
Swin Transformer Assisted Prior Attention Network for Medical Image Segmentation




Abstract
:Featured Application
Abstract
1. Introduction
- A novel network structure called Swin-PANet is proposed for medical image segmentation, which consists of a prior attention network and a hybrid Transformer network. The proposed Swin-PANet follows the coarse-to-fine strategy and dual supervision strategy to improve the segmentation performance.
- The proposed Swin-PANet addresses the dilemma that traditional Transformer network has poor interpretability in the process of attention calculation, and Swin-PANet can insert its attention predictions into prior attention network for intermediate supervision learning which is humanly interpretable and controllable.
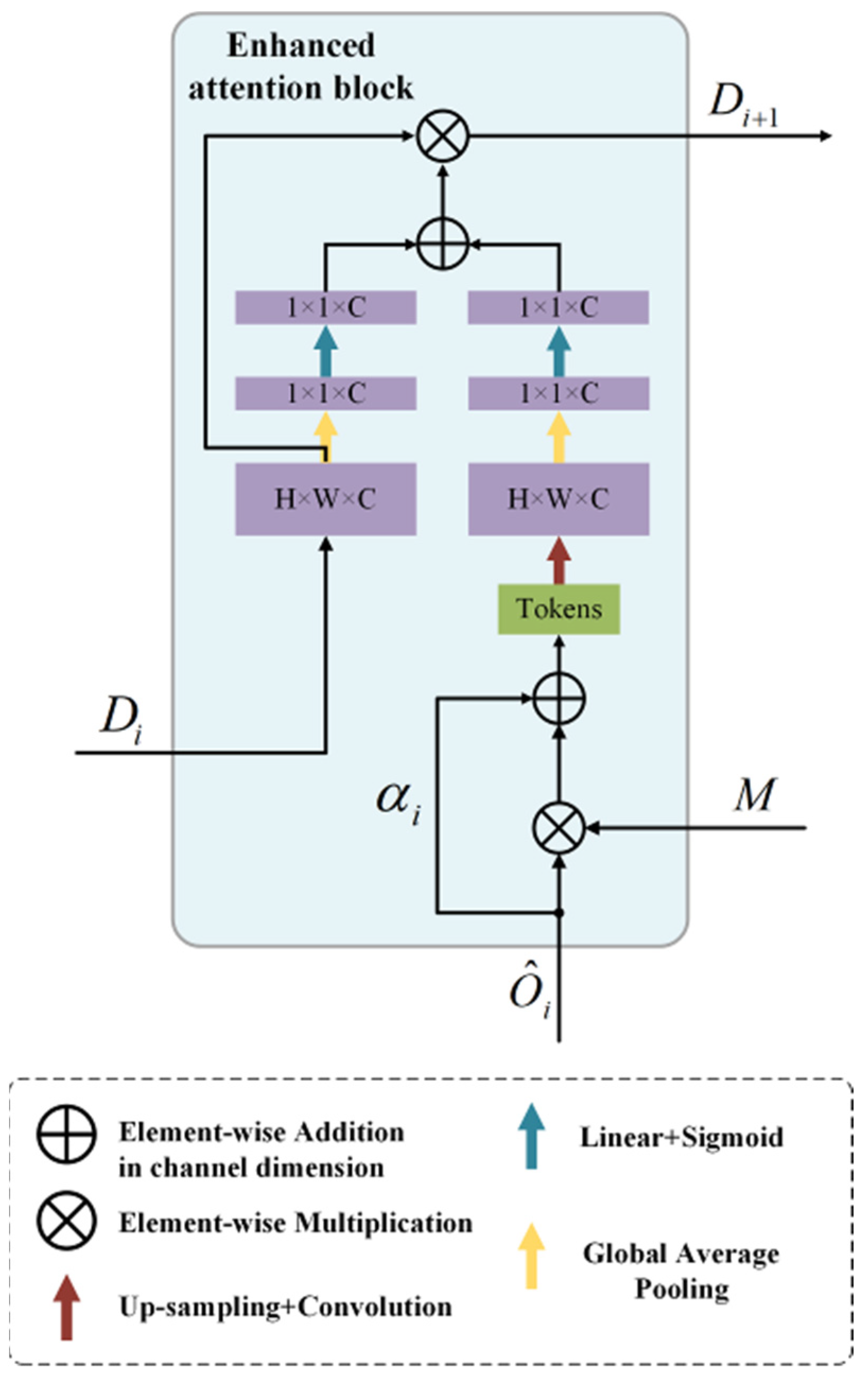
- Enhanced attention bock is proposed and equipped in the hybrid Transformer network, which is to utilize a feature fusion between global and local contexts along channel-wise for achieving a better performance of attention learning.
2. State of the Art and Related Work
2.1. CNN-Based Methods
2.2. Vision Transformers
2.3. Transformer Complements CNNs
3. Modeling, Methods, and Design
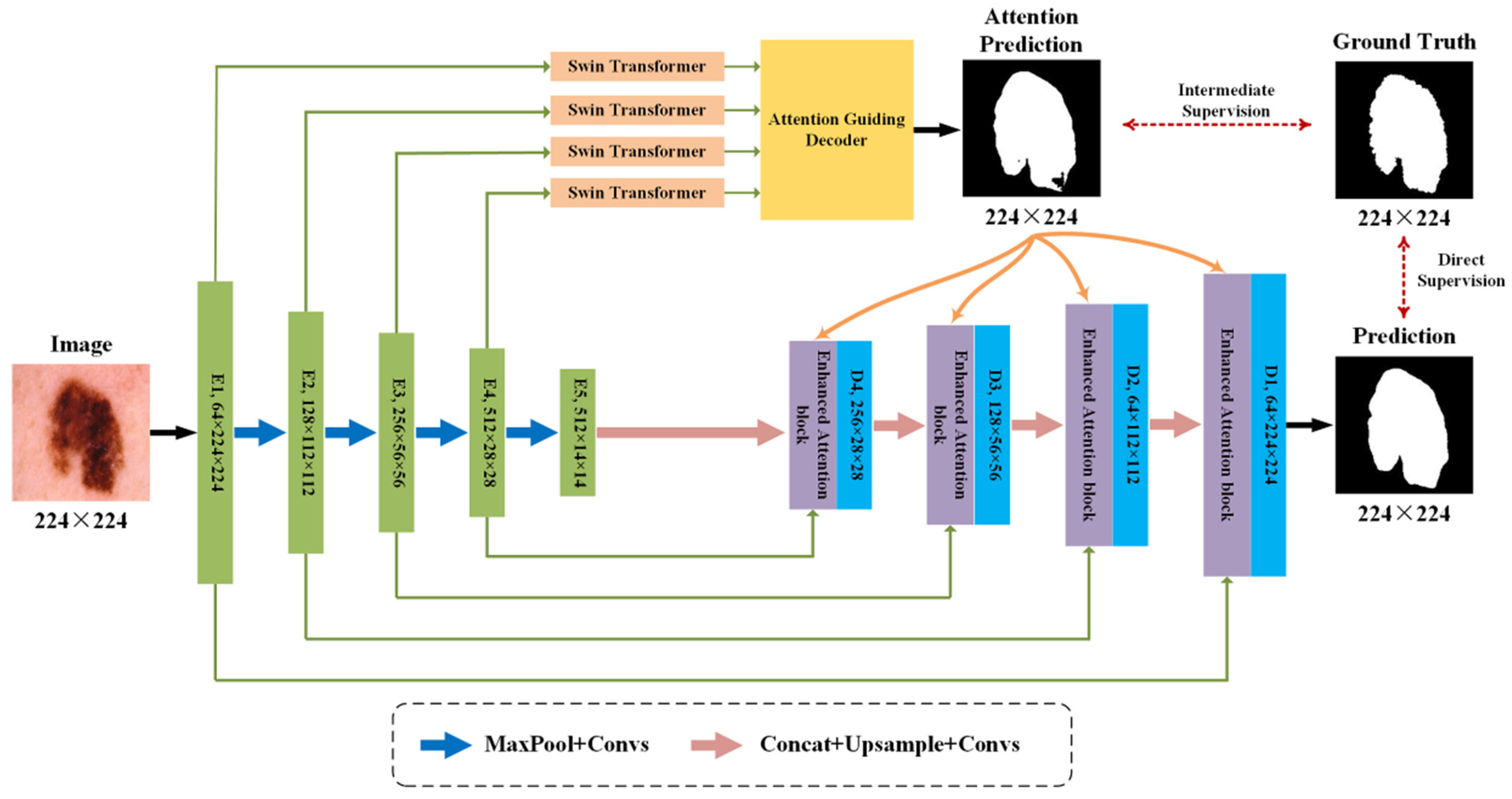
3.1. Overview of Network Structure
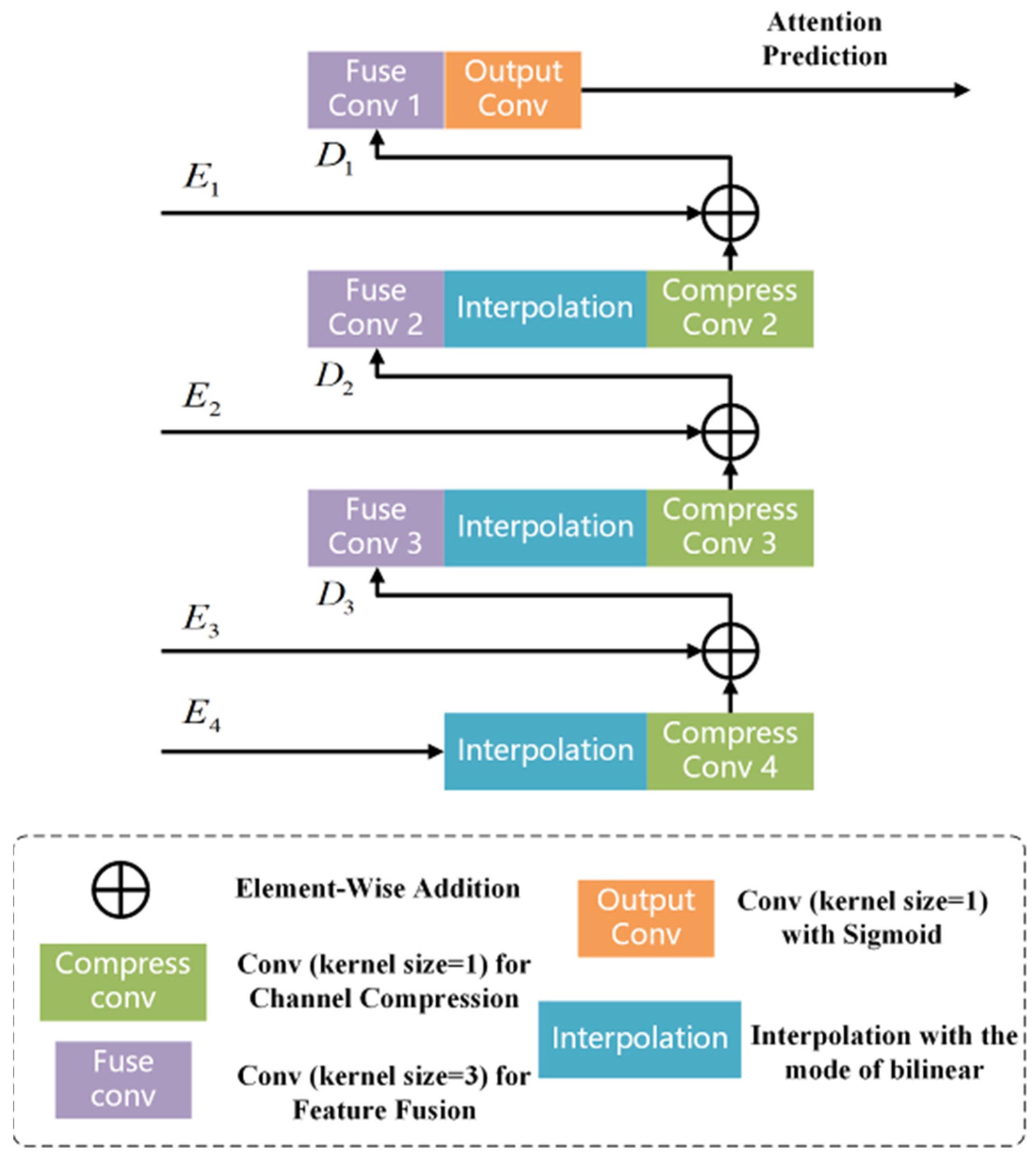
3.2. Swin Transformer and Attention Guiding Decoder
3.3. Hybrid Transformer Network
3.4. Dual Supervision Strategy
4. Experimental Results
4.1. Experiment Setup
4.1.1. Datasets
4.1.2. Implementation Details
4.1.3. Evaluation Criteria
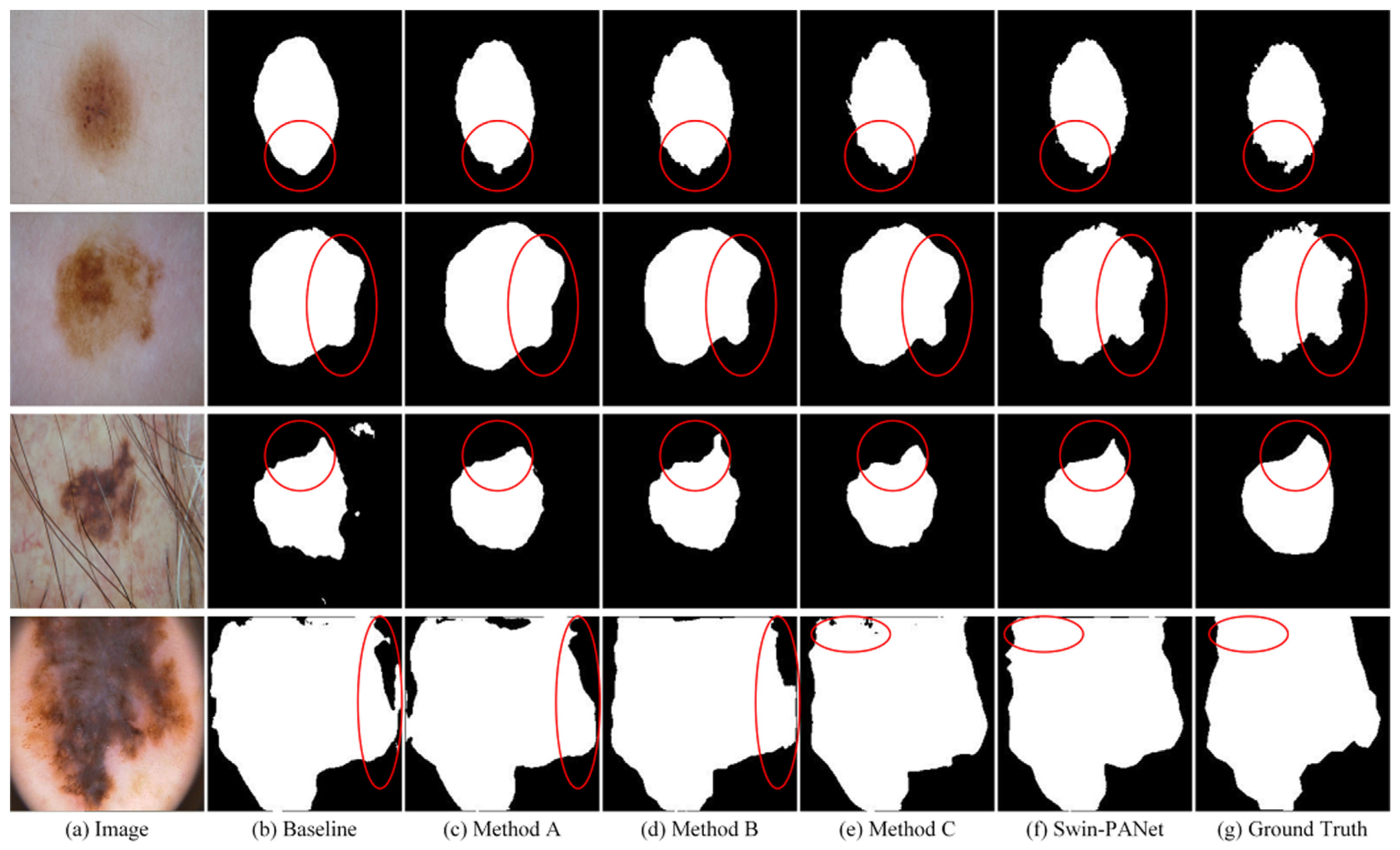
4.2. Comparisons with State-of-the-Art Methods on GlaS and MoNuSeg Datasets
4.3. Ablation Studies
4.4. Experimental Summary and Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. The Code Snippets of the Network Structure
| n_channels = 3 |
| n_labels = 1 |
| epochs = 300 |
| img_size = 224 |
| vis_frequency = 10 |
| early_stopping_patience = 100 |
| pretrain = False |
| task_name = ‘GlaS’ # GlaS, MoNuSeg, and ISIC 2016 |
| learning_rate = 0.005 |
| batch_size = 2 |
| Transformer_patch_sizes = [2, 4] |
| Transformer.dropout_rate = 0.1 |
| base_channel = 32 |
| class Swin-PANet(nn.Module): |
| def __init__(self, config,n_channels = 3, n_classes = 1,img_size = 224,vis = False): |
| super().__init__() |
| self.vis = vis |
| self.n_channels = n_channels |
| self.n_classes = n_classes |
| in_channels = config.base_channel |
| self.down1 = DownBlock(in_channels, in_channels*2, nb_Conv = 2) |
| self.down2 = DownBlock(in_channels*2, in_channels*4, nb_Conv = 2) |
| self.down3 = DownBlock(in_channels*4, in_channels*8, nb_Conv = 2) |
| self.down4 = DownBlock(in_channels*8, in_channels*8, nb_Conv = 2) |
| self.prior_attention_network = Intermediate_supervision(in_channels*2, in_channels*4, in_channels*8, in_channels*8) |
| self.up4 = UpBlock(in_channels*16, in_channels*4, in_channels*4, nb_Conv = 2) |
| self.up3 = UpBlock(in_channels*8, in_channels*2, in_channels*4, nb_Conv = 2) |
| self.up2 = UpBlock(in_channels*4, in_channels, in_channels*4, nb_Conv = 2) |
| self.up1 = UpBlock(in_channels*2, in_channels, in_channels*4, nb_Conv = 2) |
| self.outc = nn.Conv2d(in_channels, n_classes, kernel_size = (1,1), stride = (1,1)) |
| self.last_activation = nn.Sigmoid() # if using BCELoss |
| def forward(self, x): |
| x = x.float() |
| x1 = self.ConvBatchNorm(x) |
| x2 = self.down1(x1) |
| x3 = self.down2(x2) |
| x4 = self.down3(x3) |
| x5 = self.down4(x4) |
| attention_prediction = self.prior_attention_network(x1,x2,x3,x4) |
| x = self.up4(x5, x4, attention_prediction) |
| x = self.up3(x, x3, attention_prediction) |
| x = self.up2(x, x2, attention_prediction) |
| x = self.up1(x, x1, attention_prediction) |
| logits = self.last_activation(self.outc(x)) |
| return attention_prediction, logits |
| images, masks = batch[‘image’], batch[‘label’] |
| images, masks = images.cuda(), masks.cuda() |
| preds, attention_prediction = model(images) |
| intermediate_loss = intermediate_criterion(attention_prediction, masks.float()) |
| out_loss = direct_criterion(preds, masks.float()) |
| intermediate_loss.backward(grad = True) |
| out_loss.backward() |
| optimizer.step() |
References
- Hatamizadeh, A.; Tang, Y.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B.; Xu, D. Unetr: Transformers for 3d medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Online, 5 January 2022. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- Zhao, X.; Zhang, P.; Song, F.; Ma, C.; Fan, G.; Sun, Y.; Zhang, G. Prior Attention Network for Multi-Lesion Segmentation in Medical Images. arXiv 2021, arXiv:2110.04735. [Google Scholar]
- Wang, H.; Cao, P.; Wang, J.; Zaiane, O.R. UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspective with Transformer. arXiv 2021, arXiv:2109.04335. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11 October 2021. [Google Scholar]
- Tsai, A.; Yezzi, A.; Wells, W.; Tempany, C.; Tucker, D.; Fan, A.; Grimson, W.; Willsky, A. A shape-based approach to the segmentation of medical imagery using level sets. IEEE Trans. Med. Imaging 2003, 2, 137–154. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Held, K.; Kops, E.R.; Krause, B.J.; Wells, W.M.; Kikinis, R.; Muller-Gartner, H.W. Markov random field segmentation of brain mr images. IEEE Trans. Med. Imaging 1997, 16, 878–886. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5 October 2015. [Google Scholar]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.; Petersen, J.; Maier-Hein, K.H. nnu-net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 2021, 18, 201–211. [Google Scholar] [CrossRef]
- Jin, Q.; Meng, Z.; Sun, C.; Cui, H.; Su, R. Ra-unet: A hybrid deep attention-aware network to extract liver and tumor in ct scans. Front. Bioeng. Biotechnol. 2020, 8, 1471. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Bangalore, India, 17 August 2017. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. Deep Learn. Med. Image Anal. Multimodal Learn. Clin. Decis. Support 2018, 11045, 3–11. [Google Scholar]
- Xiao, X.; Lian, S.; Luo, Z.; Li, S. Weighted res-unet for high-quality retina vessel segmentation. In Proceedings of the 2018 9th International Conference on Information Technology in Medicine and Education, Hangzhou, China, 19 October 2018. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Isensee, F.; Petersen, J.; Kohl, S.A.; Jäger, P.F.; Maier-Hein, K.H. nnu-net: Breaking the spell on successful medical image segmentation. arXiv 2019, arXiv:1904.08128. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.-W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing, Online, 4 May 2020. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision, Stanford, CA, USA, 25 October 2016. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Greece, Athens, 17 October 2016. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. Ce-net: Context encoder network for 2d medical image segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18 June 2018. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Advan. Neural Infor. 2017, 30, 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Online, 23 August 2020. [Google Scholar]
- Prangemeier, T.; Reich, C.; Koeppl, H. Attention-based transformers for instance segmentation of cells in microstructures. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine, Seoul, Korea, 16 December 2020. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; J´egou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Online, 18 July 2021. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 10 March 2021. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. arXiv 2021, arXiv:2103.00112. [Google Scholar]
- Zhang, Y.; Liu, H.; Hu, Q. Transfuse: Fusing transformers and cnns for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September 2021. [Google Scholar]
- Valanarasu, J.M.J.; Oza, P.; Hacihaliloglu, I.; Patel, V.M. Medical transformer: Gated axial-attention for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September 2021. [Google Scholar]
- Gao, Y.; Zhou, M.; Metaxas, D.N. UTNet: A Hybrid Transformer Architecture for Medical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September 2021. [Google Scholar]
- Wang, W.; Chen, C.; Ding, M.; Yu, H.; Zha, S.; Li, J. Transbts: Multimodal brain tumor segmentation using transformer. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September 2021. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16 June 2020. [Google Scholar]
- Sirinukunwattana, K.; Pluim, J.P.W.; Chen, H.; Qi, X.; Heng, P.-A.; Guo, Y.B.; Wang, L.Y.; Matuszewski, B.J.; Bruni, E.; Sanchez, U.; et al. Gland Segmentation in Colon Histology Images: The GlaS Challenge Contest. Med. Image Anal. 2017, 35, 489–502. [Google Scholar] [CrossRef] [Green Version]
- Kumar, N.; Verma, R.; Sharma, S.; Bhargava, S.; Vahadane, A.; Sethi, A. A Dataset and a Technique for Generalized Nuclear Segmentation for Computational Pathology. IEEE Trans. Med. Imaging 2017, 36, 1550–1560. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net Architecture for Multimodal Biomedical Image Segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef]
- Wu, H.; Chen, S.; Chen, G.; Wang, W.; Lei, B.; Wen, Z. FAT-Net: Feature adaptive transformers for automated skin lesion segmentation. Med. Image Anal. 2022, 76, 102327. [Google Scholar] [CrossRef] [PubMed]
- Dai, D.; Dong, C.; Xu, S.; Yan, Q.; Li, Z.; Zhang, C.; Luo, N. Ms RED: A novel multi-scale residual encoding and decoding network for skin lesion segmentation. Med. Image Anal. 2022, 75, 102293. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wei, L.; Wang, L.; Zhou, Q.; Zhu, L.; Qin, J. Boundary-Aware Transformers for Skin Lesion Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September 2021. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | GlaS | MoNuSeg | ||
|---|---|---|---|---|
| Dice (%) | IoU (%) | Dice (%) | IoU (%) | |
| U-Net (2015) | 86.34 | 76.81 | 73.97 | 59.42 |
| UNet++ (2018) | 87.07 | 78.10 | 75.28 | 60.89 |
| AttUNet (2018) | 86.98 | 77.53 | 76.20 | 62.64 |
| MRUNet (2020) | 87.72 | 79.39 | 77.54 | 63.80 |
| TransUNet (2021) | 87.63 | 79.10 | 79.20 | 65.68 |
| MedT (2021) | 86.68 | 77.50 | 79.24 | 65.73 |
| Swin-Unet (2021) | 88.25 | 79.86 | 78.49 | 64.72 |
| UCTransNet (2021) | 89.84 | 82.24 | 79.87 | 66.68 |
| UCTransNet-pre | 90.18 | 82.95 | 77.19 | 63.80 |
| Swin-PANet (ours) | 91.42 | 84.88 | 81.59 | 69.00 |
| Method | ISIC 2016 | |
|---|---|---|
| Dice (%) | IoU (%) | |
| Baseline (U-Net) | 86.82 | 78.23 |
| Baseline + Swin − Trans | 89.98 | 83.43 |
| Baseline + AGD | 89.79 | 82.81 |
| Baseline + AGD + EAB | 90.12 | 83.74 |
| Baseline + Swin − Trans + EAB | 89.56 | 82.50 |
| Baseline + Swin − Trans +AGD + EAB | 90.68 | 84.06 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, Z.; Fan, N.; Xu, K. Swin Transformer Assisted Prior Attention Network for Medical Image Segmentation. Appl. Sci. 2022, 12, 4735. https://doi.org/10.3390/app12094735
Liao Z, Fan N, Xu K. Swin Transformer Assisted Prior Attention Network for Medical Image Segmentation. Applied Sciences. 2022; 12(9):4735. https://doi.org/10.3390/app12094735
Chicago/Turabian StyleLiao, Zhihao, Neng Fan, and Kai Xu. 2022. "Swin Transformer Assisted Prior Attention Network for Medical Image Segmentation" Applied Sciences 12, no. 9: 4735. https://doi.org/10.3390/app12094735
APA StyleLiao, Z., Fan, N., & Xu, K. (2022). Swin Transformer Assisted Prior Attention Network for Medical Image Segmentation. Applied Sciences, 12(9), 4735. https://doi.org/10.3390/app12094735