
Impact of Dataset and Model Parameters on Machine Learning Performance for the Detection of GPS Spoofing Attacks on Unmanned Aerial Vehicles

 ,
,  ,
,
Abstract
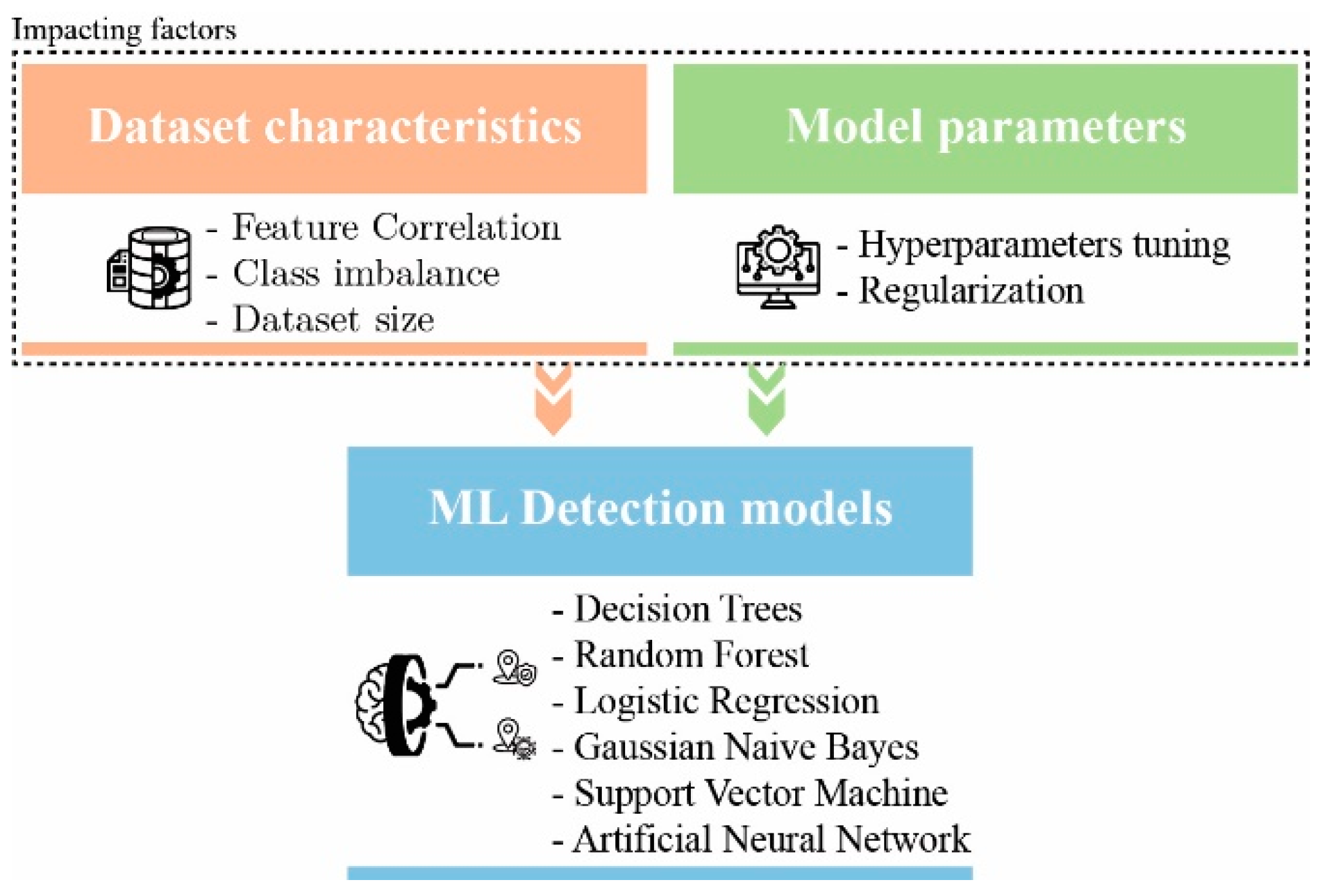
:1. Introduction
- Evaluating the impact of hyperparameter tuning and regularization parameters on the performance of ML techniques to detect GPS spoofing attacks targeting UAVs,
- Evaluating the impact of correlated and uncorrelated features on ML model performance,
- Investigating the impact of correlated features on ML model performance with respect to dataset size,
- Examining the impact of the percentage of malicious samples in the dataset on ML model performance.
2. Methodology
2.1. Dataset Assessment
2.1.1. Data Pre-Processing
2.1.2. Feature Selection
2.2. Classification Techniques
2.3. Hyperparameter Tuning
3. Results
- Tuned hyperparameters and regularized learning parameters improve models’ performance in terms of the selected metrics.
- The presence of correlated features in a dataset degrades models’ performance. Identifying and removing redundant features from the dataset improves significantly this performance.
- Dataset size plays an important role in models’ performance which increases as the size increases.
- Class imbalance leads to biased models with degrading performance.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Manesh, M.R.; Kaabouch, N. Cyber-Attacks on Unmanned Aerial System Networks: Detection, Countermeasure, and Future Research Directions. Comput. Secur. 2019, 85, 386–401. [Google Scholar] [CrossRef]
- Aissou, G.; Slimane, H.O.; Benouadah, S.; Kaabouch, N. Tree-Based Supervised Machine Learning Models for Detecting GPS Spoofing Attacks on UAS. In Proceedings of the 2021 IEEE 12th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 1–4 December 2021; pp. 649–653. [Google Scholar]
- Wesson, K.; Shepard, D.; Humphreys, T. Straight Talk on Anti-Spoofing: Securing the Future of PNT. GPS World 2012, 23, 32–39. [Google Scholar]
- Kwon, K.C.; Shim, D.S. Performance Analysis of Direct GPS Spoofing Detection Method With AHRS/Accelerometer. Sensors 2020, 20, 954. [Google Scholar] [CrossRef] [Green Version]
- Alrefaei, F.; Alzahrani, A.; Song, H.; Alrefaei, S. A Survey on the Jamming and Spoofing attacks on the Unmanned Aerial Vehicle Networks. In Proceedings of the 2022 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), Toronto, ON, Canada, 1–4 June 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Manesh, M.R.; Kenney, J.; Hu, W.C.; Devabhaktuni, V.K.; Kaabouch, N. Detection of GPS Spoofing Attacks on Unmanned Aerial Systems. In Proceedings of the 2019 16th IEEE Annual Consumer Communications and Networking Conference, CCNC 2019, Las Vegas, NV, USA, 11–14 January 2019. [Google Scholar] [CrossRef]
- Meng, L.; Yang, L.; Ren, S.; Tang, G.; Zhang, L.; Yang, F.; Yang, W. An Approach of Linear Regression-Based UAV GPS Spoofing Detection. Wirel. Commun. Mob. Comput. 2021, 2021, 5517500. [Google Scholar] [CrossRef]
- Schmidt, E.; Gatsis, N.; Akopian, D. A GPS Spoofing Detection and Classification Correlator-Based Technique Using the LASSO. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 4224–4237. [Google Scholar] [CrossRef]
- Shafique, A.; Mehmood, A.; Elhadef, M. Detecting Signal Spoofing Attack in UAVs Using Machine Learning Models. IEEE Access 2021, 9, 93803–93815. [Google Scholar] [CrossRef]
- Panice, G.; Luongo, S.; Gigante, G.; Pascarella, D.; di Benedetto, C.; Vozella, A.; Pescapè, A. An SVM-Based Detection Approach for GPS Spoofing Attacks to UAV. In Proceedings of the 2017 23rd International Conference on Automation and Computing (ICAC), Huddersfield, UK, 7–8 September 2017; pp. 1–11. [Google Scholar]
- Wang, S.; Wang, J.; Su, C.; Ma, X. Intelligent Detection Algorithm Against UAVs’ GPS Spoofing Attack. In Proceedings of the International Conference on Parallel and Distributed Systems—ICPADS, Hong Kong, China, 2–4 December 2020; pp. 382–389. [Google Scholar] [CrossRef]
- Semanjski, S.; Semanjski, I.; de Wilde, W.; Muls, A. Use of Supervised Machine Learning for GNSS Signal Spoofing Detection With Validation on Real-World Meaconing and Spoofing Data—Part I. Sensors 2020, 20, 1171. [Google Scholar] [CrossRef] [Green Version]
- Xue, N.; Niu, L.; Hong, L.X.; Li, Z.; Hoffaeller, L.; Pöpper, C. DeepSIM: GPS Spoofing Detection on UAVs Using Satellite Imagery Matching. In Proceedings of the Annual Computer Security Applications Conference 2020, Austin, TX, USA, 7–11 December 2020; pp. 304–319. [Google Scholar]
- Khoei, T.T.; Ismail, S.; Kaabouch, N. Dynamic Selection Techniques for Detecting GPS Spoofing Attacks on UAVs. Sensors 2022, 22, 662. [Google Scholar] [CrossRef]
- Gasimova, A.; Khoei, T.T.; Kaabouch, N. A Comparative Analysis of the Ensemble Models for Detecting GPS Spoofing attacks on UAVs. In Proceedings of the 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 26–29 January 2022; pp. 310–315. [Google Scholar]
- Khoei, T.T.; Gasimova, A.; Ahajjam, M.A.; Shamaileh, K.A.; Devabhaktuni, V.; Kaabouch, N. A Comparative Analysis of Supervised and Unsupervised Models for Detecting GPS Spoofing Attack on UAVs. In Proceedings of the 2022 IEEE International Conference on Electro Information Technology (eIT), Mankato, MN, USA, 19–21 May 2022; pp. 279–284. [Google Scholar] [CrossRef]
- Wei, X.; Sun, C.; Lyu, M.; Song, Q.; Li, Y. ConstDet: Control Semantics-Based Detection for GPS Spoofing Attacks on UAVs. Remote Sens. 2022, 14, 5587. [Google Scholar] [CrossRef]
- Yoon, H.J.; Wan, W.; Kim, H.; Hovakimyan, N.; Sha, L.; Voulgaris, P.G. Towards Resilient UAV: Escape Time in GPS Denied Environment with Sensor Drift. IFAC-PapersOnLine 2019, 52, 423–428. [Google Scholar] [CrossRef]
- Dang, Y.; Benzaïd, C.; Shen, Y.; Taleb, T. GPS Spoofing Detector with Adaptive Trustable Residence Area for Cellular based-UAVs. In Proceedings of the GLOBECOM 2020–2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Qiao, Y.; Zhang, Y.; Du, X. A Vision-Based GPS-Spoofing Detection Method for Small UAVs. In Proceedings of the 13th International Conference on Computational Intelligence and Security, CIS 2017, Hong Kong, China, 15–18 December 2017; pp. 312–316. [Google Scholar]
- Varshosaz, M.; Afary, A.; Mojaradi, B.; Saadatseresht, M.; Parmehr, E.G. Spoofing detection of civilian UAVs using visual odometry. ISPRS Int. J. Geo-Inf. 2019, 9, 6. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Chen, X.Y.; Zhang, H.; Xiong, L.D.; Lei, H.; Deng, S.H. Hyperparameter Optimization for Machine Learning Models Based on Bayesian Optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar] [CrossRef]
- Yeo, I.-K.; Johnson, R.A. A New Family of Power Transformations to Improve Normality or Symmetry. Biometrika 2000, 87, 954–959. [Google Scholar] [CrossRef]
- Friedrichs, F.; Igel, C. Evolutionary Tuning of Multiple SVM Parameters. Neurocomputing 2005, 64, 107–117. [Google Scholar] [CrossRef]
- McHugh, L. The Chi-Square Test of Independence. Biochem. Med. 2013, 23, 143–149. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Fitch, F.B.; McCulloch, W.S.; Pitts, W. A Logical Calculus of the Ideas Immanent in Nervous Activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Murphy, K.P. Naive Bayes Classifiers; University of British Columbia: Vancouver, BC, Canada, 2006; Volume 18, pp. 1–8. [Google Scholar]
- Crawford, S.L. Extensions to the CART Algorithm. Int. J. Man-Mach. Stud. 1989, 31, 197–217. [Google Scholar] [CrossRef]
- Menard, S. Applied Logistic Regression Analysis; Sage: Thousand Oaks, CA, USA, 2002; Volume 106. [Google Scholar]
- Liu, R.; Liu, E.; Yang, J.; Li, M.; Wang, F. Optimizing the Hyper-Parameters for SVM by Combining Evolution Strategies with a Grid Search. Intell. Control. Autom. 2006, 344, 712–721. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Xiang, W.; Zhining, Y. Neural Network Hyperparameter Tuning Based on Improved Genetic Algorithm. ACM Int. Conf. Proc. Ser. 2019, 17–24. [Google Scholar] [CrossRef]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; de Freitas, N. Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proc. IEEE 2016, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, V. Bayesian Optimization for Accelerating Hyper-Parameter Tuning. In Proceedings of the 2019 IEEE Second International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), Sardinia, Italy, 3–5 June 2019; pp. 302–305. [Google Scholar] [CrossRef]
- Khoei, T.T.; Kaabouch, N. Densely Connected Neural Networks for Detecting Denial of Service Attacks on Smart Grid Network. In Proceedings of the 2022 IEEE 13th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 26–29 October 2022; pp. 207–211. [Google Scholar] [CrossRef]
- Ismail, S.; Reza, H. Evaluation of Naïve Bayesian Algorithms for Cyber-Attacks Detection in Wireless Sensor Networks. In Proceedings of the 2022 IEEE 509 World AI IoT Congress (AIIoT), Seattle, WA, USA, 6–9 June 2022; pp. 283–289. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Jafari, F.; Dorafshan, S. Bridge Inspection and Defect Recognition with Using Impact Echo Data, Probability, and Naive Bayes Classifiers. Infrastructures 2021, 6, 132. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detection Model | Dataset Characteristics | Model Parameters | |||
|---|---|---|---|---|---|
| Correlation Technique | Class Imbalance | Dataset Size | Hyperparameter Tuning | Regularization | |
| Artificial Neural Network [6] | - | Balanced | 3000 Samples | - | - |
| Linear Regression-Based and Long Short-Term Memory [7] | - | - | 40,000 Samples | - | - |
| Selection Operator, Least Absolute Shrinkage [8] | Two-Phase Correlator | - | - | Selection Operator and Least Absolute Shrinkage | - |
| K-Learning-Based [9] | - | - | - | - | - |
| Support Vector Machine [10] | - | - | - | - | - |
| Long Short-Term Memory [11] | - | Balanced | - | - | - |
| Support Vector Machine [12] | Pearson’s Correlation Coefficient | - | - | - | - |
| DeepSIM [13] | - | - | 7740 Images | - | - |
| Metric Optimized Dynamic and Weighted Metric Optimized Dynamic [14] | Spearman’s Correlation Coefficient | Balanced | 10,055 Samples | Bayesian Optimization | - |
| Random Forest, Gradient Boost, XGBoost, and LightGBM [2] | Spearman’s Correlation Coefficient | Balanced | 10,055 Samples | - | - |
| Bagging, Boosting, and Stacking [15] | Pearson’s Correlation Coefficient | Balanced | 10,055 Samples | Grid Search | - |
| Gaussian Naïve Bayes, Random Forest, Classification and Regression Decision Tree, Linear-Support Vector Machine, Logistic Regression, Principal Component Analysis, Artificial Neural Network, and Autoencoder [16] | Pearson’s Correlation Coefficient | Balanced | 10,055 Samples | Grid Search and Adadelta optimizer | - |
| Support Vector Machine and K-fold [17] | - | - | - | K-fold cross validation | - |
| CONSDET [18] | Simple Correlation | Balanced | 10,296 Samples | - | - |
| Resilient State Estimation [19] | - | - | - | - | - |
| 5G-assisted UAV [20] | - | - | - | - | - |
| Vision Inertial Measurement Unit [21] | - | - | - | - | - |
| Visual Odometry [22] | - | - | - | - | - |
| Feature | Abbreviation |
|---|---|
| Pseudorandom Number | PRN |
| Carrier Doppler | DO |
| Carrier Phase Shift | CP |
| Pseudo Range | PD |
| Prompt In-phase Component | PIP |
| Receiver Time | RX |
| Prompt Quadrature Component | PQP |
| Time of Week | TOW |
| Prompt Correlator | PC |
| Early Correlator | EC |
| Tracking Carrier Doppler | TCD |
| Carrier to Noise | C/N0 |
| Late Correlator | LC |
| Classifier | Regularized Learning Parameter | Optimal Hyperparameters Values |
|---|---|---|
| SVM | C | C = 8, degree = 1, gamma = 1.717, kernel = ‘poly’ |
| ANN | alpha | activation = ‘identity’, solver = ‘lbfgs’, alpha = 0.173 |
| RF | ccp_alpha | n_estimators = 738, max_depth = 112, min_samples_split = 5, ccp_alpha = 10 |
| GNB | var_smoothing | var_smoothing = 5 |
| CART | ccp_alpha | max_depth = 32.0, Criterion = ‘gini’, splitter = ‘best’, ccp_alpha = 5, max_features = ‘log2’ |
| LR | C | max_iter = 10, penalty = ‘l2’, C = 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Talaei Khoei, T.; Ismail, S.; Shamaileh, K.A.; Devabhaktuni, V.K.; Kaabouch, N. Impact of Dataset and Model Parameters on Machine Learning Performance for the Detection of GPS Spoofing Attacks on Unmanned Aerial Vehicles. Appl. Sci. 2023, 13, 383. https://doi.org/10.3390/app13010383
Talaei Khoei T, Ismail S, Shamaileh KA, Devabhaktuni VK, Kaabouch N. Impact of Dataset and Model Parameters on Machine Learning Performance for the Detection of GPS Spoofing Attacks on Unmanned Aerial Vehicles. Applied Sciences. 2023; 13(1):383. https://doi.org/10.3390/app13010383
Chicago/Turabian StyleTalaei Khoei, Tala, Shereen Ismail, Khair Al Shamaileh, Vijay Kumar Devabhaktuni, and Naima Kaabouch. 2023. "Impact of Dataset and Model Parameters on Machine Learning Performance for the Detection of GPS Spoofing Attacks on Unmanned Aerial Vehicles" Applied Sciences 13, no. 1: 383. https://doi.org/10.3390/app13010383