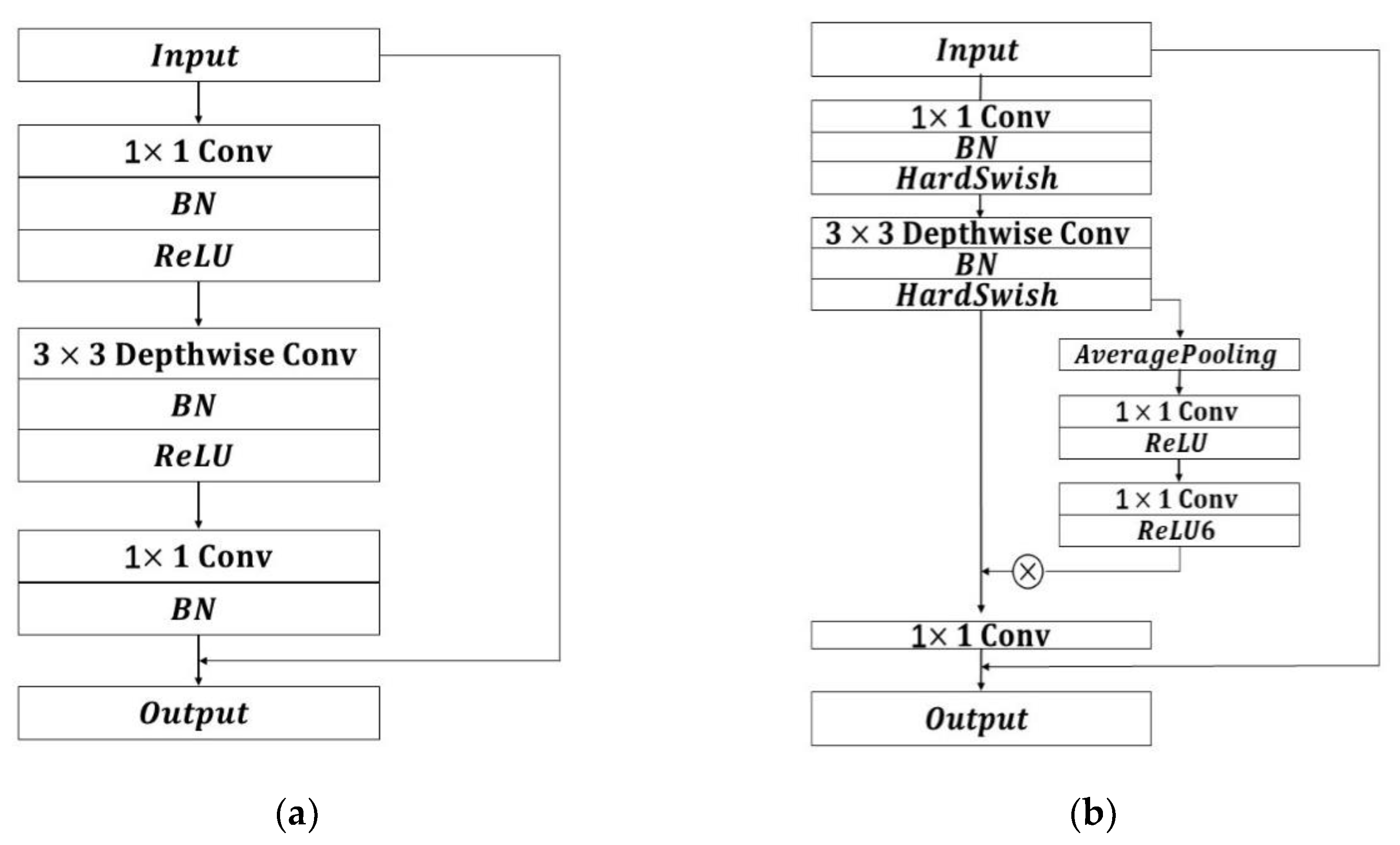
3.1. Lightweight Residual Convolutional Attention Network
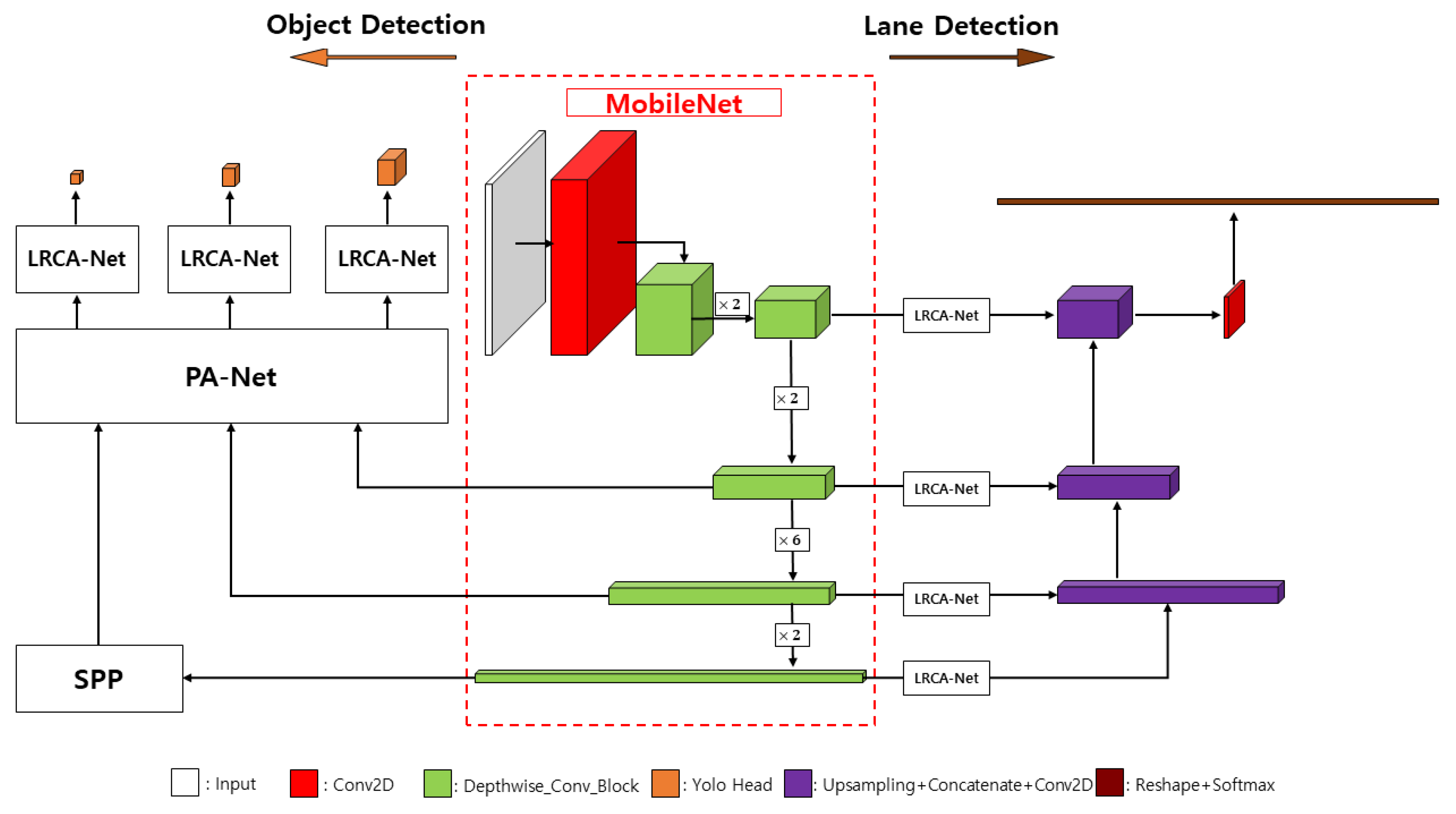
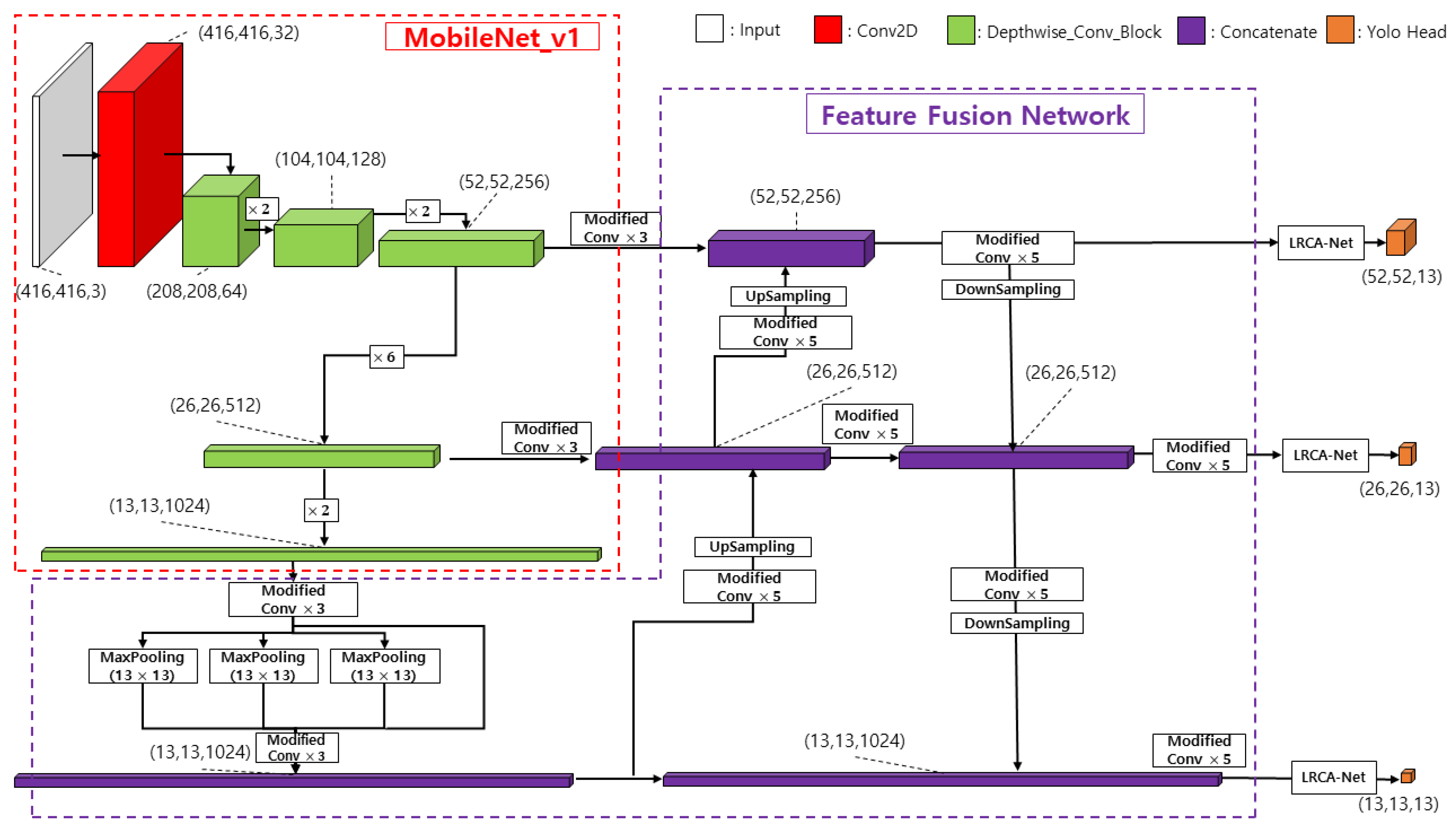
3.2. Object Detection Network
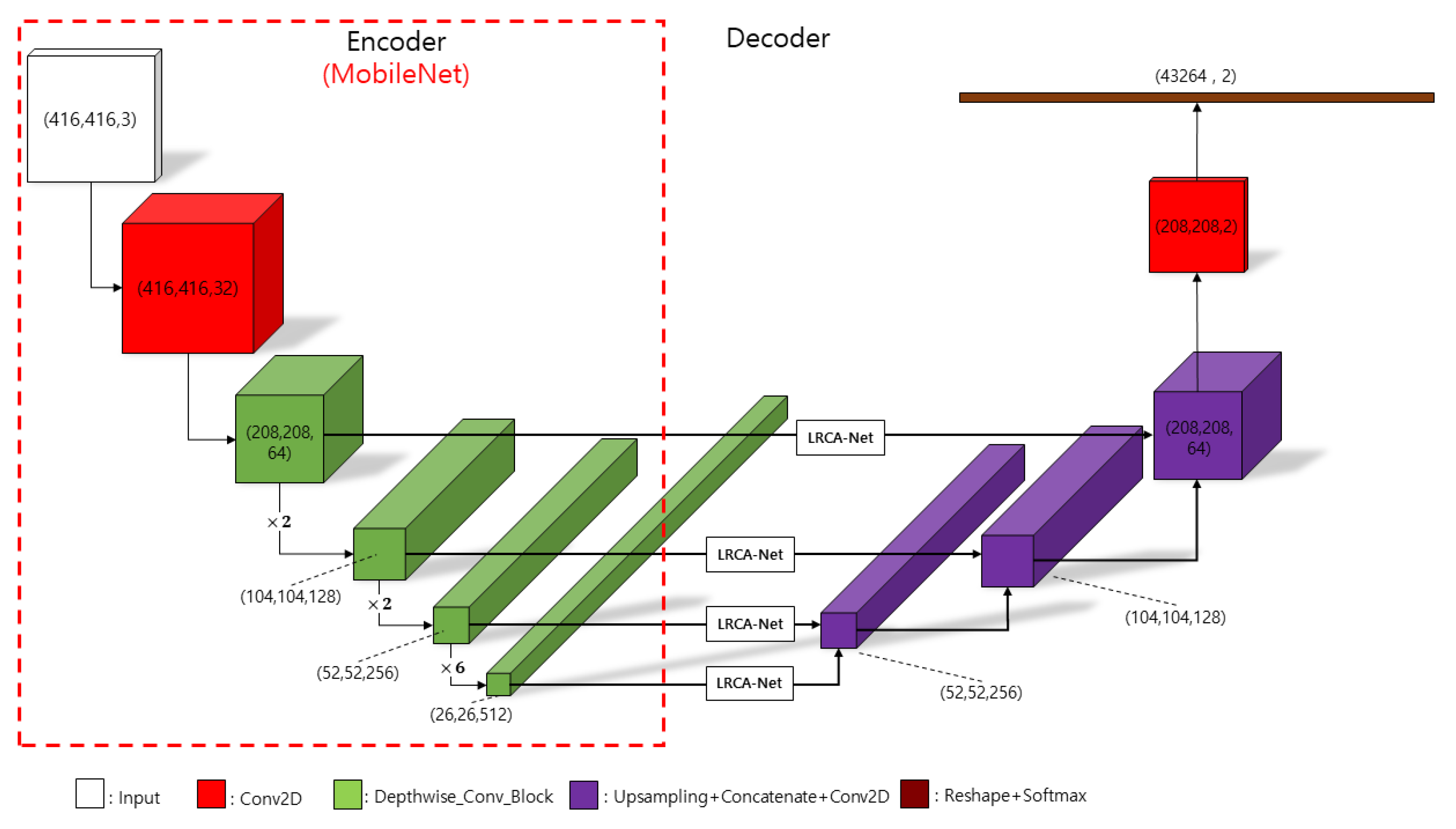
3.3. Lane Detection Network
4. Experimental Results
4.1. Experimental Dataset and Parameters Setting
4.2. Metrics
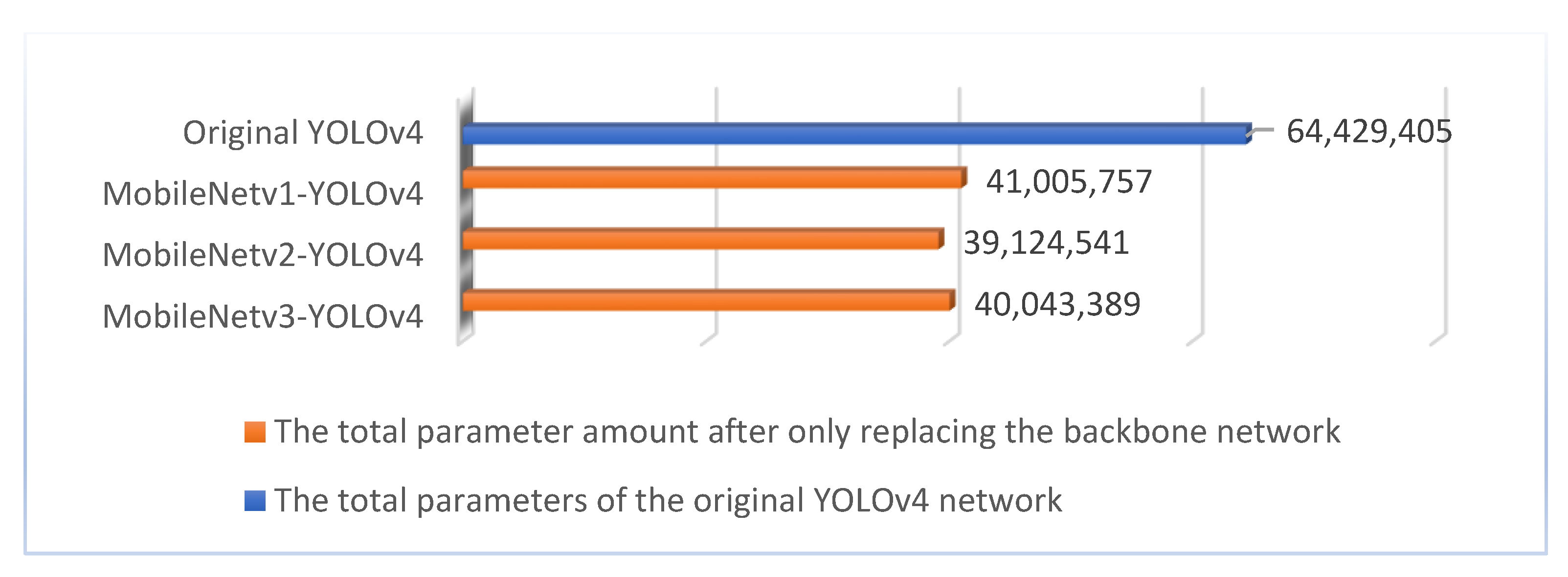
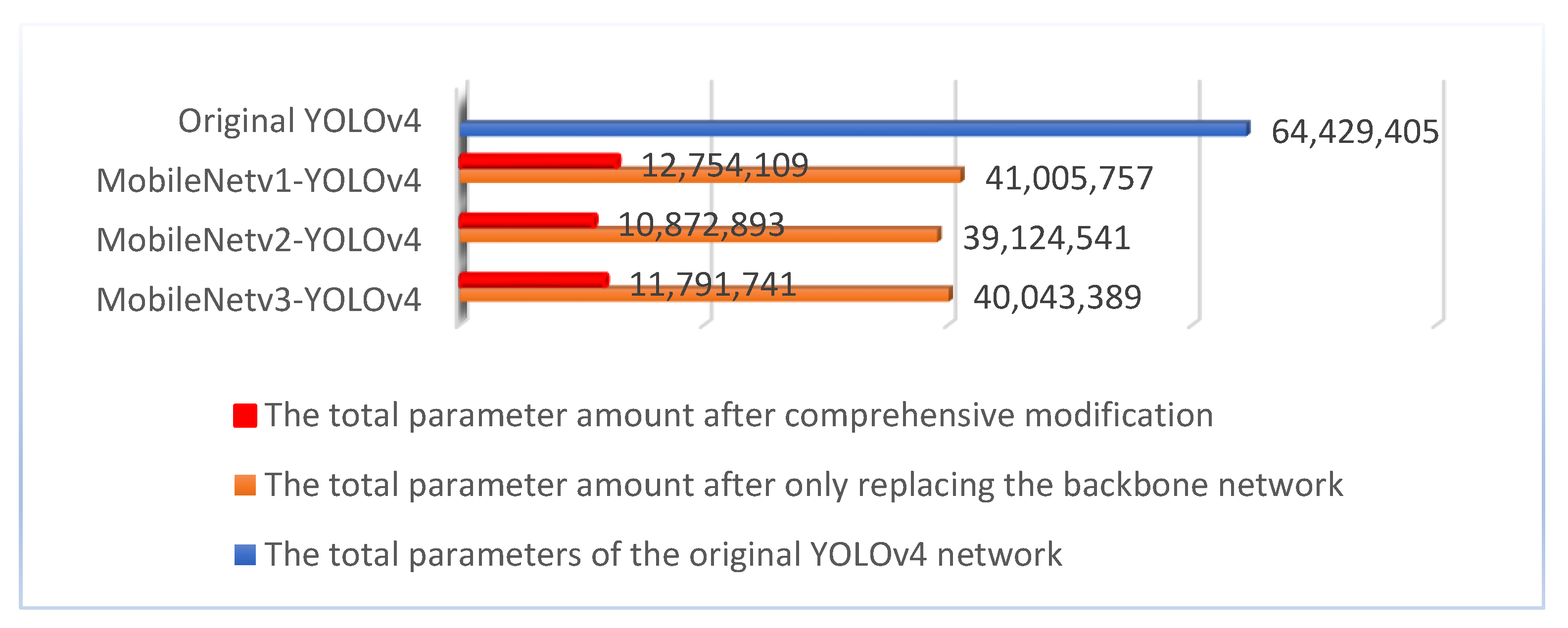
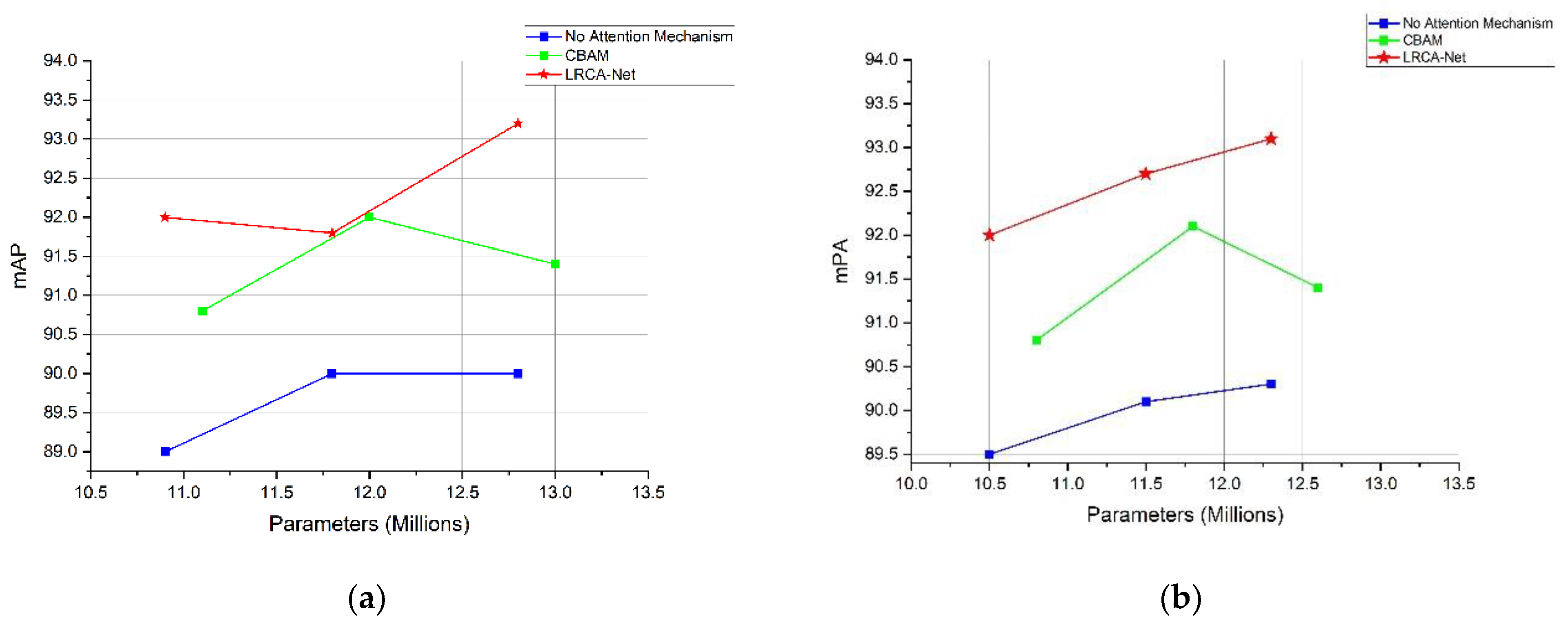
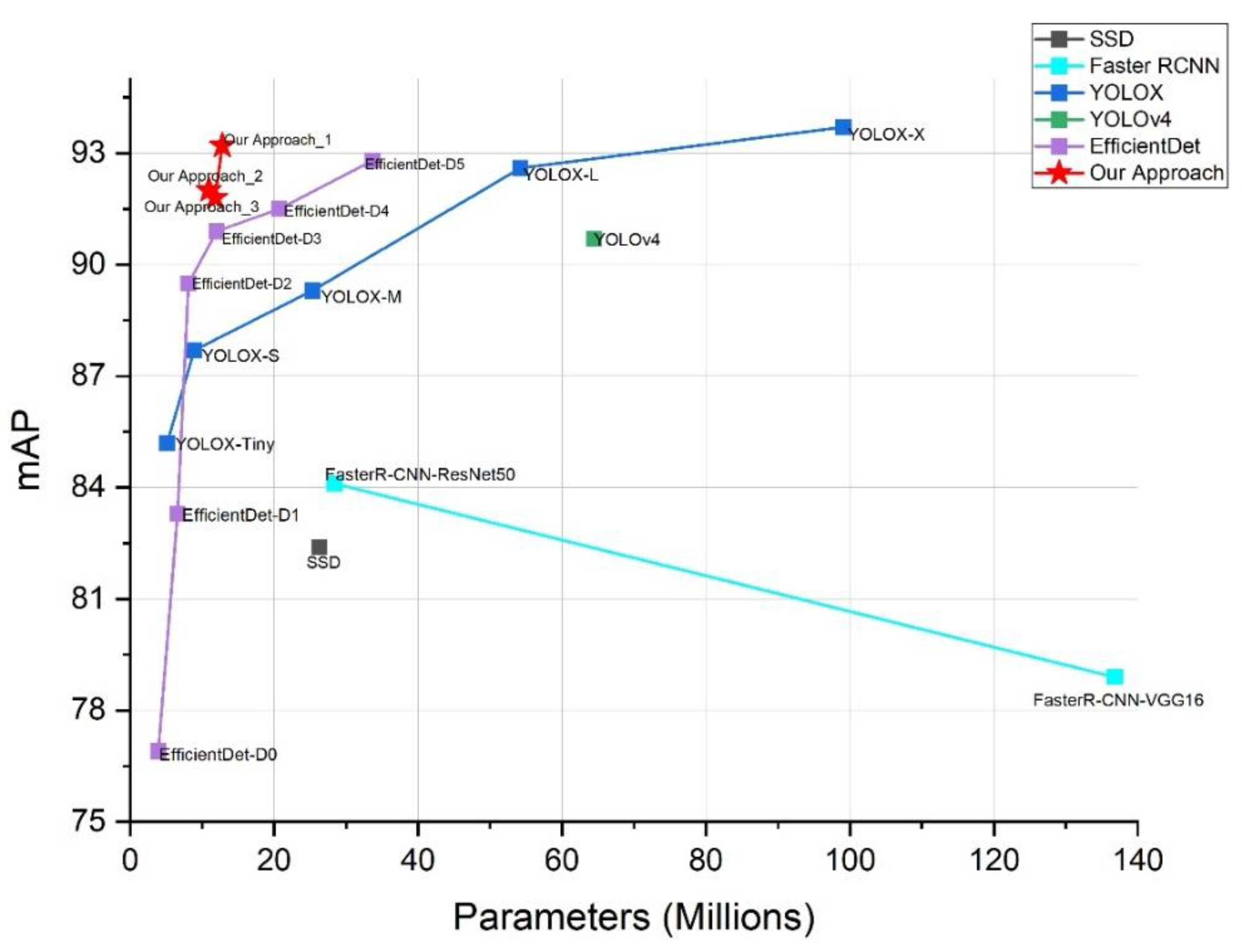
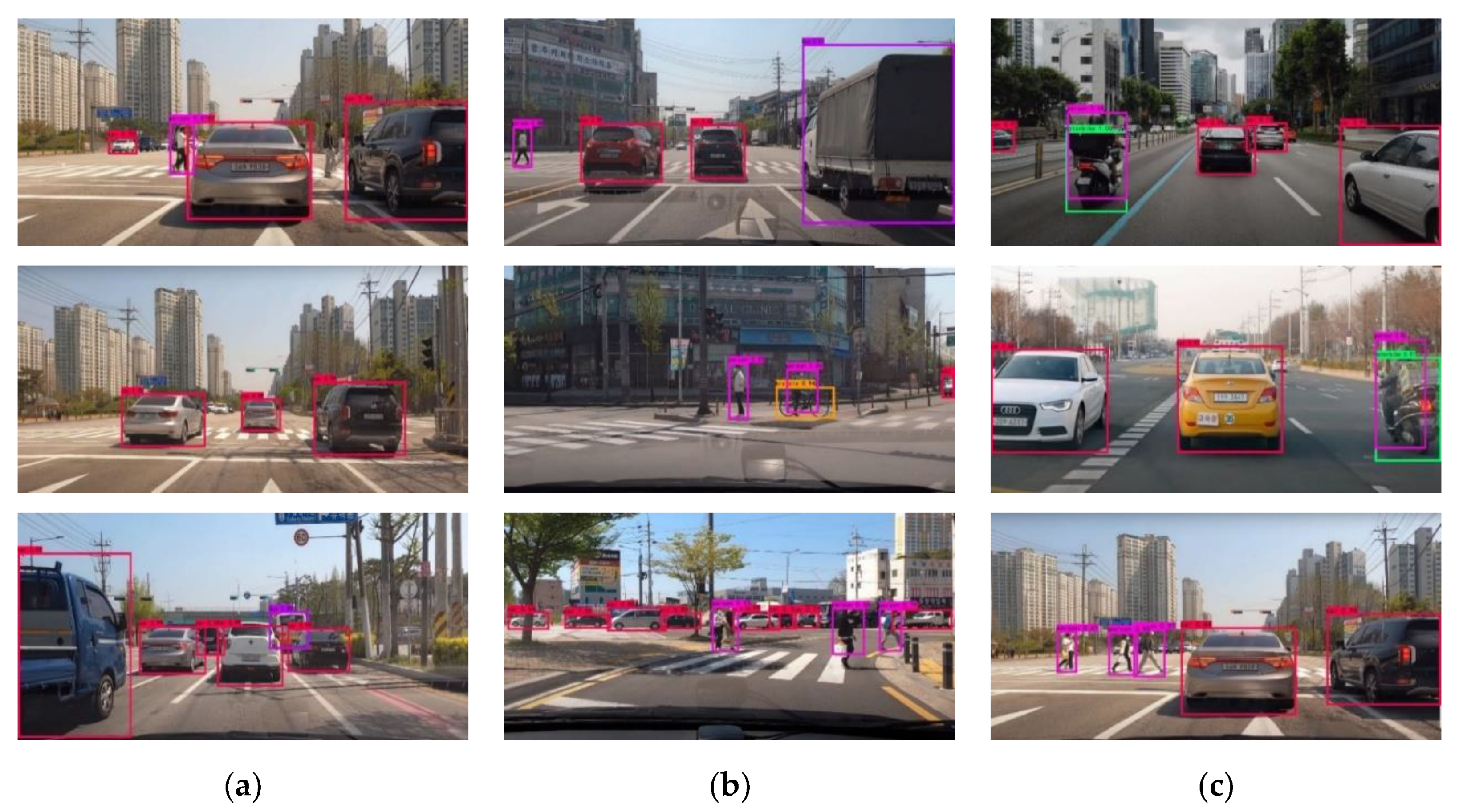
4.3. Experimental Result and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1. [Google Scholar]
- Yoo, H.; Yang, U.; Sohn, K. Gradient-enhancing. conversion for illumination-robust lane detection. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1083–1094. [Google Scholar] [CrossRef]
- Küçükmanisa, A.; Tarım, G.; Urhan, O. Real-time. illumination and shadow invariant lane detection on mobile platform. J. Real-Time Image Processing 2019, 16, 1781–1794. [Google Scholar] [CrossRef]
- Kortli, Y.; Marzougui, M.; Bouallegue, B.; Bose, J.S.C.; Rodrigues, P.; Atri, M. A novel illumination-invariant lane detection system. In Proceedings of the 2017 2nd International Conference on Anti-Cyber Crimes (ICACC), Abha, Saudi Arabia, 26–27 March 2017; pp. 166–171. [Google Scholar]
- Liang, H.; Seo, S. Lane Model Extraction Based on Combination of Color and Edge Information from Car Black-box Images. J. Korean Soc. Surv. Geod. Photogramm. Cartogr. 2021, 39, 1–11. [Google Scholar]
- Zhou, S.; Jiang, Y.; Xi, J.; Gong, J.; Xiong, G.; Chen, H. A novel lane detection based on geometrical model and gabor filter. In Proceedings of the 2010 IEEE Intelligent Vehicles Symposium, La Jolla, CA, USA, 21–24 June 2010; pp. 59–64. [Google Scholar]
- Joshy, N.; Jose, D. Improved detection and tracking of lane marking using hough transform. IJCSMC 2014, 3, 507–513. [Google Scholar]
- Jung, C.R.; Kelber, C.R. Lane following and lane departure using a linear-parabolic model. Image Vis. Comput. 2005, 23, 1192–1202. [Google Scholar] [CrossRef]
- Niu, J.; Lu, J.; Xu, M.; Lv, P.; Zhao, X. Robust lane detection using two-stage feature extraction with curve fitting. Pattern Recognit. 2016, 59, 225–233. [Google Scholar] [CrossRef]
- Chen, W.; Wang, W.; Wang, K.; Li, Z.; Li, H.; Liu, S. Lane departure warning systems and lane line detection methods based on image processing and semantic segmentation: A review. J. Traffic Transp. Eng. 2020, 7, 748–774. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Processing Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Xu, H.; Wang, S.; Cai, X.; Zhang, W.; Liang, X.; Li, Z. Curvelane-nas: Unifying lane-sensitive architecture search and adaptive point blending. In European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 689–704. [Google Scholar]
- Wang, H.; Jiang, X.; Ren, H.; Hu, Y.; Bai, S. Swiftnet: Real-time video object segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1296–1305. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Itti, L.; Koch, C. Computational. modelling of visual attention. Nat. Rev. Neurosci. 2001, 2, 194–203. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11531–11539. [Google Scholar]
- Frankle, J.; Carbin, M. The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv 2018, arXiv:1803.03635. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Adam, H. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Smirnov, E.A.; Timoshenko, D.M.; Andrianov, S.N. Comparison of regularization methods for imagenet classification with deep convolutional neural networks. Aasri Procedia 2014, 6, 89–94. [Google Scholar] [CrossRef]
- Xing, Y.; Lv, C.; Wang, H.; Cao, D.; Velenis, E. An ensemble deep learning approach for driver lane change intention inference. Transp. Res. Part C Emerg. Technol. 2020, 115, 102615. [Google Scholar] [CrossRef]
- Zou, Q.; Jiang, H.; Dai, Q.; Yue, Y.; Chen, L.; Wang, Q. Robust. lane detection from continuous driving scenes using deep neural networks. IEEE Trans. Veh. Technol. 2019, 69, 41–54. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Segnet, R.C. A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Layer | Output Shape | Parameters | Total Parameters |
|---|---|---|---|---|
| CBAM | Input | 26 × 26 × 512 | 0 | 65,634 |
| Global Average Pooling (Input) | 1 × 1 × 512 | 0 | ||
| Global Max Pooling (Input) | 1 × 1 × 512 | 0 | ||
| Channel Attention_FC1 (GAP, GMP) | 1 × 1 × 64 | 32,768 | ||
| Channel Attention_FC2 (FC1(GAP), FC1(GMP)) | 1 × 1 × 512 | 32,768 | ||
| Add (CA_FC2) | 1 × 1 × 512 | 0 | ||
| Activation (Sigmoid)_1 (Add) | 1 × 1 × 512 | 0 | ||
| Multiply_1 (Input, Activation_1) | 26 × 26 × 512 | 0 | ||
| Average Pooling (Multiply_1) | 26 × 26 × 1 | 0 | ||
| Max Pooling (Multiply_1) | 26 × 26 × 1 | 0 | ||
| Concatenate (AP, MP) | 26 × 26 × 2 | 0 | ||
| Spatial Attention (Concatenate) | 26 × 26 × 1 | 98 | ||
| Activation (Sigmoid)_2 (SA) | 26 × 26 × 1 | 0 | ||
| Multiply_2 (Multiply_1, Activation_2) | 26 × 26 × 512 | 0 | ||
| LRCA-Net | Input | 26 × 26 × 512 | 0 | 108 |
| Global Average Pooling (Input) | 1 × 1 × 512 | 0 | ||
| Global Max Pooling (Input) | 1 × 1 × 512 | 0 | ||
| Channel Attention_1DConv 1 (GAP) | 1 × 1 × 512 | 5 | ||
| Channel Attention_1DConv 2 (GMP) | 1 × 1 × 512 | 5 | ||
| Add_1 (Channel Attention_1DConv 1, Channel Attention_1DConv 2) | 1 × 1 × 512 | 0 | ||
| Activation (Sigmoid)_3 (Add_1) | 1 × 1 × 512 | 0 | ||
| Multiply_3 (Input, Activation_3) | 26 × 26 × 512 | 0 | ||
| Average Pooling (Multiply_3) | 26 × 26 × 1 | 0 | ||
| Max Pooling (Multiply_3) | 26 × 26 × 1 | 0 | ||
| Concatenate (AP, MP) | 26 × 26 × 2 | 0 | ||
| Spatial Attention (Concatenate) | 26 × 26 × 1 | 98 | ||
| Activation (Sigmoid)_4 (SA) | 26 × 26 × 1 | 0 | ||
| Multiply_4 (Multiply_3, Activation_4) | 26 × 26 × 512 | 0 | ||
| Add_2 (Input, Multiply_4) | 26 × 26 × 512 | 0 |
| Category | Color |
|---|---|
| Lane | |
| Fence | |
| Construction | |
| Traffic Sign | |
| Car | |
| Truck | |
| Vegetation |
| Items | Description | |
|---|---|---|
| H/W | CPU | Intel(R) Core(TM) i7-10700 |
| RAM | 32 GB | |
| SSD | Samsung SSD 512 GB | |
| Graphics Card | NVIDIA GeForce GTX 1650 | |
| S/W | Operating System | Windows 10 Pro, 64bit |
| Programming Language | Python 3.6 | |
| Learning Framework | TensorFlow 1.13.2 | |
| API | Keras 2.1.5 | |
| Method | Backbone | AP | mAP | Parameters (Millions) | ||||
|---|---|---|---|---|---|---|---|---|
| Bus | Bicycle | Motorbike | Person | Car | ||||
| No attention mechanism | MobileNetv1 | 90.3 | 92.8 | 88.5 | 88.2 | 90.2 | 90 | 12.8 |
| MobileNetv2 | 89.7 | 91.1 | 89.1 | 88.5 | 90.6 | 89 | 10.9 | |
| MobileNetv3 | 89.4 | 90.2 | 92.3 | 88.4 | 89.7 | 90 | 11.8 | |
| CBAM | MobileNetv1 | 92 | 91 | 88 | 90 | 90.2 | 91.4 | 13 |
| MobileNetv2 | 93.6 | 91.7 | 92.2 | 89.2 | 87.3 | 90.8 | 11.1 | |
| MobileNetv3 | 92.5 | 92.3 | 90 | 90.1 | 91.7 | 92 | 12 | |
| LRCA-Net | MobileNetv1 | 95.4 | 94.7 | 92.6 | 92.1 | 90.2 | 93.2 | 12.8 |
| MobileNetv2 | 94.3 | 93.2 | 93.4 | 91.7 | 87.4 | 92 | 10.9 | |
| MobileNetv3 | 94.5 | 92.6 | 92.7 | 91.1 | 89.1 | 91.8 | 11.8 | |
| Method | Backbone | PA | mPA | Parameters (Millions) | |
|---|---|---|---|---|---|
| Lane | Background | ||||
| No attention mechanism | MobileNetv1 | 92.4 | 88.2 | 90.3 | 12.3 |
| MobileNetv2 | 91.7 | 87.3 | 89.5 | 10.5 | |
| MobileNetv3 | 928 | 87.4 | 90.1 | 11.5 | |
| CBAM | MobileNetv1 | 93.3 | 89.5 | 91.4 | 12.6 |
| MobileNetv2 | 91.5 | 90.1 | 90.8 | 10.8 | |
| MobileNetv3 | 93.7 | 90.5 | 92.1 | 11.8 | |
| LRCA-Net | MobileNetv1 | 95.5 | 90.7 | 93.1 | 12.3 |
| MobileNetv2 | 92.9 | 91.1 | 92 | 10.5 | |
| MobileNetv3 | 95.1 | 90.3 | 92.7 | 11.5 | |
| Method | Input Size | Backbone | mAP | Parameters (Millions) | FPS |
|---|---|---|---|---|---|
| SSD | 300 × 300 | VGG16 | 82.4 | 26.3 | 15 |
| Faster RCNN-VGG16 | 600 × 600 | VGG16 | 78.9 | 136.8 | 3 |
| Faster R-CNN-ResNet50 | 600 × 600 | ResNet50 | 84.1 | 28.4 | 13 |
| YOLOX-Tiny | 640 × 640 | Modified CSP | 85.2 | 5.1 | 72 |
| YOLOX-S | 640 × 640 | Modified CSP | 87.7 | 8.9 | 41 |
| YOLOX-M | 640 × 640 | Modified CSP | 89.3 | 25.3 | 14 |
| YOLOX-L | 640 × 640 | Modified CSP | 92.6 | 54.2 | 6 |
| YOLOX-X | 640 × 640 | Modified CSP | 93.7 | 99.1 | 3 |
| YOLOv4 | 416 × 416 | CSPDark-53 | 90.7 | 64.4 | 5 |
| EfficientDet-D0 | 512 × 512 | Efficient-B0 | 76.9 | 3.9 | 96 |
| EfficientDet-D1 | 640 × 640 | Efficient-B1 | 83.3 | 6.6 | 70 |
| EfficientDet-D2 | 768 × 768 | Efficient-B2 | 89.5 | 8.1 | 42 |
| EfficientDet-D3 | 896 × 896 | Efficient-B3 | 90.9 | 12 | 30 |
| EfficientDet-D4 | 1024 × 1024 | Efficient-B4 | 91.5 | 20.7 | 18 |
| EfficientDet-D5 | 1280 × 1280 | Efficient-B5 | 92.8 | 33.7 | 11 |
| Our Approach-1 | 416 × 416 | MobileNetv1 | 93.2 | 12.8 | 29 |
| Our Approach-2 | 416 × 416 | MobileNetv2 | 92 | 10.9 | 34 |
| Our Approach-3 | 416 × 416 | MobileNetv3 | 91.8 | 11.8 | 32 |
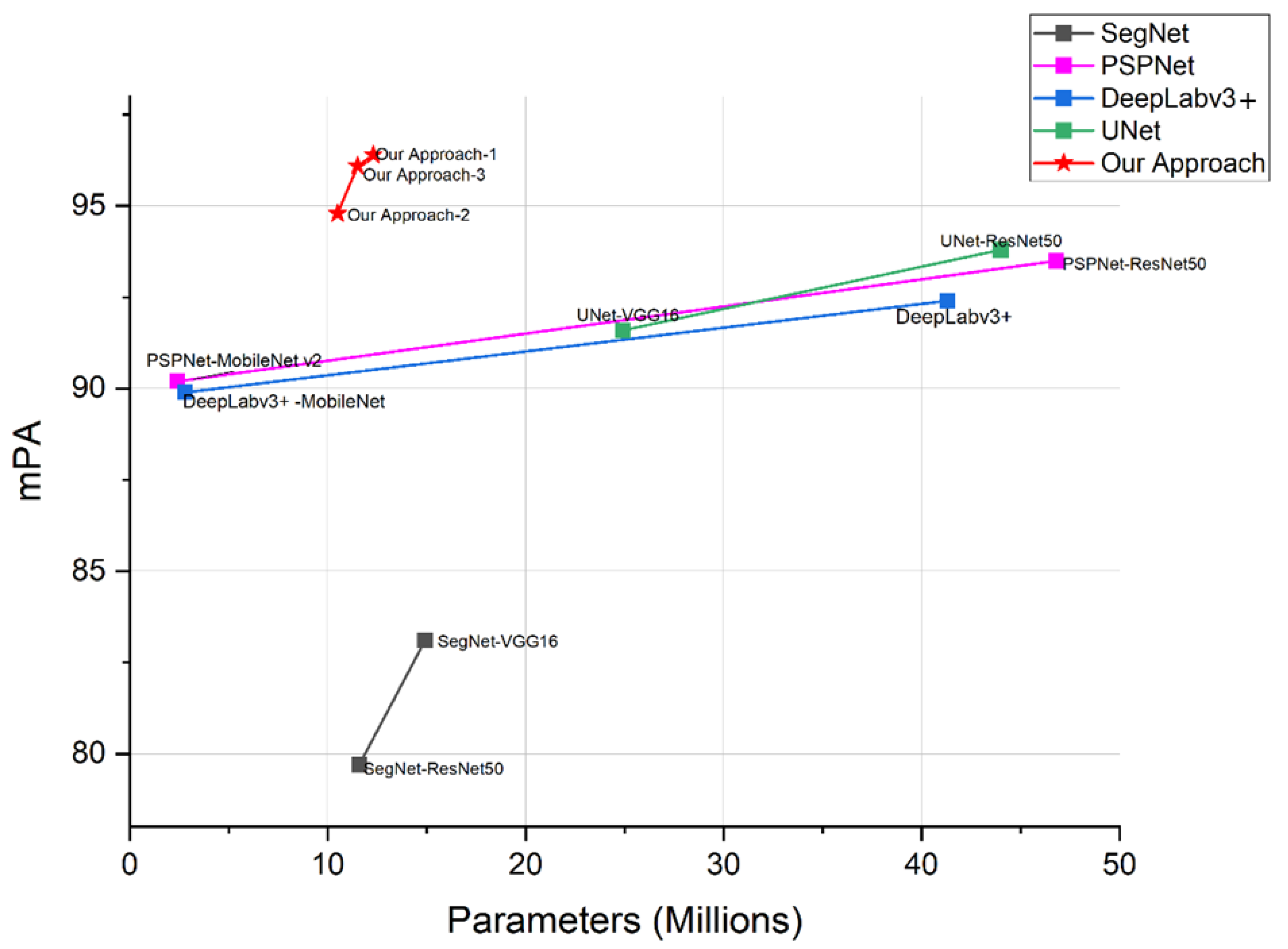
| Method | Input Size | Backbone | mPA | Parameters (Millions) | FPS |
|---|---|---|---|---|---|
| SegNet-VGG16 | 416 × 416 | VGG16 | 79.7 | 11.6 | 32 |
| SegNet-ResNet50 | 416 × 416 | ResNet50 | 83.1 | 14.9 | 24 |
| PSPNet-ResNet50 | 473 × 473 | ResNet50 | 93.5 | 46.8 | 8 |
| PSPNet-MobileNetv2 | 473 × 473 | MobileNetv2 | 90.2 | 2.4 | 150 |
| DeepLabv3+ | 512 × 512 | Xception | 92.4 | 41.3 | 9 |
| DeepLabv3+-MobileNetv2 | 512 × 512 | MobileNetv2 | 89.9 | 2.8 | 130 |
| UNet-VGG16 | 512 × 512 | VGG16 | 91.6 | 24.9 | 15 |
| UNet-ResNet50 | 512 × 512 | ResNet50 | 93.8 | 44 | 8 |
| Our Approach-1 | 512 × 512 | MobileNetv1 | 96.4 | 12.3 | 30 |
| Our Approach-2 | 512 × 512 | MobileNetv2 | 94.8 | 10.5 | 35 |
| Our Approach-3 | 512 × 512 | MobileNetv3 | 96.1 | 11.5 | 33 |
| Method | Lane | Fence | Construction | Traffic Sign | Car | Truck | Vegetation | mIoU |
|---|---|---|---|---|---|---|---|---|
| SegNet-VGG16 | 62.2 | 71.2 | 83 | 69.7 | 79 | 84.6 | 91.4 | 77.3 |
| SegNet-ResNet50 | 73.4 | 70.5 | 89.2 | 68.1 | 82.9 | 89.4 | 92.8 | 80.9 |
| PSPNet-ResNet50 | 89.4 | 93.6 | 84.3 | 95.1 | 90.7 | 94.5 | 90.8 | 91.2 |
| PSPNet-MobileNetv2 | 87.2 | 93.7 | 85.6 | 90 | 89.5 | 90.4 | 82.4 | 88.4 |
| DeepLabv3+ | 86.1 | 92.1 | 81.6 | 84.9 | 86.4 | 92.1 | 86.5 | 87.1 |
| DeepLabv3+-MobileNetv2 | 86.5 | 91.4 | 79.5 | 82.1 | 83.5 | 89.2 | 94.7 | 86.7 |
| UNet-VGG16 | 87.3 | 88.5 | 90.7 | 88.1 | 84.4 | 89 | 94.3 | 88.9 |
| UNet-ResNet50 | 89.6 | 89.2 | 91.3 | 88.7 | 90.1 | 90.5 | 94.1 | 91.5 |
| Our Approach-1 | 93.7 | 94.3 | 88.4 | 90.4 | 93.8 | 95 | 97.5 | 93.3 |
| Our Approach-2 | 91.5 | 92.8 | 87.1 | 92.7 | 91.9 | 92.6 | 98.9 | 92.5 |
| Our Approach-3 | 92.8 | 94.4 | 91 | 91.7 | 93.5 | 94.3 | 83.5 | 91.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, H.; Seo, S. Lightweight Deep Learning for Road Environment Recognition. Appl. Sci. 2022, 12, 3168. https://doi.org/10.3390/app12063168
Liang H, Seo S. Lightweight Deep Learning for Road Environment Recognition. Applied Sciences. 2022; 12(6):3168. https://doi.org/10.3390/app12063168
Chicago/Turabian StyleLiang, Han, and Suyoung Seo. 2022. "Lightweight Deep Learning for Road Environment Recognition" Applied Sciences 12, no. 6: 3168. https://doi.org/10.3390/app12063168
APA StyleLiang, H., & Seo, S. (2022). Lightweight Deep Learning for Road Environment Recognition. Applied Sciences, 12(6), 3168. https://doi.org/10.3390/app12063168