


Citrus Tree Crown Segmentation of Orchard Spraying Robot Based on RGB-D Image and Improved Mask R-CNN

(This article belongs to the Section Agricultural Science and Technology)
Abstract
:1. Introduction
- For improved object identification, RGB-D images are collected, and the image noise outside the effective spraying area is removed by aligning pixels and adjusting the visual distance. Compared to that of RGB images, the bbox AP50 score is improved by 0.3% for RGB-D images.
- To increase robustness in complex backgrounds, the model is trained using citrus crown images with different backgrounds at different growth stages. The model’s bbox and seg AP50 indicators are averaged over 95%, indicating a good overall performance and strong generality.
- To improve the accuracy of tree crown segmentation, an improved instance segmentation method based on the Mask R-CNN framework is proposed. The UNet++ is a commonly used semantic segmentation network [37]. We employ a feature map-based SE block (a neural network that can improve the feature extraction ability) with UNet++ (MSEU) in the R-CNN. The SE block is integrated with the residual network (ResNet) [38,39] to improve the extractability of tree crown features, and the UNet++ is introduced in the mask branch (a neural network used for segmenting images) to further improve segmentation quality. Compared with those of the optimal Mask R-CNN, the bbox and seg AP50 of MSEU R-CNN were improved by 3.4% and 2.4%, respectively.
2. Methods and Materials
2.1. Image Dataset
2.2. Dataset Production
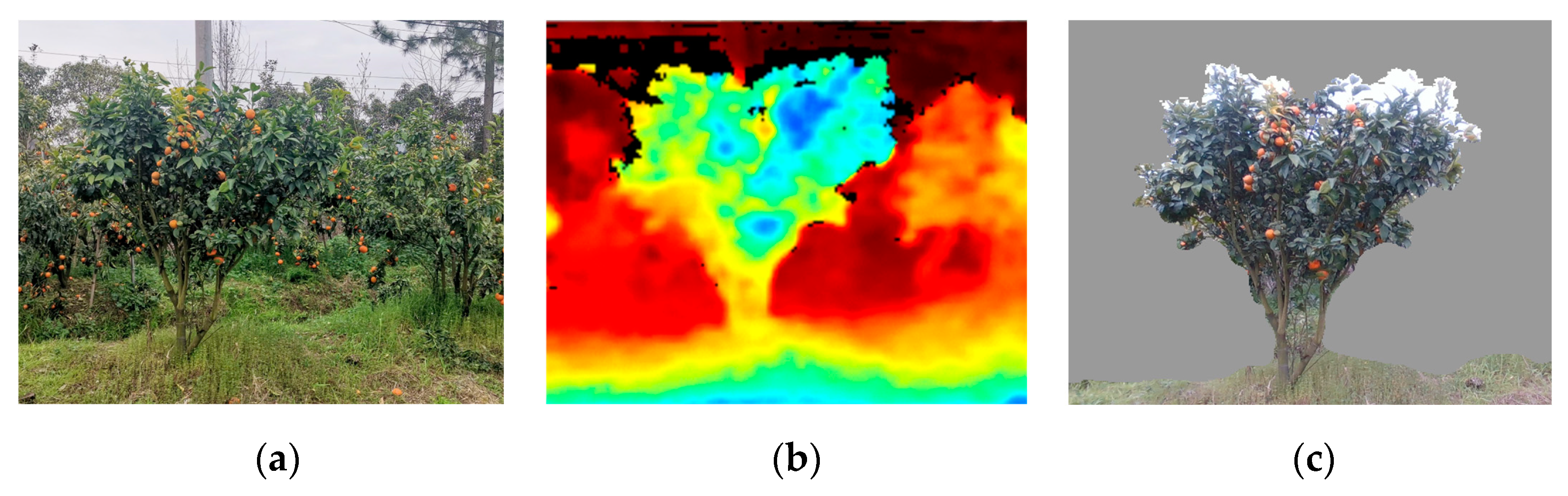
2.2.1. Generated RGB-D Tree Crown Images
2.2.2. Image Annotation and Data Augmentation
2.3. MSEU R-CNN Citrus Crown Instance Segmentation Model
2.3.1. SE-ResNet
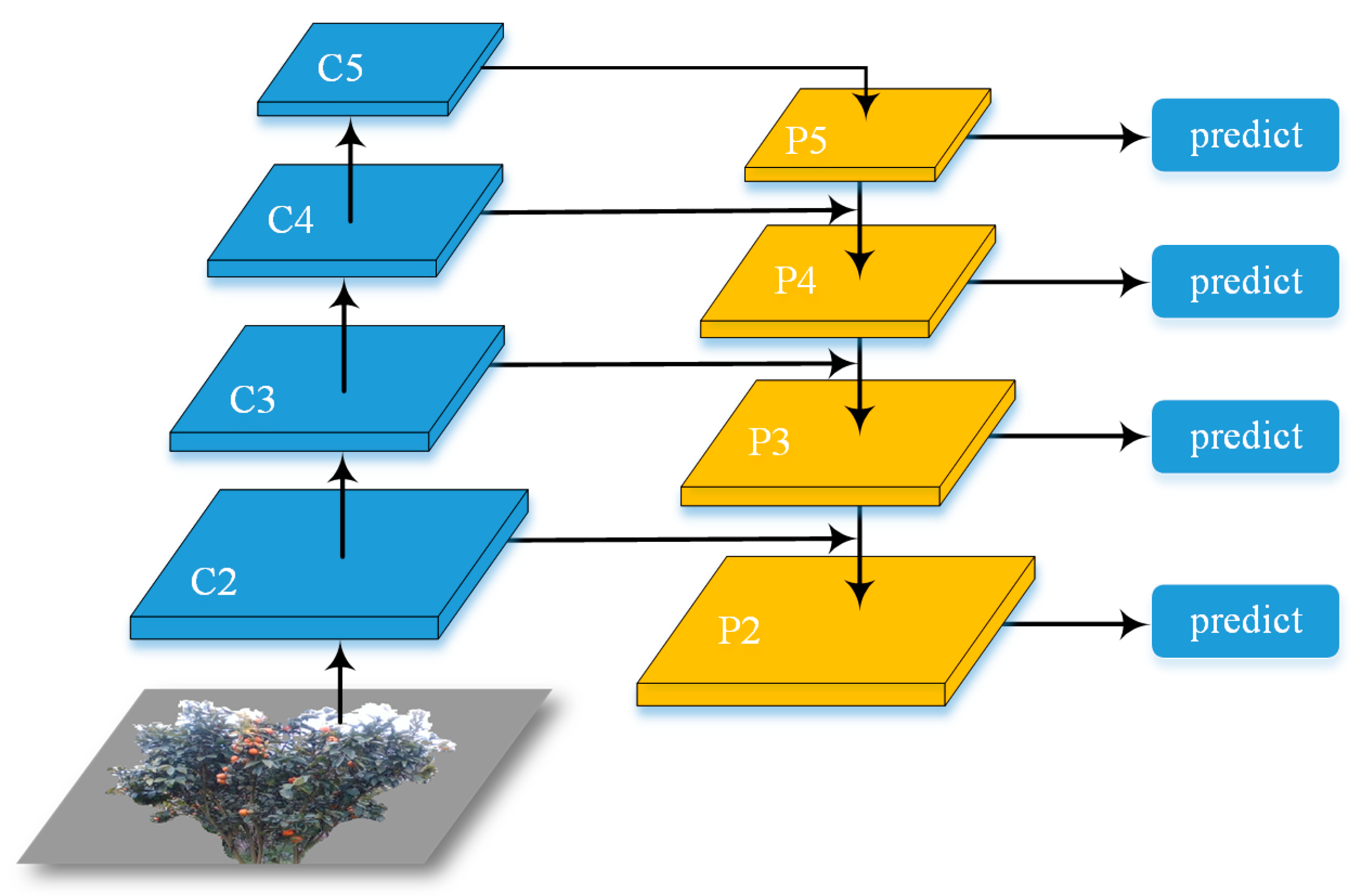
2.3.2. FPN
2.3.3. RPN and ROIAlign
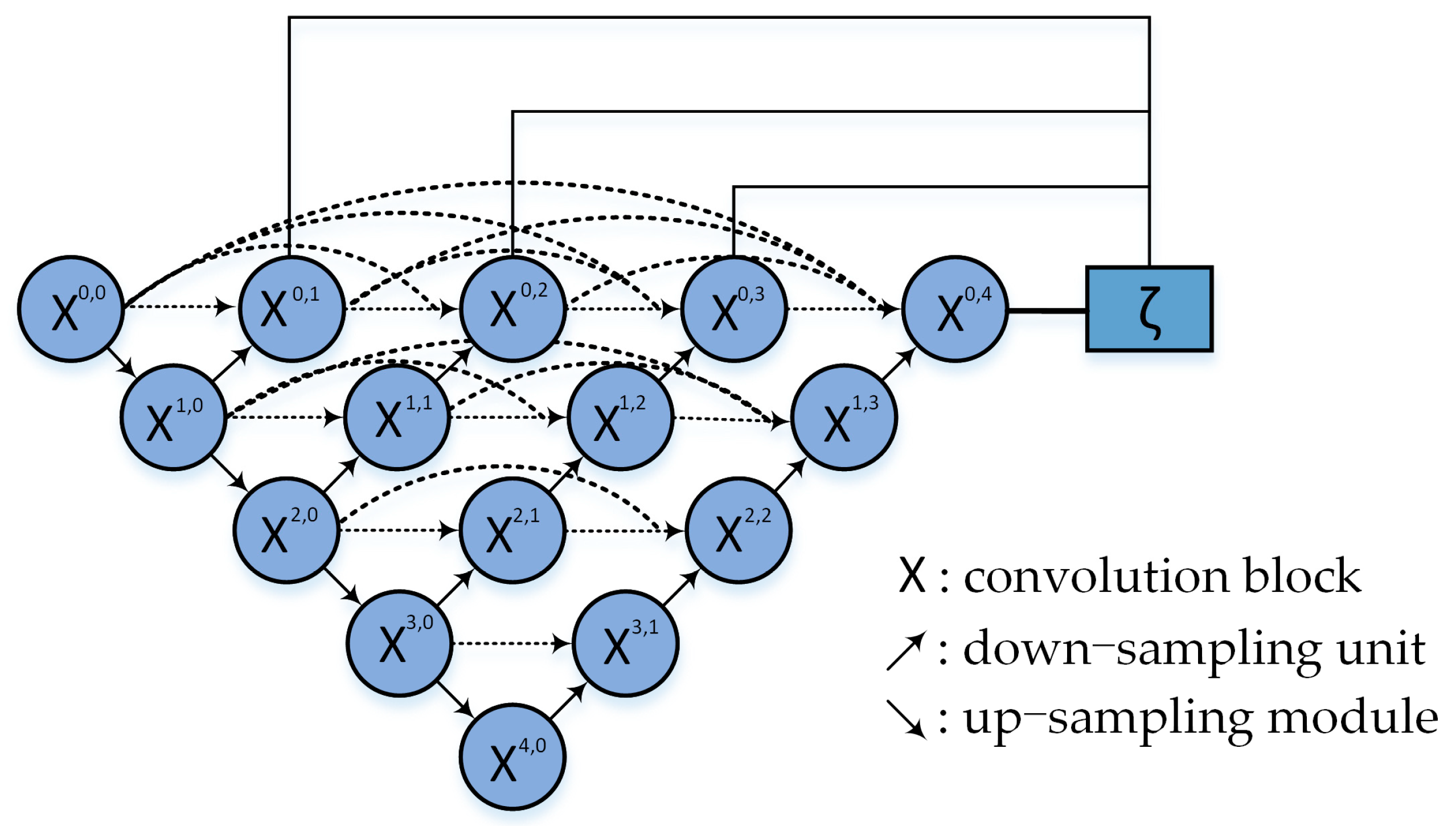
2.3.4. Unet++ Replaces the FCN
3. Results and Discussion
3.1. Evaluation Index
3.2. Model Training
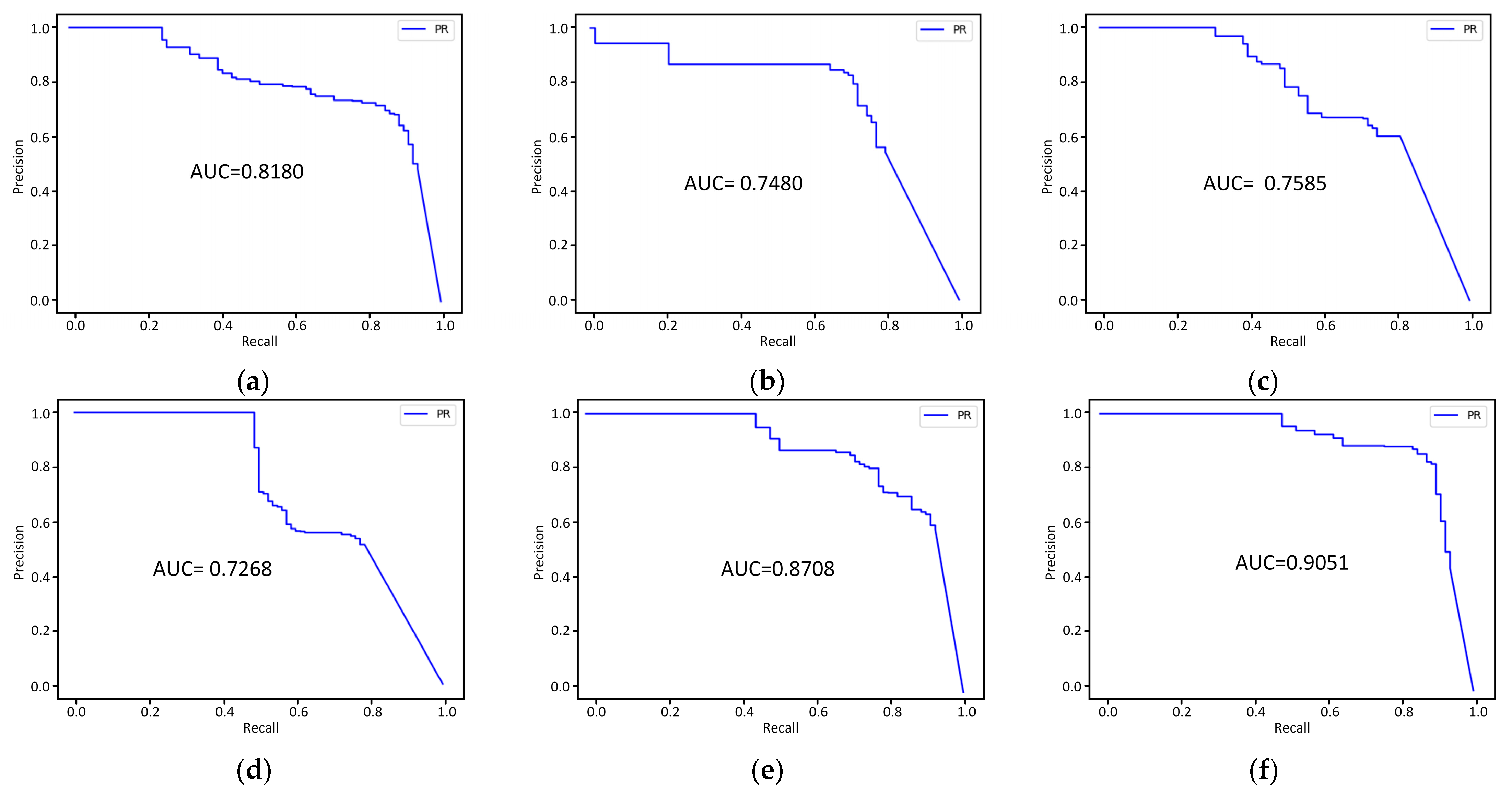
3.3. Test Result Analysis
3.3.1. RGB-D Image Validity Analysis
3.3.2. MSEU R-CNN Instance Segmentation Performance Test
3.3.3. Effectiveness Analysis of Model Structure Optimization
3.3.4. Comparison and Analysis with Other Instance Segmentation Models
4. Conclusions and Future Work
- (1)
- The detection accuracy of the MSEU R-CNN RGB-D tree-crown image was higher than that of RGB, indicating that the depth image can effectively reduce the interference of complex backgrounds and non-targeted tree crowns.
- (2)
- The MSEU R-CNN’s segmentation results at different stages showed that the detection and segmentation accuracies of tree crowns at the flourishing stage were the highest, whereas those at the seedling and fruit-bearing stages were lower. However, the average bbox and seg AP50 measures were more than 95%, indicating that the overall performance was excellent with strong generalizability.
- (3)
- Compared with the original Mask R-CNN model, the proposed model effectively improves the recognition and segmentation accuracies of a single citrus crown under the condition of a small average running time change, and the segmentation quality of the crown mask is more precise, which helps accurately evaluate crown parameters. Compared with other models, the experimental results show that the segmentation performance of the proposed model is obviously better than that of BoxInst and CondInst models.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Meshram, A.T.; Vanalkar, A.V.; Kalambe, K.B.; Badar, A.M. Pesticide spraying robot for precision agriculture: A categorical literature review and future trends. J. Field Robot. 2022, 39, 153–171. [Google Scholar] [CrossRef]
- Hejazipoor, H.; Massah, J.; Soryani, M.; Vakilian, K.A.; Chegini, G. An intelligent spraying robot based on plant bulk volume. Comput. Electron. Agric. 2021, 180, 105859. [Google Scholar] [CrossRef]
- Manandhar, A.; Zhu, H.; Ozkan, E.; Shah, A. Techno-economic impacts of using a laser-guided variable-rate spraying system to retrofit conventional constant-rate sprayers. Precis. Agric. 2020, 21, 1156–1171. [Google Scholar] [CrossRef]
- Chen, L.; Wallhead, M.; Reding, M.; Horst, L.; Zhu, H. Control of Insect Pests and Diseases in an Ohio Fruit Farm with a Laser-guided Intelligent Sprayer. HortTechnology 2020, 30, 168–175. [Google Scholar] [CrossRef] [Green Version]
- Dou, H.; Zhai, C.; Chen, L.; Wang, X.; Zou, W. Comparison of Orchard Target-Oriented Spraying Systems Using Photoelectric or Ultrasonic Sensors. Agriculture 2021, 11, 753. [Google Scholar] [CrossRef]
- Maghsoudi, H.; Minaei, S.; Ghobadian, B.; Masoudi, H. Ultrasonic sensing of pistachio canopy for low-volume precision spraying. Comput. Electron. Agric. 2015, 112, 149–160. [Google Scholar] [CrossRef]
- Li, H.; Zhai, C.; Weckler, P.; Wang, N.; Yang, S.; Zhang, B. A Canopy Density Model for Planar Orchard Target Detection Based on Ultrasonic Sensors. Sensors 2017, 17, 31. [Google Scholar] [CrossRef] [Green Version]
- Mahmud, M.S.; Zahid, A.; He, L.; Choi, D.; Krawczyk, G.; Zhu, H.; Heinemann, P. Development of a LiDAR-guided section-based tree canopy density measurement system for precision spray applications. Comput. Electron. Agric. 2021, 182, 106053. [Google Scholar] [CrossRef]
- Gu, C.; Zhai, C.; Wang, X.; Wang, S. CMPC: An Innovative Lidar-Based Method to Estimate Tree Canopy Meshing-Profile Volumes for Orchard Target-Oriented Spray. Sensors 2021, 21, 4252. [Google Scholar] [CrossRef]
- Cheraïet, A.; Naud, O.; Carra, M.; Codis, S.; Lebeau, F.; Taylor, J. An algorithm to automate the filtering and classifying of 2D LiDAR data for site-specific estimations of canopy height and width in vineyards. Biosyst. Eng. 2020, 200, 450–465. [Google Scholar] [CrossRef]
- Hu, X.; Wang, X.; Yang, X.; Wang, D.; Zhang, P.; Xiao, Y. An infrared target intrusion detection method based on feature fusion and enhancement. Def. Technol. 2020, 16, 737–746. [Google Scholar] [CrossRef]
- Giles, D.K.; Klassen, P.; Niederholzer, F.J.A.; Downey, D. “Smart” sprayer technology provides environmental and economic benefits in California orchards. Calif. Agric. 2011, 65, 85–89. [Google Scholar] [CrossRef] [Green Version]
- Hočevar, M.; Širok, B.; Jejčič, V.; Godeša, T.; Lešnika, M.; Stajnko, D. Design and testing of an automated system for targeted spraying in orchards. J. Plant Dis. Prot. 2010, 117, 71–79. [Google Scholar] [CrossRef]
- Beyaz, A.; Dagtekin, M. Comparison effectiveness of canopy volume measurements of citrus species via arduino based ultrasonic sensor and image analysis techniques. Fresenius Environ. Bull. 2017, 26, 6373–6382. [Google Scholar]
- Asaei, H.; Jafari, A.; Loghavi, M. Site-specific orchard sprayer equipped with machine vision for chemical usage management. Comput. Electron. Agric. 2019, 162, 431–439. [Google Scholar] [CrossRef]
- Liu, T.; Im, J.; Quackenbush, L.J. A novel transferable individual tree crown delineation model based on Fishing Net Dragging and boundary classification. ISPRS J. Photogramm. Remote. Sens. 2015, 110, 34–47. [Google Scholar] [CrossRef]
- Gao, G.; Xiao, K.; Jia, Y. A spraying path planning algorithm based on colour-depth fusion segmentation in peach orchards. Comput. Electron. Agric. 2020, 173, 105412. [Google Scholar] [CrossRef]
- Xiao, K.; Ma, Y.; Gao, G. An intelligent precision orchard pesticide spray technique based on the depth-of-field extraction algorithm. Comput. Electron. Agric. 2017, 133, 30–36. [Google Scholar] [CrossRef]
- Milella, A.; Marani, R.; Petitti, A.; Reina, G. In-field high throughput grapevine phenotyping with a consumer-grade depth camera. Comput. Electron. Agric. 2019, 156, 293–306. [Google Scholar] [CrossRef]
- Kim, J.; Seol, J.; Lee, S.; Hong, S.-W.; Son, H.I. An Intelligent Spraying System with Deep Learning-based Semantic Segmentation of Fruit Trees in Orchards. In Proceedings of the 2020 IEEE international conference on robotics and automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Anagnostis, A.; Tagarakis, A.; Kateris, D.; Moysiadis, V.; Sørensen, C.; Pearson, S.; Bochtis, D. Orchard Mapping with Deep Learning Semantic Segmentation. Sensors 2021, 21, 3813. [Google Scholar] [CrossRef]
- Martins, J.; Nogueira, K.; Osco, L.; Gomes, F.; Furuya, D.; Gonçalves, W.; Sant’Ana, D.; Ramos, A.; Liesenberg, V.; dos Santos, J.; et al. Semantic Segmentation of Tree-Canopy in Urban Environment with Pixel-Wise Deep Learning. Remote Sens. 2021, 13, 3054. [Google Scholar] [CrossRef]
- Seol, J.; Kim, J.; Son, H.I. Field evaluations of a deep learning-based intelligent spraying robot with flow control for pear orchards. Precis. Agric. 2022, 23, 712–732. [Google Scholar] [CrossRef]
- Lin, G.; Tang, Y.; Zou, X.; Wang, C. Three-dimensional reconstruction of guava fruits and branches using instance segmentation and geometry analysis. Comput. Electron. Agric. 2021, 184, 106107. [Google Scholar] [CrossRef]
- Xu, P.; Fang, N.; Liu, N.; Lin, F.; Yang, S.; Ning, J. Visual recognition of cherry tomatoes in plant factory based on improved deep instance segmentation. Comput. Electron. Agric. 2022, 197. [Google Scholar] [CrossRef]
- Zhang, C.; Ding, H.; Shi, Q.; Wang, Y. Grape Cluster Real-Time Detection in Complex Natural Scenes Based on YOLOv5s Deep Learning Network. Agriculture 2022, 12, 1242. [Google Scholar] [CrossRef]
- Craze, H.A.; Pillay, N.; Joubert, F.; Berger, D.K. Deep Learning Diagnostics of Gray Leaf Spot in Maize under Mixed Disease Field Conditions. Plants 2022, 11, 1942. [Google Scholar] [CrossRef]
- Love, N.L.R.; Bonnet, P.; Goëau, H.; Joly, A.; Mazer, S.J. Machine Learning Undercounts Reproductive Organs on Herbarium Specimens but Accurately Derives Their Quantitative Phenological Status: A Case Study of Streptanthus tortuosus. Plants 2021, 10, 2471. [Google Scholar] [CrossRef]
- Safonova, A.; Guirado, E.; Maglinets, Y.; Alcaraz-Segura, D.; Tabik, S. Olive Tree Biovolume from UAV Multi-Resolution Image Segmentation with Mask R-CNN. Sensors 2021, 21, 1617. [Google Scholar] [CrossRef]
- Hao, Z.; Lin, L.; Post, C.J.; Mikhailova, E.A.; Li, M.; Chen, Y.; Yu, K.; Liu, J. Automated tree-crown and height detection in a young forest plantation using mask region-based convolutional neural network (Mask R-CNN). ISPRS J. Photogramm. Remote Sens. 2021, 178, 112–123. [Google Scholar] [CrossRef]
- Zhang, C.; Zhou, J.; Wang, H.; Tan, T.; Cui, M.; Huang, Z.; Wang, P.; Zhang, L. Multi-Species Individual Tree Segmentation and Identification Based on Improved Mask R-CNN and UAV Imagery in Mixed Forests. Remote Sens. 2022, 14, 874. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, D.; Liu, Z.; Gu, X.; Wu, W.; Chen, Y.; Wang, L. Automatic Detection of Pothole Distress in Asphalt Pavement Using Improved Convolutional Neural Networks. Remote Sens. 2022, 14, 3892. [Google Scholar] [CrossRef]
- Liu, Z.; Gu, X.; Chen, J.; Wang, D.; Chen, Y.; Wang, L. Automatic recognition of pavement cracks from combined GPR B-scan and C-scan images using multiscale feature fusion deep neural networks. Autom. Constr. 2023, 146, 104698. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, W.; Gu, X.; Li, S.; Wang, L.; Zhang, T. Application of Combining YOLO Models and 3D GPR Images in Road Detection and Maintenance. Remote Sens. 2021, 13, 1081. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet plus plus: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1866. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Hao, Y.; Liu, Y.; Wu, Z.; Han, L.; Chen, Y.; Chen, G.; Chu, L.; Tang, S.; Yu, Z.; Chen, Z.; et al. EdgeFlow: Achieving Practical Interactive Segmentation with Edge-Guided Flow. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2014. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Liu, Z.; Gu, X.; Wu, W.; Zou, X.; Dong, Q.; Wang, L. GPR-based detection of internal cracks in asphalt pavement: A combination method of DeepAugment data and object detection. Measurement 2022, 197, 111281. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Revaud, J.; Almazan, J.; Rezende, R.; De Souza, C. Learning with Average Precision: Training Image Retrieval with a Listwise Loss. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef] [Green Version]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv preprint 2017, arXiv:1704.06857. [Google Scholar]
- Wang, D.; He, D. Fusion of Mask RCNN and attention mechanism for instance segmentation of apples under complex background. Comput. Electron. Agric. 2022, 196, 106864. [Google Scholar] [CrossRef]
- Liu, Z.; Yeoh, J.K.; Gu, X.; Dong, Q.; Chen, Y.; Wu, W.; Wang, L.; Wang, D. Automatic pixel-level detection of vertical cracks in asphalt pavement based on GPR investigation and improved mask R-CNN. Autom. Constr. 2023, 146, 104689. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, H.; Sun, K.; Tian, Z.; Shen, C.; Huang, Y.; Yan, Y. Blendmask: Top-down meets bottom-up for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Tian, Z.; Shen, C.; Wang, X.; Chen, H. Boxinst: High-performance instance segmentation with box annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H. Conditional Convolutions for Instance Segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
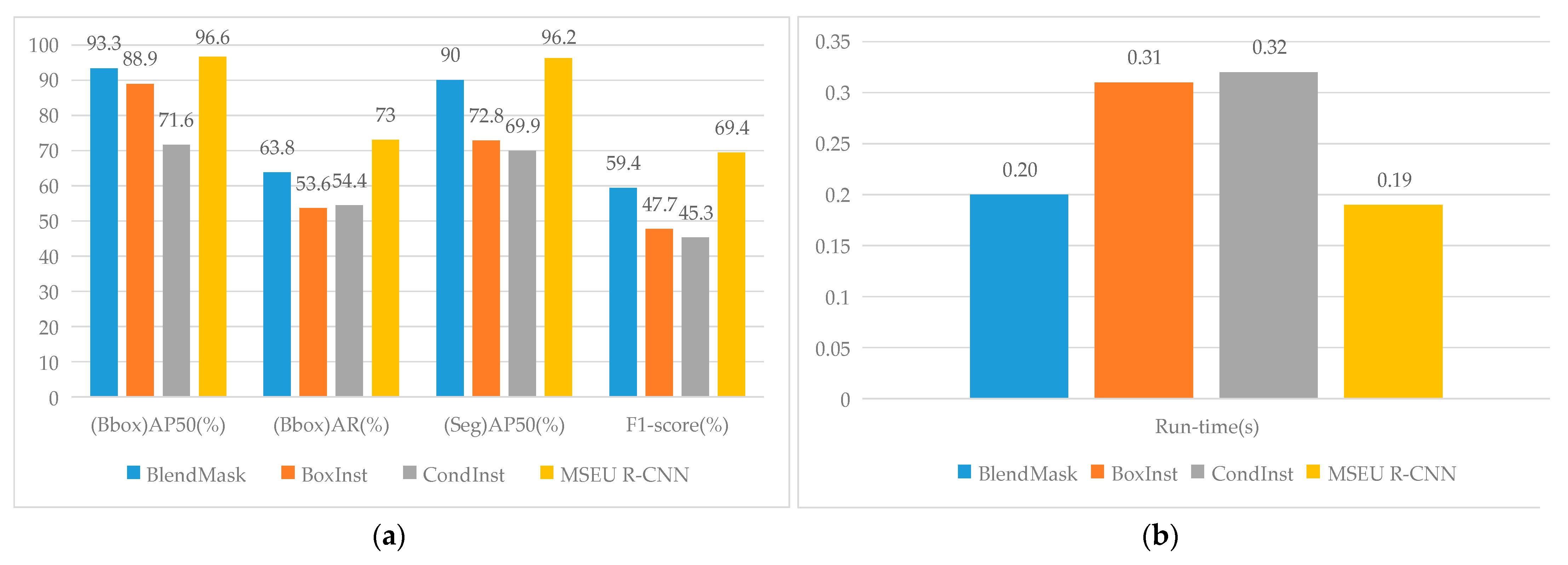{kind=link}
{kind=link}
| Sensors | Advantages | Disadvantages |
|---|---|---|
| Ultrasonic sensors |
|
|
| Lidar sensors |
|
|
| Infrared sensors |
|
|
| Camera sensors |
|
|
| Dataset 1 | Dataset 2 | |||||
|---|---|---|---|---|---|---|
| Growth Period | Training Set | Verification Set | Testing Set | Training Set | Verification Set | Testing Set |
| Seedling | 455 | 132 | 65 | 425 | 152 | 68 |
| Flourishing | 464 | 146 | 66 | 479 | 131 | 67 |
| Fruition | 481 | 122 | 69 | 496 | 107 | 64 |
| Dataset | (Bbox)AP | (Bbox)AR | (Seg)AP | F1-Score |
|---|---|---|---|---|
| No using RGB-D | 0.5792 | 0.6540 | 0.5737 | 0.6143 |
| Using RGB-D | 0.5809 | 0.6793 | 0.5747 | 0.6263 |
| Promotion ratio | 0.3% | 4.0% | 0.1% | 2.0% |
| Evaluating Indicator | Seedling | Flourishing | Fruiting | Average Value |
|---|---|---|---|---|
| (Bbox) AP50 (%) | 95.2 | 99.5 | 95.1 | 96.6 |
| (Bbox) AR (%) | 66.8 | 82.0 | 70.3 | 73.0 |
| (Seg) AP50 (%) | 95.6 | 99.7 | 93.1 | 96.2 |
| F1-score (%) | 62.7 | 80.0 | 65.2 | 69.4 |
| Number | Model | Backbone | Mask Branch |
|---|---|---|---|
| Model 1 | Mask R-CNN | ResNet-18-FPN | FCN |
| Model 2 | Mask R-CNN | ResNet-50-FPN | FCN |
| Model 3 | Mask R-CNN | ResNet-101-FPN | FCN |
| Model 4 | Mask R-CNN | ResNext-50-FPN | FCN |
| Model 5 | Mask R-CNN | SE-ResNet-18-FPN | FCN |
| Model 6 | MSEU R-CNN | SE-ResNet-18-FPN | Unet++ |
| Number | (Bbox)AP50 (%) | (Bbox)AR (%) | (Seg)AP50 (%) | F1-Score (%) | MioU50 (%) | Run-Time (s) |
|---|---|---|---|---|---|---|
| Model 1 | 93.2 | 70.6 | 91.3 | 65.6 | 64.6 | 0.17 |
| Model 2 | 77.9 | 57.3 | 76.7 | 52.0 | 61.0 | 0.18 |
| Model 3 | 80.7 | 57.8 | 75.5 | 54.1 | 56.6 | 0.21 |
| Model 4 | 80.5 | 61.4 | 77.4 | 57.1 | 71.0 | 0.23 |
| Model 5 | 93.8 | 72.9 | 93.6 | 68.4 | 72.9 | 0.19 |
| Model 6 | 96.6 | 73.0 | 96.2 | 69.4 | 74.2 | 0.19 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cong, P.; Zhou, J.; Li, S.; Lv, K.; Feng, H. Citrus Tree Crown Segmentation of Orchard Spraying Robot Based on RGB-D Image and Improved Mask R-CNN. Appl. Sci. 2023, 13, 164. https://doi.org/10.3390/app13010164
Cong P, Zhou J, Li S, Lv K, Feng H. Citrus Tree Crown Segmentation of Orchard Spraying Robot Based on RGB-D Image and Improved Mask R-CNN. Applied Sciences. 2023; 13(1):164. https://doi.org/10.3390/app13010164
Chicago/Turabian StyleCong, Peichao, Jiachao Zhou, Shanda Li, Kunfeng Lv, and Hao Feng. 2023. "Citrus Tree Crown Segmentation of Orchard Spraying Robot Based on RGB-D Image and Improved Mask R-CNN" Applied Sciences 13, no. 1: 164. https://doi.org/10.3390/app13010164
APA StyleCong, P., Zhou, J., Li, S., Lv, K., & Feng, H. (2023). Citrus Tree Crown Segmentation of Orchard Spraying Robot Based on RGB-D Image and Improved Mask R-CNN. Applied Sciences, 13(1), 164. https://doi.org/10.3390/app13010164