
Cross-Modal Manifold Propagation for Image Recommendation


Abstract
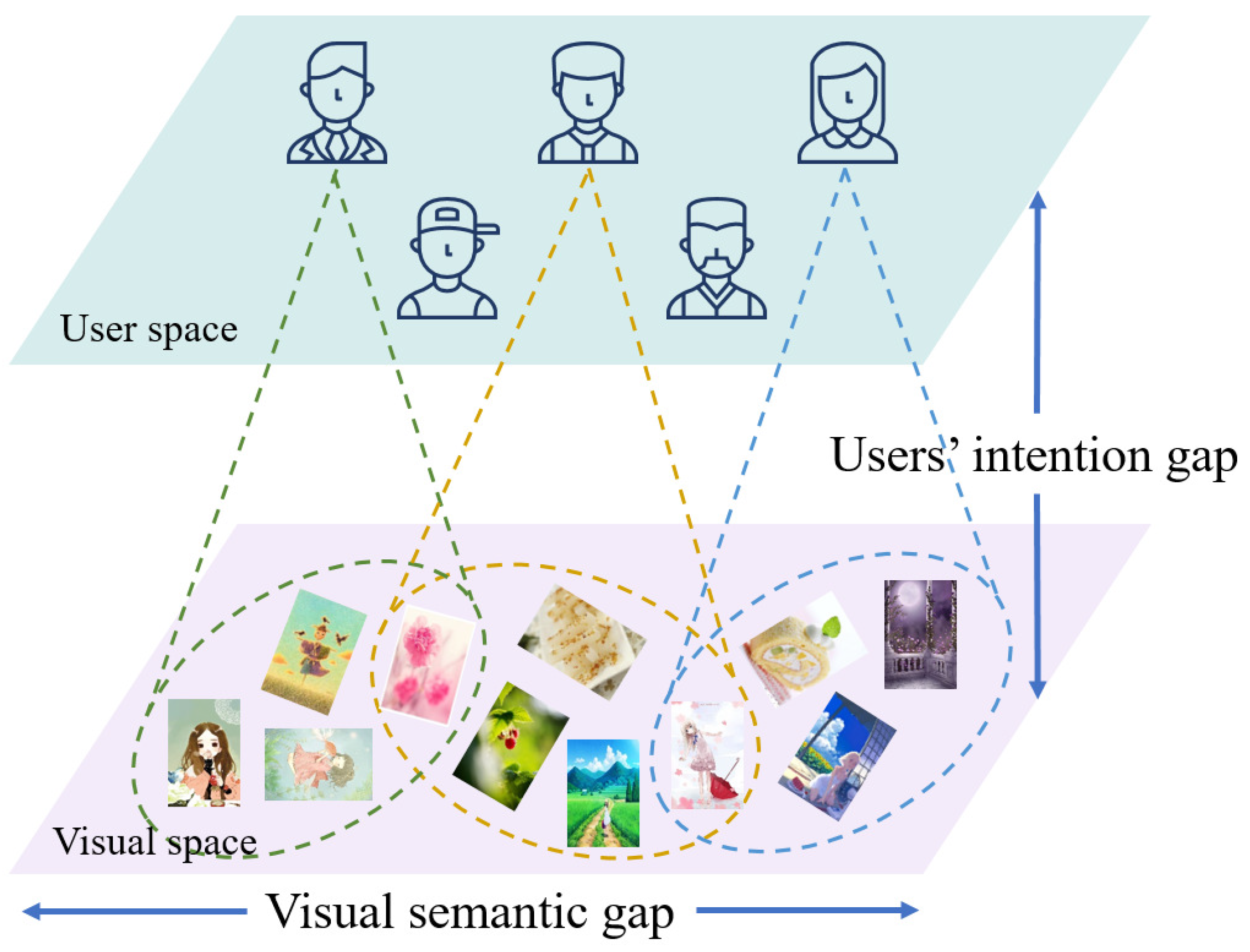
:1. Introduction
- We designed user interest-oriented semantic image ranking for cross-modal collaborative recommendation by investigating the distributions of both user interest and visual semantics.
- The proposed CMP reveals the trend of interests for users and estimates interest-aware user-image correlation by spreading users’ image records on users’ interest manifold.
- CMP leverages visual manifold modularization to help reduce the computational burden on visual manifold propagation, and promote estimating semantic visual-aware user-image scores for recommendation.
2. Related Work
2.1. Collaborative Filtering and Visual Recommendation
2.2. Multimodal Collaborative Recommendation
3. Cross-Modal Manifold Propagation
3.1. Interest Manifold Propagation
3.2. Visual Manifold Propagation
| Algorithm 1 Visual manifold modularization. |
Input:—visual image database. Output:
Modularized visual manifold.
|
3.3. Cross-Modal Collaborative Ranking
| Algorithm 2 Cross-modal collaborative manifold propagation. |
Input:—visual image database; —set of users; —historical records between V and U. Output:
Image list for personalized recommendation.
|
4. Experimental Analysis
- As a primary component in CMP, the manifold construction of user interests and visual semantics is explored first to investigate their complementary role in image recommendation.
- On collaborative fusion, experiments investigate multiple fusion rules compared with the introduced interest-aware semantic fusion to illustrate its merit.
- The performance of CMP is compared with that of single-modal UMP and VMP to illustrate the cross-modal collaborative ability of user manifold propagation and visual manifold propagation in CMP.
- Experiments were conducted to compare the recommendation performance of CMP to that of network-based inference (NBI) [14], collaborative filtering-based (CF) recommendation [40], content-based (CB) recommendation [11], content-based bipartite graph (CBG) [41], collaborative representation based inference (CRC) [42], SVM based inference [43], hybrid recommendation [21], progressive manifold ranking (PMR), and modularized manifold ranking (MMR) [23].
4.1. Interest Manifold Construction
- Relationship-based manifold on the common interest of users from user–image relationships.
- Representation-based manifold on user representation and similarity evaluation.
4.2. Visual Manifold Construction
- Relationship-based manifold by commonly shared users between images over user-image relationships.
- Representation-based manifold on semantic visual correlations over AlexNet-based visual features.
4.3. Collaborative Fusion
4.4. Experimental Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural Collaborative Filtering. In Proceedings of the International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Wu, L.; Chen, L.; Hong, R.; Fu, Y.; Xie, X.; Wang, M. A Hierarchical Attention Model for Social Contextual Image Recommendation. IEEE Trans. Knowl. Data Eng. 2019, 32, 1854–1867. [Google Scholar] [CrossRef] [Green Version]
- Xue, F.; He, X.; Wang, X.; Xu, J.; Liu, K.; Hong, R. Deep item-based collaborative filtering for top-N recommendation. ACM Trans. Inf. Syst. (TOIS) 2019, 37, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.-S. Neural Graph Collaborative Filtering. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- Gong, C.; Tao, D.; Yang, J.; Liu, W. Teaching-to-Learn and Learning-to-Teach for multi-label propagation. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 1610–1616. [Google Scholar]
- Geng, X.; Zhang, H.; Bian, J.; Chua, T.-S. Learning image and user features for recommendation in social networks. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 4274–4282. [Google Scholar]
- Niu, W.; Caverlee, J.; Lu, H. Neural Personalized Ranking for Image Recommendation. In Proceedings of the ACM International Conference on Web Search and Data Mining (ACM WSDM), Marina Del Rey, CA, USA, 5–9 February 2018; pp. 423–431. [Google Scholar]
- Jian, M.; Jia, T.; Yang, X.; Wu, L.; Huo, L. Cross-modal collaborative manifold propagation for image recommendation. In Proceedings of the ACM SIGMM International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 344–348. [Google Scholar]
- Wu, Y.; Dubois, C.; Zheng, A.X.; Ester, M. Collaborative denoising auto-encoders for top-N recommender systems. In Proceedings of the ACM International Conference on Web Search & Data Mining, Shanghai, China, 31 January–6 February 2016; pp. 153–162. [Google Scholar]
- Chen, J.; Zhang, H.; He, X.; Nie, L.; Wei, L.; Chua, T.S. Attentive collaborative filtering: Multimedia recommendation with item- and component-level attention. In Proceedings of the ACM International Conference on Research & Development in Information Retrieval (SIGIR), Tokyo, Japan, 7–11 August 2017; pp. 153–162. [Google Scholar]
- Pazzani, M.J.; Billsus, D. Content-based recommendation systems. Adapt. Web 2007, 4321, 325–341. [Google Scholar]
- Cantador, I.; Bellogín, A.; Vallet, D. Content-based recommendation in social tagging systems. In Proceedings of the ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 237–240. [Google Scholar]
- Lovato, P.; Bicego, M.; Segalin, C.; Perina, C.; Sebe, N.; Cristani, M. Faved! Biometrics: Tell me which image you like and I’ll tell you who you are. IEEE Trans. Inf. Forensics Secur. 2014, 9, 364–374. [Google Scholar] [CrossRef] [Green Version]
- Zhou, T.; Ren, J.; Medo, M.; Zhang, Y.-C. Bipartite network projection and personal recommendation. Phys. Rev. E 2007, 76, 46–115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, H.; Shen, F.; Liu, W.; He, X.; Luan, H.; Chua, T.-S. Discrete collaborative filtering. In Proceedings of the ACM International Conference on Research & Development in Information Retrieval (SIGIR), Pisa, Italy, 17–21 July 2016; pp. 325–334. [Google Scholar]
- Yan, M.; Sang, J.; Xu, C.; Hossain, M.S. A unified video recommendation by cross-network user modeling. ACM Trans. Multimed. Comput. Commun. Appl. 2016, 12, 53. [Google Scholar] [CrossRef]
- Niepert, M.; Ahmed, M.H.; Kutzkov, K. Learning Convolutional Neural Networks for Graphs. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2014–2023. [Google Scholar]
- Li, Y.; Mei, T.; Cong, Y.; Luo, J. User-curated image collections: Modeling and recommendation. In Proceedings of the IEEE International Conference on Big Data, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 591–600. [Google Scholar]
- You, Q.; Bhatia, S.; Luo, J. A picture tells a thousand words–About you! User interest profiling from user generated visual content. Signal Process. 2016, 124, 45–53. [Google Scholar] [CrossRef] [Green Version]
- Hong, R.; Li, L.; Cai, J.; Tao, D.; Wang, M.; Tian, Q. Coherent Semantic-Visual Indexing for Large-Scale Image Retrieval in the Cloud. IEEE Trans. Image Process. 2017, 26, 4128–4138. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, P.; Lu, T.; Gu, H.; Gu, N. Hybrid recommendation model based on incremental collaborative filtering and content-based algorithms. In Proceedings of the 2017 IEEE International Conference on Computer Supported Cooperative Work in Design, Wellington, New Zealand, 26–28 April 2017; pp. 337–342. [Google Scholar]
- Jia, T.; Jian, M.; Wu, L.; He, Y. Modular manifold ranking for image recommendation. In Proceedings of the IEEE International Conference on Multimedia Big Data (BigMM), Xi’an, China, 13–16 September 2018; pp. 1–5. [Google Scholar]
- Jian, M.; Guo, J.; Zhang, C.; Jia, T.; Wu, L.; Yang, X.; Huo, L. Semantic Manifold Modularization-based Ranking for Image Recommendation. Pattern Recognit. 2021, 120, 108100. [Google Scholar] [CrossRef]
- Mei, T.; Yang, B.; Hua, X.-S.; Li, S. Contextual video recommendation by multimodal relevance and user feedback. ACM Trans. Inf. Syst. 2011, 39, 1–24. [Google Scholar] [CrossRef]
- Forestiero, A. Heuristic recommendation technique in Internet of Things featuring swarm intelligence approach. Expert Syst. Appl. 2022, 197, 115904. [Google Scholar] [CrossRef]
- Comito, C.; Forestiero, A.; Pizzuti, C. Word Embedding based Clustering to Detect Topics in Social Media. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence (WI), Thessaloniki, Greece, 14–17 October 2019; pp. 192–199. [Google Scholar]
- Yuan, Z.; Sang, J.; Xu, C.; Liu, Y. A unified framework of latent feature learning in social media. IEEE Trans. Multimed. 2014, 16, 1624–1635. [Google Scholar] [CrossRef]
- Srivastava, N.; Salakhutdinov, R. Multimodal Learning with Deep Boltzmann Machines. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 2222–2230. [Google Scholar]
- Xang, X.; Zhang, T.; Xu, C.; Yang, M.-H. Boosted multifeature learning for cross-domain transfer. ACM Trans. Multimed. Comput. Commun. Appl. 2015, 11, 1–18. [Google Scholar]
- Yang, X.; Zhang, T.; Xu, C. Cross-domain feature learning in multimedia. IEEE Trans. Multimed. 2014, 17, 64–78. [Google Scholar] [CrossRef]
- Kang, C.; Xiang, S.; Liao, S.; Xu, C.; Pan, C. Learning consistent feature representation for cross-modal multimedia retrieval. IEEE Trans. Multimed. 2015, 17, 370–381. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, Y.; Tian, Q.; Zhuo, L.; Liu, X. Personalized social image recommendation method based on user-image-tag model. IEEE Trans. Multimed. 2017, 19, 2439–2449. [Google Scholar] [CrossRef]
- Sejal, D.; Ganeshsingh, T.; Venugopal, K.R.; Iyengar, S.S.; Patnaik, L.M. ACSIR: ANOVA cosine similarity image recommendation in vertical search. Int. J. Multimed. Inf. Retr. 2017, 6, 1–12. [Google Scholar] [CrossRef]
- Harakawa, R.; Takehara, D.; Ogawa, T.; Haseyama, M. Sentiment-aware personalized tweet recommendation through multimodal FFM. Multimed. Tools Appl. 2018, 77, 18741–18759. [Google Scholar] [CrossRef]
- Bai, P.; Ge, Y.; Liu, F.; Lu, H. Joint interaction with context operation for collaborative filtering. Pattern Recognit. 2019, 88, 729–738. [Google Scholar] [CrossRef] [Green Version]
- Tang, J.; Shu, X.; Li, Z.; Jiang, Y.-G.; Tian, Q. Social anchor-unit graph regularized tensor completion for large-scale image retagging. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2027–2034. [Google Scholar] [CrossRef] [Green Version]
- Yu, X.; Jiang, F.; Du, J.; Gong, D. A cross-domain collaborative filtering algorithm with expanding user and item features via the latent factor space of auxiliary domains. Pattern Recognit. 2019, 94, 96–109. [Google Scholar] [CrossRef]
- Wu, L.; Sun, P.; Hong, R.; Fu, Y.; Wang, X.; Wang, M. SocialGCN: An efficient graph convolutional network based model for social recommendation. arXiv 2018, arXiv:1811.02815. [Google Scholar]
- Krizhevsk, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Wu, L.; Zhang, L.; Jian, M.; Zhang, D.; Liu, H. Image recommendation on content-based bipartite graph. In Proceedings of the International Conference on Internet Multimedia Computing and Service, Qingdao, China, 23–25 August 2017; pp. 339–348. [Google Scholar]
- Zhang, L.; Yang, M.; Feng, X. Sparse representation or collaborative representation: Which helps face recognition? In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 471–478. [Google Scholar]
- Joachims, T. Making large-scale SVM learning practical. Tech. Rep. 1998, 8, 499–526. [Google Scholar]
- Liu, H.; Wu, L.; Zhang, D.; Jian, M.; Zhang, X. Multi-perspective User2Vec: Exploiting re-pin activity for user representation learning in content curation social network. Signal Process. 2018, 142, 450–456. [Google Scholar] [CrossRef]
- Sarwar, B.M.; Karypis, G.; Konstan, J.A.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the Web Conference (WWW), Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UMP | VMP | CMP | |
|---|---|---|---|
| MRR | 25.6% | 32.0% | 45.1% |
| CRC | SVM | CF | CBG | CB | NBI | Hybrid | PMR | MMR | CMP | |
|---|---|---|---|---|---|---|---|---|---|---|
| MRR | 0.16% | 4.0% | 1.3% | 12.7% | 2.9% | 22.9% | 5.4% | 26.8% | 32.0% | 45.1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jian, M.; Guo, J.; Fu, X.; Wu, L.; Jia, T. Cross-Modal Manifold Propagation for Image Recommendation. Appl. Sci. 2022, 12, 3180. https://doi.org/10.3390/app12063180
Jian M, Guo J, Fu X, Wu L, Jia T. Cross-Modal Manifold Propagation for Image Recommendation. Applied Sciences. 2022; 12(6):3180. https://doi.org/10.3390/app12063180
Chicago/Turabian StyleJian, Meng, Jingjing Guo, Xin Fu, Lifang Wu, and Ting Jia. 2022. "Cross-Modal Manifold Propagation for Image Recommendation" Applied Sciences 12, no. 6: 3180. https://doi.org/10.3390/app12063180
APA StyleJian, M., Guo, J., Fu, X., Wu, L., & Jia, T. (2022). Cross-Modal Manifold Propagation for Image Recommendation. Applied Sciences, 12(6), 3180. https://doi.org/10.3390/app12063180