1. Introduction
An electro-larynx is the most commonly used assistive device for laryngectomees’ speech recovery. An electro-larynx is easy to understand and operate and suitable for people of all ages and health conditions. However, due to flattened fundamental frequency (F0) and mechanical and radiation noise, electro-laryngeal (EL) speech is insufficiently intelligible and natural, especially for tonal languages such as Mandarin Chinese [
1,
2,
3]. Due to the inflexible variation of F0, Mandarin EL speech sounds mechanical. That is why EL speech is less natural. Large radiation noises result in the poor quality of continuous EL speech. Meanwhile, laryngectomees lack airflow and air pressure, which hampers their pronouncing process. As a result, EL speech is poor in intelligibility. Mandarin Chinese is a tonal language whose intelligibility is greatly influenced by tone variation. Therefore, the inflexible variation of F0 also leads to the poor intelligibility and rhythm of Mandarin EL speech. Although using an F0-controllable electro-larynx, a speaker can pronounce the four tones of Mandarin Chinese speech, the inflexible F0 variation still seriously affects the naturalness of Mandarin EL speech.
To improve the intelligibility and naturalness of EL speech, researchers have tried multiple approaches. During the early stage, researchers mainly tried to improve the electro-larynx, exploring an electro-larynx controlled by biophysical signals. For instance, researches tried to improve the flexibility of F0 variation through applying vocal air pressure signals [
4], neck strap muscle electromyographically activity signals [
5,
6], finger pressure signals [
7] or finger sliding signals [
8,
9]. Meanwhile, radiation noise is still an important factor that influences the intelligibility of EL speech. In this regard, researchers tried to reduce the radiation noise through various approaches including noise cancelling based on adaptive filter [
10,
11,
12] and spectral subtraction [
13,
14,
15]. The enhancement of Mandarin EL speech is different from the enhancement of normal speech with background noise [
16,
17,
18], for that the Mandarin EL speech has the drawbacks of radiation noise and tone errors [
1,
2,
3], which make it more difficult to deal with. Signal processing methods can effectively reduce the radiation noise of Mandarin EL speech [
10,
11,
12,
13,
14,
15]. However, traditional approaches of improving the F0-controllable electro-larynx (this approach cannot reduce the radiation noise) or reducing radiation noise through signal processing (this approach cannot improve the flexibility of F0 variation) still have deficiencies in making EL speech more intelligible and natural. Recently, researchers applied frame-by-frame voice conversion (VC, parallel-dependent VC) to improve the intelligibility and naturalness of the EL speech [
19,
20,
21,
22]. However, this parallel-dependent VC approach is still deficient in enhancing Mandarin EL speech. This deficiency is due to the complicated tone-variation rules of Mandarin EL speech and is more prominent when the Mandarin EL speech is pronounced using a finger-pressed electro-larynx at fixed tone [
23]. Meanwhile, the pipeline approach obtaining semantic content from Mandarin EL speech through automatic speech recognition (ASR) [
24] can also help improve the intelligibility and naturalness of Mandarin EL speech.
Although the pipeline approach [
25] effectively improves the intelligibility and naturalness of Mandarin EL speech, the approach includes multiple steps that may lead to hard-to-improve deficiencies such as high error rate of syllables or low tone accuracy. Therefore, both the parallel-dependent VC and the pipeline approach have their own drawbacks in dealing with Mandarin EL speech. Kaneko et al. [
26] proposed parallel-data-free VC based on cycle-consistent generative adversarial networks (CycleGAN). This CycleGAN-based VC does not require parallel source-target content but has poor performance in dealing with the Mel-Spectrogram [
27]. The CycleGAN-VC3 (VC3 in this paper) proposed by Kaneko et al. [
27] incorporates a 2-1-2 dimension (2D-1D-2D) generator based on time-frequency adaptive normalization (TFAN), an improved version of CycleGAN-VC2 [
28]. However, VC3 is still weak in processing Mandarin EL speech with complicated tone variations. To solve the problem, we design neural networks with 2D-conformer-1D-transformer-2D-transformer (2D-Con-1D-Tran-2D-Con) architecture as the generator for our CycleGAN, which is used to enhance Mandarin EL speech. The transformer proposed by Vaswani, et al. [
29] and conformer proposed by Gulati, et al. [
30] achieve good performance in processing sequential data, and in particular, the transformer can capture long-distance dependencies. The conformer and transformer both have been successful in speech recognition and separation. The conformer in 2D-Con-1D-Tran-2D-Con architecture is used to process the input Mel-Spectrogram and the convolutional layer can capture both frequency and temporal information. The transformer in the proposed architecture can capture the dependencies of the input sequence. The proposed architecture is used to take advantage of both contextual semantic information and frequency information.
WaveNet proposed by Oord et al. [
31] is an advanced speech synthesis technology. As a neural vocoder, WaveNet can synthesize high-quality speech based on low-dimension acoustic features such as the Mel-Spectrogram. WaveNet can effectively make up for the defects of traditional vocoders. In this paper, WaveNet is used to directly convert Mel-Spectrogram parameters into waveform signals.
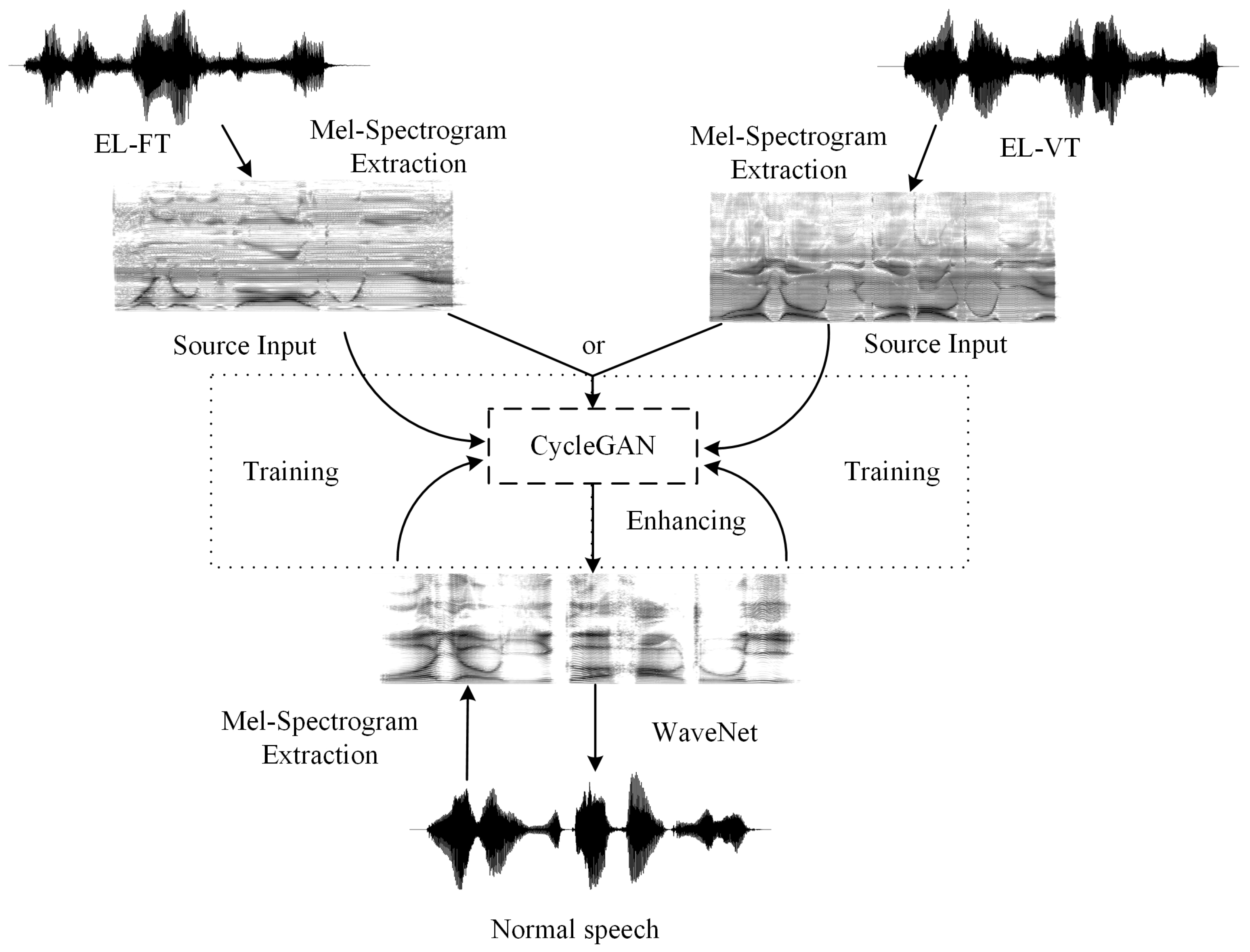
To our knowledge, we are the first to use CycleGAN-based VC to enhance Mandarin EL speech. The main contributions of this paper are as follows: The 2D-Con-1D-Tran-2D-Con neural networks are designed as the generator in CycleGAN to process the input, and the 2D-Conformer is designed as the discriminator in CycleGAN to discriminate whether the predictions approximate the outputs. This architecture is used to capture contextual semantic information to enhance the tone variation of continuous Mandarin EL speech. The CycleGAN-based VC is applied to address the problem that the source speech (Mandarin EL speech) and the target speech (normal speech) are not strictly parallel. This is because the Mandarin EL speech has some tone errors. Objective and subjective evaluations are designed to test the proposed approach. In particular, average tone accuracy and word perception error rate are used in subjective evaluation to explain the effect of enhancement.
The rest of this paper is organized as follows.
Section 2 introduces the proposed methods to further enhance Mandarin EL speech.
Section 3 introduces the experimental results of evaluation for enhancement.
Section 4 discusses the advantages and limitations of the proposed methods.
Section 5 give the conclusions of our research.
4. Discussion
VC is a powerful tool to improve the intelligibility and naturalness of EL speech. Traditional VC approaches are on a parallel-dependent basis and are based on the belief that the mapping relationship from source to target acoustic features can be represented using statistical machine learning. However, parallel-dependent approaches are weak in enhancing Mandarin EL speech, especially EL-FT, because such approaches cannot take advantage of contextual semantic information during processing. CycleGAN is a powerful tool in image transformation [
32], from which we take reference to develop a more effective approach to enhance Mandarin EL speech. Traditionally, parameters including F0, Mel-Cepstrum, and band aperiodicity (extracted using STRAIGHT [
38], or CodeAP extracted using WORLD) are used as acoustic features. In this paper, we use the Mel-Spectrogram parameters instead of a combination of features. The Mel-Spectrogram parameters have been widely applied in the text-to-speech conversion [
39,
40,
41]. The experiment results show that Mel-Spectrogram parameters and the combination of features do not differ greatly from each other in enhancing continuous Mandarin EL speech. Furthermore, we use WaveNet as the neural vocoder to directly resynthesize the Mel-Spectrogram parameters into waveform signals. Our research can be applied to improve the communication ability of the laryngectomees. Additionally, this proposed method can also be used to popularize the application of the Electro-Larynx.
The objective and subjective evaluation results show that the proposed approach performs better than traditional parallel-dependent VC in enhancing Mandarin EL speech. In particular, the proposed approach substantially improves tone accuracy and reduces WER. Moreover, the intelligibility and naturalness MOSs of 2C1T2C-FT are much higher than those of EL-FT, CLDNN-FT and VC3-FT; the intelligibility and naturalness MOSs of 2C1T2C-VT are much higher than those of EL-VT, CLDNN-VT and VC3-VT. This is because the proposed approach takes advantage of contextual semantic information based on the whole input speech. Our approach improves both the frequency and temporal information of Mandarin EL speech.
Although the proposed approach effectively improves the intelligibility and naturalness of Mandarin EL speech, the training process still takes up more than 10 GB of graphics processing unit (GPU) memory and at least 168 h. The time cost of our proposed method, CLDNN-based VC and VC3 are close. In the future, it would be an important task to explore a quicker training process requiring smaller GPU memory. Delay of processing is one major shortcoming of our approach. In the future, we would explore ways to reduce the delay, which would be more useful for laryngectomees.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}