
Automatic Speech Recognition for Uyghur, Kazakh, and Kyrgyz: An Overview

 , and
, and 
Abstract
:1. Introduction
2. Low-Resource Language Speech Recognition
2.1. History of Speech Recognition Technology
2.2. Methods of Low-Resource Language Speech Recognition
2.2.1. Data Augmentation
2.2.2. Phoneme Mapping
2.2.3. Feature Sharing
2.2.4. Unsupervised Learning
2.2.5. Completely Unsupervised Learning
2.2.6. Massively Multilingual Modeling
2.2.7. Other Resources
3. Linguistic Analysis of Uyghur, Kazakh, and Kyrgyz
3.1. Commonalities of the Three Languages
3.2. Individualities of Each Language
3.2.1. Alphabets
3.2.2. Phoneme Set
3.2.3. Vowel Harmony
3.2.4. Vowel Reduction
3.2.5. Other Differences
4. Advances in Speech Recognition for Uyghur, Kazakh, and Kyrgyz
4.1. Resource Accumulation
4.1.1. THUYG-20
4.1.2. M2ASR
4.1.3. Common Voice
4.1.4. KSC/KSC2

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resource | Language | Date | Contributor | Data Size | Attributes |
|---|---|---|---|---|---|
| THUYG-20 [112] | Uyghur | 2017 | THU & XJU | Speech: 20 h | Reading, Office, Mic |
| M2ASR-Uyghur | Uyghur | 2021 | M2ASR | Speech: 136 h, Text: 88 M | Reading, Mobile |
| M2ASR-Kazakh [118] | Kazakh | 2021 | M2ASR | Speech: 78 h, Text: 100 M | Reading, Mobile |
| M2ASR-Kyrgyz | Kyrgyz | 2021 | M2ASR | Speech: 166 h, Text: 6 M | Reading, Mobile |
| CommonV-Uyghur [102] | Uyghur | 2021 | Mozilla, etc. | Speech: 119 h | Crowdsourced |
| CommonV-Kazakh [102] | Kazakh | 2021 | Mozilla, etc. | Speech: 2 h | Crowdsourced |
| CommonV-Kyrgyz [102] | Kyrgyz | 2021 | Mozilla, etc. | Speech: 2 h | Crowdsourced |
| IARPA-Kazakh [100] | Kazakh | 2021 | IARPA | Speech: 64 h | Mic and Telephone |
| KSC [114] | Kazakh | 2020 | ISSAI | Speech: 332 h | Crowdsourced |
| KazakhTTS [115] | Kazakh | 2021 | ISSAI | Speech: 93 h | 2 Speakers |
| KazakhTTS2 [116] | Kazakh | 2022 | ISSAI | Speech: 271 h | 5 Speakers |
| KSC2 [117] | Kazakh | 2022 | ISSAI | Speech: 1128 h | Crowdsourced, Reading |
4.2. Technical Development
4.2.1. Uyghur
4.2.2. Kazakh
4.2.3. Kyrgyz
4.3. Analysis and Discussion
4.3.1. The Importance of Open-Source Data
4.3.2. The Diversity of Data Sources
4.3.3. Language Individuality Not Fully Used
4.3.4. Language Commonality Not Fully Used
5. Conclusions and Discussions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Uyghur Phoneme Table


Appendix B. Kazakh Phoneme Table


Appendix C. Kyrgyz Phoneme Table

Appendix D. Differences in Arabic Character Sets of the Three Languages


References
- Besacier, L.; Barnard, E.; Karpov, A.; Schultz, T. Automatic speech recognition for under-resourced languages: A survey. Speech Commun. 2014, 56, 85–100. [Google Scholar] [CrossRef]
- Wu, H. A Comparative Study on the Phonetics of Turkic Languages; Minzu University of China Press: Beijing, China, 2011. [Google Scholar]
- Yu, D.; Deng, L. Automatic Speech Recognition; Springer: Berlin/Heidelberg, Germany, 2016; Volume 1. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Deng, L.; Hinton, G.; Kingsbury, B. New types of deep neural network learning for speech recognition and related applications: An overview. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–30 May 2013; pp. 8599–8603. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Penn, G. Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4277–4280. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef] [Green Version]
- Bi, M.; Qian, Y.; Yu, K. Very deep convolutional neural networks for LVCSR. In Proceedings of the INTERSPEECH, Dresden, Germany, 6–12 September 2015; pp. 3259–3263. [Google Scholar]
- Sercu, T.; Puhrsch, C.; Kingsbury, B.; LeCun, Y. Very deep multilingual convolutional neural networks for LVCSR. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4955–4959. [Google Scholar]
- Yu, D.; Xiong, W.; Droppo, J.; Stolcke, A.; Ye, G.; Li, J.; Zweig, G. Deep convolutional neural networks with layer-wise context expansion and attention. In Proceedings of the INTERSPEECH, San Francisc, CA, USA, 8–12 September 2016; pp. 17–21. [Google Scholar]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition. arXiv 2014, arXiv:1402.1128. [Google Scholar]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–30 May 2013; pp. 6645–6649. [Google Scholar]
- Li, X.; Wu, X. Constructing long short-term memory based deep recurrent neural networks for large vocabulary speech recognition. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 4520–4524. [Google Scholar]
- Miao, Y.; Metze, F. On speaker adaptation of long short-term memory recurrent neural networks. In Proceedings of the INTERSPEECH, Dresden, Germany, 6–12 September 2015; pp. 1101–1105. [Google Scholar]
- Miao, Y.; Li, J.; Wang, Y.; Zhang, S.X.; Gong, Y. Simplifying long short-term memory acoustic models for fast training and decoding. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2284–2288. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar]
- He, Y.; Sainath, T.N.; Prabhavalkar, R.; McGraw, I.; Alvarez, R.; Zhao, D.; Rybach, D.; Kannan, A.; Wu, Y.; Pang, R.; et al. Streaming end-to-end speech recognition for mobile devices. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6381–6385. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; Volume 30. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Dong, L.; Xu, S.; Xu, B. Speech-transformer: A no-recurrence sequence-to-sequence model for speech recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5884–5888. [Google Scholar]
- Karita, S.; Chen, N.; Hayashi, T.; Hori, T.; Inaguma, H.; Jiang, Z.; Someki, M.; Soplin, N.E.Y.; Yamamoto, R.; Wang, X.; et al. A comparative study on Transformer vs RNN in speech applications. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2019; pp. 449–456. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. wav2vec: Unsupervised pre-training for speech recognition. arXiv 2019, arXiv:1904.05862. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Hsu, W.N.; Bolte, B.; Tsai, Y.H.H.; Lakhotia, K.; Salakhutdinov, R.; Mohamed, A. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3451–3460. [Google Scholar] [CrossRef]
- Bourlard, H.A.; Morgan, N. Connectionist Speech Recognition: A Hybrid Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 247. [Google Scholar]
- Rabiner, L.; Juang, B.H. Fundamentals of Speech Recognition; Prentice-Hall, Inc.: Hoboken, NJ, USA, 1993. [Google Scholar]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech recognition using deep neural networks: A systematic review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Li, J.; Deng, L.; Haeb-Umbach, R.; Gong, Y. Robust Automatic Speech Recognition: A Bridge to Practical Applications; Academic Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Li, J. Recent advances in end-to-end automatic speech recognition. APSIPA Trans. Signal Inf. Process. 2022, 11. [Google Scholar] [CrossRef]
- Wang, D.; Wang, X.; Lv, S. An overview of end-to-end automatic speech recognition. Symmetry 2019, 11, 1018. [Google Scholar] [CrossRef] [Green Version]
- Padmanabhan, J.; Johnson Premkumar, M.J. Machine learning in automatic speech recognition: A survey. IETE Tech. Rev. 2015, 32, 240–251. [Google Scholar] [CrossRef]
- Hasegawa-Johnson, M.A.; Jyothi, P.; McCloy, D.; Mirbagheri, M.; Di Liberto, G.M.; Das, A.; Ekin, B.; Liu, C.; Manohar, V.; Tang, H.; et al. ASR for under-resourced languages from probabilistic transcription. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 25, 50–63. [Google Scholar] [CrossRef]
- Yin, S.; Liu, C.; Zhang, Z.; Lin, Y.; Wang, D.; Tejedor, J.; Zheng, T.F.; Li, Y. Noisy training for deep neural networks in speech recognition. EURASIP J. Audio Speech Music. Process. 2015, 2015, 2. [Google Scholar] [CrossRef]
- Cui, X.; Goel, V.; Kingsbury, B. Data augmentation for deep neural network acoustic modeling. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 469–1477. [Google Scholar]
- Kim, C.; Misra, A.; Chin, K.; Hughes, T.; Narayanan, A.; Sainath, T.; Bacchiani, M. Generation of large-scale simulated utterances in virtual rooms to train deep-neural networks for far-field speech recognition in Google Home. In Proceedings of the INTERSPEECH 2017, Stockholm, Sweden, 20–24 August 2017; pp. 379–383. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Khudanpur, S. Audio augmentation for speech recognition. In Proceedings of the INTERSPEECH, Dresden, Germany, 6–12 September 2015; pp. 3586–3589. [Google Scholar]
- Jaitly, N.; Hinton, G.E. Vocal tract length perturbation (VTLP) improves speech recognition. In Proceedings of the ICML Workshop on Deep Learning for Audio, Speech and Language, Atlanta, GA, USA, 16 June 2013; Volume 117, p. 21. [Google Scholar]
- Laptev, A.; Korostik, R.; Svischev, A.; Andrusenko, A.; Medennikov, I.; Rybin, S. You do not need more data: Improving end-to-end speech recognition by text-to-speech data augmentation. In Proceedings of the 2020 13th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Chengdu, China, 17–19 October 2020; pp. 439–444. [Google Scholar]
- Li, J.; Gadde, R.; Ginsburg, B.; Lavrukhin, V. Training neural speech recognition systems with synthetic speech augmentation. arXiv 2018, arXiv:1811.00707. [Google Scholar]
- Du, C.; Yu, K. Speaker augmentation for low resource speech recognition. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7719–7723. [Google Scholar]
- Xu, J.; Tan, X.; Ren, Y.; Qin, T.; Li, J.; Zhao, S.; Liu, T.Y. Lrspeech: Extremely low-resource language speech synthesis and recognition. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 2802–2812. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Meng, L.; Xu, J.; Tan, X.; Wang, J.; Qin, T.; Xu, B. MixSpeech: Data augmentation for low-resource automatic speech recognition. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7008–7012. [Google Scholar]
- Nguyen, T.S.; Stueker, S.; Niehues, J.; Waibel, A. Improving sequence-to-sequence speech recognition training with on-the-fly data augmentation. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7689–7693. [Google Scholar]
- Kanda, N.; Takeda, R.; Obuchi, Y. Elastic spectral distortion for low resource speech recognition with deep neural networks. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; pp. 309–314. [Google Scholar]
- Ragni, A.; Knill, K.M.; Rath, S.P.; Gales, M.J. Data augmentation for low resource languages. In Proceedings of the INTERSPEECH. International Speech Communication Association (ISCA), Singapore, 14–18 September 2014; pp. 810–814. [Google Scholar]
- Gokay, R.; Yalcin, H. Improving low resource Turkish speech recognition with data augmentation and TTS. In Proceedings of the 2019 16th International Multi-Conference on Systems, Signals & Devices (SSD), Istanbul, Turkey, 21–24 March 2019; pp. 357–360. [Google Scholar]
- Hartmann, W.; Ng, T.; Hsiao, R.; Tsakalidis, S.; Schwartz, R.M. Two-stage data augmentation for low-resourced speech recognition. In Proceedings of the INTERSPEECH, San Francisc, CA, USA, 8–12 September 2016; pp. 2378–2382. [Google Scholar]
- Schultz, T.; Waibel, A. Experiments on cross-language acoustic modeling. In Proceedings of the INTERSPEECH, Aalborg, Denmark, 3–7 September 2001; pp. 2721–2724. [Google Scholar]
- Lööf, J.; Gollan, C.; Ney, H. Cross-language bootstrapping for unsupervised acoustic model training: Rapid development of a Polish speech recognition system. In Proceedings of the INTERSPEECH, Brighton, UK, 6–10 September 2009; pp. 88–91. [Google Scholar]
- Heigold, G.; Vanhoucke, V.; Senior, A.; Nguyen, P.; Ranzato, M.; Devin, M.; Dean, J. Multilingual acoustic models using distributed deep neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–30 May 2013; pp. 8619–8623. [Google Scholar]
- Hermansky, H.; Ellis, D.P.; Sharma, S. Tandem connectionist feature extraction for conventional HMM systems. In Proceedings of the 2000 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Istanbul, Turkey, 5–9 June 2000; Volume 3, pp. 1635–1638. [Google Scholar]
- Thomas, S.; Ganapathy, S.; Hermansky, H. Cross-lingual and multi-stream posterior features for low resource LVCSR systems. In Proceedings of the IINTERSPEECH, Chiba, Japan, 26–30 September 2010; pp. 877–880. [Google Scholar]
- Thomas, S.; Ganapathy, S.; Hermansky, H. Multilingual MLP features for low-resource LVCSR systems. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4269–4272. [Google Scholar]
- Knill, K.M.; Gales, M.J.; Rath, S.P.; Woodland, P.C.; Zhang, C.; Zhang, S.X. Investigation of multilingual deep neural networks for spoken term detection. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; pp. 138–143. [Google Scholar]
- Veselỳ, K.; Karafiát, M.; Grézl, F.; Janda, M.; Egorova, E. The language-independent bottleneck features. In Proceedings of the 2012 IEEE Spoken Language Technology Workshop (SLT), Miami, FL, USA, 2–5 December 2012; pp. 336–341. [Google Scholar]
- Tüske, Z.; Pinto, J.; Willett, D.; Schlüter, R. Investigation on cross-and multilingual MLP features under matched and mismatched acoustical conditions. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, USA, 26–30 May 2013; pp. 7349–7353. [Google Scholar]
- Huang, J.T.; Li, J.; Yu, D.; Deng, L.; Gong, Y. Cross-language knowledge transfer using multilingual deep neural network with shared hidden layers. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, USA, 26–30 May 2013; pp. 7304–7308. [Google Scholar]
- Ghoshal, A.; Swietojanski, P.; Renals, S. Multilingual training of deep neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, USA, 26–30 May 2013; pp. 7319–7323. [Google Scholar]
- Dalmia, S.; Sanabria, R.; Metze, F.; Black, A.W. Sequence-based multi-lingual low resource speech recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4909–4913. [Google Scholar]
- Inaguma, H.; Cho, J.; Baskar, M.K.; Kawahara, T.; Watanabe, S. Transfer learning of language-independent end-to-end ASR with language model fusion. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6096–6100. [Google Scholar]
- Watanabe, S.; Hori, T.; Hershey, J.R. Language independent end-to-end architecture for joint language identification and speech recognition. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2017; pp. 265–271. [Google Scholar]
- Cho, J.; Baskar, M.K.; Li, R.; Wiesner, M.; Mallidi, S.H.; Yalta, N.; Karafiat, M.; Watanabe, S.; Hori, T. Multilingual sequence-to-sequence speech recognition: Architecture, transfer learning, and language modeling. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 521–527. [Google Scholar]
- Zhou, S.; Xu, S.; Xu, B. Multilingual end-to-end speech recognition with a single transformer on low-resource languages. arXiv 2018, arXiv:1806.05059. [Google Scholar]
- Shetty, V.M.; NJ, M.S.M. Improving the performance of transformer based low resource speech recognition for Indian languages. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 8279–8283. [Google Scholar]
- Müller, M.; Stüker, S.; Waibel, A. Language adaptive DNNs for improved low resource speech recognition. In Proceedings of the INTERSPEECH, San Francisco, CA, USA, 8–12 September 2016; pp. 3878–3882. [Google Scholar]
- Burget, L.; Schwarz, P.; Agarwal, M.; Akyazi, P.; Feng, K.; Ghoshal, A.; Glembek, O.; Goel, N.; Karafiát, M.; Povey, D.; et al. Multilingual acoustic modeling for speech recognition based on subspace Gaussian mixture models. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 4334–4337. [Google Scholar]
- Povey, D.; Burget, L.; Agarwal, M.; Akyazi, P.; Feng, K.; Ghoshal, A.; Glembek, O.; Goel, N.K.; Karafiát, M.; Rastrow, A.; et al. Subspace Gaussian mixture models for speech recognition. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 4330–4333. [Google Scholar]
- Vu, N.T.; Imseng, D.; Povey, D.; Motlicek, P.; Schultz, T.; Bourlard, H. Multilingual deep neural network based acoustic modeling for rapid language adaptation. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 7639–7643. [Google Scholar]
- Tong, S.; Garner, P.N.; Bourlard, H. Multilingual training and cross-lingual adaptation on CTC-based acoustic model. arXiv 2017, arXiv:1711.10025. [Google Scholar]
- Tong, S.; Garner, P.N.; Bourlard, H. An investigation of multilingual ASR using end-to-end LF-MMI. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6061–6065. [Google Scholar]
- Kim, S.; Seltzer, M.L. Towards language-universal end-to-end speech recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4914–4918. [Google Scholar]
- Tong, S.; Garner, P.N.; Bourlard, H. Fast Language Adaptation Using Phonological Information. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2016; pp. 2459–2463. [Google Scholar]
- Zavaliagkos, G.; Colthurst, T. Utilizing untranscribed training data to improve performance. In Proceedings of the DARPA Broadcast News Transcription and Understanding Workshop, Landsdowne, India, 8–11 February 1998. [Google Scholar]
- Billa, J. Improving low-resource ASR performance with untranscribed out-of-domain data. arXiv 2021, arXiv:2106.01227. [Google Scholar]
- Vu, N.T.; Kraus, F.; Schultz, T. Rapid building of an ASR system for under-resourced languages based on multilingual unsupervised training. In Proceedings of the Twelfth Annual Conference of the International Speech Communication Association, Florence, Italy, 27–31 August 2011. [Google Scholar]
- Renduchintala, A.; Ding, S.; Wiesner, M.; Watanabe, S. Multi-modal data augmentation for end-to-end ASR. arXiv 2018, arXiv:1803.10299. [Google Scholar]
- Conneau, A.; Baevski, A.; Collobert, R.; Mohamed, A.; Auli, M. Unsupervised cross-lingual representation learning for speech recognition. arXiv 2020, arXiv:2006.13979. [Google Scholar]
- Javed, T.; Doddapaneni, S.; Raman, A.; Bhogale, K.S.; Ramesh, G.; Kunchukuttan, A.; Kumar, P.; Khapra, M.M. Towards building ASR systems for the next billion users. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; Volume 36, pp. 10813–10821. [Google Scholar]
- Zhang, Z.Q.; Song, Y.; Wu, M.H.; Fang, X.; Dai, L.R. XLST: Cross-lingual self-training to learn multilingual representation for low resource speech recognition. arXiv 2021, arXiv:2103.08207. [Google Scholar]
- Wiesner, M. Automatic Speech Recognition without Transcribed Speech or Pronunciation Lexicons. Ph.D. Thesis, Johns Hopkins University, Baltimore, MD, USA, 2021. [Google Scholar]
- Wang, C.; Wu, Y.; Qian, Y.; Kumatani, K.; Liu, S.; Wei, F.; Zeng, M.; Huang, X. Unispeech: Unified speech representation learning with labeled and unlabeled data. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 22–23 November 2021; pp. 10937–10947. [Google Scholar]
- Liu, D.R.; Chen, K.Y.; Lee, H.Y.; Lee, L.S. Completely unsupervised phoneme recognition by adversarially learning mapping relationships from audio embeddings. arXiv 2018, arXiv:1804.00316. [Google Scholar]
- Chen, K.Y.; Tsai, C.P.; Liu, D.R.; Lee, H.Y.; Lee, L.S. Completely unsupervised speech recognition by a generative adversarial network harmonized with iteratively refined hidden markov models. arXiv 2019, arXiv:1904.04100. [Google Scholar]
- Baevski, A.; Hsu, W.N.; Conneau, A.; Auli, M. Unsupervised speech recognition. Adv. Neural Inf. Process. Syst. 2021, 34, 27826–27839. [Google Scholar]
- Liu, A.H.; Hsu, W.N.; Auli, M.; Baevski, A. Towards End-to-end Unsupervised Speech Recognition. arXiv 2022, arXiv:2204.02492. [Google Scholar]
- Aldarmaki, H.; Ullah, A.; Ram, S.; Zaki, N. Unsupervised automatic speech recognition: A review. Speech Commun. 2022, 139, 76–91. [Google Scholar] [CrossRef]
- Adams, O.; Wiesner, M.; Watanabe, S.; Yarowsky, D. Massively multilingual adversarial speech recognition. arXiv 2019, arXiv:1904.02210. [Google Scholar]
- Black, A.W. CMU wilderness multilingual speech dataset. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5971–5975. [Google Scholar]
- Pratap, V.; Sriram, A.; Tomasello, P.; Hannun, A.; Liptchinsky, V.; Synnaeve, G.; Collobert, R. Massively multilingual ASR: 50 languages, 1 model, 1 billion parameters. arXiv 2020, arXiv:2007.03001. [Google Scholar]
- Li, X.; Metze, F.; Mortensen, D.R.; Black, A.W.; Watanabe, S. ASR2K: Speech recognition for around 2000 languages without audio. arXiv 2022, arXiv:2209.02842. [Google Scholar]
- Moran, S.; McCloy, D. PHOIBLE 2.0. Jena: Max Planck Institute for the Science of Human History. 2019. Available online: https://phoible.org/ (accessed on 25 December 2022).
- Schultz, T. Globalphone: A multilingual speech and text database developed at Karlsruhe university. In Proceedings of the Seventh International Conference on Spoken Language Processing, Denver, CO, USA, 16–20 September 2002. [Google Scholar]
- Harper, M.P. Data Resources to Support the Babel Program Intelligence Advanced Research Projects Activity (IARPA). 2011. Available online: https://www.ldc.upenn.edu/sites/www.ldc.upenn.edu/files/harper.pdf (accessed on 25 December 2022).
- Pratap, V.; Xu, Q.; Sriram, A.; Synnaeve, G.; Collobert, R. MLS: A large-scale multilingual dataset for speech research. arXiv 2020, arXiv:2012.03411. [Google Scholar]
- Ardila, R.; Branson, M.; Davis, K.; Henretty, M.; Kohler, M.; Meyer, J.; Morais, R.; Saunders, L.; Tyers, F.M.; Weber, G. Common voice: A massively-multilingual speech corpus. arXiv 2019, arXiv:1912.06670. [Google Scholar]
- Roger, V.; Farinas, J.; Pinquier, J. Deep neural networks for automatic speech processing: A survey from large corpora to limited data. EURASIP J. Audio Speech Music Process. 2022, 2022, 19. [Google Scholar] [CrossRef]
- Yadav, H.; Sitaram, S. A survey of multilingual models for automatic speech recognition. arXiv 2022, arXiv:2202.12576. [Google Scholar]
- Wikipedia. Turkic Languages. Available online: https://en.wikipedia.org/wiki/Turkic_languages (accessed on 27 September 2022).
- Wikipedia. Kyrgyz Language. Available online: https://en.wikipedia.org/wiki/Kyrgyz_language (accessed on 27 September 2022).
- Xue, H.-J.; Dong, X.-H.; Zhou, X.; Turghun, O.; Li, X. Research on Uyghur speech recognition based on subword unit. Comput. Eng. 2011, 37, 208–210. [Google Scholar]
- Abulhasm, U. Comparison of vowel systems in Kazakh, Kirgiz and Uyghur languages. J. Course Educ. Res. 2014, 88–89. [Google Scholar]
- Wang, L.; Yidemucao, D.; Silamu, W.S. An investigation research on the similarity of Uyghur Kazakh Kyrgyz and Mongolian languages. J. Chin. Inf. Process. 2013, 27, 180–186. [Google Scholar]
- Yishak, T. On phonetic differences between Kirgiz and Uyghur languages and their causes. J. Hetian Norm. Coll. 2015, 69–74. [Google Scholar]
- Xin, R. Research on Harmonious Pronunciation Mechanism of Kazakh Phonetics; China Social Sciences Press: Beijing, China, 2022. [Google Scholar]
- Rouzi, A.; Shi, Y.; Zhiyong, Z.; Dong, W.; Hamdulla, A.; Fang, Z. THUYG-20: A free Uyghur speech database. J. Tsinghua Univ. Sci. Technol. 2017, 57, 182–187. [Google Scholar]
- Wang, D.; Zheng, T.F.; Tang, Z.; Shi, Y.; Li, L.; Zhang, S.; Yu, H.; Li, G.; Xu, S.; Hamdulla, A.; et al. M2ASR: Ambitions and first year progress. In Proceedings of the 2017 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment (O-COCOSDA), Seoul, Republic of Korea, 1–3 November 2017; pp. 1–6. [Google Scholar]
- Khassanov, Y.; Mussakhojayeva, S.; Mirzakhmetov, A.; Adiyev, A.; Nurpeiissov, M.; Varol, H.A. A crowdsourced open-source Kazakh speech corpus and initial speech recognition baseline. arXiv 2020, arXiv:2009.10334. [Google Scholar]
- Mussakhojayeva, S.; Janaliyeva, A.; Mirzakhmetov, A.; Khassanov, Y.; Varol, H.A. KazakhTTS: An open-source Kazakh text-to-speech synthesis dataset. arXiv 2021, arXiv:2104.08459. [Google Scholar]
- Mussakhojayeva, S.; Khassanov, Y.; Varol, H.A. KazakhTTS2: Extending the Open-Source Kazakh TTS Corpus With More Data, Speakers, and Topics. arXiv 2022, arXiv:2201.05771. [Google Scholar]
- Mussakhojayeva, S.; Khassanov, Y.; Varol, H.A. KSC2: An Industrial-Scale Open-Source Kazakh Speech Corpus. In Proceedings of the INTERSPEECH, Incheon, Republic of Korea, 18–22 September 2015; pp. 1367–1371. [Google Scholar]
- Shi, Y.; Hamdullah, A.; Tang, Z.; Wang, D.; Zheng, T.F. A free Kazakh speech database and a speech recognition baseline. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 745–748. [Google Scholar]
- Wang, K.; Fan, Z.; Turhunjan; Fang, X.; Xu, S.; Wumaier. Integrated speech corpus system of Uyghur language. In Proceedings of the NCMMSC, Harbin, China, 30 July 1998; pp. 366–368. [Google Scholar]
- Wang, K. A Study of Uighur Syllable Speech Recognition and the Base Element of the Recognition. Comput. Sci. 2003, 30, 182–184. [Google Scholar]
- Silamu, W.; Tursun, N.; Saltiniyaz, P. Speech processing technology of Uyghur language. In Proceedings of the 2009 Oriental COCOSDA International Conference on Speech Database and Assessments, Urumqi, China, 10–12 August 2009; pp. 19–24. [Google Scholar]
- Ablimit, M.; Neubig, G.; Mimura, M.; Mori, S.; Kawahara, T.; Hamdulla, A. Uyghur morpheme-based language models and ASR. In Proceedings of the IEEE 10th International Conference on Signal Processing Proceedings, Beijing, China, 24–28 October 2010; pp. 581–584. [Google Scholar]
- Li, X.; Cai, S.; Pan, J.; Yan, Y.; Yang, Y. Large vocabulary Uyghur continuous speech recognition based on stems and suffixes. In Proceedings of the 2010 7th International Symposium on Chinese Spoken Language Processing, Tainan and Sun Moon Lake, Tainan, Taiwan, 29 November–3 December 2010; pp. 220–223. [Google Scholar]
- Tuerxun, T.; Dai, L. Deep neural network based Uyghur large vocabulary continuous speech recognition. J. Data Acquis. Process. 2015, 30, 365–371. [Google Scholar]
- Batexi, Q.; Huanag, H.; Wang, X. Uyghur speech recognition based on deep neural networks. Comput. Eng. Des. 2015, 36, 2239–2244. [Google Scholar]
- Ding, F.-L.; Guo, W.; Sun, J. Research on end-to-end speech recognition system for Uyghur. J. Chin. Comput. Syst. 2020, 41, 19–23. [Google Scholar]
- Subi, A.; Nurmemet, Y.; Huang, H.; Wushouer, S. End to end Uyghur speech recognition based on multi task learning. J. Signal Process. 2021, 37, 1852–1859. [Google Scholar]
- Yolwas, N.; Junhua, L.; Silamu, W.; Tursun, R.; Abilhayer, D. Crosslingual acoustic modeling in Uyghur speech recognition. J. Tsinghua Univ. Sci. Technol. 2018, 58, 342–346. [Google Scholar]
- Wang, J.; Huang, H.; Xu, H.; Hu, Y. Low-resource Uyghur speech recognition based on transfer learning. Comput. Eng. 2018, 44, 281–645. [Google Scholar]
- Abulimiti, A.; Schultz, T. Automatic speech recognition for Uyghur through multilingual acoustic modeling. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 6444–6449. [Google Scholar]
- Shi, Y.; Tang, Z.; Lit, L.; Zhang, Z.; Wang, D. Map and relabel: Towards almost-zero resource speech recognition. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; pp. 591–595. [Google Scholar]
- Ablimit, M.; Parhat, S.; Hamdulla, A.; Zheng, T.F. A multilingual language processing tool for Uyghur, Kazak and Kirghiz. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 737–740. [Google Scholar]
- Hu, P.; Huang, S.; Lv, Z. Investigating the use of mixed-units based modeling for improving Uyghur speech recognition. In Proceedings of the SLTU, Gurugram, India, 29–31 August 2018; pp. 215–219. [Google Scholar]
- Liu, C.; Zhang, Z.; Zhang, P.; Yan, Y. Character-aware subword level language modeling for Uyghur and Turkish ASR. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 3495–3499. [Google Scholar]
- Qiu, Z.; Jiang, W.; Mamut, T. Improving Uyghur ASR systems with decoders using morpheme-based language models. arXiv 2020, arXiv:2003.01509. [Google Scholar]
- Tuersun, R.; Hairula, A.; Yolwas, N.; Silamu, W. Designed research of Uygur dialects speech corpus. In Proceedings of the NCMMSC, Lianyungang, China, 11–13 October 2017. [Google Scholar]
- Bukhari, D.; Wang, Y.; Wang, H. Multilingual convolutional, long short-term memory, deep neural networks for low resource speech recognition. Procedia Comput. Sci. 2017, 107, 842–847. [Google Scholar] [CrossRef]
- Yulong, L.; Dan, Q.; Zhen, L.; Wenlin, Z. Uyghur speech recognition based on convolutional neural network. J. Inf. Eng. Univ. 2017, 18, 44–50. [Google Scholar]
- Ma, G.; Hu, P.; Kang, J.; Huang, S.; Huang, H. Leveraging phone mask training for phonetic-reduction-robust E2E Uyghur speech recognition. arXiv 2022, arXiv:2204.00819. [Google Scholar]
- Khomitsevich, O.; Mendelev, V.; Tomashenko, N.; Rybin, S.; Medennikov, I.; Kudubayeva, S. A bilingual Kazakh-Russian system for automatic speech recognition and synthesis. In Proceedings of the International Conference on Speech and Computer, Athens, Greece, 20–24 September 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 25–33. [Google Scholar]
- Dawel, A.; Nurmemet, Y.; Liu, Y. On language model construction for LVCSR in Kazakh. Comput. Eng. Appl. 2016, 52, 178–181. [Google Scholar]
- Mamyrbayev, O.; Turdalyuly, M.; Mekebayev, N.; Mukhsina, K.; Keylan, A.; BabaAli, B.; Nabieva, G.; Duisenbayeva, A.; Akhmetov, B. Continuous speech recognition of Kazakh language. In Proceedings of the ITM Web of Conferences. EDP Sciences, Timisoara, Romania, 23–26 May 2019; Volume 24, p. 01012. [Google Scholar]
- Mamyrbayev, O.; Turdalyuly, M.; Mekebayev, N.; Alimhan, K.; Kydyrbekova, A.; Turdalykyzy, T. Automatic recognition of Kazakh speech using deep neural networks. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Yogyakarta, Indonesia, 8–11 April 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 465–474. [Google Scholar]
- Mamyrbayev, O.; Alimhan, K.; Zhumazhanov, B.; Turdalykyzy, T.; Gusmanova, F. End-to-end speech recognition in agglutinative languages. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Phuket, Thailand, 23–26 March 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 391–401. [Google Scholar]
- Mamyrbayev, O.Z.; Oralbekova, D.O.; Alimhan, K.; Nuranbayeva, B.M. Hybrid end-to-end model for Kazakh speech recognition. Int. J. Speech Technol. 2022, 1–10. [Google Scholar] [CrossRef]
- Orken, M.; Dina, O.; Keylan, A.; Tolganay, T.; Mohamed, O. A study of transformer-based end-to-end speech recognition system for Kazakh language. Sci. Rep. 2022, 12, 8337. [Google Scholar] [CrossRef] [PubMed]
- Beibut, A.; Darkhan, K.; Olimzhan, B.; Madina, K. Development of Automatic speech recognition for Kazakh language using transfer learning. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 5880–5886. [Google Scholar] [CrossRef]
- Kuanyshbay, D.; Baimuratov, O.; Amirgaliyev, Y.; Kuanyshbayeva, A. Speech data collection system for Kazakh language. In Proceedings of the 2021 16th International Conference on Electronics Computer and Computation (ICECCO), Almaty, Kazakhstan, 25–26 November 2021; pp. 1–8. [Google Scholar]
- Mussakhojayeva, S.; Khassanov, Y.; Atakan Varol, H. A study of multilingual end-to-end speech recognition for Kazakh, Russian, and English. In Proceedings of the International Conference on Speech and Computer, St. Petersburg, Russia, 27–30 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 448–459. [Google Scholar]
- Jie, S.; Silamu, W.; Tursun, R. Research on CMN-based recognition of Kirgiz with less resources. Mod. Electron. Tech. 2018, 41, 132–136. [Google Scholar]
- Kuznetsova, A.; Kumar, A.; Fox, J.D.; Tyers, F.M. Curriculum optimization for low-resource language speech recognition. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 24–28 April 2022; pp. 8187–8191. [Google Scholar]
- Prasad, M.; van Esch, D.; Ritchie, S.; Mortensen, J.F. Building large-vocabulary ASR systems for languages without any audio training data. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 271–275. [Google Scholar]
- Riviere, M.; Joulin, A.; Mazaré, P.E.; Dupoux, E. Unsupervised pretraining transfers well across languages. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7414–7418. [Google Scholar]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S. DARPA TIMIT acoustic-phonetic continous speech corpus CD-ROM. NIST speech disc 1-1.1. NASA STI/Recon Tech. Rep. N 1993, 93, 27403. [Google Scholar]
- Paul, D.B.; Baker, J. The design for the Wall Street Journal-based CSR corpus. In Proceedings of the Speech and Natural Language: Proceedings of a Workshop, Harriman, NY, USA, 23–26 February 1992. [Google Scholar]
- Li, A.; Yin, Z.; Wang, T.; Fang, Q.; Hu, F. RASC863-A Chinese speech corpus with four regional accents. In Proceedings of the ICSLT-o-COCOSDA, New Delhi, India, 17–19 November 2004; pp. 15–19. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Wang, D.; Zhang, X. Thchs-30: A free Chinese speech corpus. arXiv 2015, arXiv:1512.01882. [Google Scholar]
- Bu, H.; Du, J.; Na, X.; Wu, B.; Zheng, H. Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline. In Proceedings of the 2017 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment (O-COCOSDA), Seoul, Republic of Korea, 1–3 November 2017; pp. 1–5. [Google Scholar]
- Du, J.; Na, X.; Liu, X.; Bu, H. Aishell-2: Transforming mandarin ASR research into industrial scale. arXiv 2018, arXiv:1808.10583. [Google Scholar]
- Novotney, S.; Callison-Burch, C. Cheap, fast and good enough: Automatic speech recognition with non-expert transcription. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010; pp. 207–215. [Google Scholar]
- Eskenazi, M.; Levow, G.A.; Meng, H.; Parent, G.; Suendermann, D. Crowdsourcing for Speech Processing: Applications to Data Collection, Transcription and Assessment; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Chen, G.; Chai, S.; Wang, G.; Du, J.; Zhang, W.Q.; Weng, C.; Su, D.; Povey, D.; Trmal, J.; Zhang, J.; et al. GigaSpeech: An evolving, multi-domain ASR corpus with 10,000 hours of transcribed audio. arXiv 2021, arXiv:2106.06909. [Google Scholar]
- Zhang, B.; Lv, H.; Guo, P.; Shao, Q.; Yang, C.; Xie, L.; Xu, X.; Bu, H.; Chen, X.; Zeng, C.; et al. WenetSpeech: A 10,000+ hours multi-domain mandarin corpus for speech recognition. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 24–28 April 2022; pp. 6182–6186. [Google Scholar]
- Nagrani, A.; Chung, J.S.; Xie, W.; Zisserman, A. Voxceleb: Large-scale speaker verification in the wild. Comput. Speech Lang. 2020, 60, 101027. [Google Scholar] [CrossRef]
- Li, L.; Liu, R.; Kang, J.; Fan, Y.; Cui, H.; Cai, Y.; Vipperla, R.; Zheng, T.F.; Wang, D. CN-Celeb: Multi-genre speaker recognition. Speech Commun. 2022, 137, 77–91. [Google Scholar] [CrossRef]
- McCollum, A.G.; Chen, S. Kazakh. J. Int. Phon. Assoc. 2021, 51, 276–298. [Google Scholar] [CrossRef]
- Özçelik, Ö. Kazakh phonology. In Encyclopedia of Turkic Languages and Linguistics; Brill: Leiden, The Netherlands, 1994; 6p, Available online: https://oozcelik.pages.iu.edu/papers/Kazakh%20phonology.pdf (accessed on 26 December 2022).
| Method | Summary |
|---|---|
| Data augmentation | Various data augmentation approaches to simulate complex behavioral and/or environmental variety. |
| Phoneme mapping | Construct correlations between phonemes of different languages, so that one language can borrow models from other languages. This may construct a system for a new language even without any training data. |
| Feature sharing | Resorting to the commonality of human pronunciation, employ multilingual data to train generic acoustic feature extractor, so that the data required for training the acoustic model for a new language can be significantly reduced. |
| Unsupervised learning | Using semi-supervised or self-supervised learning approach to utilize unlabelled data. |
| Completely unsupervised learning | No transcribed data at all, employ unparallel speech and text to train ASR systems. |
| Massively multilingual modeling | Utilize speech data and lexical knowledge of a large amount of languages, to train models for ‘any’ language (nearly). |
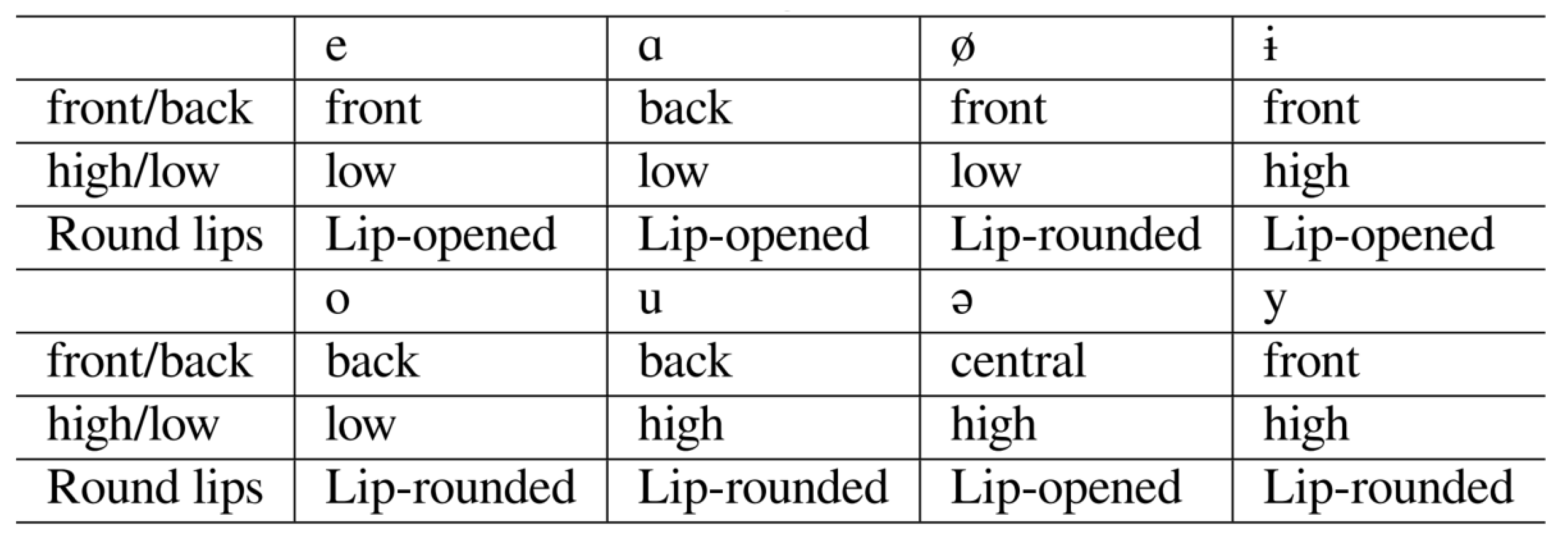
| Vowels | e | a | ø | o | u | y | æ | ɨ | i | ǝ | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Front (←)/Central (•)/Back (→) | ← | → | ← | → | → | ← | ← | ← | • | ← | • |
| Top (↑)/Bottom (↓) | ↓ | ↓ | ↓ | ↓ | ↑ | ↑ | ↓ | ↑ | ↑ | ↑ | ↑ |
| Rounded (o)/Unrounded () | o | o | o | o | |||||||
| Uyghur | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Kazakh | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Kyrgyz | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Models | CER (%) |
|---|---|
| DNN-HMM | 24.3 |
| Chain-TDNN | 17.6 |
| BLSTM-CTC/Attention | 31.5 |
| Transformer-CTC | 21.4 |
| Conformer-CTC | 11.6 |
| Conformer-CTC-MTL | 7.8 |
| ID | Models | LM | SpeedPerturb | SpecAug | Valid | Test | ||
|---|---|---|---|---|---|---|---|---|
| CER (%) | WER (%) | CER (%) | WER (%) | |||||
| 1 | DNN-HMM | Yes | Yes | No | 5.2 | 14.2 | 4.6 | 13.7 |
| 2 | Yes | Yes | Yes | 5.3 | 14.9 | 4.7 | 13.8 | |
| 3 | E2E-LSTM | No | No | No | 9.9 | 32.0 | 8.7 | 28.8 |
| 4 | Yes | No | No | 7.9 | 20.1 | 7.2 | 18.5 | |
| 5 | Yes | Yes | No | 5.7 | 15.9 | 5.0 | 14.4 | |
| 6 | Yes | Yes | Yes | 4.6 | 13.1 | 4.0 | 11.7 | |
| 7 | E2E-Transformer | No | No | No | 6.1 | 22.2 | 4.9 | 18.8 |
| 8 | Yes | No | No | 4.5 | 13.9 | 3.7 | 11.9 | |
| 9 | Yes | Yes | No | 3.9 | 12.3 | 3.2 | 10.5 | |
| 10 | Yes | Yes | Yes | 3.2 | 10.0 | 2.8 | 8.7 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, W.; Maimaitiyiming, Y.; Nijat, M.; Li, L.; Hamdulla, A.; Wang, D. Automatic Speech Recognition for Uyghur, Kazakh, and Kyrgyz: An Overview. Appl. Sci. 2023, 13, 326. https://doi.org/10.3390/app13010326
Du W, Maimaitiyiming Y, Nijat M, Li L, Hamdulla A, Wang D. Automatic Speech Recognition for Uyghur, Kazakh, and Kyrgyz: An Overview. Applied Sciences. 2023; 13(1):326. https://doi.org/10.3390/app13010326
Chicago/Turabian StyleDu, Wenqiang, Yikeremu Maimaitiyiming, Mewlude Nijat, Lantian Li, Askar Hamdulla, and Dong Wang. 2023. "Automatic Speech Recognition for Uyghur, Kazakh, and Kyrgyz: An Overview" Applied Sciences 13, no. 1: 326. https://doi.org/10.3390/app13010326
APA StyleDu, W., Maimaitiyiming, Y., Nijat, M., Li, L., Hamdulla, A., & Wang, D. (2023). Automatic Speech Recognition for Uyghur, Kazakh, and Kyrgyz: An Overview. Applied Sciences, 13(1), 326. https://doi.org/10.3390/app13010326